RTL设计与编码指导
一般性指导原则
面积和速度的平衡与互换原则
- 面积(Area)是指一个设计所消耗的目标器件的硬件资源数量,对FPGA,可以使用所消耗的触发器(FF)和查找表(LUT)来衡量。速度(Speed)是指设计在芯片上稳定运行时所能到达的最最高频率,这个频率由设计的时序状况决定,与设计满足的时钟周期、PAD to PAD Time、Clock Setup Time、Clock Hold Time和Clock-to-Output Delay等众多时序特征量密切相关,面积与速度这两个指标贯穿RTL设计的始终,是设计质量评价的终极标准。
- 面积和速度是一对对立统一的矛盾体,要求一个设计同时具备面积最小、运行频率最高,这是不现实的。科学的目标应该是在满足设计时序要求(包含对设计最高频率的要求)的前提下,占用最小的芯片面积,或在所规定的面积下使设计的时序余量更大、频率更高。
- 面积和速度的互换是RTL设计的一个重要思想,从理论上讲,一个设计如果时序余量较大,所能跑的频率远远高于设计要求,那么就能通过功能模块复用减少整个设计消耗的芯片面积;反之,如果一个设计的时序要求很高,普通方法达不到设计频率,那么一般可以通过将数据流串/并转换,并复制多个操作模块,对整个设计采取“乒乓操作”和“串/并转换”的思想进行处理,在芯片输出模块再对数据进行“并/串转换”。
WCDMA(宽带码分多址)系统中使用到了快速哈达码(FHT)运算,FHT由4步相同的算法完成:

- FHT的单步算法:
- Out[2i] = In[2i] + In[2i+8]; i = 0~7
- Out[2i+1] = In[2i+1] - In[2i+1+8]; i = 0~7
以下代码是通过设计不同端口宽度的4个但不FHT,并将这4个单步模块串联起来,从而完成数据流的流水线处理。
module fhtpart(Clk,Reset,FhtStarOne,FhtStarTwo,FhtStarThree,FhtStarFour,
I0,I1,I2,I3,I4,I5,I6,I7,I8,
I9,I10,I11,I12,I13,I14,I15,
Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7,Out8,
Out9,Out10,Out11,Out12,Out13,Out14,Out15);
input Clk;
input Reset;
input FhtStarOne,FhtStarTwo,FhtStarThree,FhtStarFour;
input [11:0] I0,I1,I2,I3,I4,I5,I6,I7,I8;
input [11:0] I9,I10,I11,I12,I13,I14,I15;
output [15:0] Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7;
output [15:0] Out8,Out9,Out10,Out11,Out12,Out13,Out14,Out15;
wire [12:0] m0,m1,m2,m3,m4,m5,m6,m7,m8,m9;
wire [12:0] m10,m11,m12,m13,m14,m15;
wire [13:0] mm0,mm1,mm2,mm3,mm4,mm5,mm6,mm7,mm8,mm9;
wire [13:0] mm10,mm11,mm12,mm13,mm14,mm15;
wire [14:0] mmm0,mmm1,mmm2,mmm3,mmm4,mmm5,mmm6,mmm7,mmm8,mmm9;
wire [14:0] mmm10,mmm11,mmm12,mmm13,mmm14,mmm15;
wire [15:0] Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7,Out8,Out9;
wire [15:0] Out10,Out11,Out12,Out13,Out14,Out15;
fht_unit1 fht_unit1(Clk,Reset,FhtStarOne,
I0,I1,I2,I3,I4,I5,I6,I7,I8,I9,I10,I11,I12,
I13,I14,I15,
m0,m1,m2,m3,m4,m5,m6,m7,m8,m9,m10,m11,m12,
m13,m14,m15
);
fht_unit2 fht_unit2(Clk,Reset,FhtStarTwo,
m0,m1,m2,m3,m4,m5,m6,m7,m8,m9,m10,m11,m12,
m13,m14,m15,
mm0,mm1,mm2,mm3,mm4,mm5,mm6,mm7,mm8,mm9,mm10,mm11,mm12,
mm13,mm14,mm15
);
fht_unit3 fht_unit3(Clk,Reset,FhtStarThree,
mm0,mm1,mm2,mm3,mm4,mm5,mm6,mm7,mm8,mm9,mm10,mm11,mm12,
mm13,mm14,mm15,
mmm0,mmm1,mmm2,mmm3,mmm4,mmm5,mmm6,mmm7,mmm8,mmm9,mmm10,mmm11,mmm12,
mmm13,mmm14,mmm15
);
fht_unit4 fht_unit4(Clk,Reset,FhtStarFour,
mmm0,mmm1,mmm2,mmm3,mmm4,mmm5,mmm6,mmm7,mmm8,mmm9,mmm10,mmm11,mmm12,
mmm13,mmm14,mmm15,
Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7,Out8,Out9,Out10,Out11,Out12,
Out13,Out14,Out15
);
endmodule
module fht_unit4(Clk,Reset,FhtStar,
In0,In1,In2,In3,In4,In5,In6,In7,In8,In9,In10,In11,In12,
In13,In14,In15,
Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7,Out8,Out9,Out10,Out11,Out12,
Out13,Out14,Out15
);
input Clk;
input Reset;
input FhtStar;
input [14:0] In0,In1,In2,In3,In4,In5,In6,In7,In8,In9;
input [14:0] In10,In11,In12,In13,In14,In15;
output [15:0] Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7,Out8,Out9;
output [15:0] Out10,Out11,Out12,Out13,Out14,Out15;
/* first Fht */
reg [15:0] Out0,Out1,Out2,Out3,Out4,Out5;
reg [15:0] Out6,Out7,Out8,Out9,Out10,Out11;
reg [15:0] Out12,Out13,Out14,Out15;
wire [14:0] In8Co =~In8+1;
wire [14:0] In9Co =~In9+1;
wire [14:0] In10Co=~In10+1;
wire [14:0] In11Co=~In11+1;
wire [14:0] In12Co=~In12+1;
wire [14:0] In13Co=~In13+1;
wire [14:0] In14Co=~In14+1;
wire [14:0] In15Co=~In15+1;
always @(posedge Clk or negedge Reset)
begin
if(!Reset)
begin
Out0<=0;Out1<=0;Out2<=0;Out3<=0;Out4<=0;Out5<=0;Out6<=0;Out7<=0;
Out8<=0;Out9<=0;Out10<=0;Out11<=0;Out12<=0;Out13<=0;Out14<=0;Out15<=0;
end
else
begin
if(FhtStar)
begin
Out0<={In0[14],In0 }+{In8[14],In8 };
Out1<={In0[14],In0 }+{In8Co[14],In8Co };
Out2<={In1[14],In1 }+{In9[14],In9 };
Out3<={In1[14],In1 }+{In9Co[14],In9Co };
Out4<={In2[14],In2 }+{In10[14],In10 };
Out5<={In2[14],In2 }+{In10Co[14],In10Co };
Out6<={In3[14],In3 }+{In11[14],In11 };
Out7<={In3[14],In3 }+{In11Co[14],In11Co };
Out8<={In4[14],In4 }+{In12[14],In12 };
Out9<={In4[14],In4 }+{In12Co[14],In12Co };
Out10<={In5[14],In5 }+{In13[14],In13 };
Out11<={In5[14],In5 }+{In13Co[14],In13Co };
Out12<={In6[14],In6 }+{In14[14],In14 };
Out13<={In6[14],In6 }+{In14Co[14],In14Co };
Out14<={In7[14],In7 }+{In15[14],In15 };
Out15<={In7[14],In7 }+{In15Co[14],In15Co };
end
end
end
endmodule
整个流水线有16个时钟周期,而FHT模块的频率很高,加法本身仅消耗1个时钟周期。如果将但不FHT运算复用4次,就能大幅度节约所消耗的资源。
- FHT运算复用结构图

复用单步算法的FHT运算模块
module wch_fht(Clk,Reset,
PreFhtStar,
In0,In1,In2,In3,In4,In5,In6,In7,
In8,In9,In10,In11,In12,In13,In14,In15,
Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7,Out8,
Out9,Out10,Out11,Out12,Out13,Out14,Out15
);
input Clk;
input Reset;
input PreFhtStar;
input [11:0] In0,In1,In2,In3,In4,In5,In6,In7;
input [11:0] In8,In9,In10,In11,In12,In13,In14,In15;
output [15:0] Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7;
output [15:0] Out8,Out9,Out10,Out11,Out12,Out13,Out14,Out15;
reg [15:0] Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7;
reg [15:0] Out8,Out9,Out10,Out11,Out12,Out13,Out14,Out15;
wire [15:0] Temp0,Temp1,Temp2,Temp3,Temp4,Temp5,Temp6,Temp7;
wire [15:0] Temp8,Temp9,Temp10,Temp11,Temp12,Temp13,Temp14,Temp15;
reg [2:0] Cnt3;//count from 0 to 4,when Reset Cnt3=7;
reg FhtEn;//Enable fht culculate
always @(posedge Clk or negedge Reset)
begin
if (!Reset)
Cnt3<= #1 3'b111;
else
begin
if(PreFhtStar)
Cnt3<= #1 3'b100;
else
Cnt3<= #1 Cnt3-1;
end
end
always @(posedge Clk or negedge Reset)
if (!Reset)
FhtEn<= #1 0;
else
begin
if (PreFhtStar)
FhtEn<= #1 1;
if (Cnt3==1)
FhtEn<= #1 0;
end
//补码运算,复制符号位
assign Temp0=(Cnt3==4)?{4{In0[11]},In0}:Out0;
assign Temp1=(Cnt3==4)?{4{In1[11]},In1}:Out1;
assign Temp2=(Cnt3==4)?{4{In2[11]},In2}:Out2;
assign Temp3=(Cnt3==4)?{4{In3[11]},In3}:Out3;
assign Temp4=(Cnt3==4)?{4{In4[11]},In4}:Out4;
assign Temp5=(Cnt3==4)?{4{In5[11]},In5}:Out5;
assign Temp6=(Cnt3==4)?{4{In6[11]},In6}:Out6;
assign Temp7=(Cnt3==4)?{4{In7[11]},In7}:Out7;
assign Temp8=(Cnt3==4)?{4{In8[11]},In8}:Out8;
assign Temp9=(Cnt3==4)?{4{In9[11]},In9}:Out9;
assign Temp10=(Cnt3==4)?{4{In10[11]},In10}:Out10;
assign Temp11=(Cnt3==4)?{4{In11[11]},In11}:Out11;
assign Temp12=(Cnt3==4)?{4{In12[11]},In12}:Out12;
assign Temp13=(Cnt3==4)?{4{In13[11]},In13}:Out13;
assign Temp14=(Cnt3==4)?{4{In14[11]},In14}:Out14;
assign Temp15=(Cnt3==4)?{4{In15[11]},In15}:Out15;
always @(posedge Clk or negedge Reset)
begin
if (!Reset)
begin
Out0<=0;Out1<=0;Out2<=0;Out3<=0;Out4<=0;Out5<=0;Out6<=0;Out7<=0;
Out8<=0;Out9<=0;Out10<=0;Out11<=0;Out12<=0;Out13<=0;Out14<=0;Out15<=0;
end
else
begin
if ((Cnt3<=4) && Cnt3>=0 && FhtEn)
begin
Out0[15:0]<= #1 Temp0[15:0]+Temp8[15:0];
Out1[15:0]<= #1 Temp0[15:0]-Temp8[15:0];
Out2[15:0]<= #1 Temp1[15:0]+Temp9[15:0];
Out3[15:0]<= #1 Temp1[15:0]-Temp9[15:0];
Out4[15:0]<= #1 Temp2[15:0]+Temp10[15:0];
Out5[15:0]<= #1 Temp2[15:0]-Temp10[15:0];
Out6[15:0]<= #1 Temp3[15:0]+Temp11[15:0];
Out7[15:0]<= #1 Temp3[15:0]-Temp11[15:0];
Out8[15:0]<= #1 Temp4[15:0]+Temp12[15:0];
Out9[15:0]<= #1 Temp4[15:0]-Temp12[15:0];
Out10[15:0]<= #1 Temp5[15:0]+Temp13[15:0];
Out11[15:0]<= #1 Temp5[15:0]-Temp13[15:0];
Out12[15:0]<= #1 Temp6[15:0]+Temp14[15:0];
Out13[15:0]<= #1 Temp6[15:0]-Temp14[15:0];
Out14[15:0]<= #1 Temp7[15:0]+Temp15[15:0];
Out15[15:0]<= #1 Temp7[15:0]-Temp15[15:0];
end
end
end
endmodule
采用复用实现方案所占面积约为原方案的1/4,代价是完成整个FHT运算的周期为原来的4倍。
-
面积复制换取速度提升

DLPC410与FPGA之间便是如此实现的,通过OSERDES模块完成4:1的数据速率转换。
硬件原则
硬件原则主要针对HDL代码编写而言,明确HDL与软件语言有本质区别的。评价一段HDL代码优劣的最终标准是其实现的硬件电路的性能(包括面积和速度)。
- 与C这种软件语言相比,HDL语言便于描述“互联”、“并发”、“时间”这3个硬件设计的基本概念
- 互连(connectivity):互连是硬件电路的一个基本要素,在C语言中,并没有直接可以用来表示模块之间互连的变量,Verilog HDL中的线网类型则专为模块互连而设计。
- 并发(concurrency):C语言是串行的,不能描述硬件之间的并行的特性,C语言编译后,其机器指令在CPU的高速缓冲队列中基本是顺序执行的;HDL可以有效的描述并行的硬件系统,硬件系统比软件系统速度快、实时性高的一个重要因素就是硬件系统中各个单元的运算是独立的,信号流是并行的。建模时,要充分理解硬件系统的并行处理特点,合理安排数据流时序,提高整个设计的效率。
- 时间(time):C程序运行时没有严格的时间概念,程序运行时间长短取决于处理器本身的性能;而HDL语言定义了绝对和相对时间度量,在仿真时可以通过时间度量与周期关系描述信号直接的时间关系。
通过for循环语句说明C和HDL语言的区别:
for(i = 0; i < 16; i++)
DoSomething();
- 在C语言的描述中,for循环代码执行效率高,表述简洁;但在HDL中,除描述仿真测试激励(testbench)时使用for循环语句外,RTL级编码中必须慎用for循环。原因:for循环会被综合器展开为所有变量情况的执行语句,每个变量独立占用寄存器资源,有些情况下不能有效复用硬件逻辑资源,造成浪费。在RTL硬件描述中,遇到类似算法,常用的方法是先搞清楚设计的时序要求,做一个reg型计数器,在每个时钟沿累加,并在每个时钟沿判断计数器情况,做相应的处理,能复用的尽量复用,即使所有操作不易复用,可以使用case语句展开描述;
- Verilog语言是分层次的,即使同一个语法关键字在不同的应用层次也有不同的理解,for循环在不同层次的不同理解:
- for循环在行为描述测试激励时的应用:推荐使用Behavior级描述激励,在描写测试激励时,推荐使用for循环。这样的好处:一是描述简单,代码清晰;二是仿真器会对for循环开放一片内存,提高代码执行效率,加快仿真进程。
- for循环在RTL级描述硬件电路的应用:for循环会被综合器展开为所有变量情况的执行语句,每个变量独立占用寄存器资源,有些情况下不能有效复用硬件逻辑资源,造成浪费。如果非常清晰for循环会被综合器展开这一基本原则,则可以逆向思维,对某些硬件上无法复用的展开结构抽象为for循环描述,大大提高代码的可读性。
reg [3:0] cnt;
always @(posedge clk)
if(sys_rst)
cnt <= 4'b0;
else
cnt <= cnt + 1;
always @(posedge clk)
begin
case(cnt)
4'b000 :
4'b001 :
4'b010 :
.....
default:
endcase
end
系统原则
系统原则包含两个层次含义:
- 一是实现的目标器件本身可以看作一个系统,需要充分有效的发挥该系统的每个单元的功效。如果设计的实现目标是FPGA,因为现在的FPGA内嵌了很多固有的硬件资源(如:可编程输入/输出单元、基本可编程逻辑单元、嵌入式块RAM、丰富的布线资源、底层嵌入式功能单元和内嵌的专用硬核(如DSP)等),如何合理地使用这些硬件资源,对设计的全局有个宏观的合理安排,比如合理安排时钟域、模块复用、约束、面积和速度等问题显得至关重要。
- 从更高层面看,对于任何一个硬件系统,如何进行模块划分与任务分配,什么样的算法和功能适合在FPGA中实现,什么样的算法和功能适合放在DSP、CPU中实现,如何划分软硬件功能,安排模块接口设计等问题都非常重要。
- FPGA设计的系统规划流程:

同步设原则与多时钟处理
同步设计原则
异步时序设计与同步时序设计
异步电路
- 电路的核心逻辑是用组合电路实现,如异步的FIFO、RAM读/写信号、地址译码等;
- 电路的主要信号、输出信号并不依赖于任何一个时钟信号,不是由时钟信号驱动FF产生;
- 异步时序电路的最大缺点是容易产生毛刺,在布局布线后用仿真和高分辨率逻辑分析仪能观测到实际信号时,这总茅厕尤为明显;
- 不利于器件移植,这包括PFGA器件族之间的移植和从FPGA向结构化ASIC的移植;
- 不利于静态时序分析(STA)、验证设计时序性能;
- 异步电路也有一些有点:无时钟歪斜的问题、低电源消耗、模块化、可组合和复用。
同步电路
- 同步电路的核心逻辑用各种各样的触发器实现;
- 电路的主要信号、输出信号等都是由某个时钟沿驱动触发器产生的;
- 同步时序电路可以很好的避免毛刺;
- 利于器件移植;
- 利于静态时序分析(STA)、验证设计时序性能。
区别
- 同步逻辑是时钟之间有固定的因果关系。异步逻辑是各时钟之间没有固定的因果关系。
- 在电路中同一个时钟源的时钟分频出来的不同频率的时钟作用于两部分电路,这两部分电路也是同步的。反之,不同时钟源的电路就是异步电路。
目前大多数综合、实现等EDA工具都是基于时序驱动(Timing Driven)优化策略的。异步时序电路增加了时序分析的难度,需要确定最佳时序路径所需的计算量超出想象,所需的时序约束相当繁琐,而且对于异步电力很多综合、实现工具的编译会带来歧义。而对于时序设计则恰恰相反,其时序路径清晰,相关时序约束简单明了,综合、实现优化容易,布局布线计算量小。
同步时序设计
同步时序设计的基本原则是使用时钟边沿触发所有的操作。如果所有寄存器的时序要求(Setup、Hold时间等指标)都能满足,则同步时序设计于异步时序设计相比,在不同的PVT(工艺、电压、温度)条件下能获得更佳的系统稳定性与可靠性。同步设计中,稳定可靠的数据采样必须遵循以下两个基本原则:
- 在有效时钟沿到达之前,数据输入至少已经稳定了采样寄存器的Setup时间之久,这个原则称为满足Setup时间原则;
- 在有效时钟沿到达后,数据输入至少还将稳定保持采样采样寄存器的Hold时间之久,这个原则称为满足Hold时间原则;
- 同步时序电路的延迟:同步时序设计中电路延迟最常用的设计方法是用分频或者倍频的时钟或者同步计数器完成所需延迟,即同步时序电路的延时被当作一个电路逻辑来设计。对于比较大的和特殊定时要求的延时,一般用高速时钟产生一个计数器,根据计数器的计数来控制延时;对于比较小的延时,可以用D触发器打一下,这种做不仅可以使信号延时一个周期,而且完成了信号与时钟的初次同步,在输入信号采样或者增加时序约束余量时使用。
亚稳态
异步时钟域转换的核心就是要保证下级时钟对上级数据采样的Setup时间和Hold时间。setup time(建立时间):时钟有效沿到来之前,数据必须保持稳定的最短时间,对应的是数据路径的最大延时;hold time(保持时间):时钟有效沿到来之后,数据必须保持稳定的最短时间,对应的是数据路径的最小延时。hold的裕量计算与时钟无关,降低时钟频率对hold时间没有影响。setup的裕量与时钟有关,降低频率即为增大时钟周期,可以解决 setup 违例问题。建立时间或者保持时间不满足导致数据采样出错,亚稳态 现象。此时触发器输出端Q在有效沿之后比较长的一段时间内处于不稳定状态,在这段时间内Q端产生毛刺并不断振荡,最终固定在某一电压值,此电压值并不一定等于原来数据输入端D的数值,这段时间称为决断时间(Resolution time),之后Q端将稳定到0或1,但到底是0还是1,这是随机的,与输入没有必然关系。
亚稳态的输出将在下一个时钟的上升沿之前稳定为0或1,如果亚稳态输出被用于其他逻辑门的输入,那么将造成难以预计的不良影响,可能会造成连锁反应,使整个数字系统工作不稳定。因此,必须采取一定的手段避免D触发器进入亚稳态,或者避免亚稳态被传递,影响整个系统的稳定性。
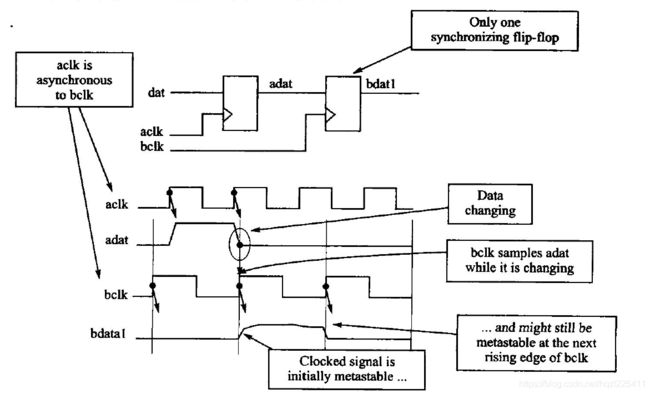
-
亚稳态的危害主要体现在破坏系统稳定性,由于输出在稳定下来之前可能是毛刺、震荡、固定的某一电压值,因此亚稳态将导致逻辑误判,严重情况下输出0~1之间电压还会使下一级产生亚稳态,导致亚稳态的传播。逻辑误判导致功能性错误,而亚稳态的传播则会扩大故障面。另外,在亚稳态下,任何诸如环境噪声、电源干扰等细微扰动都将导致更恶劣的状态不稳定。这时这个系统的传输延迟增大,状态输出错误,在某些情况下甚至会使寄存器在两个有效判定门限(VoL、VoH)之间长时间震荡。
-
只要系统中有异步元件,亚稳态就无法避免,因此设计电路首先要减少亚稳态导致的错误,其次要使系统对产生的错误不敏感。前者靠同步设计来实现,而后者则根据不同的设计应用不同发处理方法。
-
使用两级以上寄存器采样可以有效地减少亚稳态的继续传播的概率,原理:第一个触发器的输出端存在亚稳态,经过第二个触发器D端的电平仍未稳定的概率非常小,因此第二个触发器Q端基本不会产生亚稳态,理论上再添加一级寄存器,使同步采样达到3级,则末级输出亚稳态的概率基本为0。
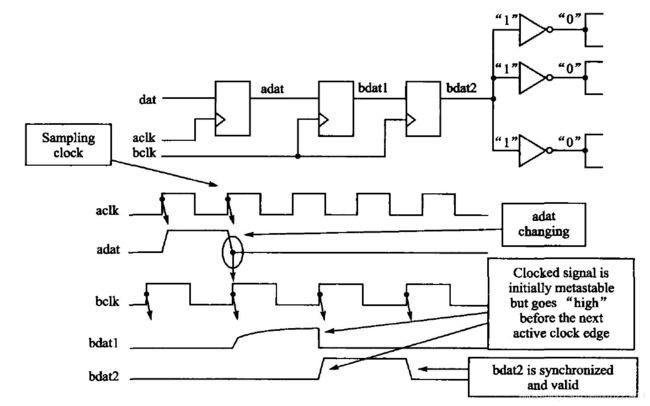
-
两级寄存器采样仅能降低亚稳态的传播,使后级电路获得有效电平,但并不能保证第二级输出的稳态电平就是正确电平。经过Resolution time之后寄存器输出的电平是一个不确定的稳定值,也就是说这种处理方法并不能排除采样错误的产生,这是就要求所设计的系统对系统错误有一定的容忍度。
当触发器的输入不满足建立时间和保持时间要求时,输出为亚稳态。为了使系统正常工作,必须采取一定的手段避免或消除其影响。在只有一个时钟的数字系统中(称为单时钟域数字系统),通过控制一个D触发器的输出到另一个D触发器输人之间组合逻辑门的数量,可以减少其带来的延迟从而避免D触发器的输人在建立时间和保持时间窗口内发生波动。但是,当一个数字系统中有两个或两个以上时钟时( 称为多时钟域系统),会出现一个时钟域的D触发器的输出作为另一个时钟域的D触发器输人的情况,当两个时钟之间没有任何关联时,亚稳态的出现是无法避免的。
在目标时钟域中,使用两个级联的D触发器。此时,在两个时钟域连接的地方,第一级触发器的输出会出现亚稳态,但在下一个时钟上升沿到达前,输出会稳定下来,此时第二级触发器上就不会出现亚稳态了,该信号提供给后面的数字电路使用,就可以避免系统的不稳定。当时钟频率非常高时,第二级触发器也有可能出现亚稳态,此时可以考虑增加级联的D触发器的数量。在实际应用中,通常使用两级D触发器级联就可以了。
使用双触发应遵循的原则:
- 级联的寄存器必须使用同一个采样时钟;
- 发送端时钟寄存器输出到接收端异步时钟域级联寄存器输入之间不能有任何其他组合逻辑;(跨时钟域的信号必须直接来自源时钟域的寄存器输出)(组合逻辑会产生毛刺,这样同步器很可能采到不需要的数据,同时组合逻辑输出的额外切换也会增加亚稳态的风险)
- 在一个点而不是在多个点上进行跨时钟域信号的同步;同步电路可以消除亚稳态及其传递,但得到的结果可能是1也可能是0,当只有一个连接点时,最多是信号延迟不同的问题,如果是多个点,那么这些信号组合后的结果可能性非常多,这会造成信号传递的错误,可能会导致下游系统出错。
- 同步器中级联的寄存器除最后一个寄存外,所有的寄存器只能有一个扇出,即其只能驱动下一级寄存器输入。
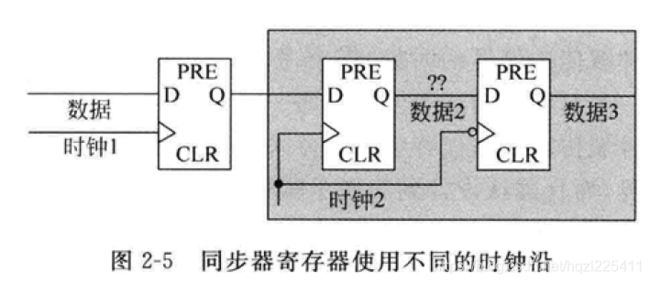
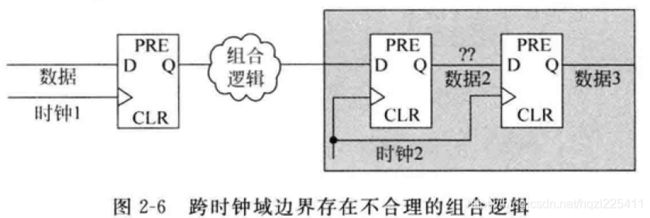
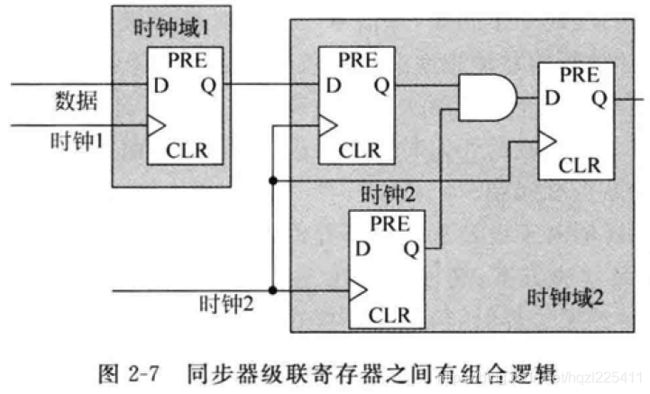
同步器中寄存器链的长度是符合上述三个原则的寄存器个数,上述提到的典型的同步器长度是2,即两级寄存器。另外,只要同步器中寄存器链处于同一个时钟域,那么寄存器链中寄存器路径之间是可以存在组合逻辑的。上图所示即为这样的一个例子。
异步时钟域数据同步
两类异步时钟域同步的表现形式
异步时钟域数据同步,即数据接口同步,是指如何在两个时钟不同步的数据域之间可靠地进行数据交换。数据的时钟域不同步主要有两种情况:
- 两个域的时钟频率相同,但相位差不固定,或者相位差固定但不可测,简称为同频异相问题;
- 两个时钟域频率不同,简称异频问题。
两种不推荐的处理方法
- 通过增加buffer或者其他门延时来调整采样:这种做法主要应用场景有两个人:一是使用分立逻辑元件(74系列)搭建简单的数字逻辑电路,另一种是在ASIC设计领域,ASIC设计领域采用这种方法是以严格的仿真和约束条件作为强力支持的;
- 盲目使用时钟正负沿调整数据采样;不推荐原因:一是使用时钟双边呀同时操作,相当于使用了一个同相倍频时钟,设计的时钟频率提高,所有相关的时序约束都会变得更紧,不利于可靠实现;二是芯片中的PLL/DLL一般能较好的保证某个时钟沿的Jitter、Skew和占空比等参数指标,对另一个时钟沿的指标控制并不是那么严格。
使用两个时钟沿的补充:
- 虽然使用了同一个时钟的两个沿,但是要保证不在同一个时钟周期内同时使用双沿,则不会增加时钟频率;
- DDR、QDR本身就是利用上下沿采样的原理,但硬件的DDR、QDR电路是专用的高速设计电路,对时钟的正沿、负沿的Jitter、Skwe和占空比等指标都有详细和明确的要求。
补充:setup 和 hold time计算
结合下文的与数据接口同步相关的常用约束
setup time(建立时间):时钟有效沿到来之前,数据必须保持稳定的最短时间,对应的是数据路径的最大延时;hold time(保持时间):时钟有效沿到来之后,数据必须保持稳定的最短时间,对应的是数据路径的最小延时。hold的裕量计算与时钟无关,降低时钟频率对hold时间没有影响。setup的裕量与时钟有关,降低频率即为增大时钟周期,可以解决 setup 违例问题。

