mysql之sql优化知识点干货分享7827字数
文章目录
-
- 前言
- 1.mysql结构简介
- 2.SQL解析过程
- 3.SQL索引
- 4.explain详解
- 5.小试牛刀
- 6.定位慢查询SQL
前言
java学友们,咱们不能一直在做增删改查的功能呀,做技术的实质要技术过硬,现在哪次跳槽不问你做过sql优化不,做过微服务么,虽然我不认为微服务有多厉害,但是眼下就是火呀哈哈,我们先从SQL优化学习吧,提升自己的价值!
此文章基于mysql8.0学习记录;
1.mysql结构简介
1.学习mysql优化,首先要简单了解一下MySql结构,连接层、业务逻辑处理层、存储引擎层、数据存储层

连接层的作用说白了就是提供客户端连接的接口层;
业务层主要完成sql的查询,需要注意的是这一层有sql优化器,也就是MySql如果分析我们写的sql比较烂效率低时,它会智能化帮我们优化sql,所以后续的sql优化时,我们将会看到跟我们预想不一样的执行计划;
数据存储层负MySQL中数据的存储和提取;
MySql主要的两种存储引擎InnoDB、MyISAM,新版本默认的存储引擎是InnoDB;
两种引擎的主要区别:
InnoDB事务优先适合高并发操作;
MyISAM性能优先也就是处理数据速度快;
一般企业都默认InnoDB事务优先;
Mysql查询支持引擎的sql
show engines;

查询当前使用的存储引擎
show VARIABLES like '%storage_engine%
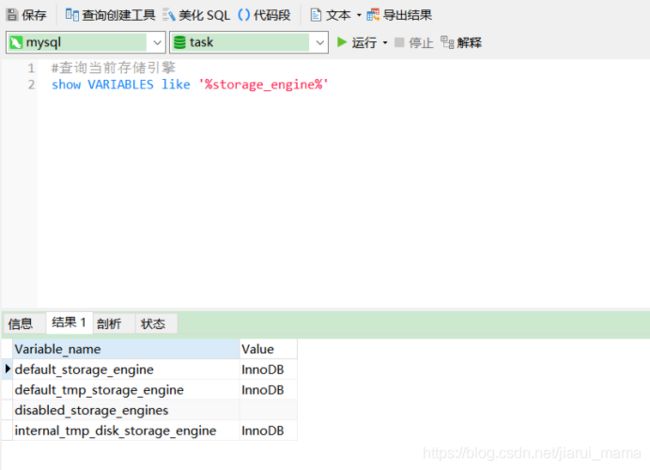
说明:我们可以根据需要修改表的存储引擎,比如我们不想用默认的InnoDB,我们也可以创建表的时候指定其他存储引擎
create table tb(
id int(2),
name varchar(6);
)ENGINE=MyISAM;
2.SQL解析过程
为什么要进行SQL优化?
如果数据库里就一条数据或者几十条,说多点几千条,那么我们怎么查也不会出现sql慢的情况,但是通过执行分析发现效率很低,我们需要优化么,如果这个表以后也是这么多数据,那么我们可以不用管它,但是随着业务数据的增长,我们会发现我擦。。。查询会越来越慢,我们就要抓紧进行SQL优化,不过还是建议既然预知会数据不断增加,就应该提前做sql优化准备。。。
总结一句就是sql查询慢
SQL的编写过程:
select–>from–>join–>on–>where–>group by–>having–>order by–>limit
但是mysql的解析过程是:
from–>on–>join–>where–>group by–>having–>select–>order by–>limit
3.SQL索引
我们常常谈的SQL优化其实说白了就是优化SQL然后较多的使用到索引,索引大白话也就是想字典目录一样,提高查找数据的速度,比如我们想在字典里面查个张三,那么如果没有目录,那么我们是不是就要把字典整个翻一遍,无情。。。好残忍。。,那么有了目录后是不是我们先查张子,在查三字很快就定位到所在的页数了;
mysql中创建索引的关键字index,官方定义:索引就是帮助MySql高效获取数据的数据结构;
MySql默认的数据结构是B数;
假如我们创建一张表,有三个字段ID、NAME、AGE,数据如下:
| ID | NAME | AGE |
|---|---|---|
| 1 | 张三1 | 50 |
| 2 | 李四1 | 60 |
| 3 | 王五1 | 18 |
| 4 | 张三2 | 22 |
| 5 | 李四2 | 33 |
| 6 | 王五2 | 44 |
| 7 | 张三3 | 88 |
然后在age字段上创建一个索引(B树),数据结构可以按照下图理解;
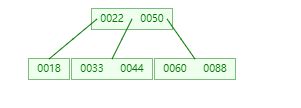
从50开始插入,比50小的放左边,比50大的放右边,这里推荐一个牛逼的国外数据结构网站,大家可以动手插入数据看一下b数结构的创建过程;
国外数据结构教程
通过B树的这种结构,比如我们需要查找60的时候查找两次就可以查到了,过程动画如下:
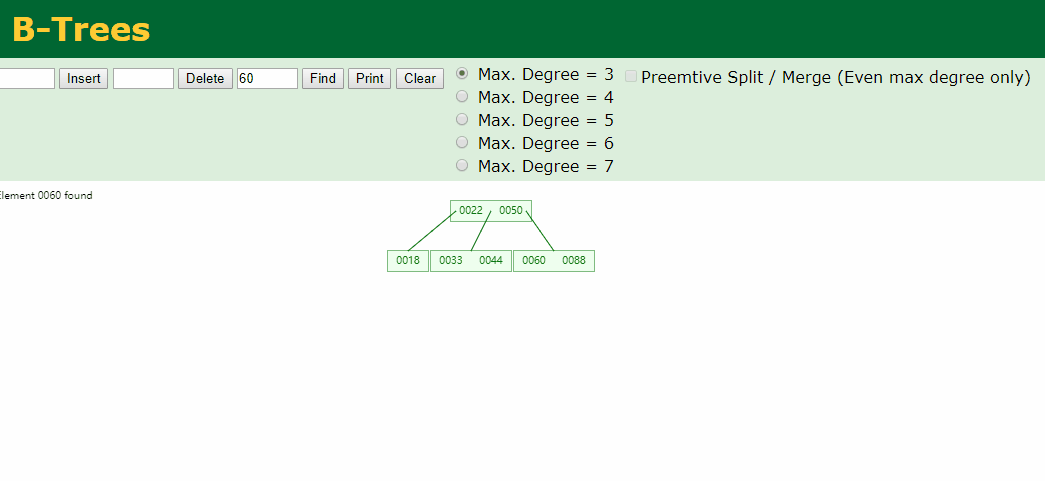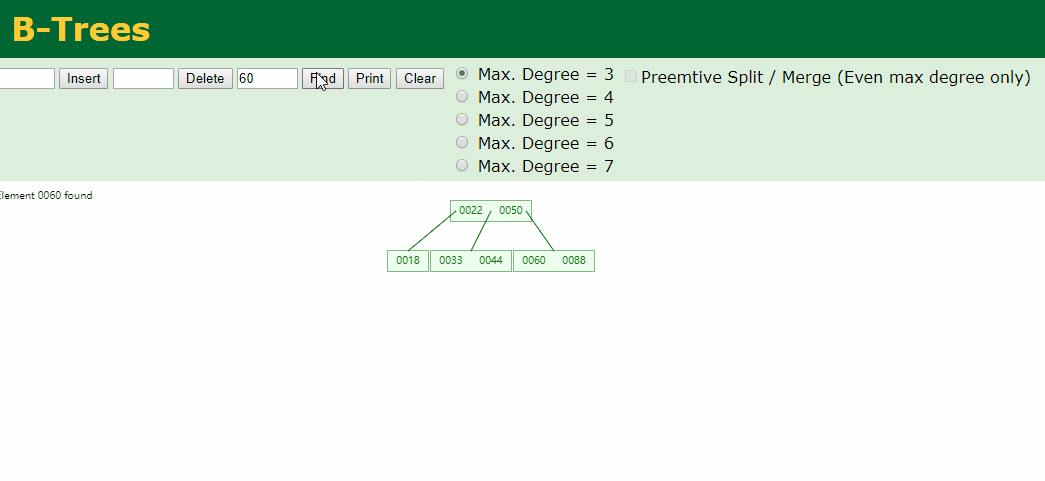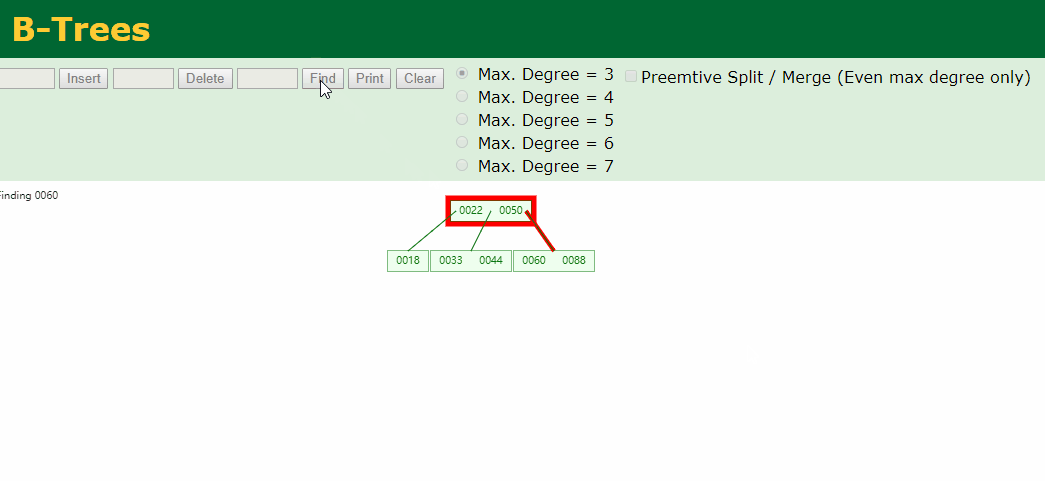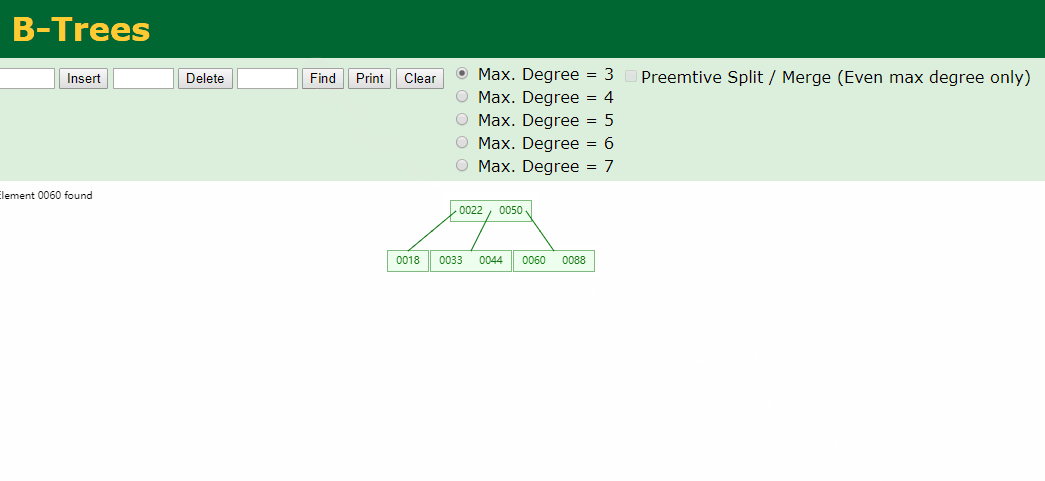
索引的优点:
- 可以像书的目录一样,提高成倍的查询速率(降低IO使用率);
- 比如我们查询语句时需要排序功能,索引已经对数据进行了排序,可以降低CPU使用率;
索引的缺点:
- 索引本身是数据结构,需要占用硬盘空间;
- 不适用少量数据、数据更新频繁、很少使用的字段;
- 索引会提高查询的速度,但是会降低增删改查的效率,因为每次增删改还需要重新维护索引,但我们大部分的操作还是在查询,所以很有必要添加索引;
索引的分类:
单值索引:就是指在某一列上加索引;
唯一索引:主键就是默认的唯一索引,但是主键索引与唯一索引的区别就是,主键不能为null,唯一所以可以为null,非主键也能加唯一索引,但是需要保证数据不能重复,不让唯一索引失效;
