【论文笔记之 Speech Separation Overview】Supervised Speech Separation Based on Deep Learning-An Overview
本文对汪徳亮于 2017 年在 IEEE/ACM Transactions on Audio, Speech, and Language Processing 上发表的论文进行简单地翻译,如有表述不当之处欢迎批评指正。欢迎任何形式的转载,但请务必注明出处。
论文链接:https://web.cse.ohio-state.edu/~wang.77/papers/Wang-Chen.taslp18.pdf。
目录
- 1. 论文目的
- 2. 摘要
- 3. 介绍
- 4. 分类器和学习机
- 5. 训练目标
-
- A. ideal Binary Mask
- B. Target Binary Mask
- C. ideal Ratio Mask
- D. Spectral Magnitude Mask
- E. Phase-Sensitive Mask
- F. Complex Ideal Ratio Mask
- G. Target Magnitude Spectrum
- H. Gammatone Frequency Target Power Spectrum
- I. Signal Approximation
- 6. 特征
- 7. 单通道分离算法
-
- A. speech enhancement
- B. Generalization of Speech Enhancement Algorithms
- C. Speech Dereverberation and Denoise
- D. Speaker Separation
- 8. 阵列分离算法
-
- A. Separation Based on Spatial Feature Extraction
- B. Time-Frequency Masking for Beamforming
- 9. 讨论与总结
-
- A. Features vs. Learning Machines
- B. Time-Frequency Domain vs. Time Domain
- C. What’s the Target?
- D. What Does a Solution to the Cocktail Party Problem Look Like?
- 10. 后记
1. 论文目的
基于深度学习的监督语音分离综述。
2. 摘要
语音分离是指从有背景干扰的语音中分离出目标语音。传统上,该问题被认为是信号处理问题。最新的一些研究将该问题视为监督学习问题。文章对近些年来基于深度学习的监督语音分离问题做了一个全面的概述。文章首先介绍了语音分离的背景和监督分离的形式,然后介绍了监督分离中的 3 个主要部分:学习机(learning machines)、训练目标和声学特征。文章的大部分内容是关于分离算法的,不仅回顾了单麦方法:包括语音增强(语音和非语音分离)、说话人分离(多说话人分离)和语音去混响,而且也回顾了多麦克风的方法。文章也讨论了监督学习中的泛化这一重要概念以及其他一些重要的概念性问题。
3. 介绍
人类的听觉系统能较容易地从混合的声源中分离出目标声源。人们在鸡尾酒会这样混合着背景噪声和其他人声的环境中似乎能轻松地只关注目标说话人的声音。语音分离也经常被称为“鸡尾酒会问题”,该术语由 E.C. Cherry 在其 1953 年的一篇论文中提出。
人类能较轻松地从被噪声、混响等干扰的信号中分离出目标语音,但构造一个系统来完成这样的工作还是一件非常有挑战的事。
语音分离已在信号处理领域进行了数十年的深入研究。根据麦克风的数目,可以将分离方法分为基于单麦和基于麦克风阵列的方法。两种传统的单麦分离方法是语音增强和计算听觉场景分析(CASA)。语音增强方法分析语音和噪声的统计特性,然后根据估计的噪声从含噪语音中估计出干净语音。最简单和最常用的方法是谱减法,为了估计背景噪声,该类方法通常假设背景噪声是平稳的,也就是说背景噪声不随着时间变化或者相比语音更加平稳。CASA 基于听觉场景分析的感知原理。
两麦或多麦阵列使用不同的原理来实现语音分离。波束形成或者空间滤波通过适当的阵列配置增强特定方向的信号,而衰减其它方向的信号。最简单的波束形成器是 delay-and-sum,它将来自目标方向的多个麦克风信号同相相加,利用相位差衰减来自其他方向的信号。噪声的抑制量依赖于麦克风阵列的间距、大小和配置。通常来说,阵列麦克风数目越多,阵列长度越大,噪声抑制量也越大。很明显,当目标源和干扰源在同一位置或靠得很近时,就不能使用波束形成。而且,在混响条件下,波束形成的作用会大打折扣,因为混响会掩盖声源的真实方位。
最近的一种方法将语音分离视为有监督学习问题。监督分离的原始公式是受 CASA 中的时频掩蔽概念启发。时频掩蔽将二维掩码应用于混合信号的时频点上以分离目标信号。CASA 的一个主要目标是理想二值掩码(IBM),它表示目标信号是否在混合信号的时频表示中占主导地位。听力研究表明,在嘈杂的环境下,理想二值掩码可以极大地提高正常听力和听力受损听众的语音可懂度。当IBM 作为计算目标时,语音分离问题变为二分类问题,这是监督学习的基本形式。在这种情况下,IBM 可以用作训练期间的期望信号或目标函数。在测试期间,学习机旨在估计 IBM。尽管作为监督语音分离中的第一个训练目标,IBM 绝不是唯一的训练目标。
自从语音分离问题被定义为分类问题以来,数据驱动的方法在语音处理领域得到了广泛的研究。过去数十年,监督语音分离通过大量的训练数据和增加的计算资源极大地提高了算法性能。监督语音分离算法可以大致分为以下几个部分:学习机(learning machines)、训练目标和声学特征。文章首先介绍了这 3 个部分,然后介绍了一些有代表性的算法。其中单麦和多麦算法将在单独的部分介绍。文章也介绍了监督语音分离所特有的泛化问题。
文章中的语音分离是指从背景干扰中分离出目标语音,这些干扰包括非语音噪声、干扰语音以及房间混响。此外,文章将语音分离和鸡尾酒会问题等同起来看待。文章中的语音增强是指语音和非语音噪声的分离,说话人分离是指分离多个人声。
文章先介绍了监督语音分离的 3 个主要部分,接着分别介绍了单麦和多麦语音分离算法,最后对文章进行了总结,并讨论了其他一些问题,例如:应将哪些信号视为目标以及如何看待一个鸡尾酒会问题的解决方案。
4. 分类器和学习机
过去数十年,DNNs 大大提高了监督学习任务的性能,如:图像分类、手写识别、自动语音识别、语言建模和机器翻译等。DNNs 也大大提高了监督语音分离的性能。该部分介绍了用于监督语音分离的 DNNs 的类型:前向多层感知机(MLPs)、卷积神经网络(CNNs)循环神经网络(RNNs)和生成对抗网络(GANs)。
MLP 是神经网络中最受欢迎的模型,使用经典的反向传播算法对其进行训练。反向传播算法通过梯度下降法调整网络权重以最小化预测误差。预测误差通过预测的输出和期望的输出之间的代价函数计算得到。其中期望的输出作为监督学习的一部分,由用户提供。例如,当 MLP 用来分类时,一个著名的代价函数是交叉熵:
− 1 N ∑ i = 1 N ∑ c = 1 C I i , c l o g ( p i , c ) -\frac{1}{N}\sum_{i=1}^{N}\sum_{c=1}^{C}I_{i,c}log(p_{i,c}) −N1i=1∑Nc=1∑CIi,clog(pi,c)
其中 i i i 是输出神经元的索引, p i , c p_{i,c} pi,c 表示预测的 i i i 属于类别 c c c 的概率。 N N N 和 C C C 分别表示输出神经元的数量和类别的数量。 I i , c I_{i,c} Ii,c 是一个二值分类器,当其值为 1 的时候,表示输出神经元 i i i 的期望类别为 c c c,否则其值为 0。对于函数逼近或者回归问题,常见的代价函数是均方误差(MSE):
1 N ∑ i = 1 N ( y i − y i ^ ) 2 \frac{1}{N}\sum_{i=1}^{N}(y_i-\hat{y_i})^2 N1i=1∑N(yi−yi^)2
其中, y i y_i yi 和 y i ^ \hat{y_i} yi^ 分别是第 i i i 个输出神经元的预测输出和期望输出。
尽管 MLP 的层数越多,其能力就越强,理论上,两个隐层的 MLP 可以逼近任意函数。反向传播算法适用于任何深度的 MLP。但是,由于存在所谓的梯度消失问题,很难训练一个具有随机初始值的多隐藏层的深度神经网络(DNN),梯度消失是指在较低层(接近输入端的网络层)上,从较高层反向传播回来的误差信号计算得到的梯度逐渐变小或消失。梯度消除导致的结果是,较低层的权重在训练阶段几乎不变,学到的有效信息很少。这也解释了为什么在 DNN 出现之前,单个隐藏层的 MLPs 是用的最多的神经网络。
Hinton 等人在 DNN 的训练上取得了重大突破。关键思想是对未标记的数据进行逐层的无监督预训练以期用标记数据进行监督训练之前正确地初始化 DNN。具体来说,Hinton 等人提出使用受限玻尔兹曼机(RBMs)逐层地预训练 DNN,并且发现 RBM 预训练可以改善随后的监督学习。还有一种方法是使用整流线性单元 ReLU 替代传统的 sigmoid 激活函数。最近的实践表明,激活函数为 ReLU 的中等深度的 MLP 可以通过大量的训练数据进行训练,而无需进行无监督预训练。最近,跳过连接(skip connections)被用来帮助训练非常深的 MLPs。
