数据库搜索解决方案coreseek在windows2008下安装使用-多库,GBK,分区,增量
coreseek是一块免费开源的中文全文检索/搜索软件,是基于sphinx研发的,可以大大的降低服务器运行负载,提高响应速度,可以实现多用户并发操作,,实现多个关键词的复合检索,支持中文分词,比lucene+中文分词的解决方案更精确,至于mysql的like搜索方式,就不做比较了.
1,下载
http://www.coreseek.cn/ 请自行选择win32或者linux版本
2,安装
//coreseek站上有完整的安装说明.可以对照参考
(1)如果是coreseek-4.x版本 请先安装Microsoft Visual C++ 2008 运行环境 (x86)

(2)解压缩下载的coreseek压缩文件,建议放在htdoc里
(3)修改配置文件,路径在 ......htdocs\coreseek\etc\csft_mysql.conf
============================================================
#MySQL数据源配置,详情请查看: http://www.coreseek.cn/products-install/mysql/
#请先将var/test/documents.sql导入数据库,并配置好以下的MySQL用户密码数据库
#源定义
source mysql
{
type = mysql#这里最好用127.0.0.1而不是localhost
sql_host = 127.0.0.1
sql_user = mysqli
sql_pass = 123456
sql_db = qianyu365_database
sql_port = 3306
#预查询,默认为一个空的查询列表,它们被用来设置字符编码,标记待索引的记录,更新内部计数器,设置SQL服务器连接选项和变量等等
sql_query_pre = SET NAMES utf8
#对于MySQL数据源,在预查询中禁用查询缓冲(query cache)(仅对indexer连接)是有用的,因为索引查询一般并会频繁地重新运行,缓冲它们的结果是没有意义的。这可以按如下方法实现:
sql_query_pre = SET SESSION query_cache_type=OFF
#主查询,只能有一个主查询。它被用来从SQL服务器获取文档,
#sql_query第一列字段必须是唯一的正整数值,无需再设置sql_attr_uint
#title、content作为字符串/文本字段,被全文索引
sql_query = SELECT q.qid,q.title,q.sid1,q.sid2,q.uid,q.asktime,q.status,q.answercount,qs.supplement FROM `cyask_question` q left join cyask_question_1 qs on q.qid=qs.qid
#sql_query =select qid,title,sid1,sid2,uid,asktime,status,answercount from cyask_question
#sql_attr_unit是整数属性列,既参与搜索结果,但不会被索引,只用于返回额外的信息,如果要声明字符串属性列可以使用sql_attr_str2ordinal
sql_attr_uint = sid1
sql_attr_uint = sid2
sql_attr_uint = status
sql_attr_uint = answercount
#sql_attr_timestamp列用于对结果进行排序,或者按此字段进行分组
#从SQL读取到的值必须为unix时间戳,作为时间属性,
sql_attr_timestamp = asktime
#命令行查询时,设置正确的字符集
sql_query_info_pre = SET NAMES utf8
#命令行查询时,从数据库读取原始数据信息
sql_query_info = SELECT * FROM cyask_question WHERE qid=$id
}
#index定义
index mysql
{
source = mysql #对应的source名称
path = E:/isweb/htdocs/coreseek/var/data/mysql #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
docinfo = extern
mlock = 0
morphology = none
min_word_len = 1
html_strip = 0
#中文分词配置,详情请查看: http://www.coreseek.cn/products-install/coreseek_mmseg/
#charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾
charset_dictpath = E:/isweb/htdocs/coreseek/etc/ #Windows环境下设置,/符号结尾,最好给出绝对路径,例如:C:/usr/local/coreseek/etc/...
