淘宝MySQL数据库高可用实现方案
一、常见的高可用MySQL解决方案
高性能性需要解决的主要有两个问题,即如何实现数据共享或同步数据,另一个是如何处理failover,数据共享一般的解决方案是通过SAN(Storage Area Network)来实现,而数据同步可以通过rsync软件或DRBD技术来实现;failover的意思就是当服务器死机或出现错误时可以自动切换到其他备用的服务器,不影响服务器上业务系统的运行。这里重点介绍一下目前比较成熟的Mysql高性能解决方案。
1、主从复制解决方案
这是MySQL自身提供的一种高可用解决方案,数据同步方法采用的是MySQL replication技术。MySQL replication就是一个日志的复制过程,在复制过程中一个服务器充当主服务器,而一个或多个其他服务器充当从服务器,简单说就是从服务器到主服务器拉取二进制日志文件,然后再将日志文件解析成相应的SQL在从服务器上重新执行一遍主服务器的操作,通过这种方式保证数据的一致性。
MySQL replication技术仅仅提供了日志的同步执行功能,而从服务器只能提供读操作,并且当主服务器故障时,必须通过手动来处理failover,通常的做法是将一台从服务器更改为主服务器。这种解决方案在一定程度上实现了MySQL的高可用性,可以实现90.000%的SLA。
为了达到更高的可用性,在实际的应用环境中,一般都是采用MySQL replication技术配合高可用集群软件来实现自动failover,这种方式可以实现95.000%的SLA。本课程会重点介绍通过KeepAlived结合MySQL replication技术实现MySQL高可用构架的解决方案。
高性能性需要解决的主要有两个问题,即如何实现数据共享或同步数据,另一个是如何处理failover,数据共享一般的解决方案是通过SAN(Storage Area Network)来实现,而数据同步可以通过rsync软件或DRBD技术来实现;failover的意思就是当服务器死机或出现错误时可以自动切换到其他备用的服务器,不影响服务器上业务系统的运行。这里重点介绍一下目前比较成熟的Mysql高性能解决方案。
主从复制架构图:
2、Heartbeat/SAN、DRBD高可用解决方案
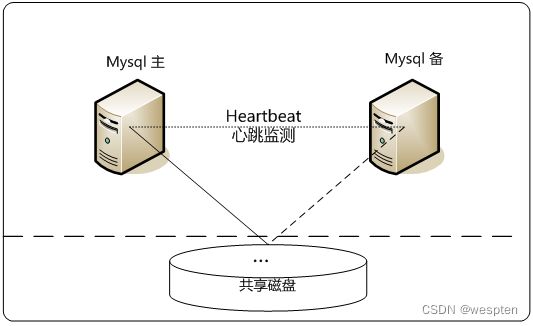
此方案是借助于第三方的软、硬件实现的,在这个方案中,处理failover的方式是高可用集群软件Heartbeat,它监控和管理各个节点间连接的网络,并监控集群服务,当节点出现故障或者服务不可用时,自动在其他节点启动集群服务。
在数据共享方面,可以通过SAN(Storage Area Network)存储来共享数据,在正常状态下,集群主节点将挂载存储进行数据读写,而当集群发生故障时,Heartbeat会首先通过一个仲裁设备将主节点挂载的存储设备释放,然后在备用节点上挂载存储,接着启动服务,通过这种方式实现数据的共享和同步。这种数据共享方式实现简单,但是成本较高,并且存在脑裂的可能,需要根据实际应用环境来选择。这种方案可以实现99.990%的SLA。
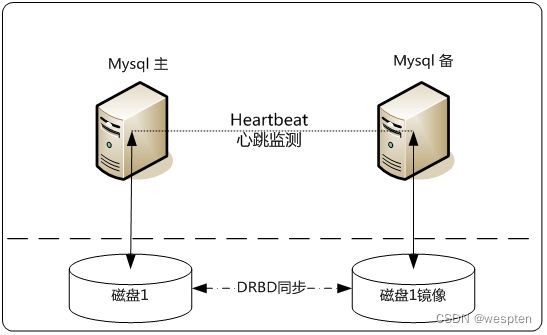
另外,在数据共享方面,还可以采用基于块级别的数据同步软件DRBD来实现。DRBD即Distributed Replicated Block Device,是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。和SAN网络不同,它并不共享存储,而是通过服务器之间的网络复制数据。这种方案实现起来稍微复杂,同时也存在脑裂的问题。可以实现99.900%的SLA。
两种不同存储架构图:
3、PXC集群解决方案
Percona XtraDB Cluster(PXC) 是MySQL高可用性和可扩展性的解决方案。并且与MySQL Server社区版本、Percona Server和MariaDB 兼容。
Percona XtraDB Cluster提供的特性有:
1. 同步复制,事务要么在所有节点提交或不提交。
2. 多主复制,可以在任意节点进行写操作。
3. 在从服务器上并行应用事件,真正意义上的并行复制。
4. 节点自动配置。
5. 数据一致性,不再是异步复制。
优点如下:
1.当执行一个查询时,在本地节点上执行。因为所有数据都在本地,无需远程访问。
2.无需集中管理。可以在任何时间点失去任何节点,但是集群将照常工作。
3.良好的读负载扩展,任意节点都可以查询。
缺点如下:
1.加入新节点,开销大。需要复制完整的数据。
2.不能有效的解决写缩放问题,所有的写操作都将发生在所有节点上。
3.有多少个节点就有多少重复的数据。
4、节点之间的复制(replication)仅支持InnoDB引擎。
5、所有的表都要有主键。锁冲突、死锁问题相对较多。
Percona XtraDB Cluster与MySQL Replication区别在于:
分布式系统的CAP理论。
C---一致性,所有节点的数据一致。
A---可用性,一个或多个节点失效,不影响服务请求。
P---分区容忍性,节点间的连接失效,仍然可以处理请求。
任何一个分布式系统,需要满足这三个中的两个。
MySQL Replication: 可用性和分区容忍性;
Percona XtraDB Cluster: 一致性和可用性;
因此MySQL Replication并不保证数据的一致性,而Percona XtraDB Cluster提供数据一致性。
4、MHA高可用解决方案
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA优势如下:
1. 故障切换快;
2. master故障不会导致数据不一致;
3. 无需修改当前的MySQL设置;
4. 无性能下降;
5. 适用于任何存储引擎;
二、通过KeepAlived搭建MySQL双主模式的高可用集群系统
1、MySQL Replication介绍
MySQL Replication是MySQL自身提供的一个主从复制功能,其实也就是一台MySQL服务器(称为Slave)从另一台MySQL服务器(称为Master)上复制日志,然后再解析日志并应用到自身的过程。MySQL Replication是单向、异步复制,基本复制过程为:Master服务器首先将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志的循环。这些日志文件可以发送到Slave服务器进行更新。当一个Slave服务器连接Master服务器时,它从Master服务器日志中读取上一次成功更新的位置。然后Slave服务器开始接收从上一次完成更新后发生的所有更新,所有更新完成,将等待主服务器通知新的更新。
MySQL Replication支持链式复制,也就是说Slave服务器下还可以再链接Slave服务器,同时Slave服务器也可以充当Master服务器角色。这里需要注意的是,在MySQL主从复制中,所有表的更新必须在Master服务器上进行,Slave服务器仅能提供查询操作。
MySQL Replication支持多种类型的复制方式,常见的有基于语句的复制、基于行的复制和混合类型的复制。
下面进行分别介绍:
1)基于语句的复制
MySQL默认采用基于语句的复制,效率很高。基本方式是:在Master服务器上执行的SQL语句,在Slave服务器上再次执行同样的语句。而一旦发现没法精确复制时,会自动选择基于行的复制。
2)基于行的复制
基本方式为:把Master服务器上改变的内容复制过去,而不是把SQL语句在从服务器上执行一遍, 从mysql5.0开始支持基于行的复制。
3)混合类型的复制
其实就是上面两种类型的组合,默认采用基于语句的复制,如果发现基于语句的复制无法精确的完成,就会采用基于行的复制。
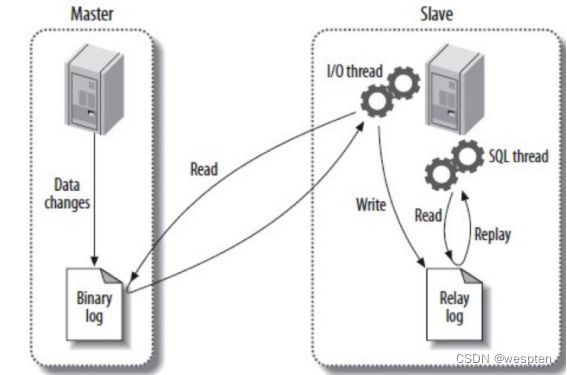
2、MySQL Replication实现原理
MySQL Replication是一个从Master复制到一个或多个Slave的、异步的过程,在Master与Slave之间实现整个复制过程主要由三个线程来完成,其中一个IO线程在Master端,另两个线程(Sql线程和IO线程)在Slave端。
要实现Mysql Replication,首先要在Master服务器上打开MySQL的Binary Log(产生二进制日志文件)功能,因为整个复制过程实际上就是Slave从Master端获取该日志,然后在自身上将二进制文件解析为SQL语句并完全顺序的执行SQL语句所记录的各种操作。
更详细的过程如下:
1)首先Slave上的IO线程连接上Master,然后请求从指定日志文件的指定位置或者从最开始的日志位置之后的日志内容。
2)Master在接收到来自Slave的IO线程请求后,通过自身的IO线程,根据请求信息读取指定日志位置之后的日志信息,并返回给Slave端的IO线程。返回信息中除了日志所包含的信息之外,还包括此次返回的信息在Master端对应的Binary Log文件的名称以及在Binary Log中的位置。
3)Slave的IO线程接收到信息后,将获取到的日志内容依次写入Slave端的Relay Log文件(类似于mysql-relay-bin.xxxxxx)的最后,并且将读取到的Master端的Binary Log的文件名和位置记录到一个名为master-info文件中,以便在下一次读取的时候能够迅速定位从哪个位置开始往后读取日志信息。
4)Slave的SQL线程在检测到Relay Log文件中新增加了内容后,会马上解析该Relay Log文件中的内容,将日志内容解析为SQL语句,然后在自身执行这些SQL,由于是在Master端和Slave端执行了同样的SQL操作,所以两端的数据是完全一样的。至此整个复制过程结束。
3、MySQL Replication常用架构
MySQL Replication技术在实际应用中有多种实现架构,常见的有:
1)一主一从,即一个Master服务器和一个Slave服务器。这是最常见的架构。
2)一主多从,即一个Master服务器和两个或两个以上Slave服务器。经常用在写操作不频繁、查询量比较大的业务环境中。
3)主主互备,又称双主互备,即两个MySQL Server互相将对方作为自己的Master,自己又同时作为对方的Slave来进行复制。主要用于对MySQL写操作要求比较高的环境中,避免了MySQL单点故障。
4)双主多从,其实就是双主互备,然后再加上多个Slave服务器。主要用于对MySQL写操作要求比较高,同时查询量比较大的环境中。
其实可以根据具体的情况灵活地将Master/Slave结构进行变化组合,但万变不离其宗,在进行Mysql Replication各种部署之前,有一些必须遵守的规则:
1)同一时刻只能有一个Master服务器进行写操作。
2)一个Master服务器可以有多个Slave服务器。
3)无论是Master服务器还是Slave服务器,都要确保各自的Server ID唯一,不然双主互备就会出问题。
4)一个Slave服务器可以将其从Master服务器获得的更新信息传递给其他的Slave服务器。依此类推。
4、MySQL主主互备模式架构图
主要设计思路是通过MySQL Replication技术将两台MySQL Server互相将对方作为自己的Master,自己又同时作为对方的Slave来进行复制。这样就实现了高可用构架中的数据同步功能,同时,将采用KeepAlived来实现Mysql的自动failover。
在这个构架中,虽然两台MySQL Server互为主从,但同一时刻只有一个MySQL Server可读写,另一个MySQL Server只能进行读操作,这样可保证数据的一致性。

MySQL主从复制的配置还是比较简单的,仅仅需要修改MySQL配置文件即可,这里要配置的是主主互备模式,但配置过程和一主一从结构是完全一样的,配置环境如下所示:
| 主机名 |
操作系统版本 |
MySQL版本 |
主机IP |
MySQL VIP |
| DB1(Master) |