卷积神经网络(CNNs)作为前馈神经网络的一种,已经被证明非常适合模式识别,尤其在视觉领域。CNNs 在模式识别中结合了有据可查的不变性,例如翻译(移位)不变性。一个典型的 CNNs 结构是卷积层和子采样层对的级联。一个卷积层包含多个特征图,每个特征图通过权重共享抽取局部特征,而不管其在上一层中的位置如何。在这种情况下,神经元的感受野表示连接到神经元的上一层的局部区域,其加权和操作类似于卷积(相关)。每个卷积层后面是一个子采样层,它们求取卷积层中神经元的感受野的平均值或最大值。子采样可以降低分辨率以及对局部变化的敏感性。CNN 中使用的权重共享也可以减少训练参数量。由于 CNN 通过其网络结构将领域知识整合到模式识别中,因此尽管 CNN 是深度网络,也可以通过反向传播算法对其进行更好地训练。
RNNs 允许循环(反馈)连接,通常是在隐藏单元之间。不像前馈网络独立地处理每个输入,RNNs 将输入视为一个序列,并对其随时间的变化进行建模。语音信号在时间上是有关联性的,当前帧的信号会受到之前帧的影响。因此 RNNs 是建模语音信号的一个很自然的选择。RNNs 通过循环连接引入了时间维度,这是很灵活而且能无限扩展的,无论多深的前馈神经网络都无法实现这个特性。某种程度上,RNNs 可以视为无限深度的 DNNs。通常使用 BTT(backpropagation through time)算法对循环连接进行训练。然而,这样的 RNN 训练容易出现梯度消失或梯度爆炸的问题,为了缓解这个问题,提出了带有存储单元的 long short-term memory(LSTM)网络。具体来说,一个存储单元包括 3 个门:输入门、遗忘门和输出门。遗忘门控制保留多少历史信息,输入门控制应向存储单元中添加多少当前信息。通过这些门,LSTM 允许在存储单元中保留上下文信息以改善 RNN 的训练。
生成对抗网络 GANs 包括两个同时训练的模型:生成模型 G 和判别模型 D。生成模型 G 学习建模目标数据,例如,从含噪语音到其对应的干净语音的映射。判别模型 D 通常是一个二值分类器,学习区分生成的样本和真实样本。该框架类似于两人对抗游戏,其中最小最大是一种行之有效的策略。在训练期间,G 旨在学习正确的映射,这样的话生成的数据能够很好的模仿真实数据,从而欺骗过 D。另一方面,D 学习更好地分辨真实的数据和 G 生成的数据。这样的对抗学习驱使两个模型提升他们各自的准确性,直到生成的样本与真实样本无法区别为止。 GANs 的关键思想是使用判别器来生成生成器的损失函数。GANs 最近已经被用于语音增强。
文章中,DNN 是指拥有至少两个隐藏层的任意神经网络,以与只有一个隐藏层的 MLPs、带有核的 SVMs、GMMs 进行区分。我们使用 DNN 表示具有深层结构的神经网络,不管它是前馈的还是循环的。
5. 训练目标
在监督语音分离中,定义一个适当的训练目标对学习和推广至关重要。有两类主要的训练目标:基于 masking 的目标和基于 mapping 的目标。基于 masking 的目标描述了干净语音与其背景干扰的时频关系,而基于 mapping 的目标对应于干净语音的频谱表示。本小节研究了该领域中提出的一些训练目标。
语音分离效果的评价指标主要分为两类:信号方面和感知方面。信号方面的评价指标旨在评价信号的增强程度或者干扰的抑制程度。除了传统的 SNR 之外,也可以单独评估分离信号的语音失真和噪声残留。像 SDR(source-to-distortion ratio)、SIR(source-to-interference ratio)和 SAR(source-to-artifact ratio)都是比较重要的评价指标。
由于可懂度和质量是语音感知的两个重要但不同的方面,因此已有客观指标被提出来用以分别评估这两个方面。比如 STOI(short-time objective intelligibility)和 PESQ(perceptual evaluation of speech quality)。

A. ideal Binary Mask
监督语音分离中使用的第一个训练目标是理想二值掩码(IBM),它是受听觉掩蔽效应和听觉场景分析中的排他性分配原理启发所提出来的。IBM 定义在含噪信号的二维时频(耳蜗谱/语谱)表示上:
I B M = { 1 , if SNR(t,f) > LC 0 , otherwise (1) IBM= \begin{cases}1,& \text{if SNR(t,f) > LC}\\ 0,& \text{otherwise}\tag{1} \end{cases} IBM={1,0,if SNR(t,f) > LCotherwise(1)
其中, t t t 和 f f f 分别代表时域和频域。当时频单元中的 SNR 超过 local criterion(LC)或者某个阈值时,该时频单元的 IBM 值为 1,否则为 0。图2(a) 展示了定义在 64 个通道耳蜗谱上的 IBM。IBM 将每个时频单元标记为目标语音为主或者干扰为主,自然地,可以认为 IBM 估计是监督分类问题,正如前述,IBM 估计常用的代价函数是交叉熵。
B. Target Binary Mask
目标二值掩码(TBM)通过将每个时频单元中的目标语音能量与固定干扰(speech-shaped noise)进行比较来得出标签。该干扰是一种与所有语音信号的平均值相对应的平稳信号。图2(b) 展示了 TBM。
C. ideal Ratio Mask
不同于每个时频单元中的硬标签,理想比例掩码(IRM)可以认为是 IBM 的一种 “软版本”:
I R M = ( S ( t , f ) 2 S ( t , f ) 2 + N ( t , f ) 2 ) β (2) IRM=(\frac{S(t,f)^2}{S(t,f)^2+N(t,f)^2})^{\beta}\tag{2} IRM=(S(t,f)2+N(t,f)2S(t,f)2)β(2)
其中, S ( t , f ) 2 S(t,f)^2 S(t,f)2 和 N ( t , f ) 2 N(t,f)^2 N(t,f)2 分别表示一个时频单元中的语音能量和噪声能量。可调参数 β \beta β 可以缩放掩码,通常取值为 0.5 0.5 0.5。若 S ( t , f ) S(t,f) S(t,f) 和 N ( t , f ) N(t,f) N(t,f) 不相关,那么 I R M IRM IRM 的平方根保留了每个时频单元中的语音能量。该假设适用于加性噪声,但不适用于房间混响情况下的卷积干扰(晚期混响可以合理地认为是不相关干扰)。如果不对 ( 2 ) (2) (2)式开平方,IRM 类似于经典的维纳滤波器,它是功率谱上目标语音的最优估计器。IRM 估计常用的代价函数是 MSE,图2(c) 展示了 IRM。
D. Spectral Magnitude Mask
谱幅度掩码(SMM)定义在干净语音和含噪语音的 STFT(short-time Fourier transform)变换上:
S M M ( t , f ) = ∣ S ( t , f ) ∣ ∣ Y ( t , f ) ∣ (3) SMM(t,f)=\frac{|S(t,f)|}{|Y(t,f)|}\tag{3} SMM(t,f)=∣Y(t,f)∣∣S(t,f)∣(3)
其中, ∣ S ( t , f ) ∣ |S(t,f)| ∣S(t,f)∣ 和 ∣ Y ( t , f ) ∣ |Y(t,f)| ∣Y(t,f)∣ 分别表示干净语音和含噪语音的谱幅度。不像 I R M IRM IRM, S M M SMM SMM 上限没有被限制为 1 1 1。为了得到分离的语音,将 S M M SMM SMM 或其估计应用到含噪语音的谱幅度上,然后使用含噪语音的相位(或干净语音相位的估计)合成分离的语音。图2(e) 展示了 SMM。
E. Phase-Sensitive Mask
相位敏感的掩码(PSM)通过增加相位信息扩展了 SMM:
P S M ( t , f ) = ∣ S ( t , f ) ∣ ∣ Y ( t , f ) ∣ c o s θ (4) PSM(t,f)=\frac{|S(t,f)|}{|Y(t,f)|}cos\theta\tag{4} PSM(t,f)=∣Y(t,f)∣∣S(t,f)∣cosθ(4)
其中 θ \theta θ 表示时频单元内干净语音和含噪语音的相位差。PSM 包含了相位差能获得较高的 SNR,相比 SMM 能估计出更好的干净语音。图2(f) 展示了 PSM。
F. Complex Ideal Ratio Mask
复数理想比例掩码(cIRM)是复数域的一种理想掩码。不像前面提到的掩码,它能从含噪语音中完美地重构出干净语音:
S = c I R M ∗ Y (5) S=cIRM*Y\tag{5} S=cIRM∗Y(5)
其中, S S S 和 Y Y Y 分别表示干净语音和含噪语音的 STFT, ∗ * ∗ 表示复数乘法。
c I R M = Y r S r + Y i S i Y r 2 + Y i 2 + i Y r S i − Y i S r Y r 2 + Y i 2 (6) cIRM=\frac{Y_rS_r+Y_iS_i}{Y_r^{2}+Y_i^{2}}+i\frac{Y_rS_i-Y_iS_r}{Y_r^{2}+Y_i^{2}}\tag{6} cIRM=Yr2+Yi2YrSr+YiSi+iYr2+Yi2YrSi−YiSr(6)
