CAS-KG——机器学习基础
说明:CAS是国科大的简称,KG是知识图谱的缩写,这个栏目之下是我整理的国科大学习到的知识图谱的相关笔记。
课程目标
- 了解以知识图谱为代表的大数据知识工程的基本问题和方法
- 掌握基于知识图谱的语义计算关键技术
- 具备建立小型知识图谱并据此进行数据分析应用的能力
教学安排
详情请见博客:CAS-KG——课程安排
文章目录
- 1. 机器学习基础理论与概念
- 2. 神经网络与是深度学习基础
-
- 感知机 Perception
- 前馈神经网络
- 3. NLP中的深度学习
- 4. 语义组合模型
-
- (1)卷积神经网络
-
- 一维卷积、二维卷积、卷积层、滤波器
- 子采样层
- CNN的应用
- 其他各种(奇怪的)卷积模型
- (2)循环神经网络
-
- 简单循环网络
- 长短时记忆神经网络:LSTM
- 门限循环单元:GRU
- 应用
- (3)Seq2Seq :Sequence to Sequence Learning
- (4)Transformer相关
-
- 自注意力(Self-Attention)模型
- Transformer: attention is all your need
- 5. “词”表示模型
-
- 5.1 神经语言模型
- 5.2 词向量2.0(word2vec)
- 5.3 词向量3.0(ELMo、BERT)
- 6. 总结
1. 机器学习基础理论与概念
机器学习是什么
- 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能;
- 机器学习是人工智能的一个分支,其目的在于使得机器可以根据数据进行自动学习,通过算法使得机器能从大量历史数据中学习规律从而对新的样本做决策;
- 它目前是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
- 机器学习主要是研究如何使计算机从给定的数据中学习规律,即从观测数据(样本)中寻找规律,并利用学习到的规律(模型)对未知或无法观测的数据进行预测。目前,主流的机器学习算法是基于统计的方法,也叫统计机器学习。
规则思维 VS. 统计思维

机器学习 ≈ 构建一个预测函数

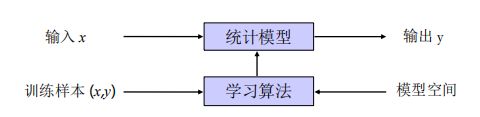
机器学习基本流程
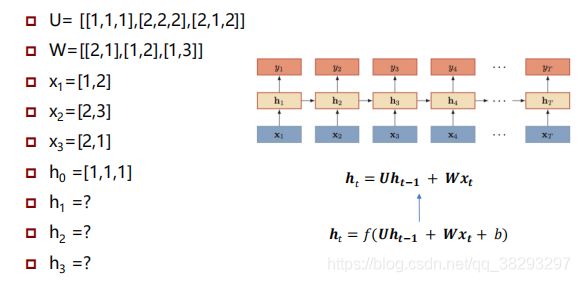
对于一个预测任务, 输入特征(向量)为 , 输出标签(one-hot向量)为 。根据模型假设选择函数集合,通过学习算法和训练数据集合, 从 中学习到函数 f ∗ ( x ) f^*(x) f∗(x)。这样,对于新的输入数据(预测对象),就可以使用函数 f ∗ ( x ) f^*(x) f∗(x) 进行预测(计算)。
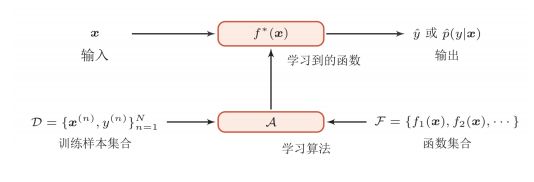
机器学习方法分类
根据人们需要对机器提供什么样子的标签,机器学习可以分为:
- 监督学习:从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
- 无监督学习:训练集没有人为标注的结果。常见的无监督学习算法有聚类。
- 半监督学习:介于监督学习与无监督学习之间,部分数据有人为标注,部分数据没有。
- 增强学习/强化学习:强调如何基于环境而行动,以取得最大化的预期利益。它并不需要出现正确的输入/输出对。强化学习更加专注于规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。
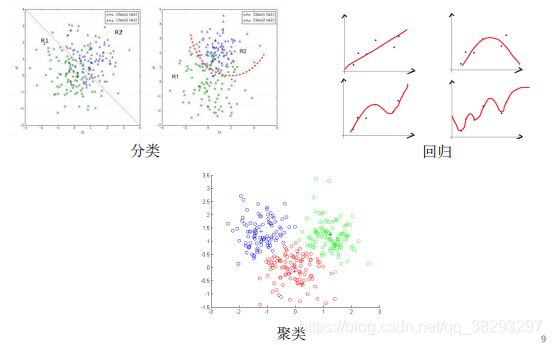
基本机器学习问题类型
-
分类(Classification): 是离散的类别标记(符号),就是分类问题。损失函数有一般用 0-1 损失函数或负对数似然函数等。在分类问题中,通过学习得到的决策函数 (, ) 也叫分类器。
-
回归(Regression): 是连续值(实数或连续整数), () 的输出也是连续值。这种类型的问题就是回归问题。对于所有已知或未知的 (, ),使得(, )和尽可能地一致。损失函数通常定义为平方误差。
-
聚类(Clustering):只有原始数据,没有确定的目标(),它基于数据的内部结构寻找观察样本的自然族群(即集群)。聚类的特点是训练数据没有标注,通常使用数据可视化等方式评价结果。
如下图所示,分类要学习到边界的决策函数,回归要学习到一条拟合的曲线,而聚类样本组织成簇。
一个例子:图像分类

如上图所示,给定一个图片,首先要将其编码成机器可以处理的形式,可以用一个 32 ∗ 32 ∗ 3 32*32*3 32∗32∗3 的RGB形式的矩阵来描述,然后通过一个分类函数,可以得到一个可以表征分类分数的十个数字。机器学习的目标就是学习到代这个函数的参数集合。
机器学习方法示例
- 训练数据: ( x i , y i ) , 1 ≤ i ≤ m (x_i,y_i), 1 \le i \le m (xi,yi),1≤i≤m
- 模型:
- 线性方法: y = f ( x ) = w T x + b y=f(x)=w^Tx+b y=f(x)=wTx+b
- 非线性方法:神经网络
- 策略:
- 损失函数: L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))
- 经验风险最小化: Q ( θ ) = 1 m ∑ i = 1 m L ( y i , f ( x i , θ ) ) Q(\theta ) = \frac{1}{m}\sum\limits_{i = 1}^m {L({y_i},f({x_i},\theta ))} Q(θ)=m1i=1∑mL(yi,f(xi,θ))
- 正则化: ∣ ∣ θ ∣ ∣ 2 ||\theta||^2 ∣∣θ∣∣2
- 优化目标函数: Q ( θ ) + λ ∣ ∣ θ ∣ ∣ 2 Q(\theta )+\lambda||\theta||^2 Q(θ)+λ∣∣θ∣∣2
机器学习三要素
- 模型:首先要考虑的问题是学习什么样的模型。在监督学习中,模型就是所要学习的条件概率函数或决策函数。模型的假设空间包含所有可能的条件概率函数或决策函数。决策函数表示的模型为非概率模型,条件概率的模型为概率模型。
- 策略:有了模型的假设空间,接着需要考虑是按上面准则学习或者选择最优模型,统计学习的目标在于从假设空间中选取最优模型。
- 算法:根据学习策略,从假设空间中选择最优的模型的计算方法。往往这个时候就将问题转化为最优化问题。通常问题的解析解不存在,需要用数值计算的方法求解,如何保证找到全局最优解就是个重要问题。
方法=模型+策略+算法
机器学习:模型
狭义地讲,机器学习是给定一些训练样本 ( x i , y i ) , 1 ≤ i ≤ N (x_i,y_i), 1 \le i\le N (xi,yi),1≤i≤N(其中, x i x_i xi是输入, y i y_i yi是需要预测的目标),让计算机自动寻找一个决策函数 f ( ⋅ ) f(·) f(⋅) 来建立 x x x 和 y y y 之间的 映射关系 。

y ^ = f ( x i , θ ) \widehat y = f({x_i},\theta ) y =f(xi,θ)
- 为决策函数的参数,为参数化模型可能的搜索空间。
- 如何度量函数及其参数的“好坏”?→ 损失函数
- 如何获取“最好” 的函数参数?→ 学习算法
机器学习:损失函数
-
在机器学习算法中,一般定义一个损失函数 (, (, )) ,在所有的训练样本上来评价决策函数的好坏(风险)。简单来说,损失函数就是度量真实样本与预测样本之间的差距。
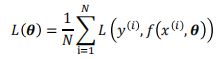
-
风险函数 ( ) 是在已知的训练样本(经验数据)上计算得来的,因此被称之为经验风险。参数的求解其实就是寻求一组参数,使得经验风险函数达到最小值,就是我们常
说的经验风险最小化原则(Empirical Risk Minimization)
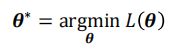
机器学习:典型损失函数
-
0-1 损失函数

-
均方差损失函数
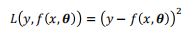
-
交叉熵损失函数( NLP 中应用最多)

机器学习:其他常用损失函数
详见:https://zhuanlan.zhihu.com/p/77686118

风险最小化准则
-
期望风险
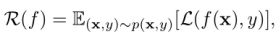
-
期望风险未知,通过经验风险近似
- 训练数据: D = { x ( n ) , y ( n ) } , i ∈ [ 1 , N ] D=\{x^{(n)},y^{(n)}\},i \in [1,N] D={x(n),y(n)},i∈[1,N]
- 经验风险最小化: Q ( θ ) = 1 m ∑ i = 1 m L ( y i , f ( x i , θ ) ) Q(\theta ) = \frac{1}{m}\sum\limits_{i = 1}^m {L({y_i},f({x_i},\theta ))} Q(θ)=m1i=1∑mL(yi,f(xi,θ))
-
机器学习问题转化成为一个最优化问题
过拟合(overfitting)与欠拟合(underfitting)
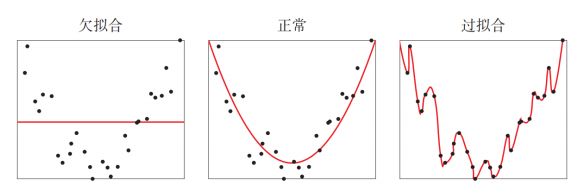
过拟合:经验风险最小化原则很容易导致模型在训练集上错误率很低,但是在未知数据上错误率很高。
结构风险最小化原则
- 为了解决过拟合问题,一般在经验风险最小化的原则上加参数的正则化(Regularization),也叫结构风险最小化原则(Structure Risk Minimization)。
-
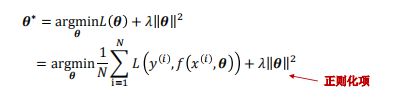
-
用来控制正则化的强度,正则化项也可以使用其它函数,比如 1 范数
-
学习:优化
-
在机器学习问题中,我们需要学习到(找到)参数 ,使得风险函数最小化。

-
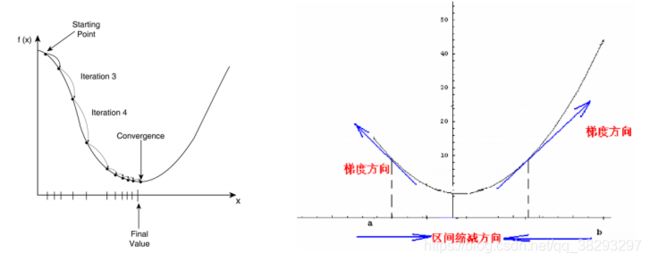
当前,通常都使用梯度下降法进行参数学习:
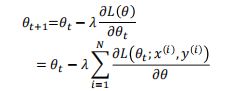
其中 为第 次迭代时的参数值. 为搜索步长, 在机器学习中也叫作学习率(learning rate)。
学习率:不大不小刚刚好
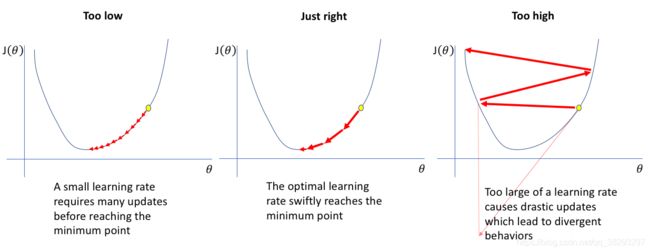

