汉字风格迁移篇---中文字体风格迁移的多任务对抗学习
文章目录
- Abstract
- I. INTRODUCTION
- II. RELATED WORK
- III. METHOD DESCRIPTION
-
- A. Problem F ormulation
- B. Base Model
- C. MTfontGAN Network Achitectures
- D. Objective Function
- E. Training Process
- IV. EXPERIMENTS
-
- A. Experimental Settings
- B. Effectiveness of Multi-Task style encoding
- C. Effects of different losses on network sharing
- D. Comparison with the State of the Art
- E. Influence of training data size to font generation
- V. CONCLUSION
- ACKNOWLEDGMENT
- REFERENCES
Abstract
由于汉字的复杂性和字体之间的显著差异,中文字体之间的抽象风格转换具有挑战性。用于此任务的现有算法通常学习每个字符的参考字体和目标字体之间的映射。随后,此映射用于生成目标字体中不存在的字符。然而,可用于训练的字符不可能覆盖丢失字符的所有细粒度部分,从而导致过拟合问题。结果,生成的目标字体的字符可能会遇到不完整或甚至部首和脏点的问题。为了解决这个问题,本文提出了一种多任务对抗式学习方法,称为MTfontGAN,以生成更生动的汉字。MTfontGAN学习将参考字体同时传输到多个目标字体。对不同任务的编码器进行对齐,以使它们集中于一般样式转换中的字符的重要部分。这种特征级的跨任务交互有效地提高了MTFONGAN的泛化能力。在三个中文字体数据集上评估了MTfontGAN的性能。实验结果表明,MTfontGAN在单任务设置中优于最先进的算法。更重要的是,增加任务数量可以提高所有任务的性能。
索引项样式转换、字体生成、多任务、GAN

【图1.中文字体样式转换示例。黑体字的八个汉字在保持内容一致的情况下,转为金黑体字。(黑体、精黑是两种中文字体)。】
I. INTRODUCTION
汉字代表着中国的文化和文明。他们在交流中起着重要作用。中文字体的数量在过去20年中快速增长,但现有字体仍无法满足数字时代多样化和个性化的需求。人们更渴望建立个性化的字体库。汉字复杂多样。中国官方字符集GB2312由6763个常用汉字组成。总数大于80000。手动创建字体耗时且需要专业技能。因此,有必要提出一种自动生成中文字体库的方法。因此,艺术家只需要设计字体的一小部分就可以生成整个中文字体库,这节省了时间和成本。
该任务的现有方法通常遵循两个方向:基于计算机图形学的方法和基于深度学习的方法。传统的基于计算机图形学的方法[1]-[4]通常通过组合笔划来构建汉字。生成的汉字的结果总是受到笔划提取效果的限制。分解和调整笔划的过程应由工作人员完成。现有的基于深度学习的方法[5]-[8]通常遵循对抗式学习或神经风格转移来生成中文字体,通常作为单个任务过程实现。图1显示了中文字体样式转换的示例。黑体字中的一些字在保持内容的一致性的同时,转为金黑体字。这些方法通常泛化能力较弱,并且由于汉字结构复杂多样,一些稍复杂的笔划无法完全学习
本文旨在解决大规模中文字体库自动生成的挑战性任务。我们提出了一种多任务对抗式学习方法,称为MTfontGAN,用于中文字体风格转换。该模型由一个具有多个子网的生成器组成,即多任务。通过使用编码器部件将参考字符转换为多个高级特征表示。多个任务的编码器层彼此共享信息,以实现更生动的字符生成。MTfontGAN包含多个鉴别器,用于生成多种字体样式。鉴别器用于将生成的字符的每种风格与其相应的基本事实进行区分。因此,同一个MTFonggan训练模型可以生成不同的字体样式结果,如图2所示。与现有算法相比,MTFongGan模型有三个独特的特点,包括:1)它同时完成从参考字体到多个目标字体的样式转换,并在所有任务中获得更好的性能;2) 多任务训练策略启用特征级别任务间的交互,使图像编码器在一般样式转换中集中于字符的重要部分;3)现有算法通常需要在超过20种字体的大型外部数据集上进行预训练,以增强其泛化能力。相比之下,MTfontGAN利用多任务学习范式,不需要这个过程。我们在四种中文字体之间进行了风格转换实验,以证明我们的方法的有效性。

