【MobileViT】
MobileViT v1
轻量级的卷积神经网络在空间上局部建模,如果想要学习全局表征,可以采用基于自注意的视觉Transformer(ViT),但ViTs的参数量比较大,因此作者提出了Mobile V i T。
知识背景
自注意
加权融合,QKV都是输入x乘以对应的W权值矩阵得到,W权值会更新学习;

dk代表K的维度,同样的有dq、dv,这样做对权值矩阵进行一次缩放再送入softmax,因为原输入乘以权值矩阵后,得到的输出矩阵中元素方差很大,会使得softmax的分布变得陡峭影响梯度稳定计算,进行一次缩放后softmax分布能变得平缓,进而在之后的训练过程中保持梯度稳定。
ViT
将输入reshape为一系列patch,然后将其投影到固定的维度空间中得到Xp,然后使用一组Transformer块学习patch间的表示。
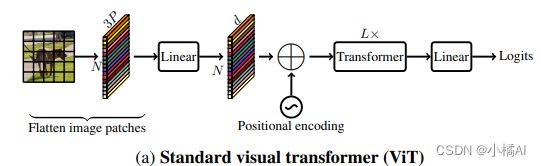
输入x∈R(H* W* C),reshape为一系列patches,Xf∈R(N* PC),P=w* h, 是patch中的像素数,N为patch数,通过Linear缩放维度为Xp∈R(N*d),
缺点:
1、忽略了CNN固有的空间归纳偏置,因此需要更多的参数来学习视觉特征;(这个地方我理解就是把像素点全部混在一起,图像原有的空间位置被忽略了)
2、相比CNN,优化能力更弱,需要大量的数据增强和L2正则化以防止过度拟合;
3、对于密集预测任务,需要昂贵的解码器。
transformer块
InputEmbedding:对输入序列进行语义信息转换,还有位置编码;
vision中transformer:只有编码过程,增加一个可学习类作为最终输入分类的向量,并通过concat方式与原一维图片向量进行拼接;MLP是分类处理部分,利用学习得到的分类向量输入MLP中;(这个学习向量在哪?)

#将x转化成qkv,
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv)
multi-head attention:h就是多头,允许模型在不同子空间里学习到相关的信息。

scaled Dot-Product Attention:QK先做矩阵乘法,再进行维度缩放,mask层只在decoder部分使用,经过softmax后与V相乘;QK相乘可以看作图片块之间的关联性,获得注意力权值后再scale到V
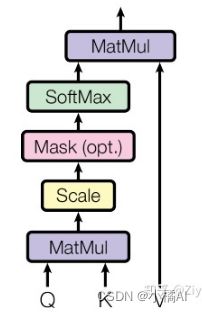
参考【Vision Transformer】超详解+个人心得 - 知乎 (zhihu.com)
基本思想
结合CNN(固有的空间偏置归纳和对数据增强的较低敏感性)和ViT(自适应加权和全局信息处理),有效地将局部和全局信息进行编码,从不同角度学习全局表示。
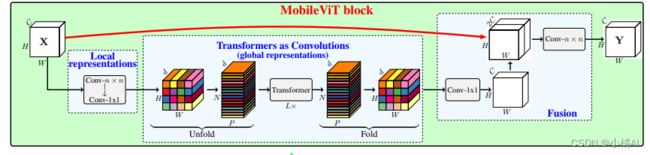
Mobile ViT块
标准卷积涉及三个操作:展开+局部处理+折叠,利用Transformer将卷积中的局部建模替换为全局建模,这使得MobileViT具有CNN和ViT的性质。
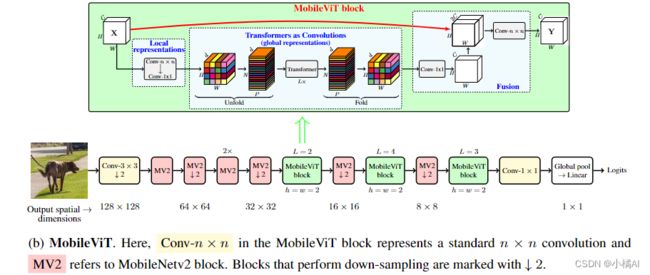
- Mobile ViT块中,n* n卷积后跟一个1* 1卷积,n* n编码局部空间,1* 1卷积体通过学习channel线性组合,将向量投影到高维空间。
- 长尺度非局部的依赖:dilated convolutions,需要谨慎选择dilation rates;或者权值也应用于填0部分而不仅仅是有效区域。(?)
- 保留空间固有偏置:将XL∈R(H* W* d)展开成XU∈R(N* P* d),P=w*h是原来部分数据的长宽,N=HW/P是patch数量,需要注意wh分别需要被WH整除;经过transformer之后得到XG,再被展开成XF(H * W * d).
- 再使用1*1卷积将其投影到低维空间,并与x concatenation,n * n卷积融合x和经过处理的数据。
- XU编码局部信息,XG针对每个局部区域,通过P patches编码全局信息,XG中每个像素可以编码X中所有像素的信息; [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FoMaSGgI-1657509646125)(image-20220706161603435.png)]
- 每个像素能看到其他所有像素,红色像素在transformer中能注意到蓝色像素,同理蓝色也能注意到周边像素,因此红色能注意到所有像素,也就能编码整张图像。(当patch过大时,无法收集到所有的像素信息)
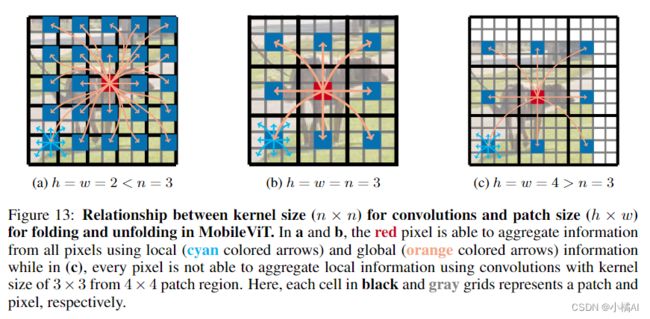
- 轻量级在于中间使用transformer学习全局信息而且没有损失空间偏置,ViT需要更多的算力去学习视觉表示;
多尺度采样训练
给定一系列排序的空间分辨率S = {(H1, W1), ··· , (Hn, Wn)},最大空间分辨率有最小的batch,加快优化更新;在每个GPU第t次迭代中随机抽样一个空间分辨率,然后计算迭代大小;

相较于以前多尺度采样,这次它不需要自己每隔几个iteration微调得到新的空间分辨率,并且改变batch提高了训练速度;使用多GPU进行训练(我猜不同空间分辨率在不同的GPU上运行)
这个可以提高网络的泛化能力,减少训练和验证之间差距;并且适用于其他网络训练;
实验过程
度量没有使用FLOPs是因为内存访问、并行度、平台特性的问题,导致FLOP无法在移动设备上实现低延迟(仅在Image-1K上对比)。
1、数据集Image-1K,对比ViTs,准确率上升,参数量降低
数据集:Image-1k;300epochs on 8 NVIDIA;batch size=1024
损失函数:cross-entropy loss;学习率:从0.0002到0.002在最初3k iteration,然后用余弦退火到0.0002;
激活函数:Swish;正则化:L2;
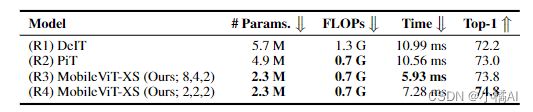
2、主干网络能力对比
在物体检测和语义分割任务上,用MobileViT做骨干网络,和MobileNet对比;
物体检测:用SSD做后续特征处理,并用深度分离卷积替代了SSD中的标准卷积;在MS-COCO上做的训练;
语义分割:用DeepLabv3做后续特征处理,在PASCAL VOC 2012上做的训练;参数量降低,准确率也有部分降低;

3、在移动设备上对比
运行速度比MobileNetv2要慢
理由:GPU上有专用的CUDA核做transformer,但这些在ViTs中被用来out-of-the-box来提高其在GPU上的可伸缩性核效率;CNN受益于几个设备级别的优化,包括卷积层的批量归一化融合;

MobileViT v2
主要思想
降低多头自注意时间复杂度有两个方向(tokens就是patches):
1、在自注意层引入sparsity,在输入序列中每个token引入tokens一个子集;使用预定义模式限制token输入(不接受所有的tokens而是接受子集,缺点训练样本少性能下降很快)或者使用局部敏感的hash分组tokens(大型序列上才能看到提升);
2、通过低秩矩阵估计得到近似自注意矩阵,由线性连接将自注意操作分解成多个更小的自注意操作(Linformer使用batch-wise矩阵乘法);
主要是为了解决v1版本的高延迟问题,本论文用分离自注意代替多头自注意提高效率,使用element-wise操作替代batch-wise矩阵乘法;
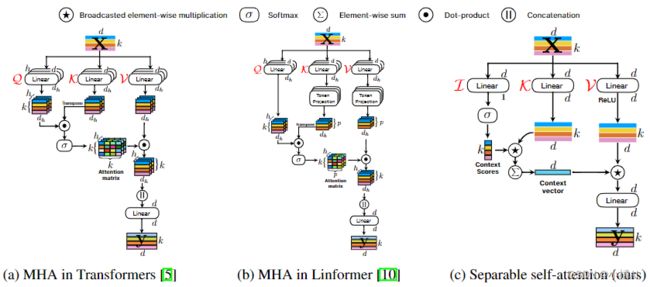
MHA
dh=d/h,最后输出k个d维tokens,这个输出会在做一次矩阵乘法变成k*d维向量,作为最后的输出;

Separable self-attention
计算latent token L的上下文得分,这些分数重新加权输入token并生成上下文向量,这个向量编码了全局信息。

分支L用矩阵(b)L将x中每个d维向量映射到标量,计算(b)L与x的距离得到一个k维向量,这个k维向量softmax后就是上下文得分cs;
分支K直接矩阵相乘得到输出Xk,与cs相乘并相加k层,得到cv,cv类似于MHA的a矩阵,也编码了所有x的输入;

分支V线性映射并由ReLU激活得到Xv,然后与cv element-wise相乘,最后通过线性层得到最后的输出。

实验过程
时间复杂度不能解释所有操作的成本,因此使用了不同k在CPU上运行;只针对Transformer这个块,分离MHA确实降低了延迟,准确率略有下降。
在ImageNet-21k-P上预训练,在ImageNet-1K上微调,预训练初始化使用ImageNet-1k的权重提高收敛速度;
1、在手机上,MobileViT比MobileFormer速度要快,但是在GPU上两者一样。
2、ConvNexT速度比MobileViTv2快,因为手机对CNN模型有优化;
3、分辨率上升时,ConvNexT和MobileViTv2之间的差距减小了,表明ViT模型有更好的缩放性能;
MobileViT v2代码讲解
网络架构

mobilevit block
将X输入3*3卷积:
conv_3x3_in = ConvLayer(
opts=opts,
in_channels=in_channels,
out_channels=in_channels,
kernel_size=conv_ksize,
stride=1,
use_norm=True,
use_act=True,
dilation=dilation, #长尺度非局部的依赖
)
再用1*1卷积做高维映射:
conv_1x1_in = ConvLayer(
opts=opts,
in_channels=in_channels,
out_channels=transformer_dim, #得到[B,C,H,W]形状向量
kernel_size=1,
stride=1,
use_norm=False,
use_act=False,
)
Unfold过程:
def unfolding(self, feature_map: Tensor) -> Tuple[Tensor, Dict]:
patch_w, patch_h = self.patch_w, self.patch_h