学习率自适应方法
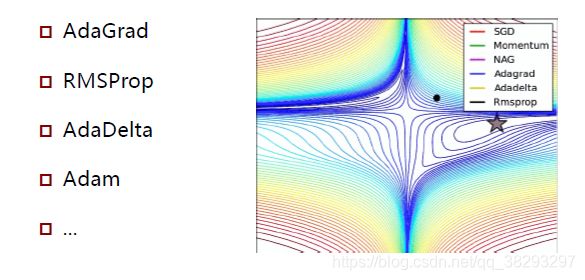
https://ruder.io/optimizing-gradient-descent/
http://xudongyang.coding.me/gradient-descent-variants/
梯度下降法
- 梯度下降是求得所有样本上的风险函数最小值,叫做批量梯度下降法
- 若样本个数 很大,输入 的维数也很大时,那么批量梯度下降法每次迭代要处理所有的样本,效率会较低
- 一种改进的方法即随机梯度下降法。随机梯度下降法(Stochastic Gradient Descent,SGD)也叫增量梯度下降,每个样本都进行更新
- 小批量梯度下降法(Mini-Batch Gradient Descent)是批量梯度下降和随机梯度下降的折中. 每次迭代时,随机选取一小部分训练样本来计算梯度并更新参数,这样既可以兼顾随机梯度下降法的优点,也可以提高训练效率

线性分类
线性分类是机器学习中最常见并且应用广泛的一种分类器 。
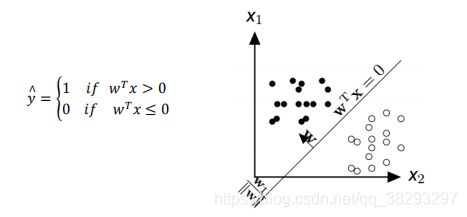
逻辑回归:Logistic Regression
-
定义目标类别 = 1 的后验概率为:
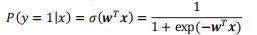
- (·) 为 logistic 函数
- 和 为增广的输入向量和权重向量。
- = 0 的后验概率为:


-
logistic函数经常用来将一个实数空间的数映射到 (0,1) 区间,记为 (): σ ( x ) = 1 1 + e − x \sigma (x) = \frac{1}{{1 + {e^{ - x}}}} σ(x)=1+e−x1
- 其导数为: σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) \sigma '(x) = \sigma (x)(1 - \sigma (x)) σ′(x)=σ(x)(1−σ(x))
- 当输入为 K 维向量 x = [ x 1 , ⋅ ⋅ ⋅ , x K ] T x = [x_1, ··· , x_K]^T x=[x1,⋅⋅⋅,xK]T 时,其导数为: σ ′ ( x ) = d i a g ( σ ( x ) ⊙ ( 1 − σ ( x ) ) ) \sigma '(x) = diag(\sigma (x) \odot (1 - \sigma (x))) σ′(x)=diag(σ(x)⊙(1−σ(x)))
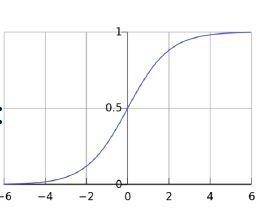
-
给定 N 个样本 ( x ( i ) , y ( i ) ) , 1 ≤ i ≤ N (x^{(i)},y^{(i)}),1≤i≤N (x(i),y(i)),1≤i≤N,我们使用交叉熵损失函数,模型在训练集的风险函为 :
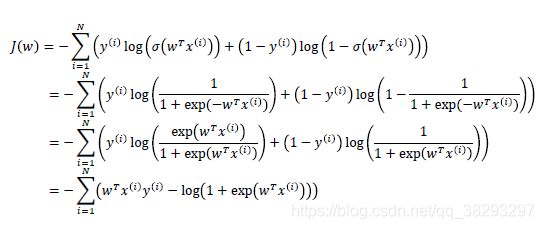
-
采用梯度下降法, J(w) 关于 w的梯度为 :
可以初始化 w0=0,然后用梯度下降法进行更新 ,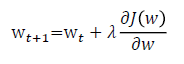
推导示例:logistic regression


编程实践

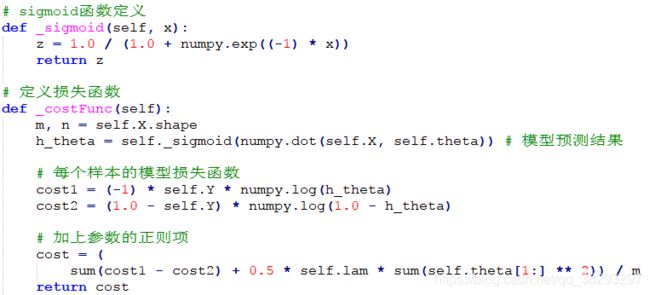

NLP应用:文本情感分类
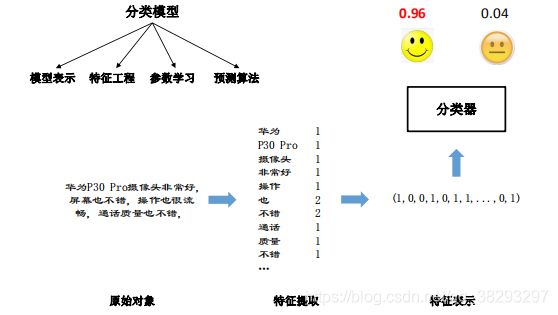
评价方法
- 常见的评价标准有正确率、准确率、召回率和 值等。
- 给定测试集 = (1, 1) , … , (, ),对于所有的 ∈{ 1,··· , } , y ^ i {\widehat y_i} y i 为 对应的模型预测结果。
- 正确率(Accuracy):[ ∣ ⋅ ∣ | · | ∣⋅∣ 为指示函数]
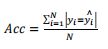
- 与正确率相对应的就是错误率:
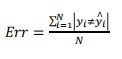
- 正确率是平均的整体性能。
- 在很多情况下需要对每个类都进行性能估计,这就需要计算准确率和召回率
- 准确率(Precision),是识别出的个体总数中正确识别的个体总数的比例。对于
类 c 来说:
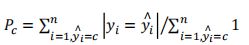
- 召回率(Recall,R),也叫查全率,是测试集中存在的个体总数中正确识别的个
体总数的比例:
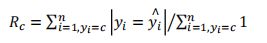
- F值:
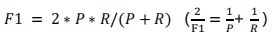
- 准确率(Precision),是识别出的个体总数中正确识别的个体总数的比例。对于
- 多类情况通常使用宏平均和微平均进行评价
- 宏平均:先对每一个类统计指标值,然后在对所有类求算术平均值。
- 微平均:对数据集中的每一个实例不分类别进行统计,然后计算相应指标。
开发集
- 在梯度下降训练的过程中,由于过拟合的原因,在训练样本上收敛的参数,并不一定在测试集上最优。
- 通常需要使用一个验证集 (也叫开发集) 来测试每一次迭代的参数在验证集上是否最优。如果在验证集上的错误率不再下降,就停止迭代。
- 如果没有验证集,可以从训练集中抽取部分数据作为验证集,也可以通过交叉验证进行(内部)模型选择。
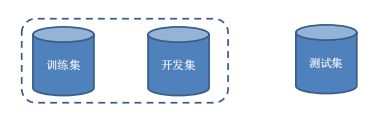
一般来说,开发集是在模型内部进行调优,测试集是在模型外部进行调优的。
多类分类
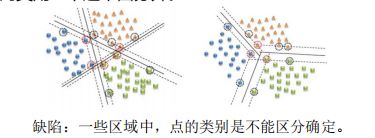
对于多类分类问题(假设类别数为 ( > 2)),一般有两种多类转两类的转换方式:
- (one-vs-rest/one-vs-all)把多类分类问题转换为 个两类分类问题,构建 个一对多的分类器。每个两类分类问题都是把某一类和其他类用一个超平面分开。
- (one-vs-one)把多类分类问题转换为 ( − 1)/2 个两类分类问题,构建( − 1)/2 个两两分类器。每个两类分类问题都是把 类中某两类用一个超平面分开。
Softmax分类
- Softmax 回归是 Logistic 回归的多类推广
- 我们定义目标类别 = 的后验概率为:
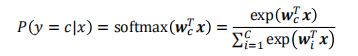
- Softmax函数
- 它能将一个含任意实数的 维向量 “压缩”到另一个 K 维实向量 ()中,使得每一个元素的范围都在 (0,1)之间,并且所有元素的和为1
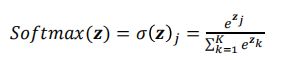
- 它能将一个含任意实数的 维向量 “压缩”到另一个 K 维实向量 ()中,使得每一个元素的范围都在 (0,1)之间,并且所有元素的和为1
其他机器学习方法/模型/任务

机器学习工具包:WEKA简介
作为一个大众化的数据挖掘工作平台, WEKA集成了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联分析以及在新的交互式界面上的可视化等等。通过其接口,可在其基础上实现自己的数据挖掘算法。
总结:机器学习三要素