其中, Y r Y_r Yr 和 Y i Y_i Yi 分别表示含噪语音的实部和虚部。 S r S_r Sr 和 S i S_i Si 分别表示干净语音的实部和虚部。由于使用了复数计算,因此掩码的值不受限制。因此使用 tanh 或 sigmoid 函数对 c I R M cIRM cIRM 进行限制。
c I R M cIRM cIRM 提供了一种相位估计,但 P S M PSM PSM 并没有。
G. Target Magnitude Spectrum
干净语音的目标幅度谱 TMS 或者 ∣ S ( t , f ) ∣ |S(t,f)| ∣S(t,f)∣ 是一种基于映射的训练目标。在这种情况下,监督学习从含噪语音中估计干净语音的幅度谱。幅度谱也可以被其他形式的谱比如功率谱或者梅尔谱所代替。通常对谱取 l o g log log,以达到压缩动态范围、优化模型训练的效果。TMS 的一种主要形式是均值归一化为 0,方差归一化为 1 的对数功率谱。将估计的干净语音幅度和含噪语音相位合到一起生成分离出的语音信号。TMS 的估计中通常使用的代价函数是 MSE。也可以使用最大似然来训练 TMS 估计器,这种方式明显地模拟输出相关性。图2(g) 展示了 TMS。
H. Gammatone Frequency Target Power Spectrum
伽马通频率目标功率谱(GF-TPS)是另一个与基于谱映射密切相关的训练目标。不同于 TMS 定义在频谱图上,GF-TPS 定义在基于伽马通滤波器组的耳蜗图上。这个目标反应出耳蜗对干净语音的响应能力,GF-TPS 的估计值很容易通过对耳蜗图求逆得到分离的语音。图2(d) 展示了 GF-TPS。
I. Signal Approximation
信号估计(SA)主要是训练比例掩码器,它能最小化干净语音及估计的干净语音谱幅度之间的差异。
S A ( t , f ) = [ R M ( t , f ) ∣ Y ( t , f ) ∣ − ∣ S ( t , f ) ∣ ] 2 (7) SA(t,f)=[RM(t,f)|Y(t,f)|-|S(t,f)|]^2\tag{7} SA(t,f)=[RM(t,f)∣Y(t,f)∣−∣S(t,f)∣]2(7)
其中 R M ( t , f ) RM(t,f) RM(t,f) 是指 SMM 的估计。因此,SA 可以认为是一种联合了比例掩码和谱映射的目标,以寻求最大化的 SNR。如果将 SA 作为目标,两阶段训练能获得更好地分离性能。第一阶段以 SMM 为目标训练学习机,第二阶段通过最小化损失函数 ( 7 ) (7) (7) 对学习机进行微调。
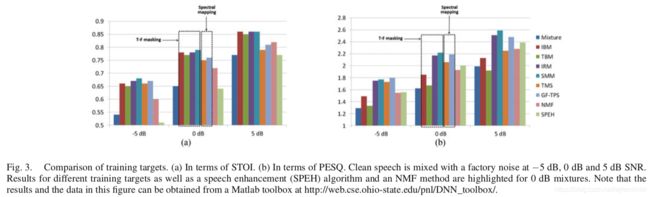
有研究使用固定的前馈 DNN 网络比较了不同训练目标的性能,该前馈 DNN 网络具有同样的输入特征并且包含 3 个隐藏层。分别使用 STOI 和 PESQ 来评价不同训练目标分离出的语音的可懂度和质量。另外,使用有代表性的语音增强算法和有监督的非负矩阵(NMF)分离算法作为基准进行评估。图3 给出了评价结果。从这项研究中可以得到许多结论。首先,就客观可懂度而言,基于掩码的目标整体要优于基于映射的目标。最近一项的研究表明,当输入信号的 SNRs 较高时,基于掩码的目标更优。而当输入信号的 SNRs 较低时,基于映射的目标更优。就语音质量而言,比例掩码优于二值掩码。需要特别说明的是 SMM 和 TMS 之间的区别,除了 SMM 的分母中有一项 ∣ Y ( t , f ) ∣ |Y(t,f)| ∣Y(t,f)∣ 外,两者其余方面是一样的。SMM 估计地更好应该是由于 TMS 对干扰信号和 SNR 不敏感,而 SMM 却比较敏感。TMS 中多对一的映射使其估计要比 SMM 更难。另外,无界谱幅度的估计往往会放大估计误差。总体而言,IRM 和 SMM 是首选目标。另外,基于 DNN 的比例掩码的性能要比有监督的 NMF 和无监督的语音增强算法的性能好得多。
上面并没有列出全部的训练目标,也有文献使用了其他训练目标,也许,最直接的目标是干净语音的时域波形信号。早期的一项研究确实使用了该目标,它训练 MLP 以从含噪语音的波形中映射出干净语音的波形,这可以称为时间映射。尽管很简单,但即使使用 DNN 来替代浅层网络,这种映射也无法正常工作。有文献使用定义在时域的训练目标,但是用来估计目标的 DNN 包括比例掩码模块和含噪相位的逆傅立叶变换模块。该训练目标和 PSM 密切相关。最近的一项研究评估了许多理想掩码的结果,并引入了所谓的理想增益掩码(IGM),它是根据传统语音增强算法中常用的先验 SNR 和后验 SNR 来定义的。有文献评估了所谓的最优比例掩码,发现它是一种基于 DNN 语音分离的有效目标,它考虑了目标语音和背景噪声之间的相关性。
6. 特征
监督学习中,特征作为输入,学习机与其互补。当特征具有区分性时,它们对学习机的需求就不那么强烈以便成功完成任务。另一方面,功能强大的学习机对特征的需求不那么强烈。在一个极端情况下,当特征使一个任务线性可分时,就需要像 Rosenblatt 感知器那样的线性分类器。在另一个极端的情况下,如果分类器能够学习适当的特征,则输入原始数据就够了,无需提取特征。对处于两个极端之间的大多数任务来说,特征提取和学习机都很重要。
在监督语音分离的早期研究中,双耳分离仅使用了双耳时间差 ITD 和双耳能量差 IID 这两个特征。单耳分离使用基于基频的特征以及幅度调制谱 AMS 这两个特征。随后的研究探索了更多的单通道特征,包括梅尔倒谱系数(MFCC)、伽马通倒谱系数(GFCC)、感知线性预测(PLP)以及相对谱变换感知线性预测(RASTA-PLP)。
文章进行了一项研究,该研究旨在探索低 SNR 时,用于监督语音分离的不同声学特征的性能。这些特征已被用于自动语音识别和基于分类的语音分离任务中。它们包括梅尔域、线性预测、伽马通域、过零率、自相关、中值时间滤波、调制和基于基频的特征。梅尔域的特征是 MFCC 和增量谱倒谱系数 DSCC,DSCC 相比 MFCC 在梅尔谱上应用了增量操作。线性预测特征是 PLP 和 RASTA-PLP。伽马通域的特征包括伽马通特征(GF)、GFCC 和伽马通频率调制系数 GFMC。通过将输入信号通过伽马通滤波器组并对子带信号进行抽取来得到 GF。峰值幅度过零率(ZCPA)根据使用伽马通滤波器组得到的子带信号计算出过零间隔以及对应的峰值幅度。自相关特征包括相对自相关序列 MFCC(RAS-MFCC)、自相关序列 MFCC(AC-MFCC)和相位自相关 MFCC(PAC-MFCC)。所有这些特征都是在自相关域计算 MFCC。中值时间滤波器是功率归一化的倒谱系数 PNCC 以及抑制缓慢变化的成分和功率包络的下降沿 SSF。调制域的特征是 Gabor 滤波器组和 AMS 特征。基于基频的特征根据基频追踪来计算时频特征,并使用周期性和瞬时频率区分以语音为主的时频单元和以噪声为主的时频单元。除了现有的特征,文章提出了一种新的称为多分辨率耳蜗谱的特征 MRCG,它在不同的时频分辨率下计算四个耳蜗谱,以提供局部信息和更多的上下文信息。
使用自回归滑动平均滤波器对这些特征进行后处理,并使用基于 MLP 的 IBM 掩码估计器对其进行评价。根据分类准确度和 HIT-FA 率对估计的掩码进行评估。表1 展示了 HIT-FA 结果。
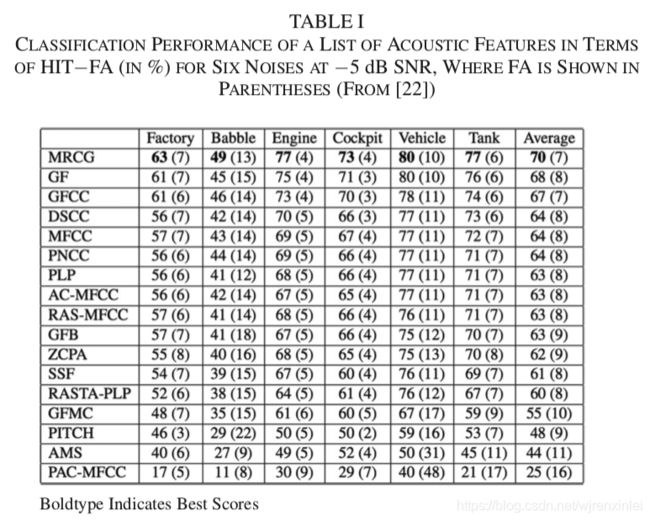
如表所示,在准确度和 HIT-FA 率方面,伽马通域的特征(MRCG、GF 和 GFCC)始终优于其它特征,其中 MRCG 表现最好。通过比较 GF 和 GFCC 特征可以看出,通过离散余弦变换(DCT)进行的倒谱压缩是无效的。值得注意的是,基频特征性能较差主要是由于在低 SNR 的情况下估计不准,事实证明基频具有较强的辨别能力。
最近,Delfarah 和 Wang 进行了另一项特征研究,他们考虑了房间混响,语音降噪和说话人分离。这项研究使用经过训练的固定的 DNN 来估计 IRM,评价结果是对未处理的含噪语音和混响语音进行 STOI 打分得到的。这项研究中的特征包括对数谱幅度 LOG-MAG 和对数梅尔谱特征 LOG-MEL,这两个都是监督分离中常用的特征。还包括原始信号的波形。为了模拟混响,使用了仿真的 RIRs 和真实录制的 RIRs,其混响时间均达到 0.9 秒。在两说话人分离任务中,目标说话人是男性,干扰说话人或是男性或是女性。表2 展示了所评估的各个特征的 STOI 增益。在无回声以及噪声匹配的情况下,STOI 的结果与表1 基本一致。使用仿真的和真实录制的 RIRs 差异也不大。但是,对于匹配噪声、非匹配噪声以及说话人分离来说,性能最好的特征是不一样的。除了 MRCG,PNCC 和 GFCC 分别在非匹配噪声及两说话人条件下得到最佳结果。对于特征组合,该研究得出的结论是:对于语音增强来说,最有效的特征集包括 PNCC、GF 和 LOG-MEL;对于说话人分离来说,最有效的特征集包括 PNCC、GFCC 和 LOG-MEL。
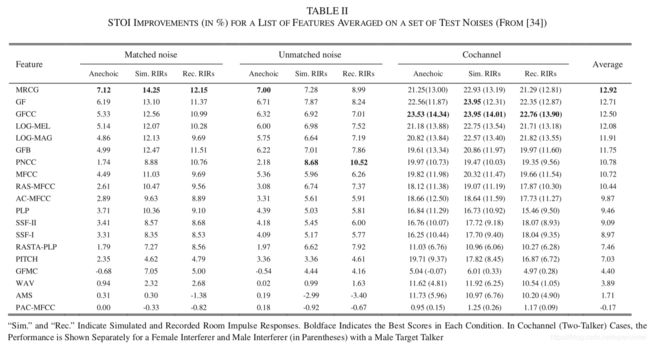
表1 和表2 中特征所引起的巨大性能差异说明了特征对于监督语音分离的重要性。表2 表明如果使用原始信号波形,而不提取特征的话,分离性能将会很差。但是需要注意的是,该项研究中使用的前馈 DNN 可能无法与原始波形信号很好地耦合。而 CNNs 和 RNNs 可能更适合于所谓的端到端分离。文章后半部分会讨论该问题。