charset_type = zh_cn.utf-8
}
#全局index定义
indexer
{
mem_limit = 128M
}
#searchd服务定义
searchd
{
listen = 9312
read_timeout = 5
max_children = 30
max_matches = 1000
seamless_rotate = 0
preopen_indexes = 0
unlink_old = 1
pid_file = E:/isweb/htdocs/coreseek/var/log/searchd_mysql.pid #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
log = E:/isweb/htdocs/coreseek/var/log/searchd_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
query_log = E:/isweb/htdocs/coreseek/var/log/query_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
binlog_path = #关闭binlog日志
}一, 如果提示Unigram dictionary load Error,检查etc下的uni.lib文件是否存在,如果没有,从压缩包里再拷一个进来,我就莫名其妙的丢了好几次========================================================
二, coreseek的数据库查询按照以下顺序进行
- 连接到数据库;
- 执行预查询 (参见“sql_query_pre”) ,以便完成所有必须的初始设置,比如为MySQL连接设置编码;
- 执行主查询 (参见 “sql_query”) ,其返回的的数据将被索引;
- 执行后查询 (参见 “sql_query_post”) ,以便完成所有必须的清理工作;
- 关闭到数据库的连接;
- 对短语进行排序 (或者学究一点, 索引类型相关的后处理);
- 再次建立到数据库的连接;
- 执行后索引查询 (参见“sql_query_post_index”) i,以便完成所有最终的清理善后工作;
- 再次关闭到数据库的连接.
三,注意set_atrr_uint的设置,上面已做了说明
四,不管你的数据库是什么编码 charset_type只能使用 zh_cn.utf-8来设置,原因

3,测试
进入到coreseek目录
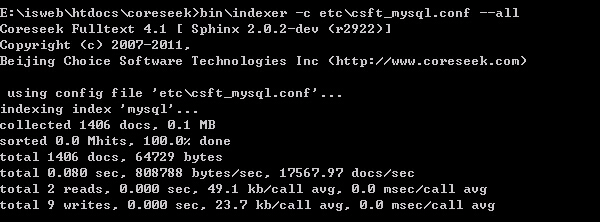
在cmd中执行命令 bin\indexer -c etc\csft_mysql.conf --all
如果看到以下画面说明配置成功

进行命令行搜索测试
bin\search -c etc\csft_mysql.conf
看到以下画面说说明乘成功

在命令行下测试搜索服务端
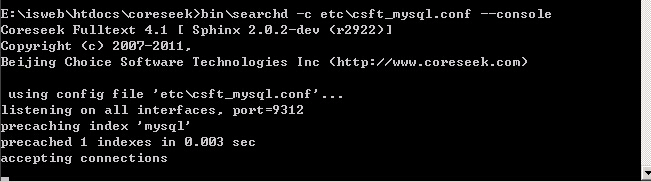
bin\searchd -c etc\csft_mysql.conf --console,停止用ctrl-c
如果出现提示 warning:compat_sphinxql_magics=1 is deprecated ... 将csft_mysql.conf中的searchd中加一句compat_sphinxql_magics=0即可
正常显示为以下状态,如果显示都正常,在进行php连接测试前先不要关闭这个服务

用php进行搜索测试
在htdocs下新建一个php文件
require '../coreseek/api/sphinxapi.php';
$s = new SphinxClient();//这里最好也使用127.0.0.1$s->SetServer('127.0.0.1', 9312);$result = $s->Query('中文');echo "<pre>";print_r($result);正常显示结果的,就可以使用了echo "</pre>";注意,字符编码的问题:无论你的数据库是什么编码,都要设定set names utf8,charset_type也要设定为zh_cn.utf-8,发送搜索请求的页面编码也使用utf-8无dom格式,如果你有使用gbk,请自行转码中文.utf8是保证搜索服务的重要设定.
4,将searchd加入windows服务
E:\isweb\htdocs\coresek\bin\searchd.exe --install --config E:\isweb\htdocs\coreseek\etc\csft_mysql.conf --servicename coorseek-search
在服务器管理中就可以启动或者停止服务
5,分区查询
索引系统需要一次性通过主查询来取得全部文档信息,虽然主索引一般都是在晚上进行,不过一次性的操作也耗费大量的内存和io资源,有可能导致整个表被锁定并使得其他操作被阻止,coreseek提供了区段查询的方法来解决此问 题
在csft_mysql.conf中设置:#取出信息表的最大和最小值sql_query_range = SELECT MIN(id),MAX(id) FROM documents#设置区段的大小sql_range_step = 1000#将主索引改为 $start和$end的范围内,coreseek会自动替换这两个值sql_query = SELECT * FROM documents WHERE id>=$start AND id<=$end#设置分区查询的时间间隔sql_ranged_throttle = 0
6,增量查询
如果整个数据集非常大,以至于难于经常性的重建索引,但是每次新增的记录却相对较少。可以使用主索引+增量索引式来实现“近实时”的索引更新。这需要两个数据源和两个索引,对大量数据建立主索引,而对新增文档建立增量索引。增量索引更新的频率可以非常快,服务器更新索引压力较轻松,可以建立一个计数表,记录主索引的更新位置,增量索引则在此位置之外进行索引操作在csft_mysql.conf主索引数据源source中设置:#建立一个表用于存贮最大索引idsql_query_pre = CREATE TABLE IF NOT EXISTS cyask_coreseek_counter ( counter_id INTEGER PRIMARY KEY NOT NULL,max_doc_id INTEGER NOT NULL)##取数据之前将表的最大id记录到sph_counter表中sql_query_pre =REPLACE INTO cyask_coreseek_counter SELECT 1, MAX(pid) FROM cyask_question增加一个增量索引数据源source delta : main{sql_query_pre = SET NAMES utf8sql_query = SELECT id, title, body FROM documents WHERE id>( SELECT max_doc_id FROM sph_counter WHERE counter_id=1 )}在主索引之外同样的增加一个增量索引index delta : main{source = deltapath = /path/to/delta}相关的分区查询和增量索引的配置工作完成下来需要设定coreseek的程序操作新的配置文件如下:
======================================================
#MySQL数据源配置,详情请查看: http://www.coreseek.cn/products-install/mysql/
#请先将var/test/documents.sql导入数据库,并配置好以下的MySQL用户密码数据库
#源定义
source mysql
{
type = mysql
sql_host = 127.0.0.1
sql_user = mysqli
sql_pass = 123456
sql_db = qianyu365_database
sql_port = 3306
#预查询,默认为一个空的查询列表,它们被用来设置字符编码,标记待索引的记录,更新内部计数器,设置SQL服务器连接选项和变量等等
sql_query_pre = SET NAMES utf8
#对于MySQL数据源,在预查询中禁用查询缓冲(query cache)(仅对indexer连接)是有用的,因为索引查询一般并会频繁地重新运行,缓冲它们的结果是没有意义的。这可以按如下方法实现:
sql_query_pre = SET SESSION query_cache_type=OFF
#建立一个表用于存贮最大索引id
sql_query_pre = CREATE TABLE IF NOT EXISTS cyask_coreseek_counter ( counter_id INTEGER PRIMARY KEY NOT NULL,max_doc_id INTEGER NOT NULL)
##取数据之前将表的最大id记录到sph_counter表中
sql_query_pre =REPLACE INTO cyask_coreseek_counter SELECT 1, MAX(qid) FROM cyask_question
#取出信息表的最大和最小值,便于设置区段查询
sql_query_range = SELECT MIN(qid),MAX(qid) FROM cyask_question
#设置区段查询的大小
sql_range_step = 1000
#设置分区查询的时间间隔
sql_ranged_throttle = 0
#主查询,只能有一个主查询。它被用来从SQL服务器获取文档,
#sql_query第一列字段必须是唯一的正整数值,无需再设置sql_attr_uint
sql_query = SELECT q.qid,q.title,q.sid1,q.sid2,q.uid,q.asktime,q.status,q.answercount,qs.supplement FROM `cyask_question` q left join cyask_question_1 qs on q.qid=qs.qid where q.qid<( SELECT max_doc_id FROM cyask_coreseek_counter WHERE counter_id=1 ) and q.qid>=$start AND q.qid<=$end
#sql_attr_unit是整数属性列,既参与搜索结果,但不会被索引,只用于返回额外的信息,如果要声明字符串属性列可以使用sql_attr_str2ordinal
#title、content作为字符串/文本字段,被全文索引
sql_attr_uint = sid1
sql_attr_uint = sid2
sql_attr_uint = status
sql_attr_uint = answercount
#sql_attr_timestamp列用于对结果进行排序,或者按此字段进行分组
#从SQL读取到的值必须为unix时间戳,作为时间属性,
sql_attr_timestamp = asktime
#命令行查询时,设置正确的字符集
sql_query_info_pre = SET NAMES utf8
#命令行查询时,从数据库读取原始数据信息
sql_query_info = SELECT * FROM cyask_question WHERE qid=$id
}
source mysql_delta : mysql
{
sql_query_pre = set names utf8
#增量源只查询上次主索引生成后新增加的数据
#如果新增加的searchid比主索引建立时的searchid还小那么会漏掉
sql_query = SELECT q.qid,q.title,q.sid1,q.sid2,q.uid,q.asktime,q.status,q.answercount,qs.supplement FROM `cyask_question` q left join cyask_question_1 qs on q.qid=qs.qid where q.qid>( SELECT max_doc_id FROM cyask_coreseek_counter WHERE counter_id=1 ) and q.qid>=$start AND q.qid<=$end
sql_query_range = SELECT MIN(qid),MAX(qid) FROM cyask_question where qid>( SELECT max_doc_id FROM cyask_coreseek_counter WHERE counter_id=1 )
}
#index定义
index mysql
{
#设置索引的源
source = mysql
#设置生成的索引存放路径
path = E:/isweb/htdocs/coreseek/var/data/mysql
#定义文档信息的存储模式,extern表示文档信息和文档id分开存储
docinfo = extern
#设置已缓存数据的内存锁定,为0表示不锁定
mlock = 0
#设置词形处理器列表,设置为none表示不使用任何词形处理器
morphology = none
#定义最小索引词的长度
min_word_len = 1
#定义是否从输入全文数据中取出HTML标记
html_strip = 0
#中文分词配置,详情请查看: http://www.coreseek.cn/products-install/coreseek_mmseg/
#charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾
#指定分词读取词典文件的位置
charset_dictpath = E:/isweb/htdocs/coreseek/etc/
#设置字符集编码类型,我这里采用的utf8编码和数据库的一致
charset_type = zh_cn.utf-8
}
#定义增量索引
index mysql_delta
{
source = mysql_delta
path = E:/isweb/htdocs/coreseek/var/data/mysql_delta
}
#全局index定义
indexer
{
#定义生成索引过程使用索引的限制
mem_limit = 512M
}
#searchd服务定义
searchd
{
#定义监听的IP和端口
listen = 9312
#定义网络客户端请求的读超时时间
read_timeout = 5
#定义子进程的最大数量
max_children = 50
#定义守护进程在内存中为每个索引所保持并返回给客户端的匹配数目的最大值
max_matches = 500
#启用无缝seamless轮转,防止searchd轮转在需要预取大量数据的索引时停止响应
#也就是说在任何时刻查询都可用,或者使用旧索引,或者使用新索引
seamless_rotate = 1
#配置在启动时强制重新打开所有索引文件
preopen_indexes = 1
#设置索引轮转成功以后删除以.old为扩展名的索引拷贝
unlink_old = 1
pid_file = E:/isweb/htdocs/coreseek/var/log/searchd_mysql.pid
log = E:/isweb/htdocs/coreseek/var/log/searchd_mysql.log
query_log = E:/isweb/htdocs/coreseek/var/log/query_mysql.log .
binlog_path = #关闭binlog日志
}
======================================================
7,定时更新操作
一,重新生成全部索引
如果searchd守护进程已经启动,那么需要加上—rotate参数:进入到coreseek目录,在cmd中执行命令bin\indexer -c etc\csft_mysql.conf --all --rotate二,设置生成主索引的定时执行命令,每天凌晨1点执行indexer -c c:\pathTo\csft.conf --index mainE:\isweb\htdocs\coresek\bin\indexer -c etc\csft_mysql.conf --rotate mysql三,设置生成增量索引的定时执行命令,每10分钟执行一次E:\isweb\htdocs\coresek\bin\indexer -c etc\csft_mysql.conf --rotate mysql_delta四,增量索引和主索引的合并,每15分钟一次E:\isweb\htdocs\coresek\bin\indexer --config etc\csft_mysql.conf --merge mysql mysql_delta --rotate