相关变量:
Tclk : Frequency of operation (can be variable), 时钟周期
Tcq : Flop clock to Flop q delay (fixed/constant), 触发器传输延时
Tcomb : Delay on the combinational logic between the Flops (can be variable), 中间组合逻辑延时
Tsetup : Setup time of a Flop (fixed/constant), 建立时间
Thold : Hold time of a Flop (fixed/constant), 保持时间
Tskew : Delay between clock edges of two adjacent flops (dalay offered by clock path)(can be variable), 时钟抖动,不确定性
setup time
正常工作满足的公式:
Tclk > Tcq + Tcomb + Tsetup + Tskew
(Tskew = TCLK1 - TCLK2 为负值,如果定义Tskew = TCLK2 - TCLK1 则为正值,需要改叫为减)
- 增大Tclk,即降低系统工作频率,一般到最后才会想要降低系统时钟频率来满足setup time
- 减小Tcomb,具体的如:pipeline(用流水线切割组合逻辑,减小路径延时),在不改变逻辑功能的前提下,改变成其他样式的组合逻辑,进行组合逻辑优化,或者改变扇出系数(针对数字IC设计)
- 减小Tskew,一般在数字IC中
- 针对数字IC设计中,芯片流片之后,只能改变Tclk
hold time
正常工作满足的公式:
Thold + Tskew < Tcq + Tcomb
- 增大Tcomb,在data path上面插入buffer来增加组合逻辑延时,但这回导致setup time变差
- 减小Tskew,数字IC设计中
异步时钟域数据同步常用方法
同频异相问题
-
两级寄存器采样
见上文亚稳态部分。在一些高速设计中需要再额外加入一级寄存器来增加MTBF(Mean Time Between Failure,平均故障间隔时间)。即同步器中两级寄存器的MTBF太短。
-
用RAM/FIFO
将上级芯片提供的数据及时钟作为写信号,将数据写入RAM/FIFO中,再将数据读出。由于时钟频率相同,RAM/FIFO两端数据从吞吐率一致,实现起来相对简单。(RAM一般使用DPRAM 双口RAM)
异频问题
可靠完成异频问题的解决方法是使用RAM/FIFO。由于时钟频率不同,所以两个端口的数据吞吐率不一致,设计时一定要开好缓冲区,并监测full、empty等指示信号,保证数据不会溢出。
数据接口的同步方法 补充
慢速时钟到快速时钟
一般设计中使用两级触发器进行缓存即可满足设计时序需求。大量实验表明,三级触发器缓存可解决 99% 以上的此类异步时序问题。
两级触发器延迟打拍并检测信号上升沿的 Verilog 描述如下:
module delay_clap(
input clk, //目的快时钟
input rstn, //异步复位信号
input sig1, //异步信号
output sig, //经过3级触发器同步后的信号
output sig2); //快时钟域同步后的信号,上升沿检测,一个周期有效时间
reg [2:0] sig2_r ; //3级缓存,前两级用于同步,后两节用于边沿检测
always @(posedge clk or negedge rstn) begin
if (!rstn) sig2_r <= 3'b0 ;
else sig2_r <= {sig2_r[1:0], sig1} ; //缓存
end
assign sig = sig2_r[2];
assign sig2 = sig2_r[1] && !sig2_r[2] ; //上升沿检测
endmodule
延迟采样法
此方法主要针对多位宽的数据传输。
例如当两个异步时钟频率比为 5 时,可以先用延迟打拍的方法对数据使能信号进行 2 级打拍缓存,然后再在快时钟域对慢时钟域的数据信号进行采集。
该方法的基本思想是保证信号被安全采集的时刻,而不用同步多位宽的数据信号,可节省部分硬件资源。
利用打拍的方法进行延迟采样的 Verilog 描述如下:
//同步模块工作时钟为 100MHz 的模块
//异步数据对来自工作时钟为 20MHz 的模块
module delay_sample(
input rstn,
input clk1,
input [31:0] din,
input din_en,
input clk2,
output [31:0] dout,
output dout_en);
//sync din_en
reg [2:0] din_en_r ;
always @(posedge clk2 or negedge rstn) begin
if (!rstn) din_en_r <= 3'b0 ;
else din_en_r <= {din_en_r[1:0], din_en} ;
end
wire din_en_pos = din_en_r[1] && !din_en_r[2] ;
//sync data
reg [31:0] dout_r ;
reg dout_en_r ;
always @(posedge clk2 or negedge rstn) begin
if (!rstn)
dout_r <= 'b0 ;
else if (din_en_pos)
dout_r <= din ;
end
//dout_en delay
always @(posedge clk2 or negedge rstn) begin
if (!rstn) dout_en_r <= 1'b0 ;
else dout_en_r <= din_en_pos ;
end
assign dout = dout_r ;
assign dout_en = dout_en_r ;
endmodule
但如果慢时钟域没有数据使能信号 din_en, 或数据使能信号一直有效,此时在快时钟域对数据使能信号进行上升沿检测的方法将会失效。因为数据使能信号一直有效,除了第一个数据,快时钟域将无法检测到后继数据的传输时刻。
解决方法就是,在快时钟域对慢时钟信号的边沿进行检测。
如果两个时钟的频率相差较小,可能还需要对数据进行延迟缓存,以保证采集到的是当拍时钟的数据;如果两个时钟的频率相差较大,数据采样时刻可以通过计数的方法获得,而不用对数据进行缓存。
利用计数延迟采样的方法对慢时钟边沿进行检测的 Verilog 描述如下:
//同步模块工作时钟为 100MHz 的模块
//异步数据对来自工作时钟为 999KHz 的模块
module delay_cnt_sample(
input rstn,
input clk1,
input [31:0] din,
input din_en,
input clk2,
output [31:0] dout,
output dout_en);
//4级缓存:3级用于打拍同步,一级用于边沿检测
reg [3:0] edge_r ;
always @(posedge clk2 or negedge rstn) begin
if (!rstn) edge_r <= 3'b0 ;
else edge_r <= {edge_r[3:0], clk1} ;
end
wire edge_pos = edge_r[2] && !edge_r[3] ;
//延迟计数器,检测到慢时钟上升沿时开始计数
reg [5:0] cnt ;
always @(posedge clk2 or negedge rstn) begin
if (!rstn) cnt <= 6'h3f ;
else if (edge_pos && din_en)
cnt <= 6'h0 ;
else if (cnt != 6'h3f) cnt <= cnt + 1'b1 ;
end
//数据同步
reg [31:0] dout_r ;
reg dout_en_r ;
always @(posedge clk2 or negedge rstn) begin
if (!rstn)
dout_r <= 'b0 ;
else if (din_en && cnt == 47) //大约在慢时钟周期中间时刻采样
dout_r <= din ;
end
//数据使能信号较数据采样时刻延迟一个周期输出
always @(posedge clk2 or negedge rstn) begin
if (!rstn) dout_en_r <= 1'b0 ;
else if (din_en && cnt==48)
dout_en_r <= 1'b1 ;
else dout_en_r <= 1'b0 ;
end
assign dout = dout_r ;
assign dout_en = dout_en_r ;
endmodule
快速信号到慢时钟域的同步——单比特
电平信号同步
同步逻辑设计中,电平信号是指长时间保持不变的信号。保持不变的时间限定是相对于慢时钟而言的。只要快时钟的信号保持高电平或低电平的时间足够长,以至于能被慢时钟在满足时序约束的条件下采集到,就可以认为该信号为电平信号。
既然电平信号能够被安全的采集到,所以从快时钟域到慢时钟域的电平信号也采用延迟打拍的方法做同步。
脉冲信号
同步逻辑设计中,脉冲信号是指从快时钟域输出的有效宽度小于慢时钟周期的信号。如果慢时钟域直接去采集这种窄脉冲信号,有可能会漏掉。
假如这种脉冲信号脉宽都是一致的,在知道两个时钟频率比的情况下,可以采用"快时钟域脉宽扩展+慢时钟域延迟打拍"的方法进行同步。

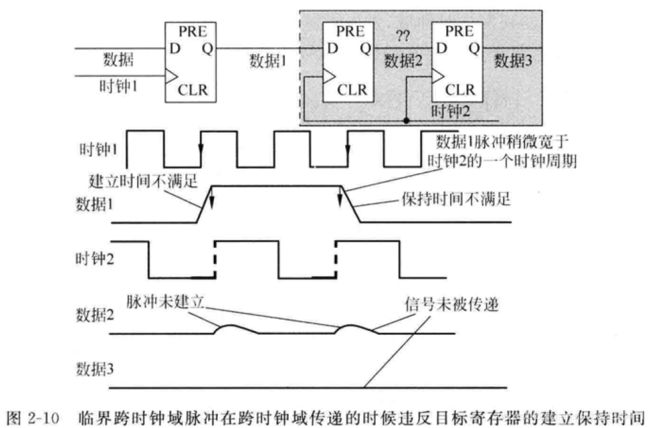
最佳的脉冲宽是最少为时钟周期的1.5倍,这样跨时钟域信号将会被接收时钟域的时钟至少稳定的采样一次。因此,快速信号到慢时钟域的第一种方法:“开环方案”,将脉冲进行展宽。
开环方案多用于相关时钟频率固定且时钟信号能够被正确分析,这种方案的好处是能在无须接收时钟域的握手信号的情况下最快地将信号传递通过跨时钟域边界。缺点是,当设计发生改变时,容易忘记重新分析之前的开环方案。
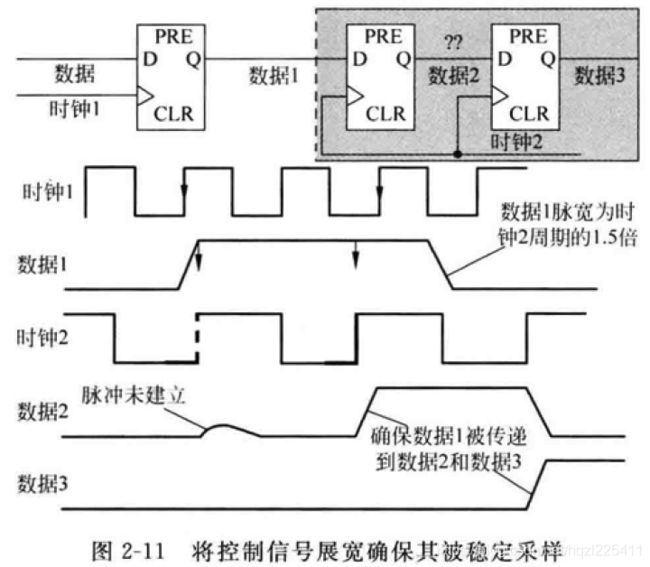
“闭环”解决方案:在发送时钟域将控制信号当使能信号传递,并将其同步到接收时钟域,然后接收时钟域收到使能控制信号后,将同步的控制信号反馈到发送时钟域,发送时钟域通过另一个同步接收器接收此反馈回来的控制信号,并以它作为正确接收的握手信号。
好处是反馈回来的同步信号可以非常安全的确认第一个使能信号已经被接收时钟域正确识别和采样。缺点是,这种信号传递方式存在相当大的延时,因为信号未被接收时钟域正确接收之前是不能释放的,即在被正确接收之前目标信号不能改变数值,也就无法传递信号的下一个数值。

如果有时窄脉冲信号又表现出电平信号的特点,即有时信号的有效宽度大于慢时钟周期而能被慢时钟采集到,那么对此类信号再进行脉冲扩展显然是不经济的。此时,可通过"握手传输"的方法进行同步。
假设脉冲信号的高电平期间为有效信号期间,其基本原理如下。
- (1) 快时钟域对脉冲信号进行检测,检测为高电平时输出高电平信号 pulse_fast_r。或者快时钟域输出高电平信号时,不要急于将信号拉低,先保持输出信号为高电平状态。
- (2) 慢时钟域对快时钟域的信号 pulse_fast_r 进行延迟打拍采样。因为此时的脉冲信号被快时钟域保持拉高状态,延迟打拍肯定会采集到该信号。
- (3) 慢时钟域确认采样得到高电平信号 pulse_fast2s_r 后,再反馈给快时钟域。
- (4) 快时钟域对反馈信号 pulse_fast2s_r 进行延迟打拍采样。如果检测到反馈信号为高电平,证明慢时钟域已经接收到有效的高电平信号。如果此时快时钟域自身逻辑不再要求脉冲信号为高电平状态,拉低快时钟域的脉冲信号即可。
此方法实质是通过相互握手的方式对窄脉冲信号进行脉宽扩展。
利用握手信号进行同步处理的 Verilog 模型描述如下:
//同步模块工作时钟大约为 25MHz 的模块
//异步数据对来自工作时钟为 100MHz 的模块
module pulse_syn_fast2s
#( parameter PULSE_INIT = 1'b0
)
(
input rstn,
input clk_fast,
input pulse_fast,
input clk_slow,
output pulse_slow);
wire clear_n ;
reg pulse_fast_r ;
/**************** fast clk ***************/
//(1) 快时钟域检测到脉冲信号时,不急于将脉冲信号拉低
always@(posedge clk_fast or negedge rstn) begin
if (!rstn)
pulse_fast_r <= PULSE_INIT ;
else if (!clear_n)
pulse_fast_r <= 1'b0 ;
else if (pulse_fast)
pulse_fast_r <= 1'b1 ;
end
reg [1:0] pulse_fast2s_r ;
/************ slow clk *************/
//(2) 慢时钟域对信号进行延迟打拍采样
always@(posedge clk_slow or negedge rstn) begin
if (!rstn)
pulse_fast2s_r <= 3'b0 ;
else
pulse_fast2s_r <= {pulse_fast2s_r[0], pulse_fast_r} ;
end
assign pulse_slow = pulse_fast2s_r[1] ;
reg [1:0] pulse_slow2f_r ;
/********* feedback for slow clk to fast clk *******/
//(3) 对反馈信号进行延迟打拍采样
always@(posedge clk_fast or negedge rstn) begin
if (!rstn)
pulse_slow2f_r <= 1'b0 ;
else
pulse_slow2f_r <= {pulse_slow2f_r[0], pulse_slow} ;
end
//控制快时钟域脉冲信号拉低
assign clear_n = ~(!pulse_fast && pulse_slow2f_r[1]) ;
endmodule
多比特信号跨时钟域同步处理
跨时钟域传递多比特信号的问题是,在同步多个信号到一个时钟域时将可能偶发数据变化歪斜(Skew),这种数据歪斜最终会在第二个时钟域的不同时钟上升沿被采集。为了避免这种多比特时钟域信号上的采样歪斜,有3种策略需要掌握:
- 多比特信号融合策略,即在可能的情况下,将多比特跨时钟域信号融合成单比特跨时钟域信号;
- 多周期路径规划策略,即使用同步加载信号来安全地传递多比特跨时钟信号;
- 使用格雷码传递多比特跨时钟信号。
多比特信号融合
例1
在接收时钟域有有一个寄存器,需要一个加载(Load)信号和一个使能(Enable)信号来加载一个数值到寄存器。如果加载和使能信号在发送时钟域的同一个时钟沿被驱动有效(即两个控制信号需要同时有效),那么这两个控制信号之间可能存在产生一个小Skew的机会,这就可能导致在接收时钟域中这两个信号被同步到不同的时钟周期。解决方法就是将加载和使能信号融合成一个单比特控制信号(这两个控制信号本身相同,且同时有效)。单比特控制信号同步到接收时钟域后作为一个“加载使能”信号同时驱动寄存器的加载和使能输入端口。
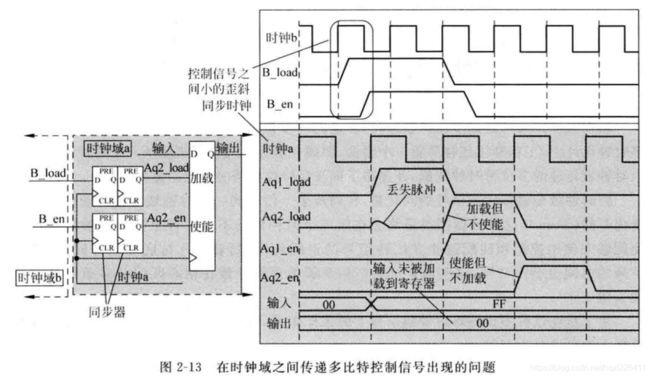

例2
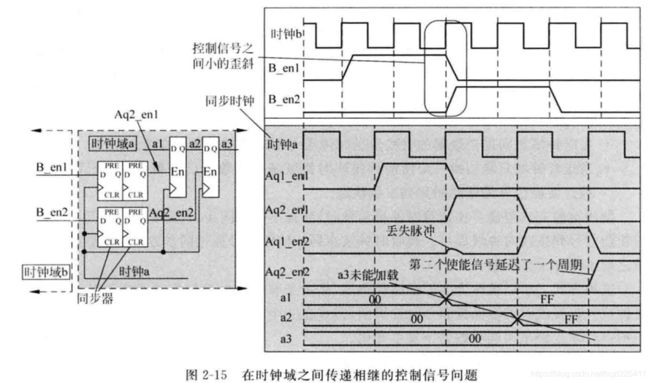
在发送时钟域先后有两个使能信号(不同于例1的同时有效),同步到接收时钟域用于控制两级流水寄存器。在第一时钟域中,B_en1控制信号正好稍微在B_en2有效前结束,这就导致在接收时钟域时钟上升沿采集B_en1和B_en2脉冲时产生一个细微的缝隙。同步后两个使能控制信号之间间隔了2个时钟周期,而不是流水一个时钟周期。这导致数据a2没有及时加载到第二个寄存器。需要注意:图中数据如果能够一直保持有效,那么在间隔一个时钟周期后,数据还是会加载到第二个寄存器,但这里要求的是严丝合缝的流水操作,所以问题就出现了。图中第二个使能信号推迟了一个时钟周期,数据a2如果能够保持有效,应该在第二个使能有效的时候加载进第二个寄存器,图中a3并未显示出来。
解决此问题,首先是在发送时钟域将两个使能控制信号融合未一个控制信号,其次是增加一个额外的寄存器将同步后的使能控制信号寄存一拍,这样数据和控制信号形成匹配的流水。如下图,这种处理方式在HDL设计时非常简单,就是将同步后的控制信号在同步时钟域寄存一拍来产生第二级寄存器的使能信号。
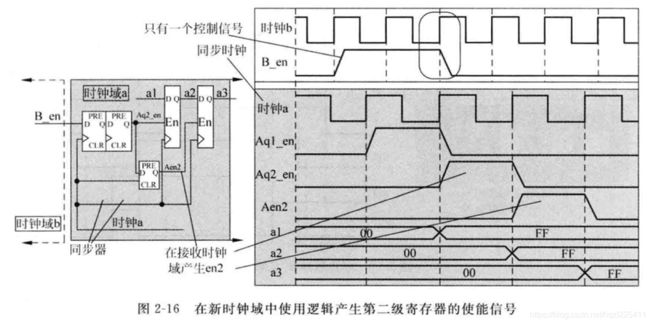
多周期路径规划
多周期路径规划是一种通用的安全传递多比特跨时钟域信号技术。多周期路径规划是指在传输非同步数据到接收时钟域时配上一个同步的控制信号,数据和控制信号被同时发送到接收时钟域,同时控制信号在接收时钟域使用两级寄存器同步到接收时钟域,使用此同步后的控制信号用来加载数据,这样数据就可以在目的寄存器被安全加载。使用这种技术的好处:
- 在时钟域之间发送数据的时候发送时钟域无须计算对应脉冲宽度;
- 发送时钟域只需切换一个使能到接收时钟域来显示数据已经被传递且已准备被加载,使能信号无须返回到其原始状态。
使用这种方式传递多比特时钟域信号时,数据不需要同步,只需要同时传递一个同步使能信号到接收时钟域即可。接收时钟域在同步使能信号通过同步方式传递到接收时钟域之前不允许采集数据。
这种方式之所以被称为多周期路径规划,是由于非同步的数据字是被直接传递到接收时钟域并在接收时钟域保持多个时钟周期,只有在一个使能信号被同步到接收时钟并被识别以后才允许该非同步数据字发生变化。
正是因为非同步数据传递到接收时钟域并在多个时钟周期内保持稳定,所以数据的传递是安全的,数据值并无陷入亚稳态的危险。
这种方式与在单时钟域中经常采用的“数据有效”技术非常类似,比如读/写FIFO的读有效和写有效等,只是这里谈论的是跨时钟域。有效信号一般是和数据对齐的,那么在传递数据和使能(或有效)信号到下一个时钟域的时候,只需要同步使能信号。下图是一种常用的跨时钟传递使能控制信号的处理方法。将使能信号经过同步器同步后传递到一个同步脉冲发生器,然后产生一个指示信号用于指示非同步多周期数据,即可在下一个接收时钟上升沿进行采集。


关键一点在于产生同步使能脉冲时,输入的控制信号的极性并不重要。图中显示输入信号d从低切换到高,在第7个时钟上升沿处再从高切换到低,看到只要输入信号d发生切换变化,都能产生同步使能脉冲,所以输入信号的每一次切换对应一次数据的变化。
值得一提的是,在单时钟域应用设计当中,经常用到类似的技术来产生数据有效信号。图中使用的是异或门,该技术的缺点是在脉冲的上升沿和下降沿都会产生一个同步脉冲,当只需要一个同步脉冲,或者说需要检测脉冲上升沿的时候,可以使用q3取反后与q2相与即可得到一个单一的同步脉冲,也即只会在上升沿处产生一个同步脉冲。
不同情况下的数据接口同步方法
输入、输出的延时(芯片间、PCB布线、一些驱动接口元件的延时等)不可测,或者可能有变动
- 对于数据的延迟不可测,或者变动,就需要建立同步机制。可以使用一个同步使能,或者同步指示信号。另外使数据通过RAM/FIFO存取。(RAM/FIFO的方法见上文)。
数据是有固定格式安排的,很多重要信息在数据的起始位置
- 这种情况在通信系统中非常普遍,通信系统中,很多数据数据都是按照“帧”组织的。而由于整个系统对时钟要求很高,常常设计一块时钟板完成高精度时钟的产生和驱动,而数据又是有起始位置的,数据的同步完全可以采用上一点的方法,采用同步指示信号,或者使用RAM/FIFO缓存一下。找到数据头的方法有两种,第一种很简单,随路传输一个数据起始位置的指示信号即可;对于有些系统,特别使异步系统封,则常常在数据中插入一段同步码(如训练序列),接收端通过状态机监测到同步码后,就能发现数据头,这种做法叫做“盲检测”。
上级数据和本级时钟是异步的,也就是说上级芯片或者模块和本级芯片或模块的时钟是异步时钟域
如果输入数据的节拍和本级芯片的处理时钟同频,可以直接使用本级芯片的时钟对输入数据寄存器采样,完成输入数据的同步化;如果输入数据和本级芯片处理时钟是异步的,特别是频率不匹配时,需要使用处理时钟对输入数据做两次寄存器采样,这样才能完成输入数据的同步化。但仅能避免亚稳态传播,并不能保证经过两级寄存器的数据一定正确。所以一般使用RAM/FIFO。
数据接口同步的约束
对于高速设计,一定要对周期、建立、保持时间等添加相应的约束,约束作用有:
- 提高设计的工作频率,满足接口数据同步的要求。通过附加周期、建立时间、保持时间等约束可以控制逻辑的综合、映射、布局和布线,以减小逻辑和布线延时,从而提高工作频率,满足接口数据同步的要求。
- 获得正确的时序分析报告。几乎所有的FPGA设计平台都包含静态时序分析报告,从而对设计的性能做出评估,静态时序分析工具以约束作为判断时序是否满足设计要求的标准,因此要求设计者能够正确输入约束,以便静态时序分析工具输出正确的时序分析报告。
与数据接口同步相关的常用约束
Xilinx
Xilinx可以附加的约束有:Period、OFFSET_IN_BEFORE、OFFSET_IN_AFTER、OFFSET_OUT_BEFORE、OFFSET_OUT_AFTER
Period

时钟的最小周期定义为:
Tclk = TCKO + TLOGIC + TNET + TSETUP - TCLK_SKEW
TCLK_SKEW = TCD2-TCD1 (如果定义Tskew = TCLK1 - TCLK2 则上式需要改为 + TCLK_SKEW)
其中TCKO是时钟输出时间(Tcq - Flop clock to Flop q delay,触发器传输延时),TLOGIC是同步元件之间的组合逻辑延迟(Tcomb - delay on the combinational logic between the Flops,中间组合逻辑延时),TNET是线网延迟, TSETUP是同步元件的建立时间,TCLK_SKEW是时钟信号延迟的差别。Skew(时钟偏移)是由于时钟信号达到寄存器的时间不同而引起的,jitter(时钟抖动)是时域的噪声信号引起的。
OFFSET_IN_BEFORE、OFFSET_IN_AFTER约束
OFFSET_IN_BEFORE 和 OFFSET_IN_AFTER 都是输入偏移约束。OFFSET_IN_BEFORE 说明了输入数据比有效时钟沿提前多长时间准备好,于是芯片内部与输入引脚相连的组合逻辑的延迟就不能大于该时间,否则有效时钟沿到来时,数据还没有稳定,采样将发生错误;OFFSET_IN_AFTER 指出输入数据在有效时钟沿之后多长时间到达芯片的输入引脚,这样也可以得到芯片内部延迟的上限,从而对与输入引脚相连的组合逻辑约束。
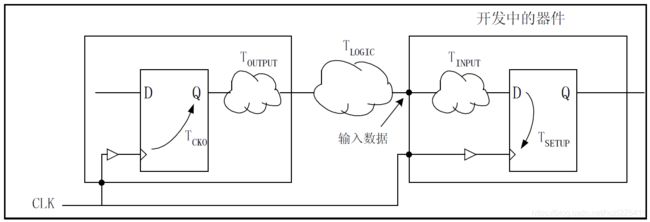
计算公式如下:
TARRIVAL = TCKO + TOUTPUT + TLOGIC
即输入数据在有效时钟沿之后的TARRIVAL时刻达到。有了这个数据之后,可以对设计输入端附加 OFFSET_IN_AFTER 约束。
例如:NET DATA_IN OFFET = IN TARRIVAL AFTER CLK;
这样对同步元件输入逻辑进行约束后,综合实现工具会努力使输入端的延时TINPUT满足以下关系:
TARRIVAL + TINPUT + TSETUP < Tclk
其中,Tinput为输入端的组合逻辑、线网和PAD的延迟之和,TSETUP为输入同步元件的建立时间。
OFFSET_OUT_AFTER 、 OFFSET_OUT_BEFORE约束
两者都是输出偏移约束,OFFSET_OUT_AFTER规定了输出数据在有效时钟沿之后多久稳定下来,那么芯片内部的输出延迟 就必须小于这个值。 OFFSET_OUT_BEFORE 指下一级芯片的输入数据应在有效时钟沿之前多长时间内准备好。
从下一级输入端的延迟可以计算出当前设计输出的数据必须在何时稳定下来,根据这个数据对设计输出端的逻辑布线进行约束,以满足下一级的建立时间要求,保证下一级采样的数据使稳定的。
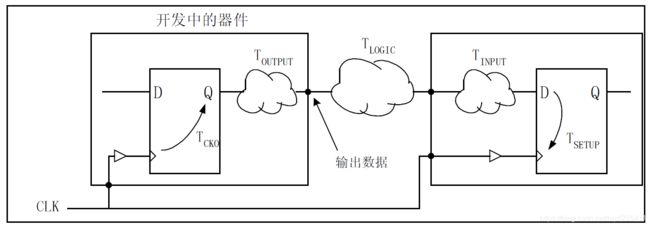
计算公式如下:
TSTABLE = TLOGIC + TINPUT + TSETUP
只要当前设计输出的数据比时钟上升沿提早TSTABLE时间稳定下来,下一级就能正确地采集数据。
根据这个数据可以对设计输出端附加 OFFSET_OUT_BEFORE 约束,例如:
NET DATA_OUT OFFET=OUT TSTABLE BEFORE CLK;
这样对同步元件输出端进行约束后,综合实现工具会努力调整该逻辑实现,使输出端的延迟满足一下关系:
TCKO + TOUTPUT + TSTABLE < Tclk
其中,TOUTPUT为设计中连接同步元件输出端的组合逻辑、线网和PAD的延迟之和,TCKO为同步元件的时钟输出时间。
Altera
Altera可以附加的约束有:Period、tus、tH、tco
Period
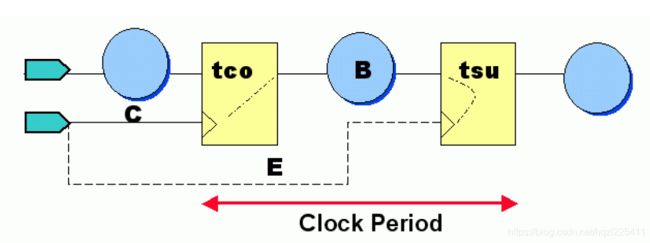
Clock Period = Clk-to-out + Data Delay + Setup Time - Clk Skew
Tclk = Tco + B + Tus - (E - C)
Fmax = 1/Tclk
对比Xilix,B中包含了两级寄存器之间的所以的logic和net的延时,与Xilinx周期定义公式完全一致。
Clock Setup Time(tsu)
想要正确采样数据,就必须使数据和使能信号在有效时钟沿达到前准备好,所谓时钟建立时间就是指时钟到达前,数据和使能已经准备好的最小时间间隔。

tus = Data Delay - Clock Delay + Micro tsu
这里定义Setup时间应该对应于整个路径的,需要区别的是另一个概念Micro tsu。Micro tsu指的是一个触发器内部的建立时间,这是触发器的固定属性,一般典型值小于1~2ns。Micro tus对应Xilinx的TSETUP。
Clock Hold Time(tH)
时钟保持时间是只能保证有效时钟沿正确采用的数据和使能信号的最小稳定时间。

