Go语言学习笔记—golang并发编程之goroutine
视频来源于B站Go语言基础进阶视频av56860636
文章为自己整理的学习笔记,侵权即删,谢谢支持!
文章目录
- 一 goroutine基本介绍
-
- 1.1 看一个需求
- 1.2 进程、线程和协程
- 1.3 并行和并发
- 1.4 Go协程和Go主线程
- 二 goroutine快速入门
-
- 2.1 案例说明
- 2.2 代码实现
- 2.3 流程说明
- 三 Go并发调度MPG模型
-
- 3.1 MPG模式基本介绍
- 3.2 MPG模式运行的状态1
- 3.3 MPG模式运行的状态2
- 3.4 goroutine调度原理
- 四 runtime包
-
- 4.1 常用函数
- 4.2 运用实例
- 五 sync包
-
- 5.1 引入背景
- 5.2 WaitGroup
- 5.3 Mutex(互斥锁)
- 5.4 RWMutex(读写锁)
一 goroutine基本介绍
1.1 看一个需求
需求:要求统计 1-9000000000 的数字中,哪些是素数?
分析思路:
- 传统的方法,就是使用一个循环,循环的判断各个数是不是素数。很慢
- 使用并发或者并行的方式,将统计素数的任务分配给多个 goroutine 去完成,这时就会使用到goroutine。速度提高 4 倍
1.2 进程、线程和协程
-
进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位。可以简单理解为“正在执行的程序”,进程的局限是创建、撤销和切换的开销比较大。
-
线程是进程的一个执行实例,是程序执行的最小单位,它是比进程更小的能独立运行的基本单位
-
一个进程可以创建和销毁多个线程,同一个进程中的多个线程可以并发执行
-
一个程序至少有一个进程,一个进程至少有一个线程
-
进程和线程的关系示意图:

-
协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine,协程的调度完全由用户控制。与传统的系统级线程和进程相比,协程的最大优势在于其"轻量级",可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常最多也不能超过1万的。这也是协程也叫轻量级线程的原因。
-
协程与多线程相比,其优势体现在:协程的执行效率极高。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。Go语言对于并发的实现是靠协程,Goroutine
1.3 并行和并发
-
多线程程序在单核上运行,就是并发
-
多线程程序在多核上运行,就是并行
-
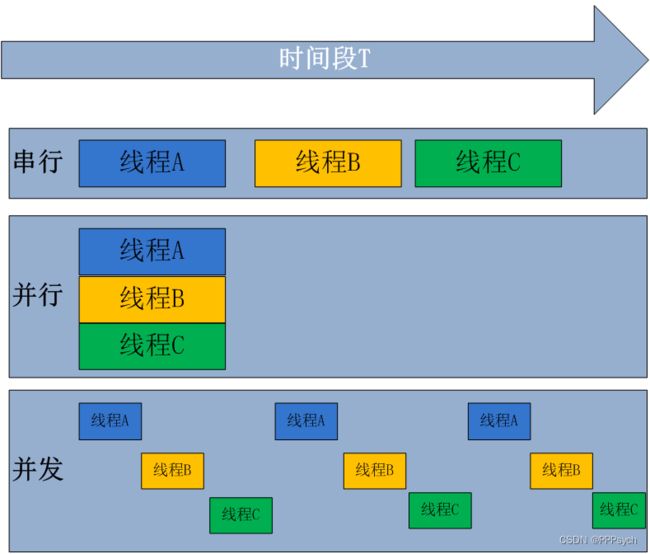
关系示意图:
说明:
- 并发:因为是在一个cpu上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),从人的角度看,好像这10哥线程都在运行,但从微观上看,在某一个时间点看,其实只有一个线程在执行,这就是并发。
- 并行:因为实在多个cpu上(比如有10个cpu),比如有10个线程,每个线程执行10毫秒(各自在不同的cpu上执行),从人的角度看,这10个线程都在运行,并且从微观角度看,在某一时间点看也同时10个线程,这就是并行。
1.4 Go协程和Go主线程
Go语言天然支持高并发是其一个很大的优势。Go 语言内置了 goroutine 机制,使用goroutine可以快速地开发并发程序, 更好的利用多核处理器资源。
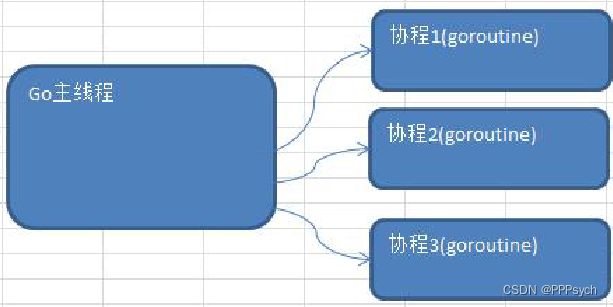
Go 主线程(有程序员直接称为线程/也可以理解成进程): 一个 Go 线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程[编译器做优化]。
Go 协程的特点:
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
Go协程和Go主线程关系示意图:
二 goroutine快速入门
2.1 案例说明
请编写一个程序,完成如下功能:
- 在主线程(可以理解成进程)中,开启一个 goroutine, 该协程每隔 1 秒输出 “hello,world”
- 在主线程中也每隔一秒输出"hello,golang", 输出 10 次后,退出程序
- 要求主线程和 goroutine 同时执行.