7. 单通道分离算法
文章该小节将讨论语音增强、语音去混响、语音去噪去混响以及说话人分离的单通道算法。解释了一些代表性的算法并讨论了监督语音分离的泛化问题。
A. speech enhancement
Yuxuan Wang 和 Deliang Wang 在 2012 年发表的两篇会议文章应该是首次将深度学习引入到语音分离中。随后他们将这两篇文章进行了扩展并于 2013 年发表了期刊论文。他们使用 DNN 进行子带分类来估计 IBM。在会议文章中,具有 RBM 预训练的前馈 DNNs 被用作二值分类器,以及结构化感知器和条件随机野的特征编码器。他们指出在所有使用 DNN 的情况下,都能得到比较强的分离效果,由于在结构化预测中融合了时间的变化,DNN 用于特征学习的结果更好。
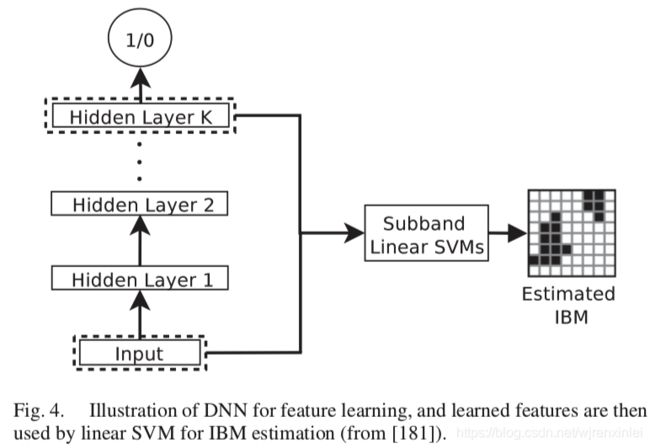
在期刊文章中,将输入信号通过 64 通道的伽马通滤波器组以获得子带信号,然后从这些子带信号中提取每个时频单元内的声学特征。这些特征构成了子带 DNNs(总共 64 个)的输入,以学习更多具有区分性的特征。图4 展示了 DNN 用于语音分离的用法。经过 DNNs 训练之后,输入特征和最后一层隐藏层学到的特征拼接到一起馈送给线性 SVMs 以有效地估计子带 IBM。
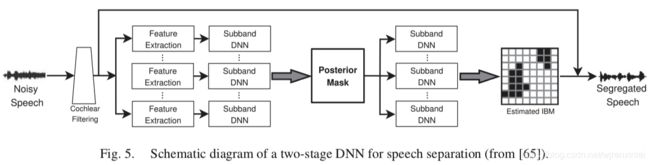
这个算法被进一步扩展为两阶段 DNN,其中,第一阶段像往常一样被训练用来估计子带 IBM,第二阶段按照以下方式明确融合了时频上下文信息。在训练了第一阶段 DNN 之后,可将二值化之前的单元级别的输出解释为语音主导时频单元的后验概率。因此,第一阶段 DNN 的输出被认为是后验掩码。在第二阶段,时频单元将以该单元为中心的后验掩码的局部窗口作为输入。图5 展示了两阶段 DNN。第二阶段的结构让人想起 CNN 中的卷积层,但它没有权值共享。这种方法显示了利用上下文的信息可以显著提高分类准确性。主观测试表明这种 DNN 可以明显改善 HI 和 NH 听众对语音的可懂度,HI 听众受益更多。这是第一个为 HI 听众在背景噪声中提供实质性语音可懂度改善的单通道算法。
Lu 等人在 2013 年发表了一篇用深度自编码器(DAE)作语音增强的文章。基本的自编码器(AE)是一种无监督学习机,它通常具有对称的结构,该结构包含一个具有绑定权重的隐藏层,学习将输入信号映射成自身。可以将多个 AE 堆叠成一个 DAE,然后对 DAE 进行有监督的微调,例如使用反向传播算法。换句话说,自编码是 RBM 预训练的一种替代方法。有些文献中的算法学习从含噪语音的梅尔功率谱映射到干净语音,因此,它可以被认为是第一个基于映射的方法。
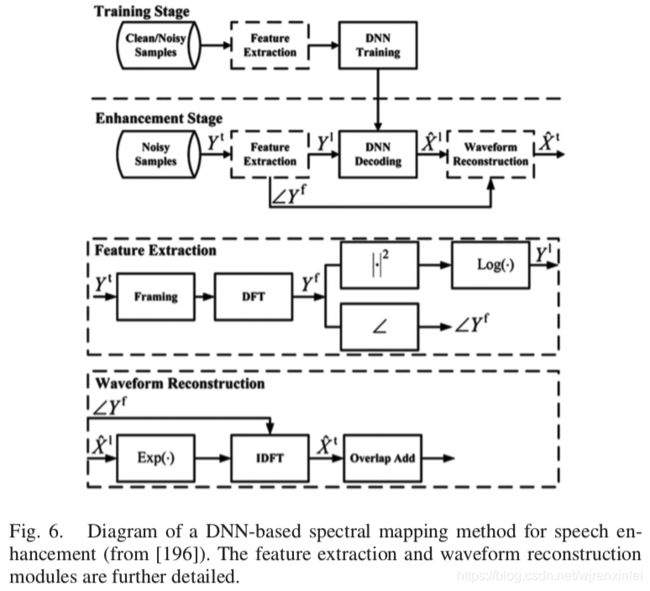
随后,Xu 等人发表了一项研究成果,该研究使用带有 RBM 预训练的 DNN 从含噪语音的对数功率谱映射到干净语音的对数功率谱。图6 展示了该结构。该项研究中使用的 DNN 是标准的带有 RBM 预训练的前向 MLP。训练之后,DNN 从含噪语音谱中估计出干净语音谱。他们的实验结果表明:在集外噪声集上,训练好的 DNN 相比典型的传统增强方法在含噪语音上的 PESQ 分值能提高 0.4~0.5。
此后的大多研究都沿着时频掩码和谱映射的方向在进行。有文章使用 LSTM 来作语音增强任务,并将其应用到鲁棒 ASR 领域里,它的训练目的是信号逼近。有文章使用 RNNs 估计 PSM。有文章提出用深层堆叠网络估计 IBM,然后将掩码估计用于基频估计,两个模块迭代几个周期之后,掩码估计和基频估计的准确性都会提高。有文章使用 DNN 同时估计 cIRM 的实部和虚部。最近有文章研究了因素级别的语音增强。在某些文章中,DNN 考虑了具有分段增益函数的感知掩码。有文章表明多目标学习可以提高增强性能。有文章证明子带谱映射的分层 DNN 要比全带谱映射的单个 DNN 产生更好的增强效果。有文章为了改善增强性能,在 DNN 中添加非连接层之间的跳过连接。有文章发现基于掩码和基于映射的多目标训练要优于单目标训练。在某些文章中,CNNs 也已用于 IRM 估计和谱映射。
除了基于掩码和谱映射的方法外,最近的研究也有使用深度学习作端到端的语音分离,也就是直接在时域进行映射,而不转为时频表示。这种方法的一个潜在优势是在重建增强语音的时候避免了使用含噪语音的相位,否则在低 SNR 的情况下会影响语音质量。最近,Fu 等人开发了一种用于语音增强的全卷积网络(去除了全连接层的 CNN),他们发现全连接很难映射信号的高频和低频分量,去除全连接后增强结果有改善。由于卷积运算与滤波器或者特征提取器相同,因此, CNNs 似乎是时域映射的一个很自然的选择。
最近有研究使用 GAN 作时域映射。在所谓的语音增强 GAN(SEGAN)中,生成器是一个全卷积网络,用来增强或去噪。判别器使用与生成器同样的卷积结构。判别器可以认为是给生成器提供了可训练的损失函数。在未经训练的含噪条件下对 SEGAN 进行了评估,但结果尚无定论,它的效果要比基于掩码和基于映射的方法差。在另一篇 GAN 的研究中,生成器试图增强含噪语音的谱,而判别器试图区分增强语音与其对应的干净语音的谱。文章中的比较结果表明,该 GAN 可获得与 DNN 同样的增强效果。
并非所有的基于深度学习的语音增强方法都基于 DNNs。例如,Le Roux 等人提出深度 NMF,它展开 NMF 操作,并在反向传播中包含乘法更新。Vu 等人提出了一个 NMF 框架,该框架训练 DNN 以将含噪语音的 NMF 激活系数映射到其干净语音上。
B. Generalization of Speech Enhancement Algorithms
对于任何监督学习任务,泛化到集外数据是至关重要的。监督增强包含 3 个方面的泛化:噪声、说话人和 SNR。对于 SNR 泛化,可以在训练集中包含更多不同的 SNR 数据,实验表明监督增强对训练中使用的精确的 SNRs 不敏感。部分原因是,即使训练中包含了一些混合的 SNR,但是帧级别或时频级别的局部 SNRs 变化范围很大,这为学习机提供了必要的多样性以使其更好地泛化。另一种替代策略是采用渐进式训练,增加隐藏层的数量来处理低 SNR 的情况。
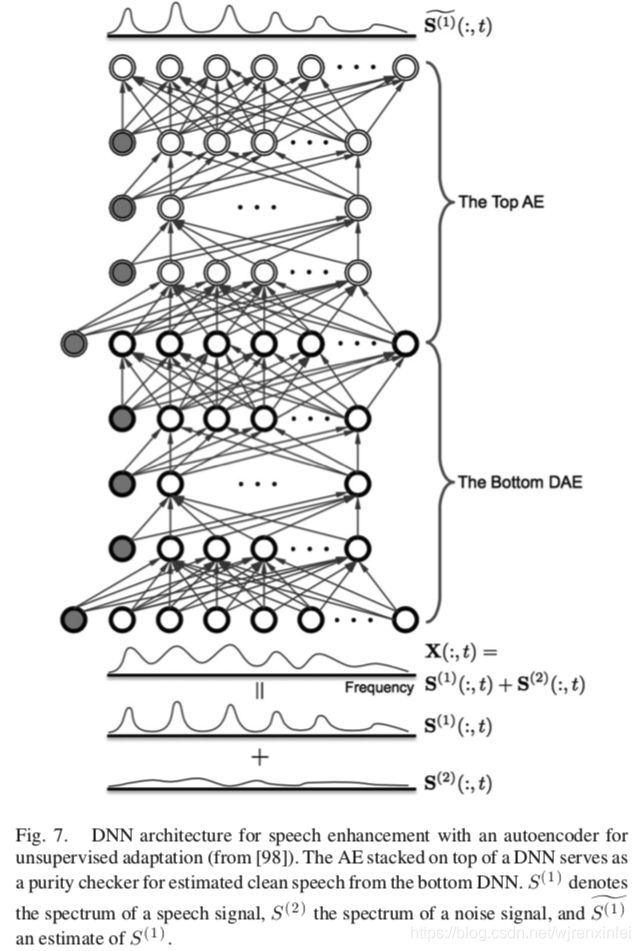
为了解决训练和测试间的不匹配,Kim 和 Smaragdis 提出了两阶段 DNN,第一阶段是一个用于谱映射的标准 DNN,第二阶段是一个在测试期间执行无监督自适应的自编码器。训练 AE 以将干净语音的幅度谱映射到其自身,因此它的训练是不需要标记数据的。然后将 AE 堆叠在 DNN 的顶部,用作纯度检查器,如图7 所示。这里面的基本原理是,效果好的增强语音趋向于在 AE 的输入和输出之间产生很小的差异,而效果差的增强语音会产生较大的差异。给一个测试混合集,已经训练的 DNN 会使用来自 AE 的误差信号进行微调。AE 模块的引入提供了一种无监督的自适应方式来适应与训练条件完全不同的测试条件,实验表明这样可以改善语音增强的性能。
噪声泛化从根本上具有挑战性,因为各种各样的平稳和非平稳噪声都可以干扰语音信号。当可获得的训练噪声是有限的时候,一种方法是通过噪声扰动来扩充训练噪声,尤其是频率扰动;具体来说,修改原始噪声的频谱以生成新的噪声。为了使基于 DNN 的映射算法对新的噪声更鲁棒,Xu 等人结合了噪声感知训练,也就是输入特征向量中包含显示的噪声估计。利用通过二值掩码估计的噪声,具有噪声感知训练的 DNN 可以更好地泛化到未训练的噪声。
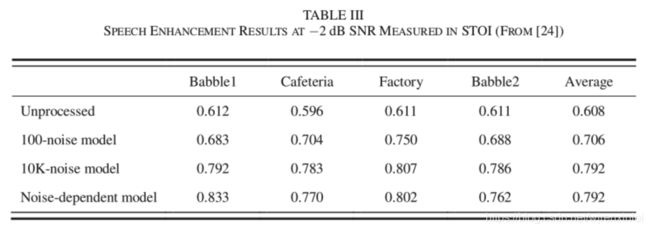
有研究系统地解决了噪声泛化问题。该研究中 DNN 被用来估计帧级别的 IRM,(另外,有研究在连续的几帧上同时估计 IRM,并对同一帧的不同估计值求均值,以生成更平滑更准确的掩码。)该 DNN 具有 5 个隐藏层,每个隐藏层有 2048 个节点,使用 ReLUs 作为激活函数。每帧的输入特征是耳蜗谱响应能量。训练集包括 SNR 为 -2dB 的 640000 句话,它们是由来自 IEEE 的 560 句干净语音和来自音效库(www.sound-ideas.com)的 10000 句噪声混合成而成。噪声总时长为 125 小时,训练集总时长为 380 小时。为了评估训练噪声量对噪声泛化的影响,同时训练一个只用了 100 句噪声的 DNN。测试集由来自 IEEE 的 160 句干净语音和非平稳噪声以不同的 SNRs 混合而成。测试集中的干净语音和噪声都未用于训练。表3 展示了用 STOI 评价的分离结果,使用 10000 句噪声训练出的模型的 STOI 较高。另外,10000 句噪声模型明显优于 100 句噪声模型。主观测试表明,大规模训练出的噪声无关的模型可以显著提高 NH 和 HI 听众在未见过的噪声下的语音可懂度。该研究有力地表明,对各种各样的噪声进行大规模训练是解决噪声泛化问题的一种有效途径。
至于说话人泛化,在特定说话人上训练出的分离系统将不能很好地工作在其它说话人上。说话人泛化的一个直接尝试是训练大量的说话人。然而,有实验结果显示,前馈 DNN 似乎无法建模大量的说话人。这样的 DNN 通常使用一个窗长的声学特征来估计掩码,而不使用长时上下文信息。前馈网络无法跟踪目标说话人,因此它倾向于将噪声误认为目标语音。RNNs 本质上就是对时间依赖性进行建模,因此它比前馈 DNN 更适合于说话人泛化。
