关于bag of words 的初步理解
from: http://blog.sciencenet.cn/blog-261330-627219.html
[转载]SIFT算法的应用--目标识别之Bag-of-words模型(转)
|||
作者:wawayu,July。编程艺术室出品。
出处:http://blog.csdn.net/v_JULY_v 。
-
引言
本blog之前已经写了四篇关于SIFT的文章,请参考九、图像特征提取与匹配之SIFT算法,九(续)、sift算法的编译与实现,九(再续)、教你一步一步用c语言实现sift算法、上,及九(再续)、教你一步一步用c语言实现sift算法、下。
上述这4篇文章对SIFT算法的原理和C语言实现都做了详细介绍,用SIFT做图像匹配效果不错。现在考虑更为高层的应用,将SIFT算法应用于目标识别:发现图像中包含的物体类别,这是计算机视觉领域最基本也是最重要的任务之一。
且原经典算法研究系列可能将改名为算法珠玑--经典算法的通俗演义。改名考虑到三点:1、不求面面俱到所有算法,所以掏炼,谓之“珠玑”;2、突出本博客内算法内容的特色-通俗易懂、简明直白,谓之“通俗”;3、侧重经典算法的研究与实现,以及实际应用,谓之“演义”。
OK,闲话少说,上一篇我们介绍了六(续)、从KMP算法一步一步谈到BM算法。下面我们来介绍有关SIFT算法的目标识别的应用--Bag-of-words模型。
-
Bag-of-words模型简介
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数(下文中,将用单词的直方图表示)。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序(这是本Bag-of-words模型的缺点之一,不过瑕不掩瑜甚至在此处无关紧要)。
-
Bag-of-words模型的应用
Bag-of-words模型的适用场合
现在想象在一个巨大的文档集合D,里面一共有M个文档,而文档里面的所有单词提取出来后,一起构成一个包含N个单词的词典,利用Bag-of-words模型,每个文档都可以被表示成为一个N维向量,计算机非常擅长于处理数值向量。这样,就可以利用计算机来完成海量文档的分类过程。
考虑将Bag-of-words模型应用于图像表示。为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。

图1 将Bag-of-words模型应用于图像表示
由于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:(1)特征检测,(2)特征表示,(3)单词本的生成,请看下图2:
图2 从图像中提取出相互独立的视觉词汇
通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
而SIFT算法是提取图像中局部不变特征的应用最广泛的算法,因此我们可以用SIFT算法从图像中提取不变特征点,作为视觉词汇,并构造单词表,用单词表中的单词表示一幅图像。
Bag-of-words模型应用三步
接下来,我们通过上述图像展示如何通过Bag-of-words模型,将图像表示成数值向量。现在有三个目标类,分别是人脸、自行车和吉他。
Bag-of-words模型的第一步是利用SIFT算法,从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起,如下图3所示:

图3 从每类图像中提取视觉词汇
第二步是利用K-Means算法构造单词表。K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为4,那么单词表的构造过程如下图4所示: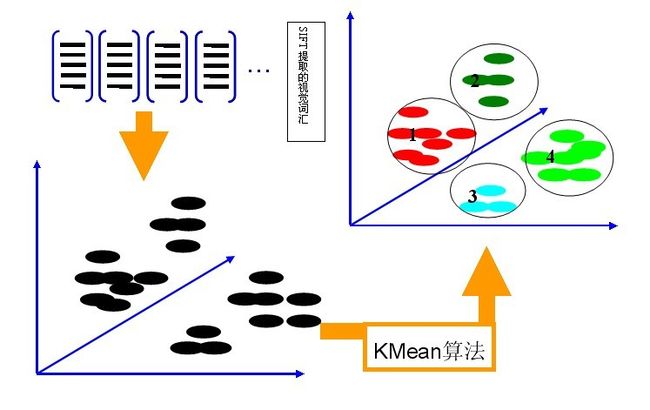
图4 利用K-Means算法构造单词表
第三步是利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。请看下图5:
图5 每幅图像的直方图表示
上图5中,我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示(我们假定存在误差,实际情况亦不外如此):
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。
需要说明的是,以上过程只是针对三个目标类非常简单的一个示例,实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,并且目标类数目越多,对应的K值也越大,一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
下面,我们再来总结一下如何利用Bag-of-words模型将一幅图像表示成为数值向量:
-
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
-
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
-
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
下面我们按照以上步骤,用C++一步步实现上述过程。
-
C++逐步实现:Bag-of-words模型表示一幅图像
在具体编码之前,我们需要事先搭配开发环境。
一. 搭建开发环境
使用的开发平台是windows xp sp3 + vs2010(windows xp sp3 + vc6.0的情况,请参考此文:九(续)、sift算法的编译与实现)
1. 从Rob Hess的个人主页:http://blogs.oregonstate.edu/hess/code/sift/,下载最新版本的sift开源库源代码sift-latest_win.zip;
2. 由于sift-latest_win.zip 要求的opencv版本是2.0以上,也下载最新版本 OpenCV-2.2.0-win32-vs2010.exe,运行安装程序将opencv安装在本地某路径下。例如,我安装在D盘根目录下。