复合索引:顾名思义就是在多列上创建了索引;
创建索引sql:
先创建一个测试表people,建表语句如下:
CREATE TABLE `people` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`id_card` varchar(255) DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=uft8
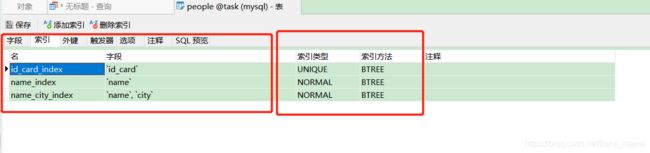
create 索引类型 索引名 on 表名 字段
#在tb表的name字段上添加单值索引
create index name_index on people(name);
#在tb表的id_card字段上添加唯一索引
create unique index id_card_index on people(id_card);
#在tb表的name、city字段上添加复合索引
create index name_city_index on people(name,city);
执行完可以看到创建成功了!
删除索引:
drop index 索引名 on 表名;
#例如删除people表的name_index索引
drop index name_index on people;
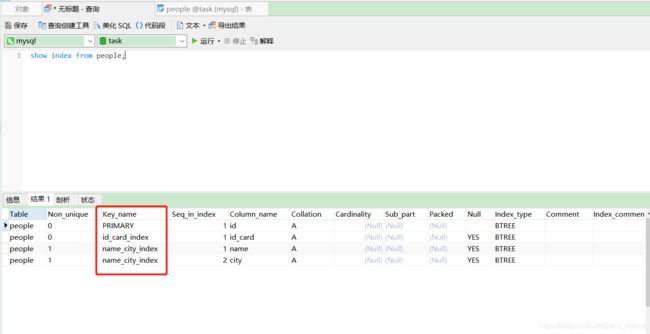
#查询索引
show index from people;
4.explain详解
mysql官网索引优化说明
准备工作:先创建三张表班级表class、老师表teacher、中间表class_teacher,sql建表语句如下:
calss–class_teacher–teacher
班级表和老师表是多对多,需要中间表进行关联,一个老师可以教多个班级,一个班级也可以有多个老师;
CREATE TABLE `class` (
`id` int(11) NOT NULL,
`class_name` varchar(255) DEFAULT NULL,
`teacher_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `teacher` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`class_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `class_teacher` (
`id` int(11) NOT NULL,
`class_id` int(11) DEFAULT NULL,
`teacher_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
#初始化班级信息
INSERT INTO `class`(`id`, `class_name`, `teacher_id`) VALUES (1, '1班', 1);
INSERT INTO `class`(`id`, `class_name`, `teacher_id`) VALUES (2, '1班', 2);
INSERT INTO `class`(`id`, `class_name`, `teacher_id`) VALUES (3, '2班', 1);
INSERT INTO `class`(`id`, `class_name`, `teacher_id`) VALUES (4, '2班', 2);
#
explain select * from class;

