大白话mysql之详细分析mysql事务日志
大白话mysql之详细分析mysql事务日志
- redo log与binlog
-
- 位置不同
- 大小不同
- 记录内容不同
- 二阶段更新流程
- 日志落盘
-
- binlog落盘策略
- redolog落盘策略
- Q&A
- 数据落盘
-
- LSN
- 数据落盘时机
-
- 定时刷新
- 系统内存不够用
- 脏页比例过高
- 数据库正常关闭
- redo log checkpoint刷盘
- Q&A
- 奔溃恢复
-
- undo log
- 奔溃恢复流程
-
- redo前滚
- undo回滚
- Q&A
- 写在最后
在后端面试中,mysql是比不可少的一环,其中对事务和日志的考察更是"重灾区", 大部分同学可能都知道mysql通过redolog、binlog和undolog保证了sql的事务性,也可以用于数据库的数据恢复,但再深入一点,如何保证事务性?更新时数据具体是如何写到磁盘的?这两个日志内容不一致怎么办?写日志也要将日志写到磁盘中,为什么会比直接写数据到磁盘效率更高?…, 这些如果一问三不知,面试官(尤其大厂面试)也差不多让你回去等消息了。
redo log与binlog
虽然可能大部分文章都有介绍过,但为了文章的完整性,我们还是从redo log和binlog的区别聊起。
位置不同
首先就是两个日志所处的位置不同了,mysql的整体架构可分为server层和存储引擎层,mysql采用插拔式的存储引擎,常见的存储引擎有myisam、innodb、memory等,在创建表时指定要使用的存储引擎(create table … engine=innodb)。

binlog是存在于server层的日志,也就是无论使用哪种存储引擎,都能使用binlog记录执行语句。而redolog是innodb存储引擎特有的。
大小不同
binlog分多个日志文件记录,单个文件的大小通过max_binlog_size设置,采用追加的方式写入,当binlog 大小超过max_binlog_size设置的大小会创建新的日志文件,然后切换到新文件继续写入。此外,可通过expire_logs_days设置binlog日志保留的天数。
redolog 的大小是固定的,在 mysql 中可以通过修改配置参数 innodb_log_files_in_group 和 innodb_log_file_size 配置日志文件数量和每个日志文件大小,采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。

记录内容不同
binlog记录操作的方法是逻辑性的语句。有statement和row两种记录格式, statement格式记 sql 语句;row 格式会记录更新前和更新后行的内容.
而redolog记录的是数据库中每个页的修改。比如“在某个数据页上做了什么修改”
二阶段更新流程
了解了两种日志的区别后,我们再来通过一条更新语句的执行流程来看看这两个日志分别如何写入的。语句内容为update t set a = a + 1 where id = 1
-
执行器通过innodb引擎获取id = 1的数据,如果数据本身在内存中,会直接返回给执行器;否则,先从磁盘中读入内存,再返回。
-
执行器拿到引擎给的行数据,把这个值加上 1,得到新的一行数据,再调用引擎接口写入这行新数据。
-
引擎将这行新数据更新到内存中。然后将对内存数据页的更新内容记录在 redolog buffer中,此时,buffer中的这条语句状态为prepare。然后告知执行器执行完成了,随时可以提交事务。
-
server层提交事务时,会先将这个操作的日志写入binlog buffer中,再调用引擎的事务提交接口,引擎会将刚写入的redolog记录状态修改为commit。更新完成。
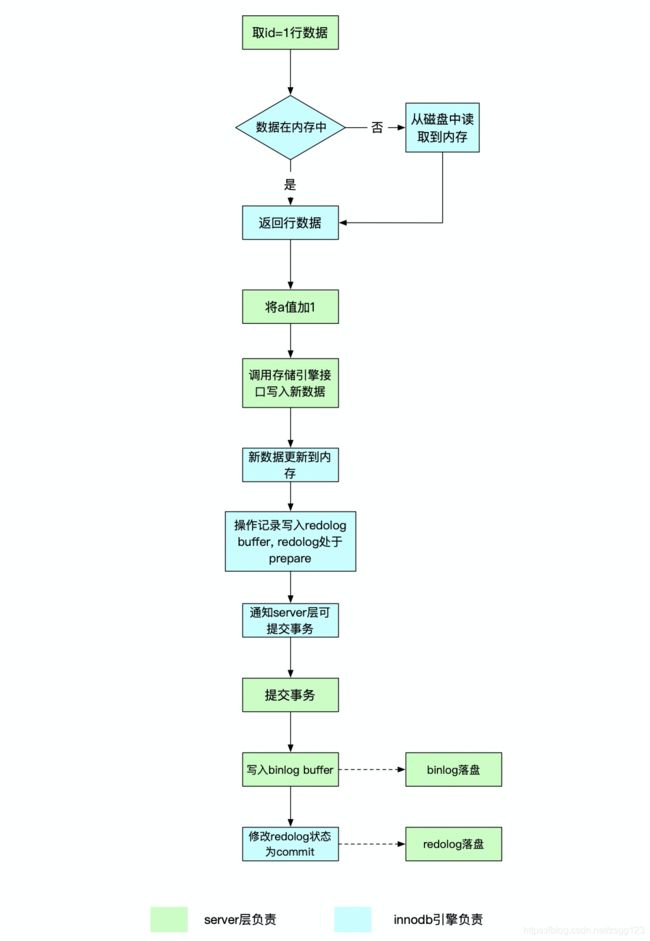
可以发现,一次更新后,不仅数据存在内存中,redolog和binlog也是先写到内存中,之后再根据设定的落盘机制进行日志落盘。
日志落盘
binlog落盘策略
mysql通过sync_binlog参数来控制binlog buffer的日志落盘策略。
sync_binlog = 0, 表示mysql不控制binlog的刷新,使用文件系统的缓存刷新策略,这时性能最好,同时风险也是最大的,一旦系统crash,binlog buffer中的日志数据都将丢失。
sync_binlog = 1 表示每次提交事务都会将buffer中的日志数据同步刷到磁盘中,最安全但由于刷盘频率较高,性能也是最差的。
sync_binlog > 1 表示binlog buffer每写入sync_binlog次事务后,再刷日志数据到磁盘中。
redolog落盘策略
在讲redolog持久化之前,我们先了解下write和fsync两个系统调用,操作系统中,内存被划分为用户空间和内核空间,用户空间存放着应用程序的缓存数据,redolog buffer就存在于用户空间中,要把用户空间的数据持久化到磁盘中,需要先调用write系统调用,把数据先写入内核空间,之后再调用fsync系统调用,将内核空间的数据写入到磁盘中。

mysql通过innodb_flush_log_at_trx_commit参数控制redo log buffer写入磁盘的时机。
innodb_flush_log_at_trx_commit = 0 表示事务提交时,日志继续保存在redolog buffer中,根据innodb_flush_log_at_timeout设置的间隔调用write和fsync将日志持久化到磁盘中,innodb_flush_log_at_timeout默认为1,也就是日志每秒写入到磁盘中。批量写入,io性能较好,但数据丢失风险较大。
innodb_flush_log_at_trx_commit = 1 表示事务提交时,都将调用write和fsync将日志写入磁盘。这种方式不会丢失任何数据,但io性能较差。
innodb_flush_log_at_trx_commit = 2 表示事务提交时,都会调用write将日志写入到内核缓存中,之后每秒调用fsync将日志写入磁盘。这种也比较安全,即使mysql程序奔溃了,os buffer中的日志也不会丢失。当然,如果操作系统也奔溃了,这部分日志也就不见了。

Q&A
Q: 处于prepare状态的redolog会被刷新到磁盘中吗?
A: 会的,例如同一时刻,有a和b两个事务,a处于prepare,b进行commit触发日志刷盘,这时会把a的redo日志也刷到磁盘中。
Q: binlog是否是多余的,可以使用redolog代替binlog吗?
A: 首先,就支持事务方面,binlog确实用处是不大的,在奔溃恢复的时候需要通过binlog确定事务是否该提交也只是避免binlog被应用到备库上了,如果主库直接回滚会导致主备数据不一致。
但binlog的”归档“功能是redolog不具备的。redolog大小固定,采用循环写,较早的日志会被覆盖,无法持久保存,而binlog是不限制大小的,日志追加写入。只要有保留binlog日志,可以恢复数据库任何时刻的状态。
Q: binlog和redolog的几种落盘策略,也是频繁写磁盘,与直接数据写磁盘有什么区别吗?
A: 日志文件是存储在连续的若干个数据页中的,所以在写日志到磁盘时只需要进行一次寻址,属于顺序读写;而写数据时,一次事务可能需要改动的数据可能涉及好几个离散的数据页,写磁盘时需要进行多次「寻道->旋转」的寻址过程,属于随机读写,速度比顺序读写差了好几个数量级。
数据落盘
为了避免频繁写入磁盘导致的性能瓶颈,数据页先在内存中修改,在内存中发生过修改的页称为脏页(因为此时页中的数据与磁盘的不一致,是”脏“的), 改动的数据页需要找时间同步到磁盘中,这个过程称为”刷脏页”。
LSN
在innodb中,每对一个数据页的修改,都会生成一个8字节的序列号lsn来标记版本,lsn的值全局单调递增,随着日志的写入而逐渐增大,lsn存在于数据页和redo log中。
在整个更新过程中,有几个lsn比较值得关注:
-
修改内存数据页中的数据时,会更新内存数据页中的LSN,暂称为data_in_buffer_lsn。
-
向redolog buffer写入日志时,会记录下对应的LSN,暂称为redo_log_in_buffer_lsn。
-
当触发到redolog的几种刷盘策略时,会将redolog buffer中的日志刷入磁盘中,并在该文件记下对应的LSN,暂称为redo_log_on_disk_lsn。
-
数据从内存中刷到磁盘时,会在磁盘上对应的数据页记录下当前的LSN,暂称为data_on_disk_lsn。
-
innodb会在适当的时候将redolog上记录的对应数据页的改动同步到磁盘中,同步进度也是通过lsn标示,称为checkpoint_lsn。(后文会详细介绍)
可以通过show engine innodb status查看各lsn的值。
lsn可以理解为数据库从创建以来产生的 redo 日志量,这个值越大,说明数据库的更新越多,也可以理解为更新的时刻。此外,每个数据页上也有一个 lsn,表示最后被修改时的 lsn,值越大表示越晚被修改。比如,数据页 A 的 lsn 为 100,数据页 B 的 lsn 为 200,checkpoint lsn 为 150,系统 lsn 为 300,表示当前系统已经更新到 300,小于 150 的数据页已经被刷到磁盘上,因此数据页 A 的最新数据一定在磁盘上,而数据页 B 则不一定,有可能还在内存中。
下面我们来讨论下innodb中发生刷脏页的几种时机。
数据落盘时机
定时刷新
innodb的主线程会定时将一定比例的脏页刷新到磁盘中,这个过程是异步的,不会影响到查询/更新等其他操作。
系统内存不够用
innodb会维护一个内存数据页的lru列表,并通过一个单独的page clear线程来保证一定的空闲数据页,当空闲页不足时,会将lru尾部的内存页淘汰掉,如果淘汰的页中有脏页,会先将脏页数据刷新到磁盘中。
脏页比例过高
innodb中,有个innodb_max_dirty_pages_pct参数,用于控制脏页在内存中的占比,当脏页比例超过设置的比例后,会刷新一部分脏页到磁盘中。
mysql> show variables like 'innodb_max_dirty_pages_pct';
+----------------------------+-----------+
| Variable_name | Value |
+----------------------------+-----------+
| innodb_max_dirty_pages_pct | 90.000000 |
+----------------------------+-----------+
数据库正常关闭
参数innodb_fast_shutdown控制着数据库关闭时的落盘策略,当设置为1时,会将所有的日志脏页和数据脏页都刷新到磁盘中;设置为2时,仅保证日志落盘。
redo log checkpoint刷盘
再回顾下更新的流程,更新操作记录到redolog,数据更新到内存中,整个更新操作就算结束了。 如果数据库异常关闭了,下次启动时,我们需要根据redolog将相应的数据页的数据改动恢复回来。
但redolog大小是固定的,采用循环写的模式,写到结尾时,会回到开头循环写日志。 所以,随着更新操作次数的积累,redolog上的记录会被覆盖掉,有些改动也就丢失了。
那不限制redolog的大小可以吗?
可以试想下,redolog达到1TG,数据库数据量有10TG,异常重启时,为了恢复数据页的改动。我们需要读取1T的日志进行恢复。如果全部的数据页都发生了修改,我们还需要将10TG的数据全部载入到内存中。 所以,不限制redolog大小后,会出现另外两个问题:
- 恢复速度较慢;
- 内存无法缓存数据库所有的数据。
redolog 采用checkpoint策略,会定期将redolog上的数据修改逐渐刷新到磁盘中,同步进度用lsn标示,称为checkpoint_lsn。redolog根据checkpoint_lsn可以划分为两部分,小于checkpoint_lsn的日志对应的数据页改动已经刷新到磁盘中,这部分日志可被覆盖重新写入;大于checkpoint_lsn部分日志对应改动还未同步到磁盘。

redolog checkpoint刷盘分为异步刷盘和同步刷盘。
checkpoint_age = redo_lsn - checkpoint_lsn
async_water_mark = 75% * total_redo_log_file_size
sync_water_mark = 90% * total_redo_log_file_size
checkpoint_age < async_water_mark, 表示当前脏页数据较少,不会触发redolog checkpoint刷盘。
async_water_mark < checkpoint_age < sync_water_mark, 会异步将一定量的脏页刷新到磁盘中,使得满足checkpoint_age < async_water_mark。异步刷新不会影响其他更新操作。
checkpoint_age > sync_water_mark, 当redolog容量设置的较小,同时进行大量的更新操作,导致剩余可使用的日志较少,会触发同步刷新,将脏页刷新到磁盘中,直到满足checkpoint_age < async_water_mark,同步刷新会阻塞用户的更新操作。
Q&A
Q: 除了redolog checkpoint,其他几种情况刷脏页会推动checkpoint_lsn吗?
A: 不会。缓冲池会维护一个管理脏页的flush_list, 一个数据页因修改了数据成为脏页后,会添加到flush_list中,脏页在刷新到磁盘中后,会从flush_list中去掉。
flush_list按数据页的最早修改 lsn (oldest_modifcation) 从小到大排序。比如一个干净页变为脏页后,data_in_buffer_lsn=100,在flush_list的位置为1,当数据页再次发生改动时,data_in_buffer_lsn变为120,但在flush_list的位置不变。
进行redo checkpoint时,选择的日志只需要与flush_list上最老的页(拥有flsuh_list上最小的lsn)进行比较即可:
- page_noflush_list != page_noredo,表示该脏页数据已被同步到磁盘中,推进checkpoint_lsn。
- page_noflush_list == page_noredo,将该脏页刷新到磁盘中,推进checkpoint_lsn。
Q: checkpoint信息存在哪?如何存储?
A: checkpoint信息存储在第一个redo日志文件的文件头中。储存采用双份存储,轮流读写的方式。
在第一个redo日志文件的文件头中有两个地方用于存储checkpoint信息,记录时来回读取这两个checkpoint域。假设只有一个 checkpoint 域,当更新checkpoint一半时,服务器也挂了,会导致整个 checkpoint 域不可用。这样数据库将无法做崩溃恢复,从而无法启动。如果有两个 checkpoint 域,那么即使一个写坏了,还可以用另外一个尝试恢复,虽然有可能这个时候日志已经被覆盖,但是至少提高了恢复成功的概率。两个 checkpoint 域轮流写,也能减少磁盘扇区故障带来的影响。
奔溃恢复
用户修改数据并成功提交了事务,此时数据改动在内存中还未落盘,如果这个时候数据库挂了,重启后,需要从日志中将成功提交的事务数据改动恢复后重新写入磁盘,保证数据不丢失,同时还要回滚没有提交的事务。奔溃恢复中,除了需要redolog和binlog日志,还离不开undo日志的支持。
undo log
进行更新操作时,都会产生undo日志:当 delete 一条记录时,会记录一条对应的 insert 日志。当 update 一条记录时,会记录一条对应相反的 update 日志.当insert一条记录时,会记录一条delete日志。
需要回滚事务时,只需要执行对应的undo操作,就可以将数据恢复。此外,通过undo日志,可以保证事务的隔离性。假设隔离级别设为读提交,当未提交的事务A修改了id=1对应的行数据,此时事务B想要读取id=1的数据,可以先拿着最新版本的数据,顺着undo日志找到满足其可见性的记录。
undo日志与普通的数据页一样,对于undo页的修改,需要先写redo日志。也可能会由于lru的规则被淘汰出内存,之后再从磁盘中读取。
奔溃恢复流程
整个奔溃恢复流程可以分为redo前滚和undo回滚两部分。
redo前滚
对于checkpoint_lsn之前的日志,对应改动已经落盘,不需要关心。首先初始化一个hash_table,扫描checkpoint_lsn之后的日志,将同一个数据页的日志分发到hash_table的相同位置,并按日志的lsn从小到大排序。扫描后,遍历整个哈希表,依次应用每个数据页的日志。应用完后,内存中数据页的状态就恢复到了奔溃之前。
undo回滚
接着,初始化undo日志,按操作类型分为undo_insert_list 和 undo_update_list,遍历两个链表,根据日志中记录的事务的状态重建事务状态,TRX_ACTIVE表示需要回滚,TRX_STATE_PREPARED表示可能需要回滚。然后将事务加入到trx_list链表中,之后,遍历trx_list,按照事务的不同状态回滚或提交。对于TRX_ACTIVE状态的事务,利用undo日志直接回滚;对于TRX_STATE_PREPARED状态的事务,根据server层的binlog来决定是否回滚,如果binlog已经写了并且日志是完整的,则提交该事务,否则就回滚。
Q&A
Q: undo日志什么时候会删除?
A: undo按操作类型可分为update/delete/insert, insert操作在事务提交前只对当前事务可见,产生的 Undo 日志可以在事务提交后直接删除。而update/delete操作,其他事务可能需要老版本数据,需要保留到undo操作对应的事务id比数据库当前所有的事务快照都小(此时数据库所有事务对此次改动均可见),才可以删除。
写在最后
喜欢本文的朋友,欢迎关注公众号「会玩code」,专注大白话分享实用技术。