【图2.我们的中文字体传输方法,即MTFongGan的概述。它学习通过实施多任务框架来关注参考字体(即HeiTi)的重要样式特征。这使得U-Net编码器对生成不同字体所需的通用样式特征进行编码。(黑体、精黑、梨树和瑶体是四种中文字体的英文名称)】
总之,本文有两个主要贡献:
1)我们提出了一种多任务对抗式学习方法,该方法仅使用单个生成器和多个鉴别器学习多个中文字体之间的映射,同时生成多个中文字形库。
2) 我们提出了一种有效的架构,使MTfontGAN在统一的框架中实现多任务的稳定训练。
实验结果表明,MTfontGAN可以扩展到三个以上的任务。本文的其余部分组织如下。第二节简要总结了相关工作。第三节描述了多任务对抗式学习方法的细节。第四节描述了四种中文字体之间的风格转换实验。最后,我们在第五节中得出结论。
II. RELATED WORK
自动生成特定风格的中文字体库目前仍然是一个具有挑战性的问题。已经探索了一些自动生成字体的方法。基于CG的方法和基于深度学习的方法是实现这一任务的主要方法。
传统的基于CG的方法[1]–[4],[9]必须从字符中提取笔划,然后将笔划合成目标字符。Tomo等人[10]提出了一种从字符图像中提取笔划的方法,并通过在自动生成的骨架上部署适当的笔划来构造字符。Lian等人[4]提出了一个合成手写字体库的系统。Lin等人[11]通过根据位置和大小信息适当放置汉字,将汉字与提取的成分合成。他们需要跟踪每个笔划,首先从用户的手写体中识别和提取成分。然而,所生成的字符的结果受到笔划提取效果的限制。此外,这种方法只关注汉字的局部表示,而不是整体风格。因此,一些属性,如生成的汉字的大小和位置,需要手动调整。
在过去十年中,深度神经网络[12]被广泛采用,以处理许多领域的许多挑战性任务。基于深度学习的字体生成方法通常分为两种类型:适应样式转换的方法[13]–[16]和图像到图像转换方法[6]、[7]、[17]。Atarsaikhan等人[18]提出了一种使用神经风格转换生成字体的方法。田提出了“重写”1方法,将给定字符从标准字体样式转换为目标样式。然而,这种方法通常计算复杂度高,生成的字符笔划不完整。
生成性对抗网络[19]是最常见的方法。这种方法通常通过生成器和鉴别器之间的对抗博弈优化前向生成模型,然后将参考字体转移到目标字体。方法“pix2pix”[6]使用条件GAN从像素预测图像像素。Jun-Y-an-Zhu等人[17]提出了“BicycleGAN”来学习两个图像域之间的多模态映射,而“CycleGAN”方法[7]解决了使用成对训练数据集的问题。
借助生成性对抗网络,提出了一些基于它们的字体生成方法。论文[20]、[21]提出了英语字符生成方法。学习生成英文字母或数字相对容易,因为英语中只有26个字母,而生成中文字体库是一项艰巨的工作。“zi2zi”项目开发了一个基于条件GAN的模型,该模型是“pix2pix”的扩展,用于生成字符。有时它生成的笔划没有被完全学习。Jie Chang等人[8]提出了一种用于字体样式转换的分层生成对抗网络(HGAN)。Lyu等人[22]提出了一种自动编码器引导的GAN网络(AEGN),可以从标准中文字体图像中合成具有特定风格的书法图像。它需要6000个配对字符作为训练集,这是该方法的一个弱点。Bo Chang等人[5]提出了一种改进的Cyclegan来传输字体样式。它用DensNet块替换ResNet块。Jiang Yue等人提出了一种生成中文字体的方法[23],该方法首先提取字符的笔划。骨架网预测目标角色的骨架流,样式网渲染其样式。
Yue Jiang等人[24]和Yexun Zhang等人[25]使用两个独立的网络分别提取字符的内容和风格。Sun等人[26]提出了一个SA-VAE框架,将汉字的先验知识纳入网络框架。然而,重影和模糊笔划是常见的问题。
为了解决上述生成字符的问题,如不完整笔划、带有噪声的图像等,基于多任务[27]中贡献的灵感,我们提出了在任务之间共享信息的MTfontGAN模型,从而生成更合理的结果。
III. METHOD DESCRIPTION
如上所述,我们的目标是解决自动生成中文字体的问题。为了获得更好的性能,我们专门设计了网络架构和损耗函数。它可以同时将参考字体转换为多种风格的目标字体。它包含多个任务,每个任务都是一种样式转换。MTfontGAN包括一个生成器和多个鉴别器,鉴别器的数量取决于同时生成字体的数量。生成器用于生成具有不同风格的多个字符,鉴别器用于将生成的字符与地面真相区分开来。对不同目标的参考字体的编码施加软对齐。这促进了目标无关字体特征的提取,以提高MTFonggan的泛化能力,并降低过度拟合的风险。我们将在本节中明确讨论该模型。
