Go语言学习笔记【5】 传值/地址/引用、管道、协程
【声明】
非完全原创,部分内容来自于学习其他人的理论和B站视频。如果有侵权,请联系我,可以立即删除掉。
一、函数形参传参的方式
一般有3种:传值、地址、引用
1、传值
go语言中基本数据类型、结构体、数组都是传值。
其特点在于:传递给函数的参数是被传数据的的副本,因此对形参(也就副本)的值进行更改操作时,并不会影响原始数据
同时,由于传值时,需要拷贝一份数据给形参,因此比较耗费资源。
type Student struct {
Name string
Id int
}
func Pass_struct(s Student) {
s.Name = "hello, go"
fmt.Printf("func afer_operating addr s = %p\tvalue_s = %+v\n", &s, s)
}
func Pass_array(arr [3]int) {
arr[0] = 9999
fmt.Printf("func afer_operating addr arr = %p\tvalue_arr = %v\n", &arr, arr)
}
func Pass_value(a bool, b string, c byte, d int8, e complex64, f float32, g rune) {
a = true
b = "hello, go"
c = 'A'
d = 66
e = complex(3, 4) // 3 + 4i
f = 88.0
g = '国'
fmt.Println("func afer_operating addr a = ", &a, "\tvalue_a = ", a)
fmt.Println("func afer_operating addr b = ", &b, "\tvalue_b = ", b)
fmt.Printf("func afer_operating addr c = 0x%x\tvalue_c = %c\n", &c, c)
fmt.Println("func afer_operating addr d = ", &d, "\tvalue_d = ", d)
fmt.Println("func afer_operating addr e = ", &e, "\tvalue_e = ", e)
fmt.Println("func afer_operating addr f = ", &f, "\tvalue_f = ", f)
fmt.Printf("func afer_operating addr g = 0x%x\tvalue_g = %c\n", &g, g)
}
func main() {
s := Student{
Id: 2022,
Name: "Jack",
}
arr := [3]int{7, 7, 7}
a := false
b := "this is a blog!"
var c byte = 'a'
var d int8 = 0
var e complex64 = complex(1, 2)
var f float32 = 0.0
var g rune = '中'
fmt.Printf("\nmain before_operating addr s = %p\tvalue_s = %+v\n", &s, s)
fmt.Printf("main before_operating addr arr = %p\tvalue_arr = %v\n", &arr, arr)
fmt.Println("main before_operating addr a = ", &a, "\tvalue_a = ", a)
fmt.Println("main before_operating addr b = ", &b, "\tvalue_b = ", b)
fmt.Printf("main before_operating addr c = 0x%x\tvalue_c = %c\n", &c, c)
fmt.Println("main before_operating addr d = ", &d, "\tvalue_d = ", d)
fmt.Println("main before_operating addr e = ", &e, "\tvalue_e = ", e)
fmt.Println("main before_operating addr f = ", &f, "\tvalue_f = ", f)
fmt.Printf("main before_operating addr g = 0x%x\tvalue_g = %c\n\n", &g, g)
Pass_struct(s)
Pass_array(arr)
Pass_value(a, b, c, d, e, f, g)
fmt.Printf("\nmain afer_func addr s = %p\tvalue_s = %+v\n", &s, s)
fmt.Printf("main afer_func addr arr = %p\tvalue_arr = %v\n", &arr, arr)
fmt.Println("main afer_func addr a = ", &a, "\tvalue_a = ", a)
fmt.Println("main afer_func addr b = ", &b, "\tvalue_b = ", b)
fmt.Printf("main afer_func addr c = 0x%x\tvalue_c = %c\n", &c, c)
fmt.Println("main afer_func addr d = ", &d, "\tvalue_d = ", d)
fmt.Println("main afer_func addr e = ", &e, "\tvalue_e = ", e)
fmt.Println("main afer_func addr f = ", &f, "\tvalue_f = ", f)
fmt.Printf("main afer_func addr g = 0x%x\tvalue_g = %c\n", &g, g)
}
output:
main before_operating addr s = 0xc00009e060 value_s = {Name:Jack Id:2022}
main before_operating addr arr = 0xc0000ae078 value_arr = [7 7 7]
main before_operating addr a = 0xc0000aa058 value_a = false
main before_operating addr b = 0xc000088240 value_b = this is a blog!
