超详细的Hadoop3.1.2架构单机、伪分布式、完全分布式安装和配置
Hadoop是大数据处理主流框架,如果要学习大数据处理与存储,hadoop是必须掌握的一种框架技术。动手安装是最基础的实践,下面介绍一下单机、伪分布式和完全分布式安装与配置、测试过程,供有需要的参考。
目录
(1)软件准备
(2)Centos安装及网络配置?
(3)JDK安装配置
(4)Hadoop单机安装及配置
(5)Hadoop伪分布配置
(6)启动HADOOP及伪分布式测试
(7)Hadoop完全分布式集群搭建及配置
(1)软件准备
包括:VMWare Workstation虚拟机
Centos764位操作系统
JDK1.8.0 64位
Hadoop3.1.2 (可以在http://mirror.bit.edu.cn/apache/hadoop/common/下载)
(2)Centos安装及网络配置
第一步,虚拟机上安装Centos64位操作系统,安装过程比较简单,许多地方都是默认设置,包括网络设置采用nat方式默认设置。

需要提示的是:在安装过程中有设置用户和root密码的地方,建议设置用户时就设置hadoop用户,密码可以自行设置。后面再登录时默认当前用户就是hadoop。这样避免再去使用useradd添加hadoop用户。
第二步. 查看IP地址: 与ubuntu不一样,输入ifconfig会出现错误,这里最简单方法就是使用ping命令,如ping 192.168.58.130,虽然无法ping通,但可以发现在弹出的信息中有from 192.168.58.138字样,这192.168.58.138就是本机的ip地址。

另外在当前命令行使用ip addr也可以将本机IP地址显示出来。
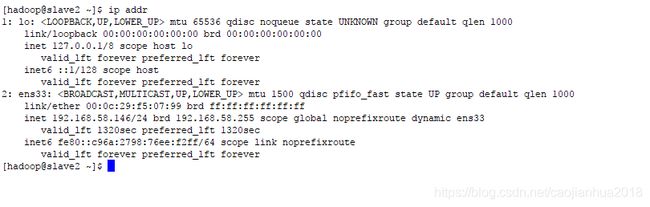
第三步,在centos系统上安装SSH服务,便于上传JDK和HADOOP包。centos最简安装只有命令窗口,没有桌面环境,在使用过程中需要用户比较熟悉linux相关命令。本步骤主要用到如下命令:
1. root账号登录安装SSH : yum install -y openssl openssh-server
yuminstallrsync(rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件)
2. root账户修改配置文件: 用vim打开配置文件/etc/ssh/sshd_config, 找到permitrootlogin将其前面的注释去掉
3. 启动SSH服务: systemctl start sshd.service
设置SSH开机自启动:systemctl enable sshd.service
第四步,修改机器hostname、设置host与ip映射
1. 修改hostname: root账户登录后输入:vi /etc/sysconfig/network, 然后修改如下:

2. 配置host与IP映射:root账户登录后输入: vi /etc/hosts,然后修改如下:

如上将本机IP地址192.168.58.138 映射为master机器名,其他两个节点也类似设置对应的机器名。可以在命令行输入:ping master,如果ping成功,说明机器名修改生效:

第五步,测试SSH,可连接。在windows上安装XSHELL或者SSH SECURE SHELL等软件,测试是否能正常登录连接。
第六步,设置SSH免密登录(这里如果不是完全分布式可以不做)。
为了便于主节点与其他从节点之间的顺畅通信,需要设置免密登录。在主节点机器上当前用户登录,命令行输入:ssh-keygen -t rsa,如下窗口。