A. Problem F ormulation
我们将多任务字体样式转换过程描述为同时从参考汉字xrs到多个目标汉字的映射。xrs→ {xts1,xts2,…,xtsn},其中n是目标字体的数量。参考字符图像是包含少量样式信息的标准字体样式的二进制字形图像,例如黑体或邓显字体。
本文介绍了MTfontGAN,它是通过提出的连续多任务学习方法实现的,学习编码共享样式特征以同时生成多个目标字体。MTfontGAN采用编码器Ep(.)提取参考字符的视觉特征。它是一种生成模型,学习从参考字符xirs到输出生成字符ˆxtsp i,xirs的映射→ ˆxtsp i,其中p∈ {1,2,…n},i是第i个输入字符。多任务训练策略支持跨任务的特征级交互。
B. Base Model
条件对抗性网络是一种很有前途的图像到图像翻译方法。首先,使用基本模型从参考字体生成一个样式化的目标字体。我们选择pix2pix[6]模型作为基础模型,因为它在图像到图像转换任务中的成功应用。生成器G被训练以产生目标字符,该目标字符不能通过反向训练的鉴别器D与“真实”图像区分,该鉴别器被训练以尽可能好地检测生成器的“假货”。
C. MTfontGAN Network Achitectures
由基本模型生成的字符通常具有噪声,并且图像模糊。此外,如果我们希望生成另一种字体,我们需要重新训练网络。因此,我们提出了基于基本模型的多任务对抗性学习模型(MTfontGAN),该模型可以同时生成多种类型的更高质量的字体。如图3所示,MTfontGAN模型由一个生成器和n个鉴别器组成,其中n是我们要生成的字体数。它们被用来区分所生成的人物的每种风格及其相应的基本事实。
1) 多任务生成器:生成器包含多个子网,即多个任务。每个任务都有编码器部分和解码器部分。基于“U-Net”的架构用于每个任务生成器[28]。通过使用编码器部分将参考字符转换为多个高级特征表示,并且使用解码器部分使用编码器层计算的特征表示逐步重建多个目标图像。
编码器网络:更重要的是,这些多个任务对应的编码器层相互连接,共享信息,有利于生成更生动的字符。
G的编码器部分由一系列卷积标准漏块组成,用于将输入图像编码为高维特征。编码器层的输入是参考字体。通过编码器层后,参考字符被转换为目标样式的高级特征表示。
对不同任务的编码器进行对齐,以使它们集中于一般样式转换中的字符的重要部分。我们试图使编码器部件的相应层中包含的参数尽可能接近。由于生成器需要生成不同样式的字体,相似的参数增加了训练网络的难度。因此,生成器将具有更强的学习能力来生成更真实的图像。为此,我们在编码器部件的相应层之间添加损耗。因此,任务可以被连接以共享信息,并且具有足够的独立参数来同时学习多种字体样式。这样,发电机具有更强的发电能力,并且网络更健壮。通过同时学习多个任务,MTfontGAN具有更好的泛化能力,并且可以降低过度拟合的风险。
解码器网络:解码器由一系列上采样层组成,其中包括4×4步长2反卷积、实例归一化和Relu,但最后一个除外。仅包含反褶积层的最后一层。输出通过S形函数转换为[0,1]。解码器可以使用由编码器层计算的特征表示逐步地重建具有特定大小和通道的目标图像。
假设每个输入字符及其目标字符具有相同的内容但样式不同,则它们应该具有类似的结构。因此,我们在相应的编码器和解码器的层,以充分利用不同级别的信息。
2) 鉴别器:MTFontGAN由多个独立的鉴别器模块组成。D={D1,D2,…,Dn},其中n是目标字体的数量。它们被用来区分所生成的人物的每种风格及其相应的基本事实。

【图3.网络架构。MTfontGAN同时学习从一个参考字体到多个目标字体样式的映射。生成模块为不同的字体生成任务使用多个U-Net。它对不同通道中的图像编码器使用软共享策略来提取参考字体的共同特征。识别模块采用对抗式学习策略来控制生成的目标字体的质量。】
D. Objective Function
我们模型的目标函数由三项组成:对抗性损失、L1损失和软对齐损失。
其中λ0、λ1和λ2是三个损失的相应权重。
对抗性损失:我们采用标准的对抗性游戏来训练每个任务模型的生成器G和鉴别器D。

多任务模型的对抗性损失是每个任务的总和。

L1损失:为了使生成的字符更清晰并添加更多细节,我们在目标函数中使用L1损失。
其中XIR和XIT相应地表示第i个参考字符和基本真值。多任务模型的L1损失是每个单个任务的总和。

每个单代任务的目标包括两部分:对抗性损失和L1,可以表示为:

其中λ0和λ1是两个损失的相应权重。
软对齐丢失:对不同目标的参考字体编码进行软对齐。由于L2简洁且对异常值更敏感,因此在连接部分,我们使用L2实现。L2可由以下公式表示:
其中n表示任务量,Tp和Tq相应地是第p个和第q个任务。K表示一个编码器部分中的总层。

【图4.中文数据集上的内容参考字体图像的示例。】
我们网络的总体目标包括三部分:对抗性损失损失、L1损失和软对准损失,可以表示为:
其中λ0、λ1和λ2是三个损失的相应权重。
E. Training Process
MTfontGAN模型使用三个损耗项进行优化:对抗性损耗、L1损耗和软对准损耗。
具体的训练策略有以下两个步骤:
1)首先独立训练基础模型:在训练MTfontGAN之前,我们首先训练基础模型,用于我们希望在mtfontgn中同时生成的每种字体样式。基本模型使用两个损失项:LGAN和LL1进行优化。预训练的参数用于初始化MTFONGAN的每个任务。
2) 训练MTfontGAN模型:在基础模型训练好后,我们训练mtfonggan模型。给定图像集{xirs,xits1,xits2,….xitsn},其中i∈ {1,2,…m},m是训练字符数,n是任务数。我们首先加载每个字体的最佳参数集。然后我们训练MTfontGAN模型。我们需要调整LL2损失的重量。在完全训练MTfontGAN网络之后,我们可以使用其余的参考字符来生成整个目标字体库。
IV. EXPERIMENTS
在本节中,我们首先介绍数据集和模型细节。然后,我们分析了MTfontGAN对超参数的敏感性。最后,我们将所提出的方法与基线和最先进的字体样式转换算法进行比较,以验证我们的方法的有效性。
A. Experimental Settings
1) 数据集:为了评估所提出的具有中文字体生成任务的MTfontGAN模型,我们构建了一个包含四种中文字体的数据集:黑体、京黑、梨树和Y aoTi。每个字体有5000个随机选择的汉字。数据分割包括4000张用于训练的图像,800张用于验证,200张用于测试。为了准备输入数据集,我们从网络下载了四种字体的源文件,并将它们转换为256*256图像。最后,将训练集转换为.npy文件,以提高MTfontGAN的性能。
我们采用HeiTi作为输入内容参考字体。HeiTi是印刷中常用字体的一部分。如图4所示,它具有笔划简洁和结构严谨的优点。由于实验MTFongGan包含三个任务,并且它可以同时生成三种字体样式,因此我们选择京黑、梨树和姚体字体作为我们的目标字体。为了提高时间效率,我们随机选择了每种字体样式中的400个字符子集作为我们的训练集。我们在后面的部分给出了整个5000个数据集的实验结果。
2) 实现细节:MTfontGAN的多个任务在每个模型中具有相同的网络层。编码器有8个堆叠的卷积InstanceForm LeakyReLu块。每个卷积层的输出信道分别为64、128、256、512、512、512、512和512。解码器具有7个叠加的反褶积瞬时值ReLu块和最终反褶积层。每个解卷积层的输出信道分别为512、512、512,256、128和64。卷积核的大小为44,步长为22。该方法在Pytorch中实现。在我们的实验中,我们将批量大小设置为16,并将λ0 10、λ1 1、λ2 25设置为0.001的初始速率,并使用Adam优化器端到端训练所提出的模型。
3) 评估指标:对于定量评估,我们在许多图像生成任务中采用了四种常用的指标:
L1:生成的图像和地面真相之间对应像素的L1;
RMSE(均方根误差):生成图像和地面真相之间对应像素的RMSE损失;PDAR(像素不一致率):相同像素与生成图像和地面真相之间像素总数的比率;
IOU(并集上的交集):生成图像和地面真相之间像素交集与像素并集的比率。
公式描述如下(等式(2)中提到L1):
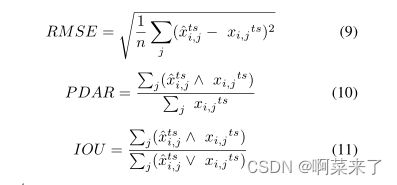
其中ˆxtsi,j是生成字符ˆxtsi的第j个元素,而xi,j ts是基础真值的第j元素,相应地,p∧ q=min(p,q)是模糊and算子,p∨ q=max(p,q)是模糊and算子。

【图5.对三种目标字体同时执行单任务字体传输的基本模型和执行多任务字体传输功能的MTfontGAN之间的字体传输性能比较。】

【图6.使用图像编码器的不同对准策略的MTfontGAN之间的性能比较。】
B. Effectiveness of Multi-Task style encoding