main before_operating addr c = 0xc0000aa059 value_c = a
main before_operating addr d = 0xc0000aa05a value_d = 0
main before_operating addr e = 0xc0000aa090 value_e = (1+2i)
main before_operating addr f = 0xc0000aa098 value_f = 0
main before_operating addr g = 0xc0000aa09c value_g = 中
func afer_operating addr s = 0xc00009e090 value_s = {Name:hello, go Id:2022}
func afer_operating addr arr = 0xc0000ae0a8 value_arr = [9999 7 7]
func afer_operating addr a = 0xc0000aa0d0 value_a = true
func afer_operating addr b = 0xc000088260 value_b = hello, go
func afer_operating addr c = 0xc0000aa0d1 value_c = A
func afer_operating addr d = 0xc0000aa0d2 value_d = 66
func afer_operating addr e = 0xc0000aa0d8 value_e = (3+4i)
func afer_operating addr f = 0xc0000aa0e0 value_f = 88
func afer_operating addr g = 0xc0000aa0e4 value_g = 国
main afer_func addr s = 0xc00009e060 value_s = {Name:Jack Id:2022}
main afer_func addr arr = 0xc0000ae078 value_arr = [7 7 7]
main afer_func addr a = 0xc0000aa058 value_a = false
main afer_func addr b = 0xc000088240 value_b = this is a blog!
main afer_func addr c = 0xc0000aa059 value_c = a
main afer_func addr d = 0xc0000aa05a value_d = 0
main afer_func addr e = 0xc0000aa090 value_e = (1+2i)
main afer_func addr f = 0xc0000aa098 value_f = 0
main afer_func addr g = 0xc0000aa09c value_g = 中
由上可知,参数的地址和原始数据的地址不一样,传值操作不会更改原始数据的值
2、传引用
传值:将变量的副本传递给形参
传引用:将变量的地址复制一份传递给形参,它也可以看作传值,只不过传的是地址值的副本
type Student struct {
Name string
Id int
}
func Pass_addr(a *int, b *Student, c *[3]int, d []int, e map[int]string, f chan int) {
(*a) = 666
(*b).Name = "Hello"
(*b).Id = 1996
c[0] = 888
fmt.Printf("func afer_operating addr a = %p\tvalue_a = %v\n", a, *a)
fmt.Printf("func afer_operating addr b = %p\tvalue_b = %v\n", b, *b)
fmt.Printf("func afer_operating addr c = %p\tvalue_c = %v\n", c, *c)
fmt.Printf("func before_operating addr d = %p\tvalue_d = %v\n", d, d)
fmt.Printf("func before_operating addr e = %p\tvalue_e = %v\n", e, e)
fmt.Printf("func before_operating addr f = %p\ttype_f = %T, len(f) = %d\n\n", f, f, len(f))
d = append(d, 999)
e[0] = "Hello"
<-f
<-f
fmt.Printf("func afer_operating addr d = %p\tvalue_d = %v\n", d, d)
fmt.Printf("func afer_operating addr e = %p\tvalue_e = %v\n", e, e)