由此生成一个私钥和一个公钥,存储在/home/hadoop/.ssh/目录下:
[hadoop@localhost ~]# cd ~/.ssh
[hadoop@localhost .ssh]# ll
total 8
-rw-------. 1 hadoop hadoop1679 Aug 11 18:37 id_rsa
-rw-r–r–. 1 hadoophadoop 408 Aug 11 18:37 id_rsa.pub
然后执行如下命令,cp id_rsa.pub authorized_keys,产生 authorized_keys文件
[hadoop@localhost .ssh]# cp id_rsa.pub authorized_keys
[hadoop@localhost .ssh]# ll
total 12
-rw-r–r–. 1 hadoop hadoop 408 Aug 11 19:34 authorized_keys
-rw-------. 1 hadoophadoop1679 Aug 11 18:37 id_rsa
-rw-r–r–. 1 hadoop hadoop 408 Aug 11 18:37 id_rsa.pub
然后修改权限ssh文件夹及authorized_keys文件:
[hadoop@localhost ~]$ chmod -R 700 .ssh
[hadoop@localhost ~]$ cd .ssh
[hadoop@localhost .ssh]$ chmod 600 authorized_keys
这里的权限700和600功能参考如下:
-rw------- (600) 只有拥有者有读写权限。
-rw-r--r-- (644) 只有拥有者有读写权限;而属组用户和其他用户只有读权限。
-rwx------ (700) 只有拥有者有读、写、执行权限。
-rwxr-xr-x (755) 拥有者有读、写、执行权限;而属组用户和其他用户只有读、执行权限。
-rwx--x--x (711) 拥有者有读、写、执行权限;而属组用户和其他用户只有执行权限。
-rw-rw-rw- (666) 所有用户都有文件读、写权限。
-rwxrwxrwx (777) 所有用户都有读、写、执行权限。
如下进行免密登录测试:ssh hadoop@master,或者直接使用ssh master,不需要输入密码时就表示配置成功。

为了实现几台机器之间互相免密登录,就需要将本机的公钥传递给其他机器,实现命令为:
[hadoop@slave1 .ssh]$ scp d_rsa.pub hadoop@slave2:/home/hadoop/
然后登录进入slave2机器,并在该机器上执行如下命令:
[hadoop@slave2]$cat id_rsa.pub >> .ssh/authorized_keys
即将slave1的公钥追加到本机的authorized_keys上。然后就可以在slave1机器上执行
[hadoop@slave1]$ssh slave2,实现免密登录
第7步,关闭防火墙
centos默认防火墙不是iptables,而是firewall。使用systemctl命令来开启和关闭防火墙。
关闭:[root@master ~]# systemctl stop firewalld
查看状态:[root@master ~]# service firewalld status
Redirecting to /bin/systemctl status firewalld.service
firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Mon 2019-08-12 09:40:50 CST; 27s ago
Docs: man:firewalld(1)
Process: 6574 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 6574 (code=exited, status=0/SUCCESS)
(3)JDK安装配置
JDK安装配置比较简单,将JDK安装包上传到当前目录下,如新建一个java文件夹,然后使用tar命令将压缩包解压,然后配置环境变量即可:
第一步,在当前用户目录下新建java文件夹:[hadoop@localhost ~]$ mkdir java
第二步,在新建的java文件夹中解压jdk包: [hadoop@localhost java]$ tar -xvf jdk-8u11-linux-x64.tar.gz
第三步,查看内容,其中jdk1.8.0_11就是jdk包所在的文件夹
[hadoop@localhost java]$ ll
total 155296
drwxr-xr-x. 8 hadoop hadoop 255 Jun 17 2014 jdk1.8.0_11
-rw-r–r–. 1 hadoop hadoop 159019376 Aug 10 21:13 jdk-8u11-linux-x64.tar.gz
[hadoop@localhost java]$ cd jdk1.8.0_11/
[hadoop@localhost jdk1.8.0_11]$ ll
total 25428
drwxr-xr-x. 2 hadoop hadoop 4096 Jun 17 2014 bin
-r–r–r–. 1 hadoop hadoop 3244 Jun 17 2014 COPYRIGHT
drwxr-xr-x. 4 hadoop hadoop 122 Jun 17 2014 db
drwxr-xr-x. 3 hadoop hadoop 132 Jun 17 2014 include
-rw-r–r–. 1 hadoop hadoop 4673670 Jun 17 2014 javafx-src.zip
drwxr-xr-x. 5 hadoop hadoop 185 Jun 17 2014 jre
drwxr-xr-x. 5 hadoop hadoop 225 Jun 17 2014 lib
-r–r–r–. 1 hadoop hadoop 40 Jun 17 2014 LICENSE
drwxr-xr-x. 4 hadoop hadoop 47 Jun 17 2014 man
-r–r–r–. 1 hadoop hadoop 159 Jun 17 2014 README.html
-rw-r–r–. 1 hadoop hadoop 525 Jun 17 2014 release
-rw-r–r–. 1 hadoop hadoop 21047086 Jun 17 2014 src.zip
-rw-r–r–. 1 hadoop hadoop 110114 Jun 17 2014 THIRDPARTYLICENSEREADME-JAVAFX.txt
-r–r–r–. 1 hadoop hadoop 178445 Jun 17 2014 THIRDPARTYLICENSEREADME.txt
其中的bin文件夹、lib文件夹、jre文件夹都是熟悉的JAVA环境变量指向路径
第四步,配置java环境变量
使用root账户登录,然后命令行输入: vi /etc/profile,在文件的最下端加入java环境变量设置:
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_11
export JRE_HOME= J A V A _ H O M E / j r e e x p o r t C L A S S P A T H = . : JAVA\_HOME/jre export CLASSPATH=.: JAVA_HOME/jreexportCLASSPATH=.:JAVA_HOME/lib: J R E _ H O M E / l i b e x p o r t P A T H = JRE\_HOME/lib export PATH= JRE_HOME/libexportPATH=JAVA_HOME/bin:$PATH
第五步,保存上述文件并使环境变量生效:source /etc/profile.
第六步,**测试java,**在当前用户命令行输入: java -version,可以看到安装成功。

