Kaggle泰坦尼克号幸存者预测
解析一名金牌选手方案
泰坦尼克号——来自灾难的机器学习
1.数据
有两个数据集,分别是训练集train.csv和测试集test.csv。
train.csv包含乘客子集的详细信息(准确地说是 891 人),揭示了他们是否幸存,也称为“基本事实”。test.csv 数据集包含类似的信息,但没有透露每位乘客是否幸存,预测这些结果是你的工作,即:使用你在 train.csv 数据中找到的模式,预测船上的其他 418 名乘客(在 test.csv中找到)是否幸存。
下面了解一下train.csv数据集中的变量:

2.实施流程
(1)了解分析问题
(2)获取训练集和数据集
(3)进行数据整理和清洗
(4)分析识别模式并探索数据,进行特征处理
(5)建模,预测和解决问题
(6)提交结果
3.代码实现
(1)导入包
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
# 数据处理清洗包
import pandas as pd
import numpy as np
import random as rnd
# 可视化包
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 机器学习算法相关包
from sklearn.linear_model import LogisticRegression, Perceptron, SGDClassifier
from sklearn.svm import SVC, LinearSVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
(2)加载数据集
train_df = pd.read_csv('./titanic/train.csv')
test_df = pd.read_csv('./titanic/test.csv')
# 获取所有特征名
print(train_df.columns.values)
#['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch','Ticket' 'Fare' 'Cabin' 'Embarked']
#查看信息
train_df.info()
#查看数据分布情况
train_df.describe()
#查看数据缺失值
train_df.isnull().sum()
#可对测试集做同样操作
数据中的缺失值:
- 在训练集中,缺失值数目 Cabin > Age > Embarked;
- 在测试集中,缺失值数目 Cabin > Age > Fare。
各种数据的数据类型:
- 在训练集中,7个特征是整数型或浮点型,5个特征是字符串型;
- 在测试集中,6个特征是整数型或浮点型,5个特征是字符串型。
对于字符串类型的数据,后期可将其转换为数值型数据。
注:df.describe(),默认是描述字符类型的属性,inclede='0’则是描述object类型的属性,include=‘all’则是对所有属性的描述
样本中数值特征的分布是什么
- 样本总数为891 人,约占泰坦尼克号上实际乘客人数(2,224 人)的40%;
- Survived 是具有 0 或 1 值的二分类变量,并且大约 38% 的样本存活,代表实际存活率38%;
- 大多数乘客(>50%)的票价等级是三等票;
- 年龄在 65-80 岁之间的老年乘客很少 (<1%);
- 近 30% 的乘客有兄弟姐妹或配偶一同登机;
- 大多数乘客 (>75%) 没有与父母或孩子一起旅行;
- 票价差异很大,少数乘客 (<1%) 支付高达 512 美元。
样本中分类特征的分布是什么
- 名称在数据集中是唯一的(count=unique=891);
- 性别变量有两个可能的值,男性占 65%(top=male,freq=577/891);
- 票号具有高比例 (22%) 的重复值 (unique=681);
- 客舱号在样本中也具有较多重复项,说明存在几名乘客共用一个小舱的现象;
- 登船港口有三个可能的值,大多数乘客是S口。
(3)基于数据分析的假设
我们想知道每个特征与幸存Survived的相关性如何,以便后期建模。事先可以假设:
- Age 年龄特征肯定与幸存相关;
- Embarked 登船港口可能与幸存或其他重要特征相关;
- Ticket 票号包含较高重复率(22%),并且和幸存之间可能没有相关性,因此可能会从我们的分析中删除;
- Cabin 客舱号可能被丢弃,因为它在训练和测试集中缺失值过多(数据高度不完整);
- PassengerId 乘客编号可能会从训练数据集中删除,因为它对幸存没有作用;
- Name 名字特征比较不规范,可能也对幸存没有直接贡献,因此可能会被丢弃。
通过旋转特征进行分析
- Pclass 观察到Pclass=1和Survived之间有显著的相关性(>0.5),因此在模型中应包含在特征。
- Sex 女性的存活率非常高达74%,因此在模型中应包含性别特征;
- SibSp和Parch 这两个特征对于某些值与Survived具有零相关性,最好从这些单独的特征中派生一个特征或一组特征,使得与Survived有显著相关性。
# 针对Pclass和Survived进行分类汇总
train_df[['Pclass','Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
#针对Sex和Survived进行分类汇总
train_df[['Sex','Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
#针对SibSP和Survived进行分类汇总
train_df[['SibSp','Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived',ascending=False)
#针对Parch和Survived进行分类汇总
train_df[['Parch','Survived']].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived',ascending=False)
(4)可视化数据分析
分析数值特征Age与Survived相关性
首先了解数值特征Age与我们的解决方案目标(Survived)之间的相关性。直方图对于分析连续数值变量很有用。
婴儿(年龄<=4)的存活率很高;最年长的乘客(年龄 = 80)幸存下来;大部分15-25 岁的人无法生存;大多数乘客的年龄在 15-35 岁之间。
这些简单的分析证实了后续工作我们应该:在模型训练中考虑年龄特征 Age;完成年龄特征的缺失值处理;捆绑年龄组。
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)