fmt.Printf("func afer_operating addr f = %p\ttype_f = %T, len(f) = %d\n", f, f, len(f))
}
func main() {
a := 0
b := Student{"World", 2022}
c := [...]int{0, 0, 0}
d := []int{1, 2, 3}
e := map[int]string{0: "World", 1: "kkk"}
f := make(chan int, 2)
f <- 1
f <- 2
fmt.Printf("before func addr a = %p\tvalue_a = %v\n", &a, a)
fmt.Printf("before func addr b = %p\tvalue_b = %v\n", &b, b)
fmt.Printf("before func addr c = %p\tvalue_c = %v\n", &c, c)
fmt.Printf("before func addr d = %p\tvalue_d = %v\n", d, d)
fmt.Printf("before func addr e = %p\tvalue_e = %v\n", e, e)
fmt.Printf("before func addr f = %p\ttype_f = %T, len(f) = %d\n\n", f, f, len(f))
Pass_addr(&a, &b, &c, d, e, f)
fmt.Printf("\nafter func addr a = %p\tvalue_a = %v\n", &a, a)
fmt.Printf("after func addr b = %p\tvalue_b = %v\n", &b, b)
fmt.Printf("after func addr c = %p\tvalue_c = %v\n", &c, c)
fmt.Printf("after func addr d = %p\tvalue_d = %v\n", d, d)
fmt.Printf("after func addr e = %p\tvalue_e = %v\n", e, e)
fmt.Printf("after func addr f = %p\ttype_f = %T, len(f) = %d\n", f, f, len(f))
}
由下图中的运行结果可以看出:
(1)a、b、c传递的是自身的引用,因此形参的地址和实参的地址是同一个,且形参的修改会直接影响实参
(2)d、e、f是引用类型,存储的是切片/map字典/通道的地址,实质上是指向切片/map字典/通道的指针,因此作为参数时,将地址值的副本传给形参,因此形参所指向的地址和实参所指向的地址是同一个
before func addr a = 0xc0000aa058 value_a = 0
before func addr b = 0xc00009e060 value_b = {World 2022}
before func addr c = 0xc0000ae078 value_c = [0 0 0]
before func addr d = 0xc0000ae090 value_d = [1 2 3]
before func addr e = 0xc0000c2450 value_e = map[0:World 1:kkk]
before func addr f = 0xc0000d4000 type_f = chan int, len(f) = 2
func afer_operating addr a = 0xc0000aa058 value_a = 666
func afer_operating addr b = 0xc00009e060 value_b = {Hello 1996}
func afer_operating addr c = 0xc0000ae078 value_c = [888 0 0]
func before_operating addr d = 0xc0000ae090 value_d = [1 2 3]
func before_operating addr e = 0xc0000c2450 value_e = map[0:World 1:kkk]
func before_operating addr f = 0xc0000d4000 type_f = chan int, len(f) = 2
func afer_operating addr d = 0xc0000c0090 value_d = [1 2 3 999]
func afer_operating addr e = 0xc0000c2450 value_e = map[0:Hello 1:kkk]
func afer_operating addr f = 0xc0000d4000 type_f = chan int, len(f) = 0
after func addr a = 0xc0000aa058 value_a = 666
after func addr b = 0xc00009e060 value_b = {Hello 1996}
after func addr c = 0xc0000ae078 value_c = [888 0 0]
after func addr d = 0xc0000ae090 value_d = [1 2 3]
after func addr e = 0xc0000c2450 value_e = map[0:Hello 1:kkk]
after func addr f = 0xc0000d4000 type_f = chan int, len(f) = 0
3、传地址
传值是将变量值得副本传给形参;
传引用是将 引用类型变量指向的对象地址或者变量的地址 的副本传给形参,形参此时指向变量或者对象,此时形参的操作会直接作用于变量或者对象,但形参重新赋值后则与原引用变量/原变量无关
传地址是将 引用类型变量的地址值或者变量指针的地址值 的副本传给形参,形参指向引用类型变量的地址或者变量指针的地址,此时
形参的赋值将会导致引用类型变量指向别的对象或者变量指针指向别的变量,即赋值会导致重新指向,赋值之后形参的操作与原对象或者变量无关
形参的直接操作会导致影响原对象或者变量,因为形参操作时,go语言会根据指针逐级查找,直到查找到原对象或变量进行操作
传引用和传地址的区别:
(1)当变量为值类型时,传引用和传地址,本质上都是传递变量的地址,区别不大
(2)当变量为引用类型时,它指向了一个对象。此时如果传它的引用,则形参是直接指向对象;如果传指向它的指针,则形参先指向引用类型的变量,而引用类型的变量指向对象,此时构成了间接指向对象。在执行速度上,传引用会稍微比传地址快
如图深紫色表示传引用,形参直接指向对象;亮青色表示传地址,形参指向对象的引用,而对象的引用指向对象

//说明:a传递的是变量的引用,b传递的是指向变量的指针,m1传递的map对象的引用,m2传递的是指向map对象的指针
func PassPointer(a *int, b *int, m1 map[int]string, m2 *map[int]string) {
m := 50
(*a) = 66 //变量的引用,直接作用于原变量
fmt.Printf("func after_op addr_a = %p, val_a = %v", a, *a)
(*b) = 88 //指向变量的指针,直接作用于原变量
fmt.Printf("\tafter_op addr_b = %p, val_b = %v\n", b, *b)
a = &m //传递是原变量的引用,重新指向,此时指针与原变量无关
var n int
b = &n //指针重新指向,此时指针与原变量无关
fmt.Printf("after_repoint addr_a = %p, val_a = %v, addr_b = %p, val_b = %v\n", a, *a, b, *b)
map2 := map[int]string{2: "Study"}
m1[0] = "Go" //map对象的引用,直接作用于原map对象
fmt.Printf("\nfunc after_op addr_m1 = %p, val_m1 = %v", m1, m1)
(*m2)[1] = "666"
fmt.Printf("\tafter_op addr_m2 = %p, val_m2 = %v\n", m2, *m2)
m1 = map2 //引用重新赋值
m2 = &map[int]string{}
fmt.Printf("after_repoint addr_m1 = %p, val_m1 = %v, addr_m2 = %p, val_m2 = %v\n", m1, m1, m2, *m2)
}
func main() {
a := 10 //定义变量a
p := &a //定义变量a的引用p,其本质是*int的指针
var q *int = p //定义指针q,注意指针p、q的地址不一样,但指针都指向变量a
fmt.Printf("main addr_a = %p, val_a = %v\naddr_p = %p, p_point_addr = %p, val_p = %v\naddr_q = %p, q_point_addr = %p, val_q = %v\n\n", &a, a, &p, p, *p, &q, q, *q)
map1 := map[int]string{0: "hello", 1: "World"}
mp := &map1
var mq *map[int]string = mp
fmt.Printf("main addr_map1 = %p, val_map1 = %v\naddr_mp = %p, mp_point_addr = %p, val_mp = %v\naddr_mq = %p, mq_point_addr = %p, val_mq = %v\n\n", map1, map1, &mp, mp, mp, &mq, mq, mq)
PassPointer(&a, q, map1, mq)
