大数据之HBase数据库
一、了解HBase
1.1 HBase简介
-
HBase是Apache的Hadoop项目的子项目
-
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库
-
建立在Hadoop文件系统之上的分布式面向列的数据库
-
属于开源项目,可以进行横向扩展
-
适用于需要实时地随机访问超大规模数据集的场景
-
不支持关系型数据库的SQL,是以键值对的方式按列存储
1.2 HBase与Hadoop之间的关系非常紧密
-
Hadoop的HDFS提供了高可靠性的底层存储支持
-
Hadoop MapReduce为HBase提供了高性能的计算能力
-
Zookeeper为HBase提供了稳定性及failover机制的保障
1.3 HBase和HDFS的比较
| HBase | HDFS |
|---|---|
| 是建立在HDFS之上的数据库 | 适于存储大容量文件的分布式文件系统 |
| 提供在较大的表快速查找 | 不支持快速单独记录查找 |
| 提供了数十亿条记录低延迟访问单行记录(随机存取) | 提供了高延迟批量处理,没有批处理概念 |
| 内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找 | 提供的数据只能顺序访问 |
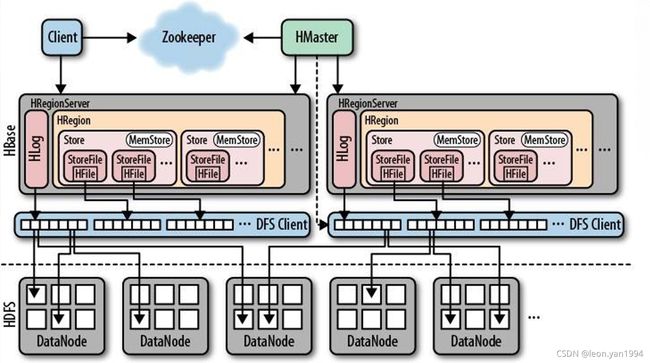
1.4 HBase体系结构
-
是Master/Slaves的主从结构,由一个HMaster和多个HRegionServer构成
-
所有服务器都是通过ZooKeeper来进行协调并处理各服务器运行期间可能遇到的错误
-
HMaster负责管理所有的HRegionServer
-
HRegionServer负责存储许多HRegion
-
HRegion是对HBase逻辑表的分块
1.4.1 HBase体系模块详解:
-
Hregion
-
HBase 使用表( Table)存储数据集,表由行和列组成
-
当表的大小超过设定值时,HBase 会自动将表划分为不同的区域(Region)。每个区域称为 HRegion, 它是 HBase 集群上分布式存储和负载均衡的最小单位
-
刚开始一个表只有一个 Hregion。随着 HRegion 开始变大,直到超出设定的大小阈值, 便会在某行的边界上把表分成两个大小基本相同的 HRegion, 称为HRegion 分裂
-
HStore 由两部分组成: MemStore 和StoreFile。用户写入的数据首先放入 MemStore,当 MemStore 满了以后再刷入(flush) StoreFile。StoreFile 是 HBase 中的最小存储单元,底层最终由 HFile 实现,而 HFile 是键值对数据的存储格式,实质是 HDFS 的二进制格式文件。
-
HBase 中不能直接更新和删除数据,所有的数据均通过追加的方式进行更新。当StoreFile 的数量超过设定的阈值将触发合并操作, 将多个 StoreFile 合并为一个StoreFile,此时进行数据的更新和删除。
-

-
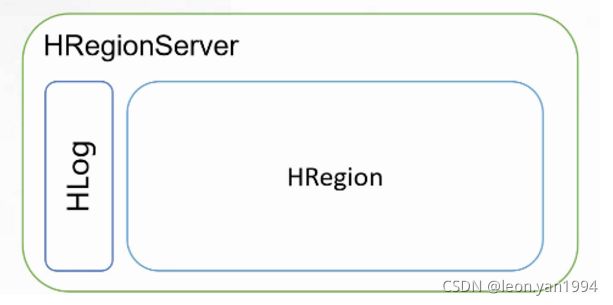
HRegionServer
-
HRegionServer 负责响应用户 I/O 请求,向 HDFS 中读写数据,一台机器上只运行一个 HRegionServer。
-
HRegionServer 包含两部分:HLog 部分和 HRegion 部分。
-
HLog 用于存储数据日志,实质是 HDFS 的 Sequence File。到达 HRegion 的写操作首先被追加到日志中, 然后才被加入内存中的 MemStore。HLog 文件主要用于故障恢复。例如某台 HRegionServer 发生故障,那么它所维护的 HRegion 会被重新分配到新的机器上,新的 HRegionServer 在加载 HRegion 的时候可以通过 HLog 对数据进行恢复。
-
HRegion 部分由多个 HRegion 组成,每个 HRegion 对应了表中的一个分块,并且每一个 HRegion 只会被一个 HRegionServer 管理。
-
-
HMaster
-
是hbase主/从集群架构中的中央节点
-
每台 HRegionServer 都会和 HMaster 服务器通信, HMaster 的主要任务就是告诉每个 HRegionServer 它要维护的 HRegion;
-
在 HBase 中可以启动多个 HMaster;
-
通过 ZooKeeper 的 Master 选举机制来保证系统中总有一个 Master 在运行。
-
HMaster 的具体功能包括:
-
管理用户对表的增、删、改、查操作;
-
管理 HRegionServer 的负载均衡,调整 HRegion 分布;
-
在 HRegion 分裂后, 负责新的 HRegion 分配;
-
在 HRegionServer 停机后, 负责失效 HRegionServer 上的 HRegion 迁移。
-
-
-
