MySQL日志系统 - 一文贯通MySQL日志
概述
Mysql的日志系统是Mysql保证无论何时崩溃数据都不会丢失的关键
众所周知Mysql是持久化的数据库, 所有的数据都是持久化到硬盘中的, 保证数据不会丢失
Mysql保证数据不会丢失是从以下两个方面来体现的
- 能够恢复到任意时刻的数据状态
- 无论在事务提交前还是提交后崩溃都能保证数据不丢失
- 事务过程中崩溃能够恢复到事务提交前的状态
- 事务提交后崩溃已提交的数据不会丢失
MySQL保证以上两个点的关键就是通过 undo log, redo log 和 binlog 这三个日志来实现的, 接下来将逐一介绍
undo log 回滚日志
undo log是Mysql的回滚日志, 存储的是老版本的数据
主要作用
-
存储老版本的数据
- 配合Read View和隐藏字段实现了Mysql的快照读
-
用于在事务执行失败的时候回滚到事务开始前的版本
undo log 有什么类型
undo log 有两种类型
对于 insert 命令, undo log 记录的是新增的记录的主键, 在回滚的时候根据 undo log 中的主键去删除对应的记录即可
对于 update / delete 命令, undo log 记录的是被修改的记录的旧数据
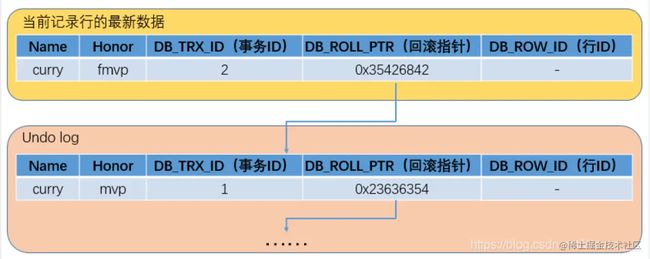
Mysql中的每一行数据都有一个最新修改当前数据行的事务id和回滚指针这两个字段, 当对数据行进行修改之后, undo log指针就会指向旧的这一行数据, 而新生成的这一行数据的回滚指针就会指向undo log指针当前指向的旧数据行
- Mysql为了避免undo log指针修改指向的时候出现并发问题, 在修改之前会对undo log指针增加排他锁以保证undo log的正确写入
undo log 什么时候删除
undo log是用于保证事务在未提交的时候可以顺利回滚到事务开始前的状态, 当事务提交之后undo log就失去作用了, 就需要被删除
undo log是交由Mysql中的 Purage 线程来负责删除的, purage会定期检查undo log中的deleted_bit 标志, 这个标志会在事务提交后被设置为true, purage 线程发现为true的记录就会负责将其删除
redo log 重做日志
redo log是Mysql的物理日志, 负责记录某个数据页执行了什么样的操作
redo log 的作用
- 负责记录提交的事务对数据的修改, 记录的内容大概就是
对x表的y页z偏移做了a更新 - 让Mysql在提交事务的时候无需等待数据持久化磁盘, 只需要将redo log持久化到磁盘就可以了
- 未清除的redo log的数量标识了未刷盘的脏页数量
为什么提交事务是选择持久化redo log, 而不是持久化数据到磁盘
持久化数据到磁盘是随机IO过程, 所以Mysql选择将数据缓存起来, 等待一个合适的时机将数据一次性写入磁盘, 减少IO
但是数据缓存在内存中有丢失的风险, 所以Mysql选择将redo log持久化
redo log是顺序写, 持久化的效率比随机写的效率要高, 并且redo log记录了数据的变化情况, 只要redo log在就可以保证在Mysql重启后恢复数据
在InnoDB中, redo log是一个固定大小的类似循环队列的存在, 每次写入都从后面write pos的位置, 在持久化数据的时候就移动check point往前读取
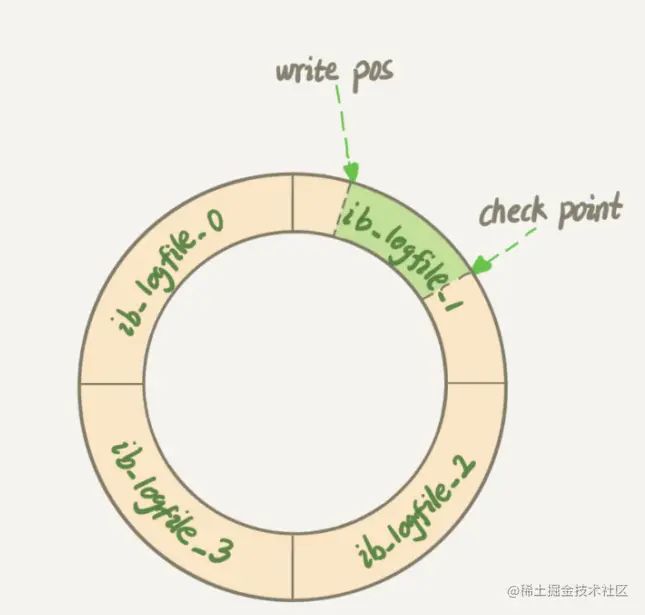
- 这样设计的原因是因为redo log是防止Mysql崩溃后缓存的脏页数据丢失而存在的