2.2 代码实现
package main
import (
"fmt"
"strconv"
"time"
)
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("test协程 hello,world" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() { //主线程
go test() // 开启一个协程
for i := 1; i <= 10; i++ {
fmt.Println("main主线程 hello,golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
main主线程 hello,golang1
test协程 hello,world1
test协程 hello,world2
main主线程 hello,golang2
main主线程 hello,golang3
test协程 hello,world3
test协程 hello,world4
main主线程 hello,golang4
main主线程 hello,golang5
test协程 hello,world5
test协程 hello,world6
main主线程 hello,golang6
main主线程 hello,golang7
test协程 hello,world7
test协程 hello,world8
main主线程 hello,golang8
main主线程 hello,golang9
test协程 hello,world9
test协程 hello,world10
main主线程 hello,golang10
[Done] exited with code=0 in 11.131 seconds
2.3 流程说明
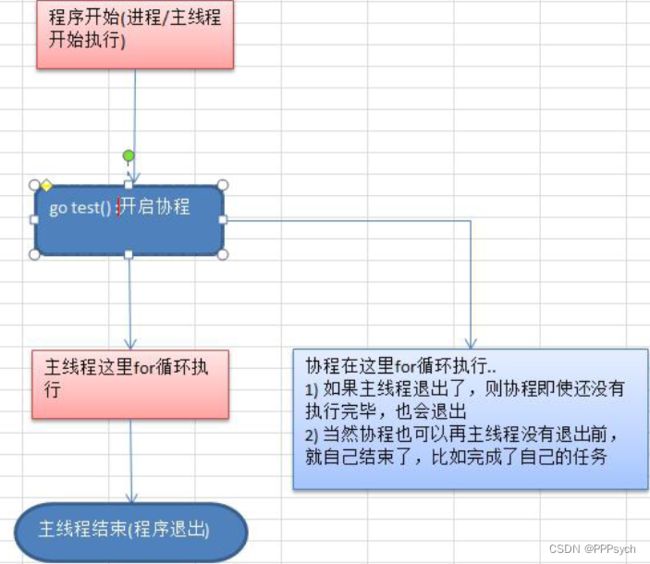
- 主线程是一个物理线程,直接作用在 cpu 上的。是重量级的,非常耗费 cpu 资源。
- 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。
- Golang 的协程机制是重要的特点,可以轻松的开启上万个协程。其它编程语言的并发机制是一般基于线程的,开启过多的线程,资源耗费大,这里就突显Golang 在并发上的优势了
三 Go并发调度MPG模型
在操作系统提供的内核线程之上,Go搭建了一个特有的两级线程模型。goroutine机制实现了M : N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置的调度器,可以让多核CPU中每个CPU执行一个协程。
创建一个协程非常简单,就是在一个任务函数前面添加一个go关键字:
// 用go关键字加上一个函数(这里用了匿名函数)
// 调用就做到了在一个新的“线程”并发执行任务
go func() {
// do something in one new goroutine
}()
3.1 MPG模式基本介绍
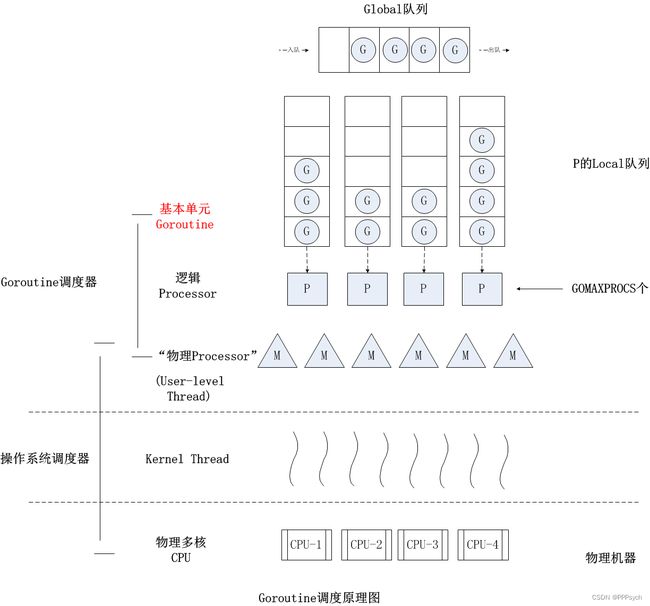
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched, 前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
- M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分。
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
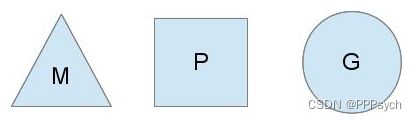
我们分别用三角形,矩形和圆形表示Machine Processor和Goroutine。
在单核处理器的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。 多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。
3.2 MPG模式运行的状态1

- 当前程序有两个M,如果两个M都在同一个cpu运行,就是并发,如果在不同的cpu上运行,则是并行
- M1和M2正在执行一个G,M1的协程队列有3个,M2的协程队列有三个
- 在正常情况下,scheduler会按照上面的流程进行调度,但是线程会发生阻塞等情况
3.3 MPG模式运行的状态2
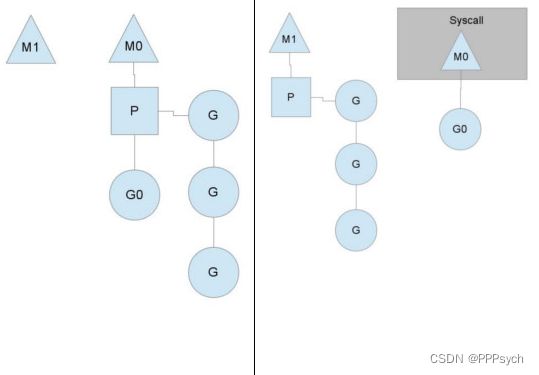
分成两部分来看:原来的情况是M0主线程正在执行G0协程并且此时有另外3个协程在队列等待。如果G0协程阻塞,比如读取文件或者数据库等,这时就会创建M1主线程(也有可能是从已有线程池中取出M1),并且将等待的3个协程挂到M1下开始执行,M0的主线程下的G0仍然执行当前操作。