patch_area = int(patch_w * patch_h)
batch_size, in_channels, orig_h, orig_w = feature_map.shape
new_h = int(math.ceil(orig_h / self.patch_h) * self.patch_h)
new_w = int(math.ceil(orig_w / self.patch_w) * self.patch_w)
#math.ceil返回ori/patch最小整数值
interpolate = False #如果不能整除H或W,transformer中需要有特殊处理
if new_w != orig_w or new_h != orig_h:
# Note: Padding can be done, but then it needs to be handled in attention function.
feature_map = F.interpolate(
feature_map, size=(new_h, new_w), mode="bilinear", align_corners=False
)
interpolate = True
# number of patches along width and height
num_patch_w = new_w // patch_w # n_w
num_patch_h = new_h // patch_h # n_h
num_patches = num_patch_h * num_patch_w # N
# [B, C, H, W] --> [B * C * n_h, p_h, n_w, p_w] 先分成魔方那个形状
reshaped_fm = feature_map.reshape(
batch_size * in_channels * num_patch_h, patch_h, num_patch_w, patch_w
)
# [B * C * n_h, p_h, n_w, p_w] --> [B * C * n_h, n_w, p_h, p_w]
#改变顺序是便于后续压扁
transposed_fm = reshaped_fm.transpose(1, 2)
# [B * C * n_h, n_w, p_h, p_w] --> [B, C, N, P] where P = p_h * p_w and N = n_h * n_w
reshaped_fm = transposed_fm.reshape(
batch_size, in_channels, num_patches, patch_area
)
# [B, C, N, P] --> [B, P, N, C]
transposed_fm = reshaped_fm.transpose(1, 3)
# [B, P, N, C] --> [BP, N, C]
patches = transposed_fm.reshape(batch_size * patch_area, num_patches, -1)
info_dict = {
"orig_size": (orig_h, orig_w),
"batch_size": batch_size,
"interpolate": interpolate,
"total_patches": num_patches,
"num_patches_w": num_patch_w,
"num_patches_h": num_patch_h,
}
return patches, info_dict
transformer过后,Flod过程(就是unflod逆过程):
def folding(self, patches: Tensor, info_dict: Dict) -> Tensor:
n_dim = patches.dim()
assert n_dim == 3, "Tensor should be of shape BPxNxC. Got: {}".format(
patches.shape
)
# [BP, N, C] --> [B, P, N, C]
patches = patches.contiguous().view(
info_dict["batch_size"], self.patch_area, info_dict["total_patches"], -1
)
batch_size, pixels, num_patches, channels = patches.size()
num_patch_h = info_dict["num_patches_h"]
num_patch_w = info_dict["num_patches_w"]
# [B, P, N, C] --> [B, C, N, P]
patches = patches.transpose(1, 3)
# [B, C, N, P] --> [B*C*n_h, n_w, p_h, p_w]
feature_map = patches.reshape(
batch_size * channels * num_patch_h, num_patch_w, self.patch_h, self.patch_w
)
# [B*C*n_h, n_w, p_h, p_w] --> [B*C*n_h, p_h, n_w, p_w]
feature_map = feature_map.transpose(1, 2)
# [B*C*n_h, p_h, n_w, p_w] --> [B, C, H, W]
feature_map = feature_map.reshape(
batch_size, channels, num_patch_h * self.patch_h, num_patch_w * self.patch_w
)
if info_dict["interpolate"]:
feature_map = F.interpolate(
feature_map,
size=info_dict["orig_size"],
mode="bilinear",
align_corners=False,
)
return feature_map
transformer块
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MVWXyEYh-1657509646133)(image-20220708161840912.png)]
qkv = self.qkv_proj(x) #卷积映射成1+2*(embed_dim) channels
# Project x into query, key and value
# Query --> [B, 1, P, N],x中每个d维向量映射到标量
# value, key --> [B, d, P, N]
query, key, value = torch.split(
qkv, split_size_or_sections=[1, self.embed_dim, self.embed_dim], dim=1
)
# apply softmax along N dimension
context_scores = F.softmax(query, dim=-1)
# Uncomment below line to visualize context scores
# self.visualize_context_scores(context_scores=context_scores)
#tensor -> [tensor, float, float]
context_scores = self.attn_dropout(context_scores)
# Compute context vector
# [B, d, P, N] x [B, 1, P, N] -> [B, d, P, N]
#其实这里我们可以看到kv两个分支并没有一个线性映射过程
context_vector = key * context_scores
# [B, d, P, N] --> [B, d, P, 1]
# 编码全局信息
context_vector = torch.sum(context_vector, dim=-1, keepdim=True)
# combine context vector with values
# [B, d, P, N] * [B, d, P, 1] --> [B, d, P, N]
out = F.relu(value) * context_vector.expand_as(value)
out = self.out_proj(out)
return out
mobilenetv2块
block = nn.Sequential()
if expand_ratio != 1:
block.add_module(
name="exp_1x1",
module=ConvLayer(
opts,
in_channels=in_channels,
out_channels=hidden_dim,
kernel_size=1,
use_act=False,
use_norm=True,
),
)
block.add_module(name="act_fn_1", module=act_fn)
block.add_module(
name="conv_3x3",
module=ConvLayer(
opts,
in_channels=hidden_dim,
out_channels=hidden_dim,
stride=stride,
kernel_size=3,
groups=hidden_dim,
use_act=False,
use_norm=True,
dilation=dilation,
),
)
block.add_module(name="act_fn_2", module=act_fn)
if use_se:
se = SqueezeExcitation(
opts=opts,
in_channels=hidden_dim,
squeeze_factor=4,
scale_fn_name="hard_sigmoid",
)
block.add_module(name="se", module=se)
block.add_module(
name="red_1x1",
module=ConvLayer(
