【sql效率优化】优雅地解决mysql深分页问题?
背景
日常需求开发过程中,相信大家对于limit一定不会陌生,但是使用limit时,当偏移量(offset)非常大时,会发现查询效率越来越慢。一开始limit 2000时,可能200ms,就能查询出需要的到数据,但是当limit 4000 offset 100000时,会发现它的查询效率已经需要1S左右,那要是更大的时候呢,只会越来越慢。
概括
本文将会讨论当mysql表大数据量的情况,如何优化深分页问题,并附上最近的优化慢sql问题的案例伪代码。
1、limit深分页问题描述
先看看表结构(随便举了个例子,表结构不全,无用字段就不进行展示了)
CREATE TABLE `p2p_detail_record` (
`id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键',
`batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量',
`uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间',
`uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id',
`start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间',
`answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间',
`end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间',
`duration` int NOT NULL DEFAULT '0' COMMENT '持续时间',
PRIMARY KEY (`id`),
KEY `idx_uuid` (`uuid`),
KEY `idx_start_time_stamp` (`start_time_stamp`) //索引,
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
复制代码假设我们要查询的深分页SQL长这样
select *
from p2p_detail_record ppdr
where ppdr .start_time_stamp >1656666798000
limit 0,2000
复制代码![]()
查询效率是94ms,是不是很快?那如果我们limit 100000,2000呢,查询效率是1.5S,已经非常慢,那如果更多呢?
![]()
2、sql慢原因分析
让我们来看看这条sql的执行计划

也走到了索引,那为什么还是慢呢?我们先来回顾一下mysql 的相关知识点。
聚簇索引和非聚簇索引
聚簇索引: 叶子节点储存的是整行的数据。
非聚簇索引: 叶子节点储存的是整行的数据对应的主键值。
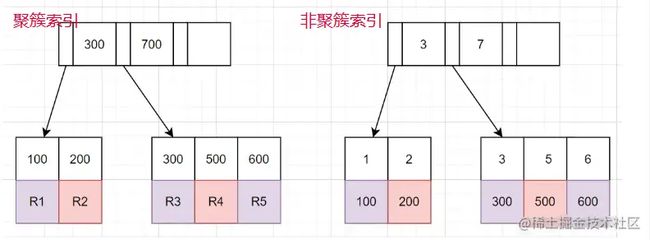
使用非聚簇索引查询的流程
- 通过非聚簇索引树,找到对应的叶子节点,获取到主键的值。
- 再通过取到主键的值,回到聚簇索引树,找到对应的整行数据。(整个过程称为回表)
回到这条sql为什么慢的问题上,原因如下
1、limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。这里需要回表100010次,大量的时间都在回表这个上面。
方案核心思路: 能不能事先知道要从哪个主键ID开始,减少回表的次数
常见解决方案
通过子查询优化
select *
from p2p_detail_record ppdr
where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1)
limit 2000
复制代码相同的查询结果,也是10W条开始的第2000条,查询效率为200ms,是不是快了不少。
![]()
标签记录法
标签记录法: 其实标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。类似书签的作用
select * from p2p_detail_record ppdr
where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4'
order by id
limit 2000
备注:bb9d67ee6eac4cab9909bad7c98f54d4是上次查询结果的最后一条ID
复制代码使用标签记录法,性能都会不错的,因为命中了id索引。但是这种方式有几个缺点。
- 1、只能连续页查询,不能跨页查询。
- 2、需要一种类似连续自增的字段(可以使用orber by id的方式)。
方案对比
- 使用通过子查询优化的方式
优点: 可跨页查询,想查哪一页的数据就查哪一页的数据。
缺点: 效率不如标签记录法。原因: 比如需要查10W条数据后,第1000条,也需要先查询出非聚簇索引对应的10W1000条数据,在取第10W开始的ID,进行查询。
- 使用 标签记录法 的方式
优点: 查询效率很稳定,非常快。
缺点:
- 不跨页查询,
- 需要一种类似连续自增的字段
关于第二点的说明: 该点一般都好解决,可使用任意不重复的字段进行排序即可。若使用可能重复的字段进行排序的字段,由于mysql对于相同值的字段排序是无序,导致如果正好在分页时,上下页中可能存在相同的数据。
实战案例
需求: 需要查询查询某一时间段的数据量,假设有几十万的数据量需要查询出来,进行某些操作。
需求分析 1、分批查询(分页查询),设计深分页问题,导致效率较慢。
CREATE TABLE `p2p_detail_record` (
`id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键',
`batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量',
`uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间',
`uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id',
`start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间',
`answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间',
`end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间',
`duration` int NOT NULL DEFAULT '0' COMMENT '持续时间',
PRIMARY KEY (`id`),
KEY `idx_uuid` (`uuid`),
KEY `idx_start_time_stamp` (`start_time_stamp`) //索引,
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
复制代码伪代码实现:
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
select *
from p2p_detail_record ppdr where 1=1
and ppdr.id > #{lastId}
order by id asc
limit #{pageSize}
复制代码 这里有个小优化点: 可能有的人会先对所有数据排序一遍,拿到最小ID,但是这样对所有数据排序,然后去min(id),耗时也蛮长的,其实第一次查询,可不带lastId进行查询,查询结果也是一样。速度更快。
总结
1、当业务需要从表中查出大数据量时,而又项目架构没上ES时,可考虑使用标签记录法的方式,对查询效率进行优化。
2、从需求上也应该尽可能避免,在大数据量的情况下,分页查询最后一页的功能。或者限制成只能一页一页往后划的场景。