机器学习第一章之大数据分析与机器学习简介
大数据分析与机器学习简介
-
- 1.1 大数据分析与机器学习概述
-
- 1.1.1 大数据分析与机器学习的应用领域
- 1.1.2 机器学习的基本概念
- 1.1.3 Python在数据科学中的作用
- 1.2 Python环境部署
-
- 1.2.1 Python安装
- 1.2.2 Pycharm安装
- 1.2.3 Jupyter Notebook使用
- 1.3 Python基础知识概要
- 1.4课程相关资源
本章将首先介绍下大数据分析的原理与应用领域、机器学习的基本概念以及Python在数据科学中的作用,然后我们会讲解如何安装Python及使用相关的代码编辑器,最后我们会提及如何快速掌握Python的基础知识。
源代码
https://shimo.im/docs/y6cCpQWqXCWvvyy8/ 《Python源代码及相关福利(机器学习)》
1.1 大数据分析与机器学习概述
说到大数据分析与机器学习(Machine Learning),有的读者可能会感觉比较陌生,然而说到AlphaGo这一击败了世界顶级围棋选手的智能机器人,想必大家都有些耳闻。AlphaGo背后的原理就是大数据分析,通过机器不停的训练与学习,在海量的数据积累后,AlphaGo逐渐掌握了大量的围棋技巧,并凭借高速的计算能力击败了顶级围棋选手。机器学习便是模拟或实现人类的学习行为,以探寻大数据背后的规律,机器学习某种程度上可以说是人工智能的核心。
1.1.1 大数据分析与机器学习的应用领域
除了在围棋领域,大数据分析在很多别的领域也有很大的应用空间。信息时代,我们每天接触的就是海量的数据,通过人力在这海量的数据中寻找规律有很大的局限性,而通过机器学习的手段来进行大数据分析则可以高效、快速地对数据进行分析并提炼规律。
我们通过下面一张表格来简单介绍下大数据分析与机器学习在8大领域的应用,其中大部分案例我们将在之后的章节中进行实例讲解。
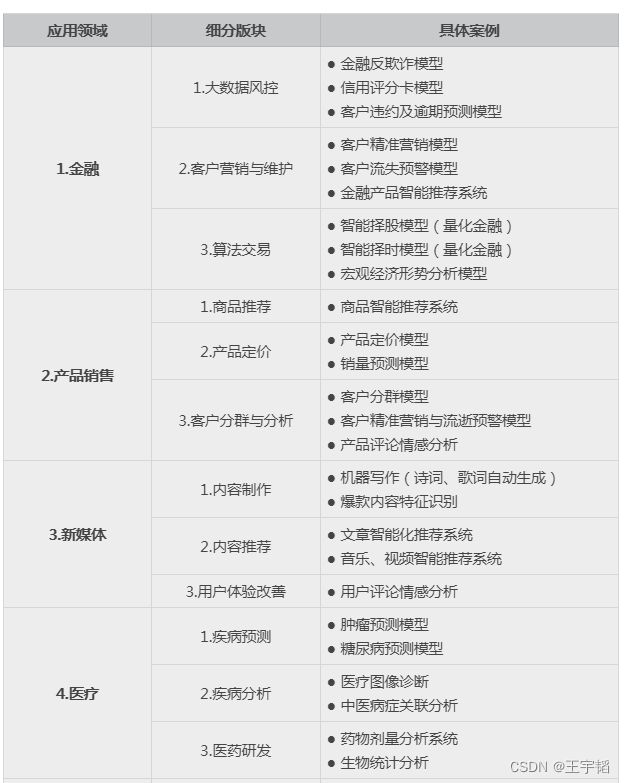
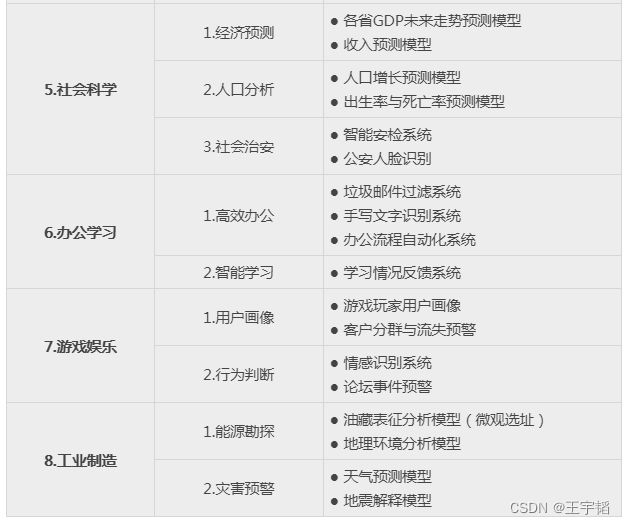
上面的案例只是作为一个展示,在实际应用中,大数据分析与机器学习还有很多应用场景。虽然不同行业的应用场景不同,但是其原理都是想通的,等学习完之后的章节,相信大家会对这些案例有个更加清晰的认知。
1.1.2 机器学习的基本概念
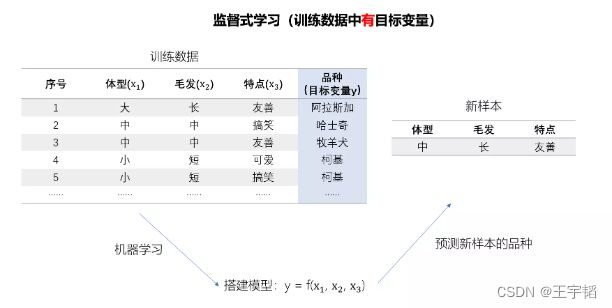
机器学习是大数据分析强有力的工具。机器学习主要分为两大类:监督式学习与非监督式学习,两者的区别就在于训练数据中是否有目标变量,或者称为预测变量。
我们用两张图来解释下两者的区别,其中监督式学习如下图所示,其训练数据中有三个特征变量(体型、毛发、特点)以及一个目标变量(品种),该机器学习的目的就是根据训练数据搭建模型来预测狗的品种。
非监督式学习如下图所示,其和监督式学习的主要区别在于:它的训练数据中只有特征变量,而没有目标变量(品种),所以它在进行机器学习的目的不是去预测品种了,以第十三章的聚类模型为例,它可以根据这些特征将训练数据中的狗进行归类,如A类狗、B类狗、C类狗,那么对于一个新样本便可以根据它的特征来判别它属于哪一个分类。