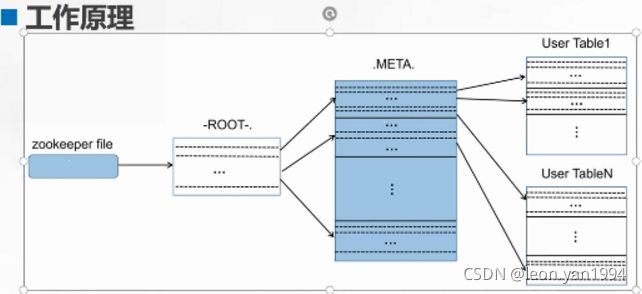
ZooKeeper
-
ZooKeeper 存储的是 HBase 中的 ROOT 表和 META 表的位置
-
元数据表( META)
-
META 表记录普通用户表的 HRegion 标识符信息
-
每个 HRegion 的标识符为:表名+开始主键+唯一 ID
-
-
根数据表( ROOT)
-
保存 META 的 HRegion 信息
-
ROOT 表是不能被分割的,也就是 ROOT 表只有一个 HRegion
-
-
1.5 HBase数据模型
-
数据模型
-
表(Table):是一个稀疏表(不存储值为 NULL 的数据),表的索引是行关键字、列关键字和时间戳。
-
行关键字(Row Key): 行的主键,唯一标识一行数据, 也称行键。表中的行根据行键进行字典排序,所有对表的访问都要通过表的行键。在创建表时, 行键不用、也不能预先定义。而在对表数据进行操作时必须指定行键,行键在添加数据时首次被确定。
-
列族( Column Family):行中的列被分为“列族”。同一个列族的所有成员具有相同的列族前缀。例如“course:math”和“course:art”都是列族“course”的成 员。一个表的列族必须在创建表时预先定义,列族名称不能包含 ASCII 控制字符(ASCII 码在 0~31 间外加 127)和冒号(:)。
-
列关键字(Column Key):也称列、列键。语法格式为:
: 其中:family 是列族名,用于表示列族前缀;qualifier 是列族修饰符, 表示列族中的一个成员。
-
存储单元格(Cell):在 HBase 中,值是作为一个单元保存在系统中。要定位一个单元,需要使用“行键+列键+时间戳”三个要素。
-
时间戳(Timestamp):插入单元格时的时间戳。默认作为单元格的版本号。 下面结合 HBase 的概念视图进一步体会这些术语。
-
-
概念视图
-
物理视图
1.6 HBase与关系数据库对比
| HBase | 关系型数据库 | |
|---|---|---|
| 数据类型 | 只有简单的字符串类型,它只保存字符串 | 有丰富的类型选择和存储方式 |
| 数据操作 | 只有简单的插入、查询、删除、清空等操作,表之间没有关联操作 | 有多种连接操作 |
| 存储模式 | 基于列存储的,每个列族都由几个文件保存。不同列族的文件是分离的 | 基于表格结构和行模式存储 |
| 数据维护 | 更新操作实际上是插入了新的数据,它的旧版本依然会保留 | 更新操作的替换修改 |
| 可伸缩性 | 具体有良好的可伸缩性 | 需要增加中间层才能实现类似的功能 |
二、了解Hive和Spark
在实际运用中,通常采用 Hadoop+Spark+Hive(MapReduce)的解决方案。利用 Hadoop 的 HDFS 解决分布式存储问题; 利用 MapReduce 或 Hive 解决离线计算问题;利用 Spark 解决实时计算;最后利用 HBase 来解决实时查询的问题。
2.1 Hive介绍
-
是Hadoop中的一个重要子项目
-
优势
可以利用MapReduce编程技术 提供了类似SQL的编程接口 实现部分SQL(结构化查询语句)语句的功能
-
定义了类SQL的语言:HiveQL
-
将外部命令解析成一个MapReduce作业,再提交到Hadoop集群进行处理
2.2 Spark介绍
-
Apache Spark 是一个大数据处理引擎
-
Spark也提供了类似MapReduce的处理
-
Spark没有提供文件管理系统,所以它必须和其它的分布式文件系统进行集成才能运行
-
优势
高效
易用 与Hadoop集成
三、部署HBase
基础环境
-
修改主机名
hostnamectl set-hostname node1 hostnamectl set-hostname node2 hostnamectl set-hostname node3
-
所有节点添加hosts解析
cat >> /etc/hosts << EOF 172.16.10.10 node1 172.16.10.11 node2 172.16.10.12 node3 EOF
-
关闭防火墙
systemctl stop firewalld systemctl disable firewalld
-
关闭内核安全机制
sed -i "s/.*SELINUX=.\*/SELINUX=disabled/g" /etc/selinux/config
-
时间同步
yum -y install chrony systemctl start chronyd chronyc sources -v
3.1 部署Hadoop环境
3.1.1 创建用户和组
-
所有node节点都需要执行