fmt.Printf("\n\nmain after func addr_map1 = %p, val_map1 = %v\naddr_mp = %p, mp_point_addr = %p, val_mp = %v\naddr_mq = %p, mq_point_addr = %p, val_mq = %v\n\n", map1, map1, &mp, mp, mp, &mq, mq, mq)
}
由下图可知:go语言只有传值操作(变量的值、变量的地址值、引用对象的地址值、指向引用对象的指针变量的地址值):
(1)传给形参的是值类型变量的引用/指向值类型变量的指针时,实际上传递的是值类型变量的地址,因此形参操作时会改变原变量,但形参重新指向后,则与传给形参的变量引用/指向变量指针断开了联系
(2)传给形参的是引用类型的变量/指向引用类型变量的指针时,实际上传递的分别是引用对象的地址、指向引用对象的指针的地址,无论哪一种,操作都会影响原引用对象,重新指向后则断开了关联
main addr_a = 0xc000126058, val_a = 10
addr_p = 0xc00014a018, p_point_addr = 0xc000126058, val_p = 10
addr_q = 0xc00014a020, q_point_addr = 0xc000126058, val_q = 10
main addr_map1 = 0xc00013e450, val_map1 = map[0:hello 1:World]
addr_mp = 0xc00014a038, mp_point_addr = 0xc00014a030, val_mp = &map[0:hello 1:World]
addr_mq = 0xc00014a040, mq_point_addr = 0xc00014a030, val_mq = &map[0:hello 1:World]
func after_op addr_a = 0xc000126058, val_a = 66 after_op addr_b = 0xc000126058, val_b = 88
after_repoint addr_a = 0xc0001260c0, val_a = 50, addr_b = 0xc0001260c8, val_b = 0
func after_op addr_m1 = 0xc00013e450, val_m1 = map[0:Go 1:World] after_op addr_m2 = 0xc00014a030, val_m2 = map[0:Go 1:666]
after_repoint addr_m1 = 0xc00013e630, val_m1 = map[2:Study], addr_m2 = 0xc00014a048, val_m2 = map[]
main after func addr_map1 = 0xc00013e450, val_map1 = map[0:Go 1:666]
addr_mp = 0xc00014a038, mp_point_addr = 0xc00014a030, val_mp = &map[0:Go 1:666]
addr_mq = 0xc00014a040, mq_point_addr = 0xc00014a030, val_mq = &map[0:Go 1:666]
二、管道
1、简介
channel是go语言协程中数据通信的双向通道,它是一个对应make创建的底层数据结构的引用。与其他引用类型一样,其零值是nil
当然,如果作为函数参数,可以将管道设置单向,避免函数内对其误操作
定义的格式:
make(chan Type) //等价于make(chan Type, 0),无缓冲区的管道
make(chan Type, capacity) //缓冲区为capacity的管道,可以存储capacity个数据
2、chan的使用
2.1、阻塞式chan
func main() {
c := make(chan int)
go func() {
defer fmt.Println("子协程结束")
fmt.Println("子协程开始执行")
for i := 0; i < 5; i++ {
c <- i //往管道中写数据
fmt.Println(i, "子协程写数据, num = ", i)
time.Sleep(time.Microsecond) //给打印预留时间
}
}()
time.Sleep(time.Millisecond * 10)
for i := 0; i < 5; i++ {
fmt.Println(i, "主线程取数据, num = ", <-c)
}
fmt.Println("main协程结束")
}
output:
子协程开始执行
0 子协程写数据, num = 0
0 主线程取数据, num = 0
1 子协程写数据, num = 1
1 主线程取数据, num = 1
2 子协程写数据, num = 2
2 主线程取数据, num = 2
3 子协程写数据, num = 3
3 主线程取数据, num = 3
4 子协程写数据, num = 4
4 主线程取数据, num = 4
main协程结束
说明:
(1)上面代码未打印"子协程结束",是因为主线程在协程之前就结束了,导致协程的defer语句没来得及打印就退出了