也可以编辑一个HelloWorldjava程序测试:

然后在命令行:
[hadoop@localhost ~]$ javac HelloWorld.java
[hadoop@localhost ~]$ javaHelloWorld
测试打印出程序中的hello结果。
(4)Hadoop单机安装及配置
hadoop安装也比较简单,主要是配置比较麻烦。
将官网上下载的hadoop包上传到当前目录,然后tar解压缩即完成安装。然后麻烦的就是去配置相应的文件,包括core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml、yarn-site.xml等。
第一步,安装hadoop,直接解压就可以。如图:
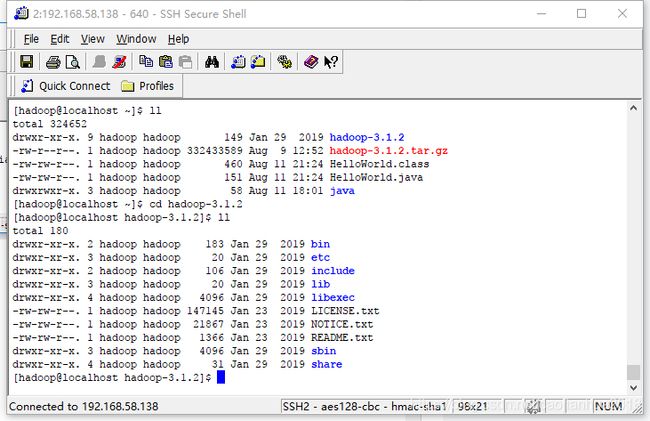
第二步,修改系统环境变量配置文件,将HADOOP的路径加入profile,
即在root账户登录后命令行输入:
vi /etc/profile
然后在之前添加的JAVA环境变量文件下方添加HADOOP相关环境变量:
#JAVA环境变量设置
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_11
export JRE_HOME= J A V A _ H O M E / j r e e x p o r t C L A S S P A T H = . : JAVA\_HOME/jre export CLASSPATH=.: JAVA_HOME/jreexportCLASSPATH=.:JAVA_HOME/lib: J R E _ H O M E / l i b e x p o r t P A T H = JRE\_HOME/lib export PATH= JRE_HOME/libexportPATH=JAVA_HOME/bin:$PATH
#HADOOP环境变量设置
export HADOOP_HOME=/home/hadoop/hadoop-3.1.2
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin
修改完成后保存该文件,然后使用:source /etc/profile使环境设置生效。
第三步,可以测试hadoop是否安装成功。在当前用户目录下命令行输入: hadoop version,如下:
[hadoop@master ~]$ hadoop version
Hadoop 3.1.2
Source code repository https://github.com/apache/hadoop.git -r 1019dde65bcf12e05ef48ac71e84550d589e5d9a
Compiled by sunilg on 2019-01-29T01:39Z
Compiled with protoc 2.5.0
From source with checksum 64b8bdd4ca6e77cce75a93eb09ab2a9
This command was run using /home/hadoop/hadoop-3.1.2/share/hadoop/common/hadoop-common-3.1.2.jar
第四步,单机非分布式测试hadoop。如下图,命令执行后将会列出MapReduce一系列程序类名及其意义。如wordcount程序、pi程序、sort排序程序等。