explain参数详解
id:降序查看,id相同的从上到下查查看。id可以为null ,当table为( union ,m,n )类型的时候,id为null,这个时候,id的顺序为 m跟n的后面。
select_type:查询类型
table:表名,别名,( union m,n )。
partitions:查询使用到表分区的分区名。
type:表连接的类型,索引类型;重点知识
possible_keys:预测可能用到的索引,这里的索引只是可能会有到,实际不一定会用到;
key:实际使用的索引;
key_len:实际使用的索引的长度,比如我们创建一个复合索引(两个int类型字段),那么我们虽然可以在kye列看到使用到了索引,但是不清楚使用了几个字段的索引,这时候可以看key_len字段是8还是4来确定我们使用了几列索引字段;
ref:表跟表之间的引用;
rows:通过索引查询到的索引数量;
Extra:额外信息;
重点聊聊type类型的知识点:
企业中实际开发中比较常见的
system>const>eq_ref>ref>range>index>all
从左到右效率逐步降低,也就是system、const是理想情况很那达到;实际优化到ref、range算是认可的;
*system/const*:当查询最多匹配一行时,常出现于where条件是=的情况。system是const的一种特殊情况,既表本身只有一行数据的情况。
结果就一条数据
explain select * from test t where t.id=1;

eq_ref:读取本表中和关联表表中的每行组合成的一行。唯一索引,对于每个索引键的查询,返回匹配唯一的数据(有且只有1个,不能多、不能0),下面在数据库实现以下;
先创建一张测试部门表和部门描述表,然后每个表插入三条数据,在部门表的desc_id创建一个唯一索引,注意desc_id列数据不能重复;
#创建部门表
CREATE TABLE `tt_department` (
`id` int(3) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`desc_id` int(3) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `index_department_id` (`desc_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
#创建部门描述表
CREATE TABLE `tt_desc` (
`id` int(3) NOT NULL,
`desc` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
#在desc_id字段创建索引
CREATE UNIQUE INDEX index_desc_id ON tt_department(desc_id);
#插入数据
INSERT INTO `tt_department`(`id`, `name`, `desc_id`) VALUES (1, '技术部', 1);
INSERT INTO `tt_department`(`id`, `name`, `desc_id`) VALUES (2, '销售部', 2);
INSERT INTO `tt_desc`(`id`, `desc`) VALUES (1, 'java研发');
INSERT INTO `tt_desc`(`id`, `desc`) VALUES (2, 'OA系统销售');
执行如下sql能出现eq_ref,可见eq_ref的条件也是比较苛刻的需要主表和引用表数据一一对应,所以实际优化中我们基本在ref和range类型算是比较优的;

