Linux基础学习笔记(十三)——文件的格式化处理
文章目录
- 前言
- sed命令
-
- 新增或删除行
- 以行为单位的显示和替换
- 部分数据的查找和替换
- awk命令
- 文本的比对
-
- diff命令
- cmp命令
- patch命令
- 小结
前言
上一篇博客完成了Linux中管道命令的梳理,这篇博客梳理一下文件的格式化输出处理,对应《鸟哥的Linux私房菜》中第11章第4节
sed命令
之前介绍过Linux的基本正则,这里在正则的基础上介绍sed命令,sed命令可将数据进行替换,删除,截取,新增等。
一堆参数,实在看不懂,直接通过实例吧
新增或删除行
删除行数据
#删除第三行到最后一行,$代表最后一行
[root@localhost shell-learn]# nl /etc/passwd | sed '3,$d'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
# 删除第二行到第五行
[root@localhost shell-learn]# nl /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
正常来说,上面的命令是要加上-e,指定交互命令的模式,但是这里没有其实也行,同时,sed后面的内容是要包含在引号中的。
新增行数据
## [n]a在指定的行数后面加上数据
[root@localhost shell-learn]# nl /etc/passwd | sed '2a drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
## [n]i在指定的行数前面加上数据,多行用\n分割即可
[root@localhost shell-learn]# nl /etc/passwd | sed '2i drink tea ......\ndrink beer?'
1 root:x:0:0:root:/root:/bin/bash
drink tea ......
drink beer?
2 bin:x:1:1:bin:/bin:/sbin/nologin
以行为单位的显示和替换
替换
#将2-5行的内容,替代为No 2-5 content
# [n1,n2]c 将n1-n2的数据替换成指定内容
[root@localhost shell-learn]# nl /etc/passwd | sed '2,5c No 2-5 content'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 content
6 sync:x:5:0:sync:/sbin:/bin/sync
显示
# 如果通过head+tail查询11~20行的数据,这样处理稍微复杂点
[root@localhost shell-learn]# nl /etc/passwd | head -n 20 | tail -n 10
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 liman:x:1000:1000:liman:/home/liman:/bin/bash
20 esuser:x:1001:1001::/home/esuser:/bin/bash
# 如果通过sed命令,会简单很多
# 这里指定 -n 表示是静默的方式,不将sed的每一行输出,输出在控制台
[root@localhost shell-learn]# nl /etc/passwd | sed -n '11,20p'
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 liman:x:1000:1000:liman:/home/liman:/bin/bash
20 esuser:x:1001:1001::/home/esuser:/bin/bash
部分数据的查找和替换
sed命令最常用,其实是查找的同时进行替换,sed可以以行为单位进行部分数据的搜寻和替代,这个功能与vi中的类似
基本命令格式如下
sed 's/要被替换的字符串/新字符串/g'
实例
# 查询man_db.conf中 包含 'MAN'的数据行
[root@localhost shell-learn]# cat /etc/man_db.conf | grep 'MAN'
# MANDATORY_MANPATH manpath_element
# MANPATH_MAP path_element manpath_element
# MANDB_MAP global_manpath [relative_catpath]
# every automatically generated MANPATH includes these fields
#MANDATORY_MANPATH /usr/src/pvm3/man
MANDATORY_MANPATH /usr/man
MANDATORY_MANPATH /usr/share/man
MANDATORY_MANPATH /usr/local/share/man
##通过sed命令,替换掉含有注释的数据
[root@localhost shell-learn]# cat /etc/man_db.conf | grep 'MAN' | sed 's/#.*$//g'
MANDATORY_MANPATH /usr/man
MANDATORY_MANPATH /usr/share/man
MANDATORY_MANPATH /usr/local/share/man
## 利用sed命令删除空白行
[root@localhost shell-learn]# cat /etc/man_db.conf | grep 'MAN' | sed 's/#.*$//g' | sed '/^$/d'
MANDATORY_MANPATH /usr/man
MANDATORY_MANPATH /usr/share/man
MANDATORY_MANPATH /usr/local/share/man
MANPATH_MAP /bin /usr/share/man
MANPATH_MAP /usr/bin /usr/share/man
直接通过sed命令修改原文件内容
sed中的-i选项,可以直接去修改指定的文件内容,而不是输出到屏幕
# 将regular_express.txt中每一行的.号替换为!
[root@localhost shell-learn]# sed -i 's/\.$/\!/g' regular_express.txt
# 在regular_express.txt最后一行加入【# this is a test】
[root@localhost shell-learn]# sed -i '$a # this is a test' regular_express.txt
这个功能非常有帮助,比如需要在指定文件的第100行后增加某些文字,如果文件过大,vim操作起来非常不方便,sed命令就能较好的满足这个场景。
awk命令
awk命令是一个比较常用的数据处理工具,sed命令是作用于整行数据的而处理,而awk比较倾向于将一行的数据分成几个数据字段来处理,这种比较适合表格类型存储的数据。通常的运作模式如下
awk '条件类型1{动作1} 条件类型2{动作2}' filename
awk主要处理每一行的字段内的数据,这些字段的默认分隔符为"空格"或"tab键"。
实例
## 查询最近登录的相关信息
[root@localhost shell-learn]# last -n 5
root pts/0 192.168.0.103 Sat Sep 3 10:21 still logged in
reboot system boot 3.10.0-1160.el7. Sat Sep 3 10:19 - 13:00 (02:41)
root pts/1 192.168.0.101 Tue Aug 23 19:31 - down (01:44)
root pts/0 192.168.0.101 Tue Aug 23 19:16 - down (01:59)
reboot system boot 3.10.0-1160.el7. Tue Aug 23 19:11 - 21:16 (02:04)
##awk命令,取出最近5次登录的用户名和ip地址
[root@localhost shell-learn]# last -n 5 | awk '{print $1 "\t" $3}'
root 192.168.0.103
reboot boot
root 192.168.0.101
root 192.168.0.101
reboot boot
wtmp Sun
这里的awk命令没有加条件限制,则awk命令会处理每一行,我们想获取的是第一列和第三列,上述命令中的$1和$3,代表第一列和第三列。$0代表当前行的数据。
整个awk命令的数据处理流程是
1、读入第一行数据,并将第一行的数据一次填入,$0,$1,$2…等变量中
2、依据"条件类型"的限制,判断是否需要进行后面的处理
3、做完所有的数据处理和条件判断
4、循环处理下一行
处了$0,$1,等变量之外,还有其他几个变量
| 变量名称 | 代表意义 |
|---|---|
| NF | 每一行拥有的字段总数 |
| NR | 目前awk所处理的是第几行数据 |
| FS | 目前的分隔符,默认是空格或者tab |
实例
[root@localhost shell-learn]# last -n 5 | awk '{print $1 "\t lines: " NR "\t columns:" NF}'
root lines: 1 columns:10
reboot lines: 2 columns:11
root lines: 3 columns:10
root lines: 4 columns:10
reboot lines: 5 columns:11
lines: 6 columns:0
wtmp lines: 7 columns:7
其他实例
## 指定以":"为分割符,且,如果userid<10则打印第1和第3列
## 但是第一行还是显示的是原始数据,这是因为awk读入第一行数据的时候
## 还是以空格为分隔符的,虽然定义了FS= ":" 但是这个仅能在第二行开始生效
[root@localhost shell-learn]# cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t" $3}'
root:x:0:0:root:/root:/bin/bash
bin 1
daemon 2
## 利用BEGIN这个关键词,可以让指定的分隔符第一行开始生效。
[root@localhost shell-learn]# cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t" $3}'
root 0
bin 1
daemon 2
一个比较复杂的实例
准备一个pay.txt,内容如下
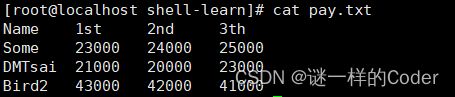
通过如下命令,计算每行的数值总和
[root@localhost shell-learn]# cat pay.txt | awk 'NR==1{printf "%10s,%10s,%10s,%10s,%10s\n",$1,$2,$3,$4,"Total"} NR>=2 {total = $2 + $3 + $4;printf "%10s %10d %10d %10d %10.2f\n",$1,$2,$3,$4,total}'
运行结果为

文本的比对
diff命令

实例
[root@localhost shell-learn]# mkdir -p /tmp/testpw
[root@localhost shell-learn]# cd /tmp/testpw/
[root@localhost testpw]# cp /etc/passwd passwd.old
[root@localhost testpw]# cat /etc/passwd | sed -e '4d' -e '6c no six line' > passwd.new
[root@localhost testpw]# ll
总用量 8
-rw-r--r--. 1 root root 907 9月 3 14:16 passwd.new
-rw-r--r--. 1 root root 964 9月 3 14:16 passwd.old
[root@localhost testpw]# diff passwd.old passwd.new
4d3 #old文件中的第四行被删除自后,基准是new文件的第三行
< adm:x:3:4:adm:/var/adm:/sbin/nologin ##old被删除的内容
6c5 ##old文件的第六行被取代成new文件的第五行
< sync:x:5:0:sync:/sbin:/bin/sync ## old文件中第6行的内容
---
## new文件中的第5行内容
> no six line
可以看到diff文件可以列出文件修改的历史
cmp命令

从文件的字节数来比较文件的差异
patch命令

这个命令主要用来根据diff产生的差异,构建升级包,这个后面源码编译的时候,会进一步总结
小结
基础的文本处理命令完成,后续开始总结shell的一些内容