CentOS release 7.4 |
mysql-5.7.20 |
192.168.88.11 |
192.168.88.10 |
| DB2(Slave) |
CentOS release 7.4 |
mysql-5.7.20 |
192.168.88.12 |
1. 修改MySQL配置文件
在默认情况下MySQL的配置文件是/etc/my.cnf,首先修改DB1主机的配置文件,在/etc/my.cnf文件中的“[mysqld]”段添加如下内容:
server-id = 1
log-bin=mysql-bin
relay-log = mysql-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%然后修改DB2主机的配置文件,在/etc/my.cnf文件中的“[mysqld]”段添加如下内容:
server-id = 2
log-bin=mysql-bin
relay-log = mysql-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%
其中,server-id是节点标识,主、从节点不能相同,必须全局唯一。log-bin表示开启MySQL的binlog日志功能。“mysql-bin”表示日志文件的命名格式,会生成文件名为mysql-bin.000001、mysql-bin.000002等的日志文件。relay-log用来定义relay-log日志文件的命名格式。
replicate-wild-ignore-table是个复制过滤选项,可以过滤掉不需要复制的数据库或表,例如“mysql.%“表示不复制mysql库下的所有对象,其他依此类推。与此对应的是replicate_wild_do_table选项,用来指定需要复制的数据库或表。
这里需要注意的是,不要在主库上使用binlog-do-db或binlog-ignore-db选项,也不要在从库上使用replicate-do-db或replicate-ignore-db选项,因为这样可能产生跨库更新失败的问题。推荐在从库上使用replicate_wild_do_table和replicate-wild-ignore-table两个选项来解决复制过滤问题。
2. 手动同步数据库
如果DB1上已经有mysql数据,那么在执行主主互备之前,需要将DB1和DB2上两个mysql的数据保持同步,首先在DB1上备份mysql数据,执行如下SQL语句:
mysql>FLUSH TABLES WITH READ LOCK;
Query OK, 0 rows affected (0.00 sec)不要退出这个终端,否则这个锁就失效了。在不退出终端的情况下,再开启一个终端直接打包压缩数据文件或使用mysqldump工具来导出数据。这里通过打包mysql文件来完成数据的备份,操作过程如下:
[root@DB1 ~]# cd /var/lib/
[root@DB1 lib]# tar zcvf mysql.tar.gz mysql
[root@DB1 lib]# scp mysql.tar.gz DB2:/var/lib/将数据传输到DB2后,依次重启DB1和DB2上面的mysql。
3. 创建复制用户并授权
首先在DB1的mysql库中创建复制用户:
grant replication slave on *.* to 'repl_user'@'192.168.88.%' identified by 'repl_passwd';
show master status;然后在DB2的mysql库中将DB1设为自己的主服务器:
change master to master_host='192.168.88.11',master_user='repl_user',master_password='repl_passwd',master_log_file='mysql-bin.000001',master_log_pos=120;这里需要注意master_log_file和master_log_pos两个选项,这两个选项的值刚好是在DB1上通过SQL语句“show master status”查询到的结果。
接着就可以在DB2上启动slave服务了,可执行如下SQL命令:
mysql> start slave; 在DB2上查看slave的运行状态,如果看出Slave_IO_Running和Slave_SQL_Running都是Yes状态,表明DB2上复制服务运行正常,到这里位置,从DB1到DB2的mysql主从复制已经完成了。接下来开始配置从DB2到DB1的mysql主从复制,这个配置过程与上面的完全一样。
接着在DB2的mysql库中创建复制用户:
grant replication slave on *.* to 'repl_user'@'192.168.88.%' identified by 'repl_passwd';
show master status;然后在DB1的mysql库中将DB2设为自己的主服务器:
change master to master_host='192.168.88.12',master_user='repl_user',master_password='repl_passwd',master_log_file='mysql-bin.000001',master_log_pos=120;最后,就可以在DB1上启动slave服务了,可执行如下SQL命令:
mysql> start slave; 下面查看下DB1上slave的运行状态,如果看出Slave_IO_Running和Slave_SQL_Running都是Yes状态,表明DB1上复制服务运行正常。
至此,mysql双主模式的主从复制已经配置完毕了。
5、配置KeepAlived实现MySQL双主高可用
在进行高可用配置之前,首先需要在DB1和DB2服务器上安装KeepAlived软件。关于KeepAlived会在后面课程做详细介绍,这里主要关注下KeepAlived的安装和配置,安装过程如下:
[root@keepalived-master app]# yum install -y gcc gcc-c++ wget popt-devel openssl openssl-devel
[root@keepalived-master app]#yum install -y libnl libnl-devel libnl3 libnl3-devel
[root@keepalived-master app]#yum install -y libnfnetlink-devel
[root@keepalived-master app]#tar zxvf keepalived-1.4.3.tar.gz
[root@keepalived-master app]# cd keepalived-1.4.3
[root@keepalived-master keepalived-1.4.3]#./configure --sysconf=/etc
[root@keepalived-master keepalived-1.4.3]# make
[root@keepalived-master keepalived-1.4.3]# make install
[root@keepalived-master keepalived-1.4.3]# systemctl enable keepalived安装完成后,进入keepalived的配置过程。默认配置文件位于/etc/keepalived/keepalived.conf。
6、测试MySQL主从同步功能
为了验证mysql的复制功能,可以编写一个简单的程序进行测试,也可以通过远程客户端登录进行测试。这里通过一个远程mysql客户端,然后利用mysql的VIP地址登录,看是否能登录,并在登录后进行读、写操作,看看DB1和DB2之间是否能够实现数据同步。
由于是远程登录测试,因此DB1和DB2两台MySQL服务器都要事先做好授权,允许从远程登录。
1. 在远程客户端通过VIP登录测试;
2. 数据复制功能测试;
7、测试KeepAlived实现MySQL故障转移
为了测试KeepAlived实现的故障转移功能,需要模拟一些故障,比如,可以通过断开DB1主机的网络、关闭DB1主机、关闭DB1上mysql服务等各种操作实现,这里在DB1服务器上关闭mysql的日志接收功能,以此来模拟DB1上mysql的故障。由于在DB1和DB2服务器上都添加了监控mysql运行状态的脚本check_slave.pl,因此当关闭DB1的mysql日志接收功能后,KeepAlived会立刻检测到,接着执行切换操作。
1. 停止DB1服务器的日志接收功能;
2. 在远程客户端测试;
三、Mysql集群架构MHA应用实战
1、MHA的概念和原理
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。
官网:https://code.google.com/p/mysql-master-ha/
https://downloads.mariadb.com/MHA/
MHA架构图:
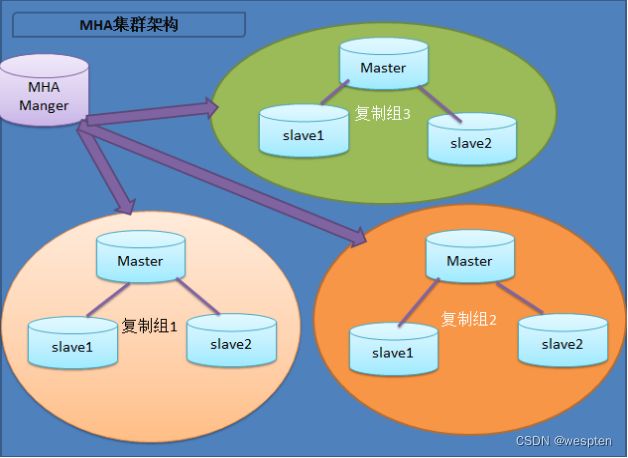
2、MHA的组成和恢复过程
Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
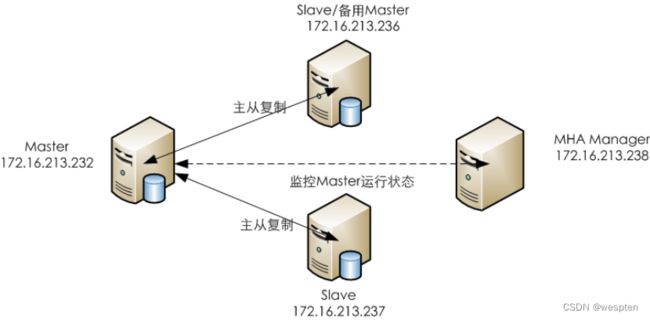
MHA集群架构:
3、mysql主从复制环境配置
1. 环境说明
接下来部署MHA,具体的搭建环境如下(所有操作系统均为centos7.4,mysql5.7.20):
| 角色 |
IP地址 |
主机名 |
Server_id |
类型 |
| Master |
172.16.213.232 |
232server |
1 |
写入 |
| Slave/备选master |
172.16.213.236 |
236server |
2 |
读 |
| Slave |
172.16.213.237 |
237server |
3 |
读 |
| MHAManager |
172.16.213.238 |
238server |
无 |
监控复制组 |
其中master对外提供写服务,备选master(实际的slave,主机名236server)提供读服务,237server也提供相关的读服务,一旦master宕机,MHA将会把备选master提升为新的master,slave节点237server也会自动修改复制地址为新的master地址。
2. 配置三个节点的ssh互信
在三个mysql节点分别执行如下操作,这里以232server为例:
[root@232server ~]# ssh-keygen -t rsa
[root@232server ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@232server ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@232server ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]最后测试三个节点之间是否可以无密码登录:
[root@232server ~]#ssh 172.16.213.236 date最后在manager节点执行如下操作:
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
3. 安装三个节点的mysql数据库
4. 配置三个节点主从关系
在3个mysql节点的my.cnf文件中添加如下内容:
server-id = 1
read-only=1
log-bin=mysql-bin
relay-log = mysql-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%其中,server-id每个节点各不相同。
5. 在3个mysql节点做授权配置6.
mysql>grant replication slave on *.* to 'repl_user'@'172.16.213.%' identified by 'repl_passwd';
mysql>grant all on *.* to 'root'@'172.16.213.%' identified by '123456'; 6. 开启主从同步
首选启动三个节点的mysql服务,然后在master节点执行如下命令:
mysql> show master status;找到master节点对应的binlog日志文件名和编号,并记录下来。这里是mysql-bin.000019和120。
接着,在两个slave节点执行入下同步操作:
mysql> change master to master_host='172.16.213.232',master_user='repl_user',master_password='repl_passwd',master_log_file='mysql-bin.000019',master_log_pos=120;执行完成后,分别在两个slave节点启动slave服务:
mysql> start slave;如果mysql是安装在/usr/local/mysql路径下,那么还需要做如下操作:
ln -s /usr/local/mysql/bin/* /usr/bin/4、MHA的安装与配置
1. 安装MHA软件
MHA提供了源码和rpm包两种安装方式,这里推荐使用rpm包安装方式,安装过程如下:
在三个节点依次安装MHA的node:
yum install perl-DBD-mysql
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm最后在MHA Manager节点上安装mha4mysql-manage:
yum install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Config-IniFiles perl-Time-HiRes
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm2. 配置MHA集群
MHA安装完成后,可在/etc/mha目录下手动创建一个文件,用来作为MHA的主配置文件,文件名称任意即可,这里创建了一个app1.cnf文件。
1)MHA主配置文件
MHA主配置文件/etc/mha/app1.cnf常用配置选项内容如下:
[server default]
user=root
password=123456
ssh_user=root
repl_user=repl_user
repl_password=repl_passwd
ping_interval=1
secondary_check_script = masterha_secondary_check -s 172.16.213.235 #master_ip_failover_script="/etc/mha/scripts/master_ip_failover"
#master_ip_online_change_script="/etc/mha/scripts/master_ip_online_change"
#shutdown_script= /script/masterha/power_manager
report_script="/etc/mha/scripts/send_report"
manager_log=/var/log/mha/app1/manager.log
manager_workdir=/var/log/mha/app1
[server1]
candidate_master=1
hostname=172.16.213.232
master_binlog_dir="/db/data"
[server2]
candidate_master=1
hostname=172.16.213.236
master_binlog_dir="/db/data"
check_repl_delay=0
[server3]
hostname=172.16.213.237
master_binlog_dir="/db/data"
no_master=1
对每个配置选项含义介绍如下:
user:默认root,表示MySQL的用户名,MHA要通过此用户执行很多命令如:STOP SLAVE, CHANGE MASTER, RESET SLAVE等。
password:user的密码,如果指定了mysql用户为root,那么这里就是root用户的密码。
ssh_user:操作系统的用户名(Manager节点和mysql主从复制节点),因为要应用,解析各种日志,推荐使用root用户,默认是MHA manager上当前用户。
repl_user:Mysql主从复制线程的用户名(最好加上)
repl_password:Mysql主从复制线程的密码(最好加上)。
ping_interval:MHA通过 ping SQL的方式监控master状态,此选项用来设置MHA manager多久去检查一次master,默认3秒,如果三次间隔都没反应,那么MHA就会认为master已经出现问题了。如果MHA Manager连不上Master是因为连接数过多错误或者认证失败,此时MHA将不会认为master出问题。
secondary_check_script:默认情况下,MHA通过单个路由(即从Manager到Master)来检查Master的可用性,这种默认的监控机制不够完善,不过,MHA还提供了一个监控master的接口,那就是通过调用secondary_check_script参数,通过定义外部脚本来实现多路由监测。
例如:
secondary_check_script = masterha_secondary_check -s remote_host1 -s remote_host2其中,masterha_secondary_check是MHA提供的一个监测脚本,remote_host1、remote_host2是远程的两台主机,建议不要和MHA manager主机在同一个网段中。
masterha_secondary_check脚本的监测机制是:
Manager-(A)->remote_host1-(B)->master_host
Manager-(A)->remote_host2-(B)->master_host监测脚本会首先通过Manager主机检测到远程主机的网络状态,这个过程是A,接着,再通过远程主机检查到master_host的状态,这个过程为B。
在过程A中,Manager主机需要通过ssh连接到远程的机器上,所以需要manager主机到远程机器上建立public key信任。在过程B中,masterha_secondary_check是通过远程主机和Master建立TCP连接来测试Master是否存活的。
在所有的路由中,如果A成功,B失败,那么MHA才认为master出现了问题,进而执行failover操作,其它情况,一律认为master是正常状态。也就是不会进行failover操作。一般来讲,强烈推荐使用多个网络上的机器,通过不同路由策略来检查MySQL Master存活状态。
master_ip_failover_script:此选项用来设置VIP漂移动作,默认MHA不会做VIP漂移,但可以通过master_ip_failover_script来指定一个VIP漂移脚本,MHA源码包中自带了一个VIP漂移脚本master_ip_failover,稍加修改就能使用,后面会介绍这个脚本的使用。
master_ip_online_changes_script:这个参数有点类似于master_ip_failover_script,但这个参数不用于master故障转意,而是master在线的切换,使用masterha_master_switch命令手动切换MySQL主服务器时后会调用此脚本。
shutdown_script:设置故障发生后关闭故障主机的脚本(该脚本的主要作用是关闭主机,防止发生脑裂),此脚本是利用服务器的远程控制IDRAC等,使用ipmitool强制去关机,以避免fence设备重启主服务器,造成脑列现象。
report_script:用来设置当新主服务器切换完成以后通过此脚本发送邮件报告。
manager_workdir:MHA Manager的工作目录,默认: /var/tmp
manager_log:MHA manager的日志目录,如果不设置,就是标准输出,和标准错误输出。
master_binlog_dir:master上产生binlog日志对应的binlog目录。默认是:/var/lib/mysql,这里是"/db/data"。
check_repl_delay:默认情况下,如果slave落后master 100M左右的relay log,MHA会放弃选择这个slave作为new master。但是,如果设置check_repl_delay=0,MHA会忽略这个限制,如果想让某个candidate_master=1特定的slave成为maseter,那么这个参数特别有用。
candidate_master:候选master,如果设置为1,那么这台机器被选举为新master的机会就越大(还要满足:binlog开启,无大延迟)。如果你设置了N台机器都为candidate_master=1,那么优先选举的顺序为从上到下。
no_master:如果对某台机器设置了no_master=1 , 那么这台机器永远都不可能成为新master,如果没有master选举了,那么MHA会自动退出。
ignore_fail:默认情况下,如果slave有问题(无法通过mysql,ssh连接,sql线程停止等等),MHA 将停止failover,如果不想让MHA manager停止,可以设置ignore_fail=1。
2)MHA的master_ip_failover文件
MHA没有vip漂移的功能,要实现VIP的自动漂移,需要一个脚本来完成,MHA manager会调用master_ip_failover_script三次,我们可以在MHA主配置文件通过添加master_ip_failover_script选项指定一个脚本来实现VIP的自动漂移功能。
MHA在源码包中自带了一个实现VIP自动漂移的脚本master_ip_failover,但默认这个脚本无法使用,需要做一些修改,修改后的master_ip_failover脚本内容如下:
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '172.16.213.239/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig enp0s8:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig enp0s8:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}5、测试MHA环境以及常见问题总结
MHA提供了两个工具用来验证MHA环境配置的正确性,可通过masterha_check_ssh和masterha_check_repl两个命令来验证。
通过masterha_check_ssh验证ssh信任登录是否配置成功:
masterha_check_ssh --conf=/etc/mha/app1.cnfmasterha_check_repl验证mysql主从复制是否配置成功:
masterha_check_repl --conf=/etc/mha/app1.cnf6、启动与管理MHA
先在当前的master节点执行如下命令:
root@232server app1]# /sbin/ifconfig eth0:1 172.16.213.239 此操作只需第一次执行,用来将vip绑定到目前的master节点上,当MHA接管了mysql主从复制后,就无需执行此操作了。所有VIP的漂移都有MHA来完成。
然后通过masterha_manager启动MHA监控:
[root@238server app1]#nohup masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover < /dev/null > /tmp/manager_error.log 2>&1 &启动参数介绍:
--ignore_last_failover:在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件。
默认情况下,MHA发生切换后会在MHA工作目录产生类似app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后删除该文件,为了方便,这里设置”--ignore_last_failover“参数。
--remove_dead_master_conf:设置了这个参数后,如果MHA failover结束后,MHA Manager会自动在配置文件中删除dead master的相关项,如果不设置,由于dead master的配置还存在文件中,那么当MHA failover后,当再次restart MHA manager后,会报错(there is a dead slave previous dead master)。
/tmp/manager_error.logs是存放MHA运行过程中的一些警告或错误信息。
可以通过masterha_check_status查看MHA状态,命令如下:
[root@238server app1]# masterha_check_status --conf=/etc/mha/app1.cnf
masterha_default (pid:29007) is running(0:PING_OK), master:172.16.213.232要关闭MHA Manage监控,可使用masterha_stop命令完成,命令如下:
[root@238server app1]# masterha_stop --conf=/etc/mha/app1.cnf
Stopped app1 successfully.
[1]+ Exit 1 nohup masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover < /dev/null > /tmp/manager_error.log 2>&1 &
7、MHA集群切换测试
1. 自动Failover
要实现自动Failover,必须先启动MHA Manager,否则无法自动切换,当然手动切换不需要开启MHA Manager监控。
A、杀掉主库mysql进程,模拟主库发生故障,进行自动failover操作。
B、看MHA切换日志,了解整个切换过程。
从Failover的输出可以看出整个MHA的切换过程,共包括以下的步骤:
1、.配置文件检查阶段,这个阶段会检查整个集群配置文件配置;
2、.宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作;
3、.复制dead maste和最新slave相差的relay log,并保存到MHA Manger具体的目录下;
4、.识别含有最新更新的slave;
5、.应用从master保存的二进制日志事件(binlog events);
6、提升一个slave为新的master进行复制;
7、使其他的slave连接新的master进行复制;
切换完成后,关注如下变化:
1、vip自动从原来的master切换到新的master,同时,manager节点的监控进程自动退出。
2、在日志目录(/var/log/mha/app1)产生一个app1.failover.complete文件。
3、如果启动mha manager时,添加了--remove_dead_master_conf参数,那么/etc/mha/app1.cnf配置文件中原来老的master配置会被删除。
2. 手动Failover(MHA Manager必须没有运行)
手动failover,这种场景意味着在业务上没有启用MHA自动切换功能,当主服务器故障时,人工手动调用MHA来进行故障切换操作,进行手动切换命令如下:
[root@iivey app1]# masterha_master_switch --master_state=dead --conf=/etc/mha/app1.cnf \
--dead_master_host=172.16.213.232 --dead_master_port=3306 \
--new_master_host=172.16.213.236 --new_master_port=3306 --ignore_last_failover注意:如果,MHA manager检测到没有dead的server,将报错,并结束failover:
Mon Apr 21 21:23:33 2018 - [info] Dead Servers:
Mon Apr 21 21:23:33 2018 - [error][/usr/local/share/perl5/MHA/MasterFailover.pm, ln181] None of server is dead. Stop failover.
Mon Apr 21 21:23:33 2018 - [error][/usr/local/share/perl5/MHA/ManagerUtil.pm, ln178] Got ERROR: at /usr/local/bin/masterha_master_switch line 533. MHA master在线切换
MHA在线切换是MHA除了自动监控切换换提供的另外一种方式,多用于诸如硬件升级,MySQL数据库迁移等等。该方式提供快速切换和优雅的阻塞写入,无需关闭原有服务器,整个切换过程在0.5-2s 的时间左右,大大减少了停机时间。
[root@iivey app1]# masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=172.16.213.232 --orig_master_is_new_slave --running_updates_limit=10000 --interactive=0MHA在线切换基本步骤:
1、检测MHA配置置及确认当前master;
2、决定新的master;
3、阻塞写入到当前master;
4、等待所有从服务器与现有master完成同步;
5、在新master授予写权限,以及并行切换从库;
6、重置原master为新master的slave;
4. 如何将故障节点重新加入集群
通常情况下自动切换以后,原master可能已经废弃掉,待原master主机修复后,如果数据完整的情况下,可能想把原来master重新作为新主库的slave,这时可以借助当时自动切换时刻的MHA日志来完成对原master的修复。
1)修改manager配置文件
将如下内容添加到/etc/mha/app1.conf中:
[server1]
candidate_master=1
hostname=172.16.213.232
master_binlog_dir="/db/data"2)修复老的master,然后设置为slave
从自动切换时刻的MHA日志上可以发现类似如下信息:
Sat May 27 14:59:17 2018 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.16.213.236', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000009', MASTER_LOG_POS=120, MASTER_USER='repl_user', MASTER_PASSWORD='xxx';意思是说,如果Master主机修复好了,可以在修复好后的Master上执行CHANGE MASTER操作,作为新的slave库。
接着,在老的master执行如下命令:
mysql>CHANGE MASTER TO MASTER_HOST='172.16.213.236', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000009', MASTER_LOG_POS=120, MASTER_USER='repl_user' MASTER_PASSWORD=repl_passwd;
mysql>start slave;
mysql> show slave status\G;这样,数据就开始同步到老的master上了。此时老的master已经重新加入集群,变成mha集群中的一个slave角色了。
3)在manger节点上重新启动监控进程
nohup masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover < /dev/null > /etc/mha/app1/logs/manager_error.log 2>&1 &
8、使用MHA需要注意的问题
1、Failover切换之后会产生一个app1.failover.complete文件,如果要进行第二次Failover测试,需要手工删除app1.failover.complete。另一种方法是通过--ignore_last_failover参数来忽略,例如:
masterha_master_switch --master_state=dead --conf=/etc/mha/app1.cnf --dead_master_host=172.16.213.236 --dead_master_port=3306 --new_master_host=172.16.213.232 --new_master_port=3306 --ignore_last_failover2、一旦发生一次切换后,mha manager监控进程将会退出,无法继续进行监控,要再次开启监控,需将原故障数据库重新加入到MHA环境中来,然后设置为slave。最后再次在mha manager上开启对master的监控进程。
3、原主节点重新加入到MHA时只能设置为slave,并且需要执行:
change master to MASTER_HOST='172.16.213.236', MASTER_USER='replicationuser',MASTER_PASSWORD='replicationuser',MASTER_LOG_FILE='mysql-bin.000004',MASTER_LOG_POS=106;上面的change信息可从mha切换日志中获取到。
4、关于ip地址的接管有几种方式,这里采用的是MHA自动调用ip别名的方式,好处是在能够保证数据库状态与业务Ip 切换的一致性。启动管理节点之后 vip会自动别名到当前主节点上。
四、通过ProxySQL实现Mysql读、写分离
1、常见的Mysql中间件
很多人都会把中间件认为是读写分离,其实读写分离只是中间件可以提供的一种功能,最主要的功能还是在于他可以分库分表。
DBProxy:是由美团点评公司技术工程部DBA团队(北京)开发维护的一个基于MySQL协议的数据中间层。它在奇虎360公司开源的Atlas基础上,修改了部分bug,并且添加了很多特性。
Atlas:是由奇虎360公发的基于MySQL协议的数据库中间件产品,它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了若干Bug,并增加了很多功能特性。目前该产品在360内部得到了广泛应用。
Cobar:阿里巴巴B2B开发的关系型分布式系统,管理将近3000个MySQL实例。 在阿里经受住了考验,后面由于作者的走开的原因cobar没有人维护 了,阿里也开发了tddl替代cobar。
MyCAT:社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活跃度很高,目前已经有一些公司在使用MyCAT。总体来说支持度比较高,也会一直维护下去。
MySQL Route:是现在MySQL 官方Oracle公司发布出来的一个中间件。
2、proxySQL简介
ProxySQL是一个高性能的、高可用性MySQL中间件,优点如下:
1)几乎所有的配置均可在线更改(其配置数据基于SQLite存储),无需重启proxysql;
2)强大的规则路由引擎,支持读写分离、查询重写、sql流量镜像;
3)详细的状态统计,相当于有了统一的查看sql性能和sql语句统计的入口;
4)自动重连和重新执行机制,若一个请求在链接或执行过程中意外中断,proxysql会根据其内部机制重新执行该操作;
5)query cache功能:比mysql自带QC更灵活,可多维度控制哪类语句可以缓存;
6)支持连接池(connection pool);
7)支持分库、分表;
8)支持负载均衡;
9)自动下线后端DB,根据延迟超过阀值、ping 延迟超过阀值、网络不通或宕机都会自动下线节点;
3、proxySQL的下载与安装
1. 下载proxySQL
proxySQL的官网是http://www.proxysql.com/ ,可以从官网提供的github下载:
Releases · sysown/proxysql · GitHub
也可以在percona站点进行下载,地址如下:Download ProxySQL
目前最新的proxySQL版本是proxysql-1.4.8。
2. 安装
proxySQL提供了源码包和rpm包两种安装方式,这里选择rpm方式进行安装,过程如下:
[root@proxysql mysql]# yum install perl-DBD-mysql
[root@proxysql mysql]# rpm -ivh proxysql-1.4.8-1-centos7.x86_64.rpm3. proxySQL的目录结构
ProxySQL安装好的数据目录在/var/lib/proxysql/,配置文件目录是/etc/proxysql.cnf。启动脚本是/etc/init.d/proxysql。
启动proxysql之后,在/var/lib/proxysql/下面可以看到如下文件:
proxysql.db:此文件是SQLITE的数据文件,proxysql配置,如后端数据库的账号、密码、路由等存储在这个数据库里面。
proxysql.log:此文件是日志文件。
proxysql.pid:此文件是是进程pid文件。
需要注意的是:proxysql.cnf是ProxySQL的一些静态配置项,用来配置一些启动选项,sqlite的数据目录等等。此配置文件只在第一次启动的时候读取进行初始化,后面只读取proxysql.db文件。
ProxySQL在启动后,会启动管理端口和客户端端口,可以在配置文件/etc/proxysql.cnf中看到管理和客户端的端口信息,默认管理的端口是6032,账号和密码都是admin,后面可以动态修改,并且管理端口只能通过本地连接;客户端默认端口是6033,账号和密码可以通过管理接口去进行设置。
4、proxySQL库表功能介绍
1. 库、表说明
首先启动proxysql ,执行如下命令:
[root@proxysql app1]# /etc/init.d/proxysql start
Starting ProxySQL: DONE!然后登录proxysql的管理端口6302,执行如下操作:
[root@proxysql app1]# mysql -uadmin -padmin -h127.0.0.1 -P6032
MySQL [(none)]> show databases;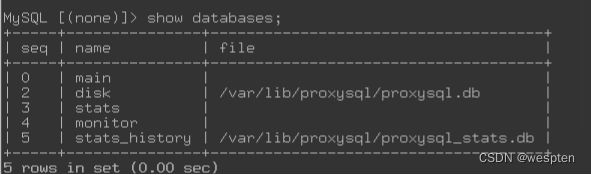
main:内存配置数据库,表里存放后端db实例、用户验证、路由规则等信息。表名以 runtime_开头的表示proxysql当前运行的配置内容,不能通过dml语句修改,只能修改对应的不以 runtime_ 开头的(在内存)里的表,然后LOAD使其生效, SAVE使其存到硬盘以供下次重启加载。
disk:是持久化到硬盘的配置,对应/var/lib/proxysql/proxysql.db文件,也就是sqlite的数据文件。
stats:是proxysql运行抓取的统计信息,包括到后端各命令的执行次数、流量、processlist、查询种类汇总/执行时间等等。
monitor:库存储 monitor模块收集的信息,主要是对后端db的健康、延迟检查。
2. main库
MySQL [(none)]> show tables from main;常用的几个表介绍如下:
global_variables:设置变量,包括监听的端口、管理账号等。
mysql_replication_hostgroups:监视指定主机组中所有服务器的read_only值,并且根据read_only的值将服务器分配给写入器或读取器主机组。ProxySQL monitor模块会监控hostgroups后端所有servers的read_only变量,如果发现从库的read_only变为0、主库变为1,则认为角色互换了,自动改写mysql_servers表里面hostgroup关系,达到自动Failover效果。
mysql_servers:设置后端MySQL的表。
mysql_users:配置后端数据库的程序账号和监控账号。
scheduler:调度器是一个类似于cron的实现,集成在ProxySQL中,具有毫秒的粒度。通过脚本检测来设置ProxySQL。
3. stats库
MySQL [(none)]> show tables from stats;常用的几个表介绍如下:
stats_mysql_commands_counters:统计各种SQL类型的执行次数和时间,通过参数mysql-commands_stats控制开关,默认是ture。
stats_mysql_connection_pool:连接后端MySQL的连接信息。
stats_mysql_processlist:类似MySQL的show processlist的命令,查看各线程的状态。
stats_mysql_query_digest:表示SQL的执行次数、时间消耗等。通过变量mysql-query_digests控制开关,默认是开。
stats_mysql_query_rules:路由命中次数统计。
4. monitor库
MySQL [(none)]> show tables from monitor;常用的几个表介绍如下:
mysql_server_connect_log:连接到所有MySQL服务器以检查它们是否可用,该表用来存放检测连接的日志。
mysql_server_ping_log:使用mysql_ping API ping后端MySQL服务器,检查它们是否可用,该表用来存放ping的日志。
mysql_server_replication_lag_log:后端MySQL服务主从延迟的检测。
5、ProxySQL的运行机制
ProxySQL有一个完备的配置系统,配置ProxySQL是基于sql命令的方式完成的。ProxySQL支持配置修改之后的在线保存、应用,不需要重启即可生效。整个配置系统分三层设计。
整个配置系统分为三层,如下所示:
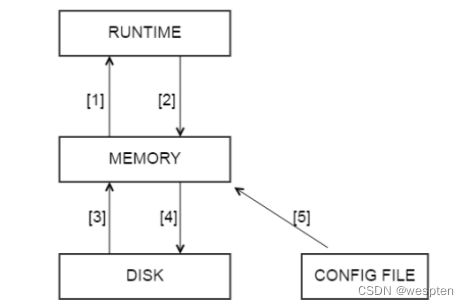
配置系统分为三层的目的有三个:
1)自动更新;
2)尽可能的不重启proxysql就可以修改配置;
3)方便回滚错误配置;
每层的功能与含义如下:
RUNTIME层:代表的是ProxySQL当前生效的正在使用的配置,包括global_variables, mysql_servers, mysql_users, mysql_query_rules表。无法直接修改这里的配置,必须要从下一层load进来。也就是说RUNTIME这个顶级层,是proxysql运行过程中实际使用的那一份配置,这一份配置会直接影响到生产环境的,所以要将配置加载进RUNTIME层时需要三思而行。
MEMORY层:用户可以通过MySQL客户端连接到此接口(admin接口),然后可以在mysql命令行查询不同的表和数据库,并修改各种配置,可以认为是SQLite数据库在内存的镜像。也就是说MEMORY这个中间层,上面接着生产环境层RUNTIME,下面接着持久化层DISK和CONFIG FILE。
MEMORY层是我们修改proxysql的唯一正常入口。一般来说在修改一个配置时,首先修改Memory层,确认无误后再接入RUNTIME层,最后持久化到DISK和CONFIG FILE层。也就是说memeory层里面的配置随便改,不影响生产,也不影响磁盘中保存的数据。通过admin接口可以修改mysql_servers、mysql_users、mysql_query_rules、global_variables等表的数据。
DISK/CONFIG FILE层: 表示持久存储的那份配置,持久层对应的磁盘文件是$(DATADIR)/proxysql.db,在重启ProxySQL的时候,会从proxysql.db文件中加载信息。而 /etc/proxysql.cnf文件只在第一次初始化的时候使用,之后如果要修改配置,就需要在管理端口的SQL命令行里进行修改,然后再save到硬盘。 也就是说DISK和CONFIG FILE这一层是持久化层,我们做的任何配置更改,如果不持久化下来,重启后,配置都将丢失。
需要注意的是:proxysql的每一个配置项在三层中都存在,但是这三层是互相独立的,也就是说,proxysql可以同时拥有三份配置,每层都是独立的,可能三份配置都不一样,也可能三份都一样。
下面总结下proxysql的启动过程:
当proxysql启动时,首先读取配置文件CONFIG FILE(/etc/proxysql.cnf),然后从该配置文件中获取datadir,datadir中配置的是sqlite的数据目录。如果该目录存在,且sqlite数据文件存在,那么正常启动,将sqlite中的配置项读进内存,并且加载进RUNTIME,用于初始化proxysql的运行。
如果datadir目录下没有sqlite的数据文件,proxysql就会使用config file中的配置来初始化proxysql,并且将这些配置保存至数据库。sqlite数据文件可以不存在,/etc/proxysql.cnf文件也可以为空,但/etc/proxysql.cnf配置文件必须存在,否则,proxysql无法启动。
6、ProxySQL下添加与修改配置
1. 添加配置
需要添加配置时,直接操作的是MEMORAY,例如:添加一个程序用户,在mysql_users表中执行一个插入操作:
MySQL [(none)]> insert into mysql_users(username,password,active,default_hostgroup,transaction_persistent) values('myadmin','mypass',1,0,1);要让这个insert生效,还需要执行如下操作:
MySQL [(none)]>load mysql users to runtime; 表示将修改后的配置(MEMORY层)用到实际生产环境(RUNTIME层)。
如果想保存这个设置永久生效,还需要执行如下操作:
MySQL [(none)]>save mysql users to disk;表示将memoery中的配置保存到磁盘中去。
除了上面两个操作,还可以执行如下操作:
MySQL [(none)]>load mysql users to memory;表示将磁盘中持久化的配置拉一份到memory中来。
MySQL [(none)]>load mysql users from config;表示将配置文件中的配置加载到memeory中。
2. 加载或保存配置
以上SQL命令是对mysql_users进行的操作,同理,还可以对mysql_servers表、mysql_query_rules表、global_variables表等执行类似的操作。
如对mysql_servers表插入完成数据后,要执行保存和加载操作,可执行如下SQL命令:
MySQL [(none)]> load mysql servers to runtime;
MySQL [(none)]> save mysql servers to disk;对mysql_query_rules表插入完成数据后,要执行保存和加载操作,可执行如下SQL命令:
MySQL [(none)]> load mysql query rules to runtime;
MySQL [(none)]> save mysql query rules to disk;对global_variables表插入完成数据后,要执行保存和加载操作,可执行如下SQL命令:
以下命令加载或保存mysql variables(global_variables):
MySQL [(none)]>load mysql variables to runtime;
MySQL [(none)]>save mysql variables to disk;以下命令加载或保存admin variables(select * from global_variables where variable_name like 'admin-%'):
MySQL [(none)]> load admin variables to runtime;
MySQL [(none)]> save admin variables to disk;
五、proxySQL+MHA构建高可用mysql读写分离架构
1、proxySQL+MHA应用架构
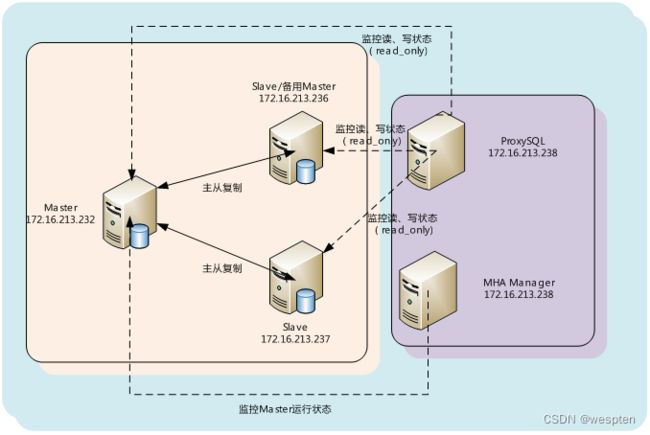
2、部署环境说明
具体的搭建环境如下(所有操作系统均为centos7.4,mysql5.7.20、proxySQL1.4.8):
| 角色 |
IP地址 |
主机名 |
Server_id |
类型 |
| Master |
172.16.213.232 |
232server |
1 |
写入 |
| Slave/备选master |
172.16.213.236 |
236server |
2 |
读 |
| Slave |
172.16.213.237 |
237server |
3 |
读 |
| MHAManager/proxysql |
172.16.213.238 |
238server |
无 |
监控复制组/mysql中间件 |
此架构分为两个部分,分别是MHA集群和proxysql中间件,MHA架构保持不变,在MHA基础上新增了proxySQL这个mysql代理软件,也就是通过proxySQL来访问MHA集群,因此,之前在MHA中介绍的VIP漂移机制就可以去掉了,web端程序的访问都直接访问proxySQL的IP地址即可,proxySQL可自动实现代理到MHA集群的访问。
3、配置后端MySQL
登入ProxySQL,把MySQL主从的信息添加进去。将主库master也就是做写入的节点放到HG 0中,salve节点做读放到HG 1。在proxysql输入命令:
mysql -uadmin -padmin -h127.0.0.1 -P6032
MySQL [(none)]>insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment) values(0,'172.16.213.232',3306,1,1000,10,'test my proxysql');
MySQL [(none)]>insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment) values(1,'172.16.213.236',3306,1,2000,10,'test my proxysql');
MySQL [(none)]>insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment) values(1,'172.16.213.237',3306,1,2000,10,'test my proxysql');
MySQL [(none)]>select * from mysql_servers;4、配置后端MySQL用户
这个用户需要先在后端每台MySQL里真实存在,一个是监控账号、一个是程序账号。
1)监控账号(用来监控后端mysql是否存活以及read_only变量):
GRANT SUPER, REPLICATION CLIENT ON *.* TO 'proxysql'@'172.16.213.%' IDENTIFIED BY 'proxysql';2)程序账号(这里为了后面测试方便给了all权限):
GRANT ALL ON *.* TO 'myadmin'@'172.16.213.%' IDENTIFIED BY 'mypass';5、proxysql中添加程序账号
1)proxysql中添加程序连接账号
在后端MySQL里添加完用户之后再配置ProxySQL:这里需要注意,default_hostgroup需要和上面的对应。
MySQL [(none)]> insert into mysql_users(username,password,active,default_hostgroup,transaction_persistent) values('myadmin','mypass',1,0,1);
MySQL [(none)]>select * from mysql_users;2)proxysql中添加健康监测账号
MySQL [(none)]>set mysql-monitor_username='proxysql';
MySQL [(none)]> set mysql-monitor_password='proxysql';
6、加载配置和变量
因为修改了servers、users和variables,所以加载的时候要执行:
MySQL [(none)]>load mysql servers to runtime;
MySQL [(none)]>load mysql users to runtime;
MySQL [(none)]>load mysql variables to runtime;
MySQL [(none)]>save mysql servers to disk;
MySQL [(none)]>save mysql users to disk;
MySQL [(none)]>save mysql variables to disk;
7、连接数据库并写入数据
通过proxysql的客户端接口访问(6033):
/usr/local/mysql/bin/mysql -h172.16.213.238 -umyadmin -pmypass -P6033
mysql>show databases;
mysql> use cmsdb;
mysql> select count(*) from cstable;
mysql> insert into cstable select * from wp_options;可以看到创建了表,并且插入了数据,查询也没问题。
proxysql有个类似审计的功能,可以查看各类SQL的执行情况。在proxysql执行SQL查看。
MySQL [(none)]> select * from stats_mysql_query_digest;8、定义路由规则
要实现读写分离,就需要定义路由规则,proxysql运行用户自定义路由规则,这个非常灵活,路由规则支持正则表达式,设置如下规则,实现读写分离:
1)select * from tb for update的语句发往master节点
2)以select开头的sql全部发送到slave
3)除去上面的规则,其它sql语句全部发送到master。
这些规则具体到proxysql数据库,应该执行如下sql语句:
MySQL [(none)]>INSERT INTO mysql_query_rules(active,match_pattern,destination_hostgroup,apply) VALUES(1,'^SELECT.*FOR UPDATE$',0,1);
MySQL [(none)]>INSERT INTO mysql_query_rules(active,match_pattern,destination_hostgroup,apply) VALUES(1,'^SELECT',1,1);插入自定义规则后,执行下面sql,使规则生效:
MySQL [(none)]>load mysql query rules to runtime;
MySQL [(none)]>save mysql query rules to disk;
MySQL [(none)]>select rule_id,active,match_pattern,destination_hostgroup,apply from runtime_mysql_query_rules;如果觉得stats_mysql_query_digest表内容过多,可通过如下sql语句清理掉之前的统计信息:
MySQL [(none)]>select * from stats_mysql_query_digest_reset;读、写分离规则生效后,再次通过6033端口运行读、写sql语句,然后再次查看读写分离状态表,发现已经实现读写分离,如下所示:
MySQL [(none)]> select * from stats_mysql_query_digest;
9、proxysql整合MHA
如何配合MHA实现高可用呢?那么需要利用到proxysql里面的mysql_replication_hostgroups表。mysql_replication_hostgroups 表的主要作用是监视指定主机组中所有服务器的read_only值,并且根据read_only的值将服务器分配给写入器或读取器主机组,定义 hostgroup 的主从关系。
ProxySQL monitor 模块会监控 HG 后端所有servers 的 read_only 变量,如果发现从库的 read_only 变为0、主库变为1,则认为角色互换了,自动改写 mysql_servers 表里面 hostgroup 关系,达到自动 Failover 效果。
MySQL [(none)]> insert into mysql_replication_hostgroups (writer_hostgroup,reader_hostgroup,comment)values(0,1,'测试读写分离高可用');
MySQL [(none)]> load mysql servers to runtime;
MySQL [(none)]> save mysql servers to disk;
MySQL [(none)]> select * from runtime_mysql_replication_hostgroups;
六、DRBD+Keepalived+Mysql+Amoeba双主双从高可用集群
1、项目实验拓扑图

2、DRBD简介
1. DRBD的概述
Distributed Replicated Block Device是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。其核心功能通过Linux的内核实现,比文件系统更加靠近操作系统内核及IO栈。
drbd 共有两部分组成:内核模块和用户空间的管理工具。
DRBD是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备,可以把它看作是一种网络RAID,它允许用户在远程机器上建立一个本地块设备的实时镜像。
2. DRBD的角色
主:在主 DRBD 设备中可以进行不受限制的读和写的操作,他可用来创建和挂载文件系统、初始化或者是直接 I/O 的快设备。
备:接收所有来自对等节点的更新,不能被应用也不能被读写访问。主要目的是保持缓冲及数据一致性。人工干预和管理程序的自动聚类算法都可以改变资源的角色。资源可以由被变换为主,以及主到备。
3. DRBD原理图
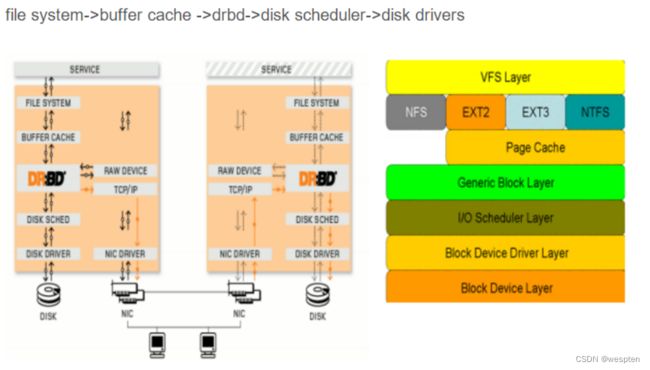
4. DRBD的特点
实时性:当某个应用程序完成对数据的修改时,复制功能立即发生。
透明性:应用程序的数据存储在镜像块设备上是独立透明的,他们的数据在两个节点上都保存一份,因此,无论哪一台服务器宕机,都不会影响应用程序读取数据的操作,所以说是透明的。
5. DRBD的同步方式
同步镜像:表示当应用程序提交本地的写操作后,数据后会同步写到两个节点上去。
异步镜像:表示当应用程序提交写操作后,只有当本地的节点上完成写操作后,另一个节点才可以完成写操作。
6. DRBD的工作模式
单主模式:任何资源在任何特定的时间,集群中只存在一个主节点。 正是因为这样在集群中,只能有一个节点可以随时操作数据,这种模式可用在任何的文件系统上( EXT3、 EXT4、 XFS等等)。
双主模式:在双主模式下(drbd8.0后支持),任何资源在任何特定的时间,集群中都存在两个主节点。犹豫双方数据存在并发的可能性,这种模式需要一个共享的集群文件系统,利用分布式的锁机制进行管理,如 GFS 和OCFS2。部署双主模式时, DRBD 是负载均衡的集群,这就需要从两个并发的主节点中选取一个首选的访问数据。这种模式默认是禁用的,如果要是用的话必须在配置文件中进行声明。
7. DRBD的同步协议
协议 A:本地完成写入,且数据包已在发送队列中,则认为写入完成。在一 个节点发生故障时,可能发生数据丢失,常用与物理上分开的节点。
协议 B:本地完成写入,并收到远程主机的收到数据确认后,则认为写入完成。在两个节点同时发生故障时,可能发生数据丢失。因为在数据传输过程中, 数据未必能提交到磁盘。
协议 C:本地完成写入,并收到远程主机的写入确认后,则认为写入完成,没有任何数据丢失,因此这是最常用的模式。
3、项目环境
| 系统类型 |
IP地址 |
主机名 |
所需软件 |
| Centos 7.4 1708 64bit |
192.168.100.101 |
master1 |
mysql-5.6.36.tar.gz drbd84-utils kmod-drbd84 drbd84-utils-sysvinit ntp |
| Centos 7.4 1708 64bit |
192.168.100.102 |
master2 |
mysql-5.6.36.tar.gz drbd84-utils kmod-drbd84 drbd84-utils-sysvinit ntpdate |
| Centos 7.4 1708 64bit |
192.168.100.103 |
slave1 |
mysql-5.6.36.tar.gz ntpdate |
| Centos 7.4 1708 64bit |
192.168.100.104 |
slave2 |
mysql-5.6.36.tar.gz ntpdate |
| Centos 7.4 1708 64bit |
192.168.100.105 |
amoeba |
amoeba-mysql-binary-2.2.0.tar.gz jdk-6u14-linux-x64.bin |
| Centos 7.4 1708 64bit |
192.168.100.106 |
client |
mysql |
4、项目实验步骤
- 部署master1节点的ntp服务以及域名解析;
- 配置master2、slave1、slave2节点同步ntp时间及域名解析(在此只列举master2单台主机配置);
- 分别在master1、master2、slave1、slave2节点上安装mysql服务(在此只列举master1单台主机配置);
- 分别在master1、master2节点上drbd服务(在此只列举master1单台主机配置);
- 配置优化master1、master2节点的drbd服务(在此只列举master1单台主机配置);
- 在master1、master2两个节点准备drbd的磁盘(在此只列举master1单台主机配置);
- 在master1主节点上进行初始化drbd的块设备并且进行测试挂载;
- 在master2从节点上测试挂载drbd块设备;
- 配置 master1节点的mysql服务数据文件的存放位置为 drbd 块设备的挂载点;
- 使用master2节点测试查看mysql中数据;
- 安装master1、master2节点的keepalived服务;
- 配置master1节点上master主节点;
- 配置master 2节点上backup从节点;
- 配置master1节点keepalived服务切换DRBD块设备;
- 配置master1、master2节点上的主从复制;
- 配置slave1节点的主从复制;
- 配置slave2节点的主从复制;
- 验证master1节点、slave1节点、slave2节点的主从复制;
- 安装amoeba数据库代理程序;
- 配置master1节点授权amoeba节点连接数据库集群;
- 修改amoeba节点的配置文件并启动测试;
- 客户端访问测试主从复制;
- 客户端访问测试读写分离;
- 关闭master1节点,测试双主热备情况;
1. 部署master1节点的ntp服务以及域名解析
[root@master1 ~]# cat <>/etc/hosts
192.168.100.101 master1
192.168.100.102 master2
192.168.100.103 slave1
192.168.100.104 slave2
END
[root@master1 ~]# yum -y install ntp
[root@master1 ~]# sed -i '/^server/s/^/#/g' /etc/ntp.conf
[root@master1 ~]# cat <>/etc/ntp.conf
server 127.127.1.0
fudge 127.127.1.0 stratum 8
END
[root@master1 ~]# systemctl start ntpd
[root@master1 ~]# systemctl enable ntpd
Created symlink from /etc/systemd/system/multi-user.target.wants/ntpd.service to /usr/lib/systemd/system/ntpd.service. 2. 配置master2、slave1、slave2节点同步ntp时间及域名解析(在此只列举master2单台主机配置)
[root@master2 ~]# cat <>/etc/hosts
192.168.100.101 master1
192.168.100.102 master2
192.168.100.103 slave1
192.168.100.104 slave2
END
[root@master2 ~]# yum -y install ntpdate
[root@master2 ~]# /usr/sbin/ntpdate 192.168.100.101
ech 9 Aug 18:04:38 ntpdate[1106]: adjust time server 192.168.100.101 offset 0.299673 sec
[root@master2 ~]# echo "/usr/sbin/ntpdate 192.168.100.101">>/etc/rc.local
[root@master2 ~]# chmod +x /etc/rc.local 3. 分别在master1、master2、slave1、slave2节点上安装mysql服务(在此只列举master1单台主机配置)
[root@master1 ~]# yum -y install ncurses cmake
[root@master1 ~]# mount /dev/cdrom /mnt/
mount: /dev/sr0 写保护,将以只读方式挂载
[root@master1 ~]# rpm -ivh /mnt/Packages/ncurses-devel-5.9-13.20130511.el7.x86_64.rpm --nodeps
[root@master1 ~]# ls
mysql-5.6.36.tar.gz
[root@master1 ~]# tar zxvf mysql-5.6.36.tar.gz -C /usr/src/
[root@master1 ~]# cd /usr/src/mysql-5.6.36/
[root@master2 mysql-5.6.36]# cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_ARCHIVE_STORAGE_ENGINE=1 -DWITH_BLACKHOLE_STORAGE_ENGINE=1 -DENABLE_DOWNLOADS=1
[root@master1 mysql-5.6.36]# make
[root@master1 mysql-5.6.36]# make install
[root@master1 mysql-5.6.36]# cd
[root@master1 ~]# cp /usr/src/mysql-5.6.36/support-files/mysql.server /etc/init.d/
[root@master1 ~]# chmod +x /etc/init.d/mysql.server
[root@master1 ~]# cat <>/usr/lib/systemd/system/mysqld.service
[Unit]
Description=mysqldapi
After=network.target
[Service]
Type=forking
PIDFile=/usr/local/mysql/logs/mysqld.pid
ExecStart=/etc/init.d/mysql.server start
ExecReload=/etc/init.d/mysql.server restart
ExecStop=/etc/init.d/mysql.server stop
PrivateTmp=Flase
[Install]
WantedBy=multi-user.target
END
[root@master1 ~]# echo "export PATH=$PATH:/usr/local/mysql/bin/" >>/etc/profile
[root@master1 ~]# source /etc/profile
[root@master1 ~]# groupadd mysql
[root@master1 ~]# useradd -g mysql mysql
[root@master1 ~]# cat </etc/my.cnf
[mysqld]
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
port = 3306
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
character_set_server=utf8
init_connect='SET NAMES utf8'
log-error=/usr/local/mysql/logs/mysqld.log
pid-file=/usr/local/mysql/logs/mysqld.pid
skip-name-resolve
END
[root@master1 ~]# mkdir /usr/local/mysql/logs
[root@master1 ~]# chown mysql:mysql /usr/local/mysql/ -R
[root@master1 ~]# /usr/local/mysql/scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
[root@master1 ~]# systemctl start mysqld
[root@master1 ~]# systemctl enable mysqld
Created symlink from /etc/systemd/system/multi-user.target.wants/mysqld.service to /usr/lib/systemd/system/mysqld.service.
[root@master1 ~]# netstat -utpln |grep 3306
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 31481/mysqld
[root@master1 ~]# mysqladmin -uroot password 123123
Warning: Using a password on the command line interface can be insecure.
[root@master1 ~]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
mysql> exit 4. 分别在master1、master2节点上drbd服务(在此只列举master1单台主机配置)
[root@master1 ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@master1 ~]# yum -y install epel-release
[root@master1 ~]# yum -y install perl-TimeDate kernel-devel kernel-headers flex resource-agents
[root@master1 ~]# rpm -ivh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
[root@master1 ~]# yum install -y drbd84-utils kmod-drbd84 drbd84-utils-sysvinit5. 配置优化master1、master2节点的drbd服务(在此只列举master1单台主机配置)
[root@master1 ~]# cp /usr/lib/modules/3.10.0-862.el7.x86_64/extra/drbd84/drbd.ko /lib/modules/$(uname -r)/kernel/lib
[root@master1 ~]# depmod
[root@master1 ~]# cat /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
[root@master1 ~]# cp /etc/drbd.d/global_common.conf{,-$(date +%s)}
[root@master1 ~]# ls /etc/drbd.d/
global_common.conf global_common.conf-1533828130
[root@master1 ~]# vi /etc/drbd.d/global_common.conf
global {
usage-count yes;
}
common {
startup {
wfc-timeout 120;
degr-wfc-timeout 120;
}
options {
# cpu-mask on-no-data-accessible
}
disk {
on-io-error detach;
}
net {
protocol C;
}
}
[root@master1 ~]# vi /etc/drbd.d/r0.res
resource r0 {
on master1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.100.101:7788;
meta-disk internal;
}
on master2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.100.102:7788;
meta-disk internal;
}
}6. 在master1、master2两个节点准备drbd的磁盘(在此只列举master1单台主机配置)
[root@master1 ~]# fdisk /dev/sdb
n--p--1--回车--回车--p--w
[root@master1 ~]# yum -y install parted
[root@master1 ~]# partprobe /dev/sdb
[root@master1 ~]# partprobe /dev/sdb1
[root@master1 ~]# dd if=/dev/zero of=/dev/sdb1 bs=1M count=1
记录了1+0 的读入
记录了1+0 的写出
1048576字节(1.0 MB)已复制,0.00917599 秒,114 MB/秒
[root@master1 ~]# drbdadm create-md r0 ##创建drbd磁盘,注意master1和master2的主机名必须更改,不然导致报错
you are the 1649th user to install this version
initializing activity log
initializing bitmap (640 KB) to all zero
Writing meta data...
New drbd meta data block successfully created.
[root@master1 ~]# /etc/init.d/drbd start ##如若出现无法加载drbd模块,重启主机可以解决
...
To abort waiting enter 'yes' [ 12]: yes
...
[root@master1 ~]# netstat -anpt |grep 7788 ##当master1单个节点服务启动的状态
tcp 0 0 192.168.100.101:7788 0.0.0.0:* LISTEN -
[root@master2 ~]# netstat -anpt |grep 7788 ##当master1和master2两个节点服务同时启动的状态
tcp 0 0 192.168.100.102:7788 192.168.100.101:56853 ESTABLISHED -
tcp 0 0 192.168.100.102:34126 192.168.100.101:7788 ESTABLISHED -
7. 在master1主节点上进行初始化drbd的块设备并且进行测试挂载
[root@master1 ~]# drbdadm -- --overwrite-data-of-peer primary r0
[root@master1 ~]# cat /proc/drbd ##等待其初始化完成
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2018-04-26 12:10:42
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:301636 nr:0 dw:0 dr:303740 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20668184
[>....................] sync'ed: 1.5% (20180/20476)M
finish: 0:23:53 speed: 14,408 (10,772) K/sec
[root@master1 ~]# mkfs -t xfs /dev/drbd0
meta-data=/dev/drbd0 isize=512 agcount=4, agsize=1310614 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242455, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@master1 ~]# mkdir /mysqldata
[root@master1 ~]# mount /dev/drbd0 /mysqldata/
[root@master1 ~]# mount |tail -1
/dev/drbd0 on /mysqldata type xfs (rw,relatime,attr2,inode64,noquota)
[root@master1 ~]# echo "ceshi" >>/mysqldata/ceshi.txt
[root@master1 ~]# cat /mysqldata/ceshi.txt
ceshi
[root@master1 ~]# umount /mysqldata/
[root@master1 ~]# drbdadm secondary r08. 在master2从节点上测试挂载drbd块设备
[root@master2 ~]# drbdadm primary r0
[root@master2 ~]# mkdir /mysqldata
[root@master2 ~]# mount /dev/drbd0 /mysqldata/
[root@master2 ~]# mount |tail -1
/dev/drbd0 on /mysqldata type xfs (rw,relatime,attr2,inode64,noquota)
[root@master2 ~]# cat /mysqldata/ceshi.txt
ceshi
[root@master2 ~]# umount /mysqldata/
[root@master2 ~]# drbdadm secondary r09. 配置 master1节点的mysql服务数据文件的存放位置为 drbd 块设备的挂载点
[root@master1 ~]# drbdadm primary r0
[root@master1 ~]# mount /dev/drbd0 /mysqldata/
[root@master1 ~]# ls /mysqldata/
ceshi.txt
[root@master1 ~]# sed -i 's/\/usr\/local\/mysql\/data/\/mysqldata\/mysql/g' /etc/my.cnf
[root@master1 ~]# grep mysqldata /etc/my.cnf
datadir = /mysqldata/mysql
[root@master1 ~]# chown -R mysql:mysql /mysqldata/
[root@master1 ~]# systemctl stop mysqld
[root@master1 ~]# /usr/local/mysql/scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/mysqldata/mysql
[root@master1 ~]# systemctl start mysqld
[root@master1 ~]# ls /mysqldata/mysql/
auto.cnf ibdata1 ib_logfile0 ib_logfile1 mysql performance_schema test
[root@master1 ~]# mysqladmin -uroot password 123123
Warning: Using a password on the command line interface can be insecure.
[root@master1 ~]# mysql -uroot -p123123
mysql> exit
[root@master1 ~]# systemctl stop mysqld
[root@master1 ~]# umount /mysqldata/
[root@master1 ~]# drbdadm secondary r010. 使用master2节点测试查看mysql中数据
[root@master2 ~]# drbdadm primary r0
[root@master2 ~]# mount /dev/drbd0 /mysqldata/
[root@master2 ~]# sed -i 's/\/usr\/local\/mysql\/data/\/mysqldata\/mysql/g' /etc/my.cnf
[root@master2 ~]# grep mysqldata /etc/my.cnf
datadir = /mysqldata/mysql
[root@master2 ~]# chown -R mysql:mysql /mysqldata/
[root@master2 ~]# systemctl restart mysqld
[root@master2 ~]# mysql -uroot -p123123
mysql> exit
[root@master2 ~]# systemctl stop mysqld
[root@master2 ~]# umount /mysqldata/
[root@master2 ~]# drbdadm secondary r0
[root@master1 ~]# drbdadm primary r0
[root@master1 ~]# mount /dev/drbd0 /mysqldata/
[root@master1 ~]# systemctl start mysqld11. 安装master1、master2节点的keepalived服务
[root@master1 ~]# yum -y install kernel-devel openssl-devel popt-devel
[root@master1 ~]# tar -zxvf keepalived-1.2.13.tar.gz -C /usr/src/
[root@master1 ~]# cd /usr/src/keepalived-1.2.13/
[root@master1 keepalived-1.2.13]# ./configure --prefix=/usr/local/keepalived
[root@master1 keepalived-1.2.13]# make &&make install
[root@master1 keepalived-1.2.13]# cd
[root@master1 ~]# mkdir -p /etc/keepalived ##程序的主配置目录
[root@master1 ~]# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/ ##复制主配置文件
[root@master1 ~]# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ ##复制启动时需要加载的配置文件
[root@master1 ~]# cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/ ##复制服务的控制脚本
[root@master1 ~]# cp /usr/local/keepalived/sbin/keepalived /usr/sbin/ ##复制keepalived的命令
[root@master1 ~]# chmod 755 /etc/init.d/keepalived ##为控制脚本指定权限12. 配置master1节点上master主节点
[root@master1 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id HA_TEST_R1 ##本服务器的名称,若环境中有多个keepalived时,此名称不能一致
}
vrrp_instance VI_1 { ##定义VRRP热备实例,每一个keep组都不同
state MASTER ##MASTER表示主服务器
interface eth0 ##承载VIP地址的物理接口
virtual_router_id 1 ##虚拟路由器的ID号,每一个keep组都不同
priority 100 ##优先级,数值越大优先级越高
advert_int 1 ##通告检查间隔秒数(心跳频率)
authentication { ##认证信息
auth_type PASS ##认证类型
auth_pass 123456 ##密码字串
}
virtual_ipaddress {
192.168.100.95 ##指定漂移地址(VIP)
}
}
:wq
[root@master1 ~]# /etc/init.d/keepalived start
Starting keepalived (via systemctl): [ 确定 ]
[root@master1 ~]# ip a |grep 192.168.100.95
inet 192.168.100.95/32 scope global eth013. 配置master 2节点上backup从节点
[root@master2 ~]# vi /etc/keepalived/keepalived.conf
global_defs {
router_id HA_TEST_R2 ##本服务器的名称
}
vrrp_instance VI_1 {
state BACKUP ##BACKUP表示从服务器
interface eth0
virtual_router_id 1
priority 99 ##优先级,低于主服务器
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.100.95
}
}
:wq
[root@master2 ~]# /etc/init.d/keepalived start
Starting keepalived (via systemctl): [ 确定 ]
[root@master2~]# ip a |grep 192.168.100.9514. 配置master1节点keepalived服务切换DRBD块设备
[root@master1 ~]# yum -y install expect
[root@master1 ~]# vi /etc/keepalived/drbd.sh
#!/bin/bash
while true;do
VIP=$(ip a |grep 192.168.100.95 |wc -l)
if [ $VIP -eq 0 ];then
/etc/init.d/keepalived start
sleep 2
VIP=$(ip a |grep 192.168.100.95 |wc -l)
if [ $VIP -eq 0 ];then
systemctl stop mysqld
sleep 2
fi
fi
MYSQLD=$(ps aux |grep mysqld |grep -v grep |wc -l)
if [ $MYSQLD -eq 0 ];then
/etc/init.d/keepalived stop
echo "mysql stats is down on $(date +%F-%T)" >>/var/log/mysqld.stats
sleep 2
umount /mysqldata
sleep 2
drbdadm secondary r0
/etc/keepalived/expect.sh 192.168.100.102 root pwd@123 "drbdadm primary r0 && mount /dev/drbd0 /mysqldata && systemctl start mysqld"
echo "mysql is already switched master2 on $(date +%F-%T)" >>/var/log/mysqld.stats
fi
done
[root@master1 ~]# vi /etc/keepalived/expect.sh
#!/usr/bin/expect
set ip [lindex $argv 0]
set user [lindex $argv 1]
set password [lindex $argv 2]
set com [lindex $argv 3]
set timeout 10
spawn ssh $user@$ip $com
expect {
"*yes/no" { send "yes\r"; exp_continue}
"*password:" { send "$password\r" }
}
interact
[root@master1 ~]# chmod +x /etc/keepalived/drbd.sh
[root@master1 ~]# chmod +x /etc/keepalived/expect.sh
[root@master1 ~]# /etc/keepalived/drbd.sh &
[root@master1 ~]# jobs -l
[1]+ 4349 running /etc/keepalived/drbd.sh15. 配置master1、master2节点上的主从复制
[root@master1 ~]# cat <>/etc/my.cnf
server-id=1
log-bin=mysql-bin
log-slave-updates=true
END
[root@master1 ~]# systemctl restart mysqld
[root@master1 ~]# mysql -uroot -p123123
mysql> grant replication slave on *.* to 'myslave'@'192.168.100.%' identified by '123123';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 412 | | | |
+------------------+----------+--------------+------------------+-------------------+
mysql> exit
[root@master2 ~]# cat <>/etc/my.cnf
server-id=1
log-bin=mysql-bin
log-slave-updates=true
END 16. 配置slave1节点的主从复制
[root@slave1 ~]# cat <>/etc/my.cnf
server-id=2
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
END
[root@slave1 ~]# systemctl restart mysqld
[root@slave1 ~]# mysql -uroot -p123123
mysql> change master to master_host='192.168.100.95',master_user='myslave',master_password='123123',master_log_file='mysql-bin.000001',master_log_pos=412;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.95
Master_User: myslave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 412
Relay_Log_File: relay-log-bin.000002
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
mysql> exit 17. 配置slave2节点的主从复制
[root@slave2 ~]# cat <>/etc/my.cnf
server-id=3
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
END
[root@slave2 ~]# systemctl restart mysqld
[root@slave2 ~]# mysql -uroot -p123123
mysql> change master to master_host='192.168.100.95',master_user='myslave',master_password='123123',master_log_file='mysql-bin.000001',master_log_pos=412;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.95
Master_User: myslave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 412
Relay_Log_File: relay-log-bin.000002
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
mysql> exit 18. 验证master1节点、slave1节点、slave2节点的主从复制
[root@master1 ~]# mysql -uroot -p123123
mysql> create database linuxfan1;
Query OK, 1 row affected (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| mysql |
| performance_schema |
| test |
+--------------------+
6 rows in set (0.00 sec)
mysql> exit
[root@slave1 ~]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| mysql |
| performance_schema |
| test |
+--------------------+
6 rows in set (0.00 sec)
mysql> exit
[root@slave2 ~]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| mysql |
| performance_schema |
| test |
+--------------------+
6 rows in set (0.00 sec)
mysql> exit19. 安装amoeba数据库代理程序
[root@amoeba ~]# ls
amoeba-mysql-binary-2.2.0.tar.gz jdk-6u14-linux-x64.bin
[root@amoeba ~]# chmod +x jdk-6u14-linux-x64.bin
[root@amoeba ~]# ./jdk-6u14-linux-x64.bin
[root@amoeba ~]# mv jdk1.6.0_14/ /usr/local/jdk1.6
[root@amoeba ~]# vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME
:wq
[root@amoeba ~]# source /etc/profile
[root@amoeba ~]# java --version
Unrecognized option: --version
Could not create the Java virtual machine.
[root@amoeba ~]# java -version
java version "1.6.0_14"
Java(TM) SE Runtime Environment (build 1.6.0_14-b08)
Java HotSpot(TM) 64-Bit Server VM (build 14.0-b16, mixed mode)20. 配置master1节点授权amoeba节点连接数据库集群
[root@master1 ~]# mysql -uroot -p123123
mysql> grant all on *.* to 'amoeba'@'192.168.100.%' identified by '123123';
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit21. 修改amoeba节点的配置文件并启动测试
[root@amoeba ~]# mkdir /usr/local/amoeba
[root@amoeba ~]# tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
[root@amoeba ~]# chmod -R 755 /usr/local/amoeba/
[root@amoeba ~]# vi /usr/local/amoeba/conf/amoeba.xml
30 admin
31
32 admin
115 master
116
117
118 master
119 slaves
:wq
[root@amoeba ~]# vi /usr/local/amoeba/conf/dbServers.xml
19
20 3306
21
22
23 test
24
25
26 amoeba
27
28
29 123123
45
46
47
48 192.168.100.95
49
50
51
52
53
54
55 192.168.100.103
56
57
58
59
60
61
62 192.168.100.104
63
64
66
67
68
69 1
70
71
72 slave1,slave2
73
74
:wq
[root@amoeba ~]# /usr/local/amoeba/bin/amoeba start &
[1] 123722. 客户端访问测试主从复制
[root@client ~]# yum -y install mysql
[root@client ~]# mysql -uadmin -padmin -h192.168.100.105 -P 8066
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| mysql |
| performance_schema |
| test |
+--------------------+
MySQL [(none)]> create database linuxfan2;
Query OK, 1 row affected (0.01 sec)
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| linuxfan2 |
| mysql |
| performance_schema |
| test |
+--------------------+
MySQL [(none)]> use linuxfan2;
Database changed
MySQL [linuxfan]> create table t1(id int,name varchar(8));
Query OK, 0 rows affected (0.02 sec)
MySQL [linuxfan]> insert into t1 values(1,'tom');
Query OK, 1 row affected (0.01 sec)
MySQL [linuxfan]> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | tom |
+------+------+
MySQL [(none)]> exit
[root@master1 ~]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| linuxfan2 |
| mysql |
| performance_schema |
| test |
+--------------------+
mysql> exit
[root@slave1 ~]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| linuxfan2 |
| mysql |
| performance_schema |
| test |
+--------------------+
mysql> exit
[root@slave2 ~]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| linuxfan2 |
| mysql |
| performance_schema |
| test |
+--------------------+
mysql> exit23. 客户端访问测试读写分离
[root@slave1 ~]# mysql -uroot -p123123
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql> use linuxfan2;
Database changed
mysql> insert into t1 values(2,'jack');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | tom |
| 2 | jack |
+------+------+
mysql> exit
[root@slave2 ~]# mysql -uroot -p123123
mysql> stop slave;
Query OK, 0 rows affected (0.01 sec)
mysql> use linuxfan2;
Database changed
mysql> insert into t1 values(3,'marry');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t1;
+------+-------+
| id | name |
+------+-------+
| 1 | tom |
| 3 | marry |
+------+-------+
mysql> exit
[root@client ~]# mysql -uadmin -padmin -h192.168.100.105 -P 8066
MySQL [(none)]> use linuxfan2;
Database changed
MySQL [linuxfan2]> insert into t1 values(4,'kali');
Query OK, 1 row affected (0.01 sec)
MySQL [linuxfan2]> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | tom |
| 2 | jack |
+------+------+
MySQL [linuxfan2]> select * from t1;
+------+-------+
| id | name |
+------+-------+
| 1 | tom |
| 3 | marry |
+------+-------+
MySQL [linuxfan2]> exit24. 关闭master1节点,测试双主热备情况
[root@master1 ~]# /etc/keepalived/drbd.sh &
[1] 51212
[root@master1 ~]# systemctl stop mysqld
[root@master1 ~]# Stopping keepalived (via systemctl): [ 确定 ]
spawn ssh [email protected] drbdadm primary r0 && mount /dev/drbd0 /mysqldata && systemctl start mysqld
...
[root@master2 ~]# ip a|grep 192.168.100.95
inet 192.168.100.95/32 scope global eth0
[root@master2 ~]# ls /mysqldata/
ceshi.txt mysql
[root@master2 ~]# netstat -utpln |grep 3306
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 8037/mysqld
[root@client ~]# mysql -uadmin -padmin -h192.168.100.105 -P 8066
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linuxfan |
| linuxfan1 |
| linuxfan2 |
| mysql |
| performance_schema |
| test |
+--------------------+
MySQL [(none)]> exit七、TMHA 淘宝MySQL数据库高可用设计
1、MySQL数据库的主要问题
1)主库单点问题
• 通过业务功能的写入主库通常只能有1个;
• 除非应用程序自己完成容灾;
2、可靠性衡量
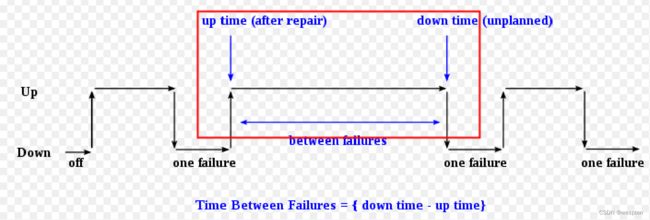
1) 可靠性指标MTBF
– Mean Time between failures;
2)1million hours的含义
– 10,000台服务器同时运行100小时就会坏一台;
3)服务器主要部件MTBF
– 主板、CPU、硬盘 1million hours (厂家标称值);
– 内存 4million hours(8根内存 ~ 1million hours);
4)整体的MTBF~1million/4=250000h~1万天
– 年故障率约2%-4%,故障率较高 ;
3、MySQL常用容灾方案—复制
1)Master
数据发生改变;
记录变化;
2)Slave
获取master的改变;
同步这些变化;
3)Binary-log
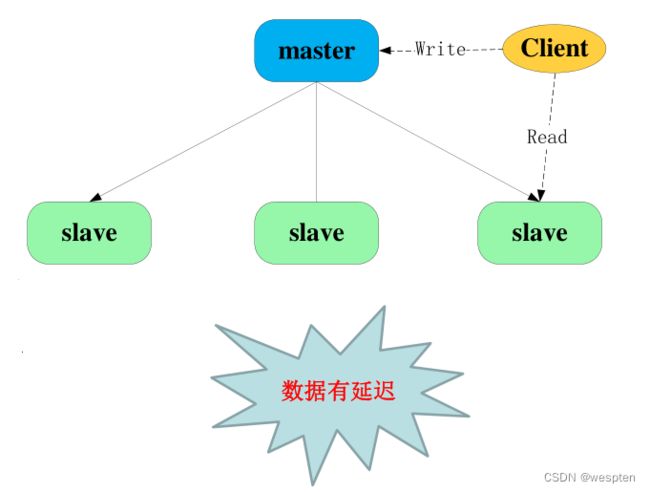
MySQL复制延迟:
1)单条SQL
• 执行(执行时间为T)完直接写入binlog;
• 延迟大概为T;
2)一个事务(包括N条)
• 先缓存到cache,全部执行完写入;
• 延迟为NT;

4、mysql切换
1)master挂了,如何?
– 选择新的主库
– 通知应用切换
– master恢复之后,如何同步
2)着重问题
– 故障是存在的
– MS数据的一致性保证
– 新主库的选举 / 应用程序感知
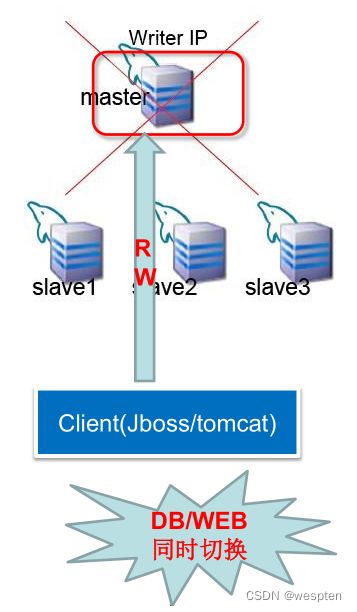
5、对应用透明的常用方法
1)Master采用虚IP的方式
– 前提:备库与主库在同一网段
– 阿里云的RDS、云聊PHPWind
官网:http://app.phpwind.com/%E2%80%93
– 腾讯的CDB
官网:http://wiki.opensns.qq.com/wiki/CDB
2)DB对外的接口是DNS
– 优势:备库与主库可以在不同机房
– 缺点:受限于DNS,若DNS故障,服务不可用
3)MHA:多个从库之间选择一个主库
官网:http://code.google.com/p/mysql-master-ha
6、分布式数据中间层(TDDL)
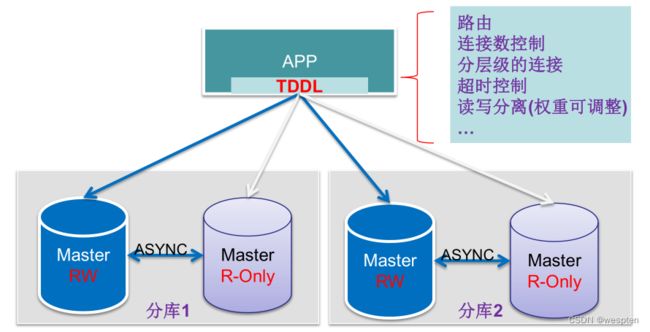
1. Master和Master-Readonly的mysql部署在不同机房;
2. 异步复制,有数据延迟;
3. 分库分表 ;
7、TMHA(master HA)整体架构
1)维护切换,如换机器、内存维修等 (双十一当天FusionIO交易主库切换)
2)异常切换
① master异常挂掉,zookeeper的agent1结点消失(如果网络,zk感知);
② agent2得知watcher事件,记录异常,创建异常结点;
③ SwitchManager获取最新的异常结点,再次确认是否异常;
④ 异常,推送tddl配置,将新主库read-only置为false,即新主库可写;

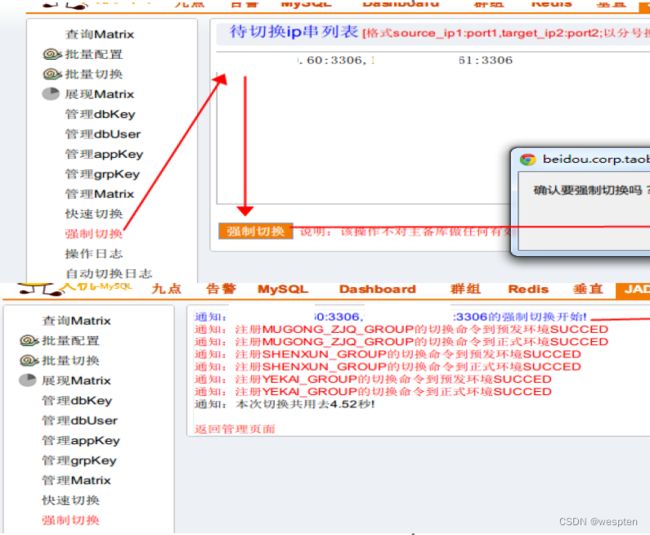
8、切换类型
1)切换类型
① 正常切换 (机器维修、扩容等);
② 强制切换 (主库load非常高,双十一);
③ 自动切换;
④ 批量切换 (16、32套库批量切换);
9、分布式系统的异常检测思路
1)Paxos:一半机器存活即可
实践中,常用master + lease来提高效率;
2)分布式系统协调服务
– Chubby (Google: Bigtable, MapReduce);
– Zookeeper (Yahoo!: hbase, hadoop子项目);
10、主库选举的检测逻辑
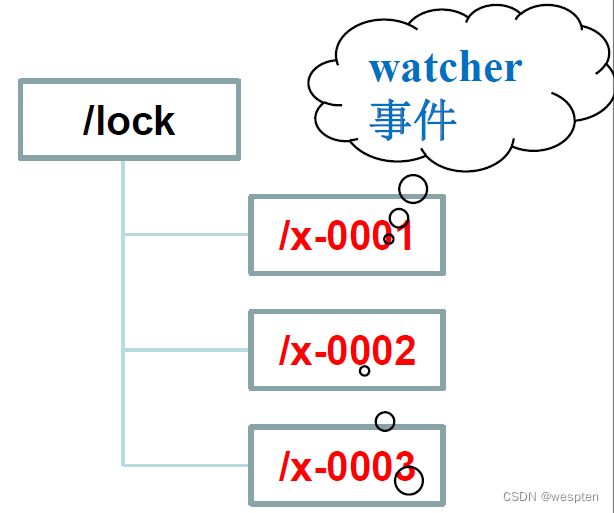
1)主库切换选举 (zk实现写锁)
– 每个mysql的客户端对应一个节点;
– 主库对应的节点为第一个节点;
– 若主库挂了,节点消失;
– 发起选举,只有一个节点获得lock;
即成为新主库。
1. 初始化阶段: 创建/transfer服务节点;
2. 创建lock子节点,zoo_create(― /locks/x-‖, SEQUENCE|EPHEMERAL);
3. zoo_get_child(―/lock‖, NULL) //不设置watcher;
4. 若当前client的id(序列的id)是当前最小的节点,则获得锁,退出;
5. 否则,zoo_wexists(last child before id, watcher);
① 若id不存在,则返回第3步
② 等待watcher的触发
11、切换部署及使用场景
1)优势
– 备库与主库不同机房
– 不受限于DNS
2)场景:三个机房
– zk部署在三个机房
– mysql:agent=1:1
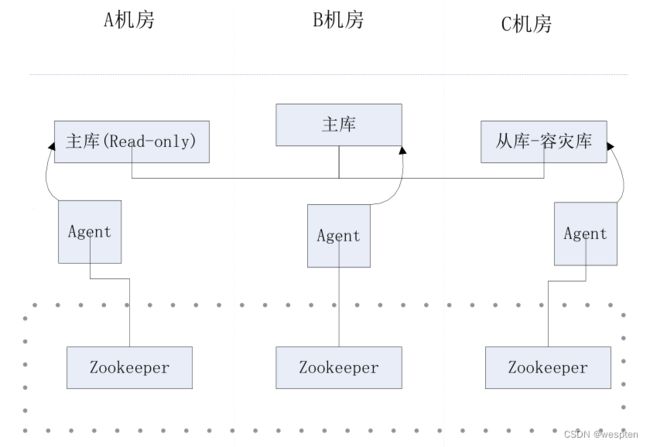
12、主库切换的触发条件
1)agent异常
– a1:agent异常退出
– a2:agent与mysql的通信异常
– a3:agent与zk之间的网络异常
– a4:机器死机
2)mysql数据库
– m1:访问异常
– m2:机器死机(同a4)
– m3:机器的网络异常(同a3)
– m4:所在的整个机房down掉

13、触发条件的抽象化、程序化
1)所有条件的表现都是/Agent1结点消失
1. mysql异常,agent1主动删除结点;
2. zk/网络异常,达到zk的超时后消失;
2)Agent2得到Agent1消失的事件(zookeeper的Watcher机制)
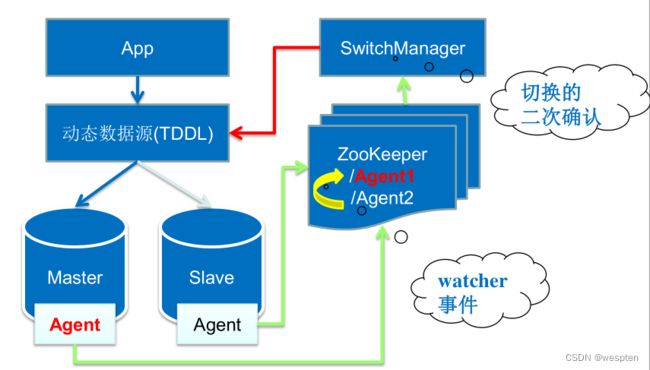
14、一致性—可能丢失的数据
1. 挂掉的master的binlog能否获取到 (记做Δ1)
2. Slave机器上的relay-log损坏(记做Δ2)
3. 简称delta(Δ)
REF : http://code.google.com/p/mysql-master-ha/
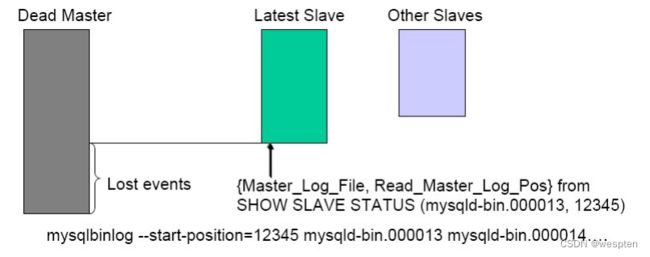
15、Δ2的回补策略
1)Slave的relay-log损坏
– 判断Exec/Read的pos
– 若不相等可能有丢失
2)处理方案
–reset slave/change master
–relay-log重新获取即可

16、Δ1的处理策略
1)需要根据决策来决定
– Dead主库起来, Δ1继续同步,不切换
– 切换, Dead主库起来,主库回滚Δ1
17、Δ1的处理策略-回滚
1)回滚宕机主库日志(必须是row模式)

逆sql:
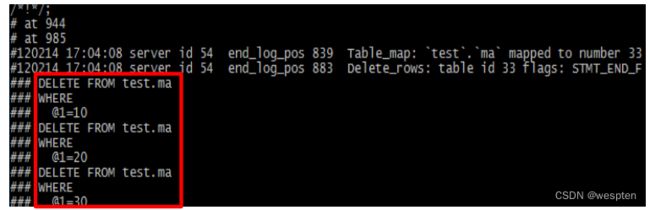
DELETE FROM test.ma WHERE id=10; 18、Δ1回滚的原理(rollback.pl)
1)倒置binlog中所有SQL顺序,保证逻辑相反
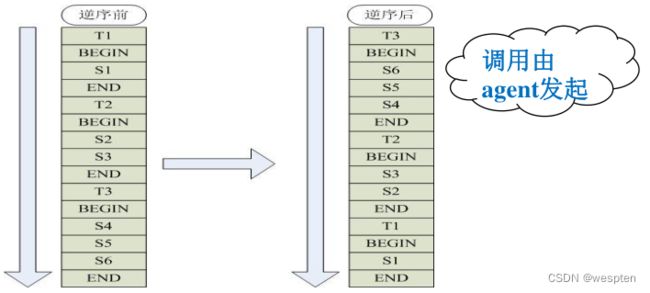
注意:
– 适当修改mysqlbinlog工具
– 双字节,第一个字节超过7F,第二个字节为5C
– URL:http://ww7.taobaodba.com/
19、Δ1回滚的使用场景
1)回滚Dead Master与新的主库一致(同步)
2)误删除的数据回滚 (表级别、数据库级别)
– 主库做了一个delete、update的数据(row模式)
– INSERT INTO test.ma(id) values (10);
20、自动切换(配置白名单即可)

1. OS、ping、mysql ping、mysql 读写自动判断即可
2. 配置白名单:在白名单里面的列表都可以自动切换(这一块是在SwitchManager里面控制)
21、数据复制中心(DRC)
架构图:
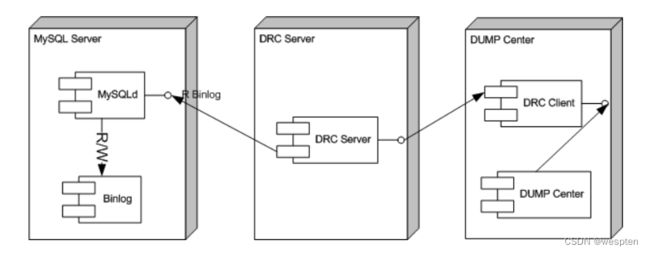
– 多线程写入目的端mysql等
– 支持事务、dump给商品搜索
总结:
1. 通过zookeeper实现配置的集中管理;
2. 数据一致性、read-only设置显得尤为重要;
3. 故障切换 + APP切换 + 人工/自动切换兼容;
补充:
Zk的监控改进
1)4-letter monitoring (mntr) / ganglia监控
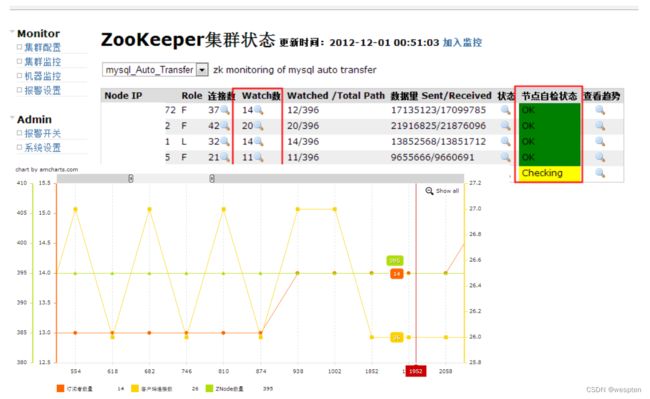
2)Taokeeper (中间件团队提供)
参考:
ZooKeeper JMX
4-letter monitoring:
1. 版本3.3.3需要添加patch-744方可(ant编译);
2. 版本3.4自动支持(另外,3.4引入observer);

Ganglia监控
Taokeeper监控