04-Hadoop之HDFS分布式文件系统详解
HDFS详解
一、 HDFS 概述
1.1 HDFS定义
HDFS( Hadoop Distribution File System), 它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
1.2 HDFS优缺点
(1)优点
a. 高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性
- 某一个副本丢失以后,它可以自动恢复
b. 适合处理大数据
- 数据规模: HDFS 是 Hadoop 项目的一个子项目。是 Hadoop 的核心组件之一, Hadoop 非常适 于存储大型数据 (比如 TB 和 PB)(需要多台节点),
- 文件规模: HDFS 使用多台计算机存储文件,能够处理百万规模以上的文件数量。
c. 可构建在廉价机器上,通过多副本机制,提高可靠性
(2) 缺点
a. 不适合低延时数据访问
对于毫秒级的存储数据,是做不到的
b. 无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标
c. 不支持并发写入、文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据append (追加), 不支持文件的随机修改
1.3 HDFS架构 (理解清楚)
思考:HDFS系统中的文件或者数据存储在哪里?
NameNode:用于管理元数据(对真实数据的描述信息)
--存储在Linux系统/opt/module/hadoop-3.1.3/name下 格式化之后,才会产生name目录
作用:
用于管理HDFS名称空间
用于配置副本策略
用于处理客户端读写请求
管理数据(Block)块映射信息
下达指令给DN
DataNode:用于存储真实块数据信息
--存储在Linux系统/opt/module/hadoop-3.1.3/data下
格式化之后,才会产生data目录
执行数据块的读写操作
SecondaryNameNode : 为NameNode分担压力, 关键时刻,辅助恢复NameNode
1.4 HDFS文件块大小(面试重点)
HDFS中文件的存储在物理上是分块存储(块为单位),块的大小可以通过dfs.blocksize设置,默认在hadoop3.x版本中是128M,hadoop2.x也是128M,hadoop1.x是64M.本地(windows系统)模式下默认的块大小是32M
注意:128M只是衡量一个文件是否要进行切块的标准,实际文件是多大,存储到Hdfs上就是多大。
例如: 块大小为128M
上传一个100M的文件, 最后在HDFS会生成一个块。实际占用空间还是100M
上传一个200M的文件, 最后在HDFS会生成两个块, 第一个块占用空间128M, 第二个块占用空间72M
块大小设置路径:在hdfs-default.xml中
dfs.blocksize
134217728
The default block size for new files, in bytes.
You can use the following suffix (case insensitive):
k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.),
Or provide complete size in bytes (such as 134217728 for 128 MB).
(1) 将文件切分为block块的好处
- 一个文件的大小可能大于集群中任意一个磁盘
- 块可以将大文件切分多个块进行存储
- 使用块进行存储可以简化存储系统
- 块非常适用于数据备份进而提供数据容错能力和可用性
(2) 块缓存
通常 DataNode 从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显示的缓存在 DataNode 的内存中,以堆外块缓存的形式存在。默认情况下,一个块仅缓存在一个DataNode的内存中,当然可以针对每个文件配置DataNode的数量。作业调度器通过在缓存块的DataNode上运行任务,可以利用块缓存的优势提高读操作的性能。
上述总结:DataNode从磁盘中读取块内容是从内存读取再写到磁盘的。(只需要清楚)
例如:
连接(join)操作中使用的一个小的查询表就是块缓存的一个很好的候选。用户或应用通过在缓存池中增加一个cache directive来告诉namenode需要缓存哪些文件及存多久。缓存池(cache pool)是一个拥有管理缓存权限和资源使用的管理性分组。例如:
一个文件 130M,会被切分成2个block块,保存在两个block块里面,实际占用磁盘130M空间,而不是占用256M的磁盘空间
思考: 为什么块的大小不能设置太小, 也不能设置太大?`
-
HDFS的块设置太小, 会增加寻址时间,程序一直在找块的开始位置;
-
如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢
总结: HDFS 块的大小设置主要取决于磁盘传输速率。
1.5 HDFS的特性总结
- 1. master/slave 架构(主从架构)
HDFS 采用 master/slave 架构。一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。Namenode 是 HDFS 集群主节点,Datanode 是 HDFS 集群从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
- 2. 分块存储
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,默认大小在 hadoop2.x 版本中是 128M。
- 3. 名字空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被 Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
- 4. NameNode 元数据管理
我们把目录结构及文件分块位置信息叫做元数据。NameNode 负责维护整个 HDFS 文件系统的目录树结构,以及每一个文件所对应的 block 块信息(block 的 id,及所在的 DataNode 服务器)。
- 5. DataNode 数据存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。每一个 block 都可以在多个 DataNode 上。DataNode 需要定时向 NameNode 汇报自己持有的 block 信息。存储多个副本(副本数量也可以通过参数设置 dfs.replication,默认是 3)
- 6. 副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
- 7. 一次写入,多次读出
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改。
正因为如此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为修改不方便,延迟大,网络开销大,成本太高。
二、 HDFS 的shell命令
2.1 基本语法
bin/hadoop fs 具体命令 OR bin/hdfs dfs 具体命令
注意:两个(hadoop、dfs)在操作dfs上的操作是完全相同的。
2.2 命令大全
-启动Hadoop集群
start-dfs.sh start-yarn.sh
-help:输出这个命令参数
hdfs dfs -help rm
-ls: 显示目录信息
hadoop fs -ls /
-mkdir:在HDFS上创建目录
hadoop fs -mkdir -p /user/atguigu
-moveFromLocal:从本地剪切粘贴到HDFS
hdfs dfs -moveFromLocal ./input/test.txt /user/atguigu/input
-appendToFile:追加一个文件到已经存在的文件末尾
hdfs dfs -appendToFile ./input/test.txt /user/atguigu/input/wc.input.txt
-cat:显示文件内容
hadoop fs -cat /user/atguigu/input/wc.input
-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
hdfs dfs -chmod 777 /user/atguigu/input/input/wc.input
hadoop fs -chown atguigu:atguigu /user/atguigu/input/input/wc.input
-copyFromLocal:从本地文件系统中拷贝文件到HDFS
hadoop fs -copyFromLocal README.txt /
-copyToLocal:从HDFS拷贝到本地
hdfs dfs -copyToLocal /user/atguigu/input/wc.input ./
-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
hdfs dfs -cp /user/atguigu/input/wc.input /user/atguigu/
-mv:在HDFS目录中移动文件
hadoop fs -mv /user/atguigu/input /user/
-get:等同于copyToLocal,就是从HDFS下载文件到本地
hadoop fs -get /user/atguigu/input/wc.input ./
-getmerge:合并下载多个文件
hdfs dfs -getmerge /user/atguigu/input/* ./input.txt
-put:等同于copyFromLocal
hadoop fs -put ./input/text.txt /user/atguigu/input/
-tail:显示一个文件的末尾
hadoop fs -tail /user/atguigu/input/wc.input
-rm:删除文件或文件夹
hadoop fs -rm -r /user/atguigu/input/wc.input
-rmdir:删除空目录
hdfs dfs -rmdir /user/atguigu/wcinput
-du统计文件夹的大小信息
hdfs dfs -du -s -h /user/atguigu/test
-setrep:设置HDFS中文件的副本数量
hdfs dfs -sdetrep 5 /README.txt
注意:这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到至少5台时,副本数才能达到5
三、 HDFS的读写数据流程(开发重点)
3.1 HDFS 写数据流程
示例:上传一个200M的文件到HDFS分布式系统
HDFS写的流程步骤如下:
1、客户端client向NameNode发送上传文件的请求,NameNode会做校验(是否具备权限,上传路径是否存在,文件是否存在,是否执行覆盖操作等)
2、NameNode返回是否可以上传
3、客户端按照集群中块大小的设置对200M的数据进行切块,即切分为128M和72M两个block块,并请求第一个block上传到哪几个DataNode服务器上(DataNode节点信息) --切块源码查看:FileInputFormat~getSplits()方法
补充:
3.1 执行上传时,是一块一块进行上传,则先请求上传0~128M的块信息(第一个block块),因为数据真实存在DataNode节点上,所以NameNode会返回dn1\dn2\dn3三个服务器节点存储数据
--思考:副本选择机制,如何选择节点并返回?
