labelme标注及标签的统一
语义分割数据集的标注
这里使用的是labelme语义分割软件。
安装直接使用指令:
pip install labelme
安装完成后,输入指令:labelme,即可打开软件,软件界面如下图所示:


打开软件之后一般需要做3项工作:
(1) 打开数据集存放的文件夹。
(2) 修改标注生成文件的存放位置,并取消在数据集的文件夹内保存标注的生成文件。此外,还需要选择自动保存功能。
(3) 选择标注的形式,一般选择多边形框进行标注。
标注中使用的快捷键:
A:上一张图像
W:下一张图像
标注完成后,生成的文件类型为:json文件,如图所示:

json文件可以使用记事本软件打开,打开后如下图所示:

在获得json文件后,需要制作标签信息。执行以下代码进行转换:
# 在cmd中运行代码:python json2png.py <json文件夹>,单独运行这个文件会报错
import os
import os.path as osp
import cv2
import shutil
import numpy as np
from PIL import Image
def json2png(json_folder, png_save_folder):
#osp.isdir(png_save_folder)用于判断参数是否为目录。
if osp.isdir(png_save_folder):
#递归删除整个文件夹下所有文件,包括此文件夹;
shutil.rmtree(png_save_folder)
# 递归创建文件夹;
os.makedirs(png_save_folder)
#返回指定路径下的文件和文件夹列表。
json_files = os.listdir(json_folder)
for json_file in json_files:
print(json_file)
json_path = osp.join(json_folder, json_file)
os.system("labelme_json_to_dataset {}".format(json_path))
label_path = osp.join(json_folder, json_file.split(".")[0] + "_json/label.png")
png_save_path = osp.join(png_save_folder, json_file.split(".")[0] + ".png")
label_png = cv2.imread(label_path, 1)
# gray_img = cv2.cvtColor(label_png, cv2.COLOR_RGB2GRAY)
# imginfo=label_png.shape
# print(imginfo)
# height=imginfo[0]
# width=imginfo[1]
# dst=np.zeros((height,width,1),np.uint8)
# for i in range(height):
# for j in range(width):
# graypixel=255-label_png[i,j]
# dst[i,j]=graypixel
cv2.imwrite(png_save_path, label_png)
# label_png[label_png > 0] = 255
# cv2.imwrite(png_save_path, label_png)
if __name__ == '__main__':
json_dir = r"D:\feizhongwenxiangmucunchuweizhi\shixi\annotation_test\label_annaotation1" #json所在文件夹
label_dir = r"D:\feizhongwenxiangmucunchuweizhi\shixi\annotation_test\png_1/" #生成之后的标签所在文件夹
json2png(json_folder=json_dir,png_save_folder=label_dir)
制作标签执行json_png文件后,如下图所示:

每个json文件生成一个对应的文档,文档里包含3张图像和1个txt文件。如下图所示:

发现同一标签的颜色不统一,即:同一类别的对象的颜色不同,如下图所示。

图中,同一类别的标签line在不同的标签图像中显示的颜色不同,这会导致网络无法学习。需要对代码进行修改。
查阅大量的文件,最后发现需要对源码进行修改:
首先找到labelme安装的位置,我这里的安装位置如下图所示:

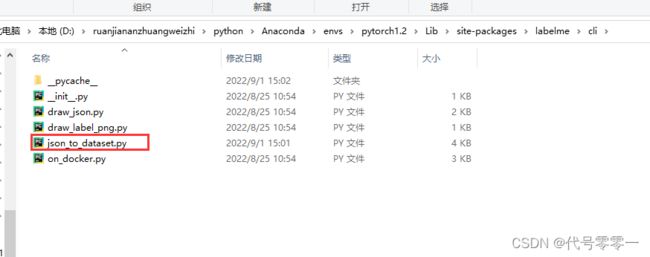
打开json_to_dataset.py文件,注释掉以下代码:
label_name_to_value = {"_background_": 0} #将图片中背景赋值为0
# for shape in sorted(data["shapes"], key=lambda x: x["label"]):
# label_name = shape["label"]
# if label_name in label_name_to_value:
# label_value = label_name_to_value[label_name]
# else:
# label_value = len(label_name_to_value)
# label_name_to_value[label_name] = label_value
然后在改代码后添加以下标签的索引字典,代码如下:
label_name_to_value = {'_background_': 0,
'line': 1,
'border': 2}
最终json_to_dataset.py文件代码如下:
import argparse
import base64
import json
import os
import os.path as osp
import imgviz
import PIL.Image
from labelme.logger import logger
from labelme import utils
def main():
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
#使用 argparse 的第一步是创建一个 ArgumentParser 对象。
# ArgumentParser 对象包含将命令行解析成 Python 数据类型所需的全部信息。
parser = argparse.ArgumentParser()
#给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的
parser.add_argument("json_file")
parser.add_argument("-o", "--out", default=None)
#ArgumentParser 通过 parse_args() 方法解析参数。
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace(".", "_")
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(json_file))
imageData = data.get("imageData")
if not imageData:
imagePath = os.path.join(os.path.dirname(json_file), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
# label_name_to_value = {"_background_": 0} #将图片中背景赋值为0
# for shape in sorted(data["shapes"], key=lambda x: x["label"]):
# label_name = shape["label"]
# if label_name in label_name_to_value:
# label_value = label_name_to_value[label_name]
# else:
# label_value = len(label_name_to_value)
# label_name_to_value[label_name] = label_value
# 加入字典索引后就会按照我们的分类选择label颜色
label_name_to_value = {'_background_': 0,
'line': 1,
'border': 2}
# 为解决问题2的同时,保证label_names.txt只写入当前图像中出现的类别。
lbl, _ = utils.shapes_to_label(
img.shape, data["shapes"], label_name_to_value
)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
# label_names={'_background_','line','border'}
lbl_viz = imgviz.label2rgb(
lbl, imgviz.asgray(img), label_names=label_names, loc="rb"
)
PIL.Image.fromarray(img).save(osp.join(out_dir, "img.png"))
#保存标签图片
utils.lblsave(osp.join(out_dir, "label.png"), lbl)
#保存带标签的可视化图像
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, "label_names.txt"), "w") as f:
for lbl_name in label_names:
f.write(lbl_name + "\n")
logger.info("Saved to: {}".format(out_dir))
if __name__ == "__main__":
main()
注意事项:
以上文件修改结束后,需要重新打开anaconda prompt窗口,然后打开labelme的环境,进入数据集的地址,进行json转png的操作。
以我的为例,具体操作如下:

