centos7上搭建hadoop3集群
准备工作:
本人是在本地Windows电脑用虚拟机开了3个centos7,模拟集群状态。
所有操作都是在root用户,用其他账号可能会带来问题,建议先在root用户操作,搭建完成没问题了可以用其他账户试试。
一、安装jdk
hadoop3最低需要jdk8,所以需要先在每个节点上安装jdk8,下载-解压-配置环境变量,这里不再多说,只要保证最后java -version能运行出来就行,3台机子都要装好。
二、配置机器名称
我的机子:10.0.2.4是node1(master),10.0.2.15是node2(slave),10.0.2.5是node3(slave)
分别进入3台机器,依次配置,以node1为例:
①
vi /etc/sysconfig/network删掉里面的内容,改成node1
②
vi /etc/hostname删掉里面的内容,改成node1
③
vi /etc/hosts追加内容,注意换行,ip改成自己的机器
10.0.2.4 node1
10.0.2.15 node2
10.0.2.5 node3
以上3步3台机子都操作一次。
三、关闭centos防火墙
①查看防火墙状态
systemctl status firewalld.service②看到 active(running)绿字表示防火墙开着,给它关掉
systemctl stop firewalld.service 关完可以运行第一步查看是否关了。
③上面只是临时关闭防火墙,重启后可能失效,我们应该永久关掉
systemctl disable firewalld.service以上3步每台机子都操作一次。
四、设置ssh免密登录
此步骤只需要在master机子上操作就行,不需要操作3次!!!
ssh-keygen -t rsa敲几下回车,执行完成后继续输入:
ssh-copy-id 10.0.2.4
ssh-copy-id 10.0.2.15
ssh-copy-id 10.0.2.5这里要注意,本机也要这么copy操作一下,所以我copy了3次,不是2次。
然后测试一下:
ssh node1
ssh node2
ssh node1 回到node1(需要密码)
ssh node3
ssh node1 再次回到node1(需要密码)看看是否可以免密登录
安装hadoop3:
一、下载解压
Apache DownloadsHome page of The Apache Software Foundation https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz我是把下载包放到 /opt/hadoop/路径下,你随意。
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz我是把下载包放到 /opt/hadoop/路径下,你随意。
解压,解压完会自动创建一个hadoop-3.3.2目录
cd /opt/hadoop
tar -zxvf hadoop-3.3.2.tar.gz然后
cd /opt/hadoop/hadoop-3.3.2
在这个目录下创建hdfs目录,然后在hdfs目录里分别再创建3个子目录:name,tmp,data,创建目录命令mkdir不会的百度一下,这几个目录留着后面配置用。
二、配置
所有路径请改成自己的
cd /opt/hadoop/hadoop-3.3.2/etc/hadoop①
vi hadoop-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_321 #JAVA_HOME写上自己jdk 的安装路径②
vi yarn-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_321 #JAVA_HOME写上自己jdk 的安装路径③
vi core-site.xml
hadoop.tmp.dir
file:/opt/hadoop/hadoop-3.3.2/hdfs/tmp
A base for other temporary directories.
io.file.buffer.size
131072
fs.defaultFS
hdfs://node1:9000
添加到④
vi hdfs-site.xml
dfs.replication
2
dfs.namenode.name.dir
file:/opt/hadoop/hadoop-3.3.2/hdfs/name
true
dfs.datanode.data.dir
file:/opt/hadoop/hadoop-3.3.2/hdfs/data
true
dfs.namenode.secondary.http-address
node1:9001
dfs.http.address
node1:50070
dfs.webhdfs.enabled
true
dfs.permissions
false
添加到⑤有些博客此处写了先把mapred-site.xml.template改名,这是hadoop2的不用管,hadoop3只有mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
添加到⑥
vi yarn-site.xml
yarn.resourcemanager.address
node1:18040
yarn.resourcemanager.scheduler.address
node1:18030
yarn.resourcemanager.webapp.address
node1:18088
yarn.resourcemanager.resource-tracker.address
node1:18025
yarn.resourcemanager.admin.address
node1:18141
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
添加到⑦配置works文件,hadoop2叫slaves
vi works
把原本的localhost删掉,新增:
node2
node3⑧修改hadoop启动文件,我原来没加这步,但是启动报错了
cd /opt/hadoop/hadoop-3.3.2/sbin
vi start-dfs.sh
在文件头部加上以下:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
⑨把配置好的hadoop发送到2个slave机器
scp -r /opt/hadoop/hadoop-3.3.2/ root@node2:/opt/hadoop/
scp -r /opt/hadoop/hadoop-3.3.2/ root@node3:/opt/hadoop/三、配置hadoop环境变量,3台机子都配置一下
vi /etc/profile
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
四、启动和测试
只在node1操作,第一次启动的话,先格式化一下(如果频繁格式化,可能导致启动失败,需要先stop-all.sh,然后删掉前面手动创建的tmp data name目录,再格式化)
hdfs namenode -format然后启动:
cd /opt/hadoop/hadoop-3.3.2/sbin
./start-all.sh相当于同时运行了start-dfs.sh和start-yarn.sh。
如果控制台没有报错的话,在master机器node1敲命令jps
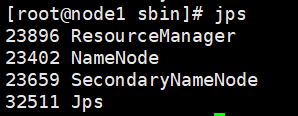
在2个slave机器node2 node3分别敲命令jps

如果master和slave机器都能出现截图的中的服务在运行,则恭喜部署成功。
没问题的话,然后我们可以测试一下:
hadoop jar /opt/hadoop/hadoop-3.3.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar pi 10 10如果运行正常不报错,能出现计算结果则再次证明hadoop集群搭建成功。
追加:
集群运行没有问题,但是我在宿主机往虚拟机的集群写入文件发现怎么都不行。
如果你也是在虚拟机搭的集群,请务必让主机能ping通集群内虚拟机,我原来虚拟机用的NAT网络,虚拟机可以上外网可以ping通宿主机,但是宿主机无法ping通虚拟机。
所以我初次的解决方案是在NAT网络做了一个端口转发:宿主机ip:9000转到hadoop集群master也就是node1机器ip:9000,这样我本地的java demo启动时候连接宿主机ip:9000实际上是转到了node1:9000,貌似是解决了ping不通虚拟机的问题,但是在上传文件的时候一直报错。
第一个错是
java.net.ConnectException: Connection timed out: no further information
接下来又报错
could only be written to 0 of the 1 minReplication nodes. There are 2 datanode(s) running and 2 node
最终结果是上传的文件存在于hadoop集群,但是会发现文件是空的并没有写入。
百度查了一天,试了各种配置,基本上最后断定原因是因为宿主机无法访问虚拟机。
我把写的demo jar包上传到node1启动后发现文件上传成功,更加断定就是ping不通的问题。
解决方案:
无非就是让宿主机可以访问虚拟机就行了。
一、我用的virtualbox虚拟机,所以你可以用桥接网卡实现ping互通,但我是在原先的nat网络基础上又新增了一个Host-Only网卡。

现在敲命令ifconfig 发现有2组ip了
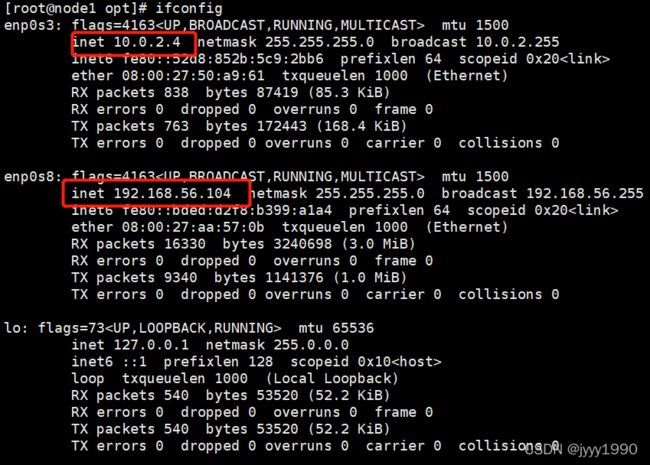
二、把node1,node2,node3的/etc/hosts改成(原来用的是10.0.2.网段的宿主机无法ping通):
192.168.56.104 node1
192.168.56.102 node2
192.168.56.103 node3宿主机的C:\Windows\System32\drivers\etc\hosts也添加上图这三行。
三、在node1,node2,node3的hadoop配置文件hdfs-site.xml加上
dfs.client.use.datanode.hostname
true
然后重新启动hadoop集群。
这时候我们的java 代码直接连 hdfs://node1:9000 就行了