如图5所示,我们将MTfontGAN的结果与基本模型进行了比较。可以看出,基本模型生成的结果确实存在严重的笔划缺失问题,例如字符“肖”(第一行中的第一个字符)的垂直笔划和字符“池”(第一行的第四个字符)左下笔划。并且生成的字符的笔划不完整,例如字符“kou”(第一行第五个字符的左侧)的水平笔划,字符“Qiao”(第一行的第七个字符)的上升笔划。此外,笔划之间存在一些不合理的连接,例如,生成的字符“mang”(第一行中的第三个字符)的三点。而字符“yi”(第一行中的第五个字符)在右下降笔划中具有冗余。此外,基本模型生成的字符具有噪声,例如字符“fo”(第一行中的第九个字符)和字符“fu”(第一行中的第十个字符)。而我们的模型在上述所有方面都表现得更好。它证明了多任务风格编码的重要性。我们的模型不仅可以生成多种字体样式而无需再训练,而且可以生成与目标字体样式一致的更清晰、更完整笔划的图像。
C. Effects of different losses on network sharing
为了找到更好的连接多个任务的方法,我们尝试了不同的方法,如L2、JS损失、Gram损失和L1。如图6所示,我们显示了使用不同损失生成的结果。尽管这些方法生成的字符样式与目标字体一致,但除L2之外的所有方法都有相同的问题。即,生成的字符的笔划不完整。此外,使用L1的方法生成具有噪声的图像。该图表明L2更合适。
D. Comparison with the State of the Art
在本节中,我们将比较我们的模型与其他现有方法的性能。我们将我们的方法的结果与最近提出的其他四种方法进行了比较:zi2zi、BicycleGAN[17]、CycleGAN[7]、DenseNet Cyclegen[5]。我们在同一数据集上为上述每个方法以及我们的方法训练一个模型。为了提高时间效率,我们随机选择了每种字体样式中的400个字符子集作为我们的训练集。
1) 视觉比较:如图7所示,BicycleGAN、CycleGAN和DenseNet Cyclegen生成的字符存在严重的笔划缺失问题。zi2zi方法产生的笔划是不完整的。CycleGAN和DenseNet Cyclegen生成的字符样式与目标字体非常不同。从这些方法的比较中,我们可以看出,我们的MTFonggan模型是生成样式化字体的更好的模型。
2) 定量评估:虽然视觉外观更直观地反映字体生成任务中样式转换结果的质量,但定量评估指标可以提供整个数据集的更高级别性能指示。表1显示了我们的方法与其他四种方法的定量比较。我们的方法可以实现最低的L1、RMSE、PDAR和最高的IOU。这些精确值表明,MTfontGAN模型优于其他方法。

【图7.在黑体到京黑、梨树和瑶体的字体转移方面,MTFONGAN in和现有方法的性能比较。】


【图8.数据集大小的影响。我们比较了分别由400和4000个数据训练的MTfonGAN模型。】
E. Influence of training data size to font generation
在本部分中,我们评估了数据集大小对字体生成的影响。我们对每种字体样式包含4000个字符的数据集进行了额外的实验。除了数据集的大小之外,所有实验条件都与第4节开头提到的相同。如图8所示,可以看出,随着数据集的增加,生成字符的效果得到了显著改善。字符具有更完整的笔划和更少的噪声,并且样式更符合目标字体。因此,数据集越大,结果越好。
V. CONCLUSION
在本文中,我们提出了一个多任务生成对抗网络,称为MTFongGan,用于学习中文字体样式转换的通用字体模式。网络共享策略被设计为最大化跨任务的正向特征级信息传播,并将任务特定的特征保留到它们自己的网络信道中。这使得MTfontGAN能够进行稳定的训练。我们的方法可以一次生成多种字体,无需再培训。实验结果表明,该方法可以自动生成高质量的中文字体库。使用我们的模型生成的角色具有更完整的结构,更接近真实情况。
尽管MTfontGAN取得了成就,但未来的工作可以从两个方向进一步探索。首先,我们将使用各种字体进行更多的实验,以验证MTfontGAN对更多中文字体的鲁棒性。其次,我们将研究它在四个或更多任务上的可伸缩性。
ACKNOWLEDGMENT
我们的工作得到了国家重点研发计划的支持,批准号为2017YFB0203000;部分由新加坡总理办公室国家研究基金会IRC@SG这是一项供资倡议。
REFERENCES
[1] S. Xu, T. Jin, H. Jiang, and F. C. M. Lau, “Automatic generation of