tH = Clock Delay - Data Delay + Micro tH
Micro tH指寄存器内部的固定保持时间,同样是寄存器的一个固有参数。
Clock-Output Delay(tco)
这个时间指的是当时钟有效沿变化后,将数据推到同步时序路径的输出端的最小时间间隔。
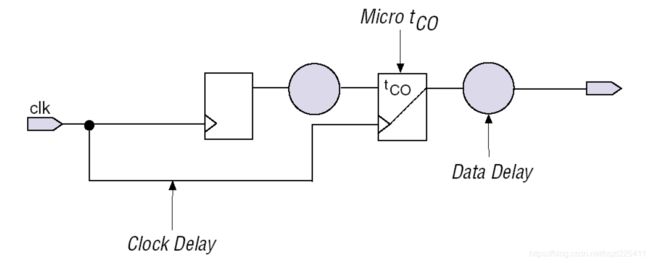
tco = Clock Delay + Micro tco + Data Delay
Micro tco是寄存器的固有特性,指寄存器相应时钟有效沿,将数据送到输出端口的内部时间参数,于Xilinx的Tcko是同一个概念。
代码风格
Coding Style, 即所谓的代码风格,Coding Style 因对象不同而异。前面已经说过本章描述的重点是区别于综合、实现工具的一-般意义的RTL级Coding Style。 这里有两层含义,首先本章所述为RTL级Coding Style,重点在于如何优化RTL级代码,并非其它层次的描述方式。所以诸如业界炒的非常热的结构化设计方法(Architectural-based design) 的代码风格的原则和方法与本章无关,甚至有很多原则和方法是与本章所述背道而驰的。
第二点,本章所描述的是不依赖于综合、实现工具的,一般意义上的代码风格。这一点深究起来比较容易混淆,首先大多数Coding Style 都是和综合工具相关联的,善于利用某种综合工具的特点,采取该综合工具推荐的Coding Style 编写RTL代码能够发挥该综合工具最大的潜能,达到事半功倍的效果。另一方面,不同的综合工具对一些语法细节的阐释略有不同,特别是那些关于优先级,实现的先后顺序等,所以不同的综合工具在个别细节上对Coding Style的解释有一定的差异。第三方面,有些Coding Style是针对某种器件的特点硬件结构的,用该厂商推荐的CodingStyle能够正确的实例化这类底层单元,合理的适用其固有的硬件结构,这种Coding Style 是与器件联系最紧密的。为了避免厚此薄彼,妄加评论,本章力图换一个角度,讨论一些一般综合工具 都支持,独立于器件之外的一-般意义上的
Coding Style的建议和准则。
架构层次设计和模块划分
架构层次编码
结构层次化编码(Hierarchical Coding)是模块化设计思想的一种体现。采用结构化编码风格,可以提高代码的可读性,易于模块划分,议于分工协作,易于设计仿真测试激励。最基本的架构化层次是由一个顶层模块和若干个子模块构成,每个子模块根据需要还可以包含自己的子模块。
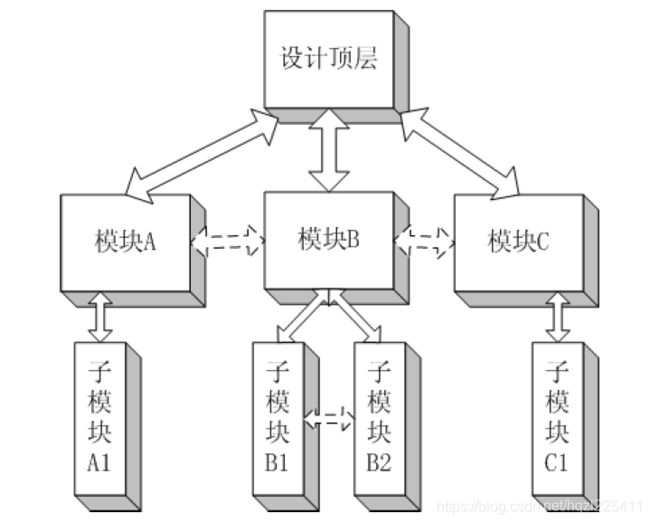
注意事项:
- 结构层次不易太深,一般为3~5层。在综合时,一般的综合工具为了获得更好的综合效果,特别是为了使综合结果所占用的面积更小,会默认将RTL代码打平。有时为了在综合后仿真和布局布线后的时序仿真钟较方便地找出一些中间信号,比如子模块之间的接口信号等,可以在综合工具中设置保留结构层次,以便仿真信号的查找和观察。
- 顶层模块最好包含对所有模块的组织和调用,而不应该完成比较复杂的逻辑功能。合理的顶层模块由输入/输出管脚声明、模块的调用与实例化、全局时钟资源、全局置位/复位、三态缓冲和一些简单的组合逻辑等组成。
- 所有的I/O信号,如输入、输出、双向信号等描述应该在顶层模块完成。
- 子模块之间也可以由接口,但最好不要建立子模块间跨层次的接口;如A1和B1之间不宜直接连接,需要交换的信号可以通过A、B的接口传递。
- 子模块的合理划分非常重要,应该综合考虑子模块的功能、结构、时序、复杂度等多方面的因素。
模块划分技巧
- 对每个同步时序设计的子模块的输出使用寄存器
这也称为用寄存器分割同步时序模块的原则。使用寄存器分割同步时序单元的好处是:便于综合工具衡量所分割的子模块中的组合电路和同步时序电路部分,从而达到更好的时序优化效果,这种模块划分符合时序约束的习惯,便于利用约束属性进行时序约束。
- 将相关的逻辑或者可以复用的逻辑划分在同一个模块中
这个做法也称为呼应系统原则,这样做的好处有:一方面将相关的逻辑和可以复用的逻辑划分在同一模块,可以最大程度上复用资源,减少设计所消耗的面积;另一方面更利于综合工具优化某个具体功能的时序关键路径。原因是,传统的综合工具只能同时优化某一部分的逻辑,而所能同时优化的逻辑的基本单元的就是模块,所以将相关功能划分在同一模块将在时序和面积上获得更好的综合优化效果。
- 将不同优化目标的逻辑分开、
合理的设计目标应该是综合考虑面积最小和频率最高两个指标,并对设计的优化目标有一个整体上的把握。对于时序紧张的部分,应该独立划分为一个模块,其优化目标为“speed”,这种划分方法便于设计者进行时序约束,也便于综合和实现工具进行优化。例如时序优化的利器Amplify, 以模块为单元进行物理区域约束,从而优化关键路径时序,以达到更高的系统工作频率就更为方便有效。另一类情况是:设计的矛盾主要集中在芯片的资源消耗上。这时应该将资源消耗过大的部分划分为独立的模块,这类模块的优化目标应该定为"Area"。同理,将他们规划到一起,更有利于区域布局与约束。这种根据优化目标进行优化的方法的最大好处是:对于某个模块综合器仅仅需要考虑一种优化目标和策略,从而比较容易达到较好的优化效果。相反的如果同时考虑两种优化目标,会使综合器陷入互相制约的困境,造成耗费巨大的综合优化时间也得不到令人满意的综合优化结果的局面。
- 将时序约束较松的逻辑归到同一模块
有些逻辑的时序非常宽松,不需要较高的时序约束,可以将这类逻辑归入同一模块,如多周期路径(multi-cycle path) 等。将这些模块归类,并指定松约束,则可以让综合器尽量的节省面积资源。将存储逻辑独立划分成模块
- 将存储逻辑独立划分成模块
RAM、ROM、CAM、FIFO等存储单元应该独立划分模块。这样做的好处是便于利用综合约束属性显化指定这些存储单元的结构和所使用的资源类型,也便于综合器将这些存储单元自动类推为指定器件的硬件原语。另一个好处是在仿真时消耗的内存也会少些,便于提高仿真速度。这是因为大多数仿真器对大.
面积的RAM都有独特的内存管理方式,以提高仿真效率。
- 合适的模块规模
从理论上将,模块的规模越大,越利于模块资源共享( Resource Sharing)。 但是庞大的模块,将要求对综合器同时处理更多的逻辑结构,这将对综合器的处理能力和计算机的配置提出了较高的要求。另外庞大的模块划分,不利于发挥目前非常流行的增量综合与实现技术的优势。
组合逻辑的注意事项
always组合逻辑信号敏感表
- 正确的信号敏感表设计方法是将always模块中使用到的所有输入信号和条件判断信号都列在信号敏感表中;
- 希望通过信号敏感表的增减完成某项逻辑功能是不可能的;
- 不完整的信号敏感表会造成前仿真结果和综合、实现后仿真结果不一致;
- 一般综合工具对于不完整的信号敏感表的默认做法是,将处理进程中用到的所有输入和判断条件信号都默认添加到综合结果的敏感表中,并对原设计代码敏感表中遗落的信号报警(warning)信息。
组合逻辑环路
组合逻辑反馈环路是数字同步逻辑设计的大忌,最容易因振荡、毛刺、时序违规等引起整个系统的不稳定和不可靠。

寄存器的Q端输出直接通过组合逻辑反馈到寄存器的异步复位端,如果Q输出为0时,经过组合逻辑运算后为异步复位端有效,则电路进入不断清零的死循环。
组合逻辑反馈环路是一种高风险设计方式,原因如下:
- 组合反馈环的逻辑功能完全依赖于其反馈环路上组合逻辑的门延迟和布线延迟等,如果这些传播延迟有任何变化,则该组合反馈单元的整体逻辑功能将彻底改变,而且改变后的逻辑功能很难确定;
- 组合反馈环的时序分析是无穷循环是时序计算,综合、实现等EDA工具迫不得已必须主动割断其时序路径,已完成相关时序计算,而不同的EDA工具对组合反馈环的处理方法各不相同,所以组合反馈环的处理方法各不同,所以组合反馈环的最终实现结果有很多不确定因素。
同步时序系统中应该避免使用组合反馈环路,注意事项有一下两点:
- 任何反馈环路必须包含寄存器;
- 检查综合、实现报告的Warning信息,发现Combinational Lopps后,进行相应的修改。
脉冲发生器
在异步时序设计中,常用延时链(Delay Chains)产生脉冲,常用的异步脉冲产生方式:
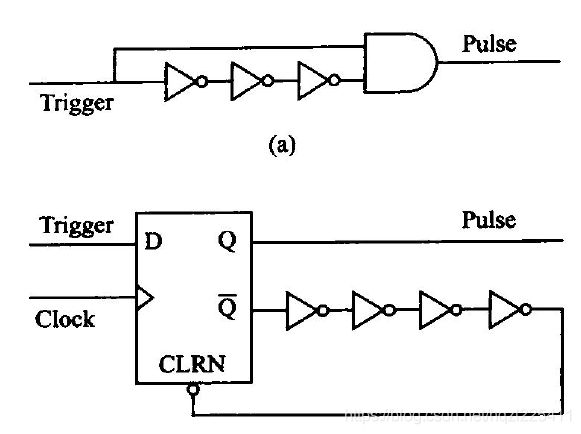
这类异步方法设计的脉冲产生电路的脉冲宽度取决于Delay Chains的门延迟和线延迟,而在FPGA中,大多数Timing Driven的综合、布线工具无法保证其布线延迟恒定。另外,PLD器件本身在不同的PVT(工艺、电压、温度)环境下其延时参数也有微小波动,所以脉冲宽度无法确定。而且STA(静态时序分析)工具也无法准确分析脉冲的特性,为时序仿真和验证带来了很多不确定性。
异步脉冲序列产生电路(Multi-Vibrators)也被称为毛刺生成器(Glitch Generator),利用组合反馈环路振荡而不断产生毛刺。如上所述,组合反馈环是同步时序必须避免的,这类基于组合反馈环的Multi-Vibrators会给设计带来稳定性、可靠性方面的问题,必须避免使用。
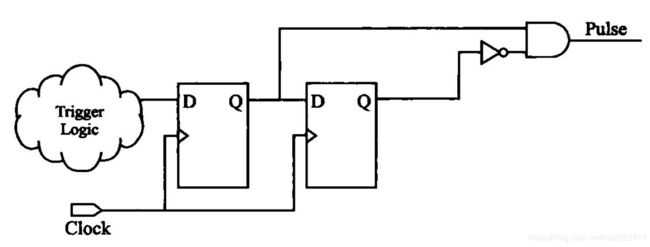
上图是同步时序设计脉冲电路的常用方法,这个设计的脉冲宽度不因器件或者设计移植而改变,恒等于时钟周期,而且避免了异步设计的诸多不确定因素,其时序路径便于计算、STA分析和仿真验证。
慎用锁存器
同步时序设计要尽量慎用锁存器(Latch),特别要注意综合出与设计意图不一致的Latch导致仿真和设计错误。对于某些特定设计一定要使用Latch时,设计者必须明确该Latch是否为有意设计的。综合出与设计意图不吻合的Latch结构主要原因在于:在设计组合逻辑时,使用不完整的条件判断语句。如:有if而没有else,或者不完整的case语句(这仅是一种可能,并不一定生成Latch);另一种情况是设计中有组合逻辑的反馈环路(combinational feedback loops)等异步逻辑。
防止产生非目的性的Latch的措施
- 使用完备的if…else语句;
- 为每个输出条件设计输出操作,对case语句设置default操作,特别是在状态机中,最好有一个default的状态转移,而且每个状态最好有一个default操作;
- 如果使用case语句时,特别是在设计状态机时,尽量附加综合约束属性,综合为完全条件case语句(full case);
- 检查设计中是否含有组合逻辑反馈环路。
时钟设计的注意事项
时钟是同步设计的基础,在同步设计中,所有的操作都是基于时钟沿触发的,所以时钟的设计对同步时序电路而言非常重要。对PLD设计,通常推荐使用FPGA内嵌的PLL/DLL完成时钟的频率与相位变化,并用全局时钟和专用时钟选择器进行时钟布线。对ASIC设计,常会用到各种各样的组合逻辑产生时钟,但这些时钟如果直接移植到同步时序电路中会带来各种各样的问题。
内部逻辑产生时钟
如果需要使用内部逻辑产生时钟,必须要在组合逻辑产生的时钟后插入寄存器,如下图。如果直接使用组合逻辑产生的信号作为作为时钟信号或者异步置位/复位信号,会使设计不稳定,这是因为组合逻辑难免产生毛刺,这些毛刺经过寄存器采样后一般影响不大,但如果作为时钟信号或者异步置位/复位信号时,如果毛刺的宽度足以驱动寄存器的时钟端或者异步置位/复位端,则必将产生错误的逻辑操作;即使毛刺的宽度不足以驱动时钟或异步置位/复位端,也会带来寄存器的不稳定,甚至激发寄存器产生亚稳态。所以对于时钟路径,必须插入寄存器以过滤毛刺。
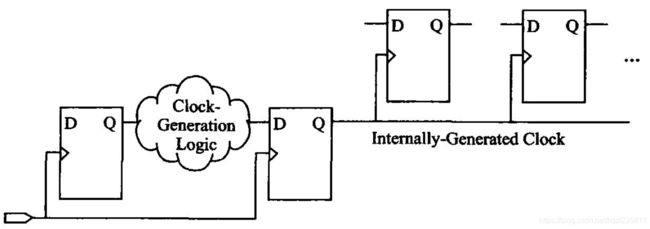
另一方面,组合逻辑产生发时钟还会带来另一个问题,组合逻辑电路的Jitter和Skew都比较大,如果时钟产生逻辑的延迟比数据路径的延迟更大,会造成负的Skew,负的Skew同步逻辑设计是灾难性的。所以使用组合逻辑产生内部时钟仅适用于时钟频率较低、时钟精度要求不高的情况。另外,这类时钟应该使用快速布线资源布线,而且需要对组合逻辑电路附加一定的约束条件,以确保时钟质量。
Ripple Counter
Ripple Counter即行波计数器,其结构为:一组寄存器级连,每个寄存器的输出接到下一级寄存器的时钟管脚,这种计数器常常用于异步分频电路。早期的PLD设计经常使用Ripple Counter以节约芯片资源。但由于Ripple Counter是一种典型的异步时序逻辑,异步时序逻辑会带来各种各样的问题,在同步时序中必须严格避免使用Ripple Counter。
时钟选择
在通信系统中,为了适应不同的数据速率要求,经常要进行时钟切换。有时为了节约功耗,也会把高速时钟切换到低速时钟,或者进行时钟休眠操作。时钟切换的最佳途径是使用芯片内部的专用Clock MUX。这些MUX的反应速度快,锁定时间短,切换瞬间带来的冲击和抖动小。
如果器件没有专用的Clock MUX,应尽量满足如下几点:
- 时钟切换控制逻辑在配置后将不再改变;
- 时钟切换之后,对所有相关电路复位,以保证所有寄存器、状态机和RAM等电路的状态不会锁死或者进入死循环;
- 所设计系统对时钟切换过程发生的短暂错误不敏感。
门控时钟
门控时钟即Gated Clock,如下图。是IC设计的一种常用的减少功耗的手段,通过Gating Logic的控制,可以控制门后端的所有寄存器不再翻转,从而有效的节约功耗。

但Gated Clock不是同步时序电路,其Gating Logic(门控逻辑)会污染Clock质量,通过控制门后会产生毛刺并使时钟Skew(偏斜)、Jitter(延时)等指标恶化。在同步时序电路中,尽量不要使用Gated Clock。
下图是改进的门控时钟电路。虽然这个改进电路已经在较大程度上解决了门控电路产生的毛刺,但要注意,这个电路工作的前提是时钟源Clock的占空比(Duty Cycle)是非常理想的50%,如果时钟的占空比不能保证50%,则会产生许多有规律的毛刺。

RTL代码优化技巧
使用Pipelining技术优化时序
Pipelining 即流水线时序优化方法,其本质是调整一个较长的组合逻辑路径中寄存器的位置,用寄存器合理分割该组合逻辑路径。从而降低对路径的clock-to-output 和 setup 等时间参数的要求,达到提高设计频率的目的。但要注意的是,使用Pipelining优化技术只能合理的调整寄存器的位置,而不应该凭空增加寄存器的级数,所以 Pipelining 有时也叫 Register Balance。
目前一些先进的综合工具能根据用户参数设置,自动运用Pipelining技术,用寄存器平衡设计(Register Balance)中较长的组合路径,在一定程度上提高设计的工作频率。这种时序优化手段对乘法器、ROM等单元效果显著。
模块复用与Resource Sharing
Resource Sharing例子:一个补码平方器
module resource_share1 (data_in,square);
input [7:0] data_in; //输入是补码
output [15:0] square;
wire [7:0] data_bar;
assign data_bar = ~data_in + 1;
assign square=(data_in[7])? (data_bar*data_bar) : (data_in*data_in);
endmodule
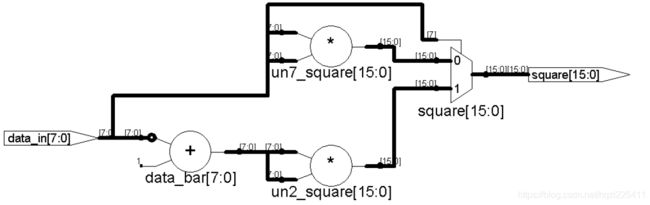
module resource_share2 (data_in,square);
input [7:0] data_in; //输入是补码
output [15:0] square;
wire [7:0] data_tmp;
assign data_tmp = (data_in[7])? (~data_in + 1) : data_in;
assign square = data_tmp * data_tmp;
endmodule

第一种实现方式需要两个16bit乘法器,同时平方,然后根据输入补码的符号选择输出结果,其关键在于使用了两个乘法器,选择器在乘法之后。第二种实现方法,首先根据输入补码的符号,换算为正数,然后再做平方,其关键在于仅仅使用一个乘法器。第二种实现方法与第一种实现方法相比节约的资源有两部分:
- 节约了一个16bit乘法器;
- 后者的选择器是1bit判断8bit,前者是1bit判断16bit的输出。
逻辑复制
逻辑复制,是一种通过增加面积而改善时序条件的优化手段。逻辑复制最常使用的场合是调整信号的扇出。如果某个信号需要驱动后级的很多单元,换句话说,也就是其扇出非常大,那么为了增加这个信号的驱动能力,必须插入很多级buffer, 这样就在一定程度 上增加了这个信号路径的延时。这时我们可以复制生成这个信号的逻辑,使多路同频同相的信号驱动后续电路,平均到每路的扇出变低,不需要加buffer也能满足驱动能力的要求,这样就节约了该信号的路径时延。
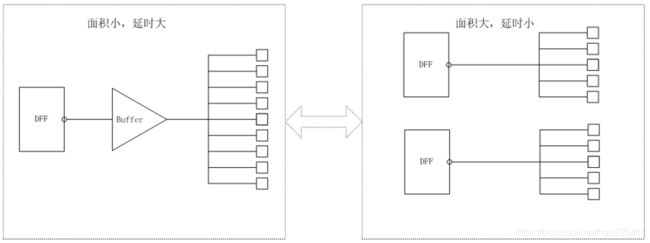
需要说明的是,现在很多综合工具都可以自动设置最大扇出值(Max Fanout), 如果某个信号的扇出值大于最大扇出,则该信自动被综合工具复制。最大扇出值和器件的工艺密切相关,其合理值应该根据器件手册的声明和工程经验设置。这里举例用逻辑复制手段调整扇出,达到优化路径时延仅仅是为了讲述逻辑复制的概念,其实逻辑复制还有其它很多形式。例如香农扩展( Shannon Expansion)等时序优化技术。香农扩展在后面将会有详细的介绍。
逻辑复制和资源共享是两个矛盾的概念,既然使用了资源共享优化技术,为什么还要做逻辑复制呢?其实这个问题的本质,还是面积与速度的平衡。逻辑复制与前面的Resource Sharing 是两个对立同一的概念。Resource Sharing 的目的是为了节省面积资源,而逻辑复制的目的是为了提高工作频率。当使用逻辑复制手段提高工作频率的时候,必然会增加面积资源,这是与资源共享相对立的方面;但是正如前面第一章面积与速度的对立统一- 样,逻辑复制和资源共享都是要到的设计目标的两种手段,一个重于速度目标,一个侧重于面积目标,两者存在一种转换与平衡的关系,所以两者又是统一的。
一个加法器哦的资源共享的例子
//第一种
module mod_copy1 (sel, a, b, c, d, data_out);
input sel, a, b, c, d;
output data_out;
assign data_out= (sel)? (a+b) : (c+d) ;
endmodule
//第二种
module mod_copy1 (sel, a, b, c, d, data_out);
input sel, a, b, c, d;
output data_out;
wire temp1, temp2;
assign temp1 = (sel)? (a) : (c) ;
assign temp2 = (sel)? (b) : (d) ;
assign data_out = temp1 + temp2;
endmodule
第一种写法比第二种省了一个加法器。但是严格的来讲,第一种写法比第二种写法耗时略微小一些,这在本例还不算十分明显,当运算模块不是加法器而是一些较复杂的逻辑时,会比较明显。当设计的时序满足要求,或者设计的面积紧张时,我们一般般会采用资源共享的优化方法,将第一种设计转换为第二种设计,绝大多数情况如是;但是在某些特殊情况下,时序非常紧张,我们会反其道而行之,将第二种设计转换为第一种设计, 从而便于调整组合逻辑信号的到达时间,提高这个加法选择器的工作频率。
香农扩展运算
香农扩展(Shannon Expansion)是一种逻辑复制,增加面积,提高频率的时序优化手段。其概念如下,布尔逻辑可以做如下扩展:
F(a,b,c) = aF(1,b,c) + a’F(0,b,c)
可以看到,香农扩展即布尔逻辑扩展,是卡诺图化简的反向运算,香农扩展相当于逻辑复制,提高频率;而卡诺逻辑化简相当于资源共享,节约面积。
香农扩展通过增加MUX,从而缩短了某个优先级高,但组合路径长的信号路径时延,从而提高了该关键路径的工作频率。
例子:
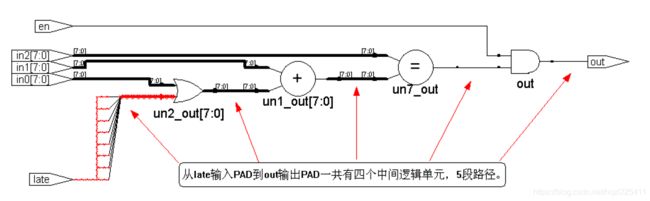
F = ((({8{late}}|in0) + in1) == in2) & en;
in0, in1, in2 都是8bit的数据,信号late和en是控制信号,late是本逻辑运算的关键路径信号,延时最大.
使用香农扩展运算得到:
F = ((({8{late}}|in0) + in1) == in2) & en
= late[((({8{1'b1}}|in0) + in1) == in2) & en] + ~late[((({8{1'b0}}|in0) + in1) == in2) & en]
= late[(8'b1 + in1) == in2 & en] + ~late[(8'b0 + in1) == in2 & en]
以late作为选择信号,late信号的优先级被提高,其信号路径的延时降低,但其代价是设计的面积增加了。
module un_shannon (in0, in1, in2, late, en, out);//未使用香农扩展
input [7 : 0] in0, in1, in2;
input late, en;
output out;
assign out = ((({8{late}} | in0) + in1) == in2) & en;
endmodule
module shannon_fast (in0, in1, in2, late, en, out);
input [7 : 0] in0, in1, in2;
input late, en;
output out;
wire late_eq_0, late_eq_1;
assign late_eq_0 = ((in0+in1) == in2) & en;
//assign late_eq_0 = ((({8{1'b0}} | in0) + in1) == in2) & en;
assign late_eq_1 = ((8'b1+in1) == in2) & en;
//assign late_eq_1 = ((({8{1'b1}} | in0) + in1) == in2) & en;
assign out = (late) ? late_eq_1 : late_eq_0;
endmodule
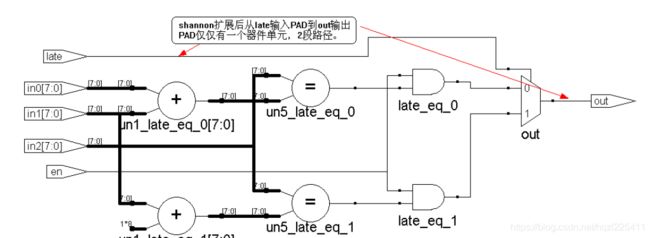
虽然使用不同的器件族,综合结果的工作频率不一致,但是从RTL视图可以清晰的看到,采用香农扩展后,对于late信号这一关键路径,消除了3个逻辑层次,从而大幅度的提高了设计的工作频率。作为提高工作频率的代价,是多用1个加法器和选择器,消耗了更多的面积。正如前面反复强调的面积和速度的平衡关系所述,是否使用香农扩展时序优化手段,关键要看被优化对象的优化目标是面积还是路径。
补充
思想与技巧:乒乓操作
“乒乓操作”是一个常常应用于数据流控制的处理技巧。
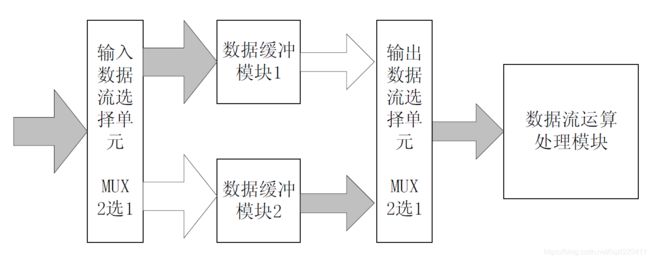
乒乓操作的处理流程描述如下:输入数据流通过“输入数据选择单元”,等时的将数据流等时分配到两个数据缓冲区。数据缓冲模块可以为任何存储模块,比较常用的存储单元为双口RAM(DPRAM)、单口RAM(SPRAM)、FIFO等。在第一个缓冲周期,将输入的数据流缓存到“数据缓冲模块1”中。在第二个缓冲周期,通过“输入数据选择单元”切换,将输入的数据流缓存到“数据缓冲模块2”中。输入的数据流缓存到“数据缓冲模块2”,与此同时,将“数据缓冲模块1”缓存的第1个周期的数据通过“输入数据选择单元”的选择,送到“数据流运算处理模块”被运算处理。在第3个缓冲周期,通过“输入数据选择单元”的再次切换,将输入的数据流缓存到“数据缓冲模块1”,与此同时,将“数据缓冲模块2”缓存的第2个周期的数据通过“输入数据选择单元”的切换,送到“数据流运算处理模块”被运算处理。如此循环,周而复始。
乒乓操作的最大特点是,通过“输入数据选择单元”和“输出数据选择单元”按节拍、相互配合的切换,将经过缓冲的数据流没有时间停顿的送到“数据流运算处理模块”,被运算与处理。把兵乓操作模块当做-一个整体,站在这个模块的两端看数据,输入数据流和输出数据流都是连续不断的,没有任何停顿,因此非常适合对数据流进行流水线式处理。所以乒乓操作常常并应用于流水线式算法,完成数据的无缝缓冲与处理。
乒乓操作的第二个优点是可以节约缓冲区空间。比如在WCDMA基带应用中,1帧(Frame)是由15 个时隙(Slot) 组成的,有时需要将1整帧的数据延时一个时隙后处理,比较直接的办法是将这帧数据缓存起来,然后延时1个时隙,进行处理。这时缓冲区的长度是1整帧数据长,假设数据速率是3.84Mb/s, 1帧长10ms, 则此时需要缓冲区长度是38400bit。如果采用乒乓操作,只需定义两个能缓冲1个slot 数据的RAM (单口RAM即可),当向一块RAM写数据的时候,从另一块RAM读数据,然后送到处理单元处理,此时,每块RAM的容量仅需2560bit即可。2块RAM加起来也只有5120bit的容量。
另外巧妙的运用乒乓操作,还可以达到用低速模块处理高速数据流的效果。如下图所示,数据缓冲模块采用了双口RAM,并在DPRAM后引入了一级数据预处理模块,这个数据预处理可以根据需要是各种数据运算,比如在WCDMA设计中,对输入数据流的解扩、解扰、去旋转等。假设端口A的输入数据流的速率为00Mb/s,乒乓操作的缓冲周期是10ms。我们下面一起分析一下各个节点端口的数据速率。

输入数据流A端口处数据速率为100Mb/s,在第1个缓冲周期10ms内,通过“输入数据选择单元”,从B1到达DPRAM1。B1的数据速率也是100Mb/s, 在10ms 内,DPRAM1要写入1Mb数据。同理在第2个10ms,数据流被切换到DPRAM2,端口B2的数据速率也是100Mb/s,DPRAM2在第2个10ms被写入1Mb数据。周而复始,在第3个10ms,数据流又切换到DPRAM1, DPRAM1被写入1Mb数据。.
仔细分析一下,就会发现到第3个缓冲周期时,留给DPRAM1读取数据并送到“数据预处理模块1” 的时间- -共是20Ms。有的同事比较困惑于DPRAM1的读数时间为什么是20ms,其实这一点完全可以实现。首先在在第2个缓冲周期,向DPRAM2写数据的10ms内,DPRAM1可以进行读操作;另外在第1个缓冲周期的第5ms起(绝对时间为5ms时刻),DPRAM1就可以边向500K以后的地址写数,边从地址0读数,到达10ms 时,DPRAM1刚好写完了1Mb 数据,并且读了500K数据,这个缓冲时间内DPRAM1读了5ms的时间;另外在第3个缓冲周期的第5ms起(绝对时间为35ms时刻),同理可以边向500K以后的地址写数,边从地址0读数,又读取了5个ms,所以截止DPRAM1第一个周期存入的数据被完全覆盖以前,DPRAM1最多可以读取了20ms 时间,而所需读取的数据为1Mb,所以端口C1的数据速率为: 1Mb/20ms=50Mb/s。 因此“数据预处理模块1” 的最低数据吞吐能力也仅仅要求为50Mb/s。 同理“数据预处理模块2”的最低数据吞吐能力也仅仅要求为50Mb/s。 换言之,通过乒乓操作,“数据预处理模块”的时序压力减轻了,所要求的数据处理速率仅仅为输入数据速率的1/2。
思想与技巧:流水线操作
首先需要声明的是这里所讲述的流水线是指一-种处理流程和顺序操作的设计思想,并非FPGA、ASIC设计中优化时序所用的“Pipelining”,关于Pipelining 优化时序的方法在上文有详细介绍。
流水线处理是高速设计中的一个常用设计手段。如果某个设计的处理流程分为若干步骤,而且整个数据处理是“单流向”的,即没有反馈或者迭代运算,前一个步骤的输出是下一个步骤的输入则可以考虑采用流水线设计方法提高系统的工作频率。流水线设计的结构示意图如下图所示:

其基本结构为:将适当划分的n个操作步骤单流向串联起来。流水线操作的最多特点和要求是,数据流在各个步骤的处理,从时间上看是连续的,如果将每个操作步骤简化假设为通过一个D触发器(就是用寄存器打一个节拍),那么流水线操作就类似一个移位寄存器组,数据流依次流经D触发器,完成每个步骤的操作。流水线设计时序示意图如下图所示:

流水线设计的一一个关键在于:整个设计时序的合理安排、前后级接口间数据流速的匹配。这就要求每个操作步骤的划分必须合理,要统筹考虑各个操作步骤间的数据流量。如果前级操作时间恰好等于后级的操作时间,设计最为简单,前级的输出直接汇入后级的输入即可。如果前级操作时间小于后级的操作时间,则需要对前级的输出数据适当缓存,才能汇入后级,还必须注意数据速率的匹配,防止后级数据的溢出。如果前级操作时间大于后级的操作时间,则必须通过逻辑复制、串并转换等手段将数据流分流,或者在前级对数据采用存储、后处理方式,否则会造成与后级的除了节拍不匹配。流水线处理方式之所以频率较高,是因为复制了处理模块,它是面积换取速度思想的又一种具体体现。
思想与技巧:串并转换
串并转换是FPGA设计的一个重要技巧,从小的着眼点讲,它是数据流处理的常用手段,从大的着眼点将它是面积与速度互换思想的直接体现。串并转换的实现方法多种多样,根据数据的排序和数量的要求,可以选用寄存器、RAM等实现。前面在乒乓操作的举例,就是通过DPRAM实现了数据流的串并转换,而且由于使用了DPRAM,数据的缓冲区可以开的很大。对于数量比较小的设计可以采用寄存器完成串并转换。如无特殊需求,应该用同步时序设计完成串并之间的转换。比如数据从串行到并行,数据排列顺序是高位在前,可以用下面的编码实现:
prl_ temp <= {prl_ temp,sr1_ in};
其中,prl _temp是并行输出缓存寄存器,srl _in 是串行数据输入。对于排列顺序有规定的串并转换,可以用case语句判断实现。对于复杂的串并转换,还可以用状态机实现。串并转换的方法总的来说比较简单,在此不做更多的解释。
高速串行收发器
为了提供更加丰富多彩的业务,和高质量的服务,很多新型通讯标准对传输速率和信号带宽都提出了更高的要求,如3G移动通讯、10G 以太网、0C192等等标准,其应用带宽都达到了GHz 级。为了满足新技术的需求,设计者设计者必须找到高速率、高可靠性、低成本的解决方案。面对这些挑战,高速串行互连方法逐步成了首选解决方案。串行背板相对于并行互联背板有许多显著的优点。串行连接地第一-个也是最重要的优点是高性能和高鲁棒性(Robust)。下图是并行数据传输和串行数据传输的示意图,两者的对比如下:
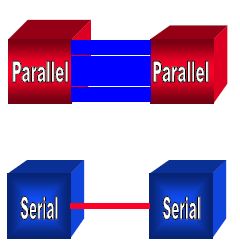
- 并行数据传输
- 多根线占用板面积
- 每根线之间互相有干扰
- 每根线需要自己的匹配电路
- 串行数据传输
- 更少的走线,占用的板面积减小
- 信号线的干扰降到最小
- 相对于并行传输只用了一小部分的匹配电路
- 没有相位差(skew)的问题
正因为上述特点,使用串行传输方式比并行传输方式更适合目前高速领域的应用。早期的串行传输的速率过低,设计复杂,所以体现不出其优势,随着微电子技术与工艺的发展,FPGA内嵌的高速串行收发器以其传输速率高、使用方便、性能可靠等优点为串行传输方案注入了新的活力。
串行收发器的英文缩写是SERDES(SERializer & DESerializer)顾名思义,它由两部分构成:发端是串行发送单元SERializer,用高速时钟调制编码数据流;接端为串行接收单元DESerializer,其主要作用是从数据流中恢复出时钟信号,并解调还原数据,根据其功能,接收单元还有一个名称叫时钟数据恢复器(CDR, Clock and data Recovery)。下图为10根数据线的串行传输和解串行接收示意图,10 根100Mhz的信号线进入SERDES器件产生串行码流,时钟也调制到码流内。反过来通过它恢复并行的数据和时钟。
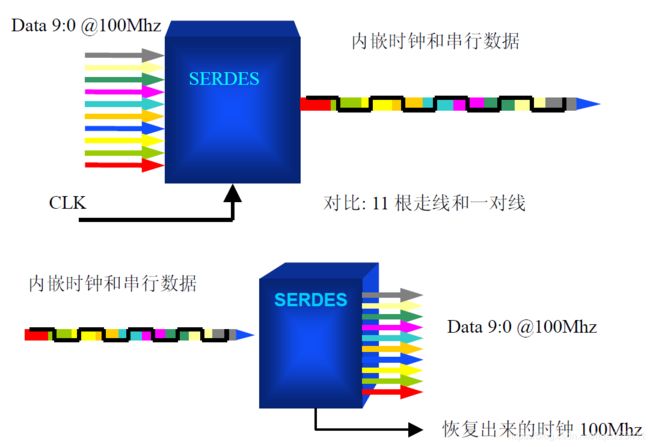
FPGA与DMD控制芯片DLPC410之间进行数据传输使用了数据转换比为4:1的SERDES模块:
4:1数据转换比时:CLK是CLKDIV的两倍,CLK是接口时钟频率,CLKDIV是FPGA内部电路工作频率。输出采用了双边沿(DDR)有效,时钟又是两倍,所以实现了4:1的数据转换比。

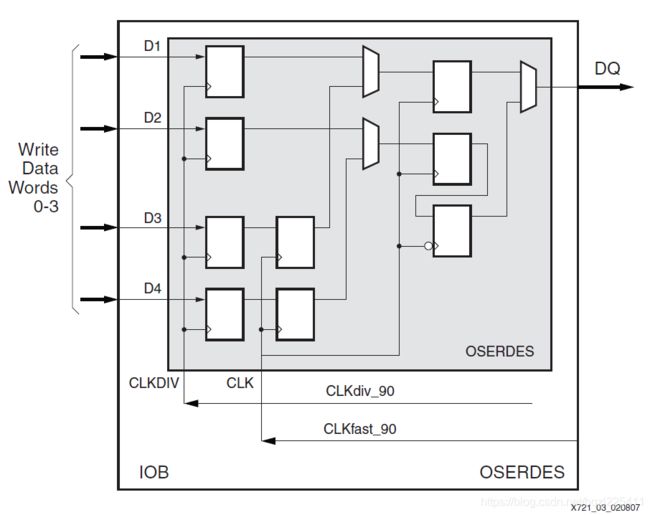
Virtex-5种输入串转并使用的是:输入串并转换逻辑资源 (ISERDES)
存储器RAM/ROM/CAM
FPGA中其实并没有专用的ROM资源,实现ROM的思路是对RAM赋初值,并保持该值。CAM(Content Addressable Memory)即内容地址存储器,在其每个存储单元都包含一个内嵌的比较逻辑,并返回于端口数据相同的所有内部数据的地址。RAM是一种根据地址读、写数据的存储单元;CAM与RAM相反,返回的是与端口数据相匹配的内存地址。CAM的应用也非常广泛,比如在路由器中 地址交换表等。
可以综合为存储器件的3种资源
与RAM等存储单元相关的资源有三类:Block RAM、LUT、Register。Block RAM即块RAM(BRAM),有时被称为Embedded Block RAM,指FPGA种内嵌的存储单元,这种RAM单元可以通过配置个glue logic(粘合逻辑)实现为单口/双口RAM、ROM、CAM、FIFO等。为了满足SOPC和复杂应用,高端FPGA种的内嵌的BRAM的容量与可配置的端口数量越来越丰富。FPGA的底层可编程逻辑单元无一例外都是触发器(Flip-Flop,FF)和查找表(Look-Up-Table,LUT)的结构,这两种基本的可编程资源都可以综合成RAM等存储单元。比较小,速度高的存储结构可以用寄存器资源实现;相对大一下,时序余量宽松的存储单元可以用LUT实现。
-
生产RAM等存储单元时,应该首选Block RAM资源
特别需要强调的是Block RAM资源的使用。由于Block RAM资源是FPGA内嵌的一种独立资源,所以推荐在生产RAM、ROM、CAM等存贮单元时,尽量首先使用Block RAM,其原因有二:第一,使用Block RAM资源,可以节约更多的FF和4-LUT等底层可编程单元。使用Block RAM可以说是“不用白不用”,是最大程度发挥所选器件效能,节约成本的一种体现;第二,Block RAM是一种可以配置的硬件结构,其可靠性和速度与用LUT和
Register构建的存贮器更有优势。 -
弄清FPGA的硬件结构,合理使用Block RAM资源
使用Block RAM时,必须要配合所选器件的结构。反之,器件选型时也必须要考虑到设计中使用到的RAM、ROM、CAM等存贮单元的容量、端口数量、结构等。一般来说用Blcok RAM可以构建出带有同步复位/置位、异步复位/置位,可选输入寄存器采样,可选输出寄存器采样等不同应用的单口/双口1多口RAM、ROM、CAM、同步/异步FIFO等典型存贮单元。在设计RAM的端口时,必须要根据Block RAM的特点,不可随意设计。
比如某个设计为 了能够在一个节拍一次读出256个数据,于是就写了一个单端口写入,256端口读出的RAM。事实上,目前没有任何一款FPGA的Block RAM的端口数量256左右!该RAM如果深度和宽度较大,也不宜于使用FF或者4-LUT(最近推出的FPGA一般是6-LUT)实现,那样将会消化巨大的可编程逻辑资源;如果用Blcok RAM实现,需要多个Block RAM拼接起来才能完成256个读端口,且不论拼接多个Block RAM需要的复杂的glue logic将会消耗巨大的逻辑资源,把很多Block RAM拼接起来,如果每个Block RAM的容量都没有使用完,将会造成非常大的Block RAM资源的浪费。
目前大多数Block RAM硬件上真正的端口配置是2 port ( true dual-read/write port)或者4 port ( true quad-read/write port) 的,设置者在使用时应该查证该器件的器件手册,尽量使用端口数量匹配的RAM,此时消耗的gluelogic最少,对Block RAM的利用率最高。在FPGA设计中,对于上面的那个例子应该摒弃使用256端口读的RAM,改用其它设计方法。例如在设计频率允许时,可以高速从1个或者一组DPRAM (双口RAM)、QPRAM (4端口RAM)读数据,然后把读出的数据缓存等齐。具体选择几块RAM和深度应该根据其器件速度和读写速度确定。通过提高频率、缓冲等齐、状态机控制等方法完全可以将那个256 端口读的设计改为等效的DPRAM或QPRAM的设计。从而避免了对逻辑资源的浪费,和物理实现上的问题。EDACN论坛上一位工程师使用Xilinx VirelI1000器件实现上述设计,改进前资源利用率大于40%的slice,最高时钟频率Max clock frequency 为32MHz;改进后资源利用率为6% slice + 2blockRAM,最高时钟频率Max clock frequency为140MHz。
-
分析BRAM容量,高效使用BRAM资源
上面举是没有考虑到Block RAM的端口数量,导致无法有效使用BRAM的例子。其实Block RAM还有很多特性非常重要,比如硬件上BlockRAM的分块数量、单块的容量、单块支持的存储深度和数据宽度等。每种FPGA的Block RAM都是以“块”的形式组织的,每块是一个一个相对独立的可配置存储器,支持不同存储深度和数据宽度的组合。有的FPGA里面只有一种Block RAM的块大小,相对比较好掌握,但是部分FPGA为了加强Blcok RAM的利用率,为用户提供更灵活的存贮方案,在其高端FPGA中,提供了多种不同容量的Block RAM。比如其Stratix/StratixGX 等系列FPGA中有一种叫TriMatix Memory 的Block RAM架构,其特点是在芯片中内嵌了三种不同大小的RAM块,分别是: 512Bits 的Block RAM,简称为M512Block; 4Kbits 大小的Block RAM,简称为M4K Block, 和512Kbits的BlockRAM,简称为M- RAM Block。这三种Block的架构不同,等效到每Kbit的端口数量也不同,在不同应用范围的芯片中三种Block的数量按照一定比例配置。这种不同大小的Block RAM结构能够较好的满足不同项目的需求,例如M512可以被实现为容量较小的FIFO、 RAM、ROM,可以在“数据接口的同步方法”中完成异步时钟域之间数据交换的DPRAM等;M4K应用最广,可以实现为较大容量的RAM、 ROM、CAM、FIFO等,可以存储数据的索引表,处理器代码,中间结果等;容量的最大的M-RAM是专为大容量存贮而设计的,可以完成通信系统,网络交换器等设备中的大容量数据存贮。使用这种分层次,不同大小的Block RAM的最大好处就是,给用户提供了多样的选择,用户根据自己存储单元大小选择需要使用的Block RAM,可以较大程度的提高Block RAM的利用率。
在使用Block RAM时,一定要注意端口宽度和容量的匹配问题。又如在ALTERA APEX-II系列器件中实现深度为128, 宽度为64bits 的DPRAM,其容量为128x 64bit= 8192Bits,似乎恰好能在2块M4K中实现。事实上实现这个128x64bits的DPRAM需要4块M4K,这是因为一块4KbitsBlockRAM的最大数据宽度是16bit, 实现数据宽度是64bits 的DPRAM必须使用4快M4K才能满足端口宽度,这样的实现方式会造成8Kbits RAM资源的浪费。在设计时和容量估计时必须要考虑。在Xilinx和LatticeFPGA中也存在同样的问题,所以说要合理高效的使用Block RAM资源,必须要了解器件的硬件结构和特性。
-
分布式RAM资源(Distributed RAM)
目前FPGA的底层可编程单元基本都是由4-LUT和FF构成的,其工艺基于SRAM结构。4-LUT的本质是16 逻辑真值表,覆盖了4x4的所有逻辑。Xilinx 基于SRAM结构的4-LUT加以特殊的地址运算和时钟结构,实现了对1bit数据的16个可选地址的存取,相当于深度为16宽度为1bit RAM。由于这种小RAM分布于每个FPGA的底层可编程单元,所以被成为分布式RAM。Lattice 的ispXPGA 也可以将底层可配置单元综合成distibutedRAM。分布式RAM的存于FPGA可编程单元之内,到底可编程逻辑的路径最短,非常易于实现灵活、高速、小容量的数据缓冲、FIFO 等。
Distributed RAM特点
- Distributed RAM的机制是同步写、异步读的,但是只需将Slice 内部与LUT连接也FF利用起来就可以实现同步写、同步读的RAM。
- 将同一个SLICEM单元里面的2个LUT连接起来,还可以实现深度为16,宽度为lbit 的双口RAM,这种实现方式也比较好理解,相当于其中一个LUT实现了带有读/写端口的16x lbit的RAM,另一个LUT实现为仅有度端口的16xlbit的RAM。按照同步时序同时在两个LUT实现的16x1bitRAM写入数据,然后在第二个LUT实现的RAM 中独立的读出数据即可。所以distrilbuted RAM支持的存储类型有:单口、双口;同步写/异步读、同步写同步读等不同类型。
- 前面介绍了1个4-LUT可以实现深度为16, 宽度为1bit 的distributed RAM,如果需要实现更大的RAM时,就需要将Slice 或者CLB内部的distributed RAM级连起来。一个CLB内部可以实现的distributed RAM的大小取决于该CLB的4-LUT的数量。
- Distributed RAM资源除了支持单口、双口RAM以外,如果被赋予固顶的值还可以实现为ROM,同样也可以实现为FIFO。
- Distributed RAM的生成方式也支持代码直接描述,附加综合实现属性或使用。器件商的P core生成器产生等方式。如Xilinx FPGA可在Verilog或VHDL代码中附加约束属性,或者用CoreGenerator 生成。对RAM/ROM等指定初值可使用CoreGenerator 产生扩展名为“ceo’的初值文件或者用“NIT” 指示原语实现。
RAM/ROM/FIFO 一般都是用软件自带的IP核生成。
全局时钟资源与时钟锁相环
全局时钟布线资源-般使用特殊工艺实现(比如全铜层),并设计了专用时钟缓冲与驱动结构,从而使全局时钟到达芯片内部的所有可配置单元、IO单元和选择性块RAM的时延和抖动都为最小。长线资源,有时也称为第二全局时钟资源。它是分布在芯片的行、列的栅栏(Bank)上,一般采用铜、铝工艺,其长度和驱动能力仅次于全局时钟资源。与全局时钟相似,第二全局时钟资源直接同可配置单元、I/O 单元和选择性块RAM等逻辑单元连接,第二全局时钟信号的驱动能力和时钟抖动延迟等指标仅次于全局时钟信号。长线资源一般比全局时钟资源的数量更丰富一些。
目前大多数FPGA厂商都在FPGA内部集成了硬的DLL (Delay-Locked Loop) 或者PLL ( Phase-Locked Loop),用以完成时钟的高精度、低抖动的倍频、分频、占空比调整移相等。目前高端FPGA产品集成的DLL和PLL资源越来越丰富,功能越来越复杂,精度越来越高(一般在ps的数量级)。Xilinx芯片主要集成的是DLL,而Altera 芯片集成的是PLL。Xilinx 芯片DLL的模块名称为CLKDLL,在高端FPGA中,CLKDLL的增强型模块为DCM (Digital Clock Manager,, 数字时钟管理模块)。Altera 芯片的PLL模块也分为增强型PLL ( Enhanced PLL)和高速(Fast PLL)等。这些时钟模块的生成和配置方法一般分为两种,一种是在HDL代码和原理图中直接实例化,另一种方法是在IP核生成器中配置相关参数,自动生成IP。Xilinx 的IP核生成器叫Core Generator, 另外在Xilinx ISE 5.x 版本中通过Archetecture Wizard 生成DCM模块。Altera 的IP核生成器叫做MegaWizard。另外可以通过在综合、实现步骤的约束文件中编写约束属性完成时钟模块的约束。
Xilinx

- IBUFG即输入全局缓冲,是与专用全局时钟输入管脚相连接的首级全局缓冲。所有从全局时钟管脚输入的信号必须经过IBUFG 单元,否则在布局布线时会报错。IBUFG 支持AGP、CTT、GTL、GTLP、 HSTL、 LVCMOS、LVDCI、LVDS、LVPECL、 LVTTL、PCI PCIX、SSTL等多种格式的IO标准。
- IBUFGDS是IBUFG 的差分形式,当信号从一对差分全局时钟管脚输入时,必须使用IBUFGDS作为全局时钟输入缓冲。IBUFGDS支持BLVDS、LDT、LVDSEXT、LVDS、LVPECL、ULVDS 等多种格式的IO标准。
- BUFG即全局缓冲,它的输入是IBUFG的输出,BUFG的输出到达FPGA内部的IOB、CLB、 Block Select RAM的时钟延迟和抖动最小。
- BUFGCE是带有时钟使能端的全局缓冲。它有一个输入 I、一个时能端CE、一个输出端O。仅当BUFGCE的时能端CE有效(高电平)时,BUFGCE才有输出。
- BUFGMUX是全局时钟选择缓冲,它有两个输入I0和I1,一个控制端S,一个输出端O。当S为低电平时输出时钟为I0, 反之为I1。需要指出的是BUFGMUX的应用十分灵活,I0和I1两个输入时钟甚至可以为异步关系。
- BUFGP相当于IBUG加上BUFG。
- BUFGDLL是全局缓冲延迟锁相环,相当于BUFG与DLL的结合。在早期设计中经常使用,用以完成全局时钟的同步、驱动等功能。随着数字时钟管理单元(DCM)的日益完善,目前BUFGDLL的应用已经逐渐被DCM所取代。
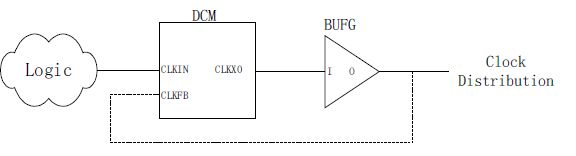
- DCM即数字时钟管理单元,主要完成时钟的同步、移相、分频、倍频、去抖动(skew)等。DCM与全局时钟有着密不可分的联系,为了达到最小的延迟和抖动,几乎所有的DCM应用都要使用全局缓冲资源。DCM可以用XilinxISE软件中的Architecture Wizard直接生成。
5种使用方法:
- IBUFG + BUFG的使用方法:
IBUFG后面连接BUFG的方法是最基本的全局时钟资源的使用方法,由于IBUFG组合BUFG相当于BUFGP,所以在这种使用方法也称为BUFGP方法。

-
IBUFGDS + BUFG的使用方法:
当输入时钟信号为差分信号时,需要使用IBUFGDS代替IBUFG。

- BUFG + DCM+BUFG的使用方法:
这种使用方法最为灵活,对全局时钟的控制更加有效。通过DCM模块不仅仅能对时钟进行同步、移相、分频、倍频等变换,而且可以使全局时钟的输出达到无抖动延迟“0”skew)。
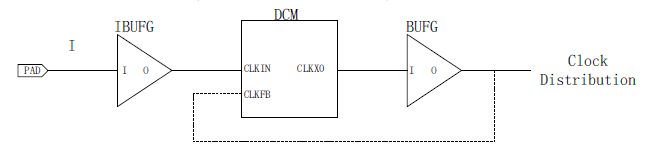
- Logic + BUFG 的使用方法:
BUFG不但可以驱动IBUFG的输出,还可以驱动其它普通信号的输出。当某个信号(时钟、使能、快速路径)的扇出非常大,并且要求抖动延迟最小时,可以使用BUFG 驱动该信号,使该信号利用全局时钟资源。但是需要注意的是,普通IO的输入或普通片内信号进入全局时钟布线层需要一个固有的延时,一般在10ns 左右,也就是说普通IO和普通片内信号从输入到BUFG输出有一个约10ns 左右的固有延时,但是BUFG的输出到片内所有单元( IOB、CLB、Block Select RAM)的延时可以忽略不计为“0”ns。
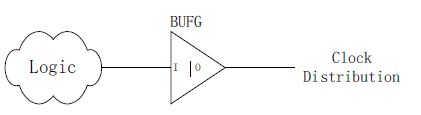
- Logic + DCM+BUFG的使用方法:
DCM同样也可以控制并变换普通时钟信号。也就是说DCM的输入也可以是普通片内信号。
使用注意事项
Xilinx全局时钟资源必须满足的重要原则是:“使用IBUFG或IBUFGDS的,充分必要条件是信号从专用全局时钟管脚输入。”换句话说,当某个信号从全局时钟管脚输入,不论它是否为时钟信号,都必须使用IBUFG或IBUFGDS;如果对某个信号使用了IBUFG或IBUFGDS硬件原语,则这个信号必定是从全局时钟管脚输入的。如果违反了这条原则,那么在布局布线时会报错。这条规则使用由Xilinx的FPGA的内部结构决定的: IBUFG和IBUFGDS的输入端仅仅与芯片的专用全局时钟输入管脚有物理连接,与普通IO和其它内部CLB等没有物理连接。另外由于BUFGP相当于IBUFG和BUFG的组合,所以BUFGP的使用也必须遵循.上述的原则。
全局时钟资源的例化方法大概可分为两种:一是在程序中直接例化全局时钟资源。二是通过综合阶段约束或者实现阶段约束实现对全局时钟资源的使用。
第一种方法比较简单,用户只需按照前面讲述的5种全局时钟资源的基本使用方法编写代码或者绘制原理图即可。第二方法是通过综合阶段约束或实现阶段的约束完成对全局时钟资源的调用。这种方法根据综合工具和布局布线工具的不同而异。另外大多数综合工具会自动分析时钟信号的扇出数目,在全局时钟资源富于的情况下,将扇出数目最大的信号自动指定使用全局时钟资源。这时用户必须检查综合结果是否满足上述使用IBUFG、IBUFGDS、 BUFGP的原则。如果某个信号因扇出很大,而被综合器自动指定使用IBUFG、IBUFGDS、BUFGP 全局时钟资源,而该信号并没有从专用全局时钟管脚输入,在布局布线时会报错。这时应该在综合是指定该信号不使用全局时钟资源,具体的综合约束命令和操作因综合工具不同而异。
Altera
Altera器件的PLL使用比较方便,一般是都是用EDA辅助工具比如Magafunction或Maga Wizard 生成IP,然后调用。Altera FPGA不同器件可用的PLL单元不同,使用是需要根据器件类型选择相应的资源,下图分别是Enhanced PLL、Fast PLL、Cyclone PLL等不同类型的PLL结构示意图。

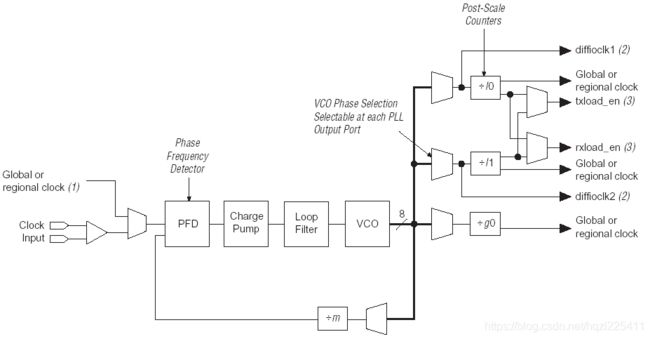

在使用Altera PLL的时候,首先应该根据自己所选的器件类型,察看该器件可用的PLL资源,然后根据需要设计PLL的参数,通过Magafunction或Maga Wizard设置PLL的参数并生成IPcore,在代码中调用即可。整个使用过.程的关键在于弄清AlterPLL的常用参数含义。
Altera器件PLL常用端口和参数简介
下面对Altera器件PLl的常用端口和参数加以简介,不同器件具体支持的端口和参数略有不同,使用时请参看该器件的器件手册。
- pllena它是PLL的使能端,高有效,当为低时,PLL无输出。
- areset它是PLL的异步复位端,高有效,异步复位PLL。
- OPERATION _MODE选择PLL的工作模式。Stratix 器件族的PLL 通过选择PLL的工作模式为“normal” 或者“zero delay buffer”,可以补偿片内和片外的时钟延迟。常用可配置的模式如下:“Norma1” 模式下,PLL的输入引脚与I/O单元的输入时钟寄存器相关连;“Zero delay buffer” 模式下,PLL的输入引脚和PLL的输出引脚的延时相关连,通过PLL的调整,到达两者“零”延时;“External feedback” 模式下,PLL的输入管脚和PLL的反馈管脚延时相关联;“No compensation”模式下,不对PLL的输入管脚进行延时补偿。
- SCAN_CHAIN, 用以动态重配Stratix PLL状态,有Long和Short两种不同宽度的扫描链。
- BANDWIDTH,用以指定PLL的相关带宽,默认情况下该参数被设置为“auto”。
- DOWN_SPREAD, SPREAD_ FREQUENCY,这两个关于扩频的参数用以减少PLL的EMI(电磁辐射)。
- clkswitch,clkloss,clkbad, 这3个参数和enhanced PLL的输入时钟切换相关,通过PLL输入时钟切换使PLL的输入在两个不同的输入时钟间切换,使用该参数必须使能“inclock1” 端口。clkloss用以指定PLL在一个输入时钟丢失时自动切换到另一个输入时钟; clkbad 用以指定PLL在一个输入时钟质量便差时自动切换到另一个输入时钟; clkswitch 用以强迫指定PLL在2个输入时钟之间切换。
- CLK[ ] MULTIPLY BY,括号内为CLKPLL的标号,该参数是最为常用的参数之一,用以设置CLKPLL的倍频因子。
- CLK[ ] DIVIDE_ BY,括号内为CLKPLL的标号,该参数是最为常用的参数之一,用以设置CLKPLL的分频因子。
- CLK[ ]_PHASE_SHIFT, 括号内为CLKPLL的标号,该参数用以设置输出时钟的相位偏移。
- CLK[ ] _ TIME_ DELAY, 括号内为CLKPLL的标号,该参数用以设置输出时钟的时间延迟,延迟时间范围从- 3ns到6ns.
- CLK[ ]_ DUTY_ _CYCLE, 括号内为CLKPLL的标号,该参数用以设置输出时钟的占空比中高电平的百分数,其可设置范围和输入时钟的频率相关。
- clkena[ ], 括号内为CLKPLL 的标号,用以指定某个CLKPLL是否有效输出。高电平有效。当某个时钟被指定clkena 为低时,其相关的VCO仍然振荡,但是输出时钟端口却被屏蔽了。
不同时钟域数据交换时,使用Altera PLL时钟的注意事项
- 同步同型时钟域之间的数据交换
如果两个PLL时钟是由同一个PLL产生的同类型的时钟(如都是全局时钟,或者都是区域性时钟),则这两个时钟域之间的register- to -register数据交换最为简单,不需要附加任何逻辑。因为从前面“数据接口的同步方法”中已经知道,在这种情况下,使用一级寄存器采样就能完成数据的同步化过程,不会产生错误电平和非稳态的传播。 - 同步异型时钟域之间的数据交换
如果两个时钟是由不同的PLL产生,或者是不同类型的时钟(一个是全局时钟,一个是区域性时钟), 由同一个时钟反馈而无时延或者相位调整,则在进行数据交换时,必须插入一个LE ( Logic element, 逻辑单元,Altera 的基本可配置模块)。如下图所示。

- 异步时钟域之间的数据交换
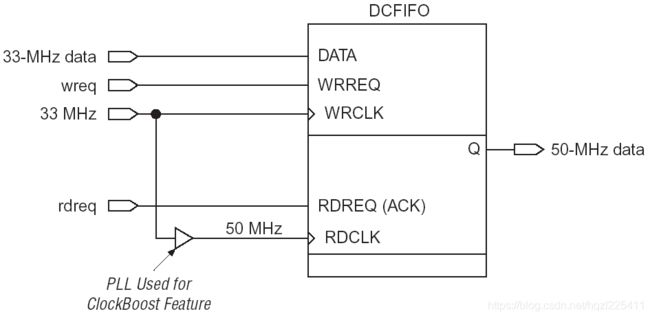
如果是完全异步的时钟域间数据交换,需按照 “数据接口的同步方法”所述方法,使用DPRAM或者FIFO完成,可以简单的绕过异步时钟域数据同步的握手和错误电平或者亚稳态等问题。Altera 举例使用DCFIFO完成异步时钟域之间的数据交换,如图38所示。
全局复位(GSR)/置位信号(GTS)
-
使用GSR/GTS前,设计者必须要搞清楚,您的设计中是否真正需要使用GSR/GTS?
这一点非常重要,GSR/GTS 不像全局时钟资源是推荐使用的全局资源。特别在Virtex/E/II Pro,Spartan-IIII 等器件族中,在用户设计资源富裕的情况下,甚至不推荐使用。主要因为GSR/GTS的skew和延时较大,速度很慢,会影响设计的速度。如果GSR/GTS的保持时间设计不够,还会导致电路并未真正的全局复位、置位,导致逻辑错误。而上述器件如果资源有富余,可以直接用长线资源(还有一种叫法为:第二全局时钟资源),它们的速度、skew 比GSR/GTS优异很多,能更好地满足设计需求。
-
GSR/GTS的三种调用方法
GSR/GTS的三种基本调用方法是:直接例化、在综合的时候加约束属性、默认类推等。
-
直接例化GSR/GTS的方法直截了当,在代码中显化例化GSR/GTS资源,明确告诉综合器,综合器只有乖乖听话了。例化方法如下:
-- This example uses both GTS and GSR pins. -- Unconnected STARTUP pins are omitted from -- component declaration. library IEEE; use ieee.std_1ogic_1164.a11; entity setreset is port ( CLK: in std_1ogic; DIN1 : in std_1ogic; DIN2: in std_1ogic; RESET: in std_1ogic; GTSInput: in std_1ogic; DOUT1: out std_1ogic; DOUT2: out std_1ogic; DOUT3: out std_1ogic); end setreset; architecture RTL of setreset is component STARTUP_VIRTEX port( GSR,GTS: in std_1ogic) ; end component; begin startup_inst: STARTUP_VIRTEX port map( GSR => RESET, GTS => GTSInput); reset_process: process (CLK, RESET) begin if (RESET = '1') then DOUT1 <= '0'; elsif (CLK = '1' and CLK'event) then DOUT1 <= DIN1; end if; end process; gtsprocess:process (GTSInput) begin if GTSInput = '0' then DOUT3 <= 'O' ; DOUT2 <= DIN2; else DOUT2 <= 'Z'; DOUT3 <= 'Z'; end if; end process; end RTL;// This example uses both GTS and GSR pins // Unused STARTUP pins are omitted from module // declaration. module setreset (CLK, DIN1, DIN2, RESET, GTSInput, DOUT1, DOUT2, DOUT3) ; input CLK; input DIN1; input DIN2; input RESET; input GTSInput; output DOUT1; output DOUT2; output DOUT3; reg DOUT1; STARTUP_VIRTEX startup_inst( .GSR (RESET), .GTS (GTSInput)); always @ (posedge CLK or posedge RESET) begin if (RESET) DOUT1 = 1 'b0; else DOUT1 = DIN1; end assign DOUT3 = (GTSInput == 1'b0) ? 1'b0 : 1'bZ; assign DOUT2 = (GTSInput == 1'b0) ? DIN2 : 1'bZ; endmodule -
在综合器的综合属性中设置使用GSR的选项,这种方法因综合器不同而设置不同。一般叫"Force GSR usage"选项,比如Synplicity 综合工具( Synplify/Synplify Pro、Ampify等 )里面的综合属性: /* synthesis xC_ isgsr = 1 */ 另外也可以在综合属性图形设置界面添加使用GSR资源的属性。比如Synplicity综合工具的SCOPE中设置,以及在Leonardo的综合约束属性图形界面设置等。
-
目前,很多综合器会自动将起到全局作用的异步复位类推为GSR,使用GSR资源,该过程是完全自动完成的,不需设计者干预,类推结果后会在综合报告中打印相关信息。但是对Xilinx的Virtex/E/II Pro,Spartan-I/II 等器件并不自动类推GSR, 如需使用,必须按照第一种方法所示,在代码中显化调用STARTUP_ VIRTEX,STARTUP_ VIRTEX2,或者STARTUP_ SPARTAN2模块。
-
-
GSR/GTS的使用方法
GSRGTS最常用的方法是用做异步全局复位/置位。当然也可以用做同步全局置位/复位,但是必须要考虑清楚一些相关的问题。另外用GSR/GTS 复位/置位状态机,企图使状态机在启动后自动进入安全状态或者IDEL状态的时候,也必须要注意状态机的编码方法,由于GSR复位的时候,程序并没有发挥作用,所以必须要搞清楚自已的设计状态,如果使用one-hot编码,一般one-hot with zero initial state的编码方法,使GSR后自动进入initial 的状态。