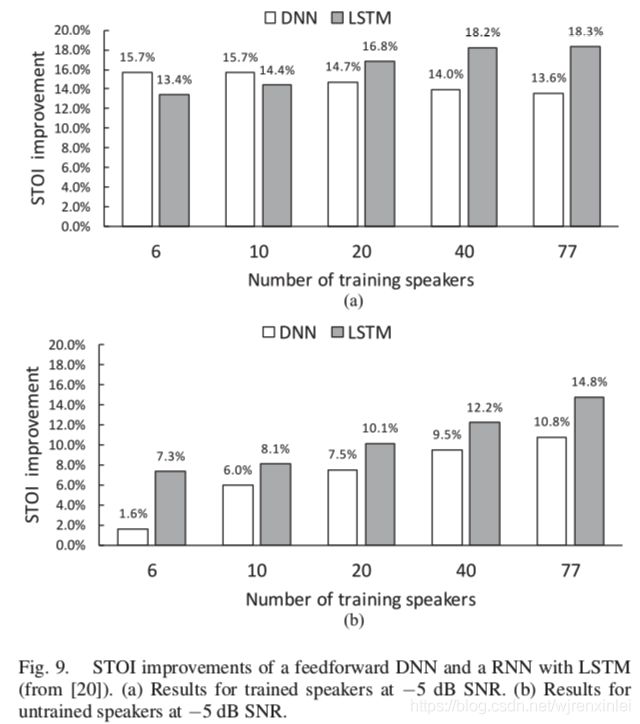
文章作者最近使用 LSTM 来解决噪声无关模型的说话人泛化问题。图8 中显示的模型使用了 3200000 句话,这些话由 10000 句噪声分别和 6、10、20、40 和 77 个说话人混合而成。图9(a) 展示了在集内说话人上的测试结果,当训练集中包含的说话人越多,DNN 的性能下降的越厉害,而 LSTM 的性能却有提升。图9(b) 展示了在集外说话人上的测试结果,LSTM 的 STOI 得分明显优于 DNN。在训练过程中,当接触到许多说话人之后,LSTM 似乎能随着时间的推移跟踪目标说话人。通过对大量说话人和大量噪声进行大规模的训练,LSTM 成为了一种有效的说话人无关和噪声无关的语音增强方法。
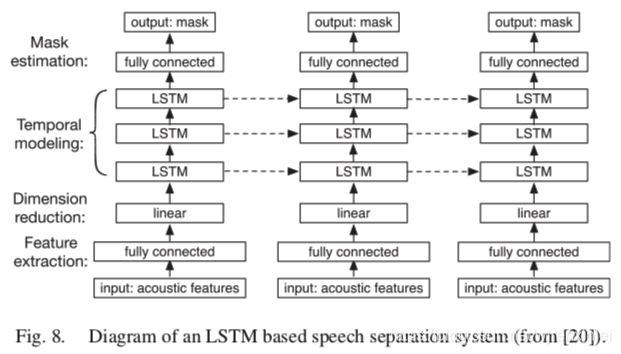
C. Speech Dereverberation and Denoise
在实际环境中,语音经常会受到混响的干扰。房间混响对应于直达信号和 RIR 的卷积,它会在时间和频率两个维度对语音造成失真。混响是语音处理中一个公认的挑战,特别是当背景噪声也同时存在的时候。因此,去混响已经被研究了很长时间。
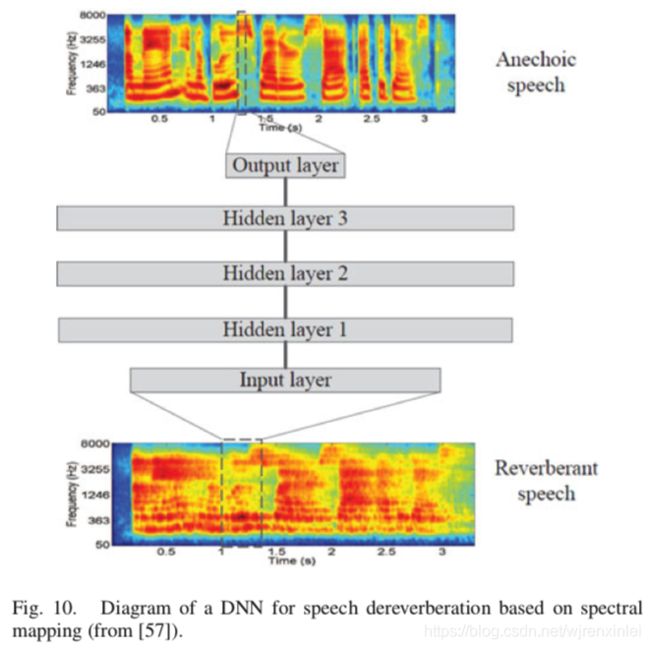
Han 等人提出了第一个基于 DNN 的去混响方法。这种方法在耳蜗谱上使用谱映射。换句话说,DNN 将混响语音帧映射到无混响语音帧,如图10 所示。训练好的 DNN 能够高质量地重建无混响语音的耳蜗谱。他们在后续的工作中将谱映射方法应用到语谱上,并同时完成去混响和去噪两个任务。
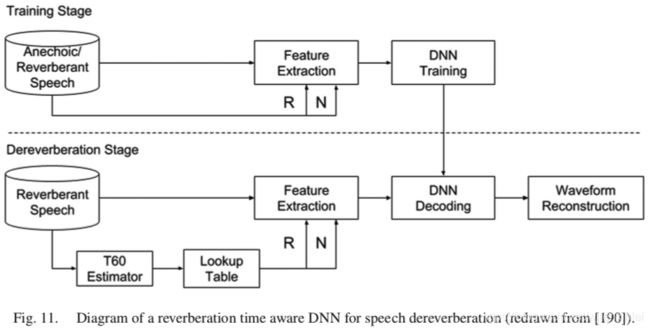
Wu 等人最近提出了一种更复杂的系统,他们发现根据混响时间(T60)选择不同的帧长和帧移时,混响性能会得到改善。基于此,他们的系统将 T60 作为特征提取和 DNN 训练中的控制参数。在去混响阶段,首先估计出 T60,然后根据估计出的 T60 选择合适的帧长和帧移以提取特征。图11 展示了所谓的混响时间感知模型。比较显示去混响性能有提升。
为了改善从含噪和混响语音中对无混响语音的估计,Xu 等人提出了一种 DNN,它可以同时预测静态、增量和加速特征。静态特征是干净语音的对数幅度,增量和加速特征是从静态特征推导而来。有人认为,DNN 既然能很好地预测静态特征,那么它也能很好地预测增量和加速特征。在 DNN 中融合动态特征可以改善去混响任务中静态特征的估计。
Zhao 等人发现:对于去混响任务而言,基于谱映射的方法要比基于时频掩码的方法更有效,而对于去噪任务而言,后者工作地要比前者好。因此,他们构建了两阶段 DNN,其中第一阶段使用比例掩码做去噪任务,而第二阶段使用谱映射做去混响任务。此外,为了缓解在重构增强语音过程中使用含噪和混响语音的相位带来的负面影响,该研究也扩展了另一篇文章中重建时域信号的技术。该研究的训练目标定义在时域,训练阶段使用的是干净语音的相位,而另一篇文章中使用的是含噪语音的相位。先分别对这两阶段模型进行训练,随后再进行联合训练。Zhao 等人的结果显示,无论训练目标是掩码还是映射,两阶段 DNN 模型性能均明显优于单阶段模型性能。
D. Speaker Separation
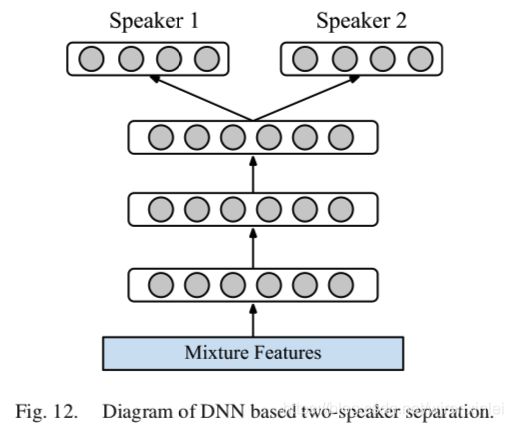
说话人分离的目标是从两个或多个语音的混合信号中分离出每个说话人的语音。在证明深度学习能够做语音增强任务之后,DNN 已经成功地被应用到语音分离任务上。如图12 所示。
据调研,Huang 等人是第一个将 DNN 应用到说话人分离任务上的研究者们。这项研究使用前馈 DNN 和 RNN 解决两说话人分离的问题。Huang 等人认为在第 t 帧处估计的两个声源的谱( S ^ 1 ( t ) \bm{\hat{S}}_1(t) S^1(t)、 S ^ 2 ( t ) \bm{\hat{S}}_2(t) S^2(t))之和不能保证等于混合信号的谱。因此,在网络中加入掩码层以按照下列公式生成两个最终的输出结果:
S ~ 1 ( t ) = ∣ S ^ 1 ( t ) ∣ ∣ S ^ 1 ( t ) ∣ + ∣ S ^ 2 ( t ) ∣ ⊙ Y ( t ) (8) \bm{\widetilde{S}}_1(t)=\frac{|\bm{\hat{S}}_1(t)|}{|\bm{\hat{S}}_1(t)|+|\bm{\hat{S}}_2(t)|}\odot\bm{Y}(t)\tag{8} S 1(t)=∣S^1(t)∣+∣S^2(t)∣∣S^1(t)∣⊙Y(t)(8)
S ~ 2 ( t ) = ∣ S ^ 2 ( t ) ∣ ∣ S ^ 1 ( t ) ∣ + ∣ S ^ 2 ( t ) ∣ ⊙ Y ( t ) (9) \bm{\widetilde{S}}_2(t)=\frac{|\bm{\hat{S}}_2(t)|}{|\bm{\hat{S}}_1(t)|+|\bm{\hat{S}}_2(t)|}\odot\bm{Y}(t)\tag{9} S 2(t)=∣S^1(t)∣+∣S^2(t)∣∣S^2(t)∣⊙Y(t)(9)
其中, Y ( t ) \bm{Y}(t) Y(t) 表示第 t t t 帧混合信号的谱。二值掩码和比例掩码都证明是有效的。另外,采用判别训练以最大化一个说话人与估计的另一个说话人之间的差异。在训练期间,最小化以下代价函数:
1 2 ∑ t ( ∣ ∣ S 1 ( t ) − S ~ 1 ( t ) ∣ ∣ 2 + ∣ ∣ S 2 ( t ) − S ~ 2 ( t ) ∣ ∣ 2 − γ ∣ ∣ S 1 ( t ) − S ~ 2 ( t ) ∣ ∣ 2 − ∣ ∣ γ S 2 ( t ) − S ~ 1 ( t ) ∣ ∣ 2 ) (10) \frac{1}{2}\sum_t(||\bm{S}_1(t)-\bm{\widetilde{S}}_1(t)||^{2}+||\bm{S}_2(t)-\bm{\widetilde{S}}_2(t)||^{2}\\-\gamma||\bm{S}_1(t)-\bm{\widetilde{S}}_2(t)||^{2}\\-||\gamma\bm{S}_2(t)-\bm{\widetilde{S}}_1(t)||^{2})\tag{10} 21t∑(∣∣S1(t)−S 1(t)∣∣2+∣∣S2(t)−S 2(t)∣∣2−γ∣∣S1(t)−S 2(t)∣∣2−∣∣γS2(t)−S 1(t)∣∣2)(10)
其中, S 1 ( t ) \bm{S}_1(t) S1(t) 和 S 2 ( t ) \bm{S}_2(t) S2(t) 分别表示两个说话人真实的谱, γ \gamma γ 是可调参数。实验结果表明,掩码层和判别训练都能改善说话人分离性能。
几个月之后,Du 等人独立地提出了用来做说话人分离的 DNN,这与 Huang 等人提出的类似。在 Du 等人研究中,DNN 被用来从两说话人混合信号的对数功率谱中估计目标说话人的对数功率谱。在另一项研究中,他们使用 DNN 从两说话人混合信号中映射出目标说话人和干扰说话人的谱,如图12 所示。他们的这些研究还解决了训练集和测试集使用相同的目标说话人,使用不同的干扰说话人的情况。
在说话人分离中,如果训练集和测试集中潜在的说话人都是一样的,那么这种情况称为说话人相关。如果允许改变干扰说话人,而目标说话人是固定的,那么这种情况称为目标相关说话人分离。在最小约束的情况下(即没有任何说话人被要求既出现在训练集又出现在测试集的情况下),这种情况称为说话人无关。从这个角度来看,Huang 等人的一部分研究是说话人相关,而另一部分研究是同时处理说话人和目标相关分离。使用目标说话人和许多干扰说话人的两说话人混合来训练模型,他们通过这种方法来减少对干扰说话人的限制。
Zhang 和 Wang 提出了一个深层集成网络来解决说话人相关和目标相关的分离问题。他们使用多上下文网络来集成不同分辨率的时域信息。集成是指堆叠多个模块,每个模块执行多上下文掩码或者映射。他们研究了不同的训练目标。对说话人相关分离来说,信号逼近是最有效的;对目标相关分离来说,信号逼近和比例掩码的联合是最有效的。此外,目标相关的分离性能和说话人相关的分离性能接近。最近,Wang 等人的研究进一步减少了对说话人的依赖。他们的方法是先将每个说话人分为四类(两男两女)中的一类,然后训练一个基于 DNN 的性别混合检测器来确定两个潜在说话人的类别。尽管对每个类别中的部分说话人进行了训练,但评估结果表明,这种说话人分离方法对每个类别中未参与训练的说话人的效果也很好。
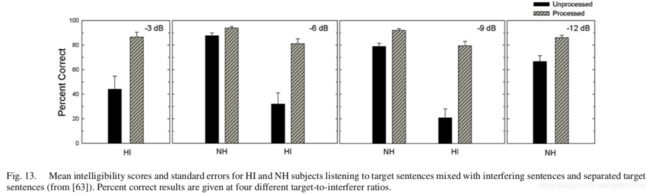
Healy 等人最近使用 DNN 来做说话人相关的两说话人分离,并让 HI 和 NH 听众来评价该 DNN 的语音可懂度。DNN 被用来估计 IRM 以及其补数,这两个分别对应于目标说话人和干扰说话人。与早期的基于 DNN 的两说话人分离研究相比,Healy 等人提出的算法使用了多个特征,并预测了多个 IRM 帧,从而实现了更好的分离效果。图13 展示了可懂度结果。对于 HI 听众来说,基于 DNN 的分离在目标干扰比(TIR)为 -3dB、-6dB 和 -9dB 的情况下,语音可懂度分别提升了 42.5%、49.2% 和 58.7%。对于 NH 听众来说,语音可懂度在统计意义上有明显提升,但是程度相对较小。值得注意的是,HI 听众的语音可懂度有了很大提升,这使得他们在 -6dB 和 -9dB TIR 的语句上与 NH 听众(没有算法的帮助)一样。