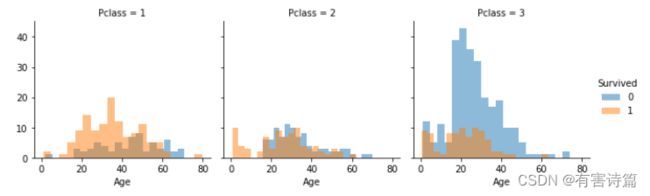
分析有序分类特征Pclass和Survived相关性
Pclass=3 有大多数乘客,但大多数没有幸存;
Pclass=2 和 Pclass=3 的婴儿乘客大多幸存下来;
Pclass=1 中的大多数乘客幸存下来;
Pclass 因乘客年龄分布而异。
综上分析,应该将Pclass纳入模型训练之中。
grid = sns.FacetGrid(train_df, col='Pclass', hue='Survived')
grid.map(plt.hist, 'Age', alpha=0.5, bins=20)
grid.add_legend();
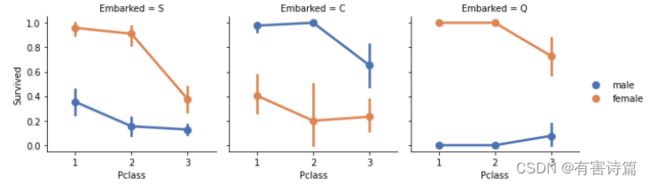
分析无序分类特征Embarked与Survived相关性
Embarked=S 和 Q 中,女性乘客的存活率远高于男性;Embarked=C 中,男性的存活率较高。这可能是 Embarked 和 Sex 相关,而 Sex 和 Survived 相关,进而造成Embarked与Survived间接相关;
对于同一票价等级和同一性别,不同登船港口的存活率不同。
综上分析,在模型训练中应该:添加 Sex 和 Embarked 特征。
grid = sns.FacetGrid(train_df, col='Embarked')
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend();
分析数值特征Fare和Survived相关性
将分类特征(具有非数值)和数字特征相关联,可以考虑将 Embarked(分类非数值)、Fare(连续数值)与 Survived(二分类数值)相关联。
支付更高票价的乘客能够更好地幸存,并且幸存率具有较明显的票价区间性;
不同的登船港口有不同的存活率。
因此,应该考虑捆绑票价特征Fare,并纳入模型训练中。
grid = sns.FacetGrid(train_df, col='Embarked', hue='Survived', palette={0: 'b', 1: 'r'})
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()
(5)整理,清洗数据
删除无用特征Ticket和Cabin
删除训练集和测试集中的无用特征
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
"After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape
从现有特征中提取新特征
在删除 Name 和 PassengerId 特征之前,分析是否可以设计 Name 特征来提取头衔Title,并测试Title和Survived之间的相关性;
使用正则表达式提取Title特征。正则表达式(\w+.)匹配 Name 特征中以点字符结尾的第一个单词,expand=False返回一个 DataFrame。
当绘制 Title、Age 和 Survived 时,注意到以下观察结果:大多数标题准确地划分了年龄组。 例如:Master Title 的平均 Age 是5岁,某些头衔大多幸存下来(Mme、Lady、Sir)或没有幸存下来(Don、Rev、Jonkheer)。
因此,决定保留新的Title特征用于模型训练。
# 使用正则表达式提取Title特征
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex']).sort_values(by='female', ascending=False) # pd.crosstab列联表
grid = sns.FacetGrid(train_df, col='Title', hue='Survived', col_wrap=3, size=2.5, aspect=1.6)
#grid = sns.FacetGrid(train_df, col='Title', hue='Survived')
grid.map(plt.hist, 'Age', alpha=0.5, bins=20)
grid.add_legend()
# 可以用更常见的名称替换许多标题或将它们归类为稀有
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace(['Mlle', 'Ms'], 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
# 将分类标题转换为序数
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping) # 将序列中的每一个元素,输入函数,最后将映射后的每个值返回合并,得到一个迭代器
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
# 现在可以从训练和测试数据集中删除Name特征以及训练集中的PassengerId 特征
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape
转换性别特征sex
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int) #男性赋值为0,女性赋值为1,并转换为整型数据
train_df.head()
填补年龄特征Age的缺失值
- 使用其他相关特征,注意到Age,Sex和pClass之间的相关性,使用Pclass和Sex特征组合机中的Age中值预测Age值;
- 基于法一,使用基于Pclass和Sex组合集的均值和标准差之间的随机数来预测Age值;
- 引入随机噪声
# 绘制Age, Pclass, Sex复合直方图
#grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid = sns.FacetGrid(train_df, col='Pclass', hue='Sex')
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()
# 创建空数组
guess_ages = np.zeros((2,3))
guess_ages
# 遍历 Sex (0 或 1) 和 Pclass (1, 2, 3) 来计算六种组合的 Age 猜测值
for dataset in combine:
# 第一个for循环计算每一个分组的Age预测值
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & \
(dataset['Pclass'] == j+1)]['Age'].dropna()
# age_mean = guess_df.mean()
# age_std = guess_df.std()
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
age_guess = guess_df.median()
# 将随机年龄浮点数转换为最接近的 0.5 年龄(四舍五入)
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
# 第二个for循环对空值进行赋值
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\
'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head()
# 创建年龄段,并确定其与Survived的相关性
# 一般在建立分类模型时,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险
train_df['AgeBand'] = pd.cut(train_df['Age'], 5) # 将年龄分割为5段,等距分箱
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)
# 将这些年龄区间替换为序数
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4
train_df.head()
train_df = train_df.drop(['AgeBand'], axis=1) # 删除训练集中的AgeBand特征
combine = [train_df, test_df]
train_df.head()
test_df
结合SibSp和Parch特征创建一个新特征FamilySize,意为包括兄弟姐妹,配偶,父母,孩子和自己的所有家人数量。
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)
创建一个新特征,取值为0表示不是独自一人,取值为1表示独自一人
# 创建新特征IsAlone
for dataset in combine:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()
舍弃Parch,SibSp和FamilySize特征,转而支持IsAlone,因为IsAlone更能反映其与Survived的相关性
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]
train_df.head()
同样,我们可以创建一个新特征Age*Pclass,以此来结合Age和Pclass变量
# 创建Age*Pclass特征以此用来结合Age和Pclass变量
for dataset in combine:
dataset['Age*Pclass'] = dataset.Age * dataset.Pclass
train_df.loc[:, ['Age*Pclass', 'Age', 'Pclass']].head(10)
train_df[['Age*Pclass', 'Survived']].groupby(['Age*Pclass'], as_index=False).mean()
填补分类特征Embarked
登船港口特征Embarked,有三种可能取值S,Q,C。仅训练数据集有两个缺失值,采用众数填补缺失值。
freq_port = train_df.Embarked.dropna().mode()[0]
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)
# 同样转换分类特征为序数
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()
对票价Fare进行分箱并替换为序数
# 测试集中Fare有一个缺失值,用中位数进行填补
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()
plt.hist(train_df['Fare'])
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4) # 根据样本分位数进行分箱,等频分箱
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
train_df.head(10)
(6)构建模型并预测结果
我们的问题是想确定输出(幸存与否)与其他变量或特征(性别、年龄、票价等级…)之间的关系,这属于典型的分类和回归问题。
当使用给定的数据集训练我们的模型时,我们称为监督式学习的机器学习。这样,模型主要有:
逻辑回归
支持向量机
KNN 或 k-最近邻
朴素贝叶斯分类器
决策树
随机森林
感知机
人工神经网络
RVM 或相关向量机
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1).copy()
X_train.shape, Y_train.shape, X_test.shape
逻辑回归
逻辑回归是以线性回归为理论支持,但又通过sigmoid函数(逻辑回归函数)引入非线性因素,用来测量分类因变量和一个或多个自变量关系的模型,最常见的就是用来处理二分类问题。我们关注模型基于训练集生成的置信度分数。
# 逻辑回归模型
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test) # logreg.predict_proba(X_test)[:,1]
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
acc_log
可以使用逻辑回归中特征的系数,来验证我们对特征创建和完成目标的假设正确与否。
正系数会增加响应的对数几率(从而增加概率),而负系数会降低响应的对数几率(从而降低概率)。
Sex是最高的正系数,意味着随着性别值的增加(男性:0 到女性:1),Survived=1 的概率增加越多;
Title是第二高的正相关特征;
相反,随着 Pclass 的增加,Survived=1 的概率降低越多;
Age是第二高的负相关特征,即随着年龄的增加,Survived=1 的概率降低越多,幸存概率越小;
Age * Pclass 对应系数绝对值较小,可能不是一个很好的人工特征。
coeff_df = pd.DataFrame(train_df.columns.delete(0))
coeff_df.columns = ['Feature']