- 当Mysql中的数据被持久化到磁盘中后, 被持久化部分的redo log其实就没有用了, 就可以腾出空间来记录新的数据
undo log 和 redo log 的区别
undo log记录的是事务执行过程中旧数据的状态, redo log记录的是数据更新之后的状态
redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性
binlog 归档日志
binlog是Mysql server层实现的日志, 是所有引擎通用的
作用
binlog记录的是mysql原始的语句逻辑, 并且是采用追加写入的形式记录的, 所以可以用于恢复mysql在任意时刻的数据库数据状态
- 所以叫binlog是归档日志 同时binlog也是Mysql实现主从复制的依赖, 从库通过从主库中复制binlog回放来同步主库的数据状态
Mysql的WAL(Write Ahead Loggin)机制
定义
先写日志到磁盘中, 再写数据到磁盘中 Mysql的写操作不是立刻写入到磁盘中的, 而是先写日志, 保证redo log和binlog都持久化到磁盘中再由后台线程选择时机将数据持久化到硬盘的
为什么要先写日志到磁盘中
因为刷脏页是一个随机读写的过程, 持久化到磁盘中的速度肯定没有redo log | binlog这些顺序写的速度快, 所以选择先在内存中对数据进行修改, 再后期选择时机异步持久化到磁盘中
所以在脏页还未刷入磁盘中的这段时间就由redo log | binlog来保证数据的持久化, 防止断电重启等情况内存中的数据丢失
当脏页满的时候需要将脏页写入到磁盘再淘汰, 为何不全部淘汰掉下次使用的时候再通过redo log来恢复呢
从性能方面考虑的, 如果每次从磁盘中读取数据到内存都需要和redo log比对更新, 效率很低
MySQL刷脏页写入到磁盘保证了数据页只要在内存中, 就肯定是当前最新的数据可以返回
如果内存中没有数据只要从磁盘中读取肯定能得到最新的正确数据, 而不用再去同redo log进行比对
binlog和redo log的写入过程 - WAL机制的基本保证
binlog和redo log都是将日志写入划分为三个过程 写入cache, write和sync
在事务执行过程中会将binlog和redo log写入到对应分配的缓存中, 以便在事务提交的时候一次性写入到磁盘中
在事务提交的时候会先进行write将数据写入到操作系统的页缓存中, 此时数据还未真正写入文件, 但是已经是交由操作系统的缓存来保管了, 如果此时Mysql进程崩溃这部分写入的数据也不会丢失, 操作系统的内核线程会负责将这部分缓存中的数据写入磁盘
- 但是如果操作系统崩溃了这部分数据就丢失了
最后就是mysql手动调用sync将写入在页缓存中的数据持久化到硬盘, 写入完成后数据就是持久化成功了
最后的write和sync步骤mysql提供了对应的参数来控制写入策略
redo log是通过innodb_flush_log_at_trx_commit来控制的
- 设置为 0 的时候,表示每次事务提交时都只是把redo log留在redo log的缓存中
- 丢失风险最大
- 设置为 1 的时候,表示每次事务提交时都将redo log直接持久化到磁盘
- 丢失风险最小, 但是IO占用大
- 设置为 2 的时候,表示每次事务提交时都只是把redo log写到page cache
- IO占用居中, 将写入到磁盘这个最占用IO的过程交由操作系统来负责
binlog是通过参数sync_binlog来控制的
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync
两阶段日志提交
什么是两阶段日志提交
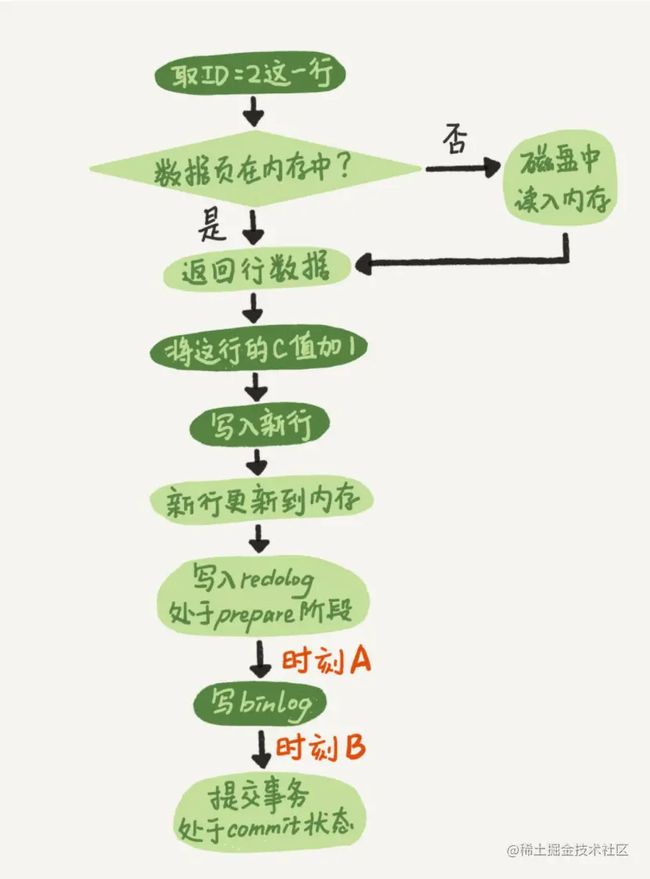