在当前home目录下新建一个input文件夹,使用vi命令编辑三个文件,
[hadoop@master ~]$ cd input
[hadoop@master input]$ ll
total 12
-rw-rw-r–. 1 hadoop hadoop 12 Aug 12 08:12 f1.txt
-rw-rw-r–. 1 hadoop hadoop 28 Aug 12 08:12 f2.txt
-rw-rw-r–. 1 hadoop hadoop 19 Aug 12 08:12 f3.txt
[hadoop@master input]$ more f1.txt
hello world
[hadoop@master input]$ more f2.txt
hello caojianhua my brother
[hadoop@master input]$ more f3.txt
hello dear brother
可以看到三个文件中分别有几个单词,其中hello重复出现了3次,brother重复出现了2次,其余的出现了1次。接下来我们用hadoop提供的样例调用其wordcount程序来执行单词统计测试。
[hadoop@master ~]$ hadoop jar hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount input output //解释:input为输入的文件夹,将处理input中的三个文件,output为输出结果文件夹。
回车执行后如果出现:2019-08-12 08:17:08,241 INFO mapreduce.Job: map 100% reduce 100%
也就是map任务和reduce任务均完成,说明程序执行正常。
然后可以使用more或者cat命令查看输出结果:
[hadoop@master ~]$ ll
total 324652
drwxr-xr-x. 9 hadoop hadoop 149 Jan 29 2019 hadoop-3.1.2
-rw-r–r–. 1 hadoop hadoop 332433589 Aug 9 12:52 hadoop-3.1.2.tar.gz
-rw-rw-r–. 1 hadoop hadoop 460 Aug 11 21:24 HelloWorld.class
-rw-rw-r–. 1 hadoop hadoop 151 Aug 11 21:24 HelloWorld.java
drwxrwxr-x. 2 hadoop hadoop 48 Aug 12 08:12 input
drwxrwxr-x. 3 hadoop hadoop 58 Aug 11 18:01 java
drwxr-xr-x. 2 hadoop hadoop 88 Aug 12 08:17 output
[hadoop@master ~]$ cd output
[hadoop@master output]$ ll
total 4
-rw-r–r–. 1 hadoop hadoop 61 Aug 12 08:17 part-r-00000
-rw-r–r–. 1 hadoop hadoop 0 Aug 12 08:17 _SUCCESS
[hadoop@master output]$ more part-r-00000
brother 2
caojianhua 1
dear 1
hello 3
my 1
world 1
在output文件夹中使用more命令查看part-r-00000文件,结果显示如上。
(5)Hadoop伪分布配置
上面第4步安装及配置表明本机可以当做hadoop服务器处理程序,也即是单机运行,不是分布式的,map和reduce使用同一进程不同阶段来执行。Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
下面介绍伪分布式配置。主要需要修改配置文件然后启动相应的集群服务。包括如下5个配置文件修改:
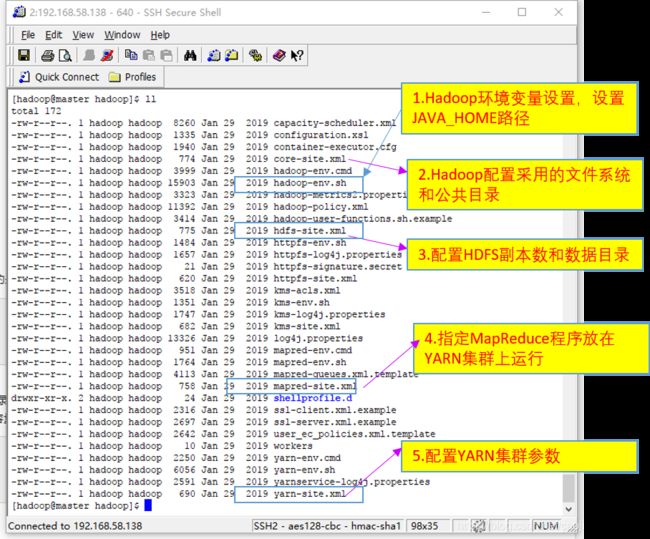
1. 修改hadoop-env.sh,设置JAVA_HOME路径
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_11
2. 修改core-site.xml,配置文件系统和存储目录
<!--设定hadoop运行时产生文件的存储路径 -->
?
? ? ? ?hadoop.tmp.dir
? ? ? ?file:/home/hadoop/hadoop-3.1.2/tmp
? ? ? ?a base for other tempory directories.
?
<!--指定namenode的通信地址,默认8020端口 -->
?
? ? ? ? fs.defaultFS
? ? ? ? hdfs://localhost:9000
? ?
3.修改配置文件hdfs-site.xml:
? ?
? ? ? ?dfs.name.dir