coeff_df["Correlation"] = pd.Series(logreg.coef_[0])
coeff_df.sort_values(by='Correlation', ascending=False)
支持向量机
支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,它的决策边界是对学习样本求解的最大边距超平面。最为常见的就是通过核函数的方法进行非线性分类。可以看到,该模型生成的置信度得分高于逻辑回归模型。
# 支持向量机模型
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_train, Y_train) * 100, 2)
acc_svc
KNN
k近邻算法是一种用于分类和回归的非参数方法。其基本思想是:在特征空间中,如果一个样本附近的k个最近样本的大多数属于某一个类别,则该样本也属于这个类别。可以看到,KNN 置信度得分优于逻辑回归,和 SVM 得分一样。
# KNN
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)
acc_knn
朴素贝叶斯分类器
朴素贝叶斯分类器是一系列以假设特征之间强独立下运用贝叶斯定理为基础的简单概率分类器。模型生成的置信度得分是目前评估的模型中最低的。
# 朴素贝叶斯分类器
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)
acc_gaussian
感知机
感知机 是一种用于监督学习二元分类器的算法(可以决定由数字向量表示的输入是否属于某个特定类的函数)。 它是一种线性分类器,即基于将一组权重与特征向量相结合的线性预测函数进行预测的分类算法。
# 感知机
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
acc_perceptron
# 线性SVC
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)
acc_linear_svc
# SDG随机梯度下降
sgd = SGDClassifier()
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_test)
acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)
acc_sgd
决策树
决策树是将特征(树枝)映射到目标值(树叶)的分类或回归方法。目标变量可以取一组有限值的树模型称为分类树;在这些树结构中,叶子代表类标签,分支代表导致这些类标签的特征的结合。目标变量可以取连续值的决策树称为回归树。模型置信度得分是目前最高的。
# 决策树
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
acc_decision_tree
# 决策树可视化
from sklearn import tree
import graphviz
import pydotplus
from IPython.display import Image
dot_data = tree.export_graphviz(decision_tree, out_file=None,
feature_names=X_train.columns,
class_names=['0','1'],
max_depth=3,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
dot_data = tree.export_graphviz(decision_tree, out_file=None,
feature_names=X_train.columns,
#class_names=['0','1'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("DTtree.pdf")
train_df[(train_df['Age*Pclass']>2.5) & (train_df['Fare']<=1.5)&(train_df['Fare']>0.5)&(train_df['IsAlone']>0.5)&(train_df['Age']>0.5)& \
(train_df['Embarked']<=1.5) &(train_df['Embarked']>0.5)&(train_df['Fare']<=2.5)&(train_df['Age']<=1.5)&(train_df['Pclass']>1.5)& \
(train_df['Title']<=1.5)]
随机森林
随机森林是一种用于分类、回归和其他任务的集成学习方法。它通过自助法(bootstrap)重采样技术,从原始训练样本集中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树,然后按以上步骤生成m棵决策树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于独立抽取的样本。模型置信度得分是目前评估的模型中最高的。
# 随机森林
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forest
(7)模型评估
我们现在可以对所有模型评估结果进行排名,以选择最适合我们问题的模型。 虽然决策树和随机森林的得分相同,但我们选择使用随机森林,因为它纠正了决策树过度拟合训练集带来的缺陷。
models = pd.DataFrame({
'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes', 'Perceptron',
'Stochastic Gradient Decent', 'Linear SVC',
'Decision Tree'],
'Score': [acc_svc, acc_knn, acc_log,
acc_random_forest, acc_gaussian, acc_perceptron,
acc_sgd, acc_linear_svc, acc_decision_tree]})
models.sort_values(by='Score', ascending=False)
总结 :
- 查看数据类型,数值型数据是否需要分箱(连续型数据),字符串型数据需要转化为数值型
- 查看特征分布
- 各个特征与预测值的相关性
- 从现有特征中提取新特征。(从姓名中衍生出新特征,并进行分箱),(年龄等距分箱)
- 一般在建立分类模型时,需要对连续变量离散化,特征离散化后,模型会更加稳定,降低了模型过拟合的风险
- 利用SIb和Parch新建特征
- 新建Age*Pclass特征