(2)虽然在协程匿名函数后面等待了10ms,但是由于管道是阻塞式的,子协程在管道中只能写一个数据,只有主线程取了数据之后,子协程才能继续写,所以打印才会是子协程写一个数据,主线程取一个数据
(3)阻塞式的chan,写数据时,如果已有数据则会阻塞,只有取了数据才能继续写;读数据时,如果没有数据,则会发生阻塞,等待有数据时才能读取。
2.2、非阻塞式chan
func main() {
c := make(chan int, 3)
go func() {
defer fmt.Println("子协程结束")
fmt.Println("子协程开始执行")
for i := 0; i < 5; i++ {
c <- i //往管道中写数据
fmt.Println(i, "子协程写数据, num = ", i)
time.Sleep(time.Microsecond) //给打印预留时间
}
}()
time.Sleep(time.Millisecond * 10)
for i := 0; i < 5; i++ {
fmt.Println(i, "主线程取数据, num = ", <-c)
time.Sleep(time.Microsecond) //给打印预留时间
}
fmt.Println("main协程结束")
}
output:
子协程开始执行
0 子协程写数据, num = 0
1 子协程写数据, num = 1
2 子协程写数据, num = 2
0 主线程取数据, num = 0
3 子协程写数据, num = 3
1 主线程取数据, num = 1
4 子协程写数据, num = 4
子协程结束
2 主线程取数据, num = 2
3 主线程取数据, num = 3
4 主线程取数据, num = 4
main协程结束
说明:
(1)代码中的管道容量是3,因此子协程最多只能写3个数据,然后会发生阻塞,等待主线程读取数据,即前三个打印的是子协程写数据
(2)接着主线程会从管道中读数据,由于主线程和协程是并行执行的,因此主线程读完数据之后,子协程会写下一个数据。即中间4行打印的是主线程取数据,子协程写下一个数据
(3)子协程数据写完之后,defer语句会被触发
(4)接着就是主线程不断取数据的打印
2.3、管道的关闭和轮询读数据
一般来说,在不知道管道容量的情况下,在管道读操作完成后最好关闭管道,一来可以避免资源的浪费,二来管道取数据时可以避免不必要的等待。
如上面程序中,如果子协程往管道中写5个值,而主线程读6个值,会导致主线程一直等待读值,程序无法结束,最后报死锁的错误
func main() {
c := make(chan int, 3)
go func() {
defer fmt.Println("子协程结束")
fmt.Println("子协程开始执行")
for i := 0; i < 5; i++ {
c <- i //往管道中写数据
fmt.Println(i, "子协程写数据, num = ", i)
time.Sleep(time.Microsecond) //给打印预留时间
}
close(c)
}()
time.Sleep(time.Millisecond * 10)
/*
for data := range c { //管道关闭, range才能正常读,否则会报错
fmt.Println("主线程取数据, num = ", data)
time.Sleep(time.Microsecond) //给打印预留时间
}
*/
for { //除了range,也可以使用取值是否ok来判断
//ok为true说明channel没有关闭,为false说明管道已经关闭
if data, ok := <-c; ok {
fmt.Println("主线程取数据, num = ", data)
time.Sleep(time.Microsecond) //给打印预留时间
} else {
break
}
}
fmt.Println("main协程结束")
}
output:
子协程开始执行
0 子协程写数据, num = 0
1 子协程写数据, num = 1
2 子协程写数据, num = 2
主线程取数据, num = 0
3 子协程写数据, num = 3
主线程取数据, num = 1
4 子协程写数据, num = 4
主线程取数据, num = 2
子协程结束
主线程取数据, num = 3
主线程取数据, num = 4
main协程结束
2.4、单向管道
默认情况下,管道是双向的,但其作为参数进行传递,可能只用到发送数据或者接收数据的功能,此时参数可以定义为单向管道。管道可以隐式转为单向管道,但单向管道不能转为双向管道
//chan<- 表示只写
func chanWriteOnly(out chan<- int) {
for i := 0; i < 5; i++ {
out <- i
}
close(out)
}
//<-chan 表示只读
func chanReadOnly(in <-chan int) {
for num := range in {
fmt.Println(num)
}
}
三、协程