3. 运行vs2010,建立一个空的控制台应用程序,取名bow。
4. 配置opencv环境。在vs2010下选择project菜单下的bow property子菜单,调出bow property pages对话框,需要配置的地方有三处:在vc++ Directory选项里需要配置Include Directories和Library Directories,在Linker选项卡的Input选项里需要配置Additional Dependencies。

至此,开发环境全部搭建并配置完毕。
二.创建c++类CSIFTDiscriptor
为了方便使用,我们将SIFT库用C++类CSIFTDiscriptor封装,该类可以计算并获取指定图像的特征点向量集合。类的声名在SIFTDiscriptor.h文件中,内容如下:
- #ifndef _SIFT_DISCRIPTOR_H_
- #define _SIFT_DISCRIPTOR_H_
- #include
- #include
- #include
- extern "C"
- {
- #include "../sift/sift.h"
- #include "../sift/imgfeatures.h"
- #include "../sift/utils.h"
- };
- class CSIFTDiscriptor
- {
- public:
- int GetInterestPointNumber()
- {
- return m_nInterestPointNumber;
- }
- struct feature *GetFeatureArray()
- {
- return m_pFeatureArray;
- }
- public :
- void SetImgName(const std::string &strImgName)
- {
- m_strInputImgName = strImgName;
- }
- int CalculateSIFT();
- public:
- CSIFTDiscriptor(const std::string &strImgName);
- CSIFTDiscriptor()
- {
- m_nInterestPointNumber = 0;
- m_pFeatureArray = NULL;
- }
- ~CSIFTDiscriptor();
- private:
- std::string m_strInputImgName;
- int m_nInterestPointNumber;
- feature *m_pFeatureArray;
- };
- #endif
成员函数实现在SIFTDiscriptor.cpp文件中,其中,CalculateSIFT函数完成特征点的提取和计算,其主要内部流程如下:
1) 调用OpenCV函数cvLoadImage加载输入图像;
2) 为了统一输入图像的尺寸,CalculateSIFT函数的第二步是调整输入图像的尺寸,这通过调用cvResize函数实现;
3) 如果输入图像是彩色图像,我们需要首先将其转化成灰度图,这通过调用cvCvtColor函数实现;
4) 调用SIFT库函数sift_feature获取输入图像的特征点向量集合和特征点个数。
- #include "SIFTDiscriptor.h"
- int CSIFTDiscriptor::CalculateSIFT()
- {
- IplImage *pInputImg = cvLoadImage(m_strInputImgName.c_str());
- if (!pInputImg)
- {
- return -1;
- }
- int nImgWidth = 320; //训练用标准图像大小
- double dbScaleFactor = pInputImg->width / 300.0; //缩放因子
- IplImage *pTmpImg = cvCreateImage(cvSize(pInputImg->width / dbScaleFactor, pInputImg->height / dbScaleFactor),
- pInputImg->depth, pInputImg->nChannels);
- cvResize(pInputImg, pTmpImg); //缩放
- cvReleaseImage(&pInputImg);
- if (pTmpImg->nChannels != 1) //非灰度图
- {
- IplImage *pGrayImg = cvCreateImage(cvSize(pTmpImg->width, pTmpImg->height),
- pTmpImg->depth, 1);
- cvCvtColor(pTmpImg, pGrayImg, CV_RGB2GRAY);
- m_nInterestPointNumber = sift_features(pGrayImg, &m_pFeatureArray);
- cvReleaseImage(&pGrayImg);
- }
- else
- {
- m_nInterestPointNumber = sift_features(pTmpImg, &m_pFeatureArray);
- }
- cvReleaseImage(&pTmpImg);
- return m_nInterestPointNumber;
- }
- CSIFTDiscriptor::CSIFTDiscriptor(const std::string &strImgName)
- {
- m_strInputImgName = strImgName;
- m_nInterestPointNumber = 0;
- m_pFeatureArray = NULL;
- CalculateSIFT();
- }
- CSIFTDiscriptor::~CSIFTDiscriptor()
- {
- if (m_pFeatureArray)
- {
- free(m_pFeatureArray);
- }
- }
三.创建c++类CImgSet,管理实验图像集合