# 创建Hadoop组 groupadd hadoop # 创建hduser用户 useradd -g hadoop hduser # 为hduser用户设置密码 passwd hduser 更改用户 hduser 的密码 。 新的 密码: 无效的密码: 密码少于 8 个字符 重新输入新的密码: passwd:所有的身份验证令牌已经成功更新。 # 为hduser用户添加sudo权限 vim /etc/sudoers 在 root ALL=(ALL) ALL 下面添加如下内容: hduser ALL=(ALL) NOPASSWD:ALL ## 保存是需要使用 :wq!
3.1.2 部署JDK环境
-
所有node节点都需要执行
# 上传安装包并安装 rpm -ivh jdk-8u171-linux-x64.rpm # 配置环境变量 echo 'export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64' >> /etc/profile echo 'export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH' >> /etc/profile echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile # 刷新环境变量 source /etc/profile # 查看Java版本 java -version
3.1.3 配置免密登录
-
仅在node1节点执行
ssh-keygen ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3
3.1.4 安装配置Hadoop
-
所有node节点都需要执行
# 安装Hadoop tar zxf hadoop-2.6.5.tar.gz -C /home/hduser/ # 修改目录名 mv /home/hduser/hadoop-2.6.5/ /home/hduser/hadoop # 配置环境变量 cat >> /etc/profile << 'EOF' export HADOOP_HOME=/home/hduser/hadoop export PATH=$HADOOP_HOME/bin:$PATH EOF # 刷新环境变量 source /etc/profile
3.1.5 修改Hadoop相关配置文件
# 编辑/home/hduser/hadoop/etc/hadoop/hadoop-env.sh 文件 vim /home/hduser/hadoop/etc/hadoop/hadoop-env.sh # 注释掉原本的export JAVA_HOME,然后再添加下面内容: export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64 # 编辑/home/hduser/hadoop/etc/hadoop/yarn-env.sh 文件 vim /home/hduser/hadoop/etc/hadoop/yarn-env.sh # 添加下面内容: export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64 # 编辑/home/hduser/hadoop/etc/hadoop/slaves 文件 vim /home/hduser/hadoop/etc/hadoop/slaves ##清空原内容,然后输入如下内容 node2 node3 # 编辑/home/hduser/hadoop/etc/hadoop/core-site.xml ##该文件是 Hadoop 全局配置 vim /home/hduser/hadoop/etc/hadoop/core-site.xml # 末行添加:# 编辑/home/hduser/hadoop/etc/hadoop/hdfs-site.xml ##该文件是 HDFS 的配置 vim /home/hduser/hadoop/etc/hadoop/hdfs-site.xml # 末行添加: fs.defaultFS hdfs://node1:9000 hadoop.tmp.dir file:/home/hduser/hadoop/tmp # 编辑/home/hduser/hadoop/etc/hadoop/mapred-site.xml ##该文件是 MapReduce的配置,可从模板文件 mapred-site.xml.template 复制 cp /home/hduser/hadoop/etc/hadoop/mapred-site.xml.template /home/hduser/hadoop/etc/hadoop/mapred-site.xml vim /home/hduser/hadoop/etc/hadoop/mapred-site.xml # 末行添加: dfs.namenode.secondary.http-address node1:50090 dfs.namenode.name.dir file:/home/hduser/hadoop/dfs/name dfs.datanode.data.dir file:/home/hduser/hadoop/dfs/data dfs.replication 2 dfs.webhdfs.enabled