1、进程、线程、协程
1.1、概念
- 进程:程序在操作系统中一次动态执行的过程,是系统进行资源分配和调度的基本单位。进程占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、页表、文件句柄等)比较大,但相对比较稳定安全。
- 线程:又叫轻量级进程,是进程的一个执行实例,是程序执行的最小单元。它从属于进程,是程序的实际执行者。线程可以共享进程方法区的内存、堆内存、系统资源,同时也有自己的资源,同一个进程的多个线程可以并发执行。线程上下文切换快,资源开销较少,但稳定性不如进程
- 协程:是一种用户态的轻量级线程,协程的调度完全由用户控制
1.2 区别和联系
区别
- 进程和线程是由系统内核进行管理控制,而协程是由用户来控制
- 线程是轻量级进程,开销较少,上下文切换较快,稳定性不如进程; 协程是轻量级线程,开销更少
- 主线程是一个物理线程,直接作用于CPU,是重量级的,非常耗费CPU资源;协程从主线程中开启的,是逻辑态,耗费资源少
- go语言的协程机制,让用户可以轻松开启上万个协程(轻量级线程);而其他编程语言的并发机制,是基于线程的,过多的线程比较耗费资源
联系
- 一个程序至少有一个进程,一个进程至少有一个线程。一个线程可以有多个协程
- 一个进程从主线程(main函数所在的线程)的执行开始,进而创建一个或多个附加线程(如go语言中用户创建的协程)
- 线程和协程都有独立的栈空间、都可以共享程序的堆空间
2、并发、并行
- 并发和并行,对于用户来说,都是看起来像是多个线程同时在执行,但主要区别在于微观层面的某一个时间点上,CPU执行的线程数目
- 并发:多个线程在单核CPU上运行,CPU和线程是1:N的关系,CPU轮询操作让每个线程执行一定时间(比如10ms),从微观的某一个时间点上来看,只有一个线程在执行
- 并行:多个线程在多核CPU上运行,CPU和线程是M:N的关系,多个线程在不同CPU上执行,从微观的某一个时间点上来看,多个线程在执行(如果CPU核数M >= N,则N个线程同时执行;如果M < N,则M个线程同时执行)
3、goroutine调度模型:MPG模型
3.1、概念
- M结构是Machine,系统线程,它由操作系统管理,是操作系统的主线程(物理线程)。M 从P 上获得G 并执行,同时还负责部分内存的管理。
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine,它维护了一个goroutine队列,含有协程执行需要的上下文
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
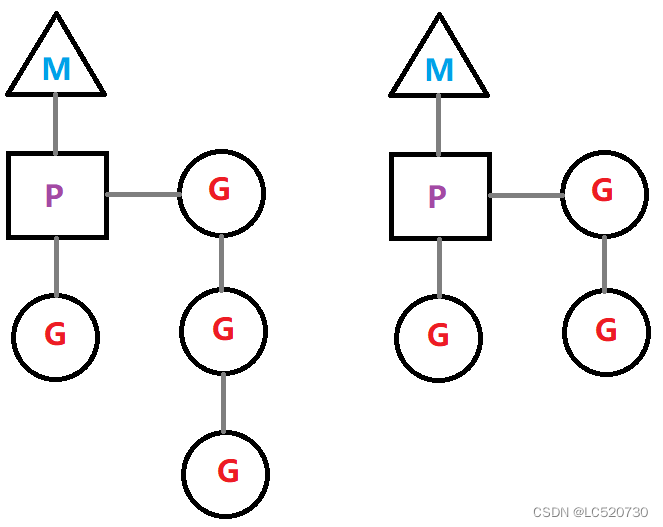
3.2、正常运行状态
- 当前程序有两个M,如果两个M运行在单核CPU上,叫并发;运行在多核CPU上,叫并行
- 两个M正在执行各自的G,左边的协程队列有三个,右边的有两个
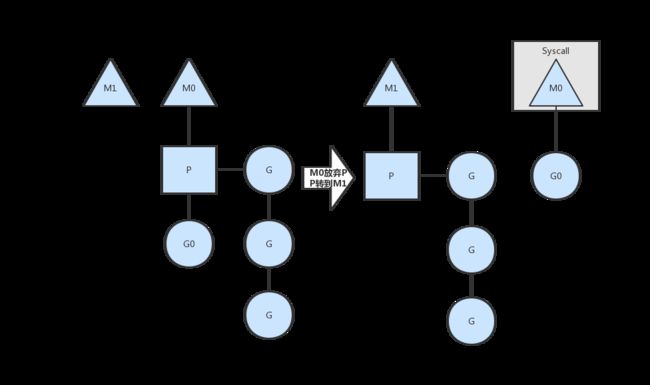
3.3、阻塞状态
- 左边M0主线程正在执行G0协程,还有三个协程在队列中排队
- 此时G0发生阻塞(读文件或者数据库等),这时候系统将创建或者从线程池中取出M1主线程,同时将等待的三个协程队列挂到M1上,M0继续执行G0协程
- 当M0执行完G0协程后,会被放回空闲的线程池中,等到新的协程来临时再次被唤醒
该调度模型可以保证G0的执行,又可以保证队列中的其他协程不会阻塞
4、协程的使用
4.1、协程求阶乘
需求:给定一个数字number,求1~number个数的阶乘,并存储到全局map中
import (
"fmt"
"runtime"
"time"
)
var m map[int]uint64
//计算阶乘
func cal_factorial(n int) {
res := 1
for i := 2; i <= n; i++ {
res *= i
}
m[n] = uint64(res)
}
func main() {
//获取当前系统的逻辑CPU数量
num := runtime.NumCPU()
//设置可同时执行的最大CPU数,并返回先前的设置
pre := runtime.GOMAXPROCS(num)
fmt.Printf("CPU_using: pre CPU num = %d, now CPU num = %d\n", pre, num)
number := 10
m = make(map[int]uint64, number)
for i := 1; i <= num; i++ {
go cal_factorial(i)
}
time.Sleep(time.Millisecond * 10)
fmt.Println(m)
}
output:
CPU_using: pre CPU num = 12, now CPU num = 12
fatal error: concurrent map writes
由上图可知,全局map在协程中存在资源冲突。此时有三种方案:
(1)将map拆成number个,每一个数字求阶乘时就传一个map,这样可以保证不冲突
