Opencv项目实战:08 Yolov3更高精度的检测物体
1、效果展示
本次物体检测,将采用新的方法,相比于上一次,它的检测效果更好,具体在下面的项目介绍当中 ,本次检测的物品有手机、牙刷、剪刀、杯子、运动球、书等。检测的这些物品是方便展示的,本来还有水果的,但昨天都吃完了,只有核桃了,大家做好后,可以自己去试试
2、项目介绍
在本项目中,我们将用新的方法对物体的检测,采用了Yolov3,当然它又有检测范围,只能鉴定我们给予的文件当中的物体,但它相较于我们之前的物体检测又有更高的精度,没有出现边界框闪烁,重叠的问题。
3、项目搭建
如图所示,其中有些文件是我从官网上下载的,那么为了说清楚它的来源,我还是写下来,以免读者看了云里雾里。
输入此网址 :YOLO:实时对象检测 (pjreddie.com)
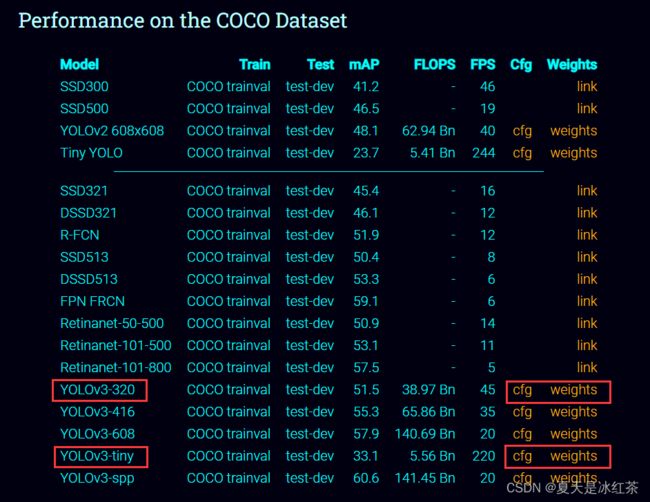
下载两种是为了比较一下它们的一些优缺点,320指的是分辨率320*320,它的检测能力属于中间吧,不过它的帧速率比起tiny要小很多,但又要比tiny的精度较高。
而coco.names是我从之前的《Opencv项目实战:05 物体检测》的一个文件,ctrl+cv过来的,不知道的可以看看此篇。(16条消息) Opencv项目实战:05 物体检测_夏天是冰红茶的博客-CSDN博客,或许你先看这篇后,更容易理解此篇。
再提一句,下载cfg是在Github里面,如果网速较慢的,可以给我评论,我考虑一下抽点时间,将Github的一些加速的方法总结一篇。
4,项目知识预备
如有不知道的地方再回头来看,现在看一遍,加一点表面印象,不要求理解。
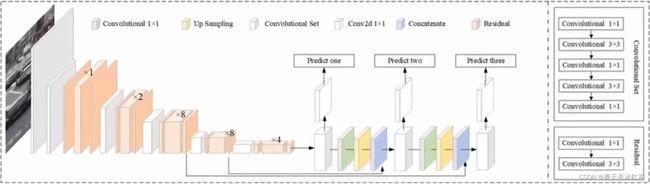
架构图:
我们可以看到这个网络,有很多层,中间的部分有很多的卷积层,而我们需要的就是末尾的那三层。
打印outputs[0][0]:
[3.8534008e-02 6.2166303e-02 4.4057447e-01 1.9734769e-01 5.1320876e-09
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00]
85的含义:

85含有中心x,y,宽,高,物体的置信度 ,其余的是每个类别的预测概率,也就是value number
x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2) 手绘图版本:
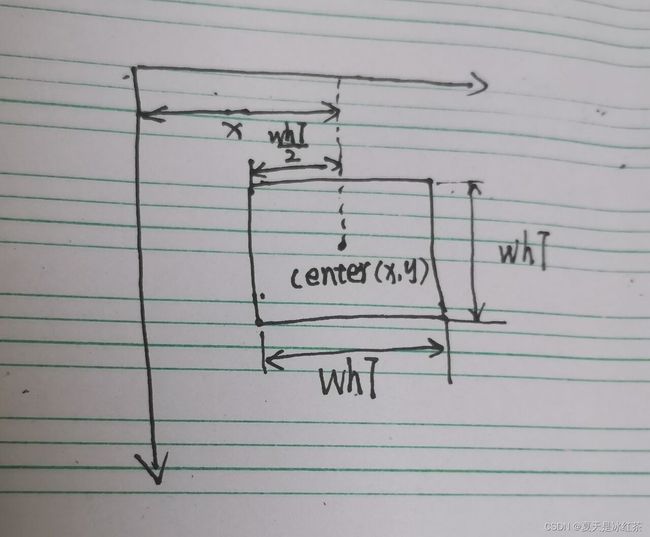
真的随手画,哈哈。大家可以理解到就成。
关于coco.names文件:
与项目5当中的文件有所区别,大家按照项目介绍当中的图对其中的内容进行删改即可。
5、项目的代码与讲解
import cv2 as cv
import numpy as np
cap = cv.VideoCapture(0)
whT = 320
confThreshold = 0.5
nmsThreshold = 0.2 #the lower it is the more aggressive it will be
print(f"以下是你可以检测的{80}种物品:")
#### LOAD MODEL#######################################
##导入coco.names文件当中的内容
classesFile = "coco.names" #
classNames = [] #
with open(classesFile, 'rt') as f: #
classNames = f.read().rstrip('\n').split('\n') #
print(classNames) #
######################################################
#### Model Files###################################################
## 引进我们的模块
modelConfiguration = "yolov3-320.cfg" #
modelWeights = "yolov3-320.weights" #
net = cv.dnn.readNetFromDarknet(modelConfiguration, modelWeights) #
net.setPreferableBackend(cv.dnn.DNN_BACKEND_OPENCV) #
