filebeat+elk搭建日志平台采集K8s容器应用日志
背景
当采用K8s技术容器化部署Springboot微服务应用时,程序打的日志只会保存在容器中,一旦重新部署销毁容器则日志就没了,而且每次要排查问题都需要上pod里,非常不友好。其次在高可用架构下,同个业务的日志必然分散在多个节点上,排查问题时需要反复横跳个pod,解决思路如下:
1.dockefile中通过VOLUME命令将应用程序日志目录挂载到宿主机上(也可以将filebeat和应用程序做到一个容器中,一是对容器编排不熟,二是CICD平台非自研无法进行此操作);
2.使用filebeat+elk收集日志;
1.前期准备
- elasticsearch-7.16
- logstach-7.16
- kibana-7.16
- filebeat-7.16
- CentOS7.9若干
filebeat+elk完全体如下:
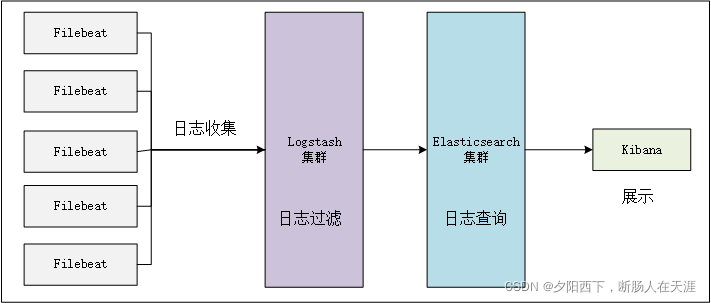
以下以单机版本为例。
如果是elk单机部署,则开放kibana和logstash的端口即可,如果是分布式部署则还需在对应的服务器上开放ES的端口;
# 开放Kibana 5601端口
firewall-cmd --zone=public --add-port=5601/tcp --permanent
# 开放Elasticsearch 9200端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent
# 开放logstash 5044端口
firewall-cmd --zone=public --add-port=5044/tcp --permanent
# 配置生效
firewall-cmd --reload
不开放端口会导致各组件之前无法通信访问、kibana无法访问等问题。
2.创建用户
es无法使用root账号启动,需要先创建一个用户。
# 创建用户
useradd elk
# 设置密码
passwd elk
# 切换用户
su elk
3.部署ES
- 上传下载好的ES包上传到服务器并解压
# 创建安装目录
mkdir /home/elk/es
# 创建es日志与数据目录
mkdir /home/elk/es/data
mkdir /home/elk/es/logs
cd /home/elk/es
# 通过FTP工具上传es安装包
# 解压
tar -xzvf elasticsearch-7.16.1-linux-x86_64.tar.gz
cd elasticsearch-7.16.1/
- 配置es
# 进入配置目录
cd config/
# 编辑配置文件
vim elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
#cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 节点名
node.name: node-01
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
# 运行数据目录
path.data: /home/elk/es/data
#
# Path to log files:
# 运行日志目录
path.logs: /home/elk/es/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
# 本节点IP
network.host: 192.168.0.1
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
# 开放通讯端口
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
# 集群节点
cluster.initial_master_nodes: ["node-01"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
- 修改用户能打开的文件数量以及能创建的进程数,不修改的话启动ES会报错。
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
soft xxx : 代表警告的设定,可以超过这个设定值,但是超过后会有警告。
hard xxx : 代表严格的设定,不允许超过这个设定的值。
nofile : 是每个进程可以打开的文件数的限制
nproc : 是操作系统级别对每个用户创建的进程数的限制
- 修改用户拥有的内存权限
vim /etc/sysctl.conf
vm.max_map_count=655360
vm.swappiness=0
- 使配置生效
/sbin/sysctl -p
- 启动es
cd /home/elk/es/elasticsearch-7.16.1
./bin/elasticsearch -d
- 验证es
curl http://192.168.0.1:9200
# 返回以下内容
{
"name" : "node-01",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "1GFsZK0mQO2OKagBncV1Jw",
"version" : {
"number" : "7.16.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "5b38441b16b1ebb16a27c107a4c3865776e20c53",
"build_date" : "2021-12-11T00:29:38.865893768Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
4.部署logstash
- 上传安装包以及创建安装目录
# 创建安装目录
mkdir /home/elk/logstash
cd /home/elk/logstash
#上传安装包
#解压
tar -xzvf logstash-7.16.1-linux-x86_64.tar.gz
# 进入安装目录
cd logstash-7.16.1/
- 配置logstash
因为logstash可以接受不同的数据来源,收集日志的工具也可能不是filebeat,所以这里最好是单独创建一个配置文件。
# 创建新的配置文件
mkdir config/conf.d
cd config/conf.d
# 创建配置文件
vim filebeat-logstash.yml
# logstash 开放5044端口接收filebeat收集的日志
input {
beats {
port => 5044
client_inactivity_timeout => 36000
}
}
# filebeat过来的日志会打上tag,用于标记区别日志来源;这里可以根据自己的需要进行过滤处理,并输出到指定的目的地;
output {
# 应用1的日志
if "app_1" in [tags] {
# 输出到es1
elasticsearch {
hosts => ["192.168.0.1:9200"]
# 给日志创建索引,es中依赖此索引进行查询
index => "app_1-%{+YYYY.MM.dd}"
}
}
# 应用2的日志
if "app_2" in [tags] {
# 输出到es2
elasticsearch {
hosts => ["xxx:9200"]
index => "app_2-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}
- 启动logstash
cd /home/elk/logstash/logstash-7.16.1/bin
# 后台启动
nohup ./logstash -f ../config/conf.d/filebeat-logstash.yml &