再细分来说,监督式学习主要分为回归分析(Regression)与分类问题(Classification):

而非监督式学习主要分为数据聚类与分群(Clustering)与数据降维(Dimension Reduction):

从机器学习模型的角度分类,可以将其分成如下的表格中的不同算法模型,这些不同的模型我们都将在之后的章节进行详细的讲解,并且每一章都会通过上一小节提到的具体实战案例巩固模型的学习,让大家知道模型的原理及其实战应用。

1.1.3 Python在数据科学中的作用
用来做数据分析的工具有很多,如经典的Matlab与R语言,以及目前非常火的Python。Python之所以能够在如今成为大数据分析的主要工具,一个主要的原因就是在Python有很多别人已经写好的数据分析以及机器学习的工具包(学术上叫作“库”),如numpy库、pandas库、Scikit-learn库(简称sklearn库)等工具包,这些库里封装了很多别人已经写好的算法模型,我们只需要直接拿过来调用即可。正是这些工具包方便了大家对数据进行分析而不需要去把精力放在数学表达式的编程构建。
了解了Python的强大之后,下面将讲解如何安装Python以及相关代码编辑器的使用方法。
1.2 Python环境部署
这一节主要讲解如何安装Python和编译器Pycharm,并将介绍编译器Jupyter notebook的使用。由于本书的重点在于大数据分析与机器学习,所以这部分内容仅讲解核心要点,更多内容可参考笔者的第一本书《Python金融大数据挖掘与分析全流程详解》,在本书的配套视频和PDF教材中对于这部分基础内容也有非常详细的讲解。
1.2.1 Python安装
这里推荐利用Anaconda 安装Python。Anaconda是Python的一个发行版本,安装好了 Anaconda就相当于安装好了Python,并且还集成了很多关于Python 科学计算的第三方库,通过这些第三方库我们便能很方便的进行数据分析与机器学习的相关研究。
Anaconda 的官网下载地址 https://www.anaconda.com/download/ ,或者直接网页搜索Anaconda,进入官网,选择下载即可,我们这边选择Python3.7版本,它默认是64位的电脑。