true # 编辑/home/hduser/hadoop/etc/hadoop/yarn-site.xml ##如果在 mapred-site.xml配置了使用YARN框架,那么YARN框架使用此文件中的配置 vim /home/hduser/hadoop/etc/hadoop/yarn-site.xml # 末行添加: mapreduce.framework.name yarn mapreduce.jobhistory.address node1:10020 mapreduce.jobhistory.webapp.address node1:19888 ## 将修改完的配置文件推送分别到node2、node3节点 scp -r /home/hduser/hadoop/* node2:/home/hduser/ scp -r /home/hduser/hadoop/* node3:/home/hduser/ yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address node1:8032 yarn.resourcemanager.scheduler.address node1:8030 yarn.resourcemanager.resource-tracker.address node1:8035 yarn.resourcemanager.admin.address node1:8033 yarn.resourcemanager.webapp.address node1:8088
3.1.6 Hadoop相关管理
# 切换到Hadoop安装目录下 cd /home/hduser/hadoop/ # 格式化,必须要做的!! bin/hdfs namenode -format # 启动hdfs sbin/start-dfs.sh # 启动yarn sbin/start-yarn.sh # 也可以使用start-all.sh全部启动 sbin/start-all.sh # 全部停止 sbin/stop-all.sh # 查看集群状态 bin/hdfs dfsadmin -report # 查看Java进程 jps # 查看50070端口 netstat -nlpt | grep 50070
3.2 部署HBase
-
所有node节点都需要执行
3.2.1 安装HBase
tar zxf hbase-1.0.2-bin.tar.gz -C /home/hduser/
3.2.2 修改配置文件
# 修改/home/hduser/hbase-1.0.2/conf/hbase-site.xml文件 vim /home/hduser/hbase-1.0.2/conf/hbase-site.xml ##末行添加:# 修改/home/hduser/hbase-1.0.2/conf/hbase-env.sh文件 vim /home/hduser/hbase-1.0.2/conf/hbase-env.sh ##末行添加: export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64 export HADOOP_HOME=/home/hduser/hadoop export HBASE_HOME=/home/hduser/hbase-1.0.2 export HBASE_MANAGES_ZK=true # 修改/home/hduser/hbase-1.0.2/conf/regionservers文件 vim /home/hduser/hbase-1.0.2/conf/regionservers ##添加节点: node2 node3 #将 3个文件分别上传到分节点node2、node3上 scp /home/hduser/hbase-1.0.2/conf/hbase-site.xml node2:/home/hduser/hbase-1.0.2/conf/hbase-site.xml scp /home/hduser/hbase-1.0.2/conf/hbase-site.xml node3:/home/hduser/hbase-1.0.2/conf/hbase-site.xml scp vim /home/hduser/hbase-1.0.2/conf/hbase-env.sh node2:/home/hduser/hbase-1.0.2/conf/hbase-env.sh scp vim /home/hduser/hbase-1.0.2/conf/hbase-env.sh node3:/home/hduser/hbase-1.0.2/conf/hbase-env.sh scp /home/hduser/hbase-1.0.2/conf/regionservers node2:/home/hduser/hbase-1.0.2/conf/regionservers scp /home/hduser/hbase-1.0.2/conf/regionservers node3:/home/hduser/hbase-1.0.2/conf/regionservers hbase.rootdir hdfs://node1:9000/hbase01 配置 HRegionServer 的数据库存储目录 hbase.cluster.distributed true 配置 HBase 为完全分布式 hbase.master node1:60000 配置 HMaster 的地址 hbase.zookeeper.quorum node1,node2,node3 配置 ZooKeeper 集群服务器的位置
3.2.3 启动HBase