ref:相对于eq_ref,主表和引用表不是一对一,则会出现ref,我们在部门表tt_department中新增一条数据;
INSERT INTO `tt_department`(`id`, `name`, `desc_id`) VALUES (3, '客服部', 3);

rang:是指在创建索引的列进行范围查询;
explain select desc_id from tt_department t where t.desc_id <3;

in关键字也是范围查找,但是使用in会概率性的使索引失效,所以建议不要使用in,而是用exists替代;
index:查询索引中的所有数据;

all:查询表中的所有数据,需要全部检索一遍数据,如果数据较多的话自然效率很低,经验之谈一般数据库上100万会有查询变慢的感觉;
注意:这里我查询的name字段没有索引,所以会查询全表,type就是all;

也来聊聊ref列吧
ref列是指索引列引用的是常量就是const,如果非常量即使引用的索引类,如下图a.desc_id=b.id,b.id就是应用列,b.desc_info=‘技术部’,那么ref就是const;
注意:这里的测试sql中desc_id和desc_info字段都是创建的普通索引;

最后在说说Extra
Extra有以下几种常见类型:
1.using filesort:如果出现这说明性能消耗大;

#创建测试表
create table test01(
a1 char(3),
a2 char(3),
a3 char(3),
INDEX idx_a1 (a1),
INDEX idx_a2 (a2),
INDEX idx_a3 (a3)
)
#创建测试语句
explain select * from test01 where a1='' order by a1;
#可以看到执行结果有了Using filesort
explain select * from test01 where a1='' order by a2;



说明:我们按照a1列查询,mysql发现有索引,便通过索引进行查询(排序好的),后面又遇到排序字段是按照a2,所以mysql又需要额外排序一遍,资源消耗大,建议出现后进行优化;
explain select * from test01 where a1=’’ order by a1;#就不会进行额外重新排序,因为a1索引字段已经进行了排序;
建议优化方法:where哪个字段 就order by 哪个字段
复合索引(最佳左前缀)
还有一种情况就是复合索引(最佳左前缀),如果出现跨列也会出现
Using filesort;
举个栗子:
#创建test02表并且同时在a1、a2、a3字段上创建复合索引;
create table test02(
a1 char(3),
a2 char(3),
a3 char(3),
INDEX idx_a1_a2_a3 (a1,a2,a3)
)
#测试出现跨列查询是会不会出现Using filesort
explain select * from test02 where a1='' order by a3;
#测试没有应用最左列Using filesort
explain select * from test02 where a2='' order by a3;
#测试无跨列的语句,效率高,没有出现Using filesort
explain select * from test02 where a1='' order by a2;




建议优化方法:where和order by 按照复合索引
2.using temporary
using temporary性能损耗大,用到了临时表,一般出现在group by语句中;

建议优化方法:查哪个列就用哪个列进行分组

3.using index
出现using index证明索引有效,相比using filesort和using temporary都性能高,官方定义为索引覆盖,也就是通过索引查询到了数据不需要再从原表中查找了,索引肯定比原表中的查询速度快且效率高;

4.using where
简单来说就是需要回原表进行查询,效率不高,下图创建了个复合索引a1,a2,a3字段没有创建索引,我们使用a3字段查询是,就会出现using where;

5.小试牛刀
创建测试表、测试数据
#创建学生表,id、姓名、年龄、性别、年级
create table student(
id int(3),
name varchar(10),
age int(3),
sex varchar(3),
grade int(3)
)
#插入测试数据
insert into student values(1,'张三',7,'01',1);
insert into student values(2,'李四',10,'01',3);
insert into student values(3,'王五',12,'01',5);
需求:查询1年级的学生姓名,年纪为7岁或者8岁,按照年纪排序;
然后我们通过explain执行分析查看执行效率
explain select name from student where age in(7,8) and grade=1 order by age desc;

可以看到type为ALL,Extra为Using where;Using filesort,效率非常低,如果数据量大后会非常慢;
优化
创建复合索引,按照前面提到的SQL执行顺序进行创建age、grade、name
from–>on–>join–>where–>group by–>having–>select–>order by–>limit
create index index_grade_name_age on student(age,grade,name);

可以看到type提高到了range级别,Extra也没有Using filesort;
为什么强调按照SQL执行顺序创建复合索引呢,我们来看实例证明,加入我们通过下面的语句创建复合索引;
create index index_grade_name_age on student(name,grade,age);

事实说明同样的SQL,不按照sql执行顺序创建复合索引,Extra就会出现Using filesort;
小总结:
- 复合索引不要跨列或者无序使用(最佳左前缀),左边索引失效后右边索引全部失效(大概率,随着算法的更新会逐步降低概率);
- 不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效,or查询也会对索引失效;
- 连接查询时,索引建立在数据量小的表字段上,经验小表驱动大表;
- 索引建立在经常查询的字段上;
- 如果主查询的数据集大,则用in,如果子查询的数据集大,则用exist;
sql优化是概率层面的优化,因为mysql会自身根据sql优化器进行优化,所以我们预测的执行分析可能跟最终的优化不一致,但是基本的优化思路我们应该了解。
6.定位慢查询SQL
6.1.Mysql8.0慢查询日志默认是开启的,慢查询日志开启因为会影响性能,所以我们建议开发调优的时候打开,部署上线的时候关闭;
6.2.Mysql默认的慢查询时间阈值是10s;
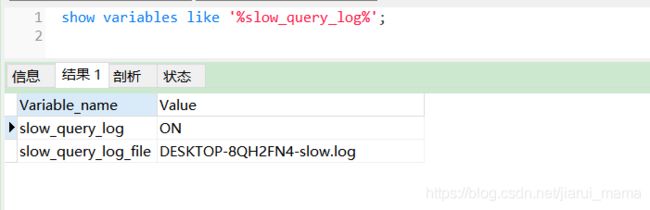
6.3.查询慢查询日志是否开启的SQL
show variables like '%slow_query_log%';
注意:是slow而不是show;
6.4.如果你的版面慢查询日志是关闭的,开始sql如下;
set global slow_query_log = 1;
6.5.慢查询日志查看
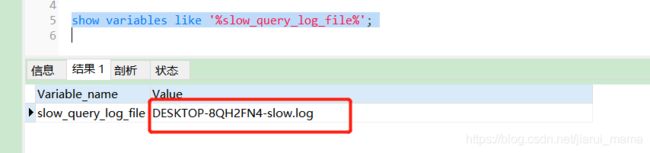
- 查询慢查询日志目录
show variables like '%slow_query_log%';
-
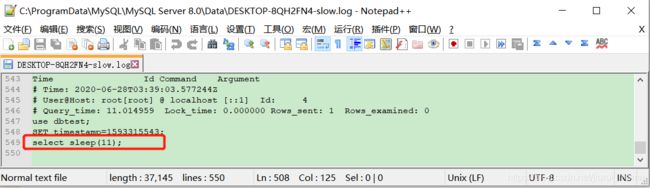
使用测试sql创建一个慢查询
select sleep(11); -
查看日志文件中可以发现已经记录了慢查询的sql;
悄悄告诉你免费赠送重磅互联网架构师教程,提升职场技术水平!
学长准备了本篇文章的pdf版本,关注回复‘mysql优化’即可领取!