2. 神经网络与是深度学习基础
传统机器学习
人工特征工程+分类器

在大数据下的机器学习中,人是不可能将这些特征去完备的提取出来的。

鉴于上面所说,有没有什么自动的方法可以让机器学到这些特征呢?这就引入深度学习
深度学习:自动学习多尺度的特征表示
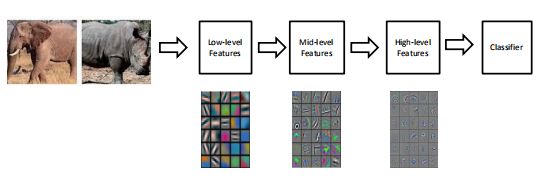
深度学习和表示学习
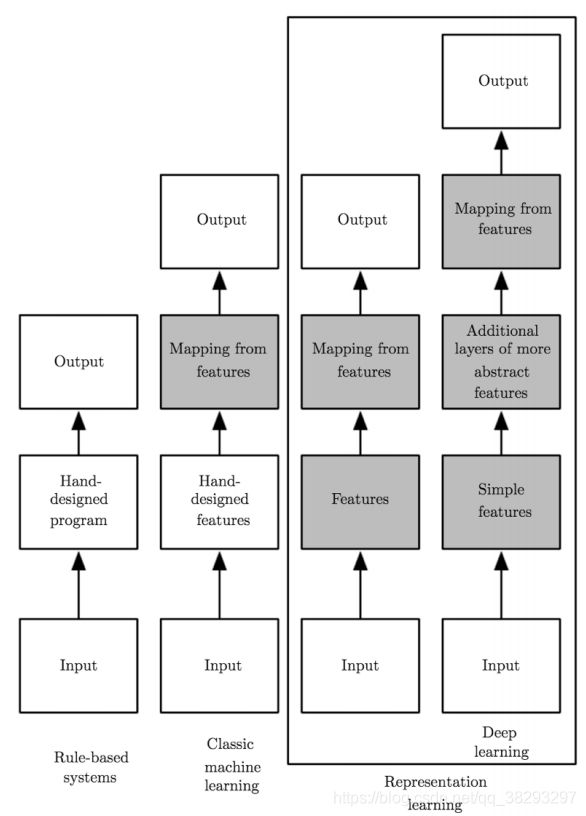
- 规则思维:人去定制一些规则,编码到程序中
- 传统的机器学习,人定义一些特征,是机器学到特征和输出之间的映射。
- 表示学习:强调特征的一些表示和变换;
- 深度学习:当表示和变换很深的时候,其实就是深度学习。
深度学习离不开感知器啊
感知机 Perception
定义
- 感知器是对生物神经细胞的简单数学模拟,是最简单的人工神经网络, 只有一个神经元。 感知器也可以看出是线性分类器的一个经典学习算法。
- 细胞体(Soma)中的神经细胞膜上有各种受体和离子通道,胞膜的受体可与相应的化学物质神经递质结合,引起离子通透性及膜内外电位差发生改变,产生相应的生理活动:兴奋或抑制。 细胞突起是由细胞体延伸出来的细长部分,又可分为树突和轴突。
- 树突(Dendrite)可以接受刺激并将兴奋传入细胞体。每个神经元可以有一或多个树突。
- 轴突 (Axons) 可以把兴奋从胞体传送到另一个神经元或其他组织。每个神经元只有一个轴突。
- 抑制与兴奋
- 神经 细胞的状态取决于从其它的神经细胞收到的输入信号量,及突触的强度(抑制或加强)。当信号量总和超过了某个阈值时,细胞体就会兴奋,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。
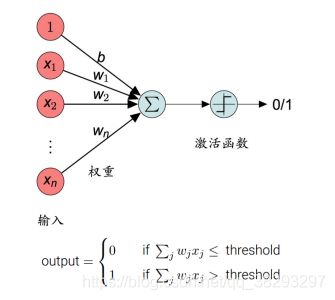
感知机几何解释
其实就是学习到一个超平面或者分界线
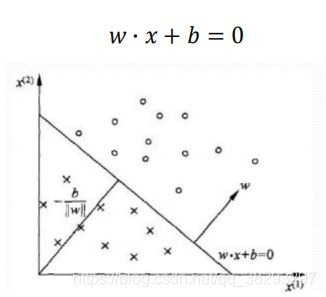
这里比较重要的就是两个参数:, b
如何学习呢?
感知机参数学习
定义一个损失函数,均方差损失函数,根据训练数据(x,y),计算w,b的导数,根据梯度下降法来更新参数。
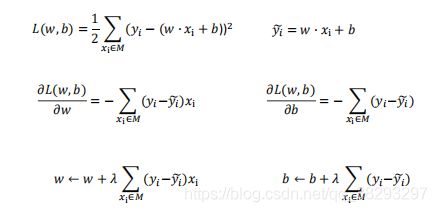
直接这么做有一个问题,这是一个线性分类器,对于非线性问题无法解释,那么这就提出了 异或问题

那么实现这个呢?
非线性的隐藏层
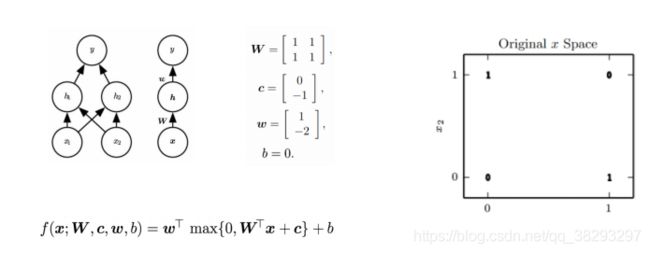
由上图可知,参数都已知了,下面来具体计算一下:
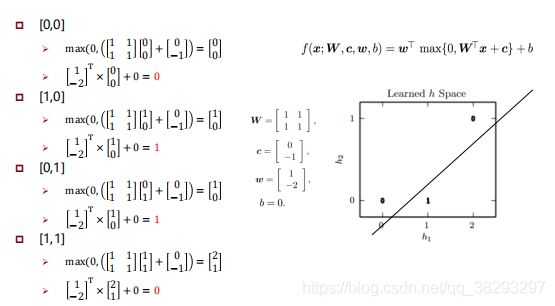
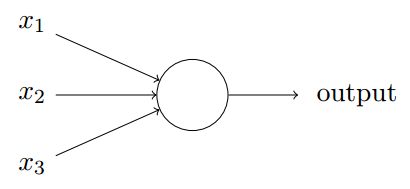
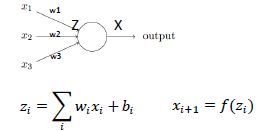
Non-linear Neurons

=∙+
=()
其中 f 是一个非线性的激活函数。用的比较多的就是 Sigmoid 函数,如下:
Sigmoid
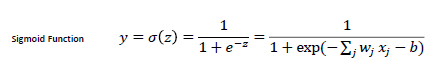
Sigmoid 可以把所有数值变幻成 0 ∼ 1 0\sim1 0∼1 之间的数值,有一个优点是:导数很好计算……
训练

当然,Sigmoid 有很多缺点,所以提出了其他激活函数;
Other Activation Functions

() = max(0, ) ,rectifier 函数被认为有生物上的解释性。神经科学家发现神经元具有单侧抑制、宽兴奋边界、稀疏激活性等特性。采用 rectifier 函数的单元也叫作正线性单元(rectified linear unit, ReLU)。
https://www.jiqizhixin.com/articles/2017-11-02-26
激活函数的性质
- 激活函数在神经元中非常重要,是实现非线性变换的核心操作.
- 为了增强网络能力(表示效果和计算效率),激活函数需要具备以下几点性质:
➢ 连续并可导(允许少数点上不可导)的非线性函数. 可导的激活函数可以直接利用数值优化的方法来学习网络参数.
➢ 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率.
➢ 激活函数的导函数的值域要在一个合适的区间内, 不能太大也不能太小,否则会影响训练的效率和稳定性.
人工神经网络
人工神经网络主要由大量的神经元以及它们之间的连接构成。因此主要考虑以下三方面:
➢ 神经元的激活规则
• 主要是指神经元输入到输出之间的映射关系,一般为非线性函数。
➢ 网络的拓扑结构
• 不同神经元之间的连接关系。
➢ 学习算法
• 通过训练数据来学习神经网络的参数。
典型网络结构
人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。

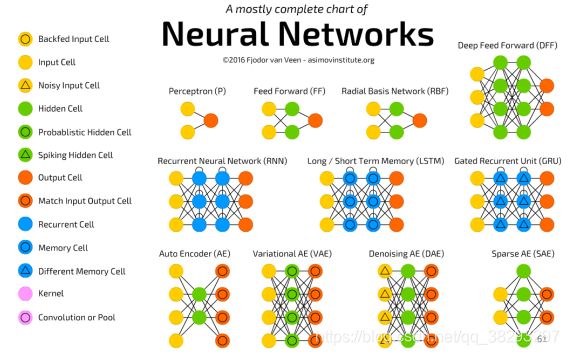
详见:http://www.asimovinstitute.org/neural-network-zoo/
前馈神经网络
组合多个神经元构建一个网络,一种比较直接的拓扑结构是前馈网络.
- 前馈神经网络(Feedforward Neural Network,FNN)是最早发明的简单人工神经网络.
- 前馈神经网络也经常称为多层感知器(Multi-Layer Perceptron,MLP).
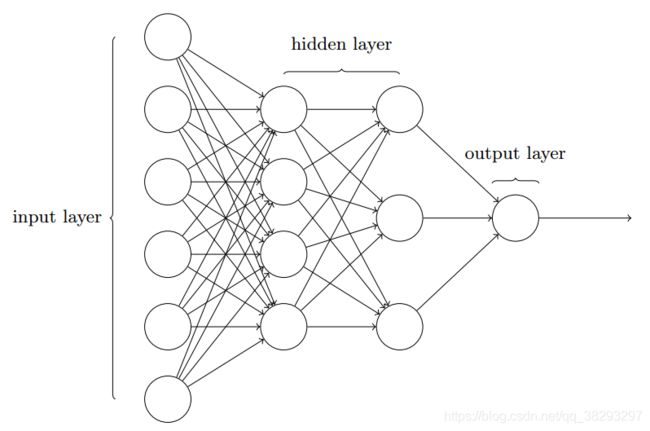
前馈计算

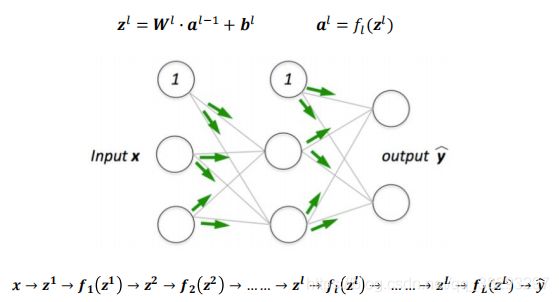
训练:梯度下降法

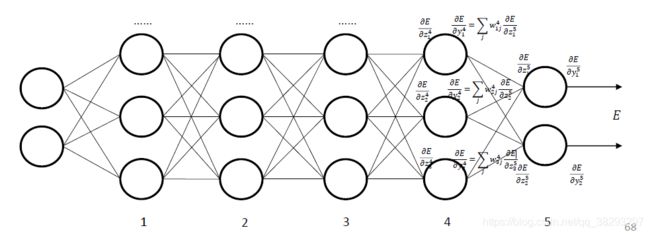
反向传播算法
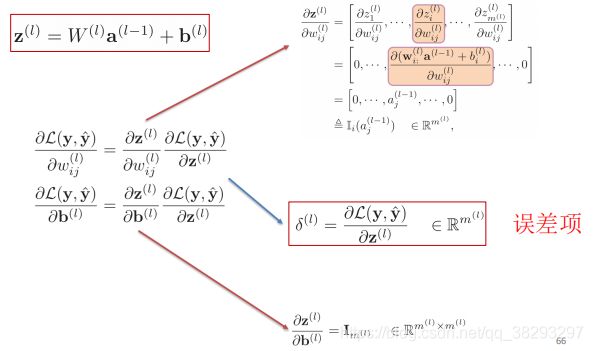
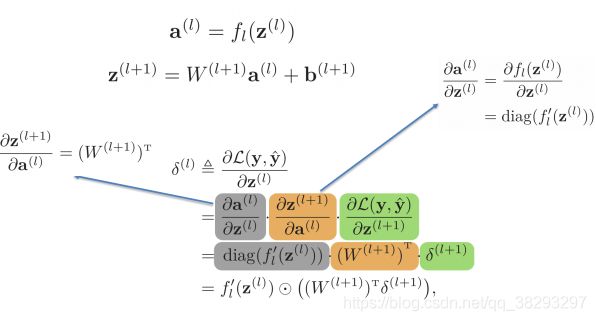
通过上图可知,第 l l l 层的误差项可以通过第 l + 1 l+1 l+1 层的误差项计算得到,这其实就是误差的反向传播。
反向传播的含义是: 第 l l l 层的误差项是 所有与该层相连接的第 l + 1 l+1 l+1 层的误差的权重和再乘以这个神经元激活函数的梯度 得到。
基于BP算法的前馈神经网络训练过程
- 前馈计算每一层的净输入 ( z ( l ) ) (z^{(l)}) (z(l)) 和激活值 ( a ( l ) ) (a^{(l)}) (a(l)),直到最后一层;
- 反向传播计算每一层的误差项 ( δ ( l ) ) (\delta ^{(l)}) (δ(l));
- 计算每一层参数的偏导数,并更新参数
常用的深度学习工具包

深度学习的三个步骤
自动梯度计算
- 数值微分(Numerical Differentiation)
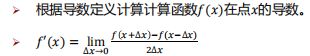
- 符号微分(Symbolic Differentiation)

- 自动微分(Automatic Differentiation, AD)


复合函数(; , ) = 1 / (−( + )) + 1 的计算图
静态计算图和动态计算图
- 静态计算图是在编译时构建计算图,计算图构建好之后在程序运行时不能改变。
- Theano和Tensorflow
- 动态计算图是在程序运行时动态构建,更便于处理复杂数据结构,也更便于调试
- Chainer, PyTorch, 飞桨(PaddlePaddle)等
- 两种构建方式各有优缺点。静态计算图在构建时可以进行优化,并行能力强,但灵活性比较差低。动态计算图则不容易优化,当不同输入的网络结构不一致时,难以并行计算,但是灵活性比较高。
总结:深度学习的发展历史

http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning/
3. NLP中的深度学习
自然语言处理

组合语义原则
- 一个复杂对象的意义是由其各组成部分的意义以及它们的组合规则来决定

词的分布表示

语义组合模型
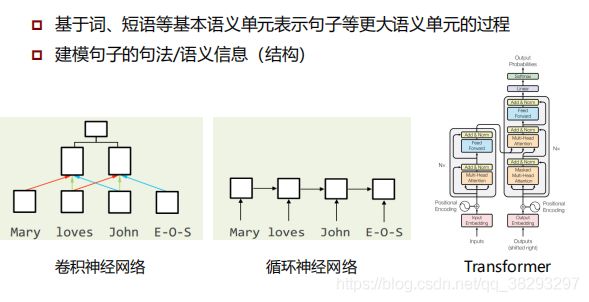
4. 语义组合模型
(1)卷积神经网络
CNN
-
Convolutional Neural Network是一种前馈神经网络。卷积神经网络是受生物学上感受野(Receptive Field) 的机制而提出的。一个神经元的感受野是指特定区域,只有这个区域内的刺激才能够激活该神经元.
- 局部链接
- 权值共享
- 采样
-
具有平移、缩放和扭曲不变性
全连接 vs. 卷积
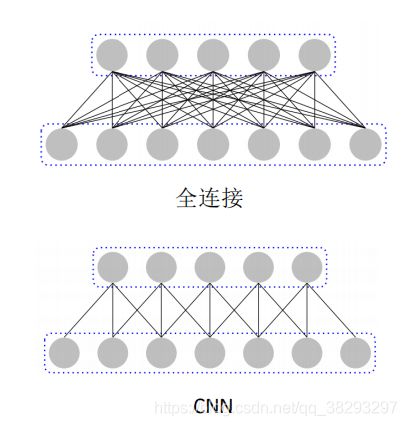
CNN是局部链接的。
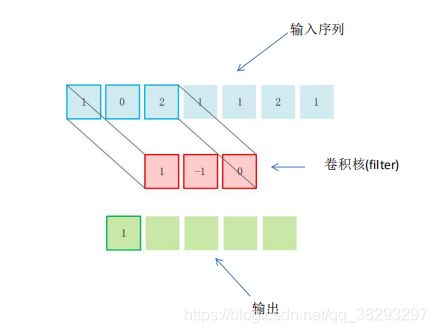
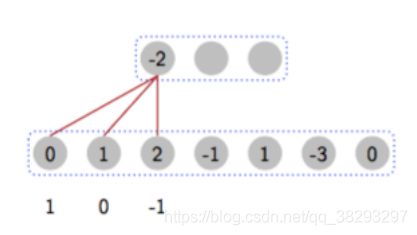
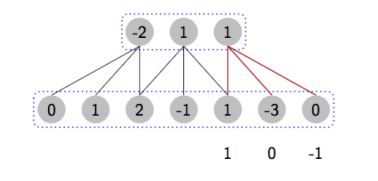
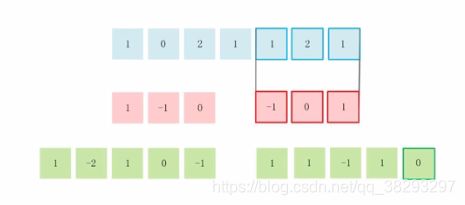
一维卷积、二维卷积、卷积层、滤波器
一维卷积
- 信号 x,信号长度 n
- 滤波器 f,滤波器长度 m
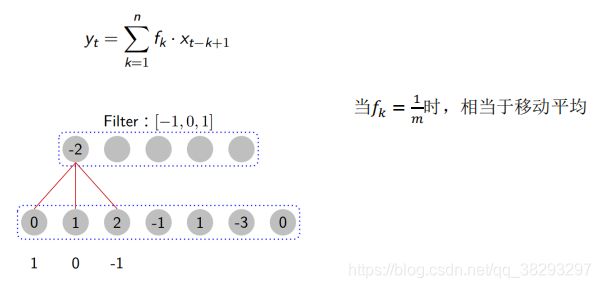
举个例子:
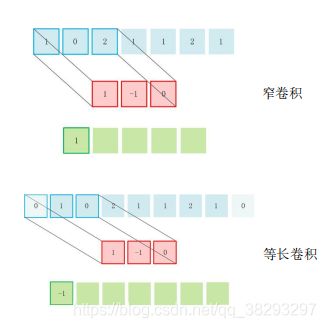
卷积类型
- 窄卷积
➢ 信号两端 不补 0
➢ 输出信号长度为 n-m+1 - 宽卷积
➢ 信号两端 补更多的 0
➢ 输出信号长度为 n+m-1 - 等长卷积
➢ 信号两端 补 0
➢ 输出信号长度为 n
滤波器步长
- Stride=2
二维卷积
- 信号 x,信号长度 M*N
- 滤波器 f,滤波器长度 m*n
- 在图像中,卷积意味着区域内像素的加权平均
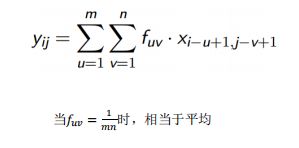
卷积类型
- 窄卷积
➢ 信号四周不补 0
➢ 输出信号长度为 M-m+1*N-n+1 - 宽卷积
➢ 信号四周补 0
➢ 输出信号长度为 M+m-1 *N+n-1 - 等长卷积
➢ 信号四周补 0
➢ 输出信号长度为 M*N
举个例子:
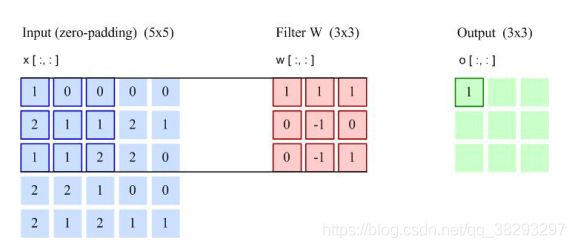
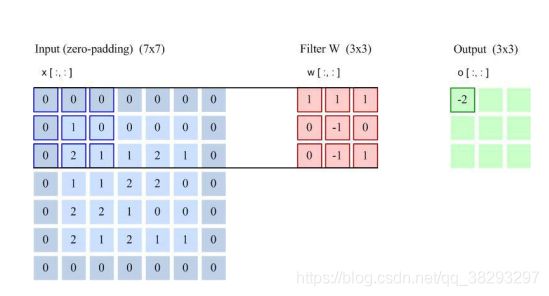
两维卷积实例

下面来比较一下全连接前馈神经网络和卷积神经网络。
全连接前馈神经网络
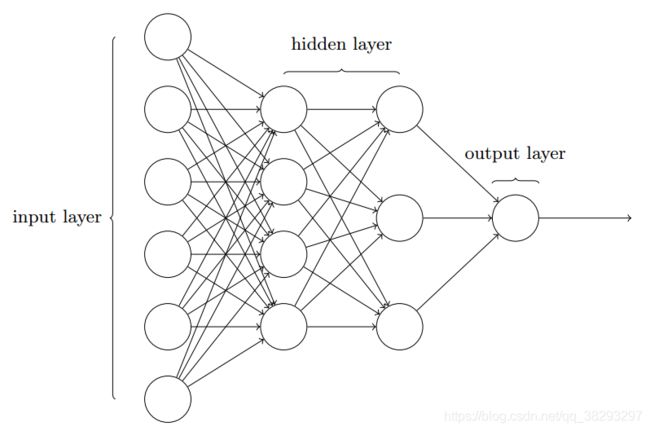
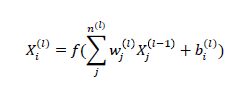
卷积神经网络
-
局部链接:第 l 层的每一个神经元都只和第 l − 1 层的一个局部窗口内的神经元相连,构成一个局部连接网络。
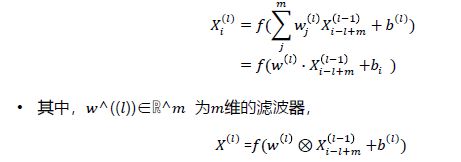
-
权值共享 :在卷积层里,我们只需要 m + 1 个
二维卷积层

前面说的都是一个卷积核的情况,那么下面
两个filters
特征映射 Feature Map
为了增强卷积层的表示能力,我们可以使用K 个不同的滤波器来得到K 组输出。每一组输出都共享一个滤波器。如果我们把滤波器看成一个特征提取器,每一组输出都可以看成是输入图像经过一个特征抽取后得到的特征。因此,在卷积神经网络中每一组输出也叫作一组特征映射(Feature Map)。
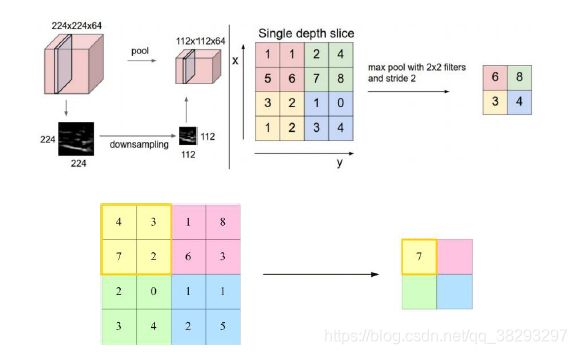
子采样层
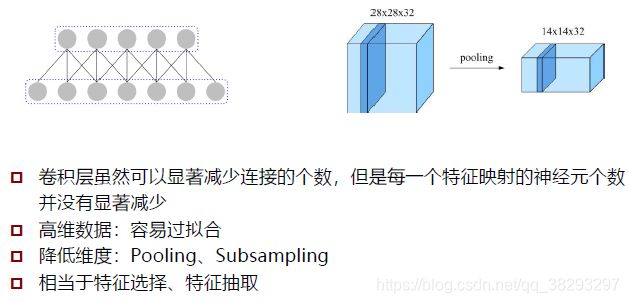