? ? ? ? ?/home/hadoop/hadoop-3.1.2/tmp/dfs/name
? ?
? ? ?
? ? ? ? dfs.data.dir
? ? ? ? ?/home/hadoop/hadoop-3.1.2/tmp/dfs/data
? ? ?
? ? ? ? dfs.replication
? ? ? ? 1
?
4. 修改配置文件 mapred-site.xml
? ?
? ? ? ? mapreduce.framework.name
? ? ? ? yarn
?
? ? yarn.app.mapreduce.am.env
? ? HADOOP_MAPRED_HOME=$HADOOP_HOME
? ? mapreduce.map.env
? ? HADOOP_MAPRED_HOME=$HADOOP_HOME
? ? mapreduce.reduce.env
? ? HADOOP_MAPRED_HOME=$HADOOP_HOME
? ?mapreduce.map.memory.mb
? ?2048
5.修改配置文件yarn-site.xml
?
? ? ? ? yarn.resourcemanager.hostname
? ? ? ? master
? ? ? ? yarn.nodemanager.aux-services
? ? ? ? mapreduce_shuffle
? ? yarn.nodemanager.vmem-check-enabled
? ? false
? ?yarn.nodemanager.vmem-pmem-ratio
? ? 5
配置文件修改并保存后,就可以开始启动Hadoop了。
(6)启动HADOOP及伪分布式测试
第一步,首先进行hadoop的初始化,在命令行输入:
[hadoop@master ~]$hadoop namenode -format
在执行结果最后出现:
2019-08-12 09:14:42,139 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.58.138
************************************************************/
表明初始化成功。
第二步,启动所有进程,在命令行输入:
[hadoop@master ~]$cd /hadoop-3.1.2/sbin
执行sbin目录中的start-all.sh脚本文件:
[hadoop@master sbin]$ ./start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [localhost]
localhost: Warning: Permanently added ‘localhost’ (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [master]
Starting resourcemanager
Starting nodemanagers
第三步,查看进程状态,在命令行输入:jps
[hadoop@master sbin]$ jps
17905 NameNode
18883 Jps
18198 SecondaryNameNode
18438 ResourceManager
18541 NodeManager
18015 DataNode
至此,单机上伪分布式Hadoop环境配置好了,一台机器上配置Hadoop集群:NameNode、DataNode、SecondaryNameNode,YARN集群:ResourceManager、NodeManager。Hadoop集群负责分布式存储和预算,YARN集群负责任务资源管理和调度。
第四步,可以在外部浏览器登录hadoop,由于本处使用的centos最简安装,没有图形界面,因此无法从服务器本机测试,需要外部浏览器测试。首先要确定防火墙关闭,然后hadoop3.0开始采用端口为:9870。因此在外部浏览器地址栏输入:
http://192.168.58.138:9870, 这里192.168.58.138是centos服务器的ip地址,9870为hadoop所用端口。
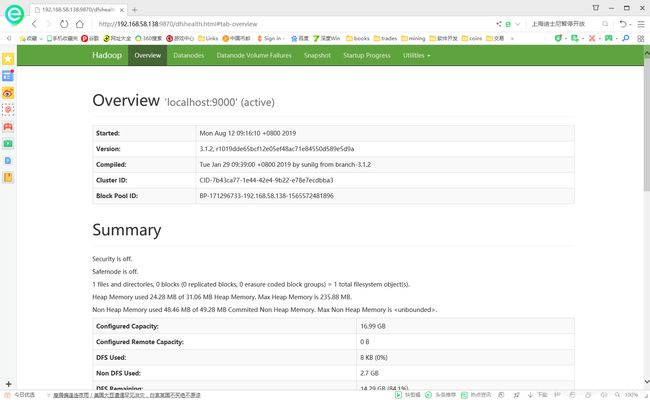
通过上述web界面浏览整个集群的状态。
第五步,实例测试,还是选用系统自带的MapReduce案例,进行wordcount测试。
(1)在hdfs系统里新建一个test文件夹,这里要理解不是真的在本地磁盘上建立文件夹,而是在虚拟的datanode上建立文件夹,实际存储路径在hdfs-site.xml设定了,即:/home/hadoop/hadoop-3.1.2/tmp/dfs/data,可以去这个目录下查看。
[hadoop@master ~]$ hdfs dfs -mkdir /test
新建成功后,可以在web界面上查看browse directory:有新建的test文件夹。

