随笔感悟:Mysql悲观锁和乐观锁
目录
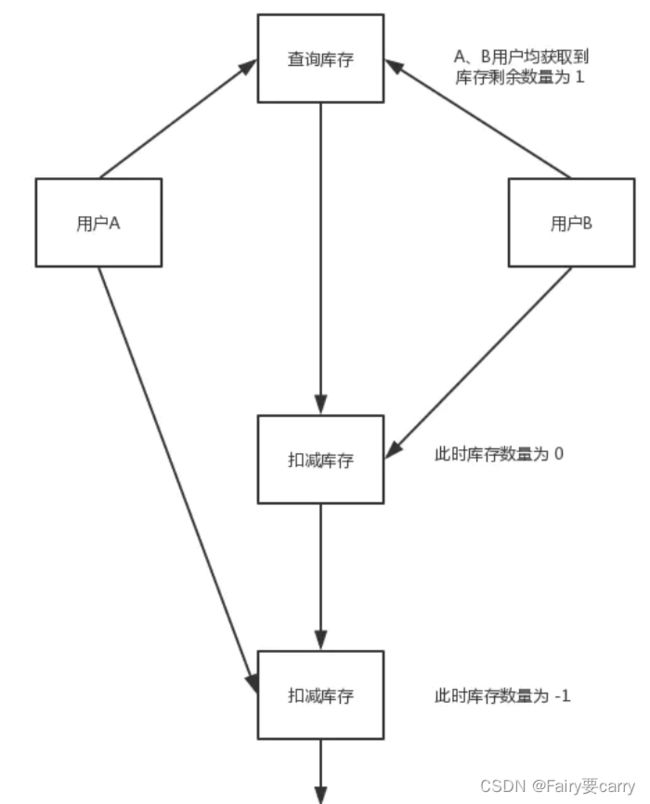
首先是场景:并发控制
悲观锁
select ... for update的使用
乐观锁
解释:
特点:
实现:
sql演示例子:
结合我们的Java代码的实现
以上更新语句存在一个比较严重的问题,即ABA问题:
解决方式:
优化
首先是场景:并发控制
为什么要使用悲观锁和乐观锁——>为了并发情况下,线程跟自己在单机情况一样得到相同的结果,保证数据的一致性;
没做好并发控制就会可能出现:脏读、不可重复读、幻读等问题;
结论:乐观锁适合并发量比较小的场景(读多写少),悲观锁适合并发量比较大的场景(写多多少);
悲观锁
目的:在并发时保证线程和单机时结果一样(宏观);当在数据库中修改某条数据时,防止同时被其他人进行修改从而造成数据不一致(微观);——>(处理:加锁防止并发,利用锁,线程锁住资源防止被其他人修改);
场景:有点像警察处理凶杀现场,对凶杀现场(资源对象)进行上锁,防止其他人对其现场进行修改;
特点:具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度
实现:像我们的表锁、行锁都是悲观锁,在java中就是synchronized关键字实现

然后我们悲观锁主要分为共享锁和排他锁
- 共享锁【shared locks】又称为读锁,简称 S 锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁【exclusive locks】又称为写锁,简称 X 锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁。获取排他锁的事务可以对数据行读取和修改。(比如行锁和表锁)
例子:
1.首先事务1先开启事务——>2.然后事务2开启事务,事务1修改id=10001的数据——>3.然后事务2修改同样为id=10001的数据发现阻塞——>结论:验证了id=10001被行锁锁住了(如果没有索引的话就是表锁)


5. 最后事务1回滚,释放锁资源,事务2又可以执行了

select ... for update的使用
1.事务1先开启事务查询id=10001的数据——>2.事务2开启查询事务1一样的数据发现阻塞——>3.然后事务1回滚或者commit即可