子采样层示例
CNN的应用
CNN在图像处理中的应用
-
LeNet-5 虽然提出时间比较早,但是是一个非常成功的神经网络模型。基于 LeNet-5 的手写数字识别系统在 90 年代被美国很多银行使用,用来识别支票上面的手写数字。LeNet-5共有 7 层。
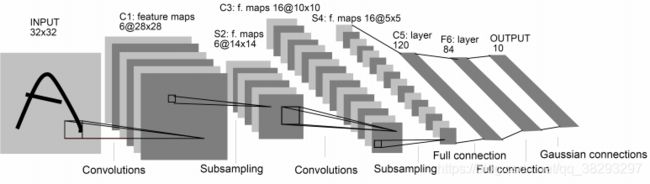
-
AlexNet
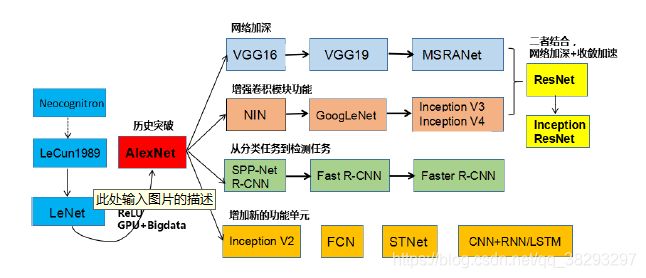
-
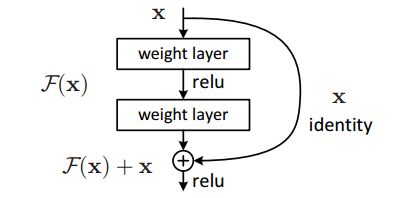
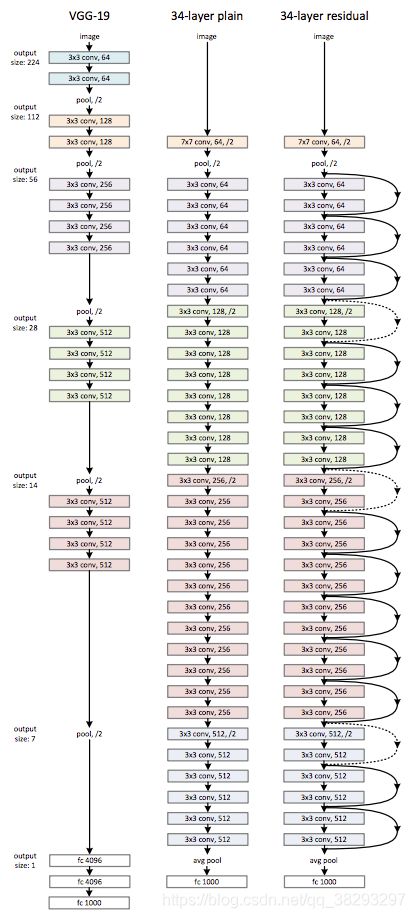
ResNet
2015 ILSVRC winner
152层
错误率:3.57%
CNN在自然语言处理中的应用
- 文本分类:情感分类

- CNN-句子建模框架
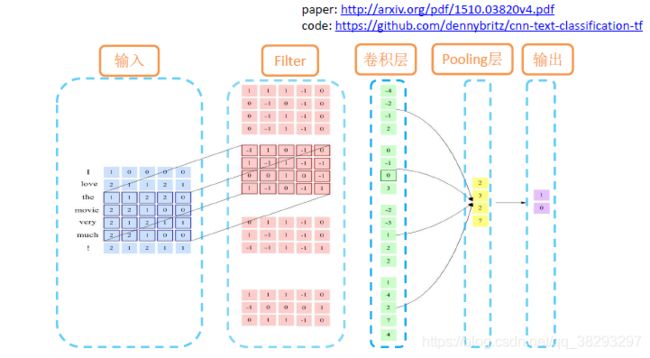
paper: http://arxiv.org/pdf/1510.03820v4.pdf
code: https://github.com/dennybritz/cnn-text-classification-tf
其他各种(奇怪的)卷积模型
前馈神经网络的不足
- 连接存在层与层之间,每层的节点之间是无连接的。
- 输入和输出的维数都是固定的,不能任意改变。无法处理变长的序列数据。
- 假设每次输入都是独立的,也就是说每次网络的输出只依赖于当前的输入。
CNN就属于前馈神经网络。然而,却有一些缺点。对于以下各种处理任务来说,不足以。所以提出了循环神经网络。
各种处理任务

(2)循环神经网络
循环神经网络可以接收变长输入,并且可以考虑时序关系。
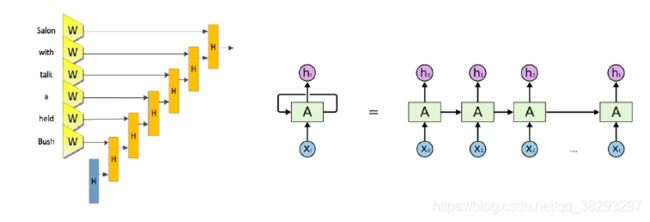
- 循环神经网络( Recurrent Neural Network, RNN),也叫递归神经网络。这里为了区别与另外一种递归神经网络( Recursive Neural Network),我们称为循环神经网络
- 前馈神经网络的输入和输出的维数都是固定的,不能任意改变。无法处理变长的序列数据。
- 假设每次输入都是独立的,也就是说每次网络的输出只依赖于当前的输入。
- 循环神经网络通过使用带自反馈的神经元,能够处理任意长度的序列。循环神经网络比前馈神经网络更加符合生物神经网络的结构。循环神经网络已经被广泛应用在语音识别、图像处理、语言模型以及自然语言生成等任务上。
更形式化的描述如下:
- 给定一个输入序列 x ( 1 : n ) = ( x ( 1 ) , x ( 2 ) , . . . , x ( t ) , . . . , x ( n ) ) x^{(1:n)}=(x^{(1)},x^{(2)},...,x^{(t)},...,x^{(n)}) x(1:n)=(x(1),x(2),...,x(t),...,x(n)),循环神经网络通过下面公式更新带反馈边的隐藏层的活性值 ,即抽象表示:
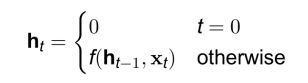
循环神经网络的示例:
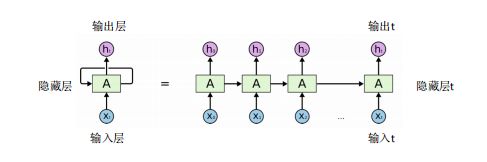
简单循环网络
-
假设时刻 t 时,输入为 xt ,隐层状态(隐层神经元活性)为 ht 。 ht 不仅和当前时刻的输入相关,也和上一个时刻的隐层状态相关。
-
一般我们使用如下函数:
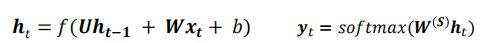
这里,是非线性函数,通常为 sigmod函数或 tanh 函数。
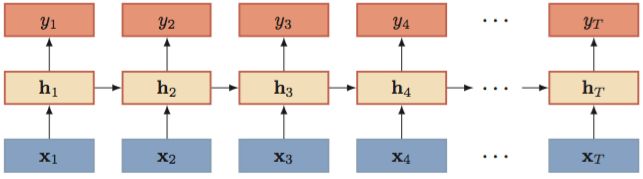
简单循环神经网络的前向计算
训练:梯度计算
- 循环神经网络的参数训练可以通过随时间进行反向传播(Backpropagation Through Time,BPTT)算法 。
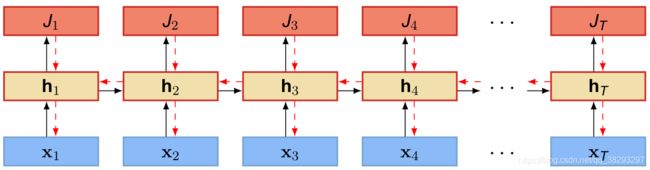
梯度
- 假设循环神经网络在每个时刻 t 都有一个监督信息,损失为 。则整个序列的损失为 J = ∑ t = 1 T J t J = \sum\limits_{t = 1}^T {{J_t}} J=t=1∑TJt。
- 损失 关于 U 的梯度为:
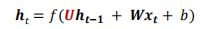
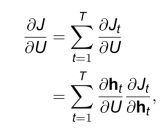
其中, 是关于 U 和 −1 的函数,而 −1 又是关于 U 和 −2 的函数。

- 因此,总的梯度为
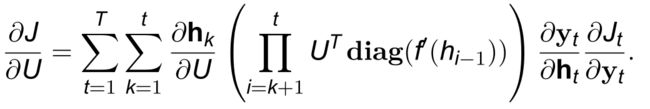
长期依赖问题/梯度消失问题

长短时记忆神经网络:LSTM
-
长短时记忆神经网络(Long Short-Term Memory Neural Network,LSTM)是循环神经网络的一个变体,可以**有效地解决简
-
LSTM 模型的关键是引入了一组记忆单元(Memory Units),允许网络可以学习何时遗忘历史信息,何时用新信息更新记忆单元。在时刻 t 时,记忆单元 c t c_t ct 记录了到当前时刻为止的所有历史信息,并受三个“门”控制:输入门 i t i_t it, 遗忘门 f t f_t ft 和输出门 o t o_t ot 。三个门的元素的值在 [ 0 , 1 ] [0, 1] [0,1] 之间。
-
在时刻 t 时 LSTM 的更新方式如下:
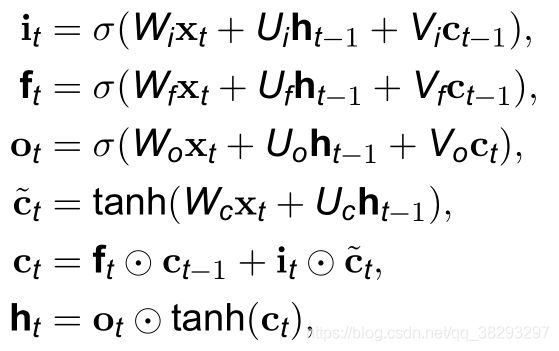
这里, x t x_t xt 是当前时刻的输入, σ σ σ 是 logistic 函数, V i V_i Vi , V f V_f Vf, V o V_o Vo 是对角矩阵。遗忘门 f t f_t ft 控制每一个内存单元需要遗忘多少信息,输入门 i t i_t it 控制每一个内存单元加入多少新的信息,输出门 o t o_t ot 控制每一个内存单元输出多少信息。
LSTM 图解
如下图所示,上面是简单的RNN,下面是LSTM
- 那么简单的RNN:隐藏状态仅与 x t x_t xt 和 x t − 1 x_{t-1} xt−1 相关;中间经过 t a n h tanh tanh 这一操作。
- LSTM里面有三个门控信息,计算过程更为复杂。
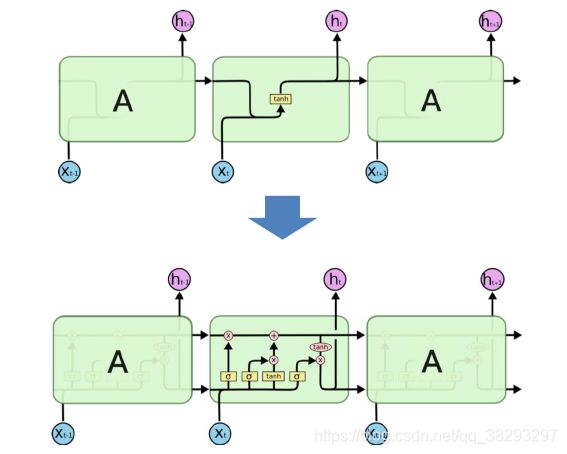
- 核心:记忆(细胞状态),核心是比普通RNN多了一个 c t c_t ct。另外一个重要的是门控信息。通过点乘计算当前应该保留多少值。
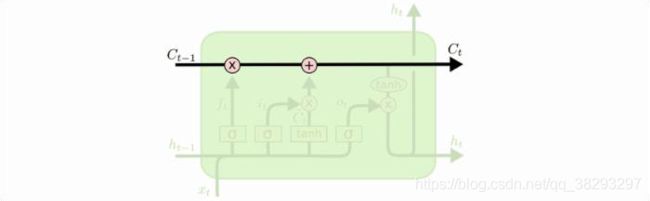
- 输入门:输入门决定了当前时刻网络的输入 x t x_t xt 有多少保存到单元状态 c t c_t ct
- 遗忘门:遗忘门决定了上一时刻的单元状态 c t − 1 c_{t-1} ct−1 有多少保留到当前的时刻 c t c_t ct
- 输出门:输出门来控制单元状态 c t c_t ct 有多少输出到 LSTM 的当前输出值 h t h_t ht

LSTM 的变种
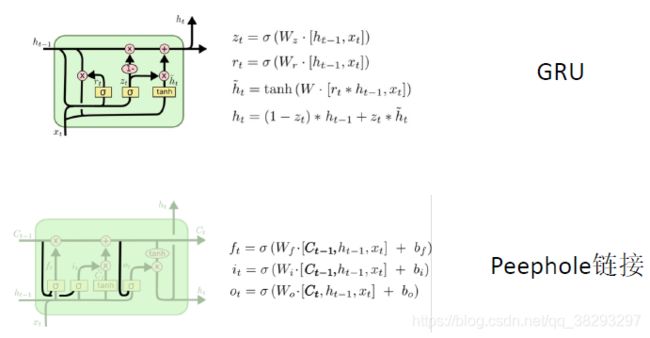
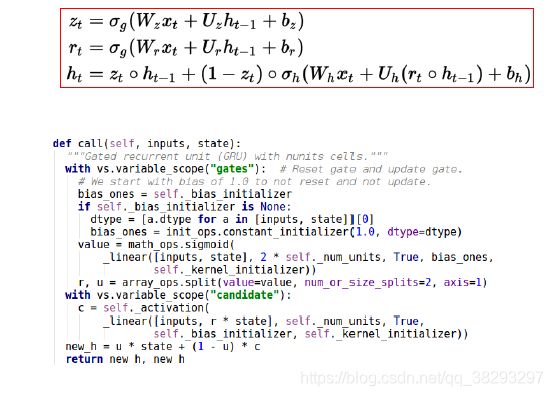
门限循环单元:GRU
-
门限循环单元(Gated Recurrent Unit,GRU)是一种比 LSTM 更加简化的版本。在 LSTM 中,输入门和遗忘门是互补关系,因为同时用两个门比较冗余。GRU 将输入门与和遗忘门合并成一个门:更新门(Update Gate),同时还合并了记忆单元和神经元活性。GRU 模型中有两个门:更新门 z z z 和重置门 r r r。
- 更新门 z z z 用来控制当前的状态需要遗忘多少历史信息和接受多少新信息。
- 重置门 r r r 用来控制候选状态中有多少信息是从历史信息中得到。
-
GRU 模型的更新方式如下:

- 这里选择 tanh 函数也是因为其导数有更大的值域
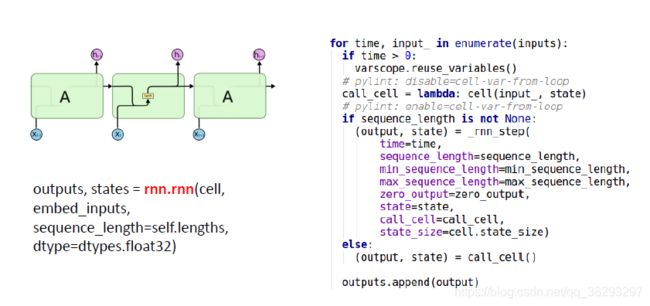
编程
- BasicRNNCell

- BasicLSTMCell
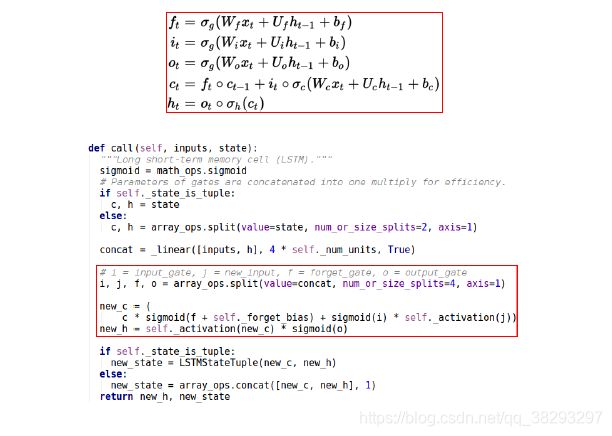
- GRUCell
- rnn
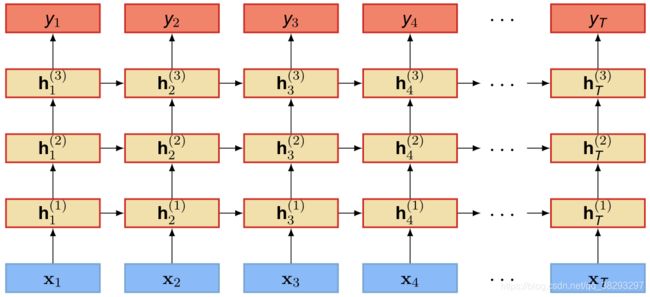
深层循环神经网络
- 循环神经网络的深度是一个有一定争议的话题。
- 一方面来说,如果我们把循环网络按时间展开,不同时刻的状态之间存在非线性连接,循环网络已经是一个非常深的网络了。
- 从另一方面来说,这个网络是非常浅的。任意两个相邻时刻的隐藏状态( h t − 1 h_{t-1} ht−1→ h t h_t ht ),隐藏状态到输出( h t − 1 h_{t-1} ht−1→ y t y_t yt ),以及输入到隐藏状态之间( x t x_{t} xt→ h t h_t ht )之间的转换只有一个非线性函数。
堆叠(Stack)循环神经网络
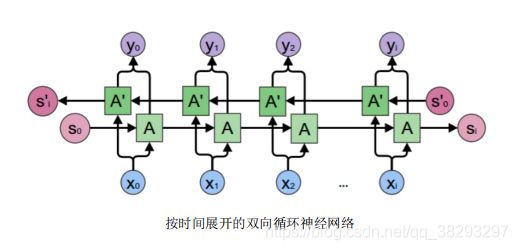
双向循环神经网络
应用
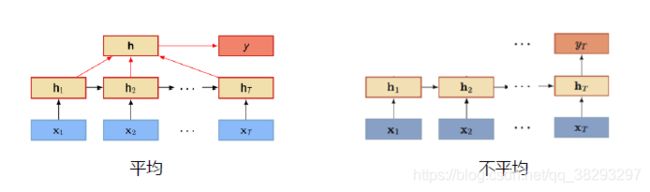
应用:序列到类别
- 输入为序列,输出为类别。比如在文本分类中,输入数据为单词的序列,输出为该文本的类别。
应用:同步序列到序列
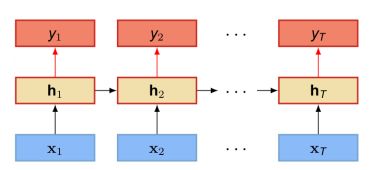
- 输入和输出同步,即每一时刻都有输入和输出。比如在序列标注问题,每个时刻的输入都需要有一个输出。输入序列和输出序列的长度相同。
应用:异步序列到序列
- 输入和输出不需要有严格的对应关系。比如在机器翻译中,输入为源语言的单词序列,输出为目标语言的单词序列。输入和输出序列并不需要保持相同的长度。
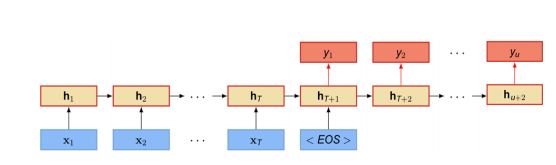
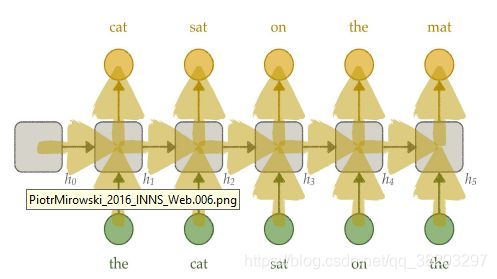
基于RNN的语言模型
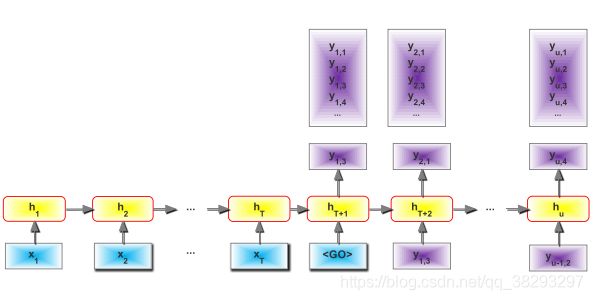
(3)Seq2Seq :Sequence to Sequence Learning
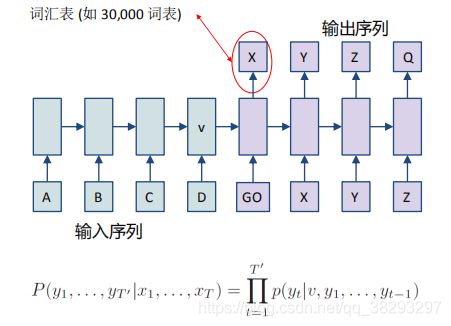
Seq2Seq: train-time
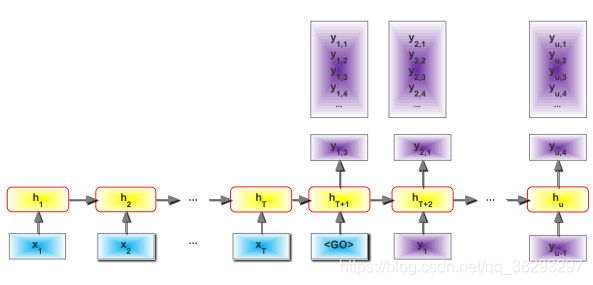
Seq2Seq: test-time
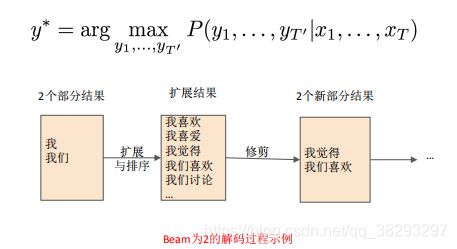
Beam Search(解码过程)
RNN-based Seq2Seq
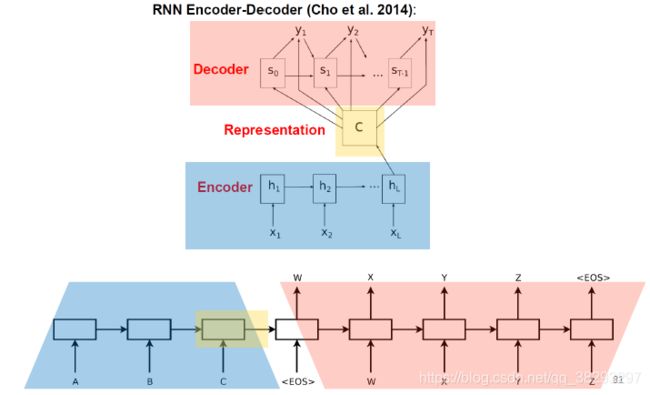
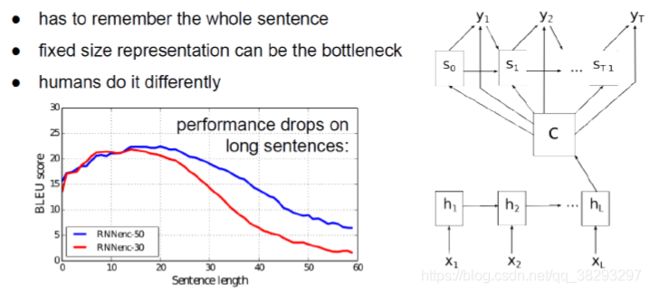
存在的问题
例如在机器翻译中:
Seq2Seq with Attention
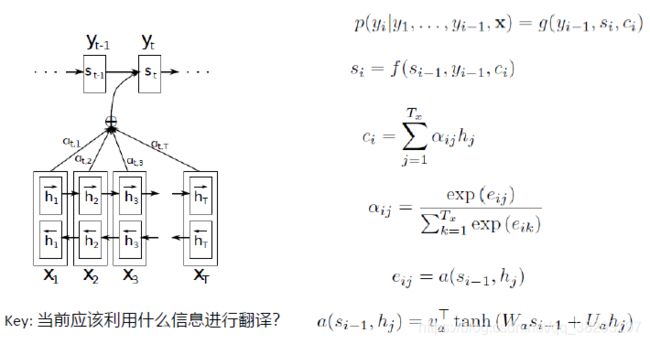
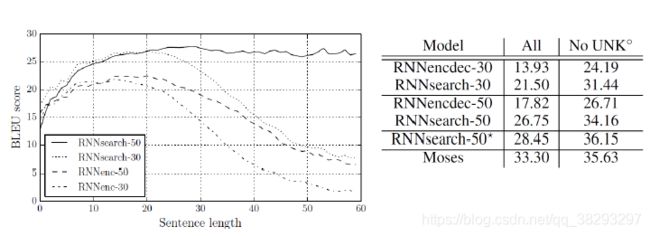
阅读理解中的Attention机制

自动摘要中的Attention机制
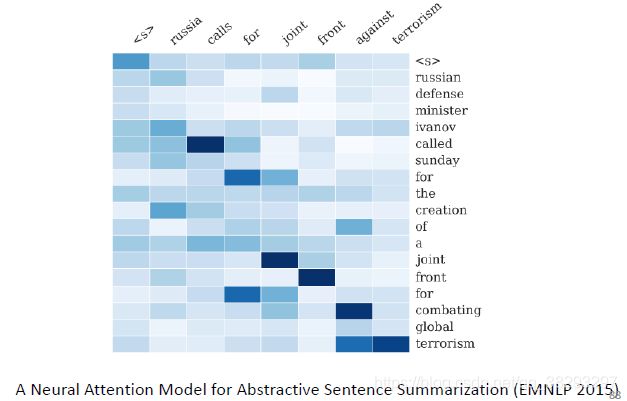
Seq2Seq Learning:Beyond RNN
-
Conv Seq2Seq, Gehring, et al, 2017
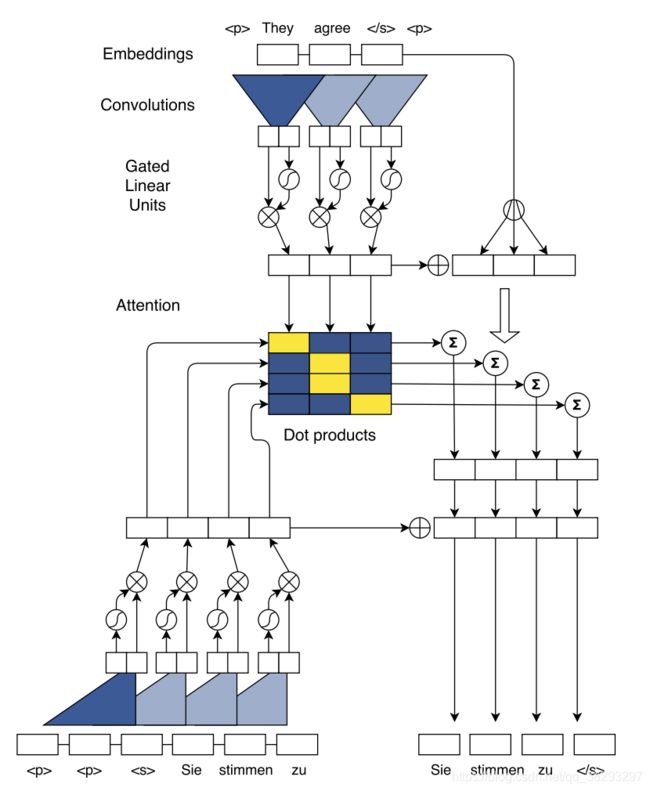
-
Att is all you need, Vaswani, et al, 2017
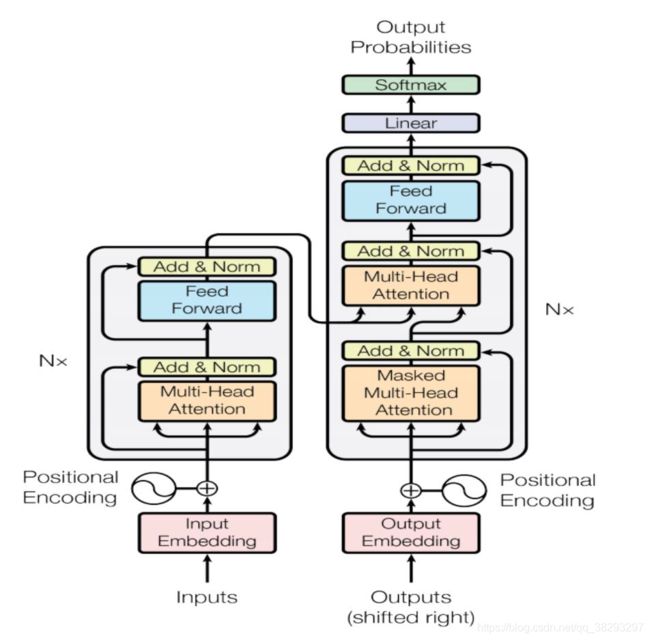
(4)Transformer相关
自注意力(Self-Attention)模型
- 当使用神经网络来处理一个变长的向量序列时,我们通常可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列。
- 只建模了输入信息的局部依赖关系。
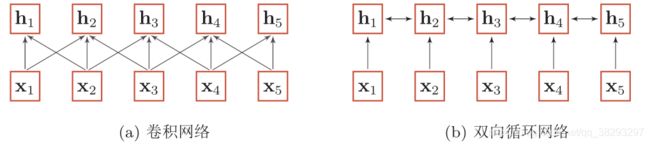
- 只建模了输入信息的局部依赖关系。
- 如何建立非局部(Non-local)的依赖关系
- 全连接?
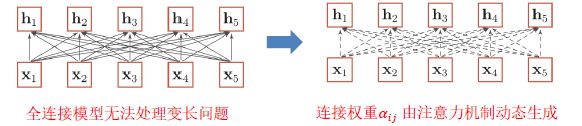
- 全连接?
自注意力示例
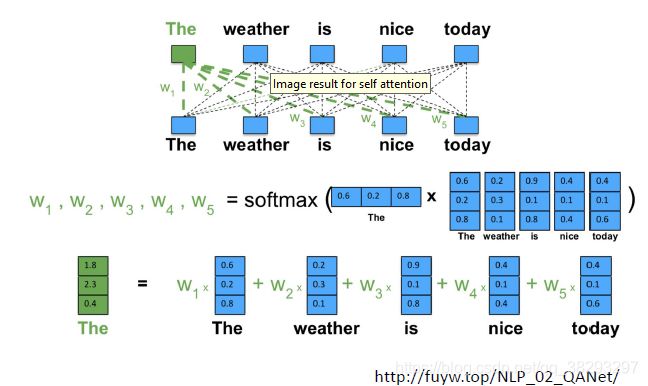
QKV模式(Query-Key-Value)
- Q:Attention的时候基于什么东西去关注
- K:关注某个事物的时候,与谁进行计算
- V:关注完以后,提取什么样的信息
- K 和 V 可以取相同或者不同的值
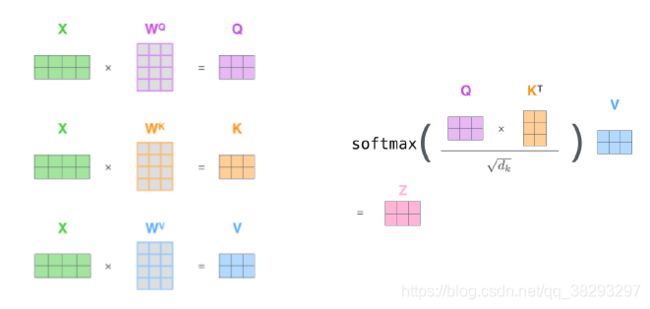
自注意力模型
- 输入序列为 X = [ x 1 , . . , x N ] ∈ R d 1 ∗ N X = [x_1,..,x_N] \in R^{d_1 * N} X=[x1,..,xN]∈Rd1∗N
- 首先生成三个向量序列
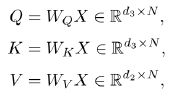
- 计算 h i h_i hi
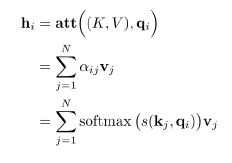
attention 的 3 种方式
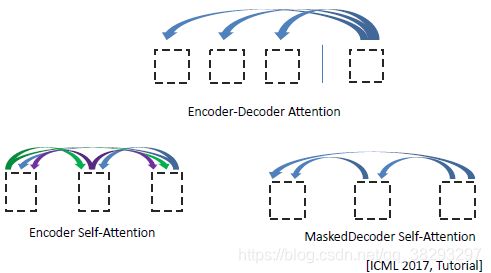
Transformer: attention is all your need

建议参考项目:https://github.com/jadore801120/attention-is-all-you-need-pytorch
-
Transformer : Scaled Dot-Product Attention

-
Transformer : Multi-Head(多头) Attention
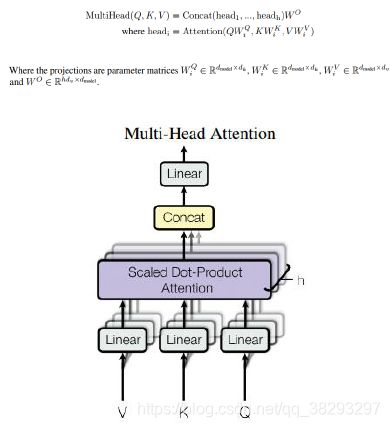

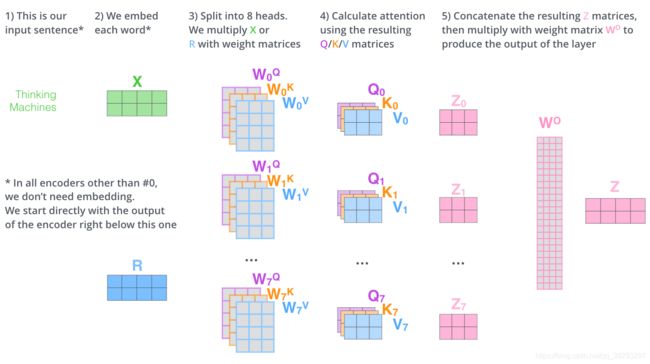
-
Transformer : Position-wise Feed-Forward Networks

-
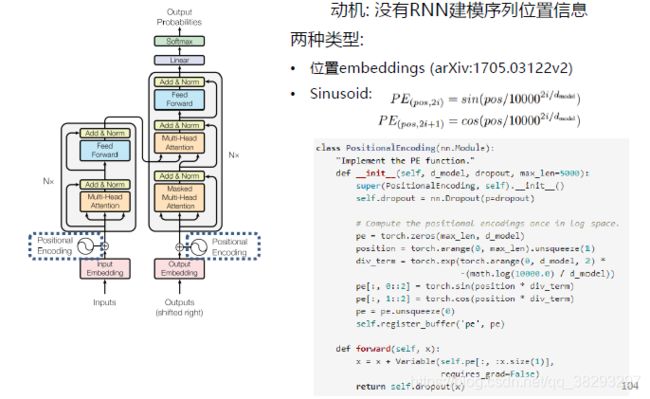
Transformer : Positional Encoding
5. “词”表示模型
5.1 神经语言模型
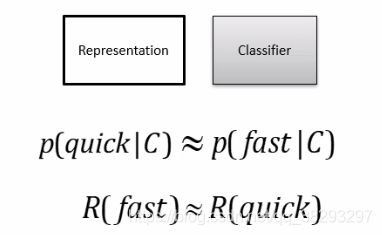
- 实际上,C是上下文表示,quick 是目标
- 那么可以用一个神经网络把上下文表示计算出来,然后利用另一个神经网络把这个目标预测出来。
- 最早的神经语言模型:Neural Network Language Model [Y.Bengio et al. 2003]
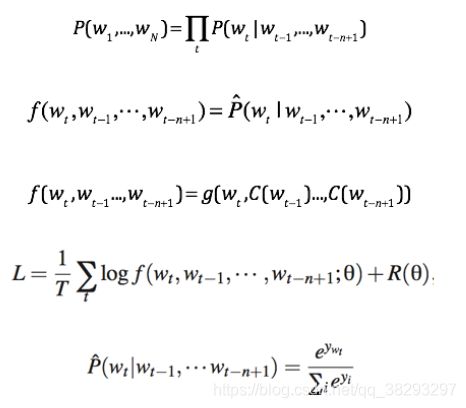
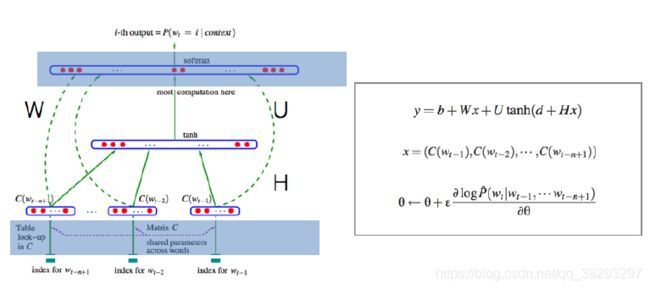
- 给定一个词,这个词的表示是固定的,通常的方式就是one-hot的形式,比如10000维,只有一个值为1;这个高维向量不变的,怎么转换成一个低维(比如100维)向量呢?
- 实际上是乘以一个10000*100 的矩阵,我们认为这个100维向量是词向量;实际上是原始的词表示乘以一个转换矩阵,变成了这个词的词向量。
- 这个转换矩阵是神经网络的参数,是可以调整的;词的原始表示是不变化的。
- 上图中间的长向量是我们的语义组合的方式拼接而成,然后利用这个语义组合做目标词的分类。
词表示
-
词表示是语言模型的副产品。在语言模型中,输入端我们需要把符号转换成一个向量的形式,输出端需要把隐藏状态转换成一个类标的形式。这两个部分其实都是词表示;对应输入部分的词向量我们称为主词向量,输出部分的词向量我们称为副词向量。
-
通过语言模型学习到的词向量比随即初始化要好得多。
- 词是语言处理中最基本的语言单元
- 词以及词间关系的表示和建模是NLP任务中重要的基础工作
-
词是语言处理中最方便处理的语言单元
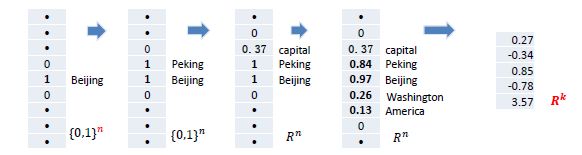
-
目标:语义相似的词表示相近
➢ 如何判定词语语义相似?
➢ 如何数值化表示词?
➢ 如何刻画数值表示的相近?
词表示学习
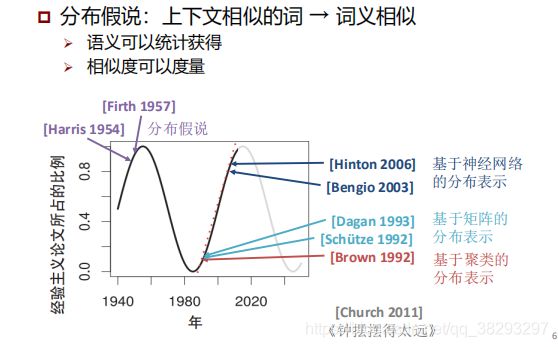
- 分布式假设:上下文相似的词 → 词义相似
- 语义可以统计获得
- 相似度可以度量
因此词表示学习中两个最重要的问题就是:
- 上下文的表示:文档、词、n元词组
- 相似度的衡量:向量的内积(余弦)

词表示方法
-
基于预测的方式
- 给定上下文对目标词进行预测
-
基于计数的方式
- 统计词-上下文共现情况,对共现矩阵进行分解
-
基于预测的方法:word2vec
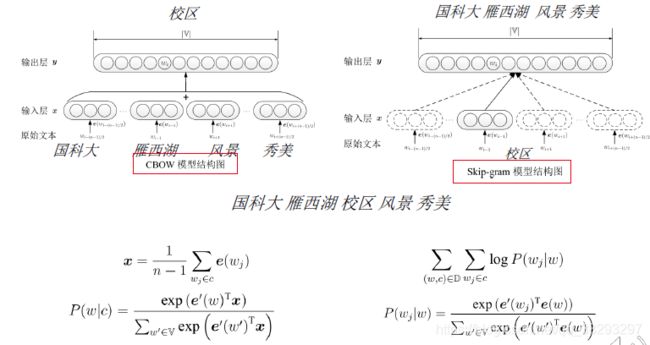
-
基于计数的方法:GloVe
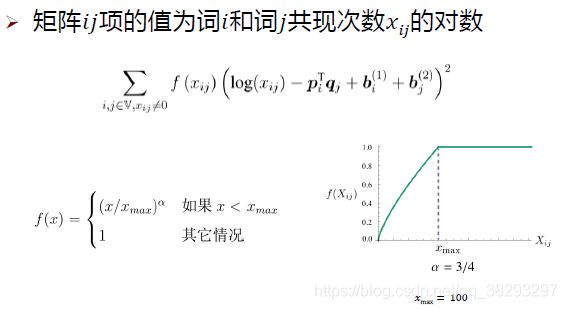
可以对每个词定义两套词向量,一个是 p i p_i pi:是第 i i i 个词所对应的输入层词向量; q j q_j qj:是第 j j j 个词所对应的输出层词向量 -
模型改进

-
技术改进
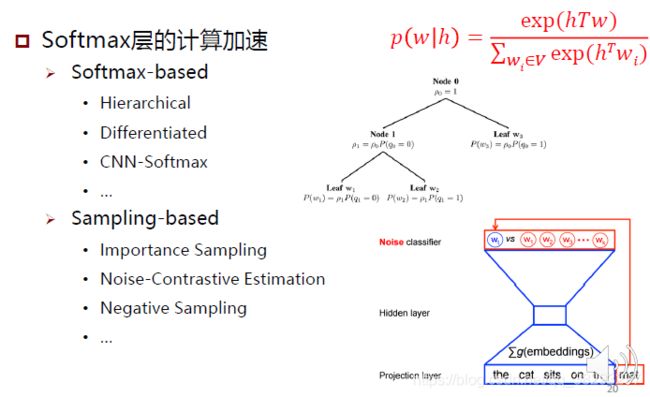
5.2 词向量2.0(word2vec)
词向量2.0的若干(实验)结论
- word2vec:计算换存储;GloVe:存储换计算
- 没有最好,只有适合
➢ 适合任务,用(任务的)领域内语料训练 - 确定合适领域的语料之后,语料越大越好
- 大语料,使用简单模型(CBOW)
- 小语料,使用复杂模型(Skip-gram)
- 使用任务相关的开发集,而非词向量的开发集
- 词的主向量/副向量 (主-副表示组合关系,主-主/副-副表示聚合关系)
词表示学习扩展
-
词表示学习扩展
➢ 多粒度:中文字词联合学习
➢ 多语言:跨语言词表示学习
➢ 异构:词、社交网络、知识图谱联合表示表示 -
词的构词法(内部结构)
➢ 江西省 vs. 四川省
➢ 星期六(星期+六)、皮鞋(皮+鞋)、教育(教+育)

…………
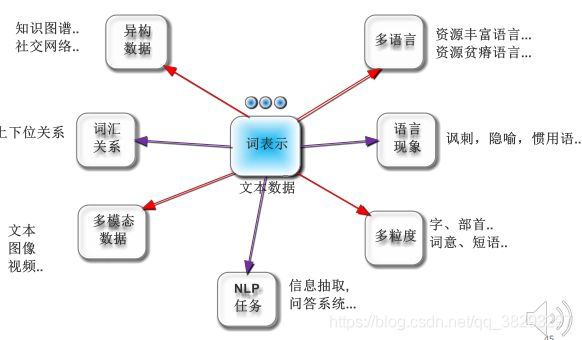
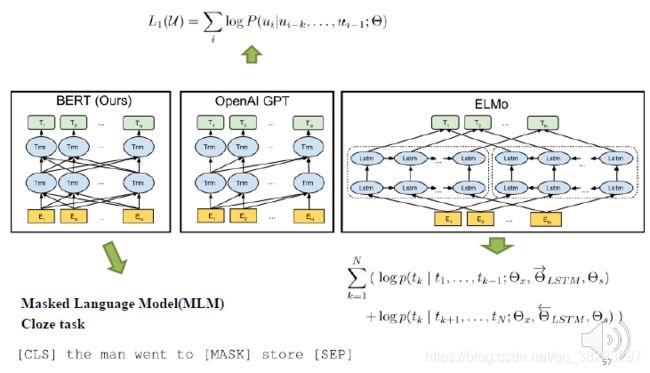
5.3 词向量3.0(ELMo、BERT)
预训练语言模型
- 非监督学习
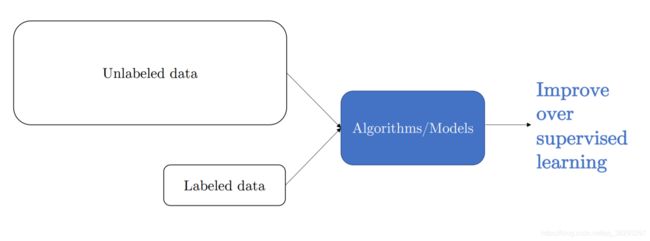
- 两阶段学习
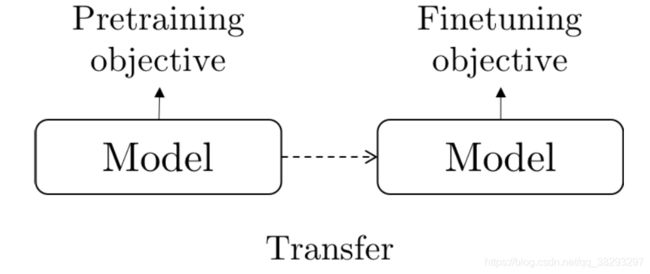
ELMo: Embeddings from Language Models

GPT: Generative Pre-Training
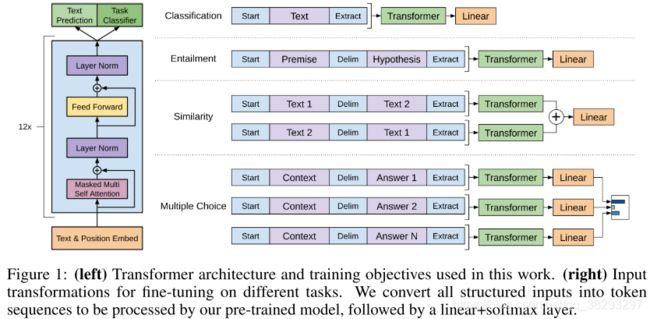
双向????
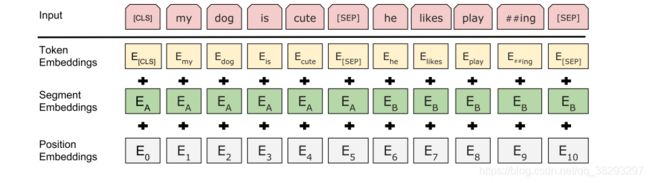
BERT的输入表示
预训练任务: Masked Language Model

预训练任务: Next Sentence Prediction

比较:ELmo、ULMFiT、GPT、BERT

6. 总结
- 看一下 ZEN:融合 N-gram 的中文编码表示