opts,
in_channels=hidden_dim,
out_channels=out_channels,
kernel_size=1,
use_act=False,
use_norm=True,
),
)
多尺度采样
#设置最小和最大size
if is_training:
self.img_batch_tuples = _image_batch_pairs(
crop_size_h=self.crop_size_h,
crop_size_w=self.crop_size_w,
batch_size_gpu0=self.batch_size_gpu0,
n_gpus=self.num_replicas,
max_scales=self.max_img_scales,
check_scale_div_factor=self.check_scale_div_factor,
min_crop_size_w=self.min_crop_size_w,
max_crop_size_w=self.max_crop_size_w,
min_crop_size_h=self.min_crop_size_h,
max_crop_size_h=self.max_crop_size_h,
)
self.img_batch_tuples = [
(h, w, self.batch_size_gpu0) for h, w, b in self.img_batch_tuples
]
def __iter__(self):
if self.shuffle:
random.seed(self.epoch)
indices_rank_i = self.img_indices[
self.rank : len(self.img_indices) : self.num_replicas
]
random.shuffle(indices_rank_i)
else:
indices_rank_i = self.img_indices[
self.rank : len(self.img_indices) : self.num_replicas
]
start_index = 0
n_samples_rank_i = len(indices_rank_i)
while start_index < n_samples_rank_i:
crop_h, crop_w, batch_size = random.choice(self.img_batch_tuples) #根据tuples设置随机大小
end_index = min(start_index + batch_size, n_samples_rank_i)
batch_ids = indices_rank_i[start_index:end_index]
n_batch_samples = len(batch_ids)
if n_batch_samples != batch_size:
batch_ids += indices_rank_i[: (batch_size - n_batch_samples)]
start_index += batch_size
if len(batch_ids) > 0: #设置batch大小
batch = [(crop_h, crop_w, b_id) for b_id in batch_ids]
yield batch
实验结果
原代码所需参数特别多,如果想要测试肯定是需要简化原代码
usage: main_train.py [-h] [--sampler.name SAMPLER.NAME] [--sampler.vbs.crop-size-width SAMPLER.VBS.CROP_SIZE_WIDTH]
[--sampler.vbs.crop-size-height SAMPLER.VBS.CROP_SIZE_HEIGHT] [--sampler.vbs.min-crop-size-width SAMPLER.VBS.MIN_CROP_SIZE_WIDTH]
[--sampler.vbs.max-crop-size-width SAMPLER.VBS.MAX_CROP_SIZE_WIDTH] [--sampler.vbs.min-crop-size-height SAMPLER.VBS.MIN_CROP_SIZE_HEIGHT]
[--sampler.vbs.max-crop-size-height SAMPLER.VBS.MAX_CROP_SIZE_HEIGHT] [--sampler.vbs.max-n-scales SAMPLER.VBS.MAX_N_SCALES]
[--sampler.vbs.check-scale SAMPLER.VBS.CHECK_SCALE] [--sampler.vbs.ep-intervals SAMPLER.VBS.EP_INTERVALS]
[--sampler.vbs.min-scale-inc-factor SAMPLER.VBS.MIN_SCALE_INC_FACTOR] [--sampler.vbs.max-scale-inc-factor SAMPLER.VBS.MAX_SCALE_INC_FACTOR]
[--sampler.vbs.scale-inc] [--sampler.vbs.num-repeats SAMPLER.VBS.NUM_REPEATS] [--sampler.bs.crop-size-width SAMPLER.BS.CROP_SIZE_WIDTH]
[--sampler.bs.crop-size-height SAMPLER.BS.CROP_SIZE_HEIGHT] [--sampler.bs.num-repeats SAMPLER.BS.NUM_REPEATS]
[--sampler.vbs.num-frames-per-clip SAMPLER.VBS.NUM_FRAMES_PER_CLIP] [--sampler.vbs.random-video-clips]
[--sampler.vbs.min-clips-per-video SAMPLER.VBS.MIN_CLIPS_PER_VIDEO] [--sampler.vbs.max-clips-per-video SAMPLER.VBS.MAX_CLIPS_PER_VIDEO]
[--sampler.vbs.clips-per-video SAMPLER.VBS.CLIPS_PER_VIDEO] [--sampler.vbs.min-frames-per-clip SAMPLER.VBS.MIN_FRAMES_PER_CLIP]
[--sampler.msc.crop-size-width SAMPLER.MSC.CROP_SIZE_WIDTH] [--sampler.msc.crop-size-height SAMPLER.MSC.CROP_SIZE_HEIGHT]
[--sampler.msc.min-crop-size-width SAMPLER.MSC.MIN_CROP_SIZE_WIDTH] [--sampler.msc.max-crop-size-width SAMPLER.MSC.MAX_CROP_SIZE_WIDTH]
[--sampler.msc.min-crop-size-height SAMPLER.MSC.MIN_CROP_SIZE_HEIGHT] [--sampler.msc.max-crop-size-height SAMPLER.MSC.MAX_CROP_SIZE_HEIGHT]
[--sampler.msc.max-n-scales SAMPLER.MSC.MAX_N_SCALES] [--sampler.msc.check-scale SAMPLER.MSC.CHECK_SCALE]
[--sampler.msc.ep-intervals SAMPLER.MSC.EP_INTERVALS] [--sampler.msc.scale-inc-factor SAMPLER.MSC.SCALE_INC_FACTOR] [--sampler.msc.scale-inc]
[--sampler.bs.num-frames-per-clip SAMPLER.BS.NUM_FRAMES_PER_CLIP] [--sampler.bs.clips-per-video SAMPLER.BS.CLIPS_PER_VIDEO]
[--dataset.root-train DATASET.ROOT_TRAIN] [--dataset.root-val DATASET.ROOT_VAL] [--dataset.root-test DATASET.ROOT_TEST] [--dataset.disable-val]
[--dataset.name DATASET.NAME] [--dataset.category DATASET.CATEGORY] [--dataset.train-batch-size0 DATASET.TRAIN_BATCH_SIZE0]
[--dataset.val-batch-size0 DATASET.VAL_BATCH_SIZE0] [--dataset.eval-batch-size0 DATASET.EVAL_BATCH_SIZE0] [--dataset.workers DATASET.WORKERS]
[--dataset.dali-workers DATASET.DALI_WORKERS] [--dataset.persistent-workers] [--dataset.pin-memory] [--dataset.prefetch-factor DATASET.PREFETCH_FACTOR]
[--dataset.img-dtype {float,half,float16}] [--dataset.cache-images-on-ram] [--dataset.cache-limit DATASET.CACHE_LIMIT]
[--dataset.sample-efficient-training.enable]
[--dataset.sample-efficient-training.sample-confidence DATASET.SAMPLE_EFFICIENT_TRAINING.SAMPLE_CONFIDENCE]