net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU) #
###################################################################
def findObjects(outputs, img):
hT, wT, cT = img.shape
bbox = []
classIds = []
confs = []
for output in outputs:
for det in output:
scores = det[5:] #我们需要寻找某一个类中,判别最高的
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
w, h = int(det[2] * wT), int(det[3] * hT) #值是百分比,乘以图像的大小才是正确的像素值
x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2)
bbox.append([x, y, w, h])
classIds.append(classId)
confs.append(float(confidence))
indices = cv.dnn.NMSBoxes(bbox, confs, confThreshold, nmsThreshold) #置信度阈值以及nms的阈值
# print(indices)
for i in indices:
box = bbox[i]
x, y, w, h = box[0], box[1], box[2], box[3]
# print(x,y,w,h)
cv.rectangle(img, (x, y), (x + w, y + h), (255, 0, 255), 2)
cv.putText(img, f'{classNames[classIds[i]].upper()} {int(confs[i] * 100)}%',
(x, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2)
while True:
success, img = cap.read()
blob = cv.dnn.blobFromImage(img, 1 / 255, (whT, whT), [0, 0, 0], 1, crop=False)
net.setInput(blob)
layersNames = net.getLayerNames()
# print(layersNames)
# print(net.getUnconnectedOutLayers())
outputNames = [(layersNames[i - 1]) for i in net.getUnconnectedOutLayers()]
# print(outputNames)
outputs = net.forward(outputNames)
# print(len(outputs)) #检测是否取到我们需要的那三层,输出为3,True
outputs=list(outputs) #输出之前是元组
# print(type(outputs[0])) #
##########################################
# print(outputs[0].shape) #(300, 85) 300,1200,4800 is is the number of bounding boxes
# print(outputs[1].shape) #(1200, 85)
# print(outputs[2].shape) #(4800, 85)
# print(outputs[0][0])
##########################################
findObjects(outputs, img)
cv.imshow('Image', img)
if cv.waitKey(1) & 0xFF ==27:
break 我们一口气讲完,准备了这些天,也不是白费的,当然有些地方,可能我讲的不是那么清楚,请见谅。但好在这次我将调试的所有过程都保留了下来,结合注释和我的讲解,7788应当是有的。
- 首先,开头部分都是些后来设置的默认条件,等用到的时候再将。我们需要导入我们的"coco.names文件",它是每个单词为一行,所以通过文件操作,将其中内容放入到一个新的列表当中,我们用到了read()、rstrip()、split()函数,不清楚的地方,可以去W3school上查询。