说话人无关的分离可以被认为是无监督聚类问题,其时频单元被聚类为由各个说话人主导的不同类别。就说话人的数量来说,聚类是一个灵活的框架,但是它并不能从有差异的信息(监督训练充分利用了该信息)中获得更多的收益。Hershey 等人率先在 DNN 的框架下解决了说话人无关的多说话人分离问题。他们称之为深度聚类的方法,联合了基于 DNN 的特征学习和谱聚类。使用下式计算相似度矩阵(affinity matrix)A:
A = Y Y T (11) \bm{A}=\bm{Y}\bm{Y}^{T}\tag{11} A=YYT(11)
其中, Y \bm{Y} Y 是通过 IBM 构建出的标识矩阵(indicator matrix)。当单元 i i i 属于说话人 c c c 的时候, Y i , c Y_{i,c} Yi,c 的值为 1,否则为 0。DNN 被嵌入到每个时频单元。可以从该嵌入中推导出估计的相似度矩阵 A ^ \bm{\hat{A}} A^。DNN 通过最小化以下代价函数,学习为来自同一说话人的时频单元输出类似的嵌入:
C Y ( V ) = ∣ ∣ A ^ − A ∣ ∣ F 2 = ∣ ∣ V V T − Y Y T ∣ ∣ F 2 (12) C_{\bm{Y}}(\bm{V})=||\bm{\hat{A}}-\bm{A}||_{F}^{2}=||\bm{V}\bm{V}^{T}-\bm{Y}\bm{Y}^{T}||_{F}^{2}\tag{12} CY(V)=∣∣A^−A∣∣F2=∣∣VVT−YYT∣∣F2(12)
其中, V \bm{V} V 是时频单元的嵌入矩阵(embedding matrix)。 V \bm{V} V 的每行代表一个时频单元。 ∣ ∣ ⋅ ∣ ∣ F 2 ||\cdot||_{F}^{2} ∣∣⋅∣∣F2 指 F r o b e n i u s Frobenius Frobenius 范数的平方。低阶公式可用于有效地计算代价函数及其导数。在推理阶段,对混合进行分段,并计算每个分段的嵌入矩阵 V \bm{V} V。然后,将所有分段的嵌入矩阵连接到一起。最后,使用 K K K-means 算法将所有分段的时频单元聚类为对应的说话人类别。段级别的聚类要比句子级别的聚类更准确,但是仅针对单个段的聚类结果,必须解决序列组织的问题。研究表明,深度聚类可获得高质量的说话人分离结果,其明显优于 CASA 方法和说话人无关的 NMF 方法。
深度聚类的最新扩展是深度吸引子网络,它也学习时频单元的高维度嵌入。与深度聚类不同,该深度网络首先会创建类似于聚类中心的吸引点,以将由不同说话人主导的时频单元匹配到其相应的吸引子上。然后通过比较嵌入点和每个吸引子,将说话人分离作为掩码估计。文献的结果显示,深度吸引子网络能比深度聚类产生更好的结果。
基于聚类的方法自然地会生成说话人无关的模型,而基于 DNN 的掩码/映射方法将 DNN 的每个输出绑定到特定的说话人上,生成说话人相关的模型。比如,基于映射的方法最小化以下代价函数:
J = ∑ k , t ∣ ∣ ( ∣ S ~ k ( t ) ∣ − ∣ S k ( t ) ∣ ) ∣ ∣ 2 (13) J=\sum_{k,t}||(|\widetilde{\bm{S}}_k(t)|-|\bm{S}_k(t)|)||^2\tag{13} J=k,t∑∣∣(∣S k(t)∣−∣Sk(t)∣)∣∣2(13)
其中, ∣ S ~ k ( t ) ∣ |\widetilde{\bm{S}}_k(t)| ∣S k(t)∣ 和 ∣ S k ( t ) ∣ |\bm{S}_k(t)| ∣Sk(t)∣ 分别表示说话人 k k k 估计的谱幅度和真实的谱幅度, t t t 表示时间帧。为了将 DNN 的输出与特定说话人解绑,以及为了使用基于掩码或映射的方法训练说话人无关的模型,Yu 等人提出了置换不变的训练,如图14 所示。对于两说话人分离,DNN 输出两个掩码,并将每个掩码都应用于含噪语音以产生估计的源。在训练 DNN 期间,代价函数是动态计算的。如果在训练数据中将每个输出分配给参考说话人 ∣ S k ( t ) ∣ |\bm{S}_k(t)| ∣Sk(t)∣,会有两种可能的分配方式,每个分配方式都与一个 MSE 相关。选择具有较低 MSE 的分配方式,并训练 DNN 以最小化相应的 MSE。在训练和推理阶段,DNN 会使用一段或多帧特征,并估计出该段的两个声源。因为 DNN 的两个输出并没有绑定到任何说话人上,因此,同一个说话人可能会在连续的段中从 DNN 的一个输出切换到另一个输出上。因此,除非段长度等于句子长度,否则估计的段级别的声源需要被有序组织起来。尽管该方法更加简单,但说话人分离的结果显示其与深度聚类方法所获得的结果是匹配的。
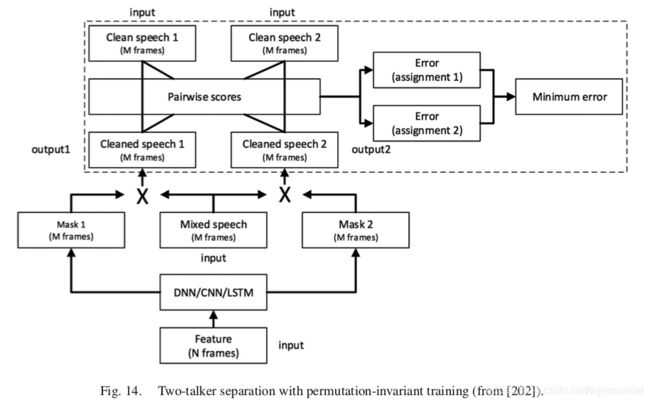
应该注意的是,尽管说话人分离评估通常集中在两说话人任务上,但分离框架可以推广到分离两个以上说话人的任务上。例如,图12 和图14 所示的系统可以直接被扩展以处理三个说话人的分离任务。也可以使用多说话人的混合来训练目标独立的模型。对于说话人无关的分离任务,深度聚类和置换不变训练都是针对多说话人提出的,而且都使用相同的数据进行评估。在将两说话人任务扩展到多说话人任务这个问题上,深度聚类比置换不变训练更直接。
从这小节回顾的工作中可以看出,使用多对不同说话人训练的 DNN 模型能够分离训练集外的说话人,这是一种说话人无关的分离情况,但这仅限于帧级别。对于说话人无关的分离任务,关键问题是如何在整个时间的单独帧上对分离的语音信号进行分组。这正是顺序组织的问题,CASA 对此进行了很多研究。置换不变训练可以被视为在 DNN 训练期间施加了顺序分组约束。另一方面,典型的 CASA 方法使用基频等高线、声道特征、节奏或韵律、甚至在有多个传感器时可以使用共同的空间方位(通常不涉及监督学习)。在作者看来,将传统的 CASA 技术和深度学习结合是未来研究的沃土。
8. 阵列分离算法
麦克风阵列可提供多个单通道录音,这其中包含了声源的空间方位信息。当声源在空间中传播时,可使用传感器阵列的输入对声源定位,然后从目标位置或方位提取出声源。传统的基于空间信息的声源分离方法包括波束形成和独立主成分分析。声定位和基于位置信息的分组是听觉感知和 CASA 的经典主题之一。
A. Separation Based on Spatial Feature Extraction
Roman 等人进行了双通道有监督语音分离的第一项研究。该研究基于两个双耳特征:ITD 和 ILD 进行有监督分类以估计 IBM。这两个特征都是从左耳和右耳的耳蜗谱的各个时频单元对中提取的。注意,在这种情况下,IBM 是在单耳(参考通道)的含噪语音上定义的。分类基于最大后验(MAP)概率,其中似然度由一个密度估计方法给出。Yilmaz 和 Rickard 大约在同一时间发布了另一种经典的两麦分离技术:DUET(Degenerate Unmixing Estimation Technique)。DUET 基于无监督聚类,它所使用的空间特征是两麦之间的相位和幅度差。在这些研究中,分类和聚类之间的对比是一个永恒的主题,并且在以后的研究中预计会出现类似的对比,例如,波束形成中的二值掩码 vs 聚类,说话人无关分离中的深度聚类 vs 掩码估计。
将麦克风阵列提供的空间信息作为深度学习的特征是对早期使用的 DNN 在单通道分离中的直接扩展。 确实,这种利用空间信息的方式为整合单通道和空间特征进行源分离提供了一个自然的框架,这一点值得强调,因为传统研究倾向于在不考虑单通道分组的情况下进行阵列分离。 值得注意的是,人类听觉场景分析可以无缝结合单耳和双耳分析,并利用特定环境中存在的任何判别性信息。
Jiang 等人发表了第一个将 DNN 用于双通道分离的研究。在该项研究中,来自双耳(或麦克风)的信号被输入给两个相应的听觉滤波器组。从时频单元对中提取 ITD 和 ILD 特征,然后将其送给子带 DNN 以估计 IBM,每个通道对应一个 DNN。另外,从左耳的输入中提取单声道特征(GFCC)。这项研究可以得出许多结论。也许最重要的是,经过训练的 DNN 可以很好地推广到未经训练的声源空间配置上去。空间配置是指声学环境中声源和传感器的特定摆放位置。这是使用监督学习的关键所在,因为存在无限的配置,并且训练集无法枚举各种配置。基于 DNN 的双耳分离被发现可以很好地泛化 RIRs 和混响时间。并且还观察到,单耳特征的结合改善了分离性能,尤其是当目标源和干扰源位于同一位置或彼此靠得较近时。
Araki 等人使用 DNN 来做谱映射,除了单通道输入外,还包括空间特征:ILD,耳间相位差(IPD)和带有从位置信息派生的初始掩码的增强特征。他们对 ASR 相关指标的评估表明,结合单通道和增强特征可以获得最佳的增强性能。Fan 等人提出了一种利用双通道和单通道输入的谱映射方法。对于双通道特征,该研究使用子带 ILD,它们比全带 ILD 更有效。 然后,将这些特征与左耳的帧级别的对数功率谱连接起来作为 DNN 的输入,该 DNN 经过训练可以映射到干净语音谱。 与其他研究进行的定量比较表明,他们的系统针对分离的语音产生了更好的 PESQ 分数,但 STOI 分数却相似。
