为什么关系数据库的未来一定是分布式数据库?
OceanBase CTO杨传辉将在本文中带大家共同回顾数据库的发展历史,了解未来趋势,揭秘 OceanBase 诞生的故事。
什么是数据库
首先,什么是数据库。顾名思义,数据库是按照数据结构来组织、存储和管理数据的仓库。历史上曾经出现过层次数据库、网状数据库以及关系数据库。
如今,关系数据库成为业界的主流。关系数据库的全称是 Relational Database Management System,简称叫 RDBMS。一般来讲,关系数据库主要应用在核心行业的核心业务场景,也就是我们经常说的 Mission-critical 场景,涉及到人、财、物等需要精确管理等应用。关系数据库有一个第一定律,那就是永远不要丢失任何一条数据。
关系数据库可以被分成三个基本的模块,包括:
关系模型,也就是我们经常听到的表格、索引、外键、范式等;
事务处理,也就是事务的 ACID,原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability);
查询优化,也就是 SQL 的解析、改写、优化、执行等等。

数据库技术的繁荣发展,也得益于很多优秀的科学家。数据库领域有四位图灵奖得主,第一位图灵奖得主是 1973 年的网状数据库的创始人 Charles W.Bachman。第二位是 1981 年关系理论的提出者 Edgar F.Codd。第三位图灵奖得主是事务处理的发明人 Jim Gray,于 1998 年获得了图灵奖,Jim Gray 也是科学研究四类范式的提出人,他是一个天才科学家。有个有趣的事可以和大家分享:当年微软想把 Jim Gray 招到西雅图的总部,但是,Jim Gray 不喜欢西雅图的天气,于是,微软专门在旧金山给 Jim Gray 建了一个单独的研究院。
第四位数据库领域的图灵奖得主是 Michael Stonebraker。Michael Stonebraker 不仅是位教授,而且还是不同数据库公司的创始人,他创立了很多不同类型的数据库产品,除了 Oracle 和 DB2 以外,绝大部分的数据库产品,都或多或少与 Michael Stonebraker 有点关系。Michael Stonebraker 最著名的一个数据库产品就是 Ingres,Ingres 是 Informix、Sybase、SQL Server、PostgreSQL 等一系列产品的前身,Michael Stonebraker 也是在 2014 年获得了图灵奖。
关系数据库发展史
根据下图的时间线,我们一起回顾下关系数据库的发展史。

1970 年,Edgar F.Codd 首先提出了关系模型。接下来就有两个关系模型的原型系统。第一个是 IBM 做出来的 System R,第二个是 Michael Stonebraker 领导的 Ingres。IBM 是关系模型的提出者,也是第一个原型系统的实现者,但是 IBM 并没有抓住关系数据库商业化的历史新机遇,反而把机会让给了一个叫 Larry Ellison 的人,1979 年 Oracle 模仿 IBM 的 System R 做出了第一个商业数据库版本 Oracle Release 1。直到 1983 年,IBM 的第一个商业数据库版本 DB2 才姗姗来迟,但是已经错过了最好的数据库发展时期。
1987 年,Sybase 和微软一起做出了 Sybase SqlServer。1989 年,微软买下了 Sybase SqlServer 的代码版权,并且形成了一个独立的 MS SqlServer 的分支。我们今天听到的 SqlServer 一般指的是微软的 MS SqlServer。
同一年,著名的开源数据库 PostgreSQL 也诞生了。
1995 年,MySQL 诞生,MySQL 的创始人叫 Monty。一个非常神奇的事情是,MySQL 早期的主要代码都是 Monty 一个人贡献的,而且到今天为止,Monty 仍然保持着写代码的习惯。
2004 年,更多的列式数据库产品,包括 MonetDB、C-Store 也加入到关系数据库的产品行列。
分布式系统发展
接下来,我们再来看下分布式系统的发展。
分布式系统也是一个相对比较古老的领域。但是直到最近的十几二十年,分布式系统才由理论变成大规模的工程实践。对分布式系统工程实践贡献最大的公司是 Google,Google 的基础设施有三驾马车,分别叫做《Google File System》、《Google MapReduce》以及《Google BigTable》。Google 发表了这三篇论文以后,基本上奠定了业界大规模分布式存储系统的理论基础,所有对分布式系统工程实践感兴趣的同学,我建议都去仔细精读这三篇论文。

