Redis 集群之主从模式
Redis 集群之主从模式
- 如何保证 Redis 的可靠性
- Redis 主从模式
-
- 为什么要采用读写分离的方式呢?
- 主从库间如何进行第一次同步?
-
- 从节点配置
- 第一阶段
- 第二阶段
- 第三阶段
- PSYN2.0
- 「主从级联模式」分担全量复制时的主库压力
-
- "主 - 从 - 从"模式
- 主从库间网络断了怎么办?
-
- 如何避免增量复制失效
- replication_buffer 与replication_backlog_buffer
-
- replication_buffer
- replication_backlog_buffer
如何保证 Redis 的可靠性
我们在前面一文读懂Redis持久化机制中分析了,如果服务器发生宕机,可以通过重新读入 RDB 文件或者回放 AOF 日志的方式恢复数据, 进而保证尽量少丢失数据,提升可靠性。
这里再次对两种持久化做一个简单的对比:
- AOF 记录的是每一次写命令,数据最全,但文件体积大,数据恢复速度慢。
- RDB 采用「二进制 + 数据压缩」的方式写磁盘,这样文件体积小,数据恢复速度也快。但是RDB的问题是,它执行快照的频率不好控制。频率太快会对系统带来性能影响,频率太慢就会造成更多的数据丢失。
Redis 4.0 以上的版本支持混合持久化 ,结合了二者的优势:
- RDB 以「二进制 + 数据压缩」方式存储,文件体积小;
- AOF 记录每一次写命令,数据最全。
经过这么一番优化,提高了数据恢复效率,当发生宕机时,我们就可以用持久化文件快速恢复 Redis 中的数据。
虽然我们已经把持久化的效率优化到最高了,但在数据恢复依旧是需要时间的,在这期间的业务应用还是会受到影响,该怎么办呢?
这就要提到 Redis 的高可靠性问题了。
Redis 的高可靠性需要做到两点保证:
- 数据尽量少丢失
- 服务尽量少中断
持久化只能保证前者,而对于后者,通常的做法就是「增加副本冗余量」。通过部署多个 Redis 实例,然后让这些实例数据保持实时同步,这样当一个实例宕机时,我们在剩下的实例中选择一个继续提供服务就好了。
这个方案也就是 Redis 的主从库模式。接下来我们分析一下 Redis 的「主从复制:多副本」。
Redis 主从模式
Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是「读写分离」的方式。
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。

为什么要采用读写分离的方式呢?
如果说从库也可以像主库一样,可以接收到写请求的话,一个直接的问题就是「数据不一致」。
例如客户端对同一个 key 连续修改了三次,这三次请求分别发送到三个不同的实例上。 那么,这个数据在这三个实例上的副本就不一致了(分别是 v1、v2 和 v3)。后续在读取这个数据的时候,就可能读取到旧的值。
如果要保持这个数据在三个实例上一致,就要涉及到加锁、实例间协商是否完成修改等一系列操作, 但这会带来巨额的开销,显然是不太能接受的。
采用「读写分离」,所有数据的修改只会在主库上进行,不用协调三个实例。 主库有了最新的数据后,会同步给从库,这样,主从库的数据就是一致的。
分析主从同步之前,我们需要弄清楚三个问题:
- 主从库同步是如何完成的呢?
- 主库数据是一次性传给从库,还是分批同步?
- 主从库间的网络断连了,数据还能保持一致吗?
接下来,我们首先来分析主从库间的第一次同步是如何进行的?这也是Redis 实例建立主从库模式后的规定动作。
主从库间如何进行第一次同步?
