机器学习的数学基础(5):最小均方误差的回归问题
一. 回归
经过前面的铺垫,我们终于要接触到实际的与机器学习有关的数学问题了。对于一个基本的监督学习模型来说,其本质是找到一个函数来拟合所给定的数据集。而找到这个拟合函数f的过程,我们称之为回归(各资料都表明回归并不是一个好的名字,但是姑且这样子去使用,其实在我的理解里用拟合更为恰当且易于理解)。
我们需要两个概念来对我们的回归问题进行更好的建模:函数集、损失函数
函数集:
对于一个回归问题而言,我们需要限定该函数的范围即其所存在的空间,例如我们可以限定该函数是一个多项式函数。当然,之前所学习的知识不能白学,我们可以限定函数存在于一个希尔伯特空间或者该希尔伯特空间的一个子空间中,后续我们会发现定义了内积的空间将对我们的计算产生非常巨大的帮助,因为我们可以将问题完全的转化为线性代数的问题去求解。
损失函数:
此外,我们还需要找到一个标准去衡量我们拟合的好坏。对于给定的数据集![]() ,通过给定一个损失函数
,通过给定一个损失函数 ![]() ,来去衡量回归的质量。
,来去衡量回归的质量。
最小均方回归问题的数学建模
假如在这里,我们采用均方误差作为我们的损失函数:![]() ,那么最终我们的问题可以被建模为如下形式:
,那么最终我们的问题可以被建模为如下形式:
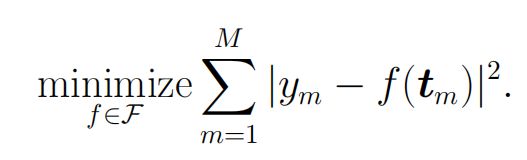
二. 线性回归问题的建模
我们先以最简单的线性回归问题为例来展开对于最小均方回归问题的讨论。
线性回归问题顾名思义,指的是其所规定的函数集为线性函数,线性函数的定义如下:
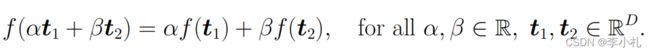
其实就是我们最先接触过的函数:一次函数。自然的我们应该明白,每一个线性函数都会对应有一个唯一的向量,并且针对于某一个回归问题,我们输入的数据集中t的维度,就应当是该函数的维度。所以函数 f(t) 完全可以被我们表示成一个内积的形式如下:
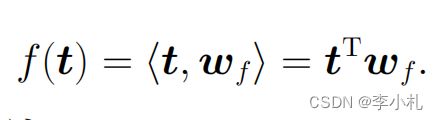
也就是说,通过内积的转化,我们的优化对象从函数变成了一个向量w。
接着进一步的,假如我们给定了M组数据,每组数据中输入的维度为D,输出的维度为1,我们可以进一步的将优化问题中的变量矩阵化:
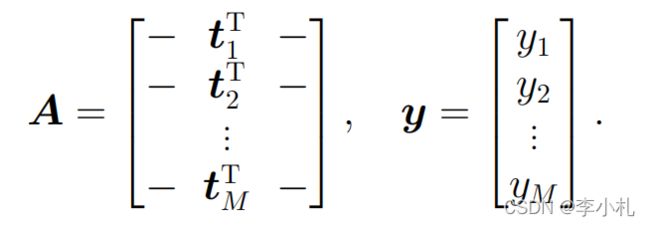
其中A是一个M*D维数的矩阵。最终我们的回归问题建模如下:
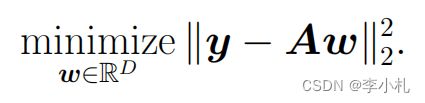
待优化的对象变成了向量w,当我们求解出向量w之后,我们的函数便可以表示为:
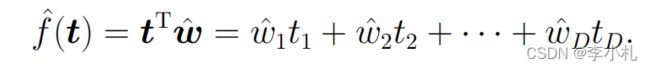
三. 线性回归问题的求解
在讨论上述问题的解之前,我们首先需要讨论一个必要的数学知识:矩阵求导
矩阵求导