4、客户端得到dn的信息后,会和dn服务器节点建立链接,客户端发送请求建立block传输通道,执行写数据操作
补充:
4.1 客户端在和dn(DataNode)建立连接时,也会有选择,选择距离客户端最近的节点请求建立链接通道(假设dn1最近)
4.2 客户端和dn1建立链接通道之后,dn1内部发请求到dn2,请求建立通道,dn2发请求到dn3,请求建立通道,dn3响应dn2,dn2响应dn1,dn1响应客户端 ,均没有问题,通道建立成功
5、数据传输时,不是说将128M的文件直接进行传输,而是客户端向dn1以Packet(数据包)为单位进行数据传输,(packet大小:64KB),每次传输64KB,最后一次传输数据大小可能不够64KB
补充:
5.1 客户端向dn1传输64KB的数据到内存,dn1落盘(在当前节点服务器上将数据由内存写到本地),并分发给dn2(内存),dn2落盘,在发给dn3(内存),dn3落盘 --逻辑上的说法
5.2 trunk数据传输过程中的最小单位(512字节),每次从0~128M中读数据,先读取512字节放入trunk中,当trunk满载时,对trunk内的数据进行校验,生成校验值(占4个字节),即共将516个字节放入Packet内,一个Packet存在N多个trunk --真实说法
5.3 各节点内部Packet是如何进行传输的?
在hdfs内部有一个队列,叫做dataQuene,每传输一个Packet,就将当前Packet放入到DQ队列中,当dn1接收到DQ中的Packet时,会将Packet从DQ队列中拉取出来,存入另一队列ackquene中(应答队列),当dn1,dn2,dn3等节点均将ackq中的数据写成功之后,ackquene中的packet移除,表示packet传输完成
6、当dn1、dn2、dn3建立通道时,或者在数据传输过程中,如果某个节点出现问题,比如dn2宕机了,那么客户端会重新发请求建立传输通道,这时,宕机的节点dn2不在请求应答,dn1 和 dn3直接建立通道,dn2不在使用,缺少副本数据,内部机器会重新配置一台来顶替dn2,保证真实节点数据和副本机制设置的保持一致
7、数据传输完成之后,流关闭,执行第二个块的数据写操作,步骤同上
3.2 副本选择机制
(1) 节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。
思考:这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
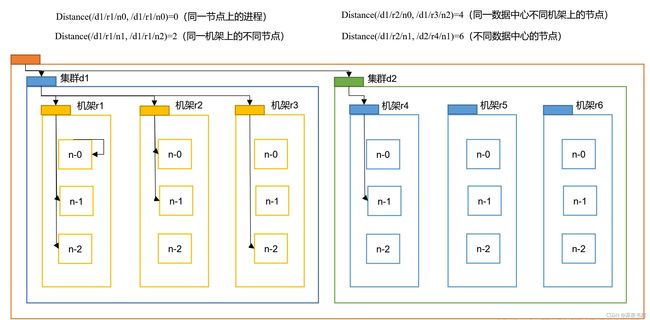
可以通过上图总结出,可用带宽效率(依次递减):
- 同一节点上的进程
- 同一机架上的不同节点
- 同一数据中心中不同机架上的节点
- 不同数据中的节点
(2) 机架感知(副本储存节点选择)
机架感知说明
http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack.
(3) 副本的存放策略
目的
- 数据的安全(优先)
- 数据块的负载均衡
解决方案(节点选择):
- 第一个副本在Client 所处的节点上。如果客户端在集群外,随机挑选一个。
- 第二个副本在另外一个机架的随机一个节点。
- 注意:第二个副本的所在机架不能和第一个副本所在机架相同
- 第三个副本在第二个副本所在的机架的随机一个节点上。(不同于第二个副本节点)
设计思想:如果第一个副本和第二个副本都放在了第一个机架上,那么写入的效率会提高,但是数据的安全性就会降低(机架损坏导致两个副本都不能使用),所以将第一个副本和第二个副本存放在不同的机架上;第三个副本存放的节点在第二个副本所在的机架上的其它节点,此时可以保证数据写入效率更高。
3.3 HDFS 读数据流程
示例: 从HDFS上下载一个200M的文件到客户端
1、 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,返回该文件的块所在的DataNode地址。
2、 客户端根据元数据返回的DataNode地址挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3、 DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4、 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
四、 HDFS中NameNode和SecondaryNameNode(面试重点)
4.1 NN 和 2NN 工作机制
4.1.1 概述
思考:NameNode中的元数据是存储在哪里的?