- 其次,引入我们从官网下载的文件,用到了readNetFromDarknet()函数,它的参数是模型配置和权重配置,也就是我们下载的模块,他会读取存储在Darknet模型文件,返回一个网络对象,这正是我们想要的。net.setPreferableBackend()要求网络使用其支持的特定计算后,它的参数需要我们给定为cv.dnn.DNN_BACKEND_OPENCV,因为它是具有一个默认的值。net.setPreferableTarget()要求网络在特定目标设备上进行计算,我选择使用的是CPU,当然要想获得更高的精度,就要使用GPU,但我并不了解,所以点到为止哈。
- 其次,我们再来讲解while True循环中的代码,读取摄像头,创建我们的网络,将图像转化为blob的形式,因为这是网络可以理解的形式,里面的参数我讲一下(whT,whT),其余的就是默认了,在开始时就已经定义了为320,那为什么是320,因为yolov3-320.cfg等,就是这个原因啦,它的分辨率就是320*320;net.setInput(blob) 就是设置网络前行的通行证;接下来,我们要获得我们最感兴趣的那三层,用net.getLayerNames()函数获取所有层的名字,在得到三个不同的输出层的索引值,接着用列表生成式,根据索引将内容放进去,得到['yolo_82', 'yolo_94', 'yolo_106']。net.forward(outputNames)返回指定层的第一个输出的blob。再往下就是我的一些调试过程,我保留了调试时的注释,不懂的地方,不妨就取消注释,跑一遍就成。
- 然后,再来讲解我们的 findObjects(outputs, img)里面的内容,获取图像的宽高通道,设置空列表,放置边界框,Id,置信度等,那么下面的操作就是为了将这些空列表填满!!!,我们在上面有展示过outputs[0][0]的输出,我们不能将中心x,中心y,宽,高,置信度等作比较,因为它们相对较大,索引是从第五个开始,然后便是我所说的填满操作,应该不难,我们就此跳过。
- 紧接着,来到尾声了,我们常会有检测时出现大小框,那么这是就需要处理,得到检测较大的那个框,让我们的检测更加的完善,cv.dnn.NMSBoxes()函数,参数confThreshold已经在开头定义,检测的大于50%,那就相当好了,nms_threshold用于非最大抑制的阈值,也是实现定义好了,这个用法我们在《Opencv项目实战:05 物体检测》就讲到过。然后就是画框,放文本的操作,几乎我们每一期的实战项目都在讲。
- 最后,引用findObjects(outputs, img)函数,开启摄像头,展示窗口,检测物体,完成后点击Esc键即可退出。
6、项目素材
GitHub:Opencv-project-training/Opencv project training/08 Yolov3 at main · Auorui/Opencv-project-training · GitHub
其中以下两个文件需要从官网下载,GitHub上面由于太大上传不了。

7、项目总结
我写的较为的详细,几乎没有我这种风格的吧,我是学c语言出生的(是我们大一的必修课,说实话我以前根本就不知道的,可能这就是小镇做题家的原因吧),后来今年的二月自学的python,中途学了些爬虫,七月在参加实验室学了点单片机(我没有基础,也被刷下去了,keil5配文件麻烦死了),给我们安排的课程python的图像处理只有区区两节,也是这两节课才对Opencv感了兴趣,自己私下在学习,后来我发现刚好学的这些东西,都是涉及人工智能领域,计算机视觉的,我想我自己一定要做出点成就来,给大家更新的系列也是我学习的过程,我上一篇《Opencv项目实战:07 人脸识别和考勤系统》之前处于热榜第三,那天早上很突然的翻了翻,就发现自己上榜了,就在前一天晚上,我都打算先停更这个系列,再到后面我发了动态,又有一位大佬的鼓励(CSDN的副总裁),真没想到会看我的动态,所以,哪怕这几天都在上网课,还是解决了这个项目所存在的难度,也谢谢大家给我的鼓励,你们的支持也是我更新的动力,我感觉大家要比其他的平台的网友要乐观,积极,还会说好话。我会继续保持这个风格,马上要去学校了,我是打算学习MySql,机器学习等,这个实战系列我准备改成一周一更了,中间我会穿插我学所学习的知识然后写成博客,不会像我之前那个栏目Openjudge乱来了(刚刚python入门,只有问题和代码)。
那么祝你在本项目中玩得开心,否则我会在下一期中见到你!!