这样的MPG调度模式,可以既让G0执行,同时也不会让队列的其他协程一直阻塞,仍然可以并发/并行执行。等到G0不阻塞后,M0会被放到空闲的主线程继续执行(从已有线程池中取),同时G0又会被唤醒。
3.4 goroutine调度原理
四 runtime包
runtime包负责管理包括内存分配、垃圾回收、栈处理、goroutine、channel、切片(slice)、map 和反射(reflection)等等。
4.1 常用函数
-
NumCPU:返回当前系统的
CPU核数量 -
GOMAXPROCS:设置最大的可同时使用的
CPU核数通过runtime.GOMAXPROCS函数,应用程序可以在运行期间设置运行时系统中得P最大数量。
需要注意的是此操作会引起“Stop the World”。所以应在应用程序最早的调用。并且最好是在运行Go程序之前设置好操作程序的环境变量GOMAXPROCS,而不是在程序中调用runtime.GOMAXPROCS函数。
无论我们传递给函数的整数值是什么值,运行时系统的P最大值总会在1~256之间。
go1.8后,默认让程序运行在多个核上,可以不用设置了
go1.8前,还是要设置一下,可以更高效的利益cpu
-
Gosched:让当前线程让出
cpu以让其它线程运行,它不会挂起当前线程,因此当前线程未来会继续执行这个函数的作用是让当前
goroutine让出CPU,当一个goroutine发生阻塞,Go会自动地把与该goroutine处于同一系统线程的其他goroutine转移到另一个系统线程上去,以使这些goroutine不阻塞。 -
Goexit:退出当前
goroutine(但是defer语句会照常执行) -
NumGoroutine:返回正在执行和排队的任务总数
runtime.NumGoroutine函数在被调用后,会返回系统中的处于特定状态的Goroutine的数量。这里的特指是指Grunnable\Gruning\Gsyscall\Gwaition。处于这些状态的Groutine即被看做是活跃的或者说正在被调度。
注意:垃圾回收所在Groutine的状态也处于这个范围内的话,也会被纳入该计数器。
-
runtime.GC:会让运行时系统进行一次强制性的垃圾收集
- 强制的垃圾回收:不管怎样,都要进行的垃圾回收。
- 非强制的垃圾回收:只会在一定条件下进行的垃圾回收(即运行时,系统自上次垃圾回收之后新申请的堆内存的单元(也成为单元增量)达到指定的数值)。
-
GOROOT :获取goroot目录
-
GOOS:目标操作系统, 查看目标操作系统 很多时候,我们会根据平台的不同实现不同的操作,就而已用GOOS了:
4.2 运用实例
① 获取goroot和os
package main
import (
"fmt"
"runtime"
)
func main() {
//获取goroot目录:
fmt.Println("GOROOT-->", runtime.GOROOT())
//获取操作系统
fmt.Println("os/platform-->", runtime.GOOS) //
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
GOROOT--> c:\go
os/platform--> windows
[Done] exited with code=0 in 1.384 seconds
② 获取cpu数量以及设置cpu数量
package main
import (
"fmt"
"runtime"
)
func main() {
//1.获取逻辑cpu的数量
fmt.Println("逻辑CPU的核数:", runtime.NumCPU())
//2.设置go程序执行的最大的:[1,256]
n := runtime.GOMAXPROCS(runtime.NumCPU())
fmt.Println(n)
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
逻辑CPU的核数: 12
12
[Done] exited with code=0 in 1.355 seconds
③ runtime.Gosched() 让出CPU时间片,先让别的协议执行,它执行完,再回来执行此协程
package main
import (
"fmt"
"runtime"
)
func show(s string) {
for i := 0; i < 2; i++ {
fmt.Println(s)
}
}
func main() {
go show("java")
// 主协程
for i := 0; i < 2; i++ {
runtime.Gosched()
fmt.Println("golang")
}
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
java
java
golang
golang
[Done] exited with code=0 in 1.224 seconds