将redo log日志提交的过程分为prepare和commit这两个阶段, binlog日志提交在这两个阶段中间
事务提交时redo log先提交后进入prepare状态, 然后binlog提交完成后redo log才能将日志的状态修改为commit已提交
为什么需要两阶段日志提交
和InnoDB引擎的回滚机制有关, InnoDB的redo log提交了事务就无法回滚了, 如果在redo log提交后binlog写入失败的话就会出现两份不统一的情况
如果此时数据库异常重启的话要依据那一份来恢复数据就值得思考了, 所以才需要两阶段日志提交
假设现在在时刻A数据库崩溃的话, 因为binlog还未写入, redo log还未提交, 所以重启后事务会回滚, 两份日志依旧是统一状态
如果是时间段B的话, 就需要对redo log的提交标志进行判断了, 在查询redo log中是否有commit提交标志, 如果有的话事务没有问题, 直接提交
如果redo log中没有对应事务的提交标志的话会对binlog进行检查
- 如果binlog完整并且带有commit标志, 就会提交事务并在redo log后面补上commit标志
- 如果binlog不完整就回滚事务
这里可以发现两阶段日志提交中发生了崩溃是依据binlog来进行标准判断的, 原因是因为主从复制是依据binlog来进行的
如果对两份日志都需要检查完整性的话, 主库挂掉切换到从库的时间会变长, 以binlog为基准的话主库挂了直接拿着binlog去从库恢复数据即可, 无需检查redo log的完整性
此外binlog是Mysql Server层的通用日志, 这也是选择binlog作为基准的原因
两阶段日志提交的缺点
-
磁盘IO次数高
- 在提交日志的时候会有redo log和binlog对应的刷盘操作, IO次数高
-
锁竞争激烈
- 为了保证多个事务提交的时候日志的记录和事务的提交顺序是一致的, 会使用锁来保证日志提交的相对顺序
- 但是在并发量大的情况下性能会变差
组提交机制
组提交机制的作用
当有躲过事务提交的时候, 将多个事务的日志合并在一起去写入, 减少磁盘IO操作
组提交机制的实现
组提交机制将commit过程拆分成三个过程, 对每个过程都维护了一个队列, 并且通过锁来保证事务的写入顺序
- 分成三个阶段分别加锁可以减少锁粒度, 无需锁住事务的整个提交过程
当队列为空的时候第一个进入队列的事务会成为后续进入的事务的领导者, 带领后续事务完成接下来的阶段操作
阶段一 : flush阶段 : 多个事务按进入的顺序将binlog从cache中写入文件 (不刷盘)
第一个进入flush阶段的事务会作为领导者领导后面进入的事务
领导者事务会带领所有的事务对 redo log 进行一次 write + fsync, 也就是将redo log 写入磁盘, 完成redo log 的propare阶段
如果在这个阶段Mysql崩溃了, 会在重启后回滚这组事务
阶段二 : sync : 对binlog文件做fsync操作 (将多个事务的binlog合并一起刷盘)
在flush阶段将binlog写入到binlog文件后, 会等待一段时间再进行刷盘, 目的是组合更多事务的binlog一起刷盘减少消耗
等待会有时间限制和最大事务限制, 满足其中一个条件就会立刻对binlog进行刷盘
sync阶段主要负责binlog的组提交, 如果当前阶段Mysql崩溃的话, 在重启后可以通过redo log的刷盘记录继续完成事务提交
- 因为此时binlog已经完成提交了, 所以可以根据redo log来继续提交事务
阶段三 : commit : 对各个事务做InnoDB的commit操作