[--dataset.sample-efficient-training.find-easy-samples-every-k-epochs DATASET.SAMPLE_EFFICIENT_TRAINING.FIND_EASY_SAMPLES_EVERY_K_EPOCHS]
[--dataset.sample-efficient-training.min-sample-frequency DATASET.SAMPLE_EFFICIENT_TRAINING.MIN_SAMPLE_FREQUENCY] [--dataset.decode-data-on-gpu]
[--dataset.sampler-type DATASET.SAMPLER_TYPE] [--dataset.trove.enable] [--dataset.trove.mount-path DATASET.TROVE.MOUNT_PATH]
[--dataset.trove.disk-cache-dir DATASET.TROVE.DISK_CACHE_DIR] [--dataset.trove.disk-cache-max-size-gb DATASET.TROVE.DISK_CACHE_MAX_SIZE_GB]
[--dataset.trove.disk-cache-mount-size-gb DATASET.TROVE.DISK_CACHE_MOUNT_SIZE_GB] [--dataset.trove.uri DATASET.TROVE.URI]
[--dataset.trove.dir-train DATASET.TROVE.DIR_TRAIN] [--dataset.trove.dir-val DATASET.TROVE.DIR_VAL]
[--dataset.imagenet.crop-ratio DATASET.IMAGENET.CROP_RATIO] [--dataset.pascal.use-coco-data]
[--dataset.pascal.coco-root-dir DATASET.PASCAL.COCO_ROOT_DIR] [--dataset.kinetics.metadata-file-train DATASET.KINETICS.METADATA_FILE_TRAIN]
[--dataset.kinetics.metadata-file-val DATASET.KINETICS.METADATA_FILE_VAL] [--anchor-generator.name ANCHOR_GENERATOR.NAME]
[--anchor-generator.ssd.output-strides ANCHOR_GENERATOR.SSD.OUTPUT_STRIDES [ANCHOR_GENERATOR.SSD.OUTPUT_STRIDES ...]]
[--anchor-generator.ssd.aspect-ratios ANCHOR_GENERATOR.SSD.ASPECT_RATIOS [ANCHOR_GENERATOR.SSD.ASPECT_RATIOS ...]]
[--anchor-generator.ssd.min-scale-ratio ANCHOR_GENERATOR.SSD.MIN_SCALE_RATIO]
[--anchor-generator.ssd.max-scale-ratio ANCHOR_GENERATOR.SSD.MAX_SCALE_RATIO] [--anchor-generator.ssd.no-clipping]
[--anchor-generator.ssd.step ANCHOR_GENERATOR.SSD.STEP [ANCHOR_GENERATOR.SSD.STEP ...]] [--matcher.name MATCHER.NAME]
[--matcher.ssd.center-variance MATCHER.SSD.CENTER_VARIANCE] [--matcher.ssd.size-variance MATCHER.SSD.SIZE_VARIANCE]
[--matcher.ssd.iou-threshold MATCHER.SSD.IOU_THRESHOLD] [--video-reader.name VIDEO_READER.NAME] [--video-reader.fast-video-decoding]
[--video-reader.frame-stack-format {sequence_first,channel_first}] [--dataset.collate-fn-name-train DATASET.COLLATE_FN_NAME_TRAIN]
[--dataset.collate-fn-name-val DATASET.COLLATE_FN_NAME_VAL] [--dataset.collate-fn-name-eval DATASET.COLLATE_FN_NAME_EVAL]
[--image-augmentation.mixup.enable] [--image-augmentation.mixup.alpha IMAGE_AUGMENTATION.MIXUP.ALPHA]
[--image-augmentation.mixup.p IMAGE_AUGMENTATION.MIXUP.P] [--image-augmentation.mixup.inplace] [--image-augmentation.cutmix.enable]
[--image-augmentation.cutmix.alpha IMAGE_AUGMENTATION.CUTMIX.ALPHA] [--image-augmentation.cutmix.p IMAGE_AUGMENTATION.CUTMIX.P]
[--image-augmentation.cutmix.inplace] [--image-augmentation.random-gamma-correction.enable]
[--image-augmentation.random-gamma-correction.gamma IMAGE_AUGMENTATION.RANDOM_GAMMA_CORRECTION.GAMMA]
[--image-augmentation.random-gamma-correction.p IMAGE_AUGMENTATION.RANDOM_GAMMA_CORRECTION.P] [--image-augmentation.random-zoom-out.enable]
[--image-augmentation.random-zoom-out.side-range IMAGE_AUGMENTATION.RANDOM_ZOOM_OUT.SIDE_RANGE]
[--image-augmentation.random-zoom-out.p IMAGE_AUGMENTATION.RANDOM_ZOOM_OUT.P] [--image-augmentation.random-scale.enable]
[--image-augmentation.random-scale.min-scale IMAGE_AUGMENTATION.RANDOM_SCALE.MIN_SCALE]
[--image-augmentation.random-scale.max-scale IMAGE_AUGMENTATION.RANDOM_SCALE.MAX_SCALE]
[--image-augmentation.random-scale.interpolation IMAGE_AUGMENTATION.RANDOM_SCALE.INTERPOLATION] [--image-augmentation.random-flip.enable]
[--image-augmentation.random-vertical-flip.enable] [--image-augmentation.random-vertical-flip.p IMAGE_AUGMENTATION.RANDOM_VERTICAL_FLIP.P]
[--image-augmentation.random-rotate.interpolation IMAGE_AUGMENTATION.RANDOM_ROTATE.INTERPOLATION]
[--image-augmentation.random-rotate.p IMAGE_AUGMENTATION.RANDOM_ROTATE.P] [--image-augmentation.random-blur.enable]
[--image-augmentation.random-blur.kernel-size IMAGE_AUGMENTATION.RANDOM_BLUR.KERNEL_SIZE]
[--image-augmentation.random-blur.kernel-type {gauss,median,average,none,any}] [--image-augmentation.random-blur.p IMAGE_AUGMENTATION.RANDOM_BLUR.P]
[--image-augmentation.random-translate.enable] [--image-augmentation.random-translate.factor IMAGE_AUGMENTATION.RANDOM_TRANSLATE.FACTOR]
[--image-augmentation.box-absolute-coords.enable] [--image-augmentation.box-percent-coords.enable] [--image-augmentation.random-jpeg-compress.enable]
[--image-augmentation.random-jpeg-compress.q-factor IMAGE_AUGMENTATION.RANDOM_JPEG_COMPRESS.Q_FACTOR]
[--image-augmentation.random-jpeg-compress.p IMAGE_AUGMENTATION.RANDOM_JPEG_COMPRESS.P] [--image-augmentation.random-gauss-noise.enable]