当把runtime.Gosched()注释掉时运行结果为:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
golang
golang
[Done] exited with code=0 in 1.796 seconds
此时主协程执行完毕后代码自动结束。
④ runtime.Goexit() 退出当前协程
package main
import (
"fmt"
"runtime"
"time"
)
func show(s string) {
for i := 0; i < 10; i++ {
if i >= 5 {
runtime.Goexit() // 当i=5时自动终止并推出当前所在协程
}
fmt.Printf("i: %v\n", i)
}
}
func main() {
go show("java")
time.Sleep(time.Second)
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
i: 0
i: 1
i: 2
i: 3
i: 4
[Done] exited with code=0 in 2.249 seconds
五 sync包
5.1 引入背景
临界资源是指并发环境中多个进程/线程/协程共享的资源。但是在并发编程中对临界资源的处理不当, 往往会导致数据不一致的问题。
例如:
package main
import (
"fmt"
"time"
)
func main() {
a := 1
go func() {
a = 2
fmt.Println("子goroutine", a)
}()
a = 3
time.Sleep(time.Second)
fmt.Println("main goroutine", a)
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
子goroutine 2
main goroutine 2
[Done] exited with code=0 in 2.173 seconds
能够发现一处被多个goroutine共享的数据。由于资源竞争的原因,当某一个goroutine在访问某个数据资源的时候,按照数值,已经判断好了条件,然后又被其他的goroutine抢占了资源,并修改了数值,等这个goroutine再继续访问这个数据的时候,数值已经不对了。
要想解决临界资源安全的问题,很多编程语言的解决方案都是同步,通过上锁的方式,在某一时间段,只能允许一个goroutine来访问这个共享数据,当前goroutine访问完毕,解锁后,其他的goroutine才能来访问。
因此可以借助于sync包下的锁操作。
sync是synchronization同步这个词的缩写,所以也会叫做同步包。这里提供了基本同步的操作,比如互斥锁等等。这里除了Once和WaitGroup类型之外,大多数类型都是供低级库例程使用的。更高级别的同步最好通过channel通道和communication通信来完成。
5.2 WaitGroup
WaitGroup,即同步等待组。在类型上,它是一个结构体。一个WaitGroup的用途是等待一个goroutine的集合执行完成。主goroutine调用了Add()方法来设置要等待的goroutine的数量。然后,每个goroutine都会执行并且执行完成后调用Done()这个方法。与此同时,可以使用Wait()方法来阻塞,直到所有的goroutine都执行完成。
方法:
-
Add():用来设置到WaitGroup的计数器的值。我们可以理解为每个waitgroup中都有一个计数器 用来表示这个同步等待组中要执行的goroutin的数量。如果计数器的数值变为0,那么就表示等待时被阻塞的goroutine都被释放,如果计数器的数值为负数,那么就会引发恐慌,程序就报错了。
-
Done():当WaitGroup同步等待组中的某个goroutine执行完毕后,设置这个WaitGroup的counter数值减1。Done()的底层代码就是调用了Add()方法
func (wg *WaitGroup) Done() { wg.Add(-1) } -
Wait():表示让当前的goroutine等待,进入阻塞状态。一直到WaitGroup的计数器为零。才能解除阻塞, 这个goroutine才能继续执行。
实例演示:
package main
import (
"fmt"
"sync"
)
/*
WaitGroup:同步等待组
步骤1:使用Add(),设置等待组中要 执行的子goroutine的数量,
步骤2:在main 函数中,使用wait(),让主程序处于等待状态。直到等待组中子程序执行完毕。解除阻塞
步骤3:子gorotuine对应的函数中使用 wg.Done(),用于让等待组中的子程序的数量减1
*/
var wg sync.WaitGroup // 创建同步等待组
func hello(i int) {
defer wg.Done() // 给wg等待中的执行的goroutine数量减1.同Add(-1)