(2)将之前本地单机测试时input文件夹中的三个文件上传到test目录中:
[hadoop@master ~]$ hdfs dfs -put input/* /test

(3)开始测试,如下命令行:
[hadoop@master hadoop-3.1.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /test /output2
2019-08-12 11:45:40,303 INFO mapreduce.Job: Running job: job_1565581394614_0001
2019-08-12 11:46:03,644 INFO mapreduce.Job: Job job_1565581394614_0001 running in uber mode : false
2019-08-12 11:46:03,714 INFO mapreduce.Job: map 0% reduce 0%
2019-08-12 11:47:56,955 INFO mapreduce.Job: map 100% reduce 0%
2019-08-12 11:48:44,873 INFO mapreduce.Job: map 100% reduce 100%
2019-08-12 11:48:48,055 INFO mapreduce.Job: Job job_1565581394614_0001 completed successfully
2019-08-12 11:48:53,548 INFO mapreduce.Job: Counters: 53
当测试结束后,可以在命令行输入:
[hadoop@master hadoop-3.1.2]$ hdfs dfs -cat /output2/*
brother 2
caojianhua 1
dear 1
hello 3
my 1
world 1
结果与单机版hadoop处理是一样的。
也可以在web界面查看
至此,整个单台机器安装Hadoop以及配置Hadoo伪分布式集群就结束了。
总体过程还比较顺利,都是边实践边记录,有几个地方需要注意的是:
(1)本次使用的是Hadoop3.1.2版本,在配置和使用时与hadoop2.0版本稍微有所差别,尤其是mapred-site配置和后面的yarn-site配置,增加了内存分配比例设置。
(2)在使用web访问hadoop时,端口号为9870,而不是之前的50070.如果要查看YARN集群状况,在web浏览器地址栏输入:
http://192.168.58.138:8088/cluster/,端口号为8088.
(7)Hadoop完全分布式集群搭建及配置
前面伪分布式集群配置好后,就可以实现完全分布式集群搭建了。具体做法记录如下:
第一步,在另外两台slave1和slave2机器上安装好JDK和HADOOP。安装过程与master机器一样,解压缩,配置环境变量,在终端测试java和hadoop的版本命令,无误后即安装好了。
第二步,在master机器上配置hadoop分布式环境变量,如上第5小节中5个相关配置文件的修改,这里完全一致。
第三步,在master机器上/home/hadoop/hadoop/etc/hadoop/路径下修改workers,设置如下:
$ vi workers
# 添加如下内容
slave1
slave2
然后保存退出
第四步,修改/home/hadoop/hadoop/sbin/目录下的几个文件,分别在start-dfs.sh和stop-dfs.sh中添加如下内容:
HDFS_DATANODE_USER=hadoop
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=hadoop
HDFS_SECONDARYNAMENODE_USER=hadoop
分别在start-yarn.sh和stop-yarn.sh中添加如下内容:
YARN_RESOURCEMANAGER_USER=hadoop
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=hadoop
第五步,分发hadoop目录至slave1和slave2机器上,就是让三台机器hadoop配置完全一致
上面的操作要在每一个节点上都同步,但是一个一个的去编辑太麻烦了,可以用scp命令,在master节点编辑好之后,直接发送给slave节点
scp -r /home/hadoop/hadoop hadoop@slave1:/home/hadoop
至此,集群各个机器的hadoop配置就完成了。与伪分布式测试一样,此时可以启动在master机器上启动hadoop,具体过程请参考伪分布式启动命令,也就是先使用hdfs namenode -format,然后在sbin目录下使用./start-all.sh执行该shell命令,就可以启动hadoop了。

测试查看一下datanode:
