深度学习之GPU
深度学习利器-GPU介绍
1 深度学习之GPU
近代史科技发展日新月异,摩尔定律从中显威,各种底层技术层出不穷,但是纵观科技发展史,几乎所有的新兴学科的发展背后都有一个字——“钱”!
作为近年来最火热的行业——人工智能,在烧钱方面同样不遑多让。众所周知,人工智能的训练和推理都需要海量的高性能计算,做深度学习的朋友都知道,现今深度学习领域的SOTA模型往往需要巨大的显存空间,这直接导致了深度学习的研究者们需要配置更强劲的 GPU 设备,否则就会分分钟面临显存与算力不足的窘境。大型企业或者研究机构可以一掷千金部署 HPC,比如近年来特别热点的GPT3等SOTA模型,可以这么说,想要跑下来、跑的快可能没有个上千万都不要去想。
当今的 AI 模型面临着对话式 AI 等更高层次的挑战,这促使其复杂度呈爆炸式增长。训练这些模型需要大规模的计算能力和可扩展性。
以英伟达目前的最先进的A100为例,NVIDIA A100 的 Tensor Core 借助 Tensor 浮点运算 (TF32) 精度,可提供比上一代 NVIDIA Volta 高 20 倍之多的性能,并且无需更改代码;若使用自动混合精度和 FP16,性能可进一步提升 2 倍。
2048 个 A100 GPU 可在一分钟内大规模处理 BERT 之类的训练工作负载,这是训练时间的世界纪录。
对于具有庞大数据表的超大型模型(例如用于推荐系统的 DLRM),A100 80GB 可为每个节点提供高达 1.3 TB 的统一显存,而且速度比 A100 40GB 快高达 3 倍。
NVIDIA 产品的领先地位在 MLPerf 这个行业级 AI 训练基准测试中得到印证,创下多项性能纪录。
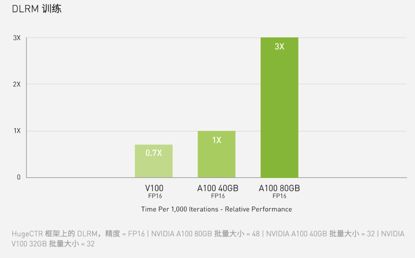
A100 80GB相对于A100 40G来说在GPU芯片上没变化,依然是A100核心,6912个CUDA核心,加速频率1.41GHz,FP32性能19.5TFLOPS,FP64性能9.7TFLOPS,INT8性能624TOPS,TDP 400W。变化的主要是显存,之前是40GB,HBM2规格的,带宽1.6TB/s,现在升级到了80GB,显存类型也变成了更先进的HBM2e,频率从2.4Gbps提升到3.2Gbps,使得带宽从1.6TB/s提升到2TB/s。
2 GPU与GPU简介
对于大众来说,CPU是用来处理计算的,而GPU是用来处理图像渲染的,从能力范围来说相对来说CPU可能更加强大,那么深度学习为什么可以使用GPU来进行加速,性能获得巨大的提升呢,下面和大家娓娓道来,可以先泡一杯茶,慢慢来看。
综合来说,大家可以这么理解,举个职场的例子,相信很多人都遇到过,CPU是一个十八班武义精通汉子,但是在职场里面由于其精通的太多,所以导致什么事情都分到了他那里,所以他在疯狂的流转,大家没注意到他做到的,只注意到他没做到的。但是GPU呢,他比较矫情,也有一定的能力,但是能力范围有限,而且他挑活,相对于CPU的任劳任怨,他只想做能出成绩的,对于其他一概不理。延伸来说吧,还有一些人是SBPU,啥叫SBPU呢,就是能力也不咋地,抢别人的功劳一流,但是自己屁也做不出来,靠着不光彩的手段和龌龊的计量,占据别人的功劳为己用,然后狂吹PPT。额,跑题了,赶紧回到正题。
2.1 CPU介绍

中央处理器(CPU),是电子计算机的主要设备之一,电脑中的核心配件。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU是计算机中负责读取指令,对指令译码并执行指令的核心部件。中央处理器主要包括两个部分,即控制器、运算器,其中还包括高速缓冲存储器及实现它们之间联系的数据、控制的总线。电子计算机三大核心部件就是CPU、内部存储器、输入/输出设备。中央处理器的功效主要为处理指令、执行操作、控制时间、处理数据。
在计算机体系结构中,CPU 是对计算机的所有硬件资源(如存储器、输入输出单元) 进行控制调配、执行通用运算的核心硬件单元。CPU 是计算机的运算和控制核心。计算机系统中所有软件层的操作,最终都将通过指令集映射为CPU的操作。
本质:CPU 由专为顺序串行处理而优化的几个核心组成,当然也可以通过多核与超线程等技术进行并行,但是受限于CPU的复杂工作流程、功耗、散热、尺寸等方面的影响,整体CPU的核心不会太多,这点也是GPU的优势。
2.2 GPU介绍

图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。 [1]
GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。GPU的生产商主要有NVIDIA和ATI。
2.3 CPU与GPU的区别

首先,针对GPU 和 CPU的各自特点进行分析,阐述下GPU相对于CPU为何在并行计算上具备优势。
- 任务模式
- CPU 由专为顺序串行处理而优化的几个核心组成
- GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。同时CPU相当的一部分时间在执行外设的中断、进程的切换等任务,而GPU有更多的时间并行计算。
- 功能定位
- GPU在渲染画面时需要同时渲染数以百万记的顶点或三角形,故GPU的设计是可以充分支持并行计算。
- CPU不但要承担计算任务还有承担逻辑控制等任务。
- 系统集成
- GPU作为一类外插设备,在尺寸、功率、散热、兼容性等方面的限制远远小于CPU,这样可以让GPU有较大的显存和带宽。
2.4 GPU在深度学习大放异彩的关键 – CUDA
GPU已经存在了很长时间,那么为何最近几年才开始大放异彩呢。个人认为主要原因有以下两个:
- 最近几年神经网络深度学习对算力的要求不断攀升,特别是CV、NLP领域的大量超算操作。
- 以前NVIDIA等厂商没有提供GPU – 深度学习之间的桥梁,把GPU真正用到深度虚线上有很大的成本,直至CUDA的出现,顺利的打通了这个桥梁。给GPU的盛行,提供了坚实的基座。
在软件层,通过CUDA抽象成了统一的编程接口并提供C/C++/Python/Java等多种编程语言的支持。CUDA的这一层抽象非常重要,因为有了这层抽象,向下开发者的代码可在不同的硬件平台上快速迁移;向上,在CUDA基础上封装了用于科学计算的cuBLAS(兼容BLAS接口),用于深度学习的cuDNN等中间件和代码库。这些中间件对于Tensorflow,PyTorch这一类的深度学习框架非常重要,可以更容易地使用CUDA和底层硬件进行机器学习的计算任务。
3 GPU的体系结构
3.1 GPU的物理体系结构
仍然以英伟达的A100 GPU为例,从整体上来说A100具备6192个Core,所以大家可以这么理解,他是一个超级的CPU,可以并行执行6192个核心。如下图

GPU的基础单位是SM,实际上在 NVidia 的 GPU 里,最基本的处理单元是所谓的 SP(Streaming Processor),而一颗 NVidia 的 GPU 里,会有非常多的 SP 可以同时做计算;而数个 SP 会在附加一些其他单元,一起组成一个 SM(Streaming Multiprocessor)。几个 SM 则会在组成所谓的 TPC(Texture Processing Clusters)。
这里我们暂时把SM可以看成是GPU计算调度的一个基本单位。一个SM具备64个用于计算的Core。针对A100来说,整个GPU上面有个108条好汉,额,是108个SM,所以整体的A100的Core的数量就是 64 * 108 = 6192。看看,够强劲吧,1个卡可以同时跑6192个并行的计算任务。
针对这个SM的架构图,再简单进行下补充:
- 最上面是PCIE层,通过PCIE接口以外设的方式集成到服务器上。
- 绿色的部分是GPU的计算核心,比如A100具备6192个Core。
- 中间蓝色部分是L2缓存
- NVLink是多个GPU间进行通信的组件,会对GPU之间的通信做些优化,减轻CPU负担,提升传输效率,这点在分布式训练中会用的比较多。
- 两侧的HBM2就是显存,目前的A100的显存有两种40G and 80G,有钱就买80G吧,差一半的显存呢
既然SM这么重要,那么我们就看看SM的硬件。

SM的相关结构:

3.2 GPU的逻辑体系结构

如果把 CUDA 的 Grid - Block - Thread 架构对应到实际的硬件上的话,会类似对应成 GPU - Streaming Multiprocessor - Streaming Processor;一整个 Grid 会直接丢给 GPU 来执行,而 Block 大致就是对应到 SM,thread 则大致对应到 SP。当然,这个讲法并不是很精确,只是一个简单的比喻而已。
- kernel:Thread执行的内容/代码/函数
- Thread:执行kernel的最小单元,调度到CUDA Core中执行
- Warp:GPU 有很多 Streaming Multiprocessors, 用来管理调度 Thread Block
- Thread Block:。多个Thread组合,被调度到SM中执行。一个SM可以同时执行多个Thread Block,但是一个Thread Block只能被调度到一个SM上。GPU 有很多 Streaming Multiprocessors, 用来管理调度 Thread Block。
- Grid:多个Thread Block的组合,被调度到整个GPU中执行
同时,Thread、Thread Block和Grid由于所处层次不同,他们可以访问的存储资源也不同。如Thread只能访问自身的寄存器,Thread Block可以访问SM中的L1缓存,而Grid则可以访问L2缓存和更大的HBM显存。
4 GPU的实战
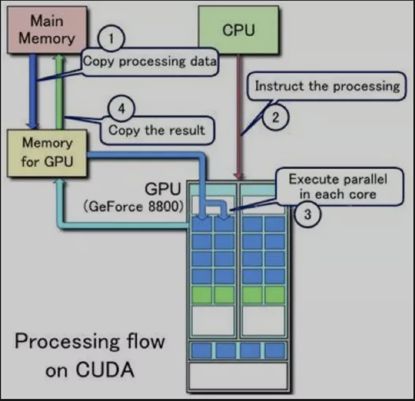
GPU的运行主要是四步:
- 从Host拷贝数据到Device
- CPU发送数据处理执行给GPU;
- 把需要Device执行的kernel函数发射给Device
- 从Device拷贝计算结果到Host
4.1 CUDA编程实战
// Device code
__global__ void VecAdd(float* A, float* B, float* C, int N)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}
// Host code
int main()
{
int N = ...;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// Initialize input vectors
...
// Allocate vectors in device memory
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid =
(N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<>>(d_A, d_B, d_C, N);
// Copy result from device memory to host memory
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
}
这里是如何体现出GPU的威力呢,举个例子:如果GPU中的每个核心都有唯一的ID,比如0号核心执行C[0] = A[0] + B[0],127号核心执行C[127] = A[127] + B[127]就好了。
int i = blockDim.x * blockIdx.x + threadIdx.x;主要是计算线程ID,那么关于线程的编码是如何呢,请看下面的简介。
那么关于线程的编码是如何呢,请看下面的简介。
- threadIdx是一个uint3类型,表示一个线程的索引。
- blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
- blockDim是一个dim3类型,表示线程块的大小。
- gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
- 下面这张图比较清晰的表示的几个概念的关系:
4.2 基于GPU的加速
整个GPU的东西还是比较多的,这块我就先简单写下吧,后续会在开个专题,这里先简单列几条:
- 算子融合
- 空域滤波
- High Level Graph Opt
- CPU & GPU Filter
5 参考资料
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
6 番外篇
个人介绍:杜宝坤,联邦学习领域前沿探索者。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:[email protected]
个人微信:
