hadoop常见组件及其功能
一、介绍1:
1.Hadoop本质上是:分布式文件系统(HDFS) + 分布式计算框架(Mapreduce) + 调度系统Yarn搭建起来的分布式大数据处理框架。
2.Hive:是一个基于Hadoop的数据仓库,适用于一些高延迟性的应用(离线开发),可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能。Hive可以认为是MapReduce的一个包装,把好写的HQL转换为的MapReduce程序,本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表是纯逻辑表。hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
3.HBase:是一个Hadoop的数据库,一个分布式、可扩展、大数据的存储。hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。HBase可以认为是HDFS的一个包装。他的本质是数据存储,是个NoSql数据库;HBase部署于HDFS之上,并且克服了hdfs在随机读写方面的缺点,提高查询效率。
对HBASE数据结构的简单说明:
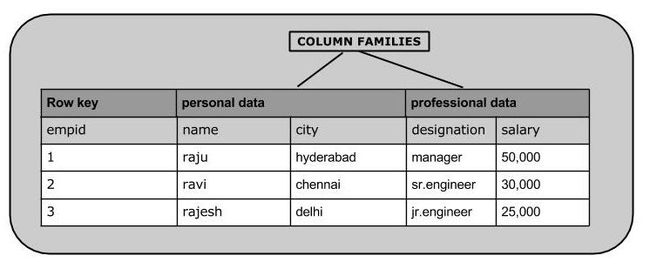
假设HBASE表内容如上,一般将personal data 和 professional data称为column family,而name、city、designation和salary则称为各个column family下面的qualifier。每一个column family都可以认为是一个字典结构,其里面的qualifier则为key,如下:
{
"row1": {
"personal_data": {
"name": "raju",
"city": "hyderabad"
},
"professional_data": {
"designation": "manager",
"salary": 5000
}
},
"row2": {...}
}其中,对于每一行,每个qualifier其实并不是必须存在的,可以缺失。除了上面的column family,qualifier之外,还有timestamp信息,即每个字段数据保留多久(TTL)。
4. Apache Hadoop 项目有两个核心组件,被称为 Hadoop 分布式文件系统 (Hadoop Distributed File System, HDFS) 的文件存储,以及被称为 MapReduce 的编程框架。有一些支持项目充分利用了 HDFS 和 MapReduce。
- HDFS: 如果您希望有 4000 多台电脑处理您的数据,那么最好将您的数据分发给 4000 多台电脑。HDFS 可以帮助您做到这一点。HDFS 有几个可以移动的部件。Datanodes 存储数据,Namenode 跟踪存储的位置。还有其他部件,但这些已经足以使您开始了。
- MapReduce: 这是一个面向 Hadoop 的编程模型。有两个阶段,毫不意外,它们分别被称为 Map 和 Reduce。如果希望给您的朋友留下深刻的印象,那么告诉他们,Map 和 Reduce 阶段之间有一个随机排序。JobTracker 管理您的 MapReduce 作业的 4000 多个组件。TaskTracker 从 JobTracker 接受订单。如果您喜欢 Java,那么用 Java 编写代码。如果您喜欢 SQL 或 Java 以外的其他语言,您的运气仍然不错,您可以使用一个名为 Hadoop Streaming 的实用程序。
- Hadoop Streaming:一个实用程序,在任何语言(C、Perl 和 Python、C++、Bash 等)中支持 MapReduce 代码。示例包括一个 Python 映射程序和一个 AWK 缩减程序。
- Hive 和 Hue: 如果您喜欢 SQL,您会很高兴听到您可以编写 SQL,并使用 Hive 将其转换为一个 MapReduce 作业。不,您不会得到一个完整的 ANSI-SQL 环境,但您的确得到了 4000 个注释和多 PB 级的可扩展性。Hue 为您提供了一个基于浏览器的图形界面,可以完成您的 Hive 工作。hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析
- Pig: 一个执行 MapReduce 编码的更高层次的编程环境。Pig 语言被称为 Pig Latin。您可能会发现其命名约定有点不合常规,但是您会得到令人难以置信的性价比和高可用性。
- Sqoop:在 Hadoop 和您最喜爱的关系数据库之间提供双向数据传输,将数据从数据库导入Hive,将Hive导入数据库等操作。。
- Oozie:管理 Hadoop 工作流。这并不能取代您的调度程序或 BPM 工具,但它在您的 Hadoop 作业中提供 if-then-else 分支和控制。
- HBase:一个超级可扩展的键值存储。它的工作原理非常像持久的散列映射(对于 Python 爱好者,可以认为是词典)。尽管其名称是 HBase,但它并不是一个关系数据库。
- FlumeNG:一个实时的加载程序,用来将数据流式传输到 Hadoop 中。它将数据存储在 HDFS 和 HBase 中。您会希望从 FlumeNG 开始,因为它对原始的水槽有所改进。
- Whirr:面向 Hadoop 的云配置。您可以在短短几分钟内使用一个很短的配置文件启动一个集群。
- Mahout:面向 Hadoop 的机器学习。用于预测分析和其他高级分析。
- Fuse:让 HDFS 系统看起来就像一个普通的文件系统,所以您可以对 HDFS 数据使用 ls、rm、cd 和其他命令。
- Zookeeper:用于管理集群的同步性。您不需要为 Zookeeper 做很多事情,但它在为您努力工作。如果您认为自己需要编写一个使用 Zookeeper 的程序,您要么非常非常聪明,并且可能是 Apache 项目的一个委员会,要么终将会有过得非常糟糕的一天。
- Azkaban对操作进行管理,比如定时脚本执行,有图形化界面,上传job简单,只需要将脚本打成包,可直接上传。
二、准则
1、确认储存规模
有很多的大数据项目其实数据量跟本没这么大,跟本不需要到使用Hadoop这类的大数据软件,所以,第一步应该是先确认数据量有多大,真的MySQL跑的太久再去使用Hadoop就好。
2、确认数据类型
除了结构化数据以外,现在有些大数据项目需要处理的是一些非结构化数据,例如文本、音频、图像、视频之类的,针对这些非结构化的数据,需要事先做处理,再用相对应的软件进行储存。
3、确认数据源
数据源非常重要,首先要先确认数据是否可获取、可用,例如微信聊天记录这种的根本就获取不了,而且会触犯到隐私。有些数据需要先做持久化再导入到数据库内储存,如何获取想要的数据有时候不是直接从数据库里抓这么简单,在获取数据源的时候,也需要考虑数据的质量,否则会提高未来使用的难度。
三、介绍2
Hadoop的核心为HDFS(分布式文件系统)和MapReduce(离线计算框架)。简单来说,HDFS就是将要储存的文件分散在不同的硬盘上,并记录他们的位置,而MapReduce就是将计算任务分配给多个计算单元,下面针对这两个核心再做进一步的说明。
1. HDFS
HDFS已经成为现在大数据的储存标准,他适合储存一次写入,多次读取的数据,并且他有自动检错、快速回复数据的功能,能够避免数据因为硬盘损坏而丢失的危险。
HDFS是由DataNode和NameNode组成的,DataNode负责储存数据,而NameNode负责管理数据,一个NameNode对应多个DataNode,NameNode记录着每个DataNode储存的数据内容,并曝露给上层系统调用,也会根据上层的指令对DataNode进行增、删、复制。
2. MapReduce
MapReduce是将计算任务分配给数据就近的处理节点,进行完运算后再合并导入结果,能很好的去进行大量数据的调取,但是延时较高,不适合处理实时流数据。
MapReduce可以分为Map和Reduce两个处理步骤。首先Map将用户输入的指令解析出一个个的Key/Value,然后再将转化成一组新的KV值,将原本的任务拆解成小的而且是临近数据的,并且确保这些运算任务彼此不会影响。而Reduce则是将这些运算的结果汇总起来,将结果写入。
另外YARN和Zookeepr都是用来管理的,YARN是面对计算资源的管理,而Zookeeper是面对服务器集群的管理。
3. YARN:资源管理框架,用来管理和调度CPU、内存的资源,避免所有的计算资源被某些任务大量占用,有点像是云管理平台可以创造不同的容器和虚拟机,并将这些硬件资源按用户的意愿分配给计算任务。
4. Zookeeper:集用来做群管理,跟微服务里的功能相似,可以在集群里面选出一个leader,并保证集群里面服务器的一致性、可靠性和实时性。
四、组件
1、Hive
Hive是将Hadoop包装成使用简单的软件,用户可以用比较熟悉的SQL语言来调取数据,也就是说,Hive其实就是将Hadoop包装成MySQL。Hive适合使用在对实时性要求不高的结构化数据处理。像是每天、每周用户的登录次数、登录时间统计;每周用户增长比例之类的BI应用。
2、HBase
HBase是用来储存和查询非结构化和半结构化数据的工具,利用row key的方式来访问数据。HBase适合处理大量的非结构化数据,例如图片、音频、视频等,在训练机器学习时,可以快速的透过标签将相对应的数据全部调出。
3、Storm
前面两个都是用来处理非实时的数据,对于某些讲求高实时性(毫秒级)的应用,就需要使用Storm。Storm也是具有容错和分布式计算的特性,架构为master-slave,可横向扩充多节点进行处理,每个节点每秒可以处理上百万条记录。可用在金融领域的风控上。
4、Impala
Impala和Hive的相似度很高,最大的不同是Impala使用了基于MPP的SQL查询,实时性比MapReduce好很多,但是无法像Hive一样可以处理大量的数据。Impala提供了快速轻量查询的功能,方便开发人员快速的查询新产生的数据。