① 假设存储在NameNode所在节点的磁盘上,因为元数据需要进行随机访问,还有响应客户请求,这样做效率必然过低,所以不可行。
② 假设存储在内存中,一旦断电,元数据就会丢失,整个集群就无法工作了,所以这也不可行。
③ 因此元数据在磁盘和内存上都会使用。
具体使用:Fsimage文件存放在磁盘中;Edits文件存放在内存中,当edits文件存储一定数量后利用滚动日志将edits保存到磁盘,并生成一个新的 edits_inprogress_xxx文件。

4.1.2 NN工作机制
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
即在NN启动时,需要先将磁盘的fsimage_current 和 edits_inprogress_001 文件加载到进行一次合并. 在内存中构建好元数据信息。 其中 seen_txid:记录正在使用的编辑日志文件
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
NN会将edits_progress进行所谓的滚动,说白了就是该文件不能再进行写入操作,会生成另外一个编辑日志文件用于记录后续的写操作.
滚动正在使用的编辑日志: edits_inprogress_001 --> edits_001
新的编辑日志: edits_inprogress_002
(4)NameNode在内存中对元数据进行增删改。
总结: NN内存中的数据 = 磁盘上正在使用的fsimage + 正在使用的edits文件.
4.1.3 2NN工作机制
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
4.2 Fsimage 和 Edits 解析
4.2.1 概念
- Fsimage文件(镜像文件):存放的是元数据。详情:HDFS 文件系统元数据的一个永久性的检查点, 其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
- Edits文件(日志文件):存放的是操作命令。详情:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
- seen_txid文件报尺寸的是一个数字,就是最后一个edits_的数字
- 每次NameNode启动的时候都就会将 Fsimage 文件读入内存,加载 Edits 里面的更新操作,保证内存中的语言数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage 和 Edits 文件进行了合并。
4.2.2 oiv查看Fsimage文件
语法: hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
案例
hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
将镜像文件转成xml文件后可以将其传到Windows桌面上进行打开
在 中可以看见文件或者目录的信息
思考:Fsimage中没有记录块所对应DataNode,为什么?
在fsimage中,并没有记录每一个block对应到哪几个datanodes的对应表信息,而只是存储了所有的关于namespace的相关信息。而真正每个block对应到datanodes列表的信息在hadoop中并没有进行持久化存储,而是在所有datanode启动时,每个datanode对本地磁盘进行扫描,将本datanode上保存的block信息汇报给namenode,namenode在接收到每个datanode的块信息汇报后,将接收到的块信息,以及其所在的datanode信息等保存在内存中。(HDFS就是通过这种块信息汇报的方式来完成 block -> datanodes list的对应表构建。Datanode向namenode汇报块信息的过程叫做blockReport,而namenode将block -> datanodes list的对应表信息保存在一个叫BlocksMap的数据结构中。)
参考:https://blog.csdn.net/weixin_43988989/article/details/104590230
总结:在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
4.2.3 oev查看Edits文件
语法: hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
案例
hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
将日志文件转成xml文件后可以将其传到Windows桌面上进行打开
思考:NameNode如何确定下次开机启动的时候合并哪些Edits?
NameNode启动时会合并最新的 Edits文件(edits_inprogress_xxx 文件)和 磁盘中最新生成的fsimage文件
总结:都是合并最新的。
4.3 CheckPoint时间设置
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
配置文件 hdfs-default.xml
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value> //修改这个值就是修改检查点时间
</property>
2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
配置文件 hdfs-default.xml
dfs.namenode.checkpoint.txns
1000000
操作动作次数
dfs.namenode.checkpoint.check.period
60
1分钟检查一次操作次数
4.4 NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方式一
/*
将secondaryNameNode中的数据cp到NameNode存储数据的目录
--NN存储的目录(/opt/module/hadoop-3.1.3/data/name/current)
*/
具体操作演示:
1、杀掉NameNode进程
jps 查看NN运行的进程号
kill -9 NN进程号
2、删除name下所有内容
rm -rf /opt/module/hadoop-3.1.3/data/name/ *
3、拷贝2NN服务器节点name下的所有内容到NN中的name目录下
scp -r atguigu@atguigu5:/opt/module/hadoop-3.1.3/data/namesecondary/* ./name/
方式二
使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中.