[--image-augmentation.random-gauss-noise.sigma IMAGE_AUGMENTATION.RANDOM_GAUSS_NOISE.SIGMA]
[--image-augmentation.random-gauss-noise.p IMAGE_AUGMENTATION.RANDOM_GAUSS_NOISE.P] [--image-augmentation.photo-metric-distort-opencv.enable]
[--image-augmentation.photo-metric-distort-opencv.alpha-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.ALPHA_MIN]
[--image-augmentation.photo-metric-distort-opencv.alpha-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.ALPHA_MAX]
[--image-augmentation.photo-metric-distort-opencv.beta-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.BETA_MIN]
[--image-augmentation.photo-metric-distort-opencv.beta-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.BETA_MAX]
[--image-augmentation.photo-metric-distort-opencv.gamma-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.GAMMA_MIN]
[--image-augmentation.photo-metric-distort-opencv.gamma-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.GAMMA_MAX]
[--image-augmentation.photo-metric-distort-opencv.delta-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.DELTA_MIN]
[--image-augmentation.photo-metric-distort-opencv.delta-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.DELTA_MAX]
[--image-augmentation.photo-metric-distort-opencv.p IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT_OPENCV.P] [--video-augmentation.random-resized-crop.enable]
[--video-augmentation.random-resized-crop.interpolation {nearest,bilinear,bicubic}]
[--video-augmentation.random-resized-crop.scale VIDEO_AUGMENTATION.RANDOM_RESIZED_CROP.SCALE]
[--video-augmentation.random-resized-crop.aspect-ratio VIDEO_AUGMENTATION.RANDOM_RESIZED_CROP.ASPECT_RATIO]
[--video-augmentation.random-short-side-resize-crop.enable]
[--video-augmentation.random-short-side-resize-crop.interpolation {nearest,bilinear,bicubic}]
[--video-augmentation.random-short-side-resize-crop.short-side-min VIDEO_AUGMENTATION.RANDOM_SHORT_SIDE_RESIZE_CROP.SHORT_SIDE_MIN]
[--video-augmentation.random-short-side-resize-crop.short-side-max VIDEO_AUGMENTATION.RANDOM_SHORT_SIDE_RESIZE_CROP.SHORT_SIDE_MAX]
[--video-augmentation.random-crop.enable] [--video-augmentation.random-horizontal-flip.enable]
[--video-augmentation.random-horizontal-flip.p VIDEO_AUGMENTATION.RANDOM_HORIZONTAL_FLIP.P] [--video-augmentation.center-crop.enable]
[--video-augmentation.resize.enable] [--video-augmentation.resize.interpolation {nearest,bilinear,bicubic}]
[--video-augmentation.resize.size VIDEO_AUGMENTATION.RESIZE.SIZE [VIDEO_AUGMENTATION.RESIZE.SIZE ...]]
[--image-augmentation.random-resized-crop.enable]
[--image-augmentation.random-resized-crop.interpolation {nearest,bilinear,bicubic,cubic,box,hamming,lanczos}]
[--image-augmentation.random-resized-crop.scale IMAGE_AUGMENTATION.RANDOM_RESIZED_CROP.SCALE]
[--image-augmentation.random-resized-crop.aspect-ratio IMAGE_AUGMENTATION.RANDOM_RESIZED_CROP.ASPECT_RATIO] [--image-augmentation.auto-augment.enable]
[--image-augmentation.auto-augment.policy IMAGE_AUGMENTATION.AUTO_AUGMENT.POLICY]
[--image-augmentation.auto-augment.interpolation IMAGE_AUGMENTATION.AUTO_AUGMENT.INTERPOLATION] [--image-augmentation.rand-augment.enable]
[--image-augmentation.rand-augment.num-ops IMAGE_AUGMENTATION.RAND_AUGMENT.NUM_OPS]
[--image-augmentation.rand-augment.magnitude IMAGE_AUGMENTATION.RAND_AUGMENT.MAGNITUDE]
[--image-augmentation.rand-augment.num-magnitude-bins IMAGE_AUGMENTATION.RAND_AUGMENT.NUM_MAGNITUDE_BINS]
[--image-augmentation.rand-augment.interpolation {nearest,bilinear,bicubic,cubic,box,hamming,lanczos}]
[--image-augmentation.random-horizontal-flip.enable] [--image-augmentation.random-horizontal-flip.p IMAGE_AUGMENTATION.RANDOM_HORIZONTAL_FLIP.P]
[--image-augmentation.random-rotate.enable] [--image-augmentation.random-rotate.angle IMAGE_AUGMENTATION.RANDOM_ROTATE.ANGLE]
[--image-augmentation.random-rotate.mask-fill IMAGE_AUGMENTATION.RANDOM_ROTATE.MASK_FILL] [--image-augmentation.resize.enable]
[--image-augmentation.resize.interpolation {nearest,bilinear,bicubic,cubic,box,hamming,lanczos}]
[--image-augmentation.resize.size IMAGE_AUGMENTATION.RESIZE.SIZE [IMAGE_AUGMENTATION.RESIZE.SIZE ...]] [--image-augmentation.center-crop.enable]
[--image-augmentation.center-crop.size IMAGE_AUGMENTATION.CENTER_CROP.SIZE [IMAGE_AUGMENTATION.CENTER_CROP.SIZE ...]]
[--image-augmentation.ssd-crop.enable]
[--image-augmentation.ssd-crop.iou-thresholds IMAGE_AUGMENTATION.SSD_CROP.IOU_THRESHOLDS [IMAGE_AUGMENTATION.SSD_CROP.IOU_THRESHOLDS ...]]
[--image-augmentation.ssd-crop.n-trials IMAGE_AUGMENTATION.SSD_CROP.N_TRIALS]
[--image-augmentation.ssd-crop.min-aspect-ratio IMAGE_AUGMENTATION.SSD_CROP.MIN_ASPECT_RATIO]
[--image-augmentation.ssd-crop.max-aspect-ratio IMAGE_AUGMENTATION.SSD_CROP.MAX_ASPECT_RATIO] [--image-augmentation.photo-metric-distort.enable]
[--image-augmentation.photo-metric-distort.alpha-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.ALPHA_MIN]
[--image-augmentation.photo-metric-distort.alpha-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.ALPHA_MAX]
[--image-augmentation.photo-metric-distort.beta-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.BETA_MIN]
[--image-augmentation.photo-metric-distort.beta-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.BETA_MAX]
[--image-augmentation.photo-metric-distort.gamma-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.GAMMA_MIN]
[--image-augmentation.photo-metric-distort.gamma-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.GAMMA_MAX]
[--image-augmentation.photo-metric-distort.delta-min IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.DELTA_MIN]
[--image-augmentation.photo-metric-distort.delta-max IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.DELTA_MAX]
[--image-augmentation.photo-metric-distort.p IMAGE_AUGMENTATION.PHOTO_METRIC_DISTORT.P] [--image-augmentation.random-resize.enable]
[--image-augmentation.random-resize.max-scale-long-edge IMAGE_AUGMENTATION.RANDOM_RESIZE.MAX_SCALE_LONG_EDGE]
[--image-augmentation.random-resize.max-scale-short-edge IMAGE_AUGMENTATION.RANDOM_RESIZE.MAX_SCALE_SHORT_EDGE]
[--image-augmentation.random-resize.min-ratio IMAGE_AUGMENTATION.RANDOM_RESIZE.MIN_RATIO]
[--image-augmentation.random-resize.max-ratio IMAGE_AUGMENTATION.RANDOM_RESIZE.MAX_RATIO]
[--image-augmentation.random-resize.interpolation {nearest,bilinear,bicubic,cubic,box,hamming,lanczos}]
[--image-augmentation.random-short-size-resize.enable]
[--image-augmentation.random-short-size-resize.short-side-min IMAGE_AUGMENTATION.RANDOM_SHORT_SIZE_RESIZE.SHORT_SIDE_MIN]
[--image-augmentation.random-short-size-resize.short-side-max IMAGE_AUGMENTATION.RANDOM_SHORT_SIZE_RESIZE.SHORT_SIDE_MAX]
[--image-augmentation.random-short-size-resize.interpolation {nearest,bilinear,bicubic,cubic,box,hamming,lanczos}]
[--image-augmentation.random-short-size-resize.max-img-dim IMAGE_AUGMENTATION.RANDOM_SHORT_SIZE_RESIZE.MAX_IMG_DIM]
[--image-augmentation.random-erase.enable] [--image-augmentation.random-erase.p IMAGE_AUGMENTATION.RANDOM_ERASE.P]
[--image-augmentation.random-gaussian-noise.enable] [--image-augmentation.random-gaussian-noise.p IMAGE_AUGMENTATION.RANDOM_GAUSSIAN_NOISE.P]
[--image-augmentation.random-crop.enable] [--image-augmentation.random-crop.seg-class-max-ratio IMAGE_AUGMENTATION.RANDOM_CROP.SEG_CLASS_MAX_RATIO]
[--image-augmentation.random-crop.pad-if-needed] [--image-augmentation.random-crop.mask-fill IMAGE_AUGMENTATION.RANDOM_CROP.MASK_FILL]
[--image-augmentation.to-tensor.dtype IMAGE_AUGMENTATION.TO_TENSOR.DTYPE] [--image-augmentation.random-order.enable]
[--image-augmentation.random-order.apply-k IMAGE_AUGMENTATION.RANDOM_ORDER.APPLY_K] [--model.layer.conv-init MODEL.LAYER.CONV_INIT]
[--model.layer.conv-init-std-dev MODEL.LAYER.CONV_INIT_STD_DEV] [--model.layer.group-linear-init MODEL.LAYER.GROUP_LINEAR_INIT]
[--model.layer.group-linear-init-std-dev MODEL.LAYER.GROUP_LINEAR_INIT_STD_DEV] [--model.layer.linear-init MODEL.LAYER.LINEAR_INIT]
[--model.layer.linear-init-std-dev MODEL.LAYER.LINEAR_INIT_STD_DEV] [--model.layer.global-pool MODEL.LAYER.GLOBAL_POOL]
[--model.activation.name MODEL.ACTIVATION.NAME] [--model.activation.inplace] [--model.activation.neg-slope MODEL.ACTIVATION.NEG_SLOPE]
[--model.normalization.name MODEL.NORMALIZATION.NAME] [--model.normalization.groups MODEL.NORMALIZATION.GROUPS]
[--model.normalization.momentum MODEL.NORMALIZATION.MOMENTUM] [--model.normalization.adjust-bn-momentum.enable]
[--model.normalization.adjust-bn-momentum.anneal-type MODEL.NORMALIZATION.ADJUST_BN_MOMENTUM.ANNEAL_TYPE]
[--model.normalization.adjust-bn-momentum.final-momentum-value MODEL.NORMALIZATION.ADJUST_BN_MOMENTUM.FINAL_MOMENTUM_VALUE]
[--model.classification.classifier-dropout MODEL.CLASSIFICATION.CLASSIFIER_DROPOUT] [--model.classification.name MODEL.CLASSIFICATION.NAME]
[--model.classification.n-classes MODEL.CLASSIFICATION.N_CLASSES] [--model.classification.pretrained MODEL.CLASSIFICATION.PRETRAINED]
[--model.classification.freeze-batch-norm] [--model.classification.activation.name MODEL.CLASSIFICATION.ACTIVATION.NAME]
[--model.classification.activation.inplace] [--model.classification.activation.neg-slope MODEL.CLASSIFICATION.ACTIVATION.NEG_SLOPE]
[--model.classification.finetune-pretrained-model] [--model.classification.n-pretrained-classes MODEL.CLASSIFICATION.N_PRETRAINED_CLASSES]