(2)在map写操作前加锁,但该方法使得协程一个个顺序执行,失去了并行的意义
(3)使用管道,避免资源竞争
//使用锁的方法
import ""
var lock sync.Mutex
//计算阶乘
func cal_factorial(n int) {
res := 1
for i := 2; i <= n; i++ {
res *= i
}
lock.Lock()
m[n] = uint64(res)
lock.Unlock()
}
output
map[1:1 2:2 3:6 4:24 5:120 6:720 7:5040 8:40320 9:362880 10:3628800 11:39916800 12:479001600]
4.2、协程和管道的练习
4.2.1、计算累加
要求:给定1~num个数,分别计算1+2+…+i的结果,并打印出来
分析:可以使用多个管道:numChan用于存放num个数字,便于多协程读取;resChan用于存放协程计算累加后的数值,便于主线程取数据并打印;exitChan用于标记协程是否写完成,因此它的容量和计算累加数据的协程的个数相等
//开启协程:用于存放1~num个数据
func wrData(m int, numChan chan int) {
for i := 1; i <= m; i++ {
numChan <- i
}
close(numChan)
fmt.Println("数据通道numChan已写入num个数所以关闭")
}
//开启计算累加数据的协程,从管道中读数据并计算累加值,然后写入
func wrRes(numChan chan int, resChan chan int, exitChan chan int) {
for {
n, ok := <-numChan
if !ok {
break
}
resChan <- n * (n + 1) / 2
}
exitChan <- 1
fmt.Println("当前协程因为从numChan取不到数据而退出")
}
//给定1~num个数,分别计算1+2+..+i的结果,并打印出来
func goRoutine_Chan(num int, coruntine_num int) {
/*
启动1个协程,将1~num的整数放入到一个channel中,如numChan
启动coruntine_num个协程,从numChan中取出整数n,计算1+2+...+n的值,并存入resChan
最后coruntine_num个协程完成任务之后,遍历resChan,显示结果[res[1]=1, res[2]=3, ...]
*/
numChan := make(chan int, num)
resChan := make(chan int, num)
exitChan := make(chan int, coruntine_num)
go wrData(num, numChan)
//启动coruntine_num个协程,从数据管道numChan中取数据计算累加值并输入
//到结果管道resChan中,若未取到数据表明numChan已无数据,则退出
for i := 0; i < coruntine_num; i++ {
go wrRes(numChan, resChan, exitChan)
}
//匿名函数检测coruntine_num个协程是否都完成
go func() {
for {
/* //也可以这样取数据,未取到数据就会阻塞
for i := 0; i < n; i++{
<- exitChan
}*/
if len(exitChan) == coruntine_num {
close(resChan)
close(exitChan)
break
}
}
}()
//输出resChan中的数据
i := 0
for v := range resChan {
fmt.Printf("res[%d] = %d\n", i+1, v)
i++
}
}
func main() {
goRoutine_Chan(20, 8)
time.Sleep(time.Second * 1)
}
output:
数据通道numChan已写入num个数所以关闭
res[1] = 1
当前协程因为从numChan取不到数据而退出
当前协程因为从numChan取不到数据而退出
当前协程因为从numChan取不到数据而退出
当前协程因为从numChan取不到数据而退出
当前协程因为从numChan取不到数据而退出
当前协程因为从numChan取不到数据而退出
当前协程因为从numChan取不到数据而退出
当前协程因为从numChan取不到数据而退出
res[2] = 3
res[3] = 6
res[4] = 10
res[5] = 15
res[6] = 21
res[7] = 28
res[8] = 36
res[9] = 45
res[10] = 55
res[11] = 66
res[12] = 78
res[13] = 91
res[14] = 105
res[15] = 120
res[16] = 136
res[17] = 153
res[18] = 171
res[19] = 190
res[20] = 210