神经网络(Neural Network)
1 引言
机器学习(Machine Learning)有很多经典的算法,其中基于深度神经网络的深度学习算法目前最受追捧,主要是因为其因为击败李世石的阿尔法狗所用到的算法实际上就是基于神经网络的深度学习算法。本文先介绍基本的神经元,然后简单的感知机,扩展到多层神经网络,多层前馈神经网络,其他常见的神经网络,接着介绍基于深度神经网络的深度学习,纸上得来终觉浅,本文最后用python语言自己编写一个多层前馈神经网络。
2 神经元模型
这是生物大脑中的基本单元——神经元。


在这个模型中,神经元接受到来自n个其他神经元传递过来的输入信号,在这些输入信号通过带权重的连接进行传递,神经元接受到的总输入值将与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出。

3 感知机与多层网络
感知机由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元。

要解决非线性可分问题,需考虑使用多层神经元功能。每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接。这样的神经网络结构通常称为“多层前馈神经网络”。
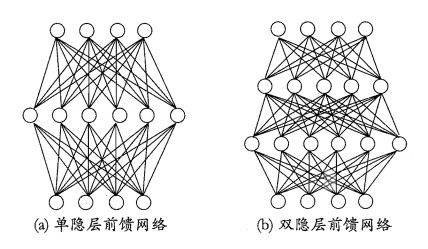
神经网络的学习过程,就是根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的阈值;换言之,神经网络“学”到的东西,蕴涵在连接权与阈值之中。
4 误差逆传播算法

网络在![]() 上的均方误差为:
上的均方误差为:

正是由于其强大的表达能力,BP神经网络经常遭遇过拟合,其训练过程误差持续降低,但测试误差却可能上升。有两种策略常用来缓解BP网络过拟合。第一种策略是“早停”:将数据分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值。第二种策略是“正则化”,其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分。
5 全局最小与局部极小
若用Ε表示神经网络在训练集上的误差,则它显然关于连接权ω和阈值θθ的函数。此时,神经网络的训练过程可看作一个参数寻优的过程,即在参数空间中,寻找最优参数使得E最小。
6 其他常见的神经网络
- RBF网络
- ART网络
- SOM网络
- 级联相关网络
- Elman网络
- Boltzmann机
7 深度学习
典型的深度学习就是很深层的神经网络,显然,对神经网络模型,提高容量的简单方法是增加隐层,隐层多了,相应的神经元连接权、阈值等参数就会更多。模型复杂度也可以通过单纯增加隐层神经元的数目来实现。
深度学习的多隐层堆叠,每层对上一层的输出进行处理的机制,可看作是在对输入信号进行逐层加工,从而把初始的,与输出目标之间联系不太密切的输入表示,转换为与输出目标联系更密切的表示,使得原来仅基于最后一层输出映射难以完成的任务成为可能。换言之,通过多层处理,逐渐将初始的“低层”特征表示转换为“高层”特征表示后,用“简单模型”即可完成复杂的分类任务,由此可将深度学习理解为进行“特征学习”或“表示学习”。
8 使用python制作神经网络
让我们勾勒神经网络类的大概样子,我们知道它应该至少有三个函数:
- 初始化函数——设置输入层节点、隐藏层节点和输出层节点
- 训练——学习给定训练集样本后,优化权重
- 查询——给定输入,从输出节点给出答案

# 神经网络类
class neuralNetwork:
# 初始化网络
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
#链接权重矩阵
self.wih = numpy.random.normal(0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.onodes, self.hnodes))
# learning rate
self.lr = learningrate
self.activation_function = lambda x: 1/(1+numpy.exp(-x))
pass
# 训练网络
def train(self, inputs_list, targets_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
final_outputs = self.activation_function(final_inputs)
# output layer error is the (target - actual)
output_errors = targets - final_outputs
# hidden layer error is the output_errors, split by weights, recombined at hidden nodes
hidden_errors = numpy.dot(self.who.T, output_errors)
# update the weights for the links between the hidden and output layers
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs))
# update the weights for the links between the input and hidden layers
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), numpy.transpose(inputs))
pass
# 查询网络
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
final_outputs = self.activation_function(final_inputs)
return final_outputs
手写数字的数据集MNIST
training_data_file = open("mnist_dataset/mnist_train.csv", 'r')
training_data_list = training_data_file.readlines()
training_data_file.close()
训练数据集
epochs = 5
for e in range(epochs):
# go through all records in the training data set
for record in training_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# scale and shift the inputs
# 输入值需要避免0,输出值需要避免1
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# create the target output values (all 0.01, except the desired label which is 0.99)
targets = numpy.zeros(output_nodes) + 0.01
# all_values[0] is the target label for this record
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
pass
pass
测试数据集
test_data_file = open("mnist_dataset/mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
scorecard = []
# go through all the records in the test data set
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
# scale and shift the inputs
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = numpy.argmax(outputs)
# append correct or incorrect to list
if (label == correct_label):
# network's answer matches correct answer, add 1 to scorecard
scorecard.append(1)
else:
# network's answer doesn't match correct answer, add 0 to scorecard
scorecard.append(0)
pass
pass
# calculate the performance score, the fraction of correct answers
scorecard_array = numpy.asarray(scorecard)
print ("performance = ", scorecard_array.su
m() / scorecard_array.size)