基于Python网络爬虫的小说网站数据分析
目录
一、 设计目的 1
二、 设计任务完成 1
三、 网络爬虫程序步骤 2
四、 爬虫详细设计 3
4.1设计环境和目标分析 3
4.2代码流程详细分析 4
4.3完整代码 9
五、 效果截图 14
六、 总结 17
七、 参考文献 17
一、设计目的
1.巩固和加深我们对python知识,以及对爬虫技术进一步加深认识。
2.提高我们编程的能力以及思考能力
二、设计任务完成
1.网络爬虫是从web中发现,下载以及存储其中的内容。并且从首页URL爬取,然后不断从当前网页获取URL加入,来不断深入获取各个URL的内容。
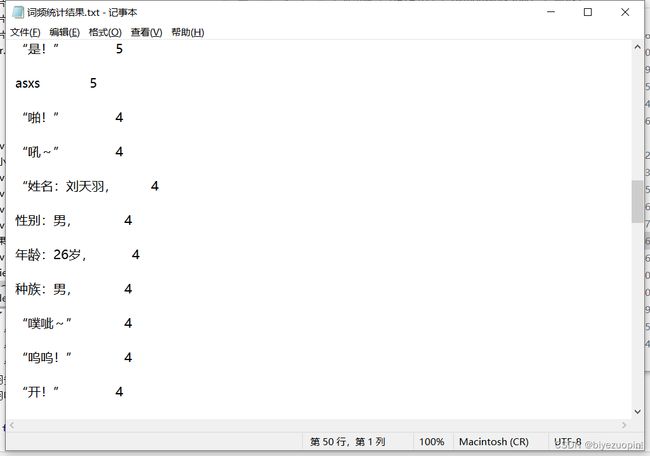
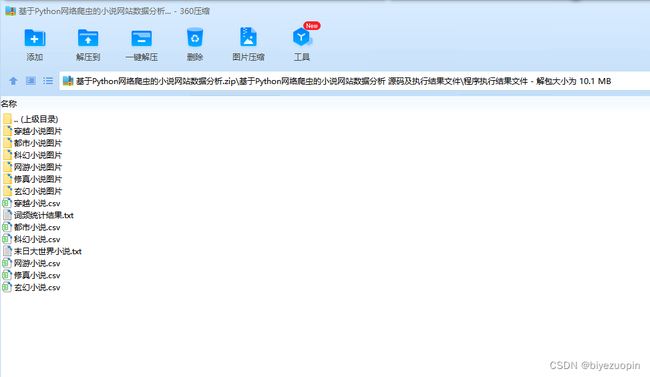
2.抓取小说网站,抓取一系列小说的篇名、作者、出版单位(或首发网站)、出版时间(或网上发布时间)、内容简介、小说封面图画、价格、读者评论或评分等多项信息,并将上述信息组织成表格形式(可以是csv、json、excel等)加以保存。另外,还可以深度抓取某部小说的多个章节或全部章节进行分词和词频统计。
3.抓取的是网站不是网站的首页。抓取的内容一定要分布在整个网站的多个页面和多个链接中。
4.程序中加入了反爬技术(包含模拟人加入了时间间隔访问,以及隐藏爬虫身份)
5.程序使用了正则表达式(通过正则来匹配标签)
from bs4 import BeautifulSoup
import requests
import random
import re
import time
import csv
import os
import threading
network_interval = 0.1 # 联网间隔,自动调整避免503
#爬取url的内容
def open_url(url):
global network_interval
header = [
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)'
] #设置多个use-agent存放在header列表中,用于伪装爬虫身份
header = {'User-Agent': str(header[random.randint(0, 3)])} #每次随机一个use-agent存放到header中
req = requests.get(url=url, headers=header) #向服务器发起请求获取数据,返回值是response类型
if req.status_code != 200: #如果发现响应的状态码不等于200,请求失败
network_interval += 0.1 #设置网络间隔时间自增加0.1,让下次读取章节暂停时间增加
print('(503 正在重试...)', round(network_interval, 2)) #提示重试
return open_url(url) #请求失败递归重新执行open_url()
if network_interval > 0.1: #如果网络间隔时间大于0.1
network_interval *= 0.995 #表示之前失败过,此次重新调整网络时间间隔,减少时间间隔
response = req.content #获取服务器响应的内容,二进制类型
response_decode = response.decode("UTF-8","ignore") #将获取的内容转换为UTF-8编码格式,是该网站的编码格式
return response_decode #返回UTF-8格式的内容
#获取首页各类小说URL
def get_novelTypelUrl(indexUrl):
html = open_url(indexUrl) #调用open_url()函数传入url获取首页内容
soup = BeautifulSoup(html,"html.parser") #解析网页
urlList = []
textList = []
aList = []
for novels in soup.select('.nav'): #select出class=nav的div元素
aList += novels.find_all(re.compile('a')) #正则选出div内的a标签列表拼接到aList列表存取
for novels in aList: #遍历存取a标签的列表
text = novels.text #获取a标签里的内容
textList.append(text) #将找到的a标签内容添加到textList列表中存取
novels = novels['href'] #提取a标签内的链接href
url = indexUrl + novels #首页网址拼接上后面的其他类型小说网址(这部分网址只是一部分,需要拼接上首页url)
urlList.append(url) #将拼接后的网址存取到列表中
textList = textList[2:8] #切割掉与小说无关的文本
urlList = urlList[2:8] #切割掉与小说无关的url
dict = {}
for i in range(len(urlList)): #循环将文本列表内元素和url列表元素用字典一一对应存储
dict[textList[i]] = urlList[i] #key值为第i个文本(小说类型),value为第i个小说类型url
return dict #返回字典,即存储各个类型的url(如玄幻小说:网址)
#获取各类小说里的每一本小说url
def get_novel(indexUrl):
dict = get_novelTypelUrl(indexUrl) #调用get_novelTypeUrl()传入首页url,返回各类型的url的字典
novelTypeList = []
for key,value in dict.items(): #遍历字典内的key和value值,key值即字典
html = open_url(value) #调用open_url()获取类型小说URL的内容,传入value
soup = BeautifulSoup(html,"html.parser") #解析网页
novelList = []
typeDict={}
urlList = []
for s2 in soup.find_all('div',attrs={'class':"l"})[0].select('.s2'): #遍历查找div中class=l的第一个元素,在里面再选类名为s2的元素返回的列表
novelList += s2.find_all('a') #从s2元素中选出a标签返回的列表拼接到novelList列表中
for url in novelList: #遍历novelList列表中的a标签
url = url['href'] #获取a标签内的href属性重新赋值到url
urlList.append(url) #将获取的小说url添加到列表中
typeDict[key] = urlList #key值为小说的类型,value为存取该类型的所有小说url的列表
novelTypeList.append(typeDict) #将该字典添加到小说类型列表中
return novelTypeList #返回该列表
#获取小说信息
def get_novelInfo(indexUrl):
global network_interval #需要操作函数外面的网络时间间隔变量
novelUrlTypeList = get_novel(indexUrl) #存取各类的每一本小说的url
novelTypeList = []
novelTypeDict = {}
for dict in novelUrlTypeList: #遍历存取各类小说的列表,元素是字典(key是类型,value是该类型全部小说的列表)
noveUrlList = []
novelType = ''
novelList = []
for key,value in dict.items(): #遍历一类小说的字典key,value,即例如存取所有玄幻小说的列表
novelType = key
noveUrlList = value
path = 'D:\pythonWorkSpace\work1\\'+str(novelType) +"图片" #写好一个路径
isExists = os.path.exists(path) #判断该路径下有无文件夹novelType(小说类型名,用来存取名字)
if not isExists: #如果不存在,创建该文件夹
os.makedirs(path)
print(novelType+'创建成功!')
else: #存在,提示已经创建文件夹
print(novelType+'已存在!')
for novel in noveUrlList: #遍历存取该类型每一部小说的url
novelDict = {}
html = open_url(novel) #调用open_url()返回url的内容
soup = BeautifulSoup(html,'html.parser') #解析网页内容
title = str(soup.find_all('h1')[0].text) #查找h1标签的第一个元素的text,即是标题
pList = soup.find_all('div',id="info")[0].select('p') #查找div,id为info的第一个元素,select其中的p元素,返回存取p元素的列表
author = str(pList[0].text).replace('作 者:','') #p元素第一个的text即是作者,但是需要切割掉作者名字前的作者多余字符串
updateTime = str(pList[2].text) #plist的第三个元素的text即最新更新时间
newChapter = str(pList[3].text) #plist的第四个元素的text即最新章节
pList = soup.find_all('div',id="intro")[0].select('p') #查找div,id为intro的第一个元素,查找其中的p元素返回列表
novelIntro = str(pList[1].text) #pList的第二个元素的text即是小说的简介
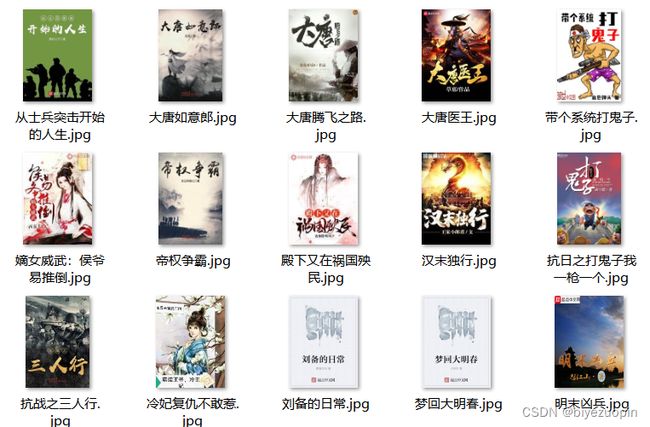
imgList = soup.find_all('div',id='fmimg')[0].select('img') #查找div,id为fmimg的第一个元素,select出img元素返回列表
imgUrl = str(imgList[0]['src']) #图片列表中的第一个img元素即是小说的简介图片,其中的src属性即是url
imgContent = requests.get(imgUrl).content #获取图片链接的二进制内容
writeImg(key,title,imgContent) #调用writeImg函数将图片写入本地文件夹
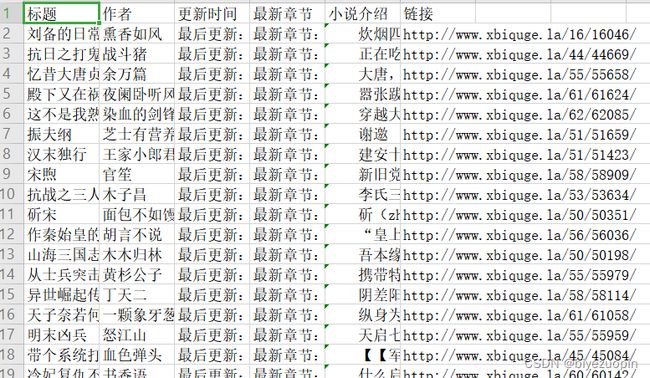
novelDict['标题'] = title #小说的标题存取到novelDict字典的标题内
novelDict['作者'] = author #小说的作者存取到novelDict字典的作者内
novelDict['更新时间'] = updateTime #小说的更新时间存取到novelDict字典的更新时间内
novelDict['最新章节'] = newChapter #小说的最新章节存取到novelDict字典的最新章节内
novelDict['小说介绍'] = novelIntro #小说的介绍存取到novelDict字典的小说介绍内
novelDict['链接'] = novel #小说的链接存取到novelDict字典的小说介绍内
print('链接:',novel)
novelList.append(novelDict) #将小说字典添加到分类小说列表
time.sleep(network_interval) #每爬一本小说的信息暂停网络时间间隔秒,来模拟人访问网站
novelTypeDict[novelType] = novelList #爬完一种类型的全部小说列表,添加到类型字典里面
novelTypeList.append(novelTypeDict) #再把字典添加到列表中
writeNovelData(novelType,novelList) #将爬取的一类型的全部小说保存到本地
#保存小说图片
def writeImg(key,title,imgContent): #imgContent传入的是小说url的content二进制形式
with open('D:\\pythonWorkSpace\\work1\\'+key+'图片\\'+title+'.jpg','wb') as f: #wb方式打开,存取到对应的title.jpg里面
f.write(imgContent) #将图片以二进制的方式写到本地
#保存小说简介到csv
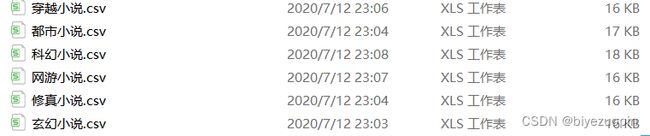
def writeNovelData(key,novelList):
with open(key+'.csv', 'w', encoding='UTF-8', newline='') as f: #以w方式打开csv文件
writer = csv.DictWriter(f,fieldnames=['标题','作者','更新时间','最新章节','小说介绍','链接']) #创建一个csv对象,头为其中的标题,作者等
writer.writeheader() #写入csv头
for each in novelList: #循环小说列表
writer.writerow(each) #将其每一本小说写入csv中
#爬取小说每一章节的URL
def chapter_url(url):
html = open_url(url) #返回url对应的content内容
soup = BeautifulSoup(html,'html.parser') #将本地的html文件转化为beautifulSoup对象,解析html
charpterUrlList = []
charpterurl = soup.find('div',id="list").select('a') #查找网页内的div标签,id为list的第一个元素,从中选出多个a标签返回列表
for i in charpterurl: #遍历a标签列表
i = i['href'] #a标签的href属性重新赋值给i
trueUrl = 'http://www.xbiquge.la'+i #小说的url拼接上章节url(不完整)即可就是有效的章节url地址
charpterUrlList.append(trueUrl) #将正确的章节url地址添加到列表中
return charpterUrlList #返回一本小说的存储所有章节的url