乐观锁
解释:
乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候(重点),才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量
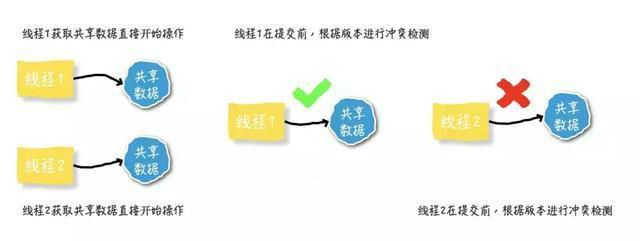
特点:
1.更加宽松,性能较好,吞吐量较高,有效避免了死锁等现象
2.但是可能会出现cpu空转的现象,造成cpu飙高
可能会出现线程一直retry,并且ABA问题也会出现,中途被其他线程改了比较的version,然后又改回来,中途做了其他事情
实现:
1.CAS实现
2.版本号控制,一般像我们mysql中在表中加一个字段version版本号:表示数据被修改的次数;当数据被修改时,verson+1;在线程更新时,在读取数据的时候也要读取version,在提交更新时,若刚才读取到的version值和当前数据库中的version值相等才更新,否则retry;
sql演示例子:
当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。比如前面的扣减库存问题,通过乐观锁可以实现如下
//1.查询数据的sql
select * from tb_item_stock where item_id=10001;
//2.修改数据的sql
update tb_item_stock set stock=stock+1,version=version+1 where item_id=10001 and version=1;事务1:先select一下看下版本,下面图片是事务1第二次select(也就是在事务2提交更新sql后的一个操作)
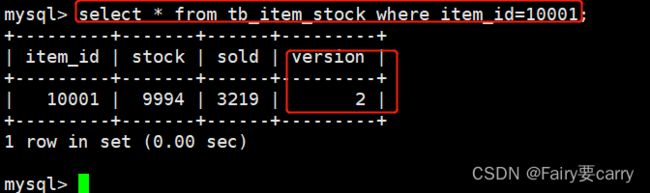
事务2:

结合我们的Java代码的实现
/**
* 模拟多版本号
*/
@Transactional
public void deduct2(){
//1.首先查询仓库里面的内容
List stocks = this.stockMapper.queryStock("10001");
//获取第一条仓库记录
Stock stock = stocks.get(0);
//2.判断仓库是否充足
if(stock!=null&&stock.getStock()>0){
//2.1扣减库存,然后设置新的版本号进行更新
stock.setStock(stock.getStock()-1);
Integer version = stock.getVersion(); //获取当前商品版本
stock.setVersion(version+1); //更新一次版本加一次,如果中途有其他的更新操作就会失败
//2.2然后进行更新——>需要进行判断如果更新影响行数为0就进行cas操作
if(this.stockMapper.update(stock,new UpdateWrapper()
.eq("item_id",stock.getItemId())
.eq("version",version))==0){
this.deduct2();//cas
}
} 以上更新语句存在一个比较严重的问题,即ABA问题:

- 比如说线程一从数据库中取出库存数 3,这时候线程二也从数据库中取出库存数 3,并且线程二进行了一些操作变成了 2。
- 然后线程二又将库存数变成 3,这时候线程一进行 CAS 操作发现数据库中仍然是 3,然后线程一操作成功。
- 尽管线程一的 CAS 操作成功,但是不代表这个过程就是没有问题的。
解决方式:
我们可以加一个时间戳,因为时间戳天然具有顺序递增性;
还一个场景,就是一旦遇上高并发的时候,就只有一个线程可以修改成功,那么就会存在大量的失败。对于像淘宝这样的电商网站,高并发是常有的事,总让用户感知到失败显然是不合理的。所以,还是要想办法减少乐观锁的粒度。一个比较好的建议,就是减小乐观锁力度,最大程度的提升吞吐率,提高并发能力!

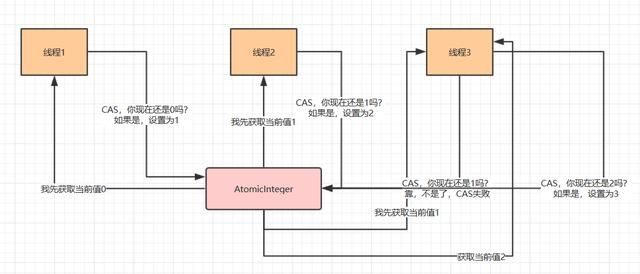
比如我们的AutomicInteger就是利用cas
public final boolean compareAndSet(int expectedValue, int newValue) {
return U.compareAndSetInt(this, VALUE, expectedValue, newValue);
}优化
LongAdder,它就是尝试使用分段 CAS 以及自动分段迁移的方式来大幅度提升多线程高并发执行 CAS 操作的性能,这个类具体是如何优化性能的呢?如图:
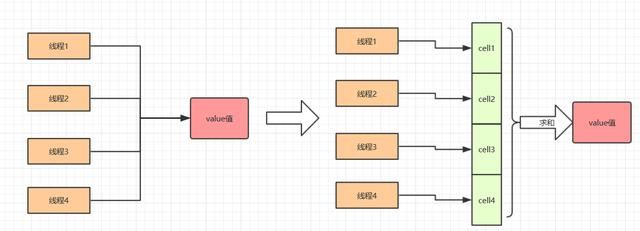
LongAdder 核心思想就是热点分离,这一点和 ConcurrentHashMap 的设计思想相似。就是将 value 值分离成一个数组,当多线程访问时,通过 hash 算法映射到其中的一个数字进行计数。而最终的结果,就是这些数组的求和累加。这样一来,就减小了锁的粒度
(41条消息) LongAdd_Fairy要carry的博客-CSDN博客_longadd