personal chinese handwriting by capturing the characteristics of personal
handwriting,” in Proceedings of the Twenty-First Innovative Applications
of Artificial Intelligence Conference, 2009, pp. 191–196.
[2] B. Zhou, Weihong Wang, and Zhanghui Chen, “Easy generation of
personal chinese handwritten fonts,” in IEEE International Conference
on Multimedia and Expo, 2011, pp. 1–6.
[3] A. Zong and Y . Zhu, “Strokebank: automating personalized chinese
handwriting generation,” in Proceedings of the National Conference On
Artificial Intelligence, 2014, pp. 3024–3029.
[4] Z. Lian, B. Zhao, and J. Xiao, “Automatic generation of large-scale
handwriting fonts via style learning,” in SIGGRAPH Asia, 2016, pp.
1–4.
[5] B. Chang, Q. Zhang, S. Pan, and L. Meng, “Generating handwritten
chinese characters using cyclegan,” in IEEE Winter Conference on
Applications of Computer Vision, 2018, pp. 199–207.
[6] P . Isola, J. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation
with conditional adversarial networks,” in IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), 2017, pp. 5967–5976.
[7] J. Zhu, T. Park, P . Isola, and A. A. Efros, “Unpaired image-to-image
translation using cycle-consistent adversarial networks,” in IEEE Inter-
national Conference on Computer Vision (ICCV), 2017, pp. 2242–2251.
[8] J. Chang, Y . Gu, Y . Zhang, and Y . Wang, “Chinese handwriting imitation
with hierarchical generative adversarial network,” in the British Machine
Vision Conference, 2018, pp. 1–12.
[9] T. Miyazaki, T. Tsuchiya, Y . Sugaya, S. Omachi, M. Iwamura, S. Uchida,
and K. Kise, “Automatic generation of typographic font from small font
subset,” IEEE Computer Graphics and Applications, vol. 40, no. 1, pp.
99–111, Jan 2020.
[10] M. Tomo, T. Tatsunori, S. Y oshihiro, O. Shinichiro, I. Masakazu,
U. Seiichi, and K. Koichi, “Automatic generation of typographic font
from small font subset,” IEEE Computer Graphics and Applications,
vol. 40, no. 1, pp. 99–111, Jan 2020.