-
仅在node1执行
# 切换到HBase可执行目录下 cd /home/hduser/hbase-1.0.2/bin # 启动hbase ./start-hbase.sh
3.3 进入HBase交互环境,并进行相关操作管理
# 进入HBase交互环境
/home/hduser/hbase-1.0.2/bin/hbase shell
hbase(main):001:0> status ## 查看状态
hbase(main):002:0> create 'chengji','nianji','xueke'
# 创建表
##语法: create '表名称','列名称 1’,'列名称 2',…,'列名称 N'
hbase(main):002:0> create 'chengji','nianji','xueke'
# 查看所有表 list
hbase(main):003:0> list
# 查看该表所有列族的详细描述信息 describe
##语法: describe '表名'
hbase(main):004:0> describe 'chengji'
# 向表中添加插入数据 put
##语法: put '表名称','行键','列键','值'
hbase(main):007:0> put 'chengji','zhangsan','xueke:shuxue','80'
# 全表单元扫描 scan
##语法: scan '表名称',{COLUMNS=>['列族名 1','列族名 2'…],参数名=>参数值…}
hbase(main):009:0> scan 'chengji'
# 获取数据 get
##语法: get '表名称','行键'
hbase(main):012:0> get 'chengji','zhangsan'
# 删除数据 delete
##语法: delete '表名称','行键','列键'
hbase(main):013:0> delete 'chengji','zhangsan','xueke:yuwen'
# 删除表 drop
##语法: drop '表名称'
hbase(main):016:0> disable 'chengji' ##先disable禁用表
0 row(s) in 1.2190 seconds
hbase(main):017:0> drop 'chengji' ##再drop删除表
0 row(s) in 0.1750 seconds
hbase(main):016:0> enable 'chengji' ##enable 启动表
3.4 将MapReduce程序和HBase关联
-
所有node节点都需要执行
cp /home/hduser/hbase-1.0.2/conf/hbase-site.xml /home/hduser/hadoop/etc/hadoop/ vi /home/hduser/hadoop/etc/hadoop/hadoop-env.sh ##末行添加以下内容: export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/home/hduser/hbase-1.0.2/lib/* # 将两个文件上传到node2、node3节点 scp /home/hduser/hadoop/etc/hadoop/hbase-site.xml node2:/home/hduser/hadoop/etc/hadoop/hbase-site.xml scp /home/hduser/hadoop/etc/hadoop/hbase-site.xml node3:/home/hduser/hadoop/etc/hadoop/hbase-site.xml scp /home/hduser/hadoop/etc/hadoop/hadoop-env.sh node2:/home/hduser/hadoop/etc/hadoop/hadoop-env.sh scp /home/hduser/hadoop/etc/hadoop/hadoop-env.sh node3:/home/hduser/hadoop/etc/hadoop/hadoop-env.sh
3.5 执行rowcounter程序并查看结果
/home/hduser/hadoop/bin/hadoop jar /home/hduser/hbase-1.0.2/lib/hbase-server-1.0.2.jar rowcounter chengji