Prometheus 是什么
监控系统不完全发展史
监控系统的发展可以粗略地划分为三个时代。
最初是SNMP监控时代,那时候的监控系统基于 SNMP 协议抓取信息;多用于监控网络设备,以硬件监控为主。典型代表有 Cadvisor + InfluxDB + Grafana,这一代监控系统只能从主机维度采集信息,没有 NameSpace、Pod 等维度的汇聚功能。
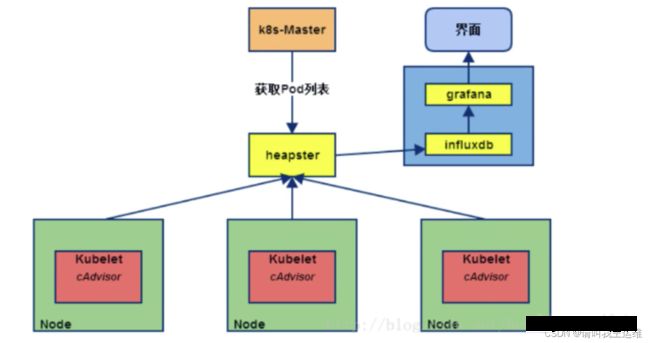
而后出现了第二代,算是第一代的改良版,可以对数据进行汇总。典型代表有 Heapster + InfluxDB + Grafana。其中,Heapster 负责调用各 node 中的 Cadvisor 接口,对数据进行汇总,然后导到 InfluxDB,可以从 cluster、node、pod 各个层面提供详细的资源使用情况。
第三代是云原生监控系统。云计算时代到来后,云原生监控系统成为新的主流。监控系统具备监控目标的数据采集、存储、报警等一套监控系统必备的功能,基于指标、日志和链路三个立体维度进行立体的系统监控。典型代表有 Metrics- Server + Prometheus。
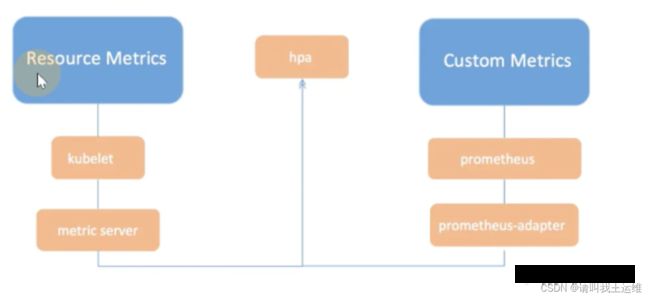
如上图,Resource Metrics 对应的接口是metrics.k8s.io,主要的实现就是 metrics-server,它提供资源监控能力,比较常见的是节点级别,pod级别,namespace级别,class级别,这类的监控指标都可以通过 metrics.k8s.io 接口获取。
Custom Metrics 对应的接口是 custom metrics.k8s.io,主要的实现是 Prometheus,它提供的是资源监控和自定义监控。
常见监控系统的三个立体维度:
指标监控(metrics):随时间推移产生的一些与监控相关的可聚合的数据点,该类数据具备:零散信息和可聚合的特性。
日志监控(logging):整体日志或分层次的日志和事件。
链路跟踪(tracing):分布式系统,对分布式链路跟踪、调用过程中发生的一系列事情(性能数据)做的收集。
Prometheus 简介
Prometheus 由 SoundCloud 开发的开源监控报警系统和时序列数据库(TSDB),主要用 Go 编写。自2012年起,许多公司及组织已经采用 Prometheus,并且该项目有着非常活跃的开发者和用户社区,现在已经成为一个独立的开源项目,并且保持独立于任何公司,Prometheus 在2016加入 CNCF ( Cloud Native Computing Foundation ), 作为在 kubernetes 之后的第二个由基金会主持的项目。github地址(https://github.com/prometheus)
Prometheus 的主要特征
- 多维数据模型(时序列数据有metric和一组key/value组成)
- 在多维度上灵活的查询语言(PromQl)
- 不依赖分布式存储,单主节点工作.
- 可以通过pushgateway进行时序列数据推送(pushing)
- 可以通过服务发现或者静态配置去获取要采集的目标服务器
- 多种可视化图表及仪表盘支持
Prometheus 架构

prometheus生态系统由多个组件组成,其中许多组件是可选的。
- promethues server:主要获取和存储时间序列数据。
- client libraries:用于对接 Prometheus Server, 可以查询和上报数据。右下角部分。
- exporters:主要是作为agent收集数据发送到prometheus server,不同的数据收集由不同的exporters实现,如监控主机有node-exporters,mysql有MySQL server exporters。
- pushgateway:允许短暂和批处理的jobs推送它们的数据到prometheus;由于这类工作的存在时间不够长,所以需要他们主动将数据推送到pushgateway,然后由pushgateway将数据发送的prometheus。总结:类似于zabbix proxy
- alertmanager:实现prometheus的告警功能。
prometheus 直接或通过pushgateway抓取数据。将数据存储在本地,并对这些数据运行规则,以便从现有数据聚合和记录新时间序列,或者生成警报。然后利用 grafana 等工具可视化数据。
Prometheus 适合做什么
Prometheus适用于录制任何纯数字时间序列。它适用于以机器为中心的监控以及高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持是一种特殊的优势。
Prometheus专为提高可靠性而设计,是您在停电期间可以快速诊断问题的系统。每个Prometheus服务器都是独立的,不依赖于网络存储或其他远程服务。当基础架构的其他部分损坏时,您可以依赖它,并且您不需要设置大量的基础架构来使用它。
Prometheus 不适合做什么
虽然 Prometheus 是一个全面的监控解决方案,但它不适合某些角色。Prometheus 的设计以可靠性和性能为核心原则。这会导致衡量指标准确性的权衡。
Prometheus 不保证收集到的数据是 100% 准确的。它适用于偶尔丢失的事件不会影响全局的高容量场景。如果您正在跟踪需要正确的敏感统计数据,您应该使用其他平台来处理这些指标。对于系统中不太重要的值,您仍然可以采用 Prometheus。
此外,Prometheus 可能不是您想要的监控堆栈中的唯一组件。它专注于存储和查询您的事件,主要使用 HTTP API。内置的 Web UI 提供基本的绘图功能,但不支持高级自定义仪表板。数据可视化场景通常通过部署一个Grafana实例来处理;这通过内置的Prometheus 集成提供仪表板和指标分析功能。
注:以上内容参考 prometheus官网