因为深度学习与机器学习的操作都是基于矩阵的,所以在进行数学推导时,矩阵求导是一个非常重要的工具。详细的推导大家可以参考这篇文章:
矩阵求导公式的数学推导(矩阵求导——基础篇) - 知乎
我在这里只列举几个最基本的傻瓜公式:
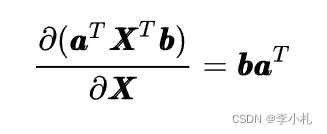
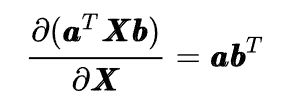
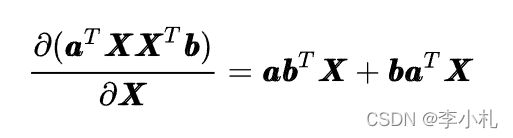
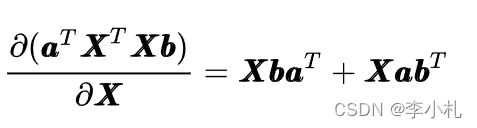
有了以上的四个公式,我们基本上就可以应对机器学习中的大部分数学推导了,当然有时间肯定还是应该仔细系统的学习一下矩阵求导的原理。
标准方程
那么我们回到优化问题上来,我们不妨来思考一下问题的解应该满足什么样的条件。显然,当函数达到最小值时,它在最小值点的梯度一定为0(无论函数是否为凸函数)。我们把它用数学的形式表示出来则有:
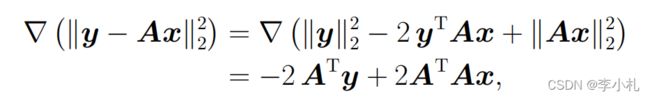
令梯度等于0,我们则有:
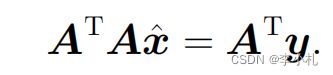
解的讨论
根据我们上述得到的标准方程,我们可以完全运用线性代数的知识进行解的情况分析。
这里我也省略掉关于矩阵的四大空间的概念,具体可以参考矩阵的四个子空间及其联系 - 知乎
首先这样的两个定理:
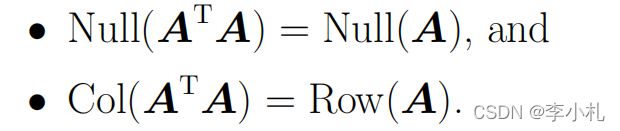
具体的证明在上述链接中也同样涉及。
那么现在我们可以得到如下的结论:
1. 标准方程一定是有解的因为无论A与y如何,都存在下列关系:
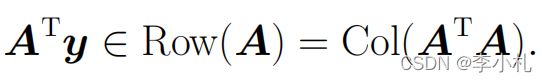
这是因为左式可以看作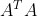 的列向量对应上x的系数,因此既然右式是在AtA的列空间中的,所以一定存在一组x对其进行表示,所以该问题是一定存在解的。
的列向量对应上x的系数,因此既然右式是在AtA的列空间中的,所以一定存在一组x对其进行表示,所以该问题是一定存在解的。
2. 当rank(A)=N时,意味着是满秩的,因此可以直接取逆。此时该问题存在唯一解:
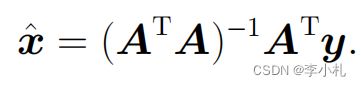
3. 如果rank(A)![]() ,
, 为标准方程的一个解,而v为A的零空间中的元素。
为标准方程的一个解,而v为A的零空间中的元素。
4. 如果rank(A)=M,那么在这种情况下我们可以直接从y-Ax的角度入手,因为我们知道我们优化目标可能的最小值一定是0,那么当rank(A)=M时,Ax=y是一定有解的。这时再分情况讨论,如果M=N,则此时A是满秩的,因此只有唯一解 以上,我们用线性代数建模了优化问题,并用线性代数解决了优化问题。![]() 。当M
。当M