Yu 等人提出了一种更复杂的双通道分离算法。该算法所使用的空间特征包括 IPD,ILD 和所谓的混合向量,它是一个单元对的组合 STFT 值的形式。所使用的 DNN 是 DAE,它先作为自动编码器在无监督的情况下进行训练,然后将其堆叠到 DNN 中进行有监督的微调。首先,通过无监督的 DAE 训练将提取的空间特征映射到能表明空间方向的高级特征。然后,为了进行分离,训练一个分类器,以将高级空间特征映射到声源方向的离散范围。该算法在子带上运行,每个子带覆盖一块连续的频带。
最近,Zhang 和 Wang 开发了一种用于估计 IRM 的 DNN,它具有一组更复杂的空间和谱特征。他们的算法如图15 所示,其中左耳和右耳输入被馈送到两个不同的模块,以进行谱(单通道)和空间(双通道)分析。谱分析是对固定波束形成器的输出进行的,该波束形成器本身通过提取互补的单通道特征集而抑制背景干扰。为了进行空间分析,提取互相关函数形式的 ITD 和 ILD。将谱和空间特征串联起来形成 DNN 的输入,以便在帧级别估计 IRM。与传统的波束形成器(包括 MVDR(最小方差无失真响应)和 MWF(多通道维纳滤波器))相比,该算法在混响多声源环境下产生的分离效果要好得多。从他们的分析中得出的一个有趣的结果是,在谱特征提取之前使用波束形成器的许多收益点可以简单地通过连接两只耳朵的单通道特征来获得。

尽管上述方法都是双通道的,涉及两个传感器,但是从具有两个传感器的阵列扩展到具有 N 个传感器(N > 2)的阵列通常很简单。以图15 中的系统为例。使用 N 个麦克风,频谱特征提取无需更改,因为传统的波束形成器使用任意数量的麦克风。对于空间特征提取,如果有两个以上的传感器,则需要扩展特征空间,具体方法是指定一个麦克风作为派生一组“双耳”特征的参考,或者考虑所有传感器对的相关性矩阵或协方差矩阵。输出是目标语音的时频掩码或谱包络,可以将其视为单通道。由于传统阵列波束形成也会产生与目标源相对应的“单通道”输出,因此基于空间特征的时频掩蔽可被视为波束形成或更准确地说是非线性的波束形成,正好与传统的波束形成相反,因为传统的波束形成是线性的。
B. Time-Frequency Masking for Beamforming
顾名思义,波束形成是增强目标方位的信号,抑制非目标方位的信号。 在实际应用中,波束形成器需要知道信号的目标方向以控制波束形成器。通常通过估计目标声源的到达方向(DOA)或声源定位来获得这种导向矢量。在混响、多声源环境中,定位目标声音绝非易事。在 CASA 中,众所周知,定位和分离是两个紧密相关的功能。对于人类的听觉,证据表明声源的定位很大程度上取决于声源的分离。
在鲁棒 ASR 的 CHiME-3 挑战赛的推动下,两项独立研究首次将基于 DNN 的单通道语音增强与传统的波束形成相结合,研究成果均发表在 ICASSP 2016 上。CHiME-3 挑战赛提供了由安装在平板电脑上的 6 个麦克风记录的来自单个说话人的含噪语音数据。在这两项研究中,单通道语音分离提供了计算导向矢量的基础,巧妙地绕过了需要通过 DOA 估计来执行的两项任务:定位多个声源和选择目标(语音)源。 为了解释他们的想法,让我们首先将 MVDR 作为代表性的波束形成器进行描述。
MVDR 旨在最大程度地减少非目标方向的噪声能量,同时施加线性约束以维持目标方向的能量。阵列的捕获信号在 STFT 域中可以描述为:
y ( t , f ) = c ( f ) s ( t , f ) + n ( t , f ) (14) {\bf{y}}(t,f)={\bf{c}}(f)s(t,f)+{\bf{n}}(t,f)\tag{14} y(t,f)=c(f)s(t,f)+n(t,f)(14)
其中 y ( t , f ) {\bf{y}}(t,f) y(t,f) 和 n ( t , f ) {\bf{n}}(t,f) n(t,f) 分别表示含噪语音和噪声信号的 STFT 空间矢量, s ( t , f ) s(t,f) s(t,f) 表示语音源的 STFT 变换。 c ( f ) s ( t , f ) {\bf{c}}(f)s(t,f) c(f)s(t,f) 表示阵列接收到的语音信号, c ( f ) {\bf{c}}(f) c(f) 表示阵列的导向矢量。
MVDR 波束形成器在频率 f f f 处确定一个权重向量 w ( f ) w(f) w(f),该向量使波束形成器的平均输出功率最小,同时保持注视(目标)方向的能量。为简洁起见,省略 f f f,可以将这个优化问题表示为:
w o p t = arg min w { w H Φ n w } , subject to w H c = 1 (15) {\bf{w}}_{opt}=\underset{{\bf{w}}}{\arg\min}\{{\bf{w}}^H{{\bf{\Phi}}}_n{\bf{w}}\}, \text{ subject to }{\bf{w}}^H{\bf{c}}=1\tag{15} wopt=wargmin{wHΦnw}, subject to wHc=1(15)
其中 H H H 表示共轭转置, Φ n {{\bf{\Phi}}}_n Φn 是噪声的空间协方差矩阵。注意,输出功率的最小化等于噪声功率的最小化。 该二次优化问题的解是:
w o p t = Φ n − 1 c c H Φ n − 1 c (16) {\bf{w}}_{opt}=\frac{{{\bf{\Phi}}}_n^{-1}{\bf{c}}}{{\bf{c}}^H{{\bf{\Phi}}}_n^{-1}{\bf{c}}}\tag{16} wopt=cHΦn−1cΦn−1c(16)
增强的语音信号为:
s ~ ( t ) = w o p t H y ( t ) (17) \widetilde{s}(t)={\bf{w}}_{opt}^H{\bf{y}}(t)\tag{17} s (t)=woptHy(t)(17)
因此,准确估计出 c {\bf{c}} c 和 Φ n {{\bf{\Phi}}}_n Φn 是 MVDR 波束形成的关键。此外, c {\bf{c}} c 对应于语音的空间协方差矩阵 Φ x {{\bf{\Phi}}}_x Φx 的主成分。在语音和噪声不相关的情况下,
Φ x = Φ y − Φ n (18) {{\bf{\Phi}}}_x={{\bf{\Phi}}}_y-{{\bf{\Phi}}}_n\tag{18} Φx=Φy−Φn(18)
因此,就像传统语音增强一样,噪声估计对于波束形成的性能至关重要。
在某些研究中,带有双向 LSTM 的 RNN 用于估计 IBM。首先,利用每个传感器的数据单通道地训练出一个通用神经网络。然后,使用训练好的网络为每个麦克风数据生成一个二值掩码,并将多个掩码通过中值运算组合为一个掩码。该掩码用于估计语音和噪声的协方差矩阵,通过它们可以求得波束形成器的系数。该研究的结果表明,MVDR 的效果不及 GEV(广义特征向量)波束形成器。某些研究提出了一种基于空间聚类的方法来计算比例掩码。这种方法使用复数域的 GMM(cGMM)来描述以噪声为主的时频单元的分布,并使用另一个 cGMM 来描述同时具有语音和噪声的时频单元的分布。在估计完参数之后,两个 cGMM 用于计算含噪语音和噪声的协方差矩阵,然后将其馈送到 MVDR 波束形成器以进行语音分离。这两种算法的性能都非常好,Higuchi 等人的方法被用于 CHiME-3 挑战赛中性能最佳的系统。
Nugraha 等人给出了不同于上述两项研究的方法。他们使用 DNN 进行单通道分离,并使用复杂的多元高斯分布来对空间信息进行建模,从而进行阵列声源分离。该研究中的 DNN 用于建模声源谱或谱映射。估算并迭代更新语音和噪声的功率谱密度(PSDs)以及空间协方差矩阵。图16 展示了该研究的处理过程。首先,根据到达时间差(TDOA)对齐阵列信号,并进行平均以生成单通道信号。然后,用 DNN 产生噪声和语音 PSDs 的初始估计。在对 PSDs 和空间协方差矩阵进行迭代估计的过程中,DNNs 用于进一步改进由多通道维纳滤波器估计的 PSDs。最后,对从多个麦克风信号中估计出的语音信号进行平均,以生成用于 ASR 评估的单个语音估计。该算法比基于 DNN 的单通道分离和基于阵列 NMF 的分离产生更好的分离和 ASR 结果。

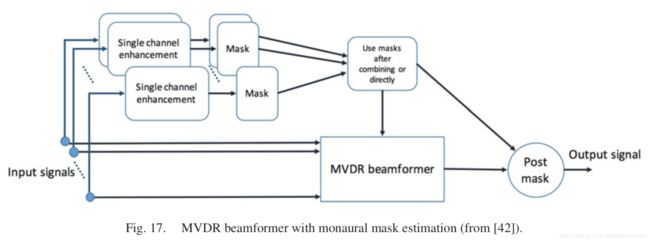
Higuchi 和 Heymann 等人在 CHiME-3 挑战赛中通过使用 DNN 估计掩码进行波束形成的成功,已经激发出了许多最新的研究,这些研究探索了整合时频掩蔽和波束形成的不同方法。Erdogan 训练了用于单通道语音增强的 RNN,并从中计算出比例掩码,以便生成 MVDR 波束形成器的系数。如图17 所示,首先为每个麦克风估计比例掩码。然后,由一个最大运算符将一个阵列中的多个掩码组合为一个掩码,与直接使用多个没有组合的掩码相比,前者能产生更好的结果。应当指出,他们在 CHiME-3 数据上的 ASR 结果并不令人信服。可以用 DNN 动态地预测波束形成的系数。 Li 等人采用了一个深层网络从阵列采集的含噪语音中预测空间滤波器,以进行自适应波束形成。波形信号被馈送到一个共享的 RNN,后者的输出被馈送到两个单独的 RNNs,以预测两麦克风的波束成形滤波器。
Zhang 等人从一组互补的单通道特征中先训练一个 DNN 以估计 IRM,然后使用最大运算符将阵列中的多个比例掩码组合为单个比例掩码。 比率掩码用于计算 MVDR 波束形成器中噪声的空间协方差矩阵:
Φ n ( t , f ) = 1 ∑ l = t − L t + L ( 1 − R M ( l , f ) ) × ∑ l = t − L t + L ( 1 − R M ( l , f ) ) y ( l , f ) y ( l , f ) H (19) {\bf{\Phi}}_n(t,f)=\frac{1}{\sum_{l=t-L}^{t+L}(1-RM(l,f))} \\ \times \sum_{l=t-L}^{t+L}(1-RM(l,f)){\bf{y}}(l,f){\bf{y}}(l,f)^H\tag{19} Φn(t,f)=∑l=t−Lt+L(1−RM(l,f))1×l=t−L∑t+L(1−RM(l,f))y(l,f)y(l,f)H(19)
其中, R M ( l , f ) RM(l,f) RM(l,f) 表示从 DNN 中估计的第 l l l 帧频点 f f f 的 IRM。噪声协方差矩阵的元素是通过相邻的 2 L + 1 2L + 1 2L+1 个帧来逐帧计算的。他们发现这种估计噪声协方差矩阵的自适应方法要比估计整句话或一个信号段的性能好得多。接着,波束形成器增强的语音信号被馈送到 DNN,以完善 IRM 的估计,对掩码估计和波束形成进行多次迭代以产生最终的输出。他们在 CHiME-3 真实评估数据上的 5.05 WER(误字率)相对于以前的最佳水平有 13.34% 的相对改善。独立地,Xiao 等人也提出了迭代比例掩蔽和波束形成。他们使用 RNN 估计语音掩码和噪声掩码。基于 ASR 损失对掩码进行优化,以便直接受益于 ASR 性能。他们表明,与传统的 MVDR 相比,该方法可显着降低 WER,尽管识别精度不及以前的最佳水平。
其他相关研究包括 Pfeifenberger 等人的研究,他们使用含噪语音连续帧的主要成分之间的余弦距离作为 DNN 估计掩码的特征。Meng 等人使用 RNN 自适应估计波束形成系数。 他们在 CHiME-3 数据上的 ASR 结果优于基线分数,但远未达到最佳分数。 Nakatani 等人集成了 DNN 掩码估计和基于 cGMM 聚类的估计,以进一步提高掩码估计的质量。 他们在 CHiME-3 数据上的结果优于通过 RNN 或 cGMM 生成的掩码所获得的结果。
9. 讨论与总结
文章提供了基于 DNN 的有监督语音分离的综述。 作者总结了有监督分离的关键组成部分,即学习机,训练目标和声学特征,并解释了有代表性的算法,并回顾了大量相关研究。 通过将分离问题表述为监督学习,基于 DNN 的分离在短短几年时间内极大地提高了用于各种语音分离任务(包括单通道语音增强,语音去混响和说话人分离)的最新技术以及阵列语音分离。 随着领域知识与数据驱动框架的紧密集成以及深度学习自身的进步,这种飞速发展将继续下去。
下面讨论与该综述有关的几个概念性问题。
A. Features vs. Learning Machines
如前述,特征对于语音分离是很重要的。但是,深度学习的一个主要吸引点就是它能自主学习出适合特定任务的特征,而不是设计该特征。那么在深度学习时代,特征提取是否有作用?我们相信答案是肯定的。所谓的天下没有免费的午餐定理规定,包括 DNN 在内的任何学习算法都无法在所有任务中实现卓越的性能。Aside from theoretical arguments, feature extraction is a way of imparting knowledge from a problem domain and it stands to reason that it is useful to incorporate domain knowledge this way。例如,CNN 在视觉模式识别中的成功部分归因于在其体系结构中使用共享权重和池化(采样)层,这有助于建立特征位置微小变化的不变表示。
可以为特定的任务学习有用的特征,但是这样做可能在计算上并不高效,尤其是在通过研究已知某些特征具有明显区分性的情况下尤其如此。以基频为例。听觉场景分析的许多研究表明,基频是听觉组织的主要提示,而 CASA 的研究表明,仅基频就可以在语音分离方面大有帮助。也许可以训练 DNN 以 “发现” 谐波作为重要特征,并且最近的一项研究对此有所暗示,但是提取基频作为输入特征似乎是将基频融合到语音分离中最直接的方法。
上面的讨论已经很清楚地表明,以上讨论并不意味着削弱学习机的重要性,而是尽管深度学习具有强大的功能,但仍主张特征提取的重要性。如前所述,CNN 中的卷积层相当于特征提取。尽管对 CNN 权重的训练出的,但使用一个特定的 CNN 体系结构可反映出其使用者的设计选择。
B. Time-Frequency Domain vs. Time Domain
监督语音分离的绝大多数研究都是在时频域进行的,这反映在文章前述部分所讨论的各种训练目标中。可替代地,可以在时域中进行语音分离而无需借助于频率的表示。如前节所指出的,通过时域映射,可以不用考虑幅度和相位问题。端到端的分离代表了使用 CNN 和 GAN 的新兴趋势。
下面按顺序进行一些评论。第一,时域映射是监督分离方法列表中的一个受欢迎的补充,它为相位增强提供了一个独特的视角。第二,同一信号可以在其时域表示和其时频域表示之间来回转换。第三,人类听觉系统在听觉路径的开始即耳蜗具有频率维度。有趣的是,注意到 Licklider 经典的 duplex theory of pitch perception,它假定了两个基频分析过程:与耳蜗中的频率维度相对应的空间过程和与每个频道的时间响应相对应的时间过程。基频估计的计算模型分为三类:频谱,时间和频谱时变方法。从这个意义上讲,具有耳蜗滤波器组的各个响应的耳蜗图是一个双工表示。
C. What’s the Target?
当声学环境中存在多种声源时,在特定时间应将哪种声源视为目标声源?理想掩码的定义假定目标源是已知的,这是语音分离应用中通常见到的情况。对于语音增强,将语音信号视为目标信号,而将非语音信号视为干扰信号。而多说话人分离的情况变得棘手。通常,这是一个听觉注意和意图的问题。这是一个复杂的问题,因为即使在相同的输入场景下,前一时刻所关注的内容与下一时刻所关注的内容也会有所不同,并且所关注的不必是语音信号。但是,仍然存在一些实际的解决方案。例如,定向助听器通过假设目标位于视线方向来解决此问题,即借助于视觉信息。在信号源分离的情况下,还有其他合理的目标定义的替代方法,例如,声音最大的信号源,之前关注的信号源(即跟踪)或最熟悉的信号源(如多说话人情况)。但是,完整的说明需要一个听觉注意的复杂模型。
D. What Does a Solution to the Cocktail Party Problem Look Like?
CASA 将鸡尾酒会问题的解决方案定义为一种在所有听觉条件下均能实现人类分离性能的系统。但是,如何实际比较机器和听众的分离性能呢?也许一个直接的方法是比较各种听觉条件下的 ASR 分数和人类语音可懂度分数。这是一个艰巨的任务,尽管由于深度学习而取得了巨大的进步,但在现实条件下 ASR 的性能仍然不足。 ASR 评估的一个缺点是依赖于 ASR 及其所有特性。
作者提出了一种不同而又具体的措施:鸡尾酒会的解决方案是一种分离系统,该系统可以将所有听觉状况下听力受损的听众的语音可懂度提高到正常听众的水平。它的定义没有 CASA 定义得那么广泛,但它的好处是,它与语音分离研究的主要驱动力紧密相连,即消除了数百万听力受损的听众的语音理解障碍。通过这一定义,上述基于 DNN 的语音增强在有限的条件下满足了这一标准,但显然并非在所有条件下都满足。全面性是人类智能化的标志,也是当今监督语音分离研究所面临的主要挑战。
在文章结束之前,作者指出,在信号处理中使用监督学习和 DNN 不仅限于语音分离,还包括自动语音识别和说话人识别。相关主题包括多基频跟踪,语音活动检测,甚至是作为信号处理中基本任务的 SNR 估计。无论是什么任务,一旦将其表述为由数据驱动的问题,就可以通过使用各种深度学习模型和构建的训练集来保证其进步。还应该提到的是,这些进步是以 DNN 模型中涉及的高计算复杂度为代价的。将信号处理视为学习的一个显著好处是,信号处理可以依靠快速发展的机器学习取得较大的进展。
最后,作者指出,人类解决鸡尾酒会问题的能力似乎与我们广泛暴露于各种嘈杂环境密切相关。研究表明,儿童在噪声中识别语音的能力比成人差,并且音乐家比非音乐家更能感知嘈杂语音,这可能是由于音乐家长期暴露于复音信号中。相对于单语者,双语者在噪声情况下的语音感知方面存在缺陷,尽管两组人在安静情况下都相当熟练。所有这些现象都体现出这样的观点,即广泛的训练(经验)是正常听觉系统对声学干扰具有显著鲁棒性的部分原因。
10. 后记
作者汪徳亮在基于深度学习的语音分离任务上有多年的研究经验,有幸见过汪徳亮本人并听过他的报告。作为语音分离的初学者,窃以为最有效的方法就是阅读一些综述性的文章,以最快的方式对该领域的研究有个全局了解,然后再由面到点深入去做研究,这也是写翻译这篇综述的初衷。
从最开始写这篇文章至此,前前后后总共花了三周时间,刚开始写的时候都是借助翻译软件将译文一个字一个字敲出来,导致精力都集中在单词或句段翻译的准确性上,翻译最后两个小节的时候,直接将翻译软件的译文复制过来,并在此基础上作修改,这样效率快了很多,而且也能将精力集中在内容本身上。由于刚接触这方面,许多术语或者相关内容翻译得不准确,如有发现请读者指出。
原文章是 2017 年发表的,语音分离在过去的这三年时间又取得了不少进展,比如 Luo Yi 提出的时域分离模型 Tasnet 和 Conv-TasNet 等。技术是日益更新的,还需及时跟进最新的研究,多阅读文献,多思考,活到老学到老!