从节点配置
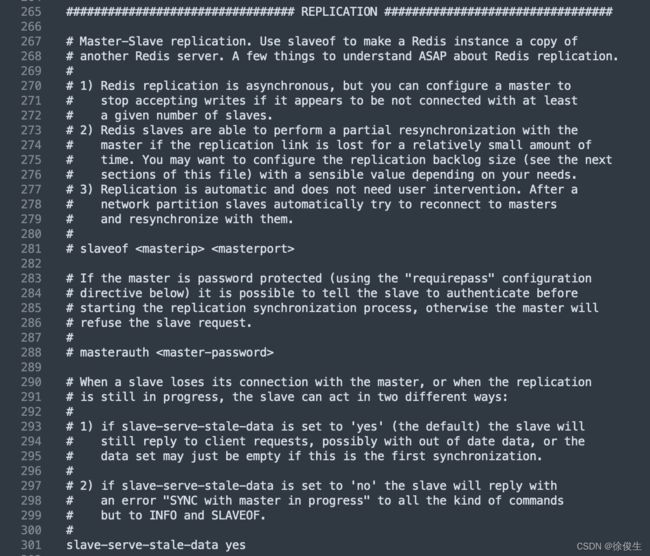
使用默认的配置启动机器,机器都是主节点。如果想要让机器变成从节点,需要在 conf 文件上配置主从复制的相关参数。
# 配置主节点的ip和端口
slaveof 192.168.1.1 6379
# 从redis2.6开始,从节点默认是只读的
slave-read-only yes
# 假设主节点有登录密码,是123456
masterauth 123456
主从库间数据第一次同步包含三个阶段,我们分析下。

第一阶段
第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。
命令格式:
PSYNC <runid> <offset>
具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。 psync 命令包含了主库的 runID 和复制进度 offset 两个参数。
psync是 Redis 2.8 版本提供的命令,用于解决sync「断线后重复制」的低效问题。
- runID:是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。 当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。
- offset:复制偏移量,此时设为 -1,表示第一次复制。
PSYNC ? -1表示全量复制。
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:「主库 runID」 和主库目前的「复制进度 offset」,返回给从库。 从库收到响应后,会记录下这两个参数,在下一次发送psync 命令时使用。
需要注意的是,
FULLRESYNC响应表示「第一次复制采用的全量复制」,也就是说,主库会把当前所有的数据都复制给从库。
如果主服务器返回的是+CONTINUE则表示需要进行「部分同步」。
第二阶段
在第二阶段,主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。
具体步骤如下:
- 主库收到完整重同步请求后,会在后台执行
bgsave命令,生成 RDB 文件,并使用一个「缓冲区:replication buffer」记录「从现在开始所有的写命令」。 - 当
bgsave命令执行完毕,主服务会将 RDB 文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。
为什么要有清空的动作?
这是因为从库在通过slaveof命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。
在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。 否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。 为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer ( 复制缓冲区),记录 RDB 文件生成后收到的所有写操作。
第三阶段
最后,也就是第三个阶段,主库会把第二阶段执行过程中新收到的写命令,再发送给从库。
具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
PSYN2.0
PSYN2.0 是 Redis 4.0 的 其中一个新特性。相比原来的 PSYN 功能,最大的变化就是支持两种场景下的部分重同步。
- slave 节点提升为 master 节点后,其他 slave 节点可以从新提升的 master 进行部分重同步;
- 另外一个场景就是slave重启后,可以进行部分重同步。
「主从级联模式」分担全量复制时的主库压力
通过上面分析「主从库间第一次数据同步」的过程,可以看到,一次全量复制,对于主库来说有两个耗时的操作:
- 生成 RDB文件;
- 传输 RDB 文件。
如果说从库数量很多,而且都要和主库进行全量复制的话,就会导致两个问题:
- 主库忙于 fork 子进程生成 RDB 文件,进行数据全量同步,fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。
- 生成 RDB 文件 需要耗费主服务器大量的CPU,内存和磁盘I/O资源。传输 RDB 文件也会占用主库的网络带宽,并对主服务器响应命令请求的时间产生影响。
那么,有没有好的解决方法可以分担主库压力呢?
其实是有的,这就是 「“主 - 从 - 从”模式」。
"主 - 从 - 从"模式
上面介绍的主从库模式,是所有的从库都是和主库连接,所有的全量复制也都是和主库进行的。
现在,我们可以通过「“主 - 从 - 从”模式」将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
简单来说,我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。 然后,我们可以再选择一些从库(例如三分之一的从库),在这些从库上执行如下命令,让它们和刚才所选的从库,建立起主从关系。
salveof 所选从库的IP 6379
这样一来,这些从库就会知道,在进行同步时,不用再和主库进行交互了,只要和级联的从库进行写操作同步就行了,这就可以减轻主库上的压力,如下图所示:

好了,到这里,我们分析了主从库间通过「全量复制」实现数据同步的过程,以及通过「“主 - 从 - 从”模式」分担主库压力的方式。 那么,一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库, 这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
听上去好像很简单,但不可忽视的是,这个过程中存在着风险点,最常见的就是网络断连或阻塞。如果网络断连,主从库之间就无法进行命令传播了, 从库的数据自然也就没办法和主库保持一致了,客户端就可能从从库读到旧数据。
接下来,我们就来聊聊网络断连后的解决办法。
主从库间网络断了怎么办?