2005 年,Hadoop 成立,Hadoop 项目的初衷就是做出 Google 三驾马车的开源实现。
2007 年,Amazon 发表了 Dynamo 的论文,Dynamo 的设计思想也比较有意思,他采用了 P2P 的思想来实现分布式的存储,里面用到了包括一致性 Hash、NWR 等一系列非常有意思的技术。当然了,最终 P2P 的技术因为没有办法保证强一致性,并没有成为业界的主流。
2009 年,Spark 项目成立。
2010 年,我所在的 OceanBase 项目成立。OceanBase 团队是分布式数据库的信仰者、实践者,OceanBase 的定位是原生分布式数据库,以追求成为分布式数据库的领导者为目标。
2011 年,另外一个云计算的巨头微软,发布了 Windows Azure Storage。
2012 年,Google Spanner 发表了论文,Spanner 是全球第一个 Global Database,采用了 TrueTime、Paxos和两阶段提交等一系列分布式的技术来实现了一个全球级别、可无限扩展的、强一致的分布式数据库。
2016 年,Amazon 发布了 Aurora,Aurora 是一个存储计算分离的系统,运行在公有云之上,它的设计思想很巧妙,它把存储与计算分离使得可以非常简单得实现存储能力的可扩展。Aurora 有个核心的设计理念:The log is the Database。
关系数据库的经验教训
关系数据库发展了这么多年,有很多的经验教训。
关于经验,今天我选两点经验分享:
第一点:应用驱动创新,应用创新与技术创新相辅相成,互为促进。关系数据库的很多技术都是应用驱动产生的,这也形成了非常强大的技术生态。
第二点:抽象与标准化,关系数据模型、事务处理模型本身就是最本质的抽象,能够获得图灵奖的一个抽象。关系数据库里面也产生了很多的标准,其中最著名的标准是 :SQL 标准和 TPC 测试标准。
早期的商业数据库也比较混乱,每一家商业数据库都说自己是最好的。最终 TPC 组织站了出来,制定了 TPC-C、TPC-H 等一系列测试标准,并且采用第三方的专业的审计机构,进行严格的审计。TPC 组织使得不同的商业数据库公司能够获得一个公平的、竞技的舞台,大家良性竞争共同促进。
分布式数据库:关系数据库的未来
我坚定认为关系数据库的未来一定是分布式数据库。为什么这么坚信?因为分布式数据库能够完全兼容集中式数据库的使用方法,包括关系模型、事务处理模型和 SQL 标准,并且融合分布式云原生的先进技术,从而充分享受到分布式的技术红利,包括高可用、可扩展、低成本、智能等等。
分布式数据库和集中式数据库的关系,有点像当年的汽车与马车,汽车刚出现的时候它并没有马车那么好用,但是我们都知道,随着时代的发展,汽车是一定会逐步替代马车的。分布式数据库也是一样,因为分布式数据库能够完全兼容集中式数据库,包含集中式数据库的能力,并且具备更好的扩展能力。所以,分布式数据库未来也一定能够替代集中式数据库。
原生分布式数据库 OceanBase
刚刚提到我们坚信分布式数据库的时代正在到来,接下来为大家介绍我们打造的这款企业级分布式数据库—— OceanBase。
OceanBase 是一个透明可扩展的企业级数据库,底层是一个原生的分布式架构,这样的设计,可以让使用者充分享受到分布式技术的技术红利,包括:
高可用:RPO = 0,RTO < 30秒,最高支持三地五中心部署,这也就意味着,当一台服务器、一个机房甚至一个城市发生故障的时候,OceanBase 都能够在 30s 内恢复,完全不丢数据;
透明扩展:完备的分布式事务、分布式查询、全局二级索引和全局一致性支持;
全球唯一通过 TPC-C 测试审计的分布式数据库,事务处理性能达到 7.07 亿 tpmC,比竞品高一个数量级;
从使用者的角度来看,OceanBase 兼容传统的企业级数据库,兼容 MySQL/Oracle的语法、企业级功能,具备与 Oracle 对标的高效处理混合负载的能力。OceanBase 已经支撑蚂蚁集团&网商银行所有核心业务的100%流量,支撑银行、保险、证券、运营商、公共事业等多个关系到国计民生的行业的重要客户的核心系统。
刚刚提到,OceanBase 诞生于2010 年,立项之初,我们的目标是做出一个原生的分布式数据库,业界并没有参考方案,这样的背景成就了 OceanBase 从0到1,100%自主研发。2010 年到 2014 年,OceanBase 在阿里巴巴的电商平台应用推广,服务了几十个电商平台的业务系统。2014 年,OceanBase 支撑了当年双 11 的峰值,这也实现了 OceanBase 核心交易类场景的 0 的突破。
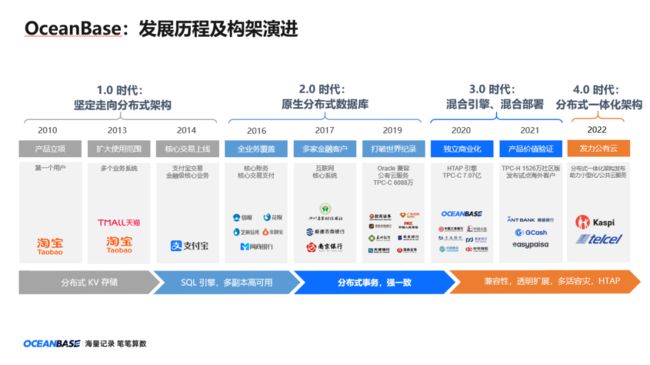
接下来的 3 年时间, 支付宝包括交易、支付、账务会员在内的所有的核心业务都是使用 OceanBase。
2017 年,OceanBase 第一次走出阿里巴巴,走出蚂蚁集团,开始对外商业化,南京银行是第一家运行在 OceanBase 上的外部客户。
2019 年,OceanBase 第一次参加 TPC-C 测试,取得 6088万 tpmc 的成绩,打破了原先的世界记录。
2020 年,OceanBase 再次参加 TPC-C 测试,取得了 7.07 亿 tpmc 的成绩。同年,OceanBase 正式进行独立公司化运作,成立北京奥星贝斯科技有限公司,致力于分布式关系数据库 OceanBase 的设计、研发、销售、服务等,助力客户实现分布式架构转型。
2021年,OceanBase 数据库正式开源,采用业界通用的Open Core模式,将OceanBase 数据库内核、分布式组件和接口驱动完全开源,共开源300万行代码,包括SQL引擎、事务引擎和存储引擎,支持多副本、分布式事务、高性能、扩展能力、故障恢复、优化器、多活容灾、语法兼容等核心技术。
本文作者 | 杨传辉
现任 OceanBase CTO。杨传辉曾在百度从事大规模云计算系统研发工作,2010 年作为创始成员之一加入 OceanBase 团队,主导了 OceanBase 历次架构设计和技术研发,从无到有实现 OceanBase 在蚂蚁集团全面落地。同时,他也主导了两次 OceanBase TPC-C 测试并打破世界纪录,著有专著《大规模分布式存储系统:原理与实践》。