fmt.Printf("i: %v\n", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 设置等待组中要执行goroutine的数量
go hello(i)
}
wg.Wait() // 表示main goroutine进入等待,意味着阻塞。即等待所有要执行的goroutine都结束才执行主协程
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
i: 1
i: 0
i: 9
i: 5
i: 3
i: 4
i: 7
i: 6
i: 8
i: 2
[Done] exited with code=0 in 1.456 seconds
5.3 Mutex(互斥锁)
什么是锁呢?就是某个协程(线程)在访问某个资源时先锁住,防止其它协程的访问,等访问完毕解锁后其他协程再来加锁进行访问。一般用于处理并发中的临界资源问题。Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。
Mutex 是最简单的一种锁类型,互斥锁,同时也比较暴力,当一个 goroutine 获得了 Mutex 后,其他 goroutine 就只能乖乖等到这个 goroutine 释放该 Mutex。
每个资源都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源。其它的协程只能等待。
互斥锁是传统并发编程对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁。
注意:对资源操作完成后,一定要解锁,否则会出现流程执行异常,死锁等问题。通常借助
defer。锁定后,立即使用defer语句保证互斥锁及时解锁。
方法:
- Lock():用于上锁。如果该锁已在使用中,则调用goroutine将阻塞,直到互斥体可用。
- Unlock():用于解锁。如果m未在要解锁的条目上锁定,则为运行时错误。锁定的互斥体不与特定的goroutine关联。允许一个goroutine锁定互斥体,然后安排另一个goroutine解锁互斥体。
实例演示1:
package main
import (
"fmt"
"sync"
"time"
)
var m int = 100
var lock sync.Mutex // 创建锁头
var wt sync.WaitGroup // 创建同步等待组
func add() {
defer wt.Done()
lock.Lock() //上锁
m += 1
time.Sleep(time.Millisecond * 10)
lock.Unlock() //解锁
}
func sub() {
defer wt.Done()
lock.Lock() //上锁
time.Sleep(time.Millisecond * 2)
m -= 1
lock.Unlock() //解锁
}
func main() {
for i := 0; i < 100; i++ {
go add()
wt.Add(1)
go sub()
wt.Add(1)
}
wt.Wait() // 主协程需等待
fmt.Printf("m: %v\n", m)
fmt.Println("程序已结束")
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
m: 100
程序已结束
[Done] exited with code=0 in 4.434 seconds
实例演示2:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
//全局变量,表示票
var ticket = 10 //100张票
var mutex sync.Mutex //创建锁头
var wg sync.WaitGroup //同步等待组对象
func saleTickets(name string) {
rand.Seed(time.Now().UnixNano())
defer wg.Done()
for {
//上锁
mutex.Lock() //g2
if ticket > 0 { //ticket 1 g1
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
fmt.Println(name, "售出:", ticket) // 1
ticket-- // 0
} else {
mutex.Unlock() //条件不满足,也要解锁
fmt.Println(name, "售罄,没有票了。。")
break
}
mutex.Unlock() //解锁
}
}
func main() {
/*
4个goroutine,模拟4个售票口,
在使用互斥锁的时候,对资源操作完,一定要解锁。否则会出现程序异常,死锁等问题。
defer语句
*/
wg.Add(4)
go saleTickets("售票口1")
go saleTickets("售票口2")
go saleTickets("售票口3")
go saleTickets("售票口4")
wg.Wait() //main要等待
fmt.Println("程序结束了。。。")
//time.Sleep(5*time.Second)
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
售票口1 售出: 10
售票口1 售出: 9
售票口4 售出: 8
售票口2 售出: 7
售票口3 售出: 6
售票口1 售出: 5
售票口4 售出: 4
售票口2 售出: 3
售票口3 售出: 2
售票口1 售出: 1
售票口1 售罄,没有票了。。
售票口2 售罄,没有票了。。
售票口4 售罄,没有票了。。
售票口3 售罄,没有票了。。
程序结束了。。。
[Done] exited with code=0 in 6.762 seconds
5.4 RWMutex(读写锁)
RWMutex是读/写互斥锁。锁可以由任意数量的读取器或单个编写器持有。RWMutex的零值是未锁定的mutex。
读写锁即是针对于读写操作的互斥锁。它与普通的互斥锁最大的不同就是,它可以分别针对读操作和写操作进行锁定和解锁操作。读写锁遵循的访问控制规则与互斥锁有所不同。在读写锁管辖的范围内,它允许任意个读操作的同时进行。但是在同一时刻,它只允许有一个写操作在进行。并且在某一个写操作被进行的过程中,读操作的进行也是不被允许的。也就是说读写锁控制下的多个写操作之间都是互斥的,并且写操作与读操作之间也都是互斥的。但是,多个读操作之间却不存在互斥关系。
- 同时只能有一个 goroutine 能够获得写锁定。
- 同时可以有任意多个 gorouinte 获得读锁定。
- 同时只能存在写锁定或读锁定(读和写互斥)。
基本遵循两大原则:
- 可以随便读,多个goroutine同时读。
- 写的时候,啥也不能干。不能读也不能写。
方法:
- RLock(): 读锁,当有写锁时,无法加载读锁,当只有读锁或者没有锁时,可以加载读锁,读锁可以加载多个,所以适用于“读多写少”的场景。
- RUnlock(): 读锁解锁,RUnlock 撤销单次RLock调用,它对于其它同时存在的读取器则没有效果。若rw并没有为读取而锁定,调用RUnlock就会引发一个运行时错误。
- Lock(): 写锁,如果在添加写锁之前已经有其他的读锁和写锁,则Lock就会阻塞直到该锁可用,为确保该锁最终可用,已阻塞的Lock调用会从获得的锁中排除新的读取锁,即写锁权限高于读锁,有写锁时优先进行写锁定。
- Unlock(): 写锁解锁,如果没有进行写锁定,则就会引起一个运行时错误。
实例演示:
package main
import (
"fmt"
"sync"
"time"
)
var rwMutex *sync.RWMutex
var wg *sync.WaitGroup
func writeData(i int) {
defer wg.Done()
fmt.Println(i, "开始写:write start。。")
rwMutex.Lock() //写操作上锁
fmt.Println(i, "正在写:writing。。。。")
time.Sleep(3 * time.Second)
rwMutex.Unlock()
fmt.Println(i, "写结束:write over。。")
}
func readData(i int) {
defer wg.Done()
fmt.Println(i, "开始读:read start。。")
rwMutex.RLock() //读操作上锁
fmt.Println(i, "正在读取数据:reading。。。")
time.Sleep(3 * time.Second)
rwMutex.RUnlock() //读操作解锁
fmt.Println(i, "读结束:read over。。。")
}
func main() {
rwMutex = new(sync.RWMutex)
wg = new(sync.WaitGroup)
wg.Add(3)
go writeData(1)
go readData(2)
go writeData(3)
wg.Wait()
fmt.Println("main..over...")
}
运行结果:
[Running] go run "c:\Users\Mechrevo\Desktop\go_pro\test.go"
3 开始写:write start。。
3 正在写:writing。。。。
1 开始写:write start。。
2 开始读:read start。。
3 写结束:write over。。
2 正在读取数据:reading。。。
1 正在写:writing。。。。
2 读结束:read over。。。
1 写结束:write over。。
main..over...
[Done] exited with code=0 in 10.164 seconds