Dubbo 远程调用
本章主要内容:
• Dubbo核心调用流程;
• Dubbo协议详解;
• Dubbo编解码器原理;
• Telnet调用原理;
• Dubbo线程模型。
1 Dubbo调用介绍
在讲解Dubbo中的RPC调用细节之前, 我们先回顾一次调用过程经历了哪些处理步骤。如果我们动手写简单的RPC调用, 则需要把服务调用信息传递到服务端, 每次服务调用的一些公用的信息包括服务调用接口、 方法名、 方法参数类型和方法参数值等, 在传递方法参数值时需要先序列化对象并经过网络传输到服务端, 在服务端需要按照客户端序列化顺序再做一次反序列化来读取信息, 然后拼装成请求对象进行服务反射调用, 最终将调用结果再传给客户端
在Dubbo中实现调用也是基于相同的原理, 下面看一下Dubbo在一次完整的RPC调用流程中经过的步骤, 如图6.1所示。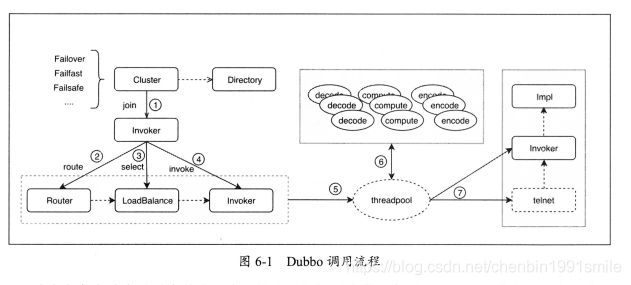
首先在客户端启动时会从注册中心拉取和订阅对应的服务列表, Cluster会把拉取的服务列表聚合成一个Invoker,每次RPC调用前会通过Directory#list获取providers地址(已经生成好的Invoker列表) , 获取这些服务列表给后续路由和负载均衡使用。 对应图6.1,在①中主要是将多个服务提供者做聚合。 在框架内部另外一个实现Directory接口是RegistryDirectory类, 它和接口名是一对一的关系(每一个接口都有一个RegistryDirectory实例) , 主要负责拉取和订阅服务提供者、 动态配置和路由项。
在Dubbo发起服务调用时, 所有路由和负载均衡都是在客户端实现的。 客户端服务调用首先会触发路由操作, 然后将路由结果得到的服务列表作为负载均衡参数, 经过负载均衡后会选出一台机器进行RPC调用, 这3个步骤依次对应于②、 ③和④。 客户端经过路由和负载均衡后,会将请求交给底层I/O线程池(比如Netty)处理, I/O线程池主要处理读写、 序列化和反序列化等逻辑, 因此这里一定不能阻塞操作, Dubbo也提供参数控制(decode.in.io)参数, 在处理反序列化对象时会在业务线程池中处理。 在⑤中包含两种类似的线程池, 一种是I/O线程池(Netty),另一种是Dubbo业务线程池(承载业务方法调用) 。
2 Dubbo协议详解
本节我们讲解Dubbo协议设计, 其协议设计参考了现有TCP/IP协议, 在阅读图6-2时, 我们发现一次RPC调用包括协议头和协议体两部分。 16字节长的报文头部主要携带了魔法数(0xdabb),以及当前请求报文是否是Request、 Response>心跳和事件的信息, 请求时也会携带当前报文体内序列化协议编号。 除此之外, 报文头部还携带了请求状态, 以及请求唯一标识和报文长度