Bag-of-words模型需要从多个目标类图像中提取视觉词汇,不同目标类的图像存储在不同子文件夹中,为了方便操作,我们设计了一个专门的类CImgSet用来管理图像集合,声明在文件ImgSet.h中:
- #ifndef _IMG_SET_H_
- #define _IMG_SET_H_
- #include
- #include
- #pragma comment(lib, "shlwapi.lib")
- class CImgSet
- {
- public:
- CImgSet (const std::string &strImgDirName) : m_strImgDirName(strImgDirName+"//"), m_nImgNumber(0){}
- int GetTotalImageNumber()
- {
- return m_nImgNumber;
- }
- std::string GetImgName(int nIndex)
- {
- return m_szImgs.at(nIndex);
- }
- int LoadImgsFromDir()
- {
- return LoadImgsFromDir("");
- }
- private:
- int LoadImgsFromDir(const std::string &strDirName);
- private:
- typedef std::vector
- IMG_SET m_szImgs;
- int m_nImgNumber;
- const std::string m_strImgDirName;
- };
- #endif
- //成员函数实现在文件ImgSet.cpp中:
- #include "ImgSet.h"
- #include
- #include
- /**
- strSubDirName:子文件夹名
- */
- int CImgSet::LoadImgsFromDir(const std::string &strSubDirName)
- {
- WIN32_FIND_DATAA stFD = {0};
- std::string strDirName;
- if ("" == strSubDirName)
- {
- strDirName = m_strImgDirName;
- }
- else
- {
- strDirName = strSubDirName;
- }
- std::string strFindName = strDirName + "//*";
- HANDLE hFile = FindFirstFileA(strFindName.c_str(), &stFD);
- BOOL bExist = FindNextFileA(hFile, &stFD);
- for (;bExist;)
- {
- std::string strTmpName = strDirName + stFD.cFileName;
- if (strDirName + "." == strTmpName || strDirName + ".." == strTmpName)
- {
- bExist = FindNextFileA(hFile, &stFD);
- continue;
- }
- if (PathIsDirectoryA(strTmpName.c_str()))
- {
- strTmpName += "//";
- LoadImgsFromDir(strTmpName);
- bExist = FindNextFileA(hFile, &stFD);
- continue;
- }
- std::string strSubImg = strDirName + stFD.cFileName;
- m_szImgs.push_back(strSubImg);
- bExist = FindNextFileA(hFile, &stFD);
- }
- m_nImgNumber = m_szImgs.size();
- return m_nImgNumber;
- }
LoadImgsFromDir递归地从图像文件夹中获取所有实验用图像名,包括子文件夹。该函数内部通过循环调用windows API函数FindFirstFile和FindNextFile来找到文件夹中所有图像的名称。
四.创建CHistogram,生成图像的直方图表示
- //ImgHistogram.h
- #ifndef _IMG_HISTOGRAM_H_
- #define _IMG_HISTOGRAM_H_
- #include
- #include "SIFTDiscriptor.h"
- #include "ImgSet.h"
- const int cnClusterNumber = 1500;
- const int ciMax_D = FEATURE_MAX_D;
- class CHistogram
- {
- public:
- void SetTrainingImgSetName(const std::string strTrainingImgSet)
- {
- m_strTrainingImgSetName = strTrainingImgSet;
- }
- int FormHistogram();
- CvMat CalculateImgHistogram(const string strImgName, int pszImgHistogram[]);
- CvMat *GetObservedData();
- CvMat *GetCodebook()
- {
- return m_pCodebook;
- }
- void SetCodebook(CvMat *pCodebook)
- {
- m_pCodebook = pCodebook;
- m_bSet = true;
- }
- public:
- CHistogram():m_pszHistogram(0), m_nImgNumber(0), m_pObservedData(0), m_pCodebook(0), m_bSet(false){}
- ~CHistogram()
- {
- if (m_pszHistogram)
- {
