梯度下降(Gradient descent)算法详解
梯度下降(Gradient descent)算法详解
说起梯度下降算法,其实并不是很难,它的重要作用就是求函数的极值。梯度下降就是求一个函数的最小值,对应的梯度上升就是求函数最大值。为什么这样说呢?兔兔之后会详细讲解的。
虽然梯度下降与梯度上升都是求函数极值的算法,为什么我们常常提到“梯度下降”而不是梯度上升“呢?主要原因是在大多数模型中,我们往往需要求函数的最小值。比如BP神经网络算法,我们得出损失函数,当然是希望损失函数越小越好,这个时候肯定是需要梯度下降算法的。梯度下降算法作为很多算法的一个关键环节,其重要意义是不言而喻的。
算法思想
梯度下降算法的思想是:先任取点(x0,f(x0)),求f(x)在该点x0的导数f"(x0),在用x0减去导数值f"(x0),计算所得就是新的点x1。然后再用x1减去f"(x1)得x2…以此类推,循环多次,慢慢x值就无限接近极小值点。
具体是有公式推导的,不过比较麻烦。其实这个算法是可以直观理解的。比如对于函数f(x)=x**2,当x大于0时,导数大于零,x减去导数值后变小;只要x大于零,每次减去一个大于零的导数,x值肯定变小。当x小于零时,导数小于零,减去小于零的数后x值增加,所以无论x0起始于何处,最终都能走到极值点0处。只不过有可能从单侧趋近(像走楼梯一样下降),也可能x一会儿大于极值点,一会儿小于极值点,交替地趋近,最终x趋于0.
import numpy as np
x=np.arange(-5,5,0.1) #定义域-5~5
y=x**2 #求解的函数
pointx=[] #用来储存每次梯度下降后的点
x0=-2 #初始值的横坐标-2,随便选的
for i in range(10): #先执行10次
xnew=x0-2*x0 #该点减去该点的导数值
x0=xnew #移动到新的点
pointx.append(x0) #储存点运动轨迹
pointy=np.array(pointx)**2
plt.plot(x,y,color="green") #画函数图像
plt.plot(pointx,pointy,color="red") #画梯度轨迹
plt.show()
结果如图1所示
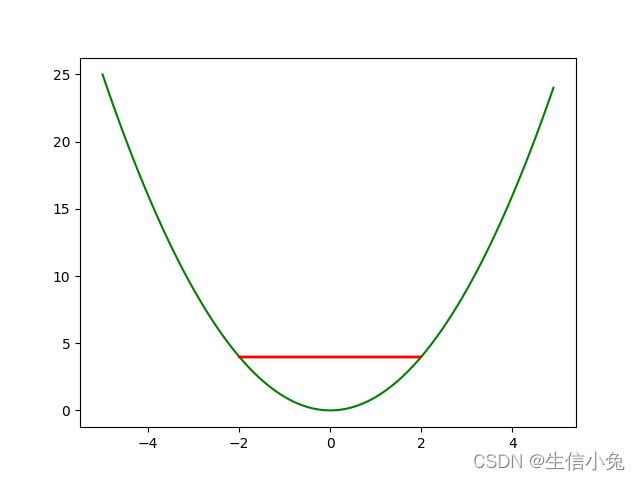
没有想到,竟然出现了水平的红线,说明点一直在两边震荡,互相踢皮球,根本没有下去。
这就涉及到一个关键的东西:学习率。
我们减去了导数,的确没有错,但是很多时候函数所在点的导数值是比较大的。所以我们可以将导数f"(x0)在乘上学习率alpha, 让梯度的步子小一点,就会解决该问题。比如我们让学习率为0.2,每次x减去0.2f"(x),结果如图2所示。
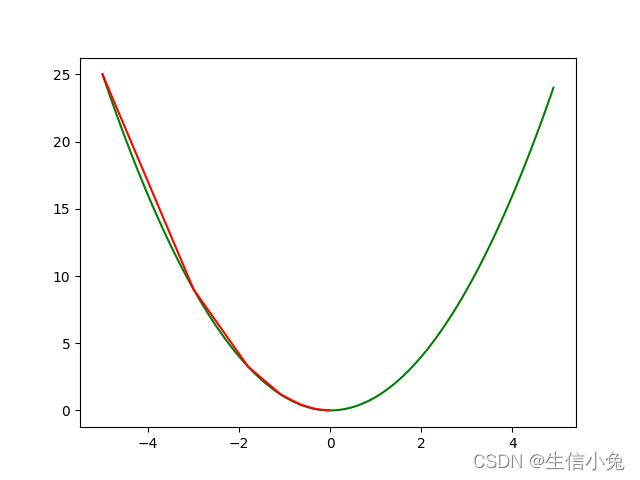
为了看起来方便,兔兔把初始值设为-5。不难发现这次的确好了很多,最终几乎收敛到极小值点。
在一般情况下,我们设置学习率在0~1之间。但是学习率也不是越小越好。如果太小的话,每次走的步子很小,需要很长时间才能到达最优解。不过对于一些模型,很可能出现导数很大的情况,alpha若不是足够小的话,很可能会出现梯度爆炸的,这一点一定小心。兔兔当年做BP神经网络时学习率没有设好,就发生了梯度爆炸的。
梯度爆炸性状就是,在极值点两边震荡,并且离极值点越来越远,最终数大的很离谱,一会儿是负10的几百次方,一会儿又是正的几百次方。形状类似图3。
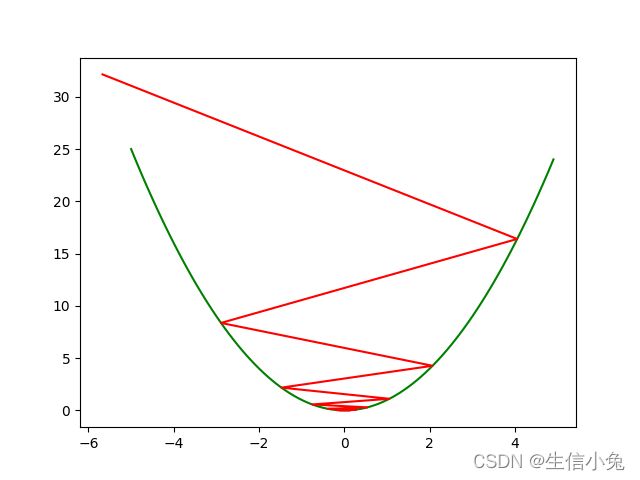
兔兔在这里设初始值为-0.1,为了方便我就直接把前面代码中学习率改成了1.2,也达到了梯度爆炸的效果。不难发现这个点在两边震荡,最终远离了极值点。
还有一种情形是梯度消失。这个在BP神经网络等模型中比较常见。当激活函数选择sigmoid函数,神经元层数很多时(不懂没关系的,兔兔之后肯定会详细讲解的),就容易出现梯度消失的情况,也就是没有了梯度。解决方法就是换激活函数,减少神经元层数。
关于梯度上升道理也是一样的,方法与上面梯度下降相同,只是这里每次x0加上alpha*f"(x0)。用前面的方法分析,最终肯定可以收敛到极大值点的。不过这个不是很常用,兔兔就不详细介绍了。
多元函数的梯度下降
对于多元函数也是一样的。比如二元函数f(x,y),我们每次只需要x0减去f(x,y)在该点对x的偏导数的值,y0减去f(x,y)在该点对y的偏导数。多次循环操作,最终就可以得到二元函数的极小值。过程类似于走山坡,一直往坡下走,走到最低点的坑洼处。
import matplotlib.pyplot as plt
ax=plt.axes(projection='3d')
x=np.arange(-5,5)
y=np.arange(-5,5)
X,Y=np.meshgrid(x,y)
Z=X**2+Y**2
ax.plot_surface(X,Y,Z,cmap="rainbow")
plt.show()

兔兔在上面绘制了函数f(x,y)=x2+y2,现在随便取初始点(4,-4,f(4,-4)),做梯度下降。学习率alpha=0.3.
import matplotlib.pyplot as plt
x0=4;y0=-4 #初始点
xlist=[x0] #储存x变化
ylist=[y0] #储存y点变化
zlist=[x0**2+y0**2]
alpha=0.3 #学习率0.3
for i in range(5): #执行5次
xnew=x0-2*x0*alpha
ynew=y0-2*y0*alpha
x0=xnew;y0=ynew
xlist.append(x0)
ylist.append(y0)
zlist.append(x0**2+y0**2)
ax.scatter(xlist,ylist,zlist,color='red',marker='^') #画点的位置
plt.show()
结果如图5所示

这里面红色的三角就是每次梯度下降后变化的位置(兔兔学艺不精,没有画好图)。但是也可以发现红色三角形不断向原点(0,0,0)靠近,最终是可以收敛到最小值点的。
总结
梯度下降算法核心就是不断减导数与学习率的乘积。在日后的学习过程中应该体会不同函数、不同算法模型中学习率的设置,并且学会处理梯度爆炸与梯度消失的情况。虽然该算法不难,却是之后神经网络算法、逻辑回归等各种算法的基础,有着重要的意义。