[--model.classification.resnet.depth MODEL.CLASSIFICATION.RESNET.DEPTH] [--model.classification.resnet.dropout MODEL.CLASSIFICATION.RESNET.DROPOUT]
[--model.classification.mitv2.attn-dropout MODEL.CLASSIFICATION.MITV2.ATTN_DROPOUT]
[--model.classification.mitv2.ffn-dropout MODEL.CLASSIFICATION.MITV2.FFN_DROPOUT]
[--model.classification.mitv2.dropout MODEL.CLASSIFICATION.MITV2.DROPOUT]
[--model.classification.mitv2.width-multiplier MODEL.CLASSIFICATION.MITV2.WIDTH_MULTIPLIER]
[--model.classification.mitv2.attn-norm-layer MODEL.CLASSIFICATION.MITV2.ATTN_NORM_LAYER] [--model.classification.mit.mode {xx_small,x_small,small}]
[--model.classification.mit.attn-dropout MODEL.CLASSIFICATION.MIT.ATTN_DROPOUT]
[--model.classification.mit.ffn-dropout MODEL.CLASSIFICATION.MIT.FFN_DROPOUT] [--model.classification.mit.dropout MODEL.CLASSIFICATION.MIT.DROPOUT]
[--model.classification.mit.transformer-norm-layer MODEL.CLASSIFICATION.MIT.TRANSFORMER_NORM_LAYER]
[--model.classification.mit.no-fuse-local-global-features] [--model.classification.mit.conv-kernel-size MODEL.CLASSIFICATION.MIT.CONV_KERNEL_SIZE]
[--model.classification.mit.head-dim MODEL.CLASSIFICATION.MIT.HEAD_DIM] [--model.classification.mit.number-heads MODEL.CLASSIFICATION.MIT.NUMBER_HEADS]
[--model.classification.mobilenetv1.width-multiplier MODEL.CLASSIFICATION.MOBILENETV1.WIDTH_MULTIPLIER]
[--model.classification.mobilenetv3.mode {small,large}]
[--model.classification.mobilenetv3.width-multiplier MODEL.CLASSIFICATION.MOBILENETV3.WIDTH_MULTIPLIER]
[--model.classification.vit.mode MODEL.CLASSIFICATION.VIT.MODE] [--model.classification.vit.dropout MODEL.CLASSIFICATION.VIT.DROPOUT]
[--model.classification.vit.vocab-size MODEL.CLASSIFICATION.VIT.VOCAB_SIZE] [--model.classification.vit.learnable-pos-emb]
[--model.classification.vit.no-cls-token] [--model.classification.mobilenetv2.width-multiplier MODEL.CLASSIFICATION.MOBILENETV2.WIDTH_MULTIPLIER]
[--model.detection.name MODEL.DETECTION.NAME] [--model.detection.n-classes MODEL.DETECTION.N_CLASSES]
[--model.detection.pretrained MODEL.DETECTION.PRETRAINED] [--model.detection.output-stride MODEL.DETECTION.OUTPUT_STRIDE]
[--model.detection.replace-stride-with-dilation] [--model.detection.freeze-batch-norm]
[--model.detection.ssd.anchors-aspect-ratio MODEL.DETECTION.SSD.ANCHORS_ASPECT_RATIO [MODEL.DETECTION.SSD.ANCHORS_ASPECT_RATIO ...]]
[--model.detection.ssd.output-strides MODEL.DETECTION.SSD.OUTPUT_STRIDES [MODEL.DETECTION.SSD.OUTPUT_STRIDES ...]]
[--model.detection.ssd.proj-channels MODEL.DETECTION.SSD.PROJ_CHANNELS [MODEL.DETECTION.SSD.PROJ_CHANNELS ...]]
[--model.detection.ssd.min-box-size MODEL.DETECTION.SSD.MIN_BOX_SIZE] [--model.detection.ssd.max-box-size MODEL.DETECTION.SSD.MAX_BOX_SIZE]
[--model.detection.ssd.center-variance MODEL.DETECTION.SSD.CENTER_VARIANCE] [--model.detection.ssd.size-variance MODEL.DETECTION.SSD.SIZE_VARIANCE]
[--model.detection.ssd.iou-threshold MODEL.DETECTION.SSD.IOU_THRESHOLD] [--model.detection.ssd.conf-threshold MODEL.DETECTION.SSD.CONF_THRESHOLD]
[--model.detection.ssd.top-k MODEL.DETECTION.SSD.TOP_K] [--model.detection.ssd.objects-per-image MODEL.DETECTION.SSD.OBJECTS_PER_IMAGE]
[--model.detection.ssd.nms-iou-threshold MODEL.DETECTION.SSD.NMS_IOU_THRESHOLD]
[--model.detection.ssd.fpn-out-channels MODEL.DETECTION.SSD.FPN_OUT_CHANNELS] [--model.detection.ssd.use-fpn]
[--model.segmentation.name MODEL.SEGMENTATION.NAME] [--model.segmentation.n-classes MODEL.SEGMENTATION.N_CLASSES]
[--model.segmentation.pretrained MODEL.SEGMENTATION.PRETRAINED] [--model.segmentation.lr-multiplier MODEL.SEGMENTATION.LR_MULTIPLIER]
[--model.segmentation.classifier-dropout MODEL.SEGMENTATION.CLASSIFIER_DROPOUT] [--model.segmentation.use-aux-head]
[--model.segmentation.aux-dropout MODEL.SEGMENTATION.AUX_DROPOUT] [--model.segmentation.output-stride MODEL.SEGMENTATION.OUTPUT_STRIDE]
[--model.segmentation.replace-stride-with-dilation] [--model.segmentation.activation.name MODEL.SEGMENTATION.ACTIVATION.NAME]
[--model.segmentation.activation.inplace] [--model.segmentation.activation.neg-slope MODEL.SEGMENTATION.ACTIVATION.NEG_SLOPE]
[--model.segmentation.freeze-batch-norm] [--model.segmentation.use-level5-exp] [--model.segmentation.seg-head MODEL.SEGMENTATION.SEG_HEAD]
[--model.segmentation.deeplabv3.aspp-rates MODEL.SEGMENTATION.DEEPLABV3.ASPP_RATES]
[--model.segmentation.deeplabv3.aspp-out-channels MODEL.SEGMENTATION.DEEPLABV3.ASPP_OUT_CHANNELS] [--model.segmentation.deeplabv3.aspp-sep-conv]
[--model.segmentation.deeplabv3.aspp-dropout MODEL.SEGMENTATION.DEEPLABV3.ASPP_DROPOUT]
[--model.segmentation.pspnet.psp-pool-sizes MODEL.SEGMENTATION.PSPNET.PSP_POOL_SIZES [MODEL.SEGMENTATION.PSPNET.PSP_POOL_SIZES ...]]
[--model.segmentation.pspnet.psp-out-channels MODEL.SEGMENTATION.PSPNET.PSP_OUT_CHANNELS]
[--model.segmentation.pspnet.psp-dropout MODEL.SEGMENTATION.PSPNET.PSP_DROPOUT]
[--model.video-classification.classifier-dropout MODEL.VIDEO_CLASSIFICATION.CLASSIFIER_DROPOUT]
[--model.video-classification.name MODEL.VIDEO_CLASSIFICATION.NAME] [--model.video-classification.n-classes MODEL.VIDEO_CLASSIFICATION.N_CLASSES]
[--model.video-classification.pretrained MODEL.VIDEO_CLASSIFICATION.PRETRAINED] [--model.video-classification.freeze-batch-norm]
[--model.video-classification.activation.name MODEL.VIDEO_CLASSIFICATION.ACTIVATION.NAME] [--model.video-classification.activation.inplace]
[--model.video-classification.activation.neg-slope MODEL.VIDEO_CLASSIFICATION.ACTIVATION.NEG_SLOPE]
[--model.video-classification.clip-out-voting-fn {sum,max}] [--model.video-classification.inference-mode] [--ema.enable] [--ema.momentum EMA.MOMENTUM]
[--ema.copy-at-epoch EMA.COPY_AT_EPOCH] [--loss.category LOSS.CATEGORY] [--loss.ignore-idx LOSS.IGNORE_IDX] [--loss.detection.name LOSS.DETECTION.NAME]
[--loss.detection.ssd-multibox-loss.neg-pos-ratio LOSS.DETECTION.SSD_MULTIBOX_LOSS.NEG_POS_RATIO]
[--loss.detection.ssd-multibox-loss.max-monitor-iter LOSS.DETECTION.SSD_MULTIBOX_LOSS.MAX_MONITOR_ITER]
[--loss.detection.ssd-multibox-loss.update-wt-freq LOSS.DETECTION.SSD_MULTIBOX_LOSS.UPDATE_WT_FREQ]
[--loss.detection.ssd-multibox-loss.label-smoothing LOSS.DETECTION.SSD_MULTIBOX_LOSS.LABEL_SMOOTHING] [--loss.segmentation.name LOSS.SEGMENTATION.NAME]
[--loss.segmentation.cross-entropy.class-weights] [--loss.segmentation.cross-entropy.aux-weight LOSS.SEGMENTATION.CROSS_ENTROPY.AUX_WEIGHT]
[--loss.segmentation.cross-entropy.label-smoothing LOSS.SEGMENTATION.CROSS_ENTROPY.LABEL_SMOOTHING]
[--loss.classification.name LOSS.CLASSIFICATION.NAME] [--loss.classification.cross-entropy.class-weights]
[--loss.classification.label-smoothing LOSS.CLASSIFICATION.LABEL_SMOOTHING] [--loss.distillation.name LOSS.DISTILLATION.NAME]
[--loss.distillation.vanilla-teacher-model LOSS.DISTILLATION.VANILLA_TEACHER_MODEL]
[--loss.distillation.vanilla-label-loss LOSS.DISTILLATION.VANILLA_LABEL_LOSS] [--loss.distillation.vanilla-alpha LOSS.DISTILLATION.VANILLA_ALPHA]
[--loss.distillation.vanilla-tau LOSS.DISTILLATION.VANILLA_TAU] [--loss.distillation.vanilla-adaptive-weight-balance]
[--loss.distillation.vanilla-accum-iterations LOSS.DISTILLATION.VANILLA_ACCUM_ITERATIONS]
[--loss.distillation.vanilla-weight-update-freq LOSS.DISTILLATION.VANILLA_WEIGHT_UPDATE_FREQ]
[--loss.distillation.vanilla-teacher-model-weights LOSS.DISTILLATION.VANILLA_TEACHER_MODEL_WEIGHTS]
[--loss.distillation.vanilla-distillation-type LOSS.DISTILLATION.VANILLA_DISTILLATION_TYPE] [--optim.name OPTIM.NAME] [--optim.eps OPTIM.EPS]
[--optim.weight-decay OPTIM.WEIGHT_DECAY] [--optim.no-decay-bn-filter-bias] [--optim.adamw.beta1 OPTIM.ADAMW.BETA1]
[--optim.adamw.beta2 OPTIM.ADAMW.BETA2] [--optim.adamw.amsgrad] [--optim.adam.beta1 OPTIM.ADAM.BETA1] [--optim.adam.beta2 OPTIM.ADAM.BETA2]
[--optim.adam.amsgrad] [--optim.sgd.momentum OPTIM.SGD.MOMENTUM] [--optim.sgd.nesterov] [--scheduler.name SCHEDULER.NAME] [--scheduler.lr SCHEDULER.LR]
[--scheduler.max-epochs SCHEDULER.MAX_EPOCHS] [--scheduler.max-iterations SCHEDULER.MAX_ITERATIONS]
[--scheduler.warmup-iterations SCHEDULER.WARMUP_ITERATIONS] [--scheduler.warmup-init-lr SCHEDULER.WARMUP_INIT_LR] [--scheduler.is-iteration-based]
[--scheduler.adjust-period-for-epochs] [--scheduler.fixed.lr SCHEDULER.FIXED.LR] [--scheduler.multi-step.lr SCHEDULER.MULTI_STEP.LR]
[--scheduler.multi-step.gamma SCHEDULER.MULTI_STEP.GAMMA]
[--scheduler.multi-step.milestones SCHEDULER.MULTI_STEP.MILESTONES [SCHEDULER.MULTI_STEP.MILESTONES ...]]
[--scheduler.cosine.min-lr SCHEDULER.COSINE.MIN_LR] [--scheduler.cosine.max-lr SCHEDULER.COSINE.MAX_LR]
[--scheduler.cyclic.min-lr SCHEDULER.CYCLIC.MIN_LR] [--scheduler.cyclic.last-cycle-end-lr SCHEDULER.CYCLIC.LAST_CYCLE_END_LR]
[--scheduler.cyclic.total-cycles SCHEDULER.CYCLIC.TOTAL_CYCLES] [--scheduler.cyclic.epochs-per-cycle SCHEDULER.CYCLIC.EPOCHS_PER_CYCLE]
[--scheduler.cyclic.steps SCHEDULER.CYCLIC.STEPS [SCHEDULER.CYCLIC.STEPS ...]] [--scheduler.cyclic.gamma SCHEDULER.CYCLIC.GAMMA]
[--scheduler.cyclic.last-cycle-type {cosine,linear}] [--scheduler.polynomial.power SCHEDULER.POLYNOMIAL.POWER]
[--scheduler.polynomial.start-lr SCHEDULER.POLYNOMIAL.START_LR] [--scheduler.polynomial.end-lr SCHEDULER.POLYNOMIAL.END_LR] [--ddp.disable]
[--ddp.rank DDP.RANK] [--ddp.world-size DDP.WORLD_SIZE] [--ddp.dist-url DDP.DIST_URL] [--ddp.dist-port DDP.DIST_PORT] [--ddp.device-id DDP.DEVICE_ID]
[--ddp.no-spawn] [--ddp.backend DDP.BACKEND] [--ddp.find-unused-params] [--stats.val STATS.VAL [STATS.VAL ...]]
[--stats.train STATS.TRAIN [STATS.TRAIN ...]] [--stats.checkpoint-metric STATS.CHECKPOINT_METRIC] [--stats.checkpoint-metric-max]
[--stats.save-all-checkpoints] [--common.seed COMMON.SEED] [--common.config-file COMMON.CONFIG_FILE] [--common.results-loc COMMON.RESULTS_LOC]
[--common.run-label COMMON.RUN_LABEL] [--common.resume COMMON.RESUME] [--common.finetune_imagenet1k COMMON.FINETUNE_IMAGENET1K]
[--common.finetune_imagenet1k-ema COMMON.FINETUNE_IMAGENET1K_EMA] [--common.mixed-precision] [--common.accum-freq COMMON.ACCUM_FREQ]
[--common.accum-after-epoch COMMON.ACCUM_AFTER_EPOCH] [--common.log-freq COMMON.LOG_FREQ] [--common.auto-resume] [--common.grad-clip COMMON.GRAD_CLIP]
[--common.k-best-checkpoints COMMON.K_BEST_CHECKPOINTS] [--common.inference-modality {image,video}] [--common.channels-last]
[--common.tensorboard-logging] [--common.bolt-logging] [--common.override-kwargs [COMMON.OVERRIDE_KWARGS [COMMON.OVERRIDE_KWARGS ...]]]
[--common.enable-coreml-compatible-module] [--common.debug-mode]