- delete m_pszHistogram;
- m_pszHistogram = 0;
- }
- if (m_pObservedData)
- {
- cvReleaseMat(&m_pObservedData);
- m_pObservedData = 0;
- }
- if (m_pCodebook && !m_bSet)
- {
- cvReleaseMat(&m_pCodebook);
- m_pCodebook = 0;
- }
- }
- private :
- bool m_bSet;
- CvMat *m_pCodebook;
- CvMat *m_pObservedData;
- std::string m_strTrainingImgSetName;
- int (*m_pszHistogram)[cnClusterNumber];
- int m_nImgNumber;
- };
- #endif
- #include "ImgHistogram.h"
- int CHistogram::FormHistogram()
- {
- int nRet = 0;
- CImgSet iImgSet(m_strTrainingImgSetName);
- nRet = iImgSet.LoadImgsFromDir();
- const int cnTrainingImgNumber = iImgSet.GetTotalImageNumber();
- m_nImgNumber = cnTrainingImgNumber;
- CSIFTDiscriptor *pDiscriptor = new CSIFTDiscriptor[cnTrainingImgNumber];
- int nIPNumber(0) ;
- for (int i = 0; i < cnTrainingImgNumber; ++i) //计算每一幅训练图像的SIFT描述符
- {
- const string strImgName = iImgSet.GetImgName(i);
- pDiscriptor[i].SetImgName(strImgName);
- pDiscriptor[i].CalculateSIFT();
- nIPNumber += pDiscriptor[i].GetInterestPointNumber();
- }
- double (*pszDiscriptor)[FEATURE_MAX_D] = new double[nIPNumber][FEATURE_MAX_D]; //存储所有描述符的数组。每一行代表一个IP的描述符
- ZeroMemory(pszDiscriptor, sizeof(int) * nIPNumber * FEATURE_MAX_D);
- int nIndex = 0;
- for (int i = 0; i < cnTrainingImgNumber; ++i) //遍历所有图像
- {
- struct feature *pFeatureArray = pDiscriptor[i].GetFeatureArray();
- int nFeatureNumber = pDiscriptor[i].GetInterestPointNumber();
- for (int j = 0; j < nFeatureNumber; ++j) //遍历一幅图像中所有的IP(Interesting Point兴趣点
- {
- for (int k = 0; k < FEATURE_MAX_D; k++)//初始化一个IP描述符
- {
- pszDiscriptor[nIndex][k] = pFeatureArray[j].descr[k];
- }
- ++nIndex;
- }
- }
- CvMat *pszLabels = cvCreateMat(nIPNumber, 1, CV_32SC1);
- //对所有IP的描述符,执行KMeans算法,找到cnClusterNumber个聚类中心,存储在pszClusterCenters中
- if (!m_pCodebook) //构造码元表
- {
- CvMat szSamples,
- *pszClusterCenters = cvCreateMat(cnClusterNumber, FEATURE_MAX_D, CV_32FC1);
- cvInitMatHeader(&szSamples, nIPNumber, FEATURE_MAX_D, CV_32FC1, pszDiscriptor);
- cvKMeans2(&szSamples, cnClusterNumber, pszLabels,
- cvTermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, 10, 1.0 ),
- 1, (CvRNG *)0, 0, pszClusterCenters); //
- m_pCodebook = pszClusterCenters;
- }
- m_pszHistogram = new int[cnTrainingImgNumber][cnClusterNumber]; //存储每幅图像的直方图表示,每一行对应一幅图像
- ZeroMemory(m_pszHistogram, sizeof(int) * cnTrainingImgNumber * cnClusterNumber);
- //计算每幅图像的直方图
- nIndex = 0;
- for (int i = 0; i < cnTrainingImgNumber; ++i)
- {
- struct feature *pFeatureArray = pDiscriptor[i].GetFeatureArray();
- int nFeatureNumber = pDiscriptor[i].GetInterestPointNumber();
- // int nIndex = 0;
- for (int j = 0; j < nFeatureNumber; ++j)
- {
- // CvMat szFeature;
- // cvInitMatHeader(&szFeature, 1, FEATURE_MAX_D, CV_32FC1, pszDiscriptor[nIndex++]);
- // double dbMinimum = 1.79769e308;
- // int nCodebookIndex = 0;
- // for (int k = 0; k < m_pCodebook->rows; ++k)//找到距离最小的码元,用最小码元代替原//来的词汇
- // {
- // CvMat szCode = cvMat(1, m_pCodebook->cols, m_pCodebook->type);
- // cvGetRow(m_pCodebook, &szCode, k);
- // double dbDistance = cvNorm(&szFeature, &szCode, CV_L2);
- // if (dbDistance < dbMinimum)
- // {
- // dbMinimum = dbDistance;
- // nCodebookIndex = k;
- // }
- // }
- int nCodebookIndex = pszLabels->data.i[nIndex++]; //找到第i幅图像中第j个IP在Codebook中的索引值nCodebookIndex
- ++m_pszHistogram[i][nCodebookIndex]; //0
- }
- }
- //资源清理,函数返回
- // delete []m_pszHistogram;
- // m_pszHistogram = 0;
- cvReleaseMat(&pszLabels);
- // cvReleaseMat(&pszClusterCenters);
- delete []pszDiscriptor;
- delete []pDiscriptor;
- return nRet;
- }
- //double descr_dist_sq( struct feature* f1, struct feature* f2 );
- CvMat CHistogram::CalculateImgHistogram(const string strImgName, int pszImgHistogram[])
- {
- if ("" == strImgName || !m_pCodebook || !pszImgHistogram)
- {
- return CvMat();
- }
- CSIFTDiscriptor iImgDisp;
- iImgDisp.SetImgName(strImgName);
- iImgDisp.CalculateSIFT();
- struct feature *pImgFeature = iImgDisp.GetFeatureArray();
- int cnIPNumber = iImgDisp.GetInterestPointNumber();
- // int *pszImgHistogram = new int[cnClusterNumber];
- // ZeroMemory(pszImgHistogram, sizeof(int)*cnClusterNumber);
- for (int i = 0; i < cnIPNumber; ++i)
- {
- double *pszDistance = new double[cnClusterNumber];
- CvMat iIP = cvMat(FEATURE_MAX_D, 1, CV_32FC1, pImgFeature[i].descr);
- for (int j = 0; j < cnClusterNumber; ++j)
- {
- CvMat iCode = cvMat(1, FEATURE_MAX_D, CV_32FC1);
- cvGetRow(m_pCodebook, &iCode, j);
- CvMat *pTmpMat = cvCreateMat(FEATURE_MAX_D, 1, CV_32FC1);
- cvTranspose(&iCode, pTmpMat);
- double dbDistance = cvNorm(&iIP, pTmpMat); //计算第i个IP与第j个code之间的距离
- pszDistance[j] = dbDistance;
- cvReleaseMat(&pTmpMat);
- }
- double dbMinDistance = pszDistance[0];
- int nCodebookIndex = 0; //第i个IP在codebook中距离最小的code的索引值
- for (int j = 1; j < cnClusterNumber; ++j)
- {
- if (dbMinDistance > pszDistance[j])
- {
- dbMinDistance = pszDistance[j];
- nCodebookIndex = j;
- }
- }
- ++pszImgHistogram[nCodebookIndex];
- delete []pszDistance;
- }
- CvMat iImgHistogram = cvMat(cnClusterNumber, 1, CV_32SC1, pszImgHistogram);
- return iImgHistogram;
- }
- CvMat *CHistogram::GetObservedData()
- {
- CvMat iHistogram;
- cvInitMatHeader(&iHistogram, m_nImgNumber, cnClusterNumber, CV_32SC1, m_pszHistogram);
- CvMat *m_pObservedData = cvCreateMat(iHistogram.cols, iHistogram.rows, CV_32SC1);
- cvTranspose(&iHistogram, m_pObservedData);
- return m_pObservedData;
- }