(二分, 三分, 矩阵, 矩阵运算及二进制 , 栈和队列)北理工集训 Day1—Day3
目录
一、二分
二、三分查找
三、矩阵,矩阵运算及二进制
四、栈和队列
很荣幸在暑假参加学校举办的北理工与我们学院联合举办的为期半个月的集训。
集训前三天是北理工的三个大一学生给我们讲课,每一个人都特别特别的厉害,参加ACM拿到亚洲区金奖银奖的那种,那么三天的时间虽然真的很短暂,但是收获却是巨大的。
首先整理一下这三天系统知识的收获,相应的一些算法题目在另外两篇文章单独整理出来放在北理工专栏,感兴趣的可以看看。
简单总结一下:第一天讲了二分,三分;第二天讲了矩阵,矩阵运算及二进制的运算;第三天讲了栈和队列以及C++的Stack类、C++里的queue、C里的String字符串类、C里的set、begin、map等接下来详细的对这些点做以总结。
一、二分
1、首先用几张图反应一下二分的思想:
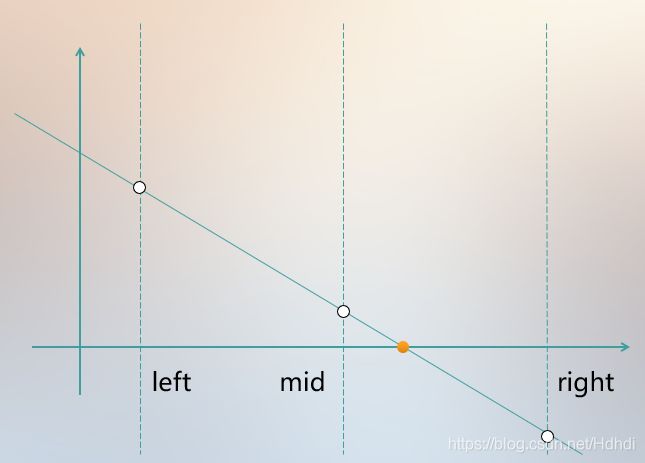
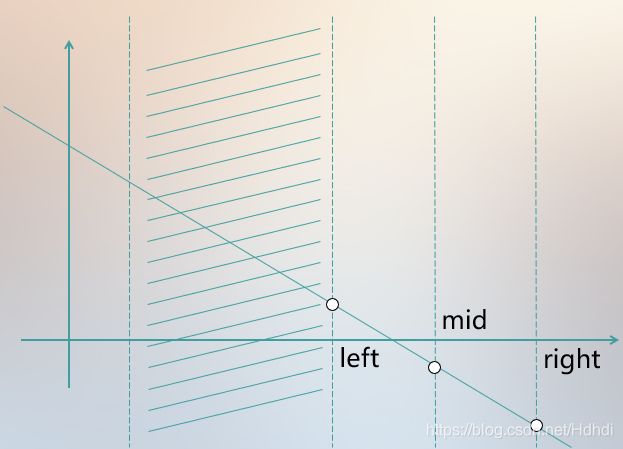
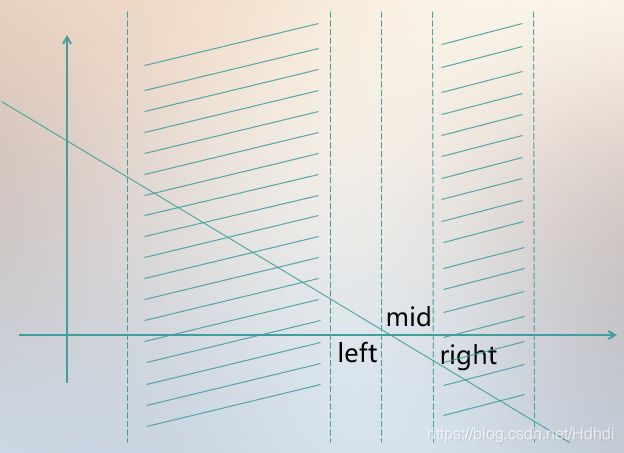
2、二分的定义:
#define eps 1e-6(eps :浮点运算误差限)
double search(){
double left = LEFT, right = RIGHT, mid;
while(right – left > eps) {
mid = (right + left) / 2;
if(fun(mid) > 0)
left = mid;
else
right = mid;
}
return mid;
}
3、二分条件:
①函数具有单调性
②若当前解不可行,则大于(或小于)当前解的所有解都不可行
4、二分枚举长度:
计算出可以分成的段数t,如果t>=k, 在长度大的半部分二分,如果t 5、二分查找 给出一个已知元素不断递增的数组,求大于或者等于x的第一个数 如:a[]={1,3,4,7,8,10},x=5 6、整数和小数二分法的区别 •整数和小数二分都是为求得结果而渐次逼近的方法,但二者之间在实现上有微小差别。 •1、终止条件不同 •2、二分区间修改方法不同 •3、结果返回不同 1、与二分查找的比较 •二分查找所面向的搜索序列的要求是:具有单调性(不一定严格单调);没有单调性的序列不是使用二分查找。 •与二分查找不同的是,三分法所面向的搜索序列的要求是:序列为一个凸性函数。通俗来讲,就是该序列必须有一个最大值(或最小值),在最大值(最小值)的左侧序列,必须满足不严格单调递增(递减),右侧序列必须满足不严格单调递减(递增)。如下图,表示一个有最大值的凸性函数: 2、算法过程: (0)当前已知一个最值可能存在的区间 (1)取区间的两个三等分点,将整个区间分成三块 (2)比较两个三等分点处的函数值,根据函数凹凸性和函数值的大小关系判断,排除三块区间中的最左侧区间或最右侧区间 ( 3)将最值可能存在的区间更新,缩小至原来的2/3 (4)重复(1)(2)(3)过程,直到区间长度在允许的相对误差限以内,即可将区间内任意值视作最值位置的估计值 其中(2)过程举例: 3、分析: 上凸函数取两个三等分点: 峰值在最左边的区间内 -> 第一个三等分点的函数值大于第二个 第一个三等分点的函数值大于第二个 -> 峰值不可能在最右边 1、算2的74次方可以把它拆开计算 2、二进制最后一位是1还是0取决于它是奇数还是偶数 3、当二进制除2末尾的1就没了eg:74(1001010),75(1001011) 4、当二进制的某一位是1时就是2的多少次方,eg:1001010就是 eg: 5、 不断地判断二进制最后一位是1还是0 过程: long long是C++的正式标准,这也就意味着,该类型不会因为编译器或者开发平台的不同而有所差异,放之四海而皆准,而且与一些系统函数、类库都有很好的交互(如常见的printf、scanf、cin和cout等)。与之相反,出身MS的__int64就有点不受待见了,在不同的编译器上可能水土不服。 6、矩阵相乘 7、斐波那契数列 1.栈 2.队列 3.栈和队列的区别 4、C里的Stack类 实现一种先进后出的数据结构,是一个模板类. C++ Stack(堆栈) 是一个容器类的改编,为程序员提供了堆栈的全部功能,——也就是说实现了一个先进后出(FILO)的数据结构。 头文件 #include 5、C里的queue queue,即"队列",和我们平时的"排队"有所类似,是一个先进先出的容器。 queue 模板类的定义在 6、C里的String字符串类 相较于C,C++中引入了string类,这使得存储字符串时不易溢出,更加安全, 而其中包含的各种操作字符串的函数,使用起来更是方便。下面是其中几种常见的函数的使用方法: 7、C里的set set 从set中查找同样可以使用count()函数和find()函数 与map不同,set中数据只能通过insert()函数进行插入。 8、C里的map C++中map容器提供一个键值对容器,map与multimap差别仅仅在于multiple允许一个键对应多个值,C++中map容器提供一个键值对容器. map的功能:自动建立key - value的对应。key 和 value可以是任意你需要的类型,包括自定义类型。 C++实际开发的过程会经常使用到map。map是一个key-value值对,key唯一,可以用find进行快速的查找。其时间复杂度为O(logN),如果采用for循环进行遍历数据时间复杂度为O(N)。如果map中的数据量比较少时,采用find和for循环遍历的效率基本没有太大的区别,但是在实际的开发过程中,存储在map中的数据往往是大量的,这个时候map采用find方式效率比遍历效率高的多。 ps:我遇到的疑问及得到的答案 ①C语言问题%f和%lf的区别? %f和%lf分别是float类型和double类型用于格式化输入输出时对应的格式符号。 在用于输出时: 在用于输入时: 所以在输入输出时,一定要区分好double和float,而使用对应的格式符号。 因为C语言的%f是浮点型函数的占位符,%If是长浮点型函数的占位符 ②CString与string的区别? 相同点:他们都可以取代对 char* 的使用 ③&在C语言中什么意思? “&”在C语言中是指“异”“或”的意思。 1)&是逻辑语言,逻辑上表示两者属于缺一不可的关系,还可以表示一个人和另外一个人之意,与and同义。如A&B,表示A与B,A和B,A+B。 2)字符 & 的最早历史可以追溯到公元1世纪,最早是拉丁语et (意为and)的连写。最早的 & 很像 E 和 T 的组合,随着印刷技术的发展,这个符号逐渐形成自己的样式并脱离其原始影子。在这个字符中,仍能看出E的影子,但是T已经消失不见。 3)在18世纪时,人们常在&后紧随一个小写的c,表示etc(et cetera,同为拉丁语,表示等等,其他。在欧洲语言中广泛使用)。 ④puts()的功能? puts()函数用来向标准输出设备屏幕输出字符串并换行。 具体是把字符串输出到屏幕上,将‘\0’转换为回车换行。调用方式是:puts(str)。其中str是字符串数组名或者字符串指针。实际上,数组名就是指针。 puts输出一串字符串后,会自动换行,不需要再加一个\n。自动换行。 以上就是这三天的一些收获,除此之外最大的感受就是觉得自己非常的菜,代码练的太少了,知识上的收获不是很多,思想上的转变很大,总之,在剩下的大学时光里一定要好好利用时间,加油! 持续更新..... ♥♥♥每天提醒自己,自己就是个菜鸡! ♥♥♥已经看到最后啦,如果对您有帮助留下的每一个点赞、收藏、关注是对菜鸡创作的最大鼓励❀ ♥♥♥有相关问题可以写在评论区,一起学习,一起进步。 ♥♥♥#include #define eps 1e-6
double search(){
double left = LEFT, right = RIGHT, mid;
while(right – left > eps) {
mid = (right + left) / 2;
if(fun(mid) > 0)
left = mid;
else
right = mid;
}
return mid;
}
int solve() {
//ret记录满足条件的最优解
int left =0,right=sum / k, ret = 0;
while(left <= right) {
mid = left + (right - left) / 2;
if(count(mid) >= k){
ret = mid;
left = mid + 1;
}
else
right = mid - 1;
}
return ret;
}
二、三分查找

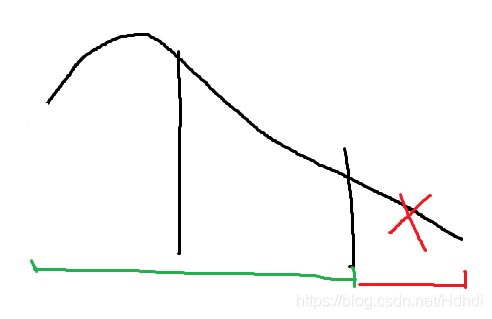
峰值在最右边的区间内 -> 第一个三等分点的函数值小于第二个
峰值在中间区间内 -> 任意情况
第一个三等分点的函数值小于第二个 -> 峰值不可能在最左边
两个函数值相等 -> 峰值只会在中间区间三、矩阵,矩阵运算及二进制
#include#include#include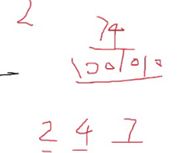 2 4 7代表第2 4 7 位是1
2 4 7代表第2 4 7 位是1![]()

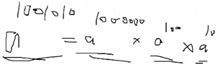
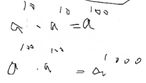
int ans=1,base=a;
while(b!=0){
int x=b%2;
if (x==1){
ans=ans*base;
}
base=base*base;
b/=2;
} →
→  →
→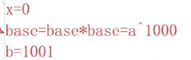 →
→
#include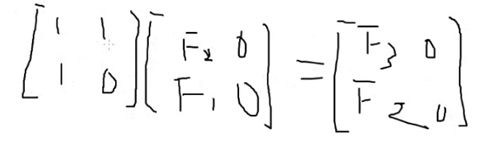
#include#include 四、栈和队列
(1)栈:栈实际上是一种线性表,它只允许在固定的一段进行插入或者删除元素,在进行数据插入或者删除的一段称之为栈顶,剩下的一端称之为栈顶。其遵循的原则是后进先出。
(2)栈的核心操作:三大核心操作,入栈,出栈,取栈顶元素
(3)对于栈的形象理解:子弹的弹夹我们一定见过,子弹在被压入的时候就相当于是一个个元素,而弹夹就相当于是栈。先被压入的子弹是最后被打出的,先压入的元素是最后出来的,也就是后进先出。
(1)队列:首先队列也是一种特殊的线性表,它允许在一端进行插入数据,在另一端进行删除数据的。队列里边有队首,队尾,队首元素。其遵循的原则是先进先出。
(2)队列的核心操作:三大核心操作分别是入队列,出队列,取队首元素。
(3)对于队列的形象理解:火车穿越隧道,火车的头相当于是队列的首,火车的尾相当于是队列的尾部。火车在穿越隧道的时候,头部先进入隧道头部也先出隧道,尾部后进入尾部后出隧道。队列也就是先入的元素先出队列,后进入的元素后出队列。
(1)栈和队列的出入方式不同:栈是后进先出、队列是先进先出。
(2)栈和队列在具体实现的时候操作的位置不同:因为栈是后进先出,它在一段进行操作;而队列是先进先出,实现的时候在两端进行。在Java标准库中实现队列时是按照链表实现的。#include
与stack 模板类很相似,queue 模板类也需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是可选的,默认为deque 类型。
queue 的基本操作有:
入队,如例:q.push(x); 将x 接到队列的末端。
出队,如例:q.pop(); 弹出队列的第一个元素,注意,并不会返回被弹出元素的值。
访问队首元素,如例:q.front(),即最早被压入队列的元素。
访问队尾元素,如例:q.back(),即最后被压入队列的元素。
判断队列空,如例:q.empty(),当队列空时,返回true。
访问队列中的元素个数,如例:q.size()#include
在C++中字符串变量和其他类型变量一样,必须先定义后使用,定义字符串变量要用类名string.#include#include#include
set对象的定义和初始化方法包括:
set
set
其中,b和e分别为迭代器的开始和结束的标记。#include#include
其中:float,单精度浮点型,对应%f。
double,双精度浮点型,对应%lf。
float类型可以使用%lf格式,但不会有任何好处。
double类型如果使用了%f格式可能会导致输出错误。
double 类型使用了%f格式,会导致输入值错误。
float类型使用double类型不仅会导致输入错误,还可能引起程序崩溃。
看定义就知道了,string是新标准,定义了namespace std;而cstring虽然也是新标,但是定义中包含的是string.h。
string中可以进行+ = += >等运算,而cstring中不能进行相关运算。
都封装了有丰富的字符串操作接口
他们都是 C++ 的类库
不同之处:CString 类是微软的 visual c++ 提供的 MFC 里面的一个类,所以只有支持 MFC 的工程才可以使用。如在 linux 上的工程就不能用 CString 了,只能用标准 C++ 中的 string 类了。另外,因为 string 类是在 c++ 标准库,所以它被封装在了 std 命名空间中,使用之前需要声明 using namespace std ,而 CString 类并不在 std 命名空间中,因为它不是 c++ 的标准库,只是微软的一个封装库,只是微软的一个封装库。这点看来用 string 类的程序的一致性更好。
string类既是一个标准 c++ 的类库,同时也是STL(Standard Template Library,标准模板库)中的类库,所以支持Iterator操作。
CString 类和 string 类提供的方法接口并不完全相同,所以不要糊里糊涂的认为某个类中怎么没有另外一个类中的方法啊。
他们和char*之间的转换方法也不一样。