布隆过滤器
第一反应
说到布隆过滤器第一反应应该是:
1、一定没有 or 可能有
2、hashCode
3、效率与成本(时间与空间)
什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的,它实际上是由一个很长的二进制向量和一系列随意映射函数组成。
它是一种基于概率的数据结构,主要用来判断某个元素是否在集合内,它具有运行速度快(时间效率),占用内存小的优点(空间效率),但是有一定的误识别率和删除困难的问题。它能够告诉你某个元素一定不在集合内或可能在集合内
原理分析
举例,假设数组长度m=19,k=2个哈希函数
既然选用hash算法,必然就会存在碰撞的可能。两个不完全相同的值计算出来的hash值有可能会出现一致。多次使用hash算法,为同一个值取不同的多个hash,取的越多。碰撞率的几率就越小。当然hash的数量也不是越多越好。
插入数据
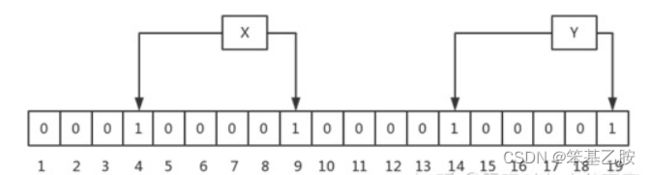
如上图,插入了两个元素,X和Y,X的两次hash取模后的值分别为4,9,因此,4和9位被置成1;Y的两次hash取模后的值分别为14和19,因此,14和19位被置成1。
插入流程
将要添加的元素给k个哈希函数
得到对应于位数组上的k个位置
将这k个位置设为1
查找数据
BloomFilter中查找一个元素,会使用和插入过程中相同的k个hash函数,取模后,取出每个bit对应的值,如果所有bit都为1,则返回元素可能存在,否则,返回元素不存在
流程说明
将要查询的元素给k个哈希函数
得到对应于位数组上的k个位置
如果k个位置有一个为0,则一定不在集合中
如果k个位置全部为1,则可能在集合中
为什么bit全部为1时,元素只是可能存在呢?
当然,如果情况如上图中只存在X、Y,而且两个元素hash后的值并不重复。那么这种情况就可以确定元素一定存在。
但是,存在另一种情况。假设我们现在要查询Z元素,假设Z元素并不存在。但是巧了经过hash计算出来的位置为9,14。我们很清楚,这里的9是属于X元素的,14是术语Y元素的。并不存在Z。但是经过hash计算的结果返回值都是1。所以程序认为Z是存在的,但实际上Z并不存在,此现象称为false positive
为什么不能删除数据
BloomFilter中不允许有删除操作,因为删除后,可能会造成原来存在的元素返回不存在,这个是不允许的,还是以一个例子说明:
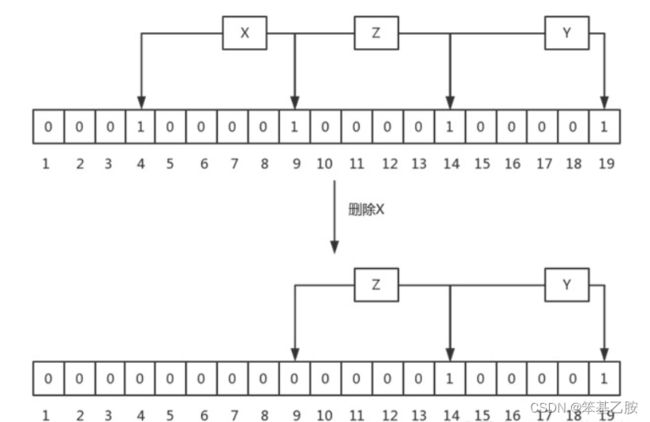
上图中,刚开始时,有元素X,Y和Z,其hash的bit如图中所示,当删除X后,会把bit 4和9置成0,这同时会造成查询Z时,报不存在的问题,这对于BloomFilter来讲是不能容忍的,因为它要么返回绝对不存在,要么返回可能存在。
问题:BloomFilter中不允许删除的机制会导致其中的无效元素可能会越来越多,即实际已经在磁盘删除中的元素,但在bloomfilter中还认为可能存在,这会造成越来越多的false positive。
优缺点
优点
常用的数据结构,如hashmap,set,bit array都能用来测试一个元素是否存在于一个集合中,相对于这些数据结构,BloomFilter有什么方面的优势呢?
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(O(k))。另外, 散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
- 对于hashmap,其本质上是一个指针数组,一个指针的开销是sizeof(void *),在64bit的系统上是64个bit,如果采用开链法处理冲突的话,又需要额外的指针开销,而对于BloomFilter来讲,返回可能存在的情况中,如果允许有1%的错误率的话,每个元素大约需要10bit的存储空间,整个存储空间的开销大约是hashmap的15%左右(数据来自维基百科)
- 对于set,如果采用hashmap方式实现,情况同上;如果采用平衡树方式实现,一个节点需要一个指针存储数据的位置,两个指针指向其子节点,因此开销相对于hashmap来讲是更多的
- 对于bit array,对于某个元素是否存在,先对元素做hash,取模定位到具体的bit,如果该bit为1,则返回元素存在,如果该bit为0,则返回此元素不存在。可以看出,在返回元素存在的时候,也是会有误判的,如果要获得和BloomFilter相同的误判率,则需要比BloomFilter更大的存储空间
布隆过滤器可以表示全集,其它任何数据结构都不能;
- 全量存储但是不存储数据本身,适合有保密要求的场景
- 空间复杂度为O(m),不会随着元素增加而增加,占用空间少
- 插入和查询时间复杂度都是 O(k), 不会随着元素增加而增加,远超一般算法。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题
- 相对于hashmap和set,BloomFilter在返回元素可能存在的情况中,有一定的误判率,这时候,调用者在误判的时候,会做一些不必要的工作,而对于hashmap和set,不会存在误判情况
- 对于bit array,BloomFilter在插入和查找元素是否存在时,需要做多次hash,而bit array只需要做一次hash,实际上,bit array可以看做是BloomFilter的一种特殊情况
在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。
- 存在误算率,数据越多,误算率越高
- 一般情况下无法从过滤器中删除数据
- 二进制数组长度和 hash 函数个数确定过程复杂
使用场景
布隆过滤器的巨大用处就是,能够迅速判断一个元素是否在一个集合中。因此他有如下三个使用场景:
- 网页爬虫对URL的去重,避免爬取相同的URL地址
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)
- 缓存穿透,将所有可能存在的数据缓存放到布隆过滤器中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
关于缓存穿透、击穿、雪崩相关内容可以查看之前我写的博客点击这里跳转
BloomFilter的使用-缓存穿透
在大多应用中,当业务系统中发送一个请求时,会先从缓存中查询;若缓存中存在,则直接返回;若返回中不存在,则查询数据库。
缓存穿透:当请求数据库中不存在的数据,这时候所有的请求都会打到数据库上,这种情况就是缓存穿透。如果当请求较多的话,这将会严重浪费数据库资源甚至导致数据库假死。
BloomFilter解决缓存穿透的思路,这种技术在缓存之前再加一层屏障,里面存储目前数据库中存在的所有key,当业务系统有查询请求的时候,首先去BloomFilter中查询该key是否存在。若不存在,则说明数据库中也不存在该数据,因此缓存都不要查了,直接返回null。若存在,则继续执行后续的流程,先前往缓存中查询,缓存中没有的话再前往数据库中的查询
项目中使用
关于布隆过滤器,我们不需要自己实现,谷歌已经帮我们实现好了。
pom引入依赖
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
代码
guava 的布隆过滤器,封装的非常好,使用起来非常简洁方便。
1、布隆过滤器的默认容错率是0.03
public static void main(String[] args) {
int size=10000;
double fpp=0.0001;
//没有设置误判率的情况下,10000→312,误判率3.12%
BloomFilter<CharSequence> bloomFilter =
BloomFilter.create(Funnels.stringFunnel(
Charset.forName("utf-8")),10000);
for (int m=0;m<size;m++){
bloomFilter.put(""+m);
}
List<Integer> list=new ArrayList<Integer>();
for(int n=size+10000;n<size+20000;n++){
if(bloomFilter.mightContain(""+n)){
list.add(n);
}
}
System.out.println("误判数量:::"+list.size());
}
//源码::在调用没有设置容错率的创建实例方法时,默认0.03的容错率
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03D);
}
2、测试容错率的变化,所需数组位数的变化
容错率0.0001,所需位数191701
public static void main(String[] args) {
// 1.创建符合条件的布隆过滤器
// 预期数据量10000,错误率0.0001
BloomFilter<CharSequence> bloomFilter =
BloomFilter.create(Funnels.stringFunnel(
Charset.forName("utf-8")),10000, 0.0001);
// 2.将一部分数据添加进去
for (int i = 0; i < 5000; i++) {
bloomFilter.put("" + i);
}
System.out.println("数据写入完毕");
// 3.测试结果输出
for (int i = 0; i < 10000; i++) {
if (bloomFilter.mightContain("" + i)) {
System.out.println(i + "存在");
} else {
System.out.println(i + "不存在");
}
}
}
容错率0.01,所需位数95850
由此可见,误判率越低,则底层维护的数组越长,占用空间越大。因此,误判率实际取值,根据服务器所能够承受的负载来决定,不是拍脑袋瞎想的。
参考文献地址: https://zhuanlan.zhihu.com/p/472935179