[11] J. W. Lin, C. Y . Hong, R. Chang, Y . C. Wang, S. Y . Lin, and
J. M. Ho, “Complete font generation of chinese characters in personal
handwriting style,” in IEEE 34th International Performance Computing
and Communications Conference (IPCCC), 2015, pp. 1–9.
[12] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of
data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507,
2006.
[13] L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using
convolutional neural networks,” in IEEE Conference on Computer Vision
and Pattern Recognition, 2016, pp. 2414–2423.
[14] X. Huang and S. Belongie, “Arbitrary style transfer in real-time with
adaptive instance normalization,” in IEEE International Conference on
Computer Vision, 2017, pp. 1510–1519.
[15] T. Q. Chen and M. W. Schmidt, “Fast patch-based style transfer of ar-
bitrary style,” in the 30th Conference on Neural Information Processing
Systems, 2016, pp. 1–5.
[16] D. Chen, L.Y uan, J. Liao, N.Y u, and G. Hua, “Stylebank: An explicit
representation for neural image style transfer,” in In Pro- ceedings of the
IEEE Conference on Computer Vision and Pattern Recognition, 2017,
pp. 1–10.
[17] J. Zhu, R. Zhang, D. Pathak, T. Darrell, A. A. Efros, O. Wang, and
E. Shechtman, “Toward multimodal image-to-image translation,” in
Conference on Neural Information Processing Systems (NIPS), 2017,
pp. 465–476.
[18] G. Atarsaikhan, B. K. Iwana, A. Narusawa, K. Yanai, and S. Uchida,
“Neural font style transfer,” in 14th IAPR International Conference on
Document Analysis and Recognition, 2017, pp. 51–56.
[19] I. J. Goodfellow, J. Pougetabadie, M. Mirza, B. Xu, D. Wardefarley,
S. Ozair, A. C. Courville, and Y . Bengio, “Generative adversarial nets,”
in Conference on Neural Information Processing Systems, 2014, pp.
2672–2680.
[20] S. Azadi, M. Fisher, V . Kim, ZhaowenWang, E. Shechtman, and
T. Darrell, “Multi-content gan for few-shot font style transfer,” in IEEE
Conference on Computer Vision and Pattern Recognition (CVPR’18),
2018, pp. 7564–7573.
[21] S. U. Hideaki Hayashi, Kohtaro Abe, “Glyphgan: Style-consistent font
generation based on generative adversarial networks,” Knowledge-Based
Systems, vol. 186, 2019.
[22] P . Lyu, X. Bai, C. Yao, Z. Zhu, T. Huang, and W. Liu, “Auto-
encoder guided gan for chinese calligraphy synthesis,” in the 14th IAPR
International Conference on Document Analysis and Recognition, 2017,
pp. 1095–1100.
[23] J. Y ue, L. Zhouhui, T. Yingmin, and X. Jianguo, “Scfont: Structure-
guided chinese font generation via deep stacked networks,” in Proceed-
ings of the AAAI Conference on Artificial Intelligence, 2019, pp. 4015–
4022.
[24] Y . Jiang, Z. Lian, Y . Tang, and J. Xiao, “Dcfont: an end-to-end deep
chinese font generation system,” in SIGGRAPH Asia, 2017, pp. 1–4.
[25] Y . Zhang, Y . Zhang, and W. Cai, “Separating style and content for
generalized style transfer,” in IEEE/CVF Conference on Computer Vision
and Pattern Recognition, 2018, pp. 8447–8455.
[26] D. Sun, T. Ren, C. Li, H. Su, and J. Zhu, “Learning to write stylized
chinese characters by reading a handful of examples,” in the 27th
International Joint Conference on Artificial Intelligence, 2018, pp. 920–
927.
[27] S. Ruder, “An overview of multi-task learning in deep neural
networks,” CoRR, vol. abs/1706.05098, 2017. [Online]. Available:
http://arxiv.org/abs/1706.05098
[28] P . F. O. Ronneberger and T. Brox, “U-net: Convolu- tional networks for
biomedical image segmentation,” in MIC-CAI, 2015, p. 234–241.