在 Redis 2.8 之前,主从库是使用 sync 命令进行同步。如果在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大。
我们上面页提到了全量复制的影响:
- 生成 RDB文件:需要耗费主服务器大量的CPU,内存和磁盘I/O资源;
- 传输 RDB 文件:占用主库的网络带宽,并对主服务器响应命令请求的时间产生影响。
从 Redis 2.8 开始,网络断了之后,主从库会采用「增量复制」的方式继续同步。 听名字大概就可以猜到它和全量复制的不同:全量复制是同步所有数据,而增量复制只会把主从库网络断连期间主库收到的命令,同步给从库。
那么,增量复制时,主从库之间具体是怎么保持同步的呢?这个问题的答案和 repl_backlog_buffer (复制积压缓冲区)有关。
复制积压缓冲区:是主库维护的一个固定长度的队列,默认大小是1MB。
我们先来分析下主从库增量同步的流程。
1)、当主从库进行数据同步时,主库会把 RDB 通信期间收到新的操作命令写入 replication buffer,同时也会把这些操作命令也写入 repl_backlog_buffer 这个缓冲区。
repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
2)、刚开始的时候,主库和从库的写读位置在一起,也就是「复制偏移量」相同,这算是它们的起始位置。 随着主库不断接收新的写操作,它在缓冲区中的写位置会逐步偏离起始位置,我们通常用偏移量来衡量这个偏移距离的大小,对主库来说,对应的偏移量就是 master_repl_offset。 主库接收的新写操作越多,这个值就会越大。
同样,从库在复制完写操作命令后,它在缓冲区中的读位置也开始逐步偏移刚才的起始位置, 此时,从库已复制的偏移量 slave_repl_offset 也在不断增加。正常情况下,这两个偏移量基本相等。
3)、如果发生从库断线,在重启之后,主从库的连接恢复,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库, 主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距。如果发现在 slave_repl_offset 之后的数据仍然存在于复制积压缓冲区里面,主库发送 +CONTINUE 回复,表示进行增量复制。
如下图所示:

这里有一个地方需要重点考虑。
因为 repl_backlog_buffer 是一个环形缓冲区,所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。 如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致不能进行增量复制,必须采用全量复制。
因此要想办法避免这一情况,一般而言,我们可以调整配置文件中 repl-backlog-size 这个参数。
如何避免增量复制失效
Redis 为复制积压缓冲区设置的默认大小是 1MB。如果主库需要执行大量的写命令,又或者断线后需要重连的时间比较长,这个大小显然不合适。
我们可以根据: second * write_size_per_second 公式来估算缓冲区的「最小」大小。
- second :从库断线后重新连上主库所需的平均时间,单位:秒;
- write_size_per_second:主库平均每秒产生的写命令数据量。
我们在实际应用中,考虑到可能存在一些突发的请求压力,我们通常需要把这个缓冲空间扩大一倍,即 repl-backlog-size = second * write_size_per_second * 2。
举个例子,如果主库每秒产生1 MB的写数据,从库断线后平均要 5 秒才能重新连上主库。这就至少需要 5 MB 的缓冲空间。 否则,新写的命令就会覆盖掉旧操作了。为了应对可能的突发压力,我们最终把 repl-backlog-size 设为 10 MB。
这样一来,增量复制时主从库的数据不一致风险就降低了。不过,如果并发请求量非常大,连两倍的缓冲空间都存不下新操作请求的话,此时,主从库数据仍然可能不一致。
针对这种情况,一方面,可以根据 Redis 所在服务器的内存资源再适当增加 repl-backlog-size 值,比如说设置成缓冲空间大小的 4 倍, 另一方面,可以考虑使用切片集群来分担单个主库的请求压力。
replication_buffer 与replication_backlog_buffer
replication_buffer
对于客户端或从库与 Redis 通信,Redis 都会分配一个内存 buffer 进行数据交互。所有数据交互都是通过这个buffer进行的。Redis先把数据写入这个buffer中,然后再把buffer中的数据发到 client socket 中再通过网络发送出去,这样就完成了数据交互。
所以主从在增量同步时,从库作为一个client,也会分配一个buffer,只不过这个buffer专门用来传播用户的写命令到从库,保证主从数据一致。我们通常把它叫做 Replication Buffer。
Redis 通过client-output-buffer-limit 参数设置这个buffer的大小。主库会给每个从库建立一个客户端,所以 replication buffer 不是共享的,而是每个从库都有一个对应的客户端。
如果主从在传播命令时,因为某些原因从库处理得非常慢,那么主库上的这个buffer就会持续增长,消耗大量的内存资源,甚至OOM。
所以Redis提供了client-output-buffer-limit参数限制这个buffer的大小,如果超过限制,主库会强制断开这个client的连接,
也就是说从库处理慢导致主库内存buffer的积压达到限制后,主库会强制断开从库的连接,
此时主从复制会中断,中断后如果从库再次发起复制请求,那么此时可能会导致恶性循环,引发复制风暴,这种情况需要格外注意。
replication_backlog_buffer
和 replication_buffer 不一样,repl_backlog_buffer 是所有从库共享的,slave_repl_offset 由从库自己记录的,这也是因为每个从库的复制进度不一定相同。从库断连后再恢复时,会给主库发送 psync 命令,并把自己当前的slave_repl_offset 发给主库。slave_repl_offset 指向的数据没有被覆盖,就能继续恢复。如果从库断开时间过长,repl_backlog_buffer环形缓冲区会被主库的写命令覆盖,那么从库重连后只能全量同步。
好了,关于主从复制的问题我们就分析到这里了。如果你还想看更多优质原创文章,欢迎关注我的公众号「ShawnBlog」。