5.部署filebeat
- 在需要采集日志的服务器上创建filebeat安装目录,上传安装包。
# 解压
tar -xzvf filebeat-7.16.1-linux-x86_64.tar.gz
# 进入安装目录
cd filebeat-7.16.1-linux-x86_64/
- 配置 filebeat
vim filebeat.yml
###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
# ============================== Filebeat inputs ===============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
# 应用程序日志
- type: log
enabled: true
# 宿主机上日志目录,通过volumes映射下来的,通配符*用来动态查询
paths:
- /data/docker/volumes/*/_data/app-run-*.*
# 给日志打上标识,logstash中通过tag进行聚合与过滤
tags: ["app_1"]
# JAVA异常堆栈同行显示,不加这个的话堆栈的每一行都是一个新日志,太难看
multiline.pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
multiline.negate: false
multiline.match: after
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
#exclude_lines: ['^DBG']
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
#include_lines: ['^ERR', '^WARN']
# Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#prospector.scanner.exclude_files: ['.gz$']
# Optional additional fields. These fields can be freely picked
# to add additional information to the crawled log files for filtering
#fields:
# level: debug
# review: 1
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
# ================================== General ===================================
# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name:
# The tags of the shipper are included in their own field with each
# transaction published.
#tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging
# ================================= Dashboards =================================
# These settings control loading the sample dashboards to the Kibana index. Loading
# the dashboards is disabled by default and can be enabled either by setting the
# options here or by using the `setup` command.
#setup.dashboards.enabled: false
# The URL from where to download the dashboards archive. By default this URL
# has a value which is computed based on the Beat name and version. For released
# versions, this URL points to the dashboard archive on the artifacts.elastic.co
# website.
#setup.dashboards.url:
# =================================== Kibana ===================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
#host: "localhost:5601"
# Kibana Space ID
# ID of the Kibana Space into which the dashboards should be loaded. By default,
# the Default Space will be used.
#space.id:
# =============================== Elastic Cloud ================================
# These settings simplify using Filebeat with the Elastic Cloud (https://cloud.elastic.co/).
# The cloud.id setting overwrites the `output.elasticsearch.hosts` and
# `setup.kibana.host` options.
# You can find the `cloud.id` in the Elastic Cloud web UI.
#cloud.id:
# The cloud.auth setting overwrites the `output.elasticsearch.username` and
# `output.elasticsearch.password` settings. The format is `:`.
#cloud.auth:
# ================================== Outputs ===================================
# Configure what output to use when sending the data collected by the beat.
# ---------------------------- Elasticsearch Output ----------------------------
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
# ------------------------------ Logstash Output -------------------------------
# 日志输出到logstash
output.logstash:
# The Logstash hosts
hosts: ["192.168.0.1:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
path就是待收集的日志所在目录,支持通配符动态匹配。如果不是容器化部署,则直接指定日志目录即可!
在K8s部署应用场景下,通过volumes挂载的目录会随每次容器启动在挂载根目录下随机生成一个专属此容器的目录进行存储,因此只能采取通配符来匹配目录。
dockerfile中指定挂载目录
# 单个目录
VOLUME /usr/local/app_1/logs
# 多个目录,必须用双引号
VOLUME ["/tmplate","/usr/local/app_1/logs"]
通过以下命令查询容器volumes挂载宿主机的目录:
# 通过docker命令查询容器ID
docker ps | grep app_1
# 通过ID查询容器信息
docker inspect 8986c07082b4
# 找到 Mounts
"Mounts": [
{
"Type": "volume",
"Name": "cd4b267a0f325a0502c750c7eb2034fcbf504e6114517c982f3e1238a4c23a7d",
# 宿主机目录
"Source": "/data/docker/volumes/cd4b267a0f325a0502c750c7eb2034fcbf504e6114517c982f3e1238a4c23a7d/_data",
# 容器中的目录
"Destination": "/usr/local/app_1/logs",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
],
- 后台启动filebeat
./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
到此已完成日志从容器-》宿主机-》filebeat收集-》logstash过滤-》ES;
6.部署kibana
- 上传安装包,解压安装
# 解压
tar -xzvf kibana-7.16.1-linux-x86_64.tar.gz
cd kibana-7.16.1-linux-x86_64/
- 配置kibana
cd config/
vim kibana.yml
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "0.0.0.0"
# Enables you to specify a path to mount Kibana at if you are running behind a proxy.
# Use the `server.rewriteBasePath` setting to tell Kibana if it should remove the basePath
# from requests it receives, and to prevent a deprecation warning at startup.
# This setting cannot end in a slash.
#server.basePath: ""
# Specifies whether Kibana should rewrite requests that are prefixed with
# `server.basePath` or require that they are rewritten by your reverse proxy.
# This setting was effectively always `false` before Kibana 6.3 and will
# default to `true` starting in Kibana 7.0.
#server.rewriteBasePath: false
# Specifies the public URL at which Kibana is available for end users. If
# `server.basePath` is configured this URL should end with the same basePath.
#server.publicBaseUrl: ""
# The maximum payload size in bytes for incoming server requests.
#server.maxPayload: 1048576
# The Kibana server's name. This is used for display purposes.
server.name: "elk"
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://192.168.0.1:9200"]
# Kibana uses an index in Elasticsearch to store saved searches, visualizations and
# dashboards. Kibana creates a new index if the index doesn't already exist.
kibana.index: ".kibana"
# The default application to load.
#kibana.defaultAppId: "home"
- 启动kibana
nohup /home/elk/kibana/kibana-7.16.1-linux-x86_64/bin/kibana &
- 访问kibana
http://192.168.0.1:5601/
8.查看已收集的日志文档


在Kibana -> Stack Management -> 索引管理中查询所有已收集到的日志索引。
9.索引模式
创建索引模式,对索引进行聚合,用于查询。

通过通配符形式进行匹配,对索引进行聚合。例如:创建索引模式为app*,则所有以app开头的索引都会被命中。
索引模式创建后,可以修改下@timestamp 字段的格式,默认的时间格式太难识别了。改为日期纳秒,YYYY-MM-DD HH:mm:s.SS

10.查询日志
选择目标索引模式,可以通过关键字、字段、时间范围来查询,常用的关键字查询可以使用and、or这类逻辑语法来筛选查询结果;字段查询中常用的host.ip可以过滤出来自指定ip的日志内容。