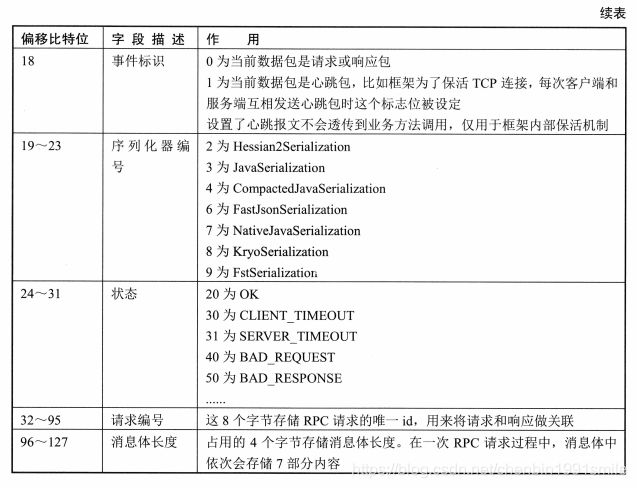
我们知道在网络通信中(基于TCP)需要解决网络粘包/解包的问题, 一些常用解决办法比如用回车、 换行、 固定长度和特殊分隔符等进行处理, 通过对前面协议的理解, 我们很容易发现Dubbo其实就是用特殊符号0xdabb魔法数来分割处理粘包问题的。
在实际使用场景中, 客户端会使用多线程并发调用服务, Dubbo是如何做到正确响应调用线程的呢? 关键点在于协议头全局请求id标识, 我们先来看一下原理图, 如图6-3
当客户端多个线程并发请求时, 框架内部会调用DefaultFuture对象的get方法进行等待。在请求发起时, 框架内部会创建Request对象, 这个时候会被分配一个唯一 id, DefaultFuture可以从Request对象中获取id,并将关联关系存储到静态HashMap中, 就是图6-3中的Futures集合。 当客户端收到响应时, 会根据Response对象中的id,从Futures集合中查找对应DefaultFuture对象, 最终会唤醒对应的线程并通知结果。 客户端也会启动一个定时扫描线程去探测超时没有返回的请求
3编解码器原理
Dubbo目前的协议格式, 有了标准协议约束, 我们需要再探讨Dubbo是怎么实现编解码的。 在讲解编解码实现前, 先熟悉一下编解码设计关系, 如图6-4所示。
在图6-4中,AbstractCodec主要提供基础能力, 比如校验报文长度和查找具体编解码器等。TransportCodec主要抽象编解码实现, 自动帮我们去调用序列化、 反序列实现和自动cleanup流。我们通过Dubbo编解码继承结构可以清晰看到, DubboCodec继承自ExchangeCodec,它又再次继承了 TelnetCodec实现。 我们前面说过Telnet实现复用了 Dubbo协议端口, 其实就是在这层编解码做了通用处理。 因为流中可能包含多个RPC请求, Dubbo框架尝试一次性读取更多完整报文编解码生成对象, 也就是图中的DubboCountCodec,它的实现思想比较简单, 依次调用DubboCodec去解码, 如果能解码成完整报文,则加入消息列表, 然后触发下一个Handler方法调用
4 Telnet调用原理
有了编解码器实现的基础, 再理解Telnet处理就容易多了。 编解码器处理有三种场景: 请求、 响应和Telent调用。 理解Telnet调用并不难, 编解码器主要把Telnet当作明文字符串处理,按照Dubbo的调用规范, 解析成调用命令格式, 然后查找对应的Invoker,发起方法调用即可。
4.2 Telnet实现健康监测
Telnet提供了健康检查的命令, 可以在Telnet连接成功后执行status -1查看线程池、 内存和注册中心等状态信息。 为了完成线程池监控、 内存和注册中心监控等诉求, Telnet提供了新的扩展点Statuschecker,如代码清单6-12所示
代码清单6・12健康检查扩展点
@SPI
public interface Statuschecker (
Status check();
)
5 ChannelHandler
如果读者熟悉Netty框架, 那么很容易理解Dubbo内部使用的ChannlHandler组件的原理,Dubbo框架内部使用大量Handler组成类似链表, 依次处理具体逻辑, 比如编解码、 心跳时间戳和方法调用Handler等。 因为Netty每次创建Handler都会经过ChannelPipeline,大量的事件经过很多Pipeline会有较多的开销, 因此Dubbo会将多个Handler聚合为一个Handler
5.1 核心Handler和线程模型
在讲解核心Handler之前, 我们先通过表6-5看一下Dubbo中Handler (ChannelHandler)的5种状态。


Dubb。 为了编织这些Handler,适应不同的场景, 提供了一套可以定制的线程模型。 为了使概念更清晰, 我们描述的I/O线程是指底层直接负责读写报文, 比如Netty线程池。 Dubbo中提供的线程池负责业务方法调用, 我们称为业务线程。 如果一些事件逻辑可以很快执行完成, 比如做个标记而已, 则可以直接在I/O线程中处理。 如果事件处理耗时或阻塞, 比如读写数据库操作等, 则应该将耗时或阻塞的任务转到业务线程池执行。 因为I/O线程用于接收请求, 如果I/O线程饱和, 则不会接收新的请求。
我们先看一下Dubbo中是如何实现线程派发的, 如图6-6所示:

在图6-6中, Dispatcher就是线程池派发器。 这里需要注意的是, Dispatcher真实的职责是创建具有线程派发能力的 ChannelHandler,比如 AllChannelHandler > MessageOnlyChannelHandler和ExecutionChannelHandler等, 其本身并不具备线程派发能力。Dispatcher属于Dubbo中的扩展点, 这个扩展点用来动态产生Handler,以满足不同的场景。 目前Dubbo支持以下6种策略调用, 如表6-7所示。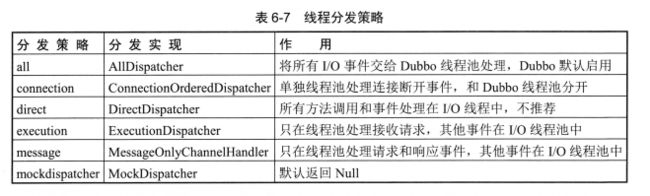
具体业务方需要根据使用场景启用不同的策略。 建议使用默认策略即可, 如果在TCP连接中需要做安全加密或校验, 则可以使用ConnectionOrderedDispatcher策略。 如果引入新的线程池, 则不可避免地导致额外的线程切换, 用户可在Dubbo配置中指定dispatcher属性让具体策略生效。
5.3 Dubbo 心跳 Handler
Dubbo默认客户端和服务端都会发送心跳报文, 用来保持TCP长连接状态。 在客户端和服务端, Dubbo内部开启一个线程循环扫描并检测连接是否超时, 在服务端如果发现超时则会主动关闭客户端连接, 在客户端发现超时则会主动重新创建连接。 默认心跳检测时间是60秒, 具体应用可以通过heartbeat进行配置。
备注:文章参考《深入理解Apache Dubbo与实战》,作者:林琳,诣极