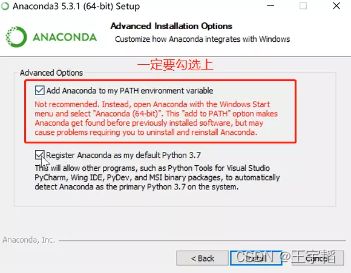
程序下载好了之后,这里建议不要改变默认安装路径(防止可能出现的安装问题),然后点击安装即可,这边有一个很重要的注意点:安装到下图这一步的时候,一定要把第一个勾给勾选上,因为这个对于初学者来说,就相当于自动配置好了环境变量,不然还得麻烦手动配置。
然后一直点Next,中间有一步“Install Microsoft VSCode环节”选择skip(跳过)即可。
其他一直选择Next即可,最后点击Finish,那Python就安装完成啦。
当你安装完Anaconda之后,它已经给你安装完一些不错的编译器了(编译器就是敲入代码的软件),比如Spyder,Jupyter Notebook,下面会介绍一款个人较喜欢的编译器Pycharm。
1.2.2 Pycharm安装
PyCharm 也是一种 Python 的编译器,如下图所示,其界面具有较强的科技风格。
到官网 http://www.jetbrains.com/pycharm/download/#section=windows 下载PyCharm安装包,我们选择免费版(Community)就完全够用了。
下载完后,双击就可以安装了,安装过程中,一直选择Next和Install即可,其中这一页选择下面两项即可。

之后一直点击Next一直到最后的Finish(结束)出现之后点击Finish即可。使用过程中有什么不清楚的可以观看本书的随书教程和视频,基本涵盖了大部分可能出现的情况。
对于按完Finish之后的第一步:这个勾选“Do not import settings”

第二步:选择页面风格,建议选择默认的黑色风格。
第三步:选择辅助工具,可以选择直接跳过。
第四步:点击“Create New Project”创建Python文件。
第五步:文件进行命名,这一步千万记得点开Project Interpreter,勾选Existing interpreter。

然后点击最右边![]() 的图片: 在弹出的页面中选择System Interpreter, 可以看到Interpreter变成了Anaconda3\Python.exe,选择OK。
的图片: 在弹出的页面中选择System Interpreter, 可以看到Interpreter变成了Anaconda3\Python.exe,选择OK。
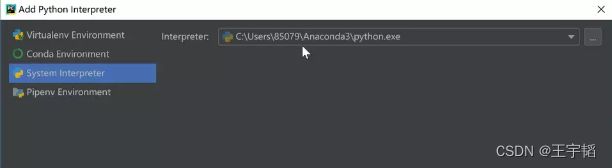
回到项目创建页面后,点击Create即可创建新的Python Project。
第六步:关闭官方小技巧提示,等待最下面的Index缓冲完毕,它缓冲的过程其实是在配置你Python的运行环境。刚运行Pycharm的时候Index缓冲的时间较长,以后就好多了。
第七步:等到Index已经缓冲完毕后,进行下一步操作:创建Python文件,如下图,点击之前创建的项目文件夹,然后右键,点击New,选择Python File。

将新的Python文件命名为 hello world。
第八步:在英文模式下输入print(‘hello world’),其中单引号双引号没有区别。
print('hello world')
这时候得等之前所说的Index缓冲结束后,我们在![]()
上或者代码输入框内右击,选择Run 'hello world’即可,这样就能成功运行程序并在下方输出hello world了。注意,如果之前说的index没有缓冲结束,你可能右击的时候还没有这个Run ‘hello world’,这个是因为你的运行环境还没有配置完毕。

之后你也可以通过点击界面右上角![]()
绿色运行按钮,运行程序,或者按住快捷键Shift + F10也可以运行程序。不过我个人还是推荐右击文件然后选择Run 'Python文件名’的方式来运行程序,这样对初学者来说不太容易出错。
下面再对Pycharm的另外一个字体大小的设置做一个介绍,大家点击File,选择下图的Settings。
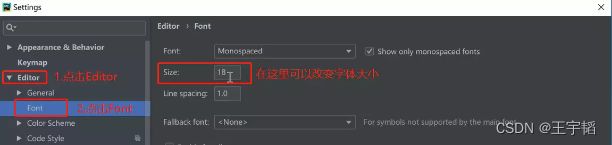
选择Settings中的Editor,选择Font,如下图所示,在右边的Size里可以调节显示字体的大小以及行间距。
Pycharm使用常见问题:
Q1:为什么我第一次打开要等很久,才能进行下一步操作?
A1:第一次打开的时候都有一小会等待缓冲的时间,特别是第一次安装的时候,当等待最下面的缓冲提示Indexing转完了之后,再进行下面的操作就没有问题啦。
![]()
Q2:为什么打开Pycharm的时候会提醒我说我没有Interpreter(运行环境)?
![]()
A2:这是因为重新打开Pycharm的时候,它默认建立了一个新的project(新项目),这个Python文件是属于这个project,而Pycharm默认运行环境为empty(空),所以如果这个project没有运行环境的话,Python文件也没有办法运行,那么这个时候就需要配置下运行环境。
解决方法如下:你可以点击上图上图中的“Configure Python interpreter”修改单个项目文件的运行环境,也可以直接把Pycharm的默认运行环境设置给改了:点击File–点击Default settings(有的Pycharm版本里叫作Other Settings -> Settings for New Projects)。
选择Project Interpreter - 选上你安装好的interpreter(具体操作方法:选择右边齿轮形状的设置按钮,选择Anaconda下的运行环境),再点击右下Apply,然后点击OK退出即可。这样默认的interpreter就关联上了,如下图所示:

1.2.3 Jupyter Notebook使用
Jupyter Notebook是Anaconda自带的一款非常不错的代码编辑软件,其的优点在于:
1、可以非常方便的进行代码分块运行;
2、运行的结果可以自动保存,不需要之后重复运行代码;
3、可以直接在这个在单个模块中打印数据进行查看,非常方便代码调试,所以它在机器学习这种常和数据打交道的过程中是很有帮助的。
4.因为是Anaconda自带的编辑器,所以无需配置环境;
5.相较于Pycharm而言,Jupyter Notebook的打开速度非常快,不过其自动查错及界面美观稍弱于Pycharm。
笔者常用Jupyter Notebook进行机器学习的代码调试与整理,最终在Pycharm中运行完整的项目。下面讲解下Jupyter Notebook的使用技巧:
1.打开和查看Jupyter Notebook
第一次接触Jupyter Notebook的时候,会感觉其打开方式相较于Pycharm直接点击Python文件即可打开会显得稍微麻烦一点,不过其打开速度非常快,熟悉之后便能方便的使用。这里首先来讲解如何来打开以及查看Jupyter Notebook。
(1)打开C盘环境下的文件
Jupyter Notebook打开方法如下:电脑左下角打开Anaconda,点击Jupyter Notebook。
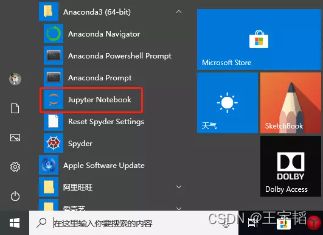
此时会在默认浏览器中打开Jupyter Notebook ,此时浏览器只是个工具载体,因此并不需要联网就能使用,如下图所示是其初始界面,可以看到此时都是C盘中的一些文件夹,我们可以在其中的任一文件夹下创建Python文件(如何创建将在下一步骤讲)。
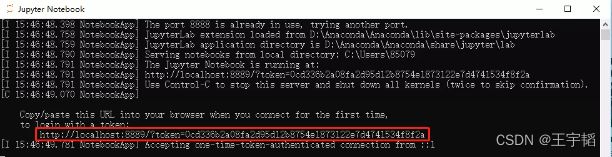
此外,除了弹出浏览器界面外,其实它还会弹出Jupyter Notebook的管理窗口,这个管理窗口正常情况下用户用不着,但是不可以关闭它,一旦关闭,则浏览器中的Jupyter Notebook则会显示连接断开。此外,如果浏览器中没有自动弹出Jupyter Notebook相关界面,也可以复制下图中红框中那行链接至浏览器搜索栏中即可。
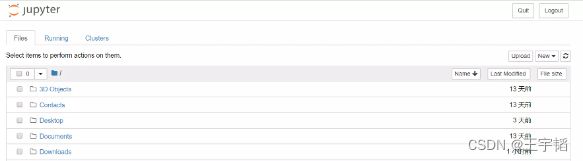
(2)打开任意磁盘中的文件
上面打开的是C盘中的相关文件,如果Jupyter Notebook代码是存储在其他磁盘该如何打开呢?如下图所示,在E盘的“机器学习演示”文件夹中有些Jupyter Notebook格式的代码文件(文件后缀为.ipynb的即为Jupyter Notebook格式的Python文件),该如何打开呢?

一种方法是将代码复制到桌面某个文件夹,然后通过上面:在C盘环境下打开的方法打开。
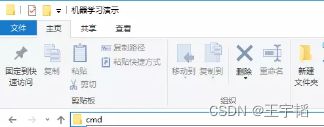
另一种方法则方便的多:如下图所示:在该文件夹的路径框内输入“cmd”,然后按Enter键,如下图所示。
然后在弹出的界面中输入“jupyter notebook”,然后按Enter回车键即可,如下图所示:

或者在文件夹中Shift + 右键,选择在此处打开 Powershell窗口,也能进入上述页面。

然后便能在默认浏览器中看到如下内容,单击相关Python文件即可将其打开并进行查看。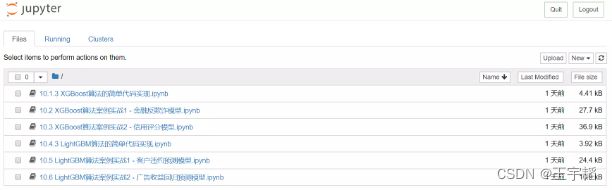
例如,我们打开其中第二个文件,其界面效果如下图所示:

此外,因为Jupyter Notebook是通过浏览器打开的,所以如果觉得界面的字体较小,可以通过Ctrl + 鼠标滚轮键来调节界面大小。
2.创建Python文件
如下图所示,在右上角的New按钮,选择Python3,可以创建Python文件,如果需要创建新文件夹,你们选择其中的Folder即可。
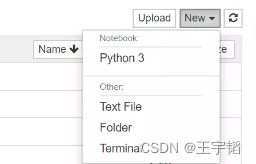
例如选择“Python3”即可创建如下的界面,点击上面的Untitled则可以重新命名文件。

和之前演示的一样,Jupyter Notebook格式的Python文件后缀名为.ipynb,而常规的Python文件后缀则为.py。因此在Jupyter Notebook中我们创建和打开的都是后缀名为.ipynb的文件。
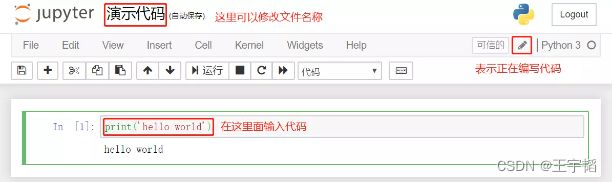
3.编写代码
如下图所示,在区块中即可编写代码,编写完毕后,按住Ctrl + Enter键即可运行当前区块,或者按上方菜单栏中的运行按钮运行代码,在编写代码的时候区块边框显示为绿色。
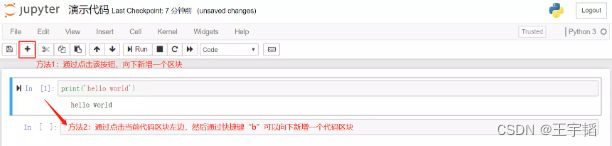
前面讲过,Jupyter Notebook的一个好处是可以分区块运行,那么该如何新增一个代码区块呢?如下图所示,我们可以通过点击左上角的“+”按钮,可以在当前代码区块下新增一个区块,第二种方法则是可以通过点击当前代码区块左边(此时该代码区块左侧边框会变成蓝色),然后通过快捷键“b”可以向下新增一个代码区块(快捷“a”则是在该代码区块上方新增一个区块)。
Jupyter Notebook的另一个好处就是在对于变量,它不需要输入print()函数,也能快速打印内容,方便编程者查看,如下图所示。
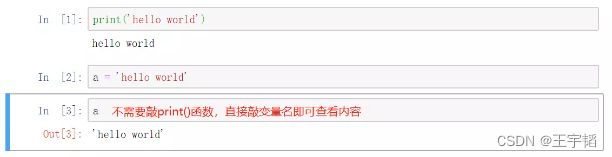
对于一些类型的数据,如下一章将要讲到的DataFrame表格类型数据,直接通过变量名打印比利用print()函数打印呈现的效果更好。
4.菜单栏介绍
这里再介绍下菜单栏,通常情况下,我们不会经常使用菜单栏,不过其中有些功能还是需要关注一下的,我们稍后会重点讲一些Cell和Kernel中的一些特色功能,下图为菜单栏:

其中File按钮可以用来打开和存储文件,File按钮中的Download As可以把Jupyter Notebook创建的后缀名为.ipynb的Python文件另存为后缀名为.py的常规Python文件。
Edit按钮中则是一些编辑区块的内容,如剪切、复制、删除区块等,其中有些功能也可以下图中的快捷方式来实现,当把鼠标悬停在快捷按钮上,可以看到相关解释。
Insert按钮可以插入区块,这个一般用下面要讲的快捷键完成;Cell按钮可以选择运行当前区块、运行当前区块之前或之后等内容;Kernel按钮中可以中断或重启程序;Help按钮中的Keyboard Shortcuts可以查看快捷键。
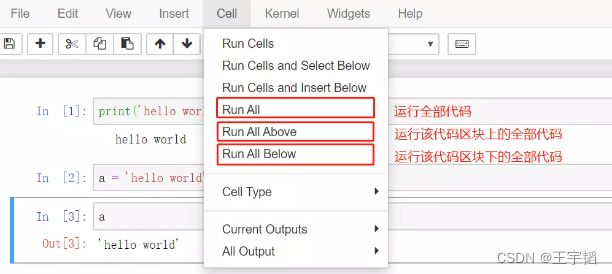
Cell菜单中的一些比较有意义的功能如下图所示:
Kernel菜单中的一些比较有意义的功能如下图所示:

之所以要特地强调下“Kernel”菜单中的“Restart”(重启系统)选项,是因为有的时候Jupyter Notebook运行过程中程序因为某些问题一直卡着不动(如代码陷入死循环),这时候通过终止按钮,或者通过上图中的“Interrupt”(中断系统)选项是终止不了程序的,而通过Restart(重启系统)则能非常快速的终止程序。
5.快捷按钮介绍
除了使用菜单栏外,Jupyter Notebook还有不错的快捷按钮,如下图所示:

依次作用为:保存;在下面插入代码块;剪切代码块、复制代码块、粘贴到下面;将选中代码块上移、将选中代码块上移;运行当前代码块、中断系统(如果中断不了,则推荐选择重启系统)、重启系统(就是上面讲的Kernel中的Restart)、重启并运行所有代码;代码以及标题框;打开命令配置。
这里单独讲解一下“代码及标题框”按钮,它可以设置区块为代码(Code)、标题(Heading)或标志(Markdown)(类似于笔记或者注释,Markdown是一种专门的笔记语言,更多Markdown的使用技巧可以自行搜索),如下图所示,通过它我们可以在代码里设置标题和标志,方便阅读代码。注意设置后要按Ctrl+Enter键运行该区块才可以完成设置。
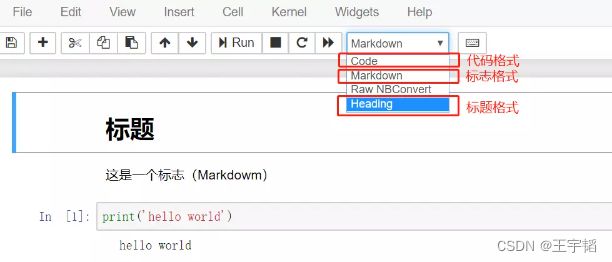
此外,通过快捷键“m”可以将代码格式的内容快速切换为标志格式的内容,通过快捷键“y”则可以切换为代码格式的内容。
6.常用快捷键
在实际操作中更多会使用快捷键来进行操作,Jupyter Notebook常用快捷键如下所示:

注意a、b、连续按两次d键等快捷键方式需要选中区块的情况下才会生效,当区块被选中时,其边框颜色为蓝色,如下图所示:
![]()
此外,Jupyter Notebook是默认不显示代码行号的,如果需要显示代码行号,可以在编程界面上通过快捷键Shift + L来显示行号,显示行号效果如下图所示:

1.3 Python基础知识概要
由于本书的重点在于大数据分析与机器学习,Python的基础知识并不复杂,在笔者的第一本书《Python金融大数据挖掘与分析全流程详解》有详细的讲解,这里不再赘述。对于零基础的读者,本书还提供相关的配套视频和PDF教材讲解这部分内容,初次接触Python的读者建议看完Python基础的内容再进行下一阶段的学习,下表是配套视频中Python基础知识的概要。

添加链接描述
1.4课程相关资源
笔者获取方式:微信号获取
添加如下微信:huaxz001 。
笔者网站:www.huaxiaozhi.com
王宇韬相关课程可通过:
京东链接:[https://search.jd.com/Search?keyword=王宇韬],搜索“王宇韬”,在淘宝、当当也可购买。加入学习交流群,可以添加如下微信:huaxz001(请注明缘由)。

各类课程可在网易云、51CTO搜索王宇韬,进行查看。