具体操作演示:
1、修改hdfs-site.xml
dfs.namenode.checkpoint.period
120
dfs.namenode.name.dir
/opt/module/hadoop-3.1.3/data/name
2、kill -9 NameNode进程
3、删除NameNode存储的数据(/opt/module/hadoop-3.1.3/data/name)
4、如果2NN不和NN在一个主机节点上,需要将2NN存储数据的目录拷贝到NN存储数据的平级目录,并删除in_use.lock文件
scp -r atguigu@atguigu5:/opt/module/hadoop-3.1.3/data/namesecondary ./
rm -rf in_use.lock
pwd ---> /opt/module/hadoop-3.1.3/data
5、导入检查点数据(等待一会ctrl+c结束掉)
bin/hdfs namenode -importCheckpoint
6、启动NameNode
hdfs --daemon start namenode
4.5 集群安全模式
4.5.1 安全模式概述
1、 NameNode 启动
NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的Fsimage文件和空的编辑日志(实际上没有创建新的文件,这里指的是将checkpoint的数据放入进行同步导致文件变化)。此时,NameNode开始监听DataNode请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对客户端来说只是只读的。
2、 DataNode启动
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
3、 安全模式退出判断
如果满足 “最小副本条件” ,NameNode会在30秒钟之后就会退出安全模式。所谓的最小副本条件指的是在整个文件系统中 99.9%的块满足最小副本级别(默认值 : dfs.replication.min = 1 最小副本数为1)。在启动一个刚刚格式化的 HDFS 集群时,因为系统中还没有任何块,所以 NameNode 不会进入安全模式。
最小副本条件解释:如果有1000个块,只需要知道1000个块中的999块其中的一个块的副本,即可退出安全模式。
4.5.2 安全模式生命周期
1、init
当NN刚启动~加载fsimage+edites日志文件~内存中元数据构建成功~NN开始监听DN请求,此过程中,NN处于安全模式下,NN的文件系统对于client是只读的
2、run
当DN启动~DN向NN发起内部通信,告知NN自己节点上DN真实块数据列表信息(安全模式下),NN收到各DN的块位置信息之后,开始运行文件系统
--NN中的真实数据存放位置不是由NN维护的,而是以块的形式存储在各DN节点上
3、safe quit:(HDFS集群系统启动完成后,自动退出安全模式)
满足‘最小副本条件’ 安全模式退出
4.5.3 安全模式操作语法
(1) bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2) bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3) bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4) bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
4.5.4 案例
案例演示:
1、在/opt/module/hadoop-3.1.3/ 路径下创建脚本safemode.sh
touch safemode.sh
2、编辑safemode.sh
a. 打开脚本
sudo vim safemode.sh
b. 编写内容是:当处于安全模式会进入等待状态(不然会直接不执行命令导致上传失败),并上传一个文件到HDFS系统
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-3.1.3/README.txt /
3、给与safemode.sh执行权限
chmod 777 safemode.sh
4、运行safemode.sh脚本
./safemode.sh
5、重新打开一个xshell控制台,执行离开等待状态
bin/hdfs dfsadmin -safemode leave
6、观察原窗口,查看原窗口hdfs的安全模式状态
bin/hdfs dfsadmin -safemode get
Safe mode is OFF
safemode.sh中的上传代码执行,hdfs集群已有上传的数据
五、 DN工作机制(面试开发重点)
5.1 DataNode工作机制

DataNode的工作机制:
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
DataNode的作用:以块的形式,来存储真实数据,128M为切块单位
切块之后的数据分为2部分:
-- 数据本身(即文件中真实的数据)
-- 元数据(对数据块的长度、校验和、时间戳等描述信息)
DataNode的存储位置: /opt/module/hadoop-3.1.3/data/data/current/BP-1901013597-192.168.202.103-1600767106029/current/finalized/subdir0/subdir0
查看后可以发现:
每个块分成两个前面同名但后缀名不同的文件
不带后缀名的文件 就是 真实存储的数据
带 .meta 后缀名的文件 就是 存储元数据的文件
5.2 数据完整性
思考:如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是DataNode节点保证数据完整性的方法。
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)DataNode在其文件创建后周期验证CheckSum。
校验码算法: crc (32位)、md5(128位) 、SHA1(160)、SHA256
5.3 掉线时限参数设置
心跳:DataNode会每隔3秒向NameNode响应一下,向NameNode证明还存活着。
如果DataNode发生故障造成DataNode无法与NameNode通信,此时,NameNode不会立刻把该节点判定为死亡,超过 “ 超市时长” (默认是10分钟 + 30秒)时,才会判定该节点已死亡。
超时时长的计算公式为:
超时时长 = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
配置文件: hdfs-site.xml
添加内容如下 第一个是毫秒单,值为5分钟,第二个单位是秒,值为3秒
dfs.namenode.heartbeat.recheck-interval
300000
dfs.heartbeat.interval
3
5.4 服役新数据节点
注意:启动新节点,不需要去停止集群,也不要配置workers文件,当需要将新增节点也可群起群停时,要去将新增节点添加到workers文件中,并分发
添加新节点
1、在hadoop104主机上再克隆一台hadoop105主机
2、修改IP地址和主机名称
vim /etc/sysconfig/network-scripts/ifcfg-ens33
将 IPADDR=192.168.1.104 改成 192.168.1.105
vim /etc/hostname
将 hadoop104 改成 hadoop105
补充:如果 /etc/hosts 文件下没有添加有192.168.1.105则还需要添加进去
3、删除hadoop105服务节点下hadoop的data和logs,并且删除/tmp的所有临时文件
rm -rf /opt/module/hadoop-3.1.3/data /opt/module/hadoop-3.1.3/logs
sudo rm -rf /tmp/*
4、source配置文件
source /etc/profile
5、在hadoop105上启动DataNode节点,直接关联到集群
hdfs --daemon start datanode --web端可以看到新增节点直接加入集群
6、 yarn --daemon start nodemanager
7、如果数据不均衡,可以用命令实现集群的再平衡
sbin/start-balancer.sh
workers的作用:在启动整个模块时会根据workers中的地址去各节点的服务。
注意:workers不是决定谁是集群中的节点。
只要配置了免密登录,并且在配置文件里配置了NameNode地址,即可加入。
5.5 退役旧数据节点
5.5.1 添加白名单
白名单:在白名单的主机节点才能被允许访问NameNode。
配置白名单步骤:
a. 在NameNode(hadoop102)的/opt/module/hadoop-3.1.3/etc/hadoop目录下创建whitelist文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/whitelist
添加以下内容(不添加hadoop105) -- 注意:不能有空格和空行
hadoop102
hadoop103
hadoop104
b. 在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性(并重启NameNode)
dfs.hosts
/opt/module/hadoop-3.1.3/etc/hadoop/whitelist
c. 配置文件分发 — 有需求可分发
xsync hdfs-site.xml
注意:虽然修改集群上某一个节点的配置后其他节点也需要同步,但是白名单只要在NameNode所在的节点上即可生效,可以不用分发
d. 刷新 NameNode
hdfs dfsadmin -refreshNodes
e. 在 web 浏览器上查看
在hadoop102:9870上的DataNode上可以查看
5.5.2 黑名单退役
黑名单作用: 在黑名单上的主机都会被强制退出
配置黑名单步骤:
a. 在NameNode(hadoop102)的/opt/module/hadoop-3.1.3/etc/hadoop目录下创建blacklist文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/blacklist
添加以下内容(不添加hadoop105) -- 注意:不能有空格和空行
hadoop102
hadoop103
hadoop104
b. 在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性(并重启NameNode)
dfs.hosts.exclude
/opt/module/hadoop-3.1.3/etc/hadoop/blacklist
c. 配置文件分发 — 有需求可分发
xsync hdfs-site.xml
d. 刷新 NameNode
hdfs dfsadmin -refreshNodes
e. 在 web 浏览器上查看
在hadoop102:9870上的DataNode上可以查看
5.6 Datanode多目录配置 — 可略
1)DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
2)具体配置如下
打开配置文件 hdfs-site.xml
配置内容如下
dfs.datanode.data.dir
file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2