算法与数据结构 --- 线性表 --- 链式表示与实现(上)
第一部分 --- 链式表示与实现(1,2)


1.链表中的结点由两个域组成:数据域和指针域:
数据域中存放在当前结点管理的数据,指针域中则存在着指向下一个结点或者上一个结点(或者二者皆有)的指针,这个指针又被称为链
2.如果链表的结点中的指针域中只有指向下一个结点的指针的话,则称这个链表为单链表。每一个单链表都具有一个头指针,这个指针指向的是链表中的第一个结点
单链表是由其头指针唯一确定的,因此单链表可以用头指针的指针名来命名
3.单链表中的最后一个结点不指向任何一个结点,所以将给它的指针域中的指针赋一个 NULL(空)值,使其成为空指针
1.单链表:只有一个指针域,这个指针域指向结点的后继
双链表:具有两个指针域,一个指针域指向结点的前驱,另一个指针域指向结点的后继
循环链表:里面的结点可能有一个指针域,也可能有两个指针域,但是最重要的是链表中的最后一个结点中一定会有一个指针域指向第一个结点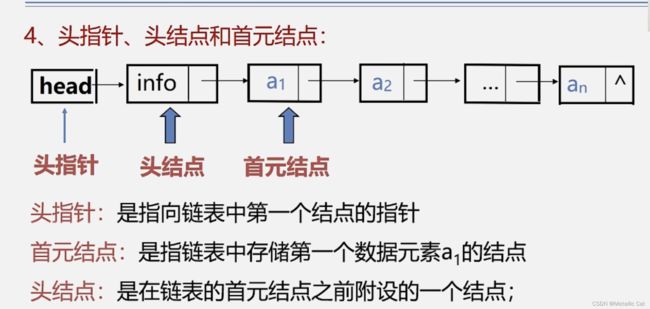
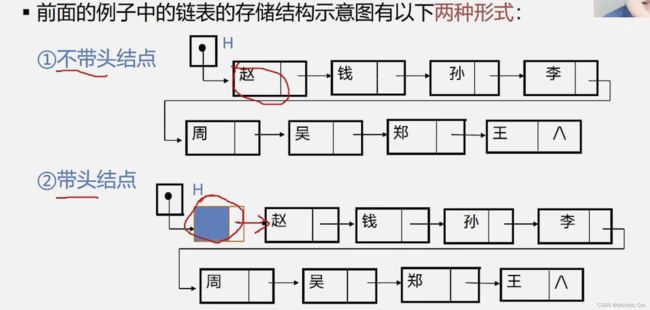

1.空表:表中没有数据元素
2.只有头指针,没有头结点时,空表的表示是将头指针置为空指针;有头指针也有头结点时,空表的表示是将头结点的指针域置为空指针
1.在顺序表中我们只需要知道一个元素的地址,就能够知道任意元素的地址了,所以顺序表是随机存取
2.在链表中,如果我们要知道第 i 个元素的地址,我们就必须知道这个元素前面 i - 1个元素的地址,即如果我们要知道第 i 个元素的地址的话,我们就必须先知道第一个元素的地址,然后通过第一个元素的地址知道第二个元素的地址,然后是第三个.....一直到第 i - 1 个元素的地址,最后通过第 i - 1 个元素的地址知道第 i 个元素的地址 , 这种就叫做顺序存取
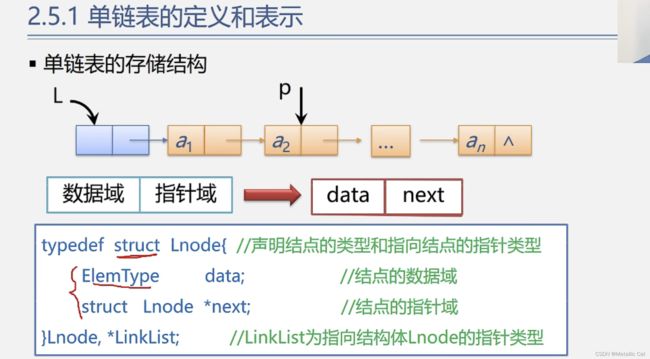
1.上面这个 typedef 同时重命名了两次,第一次是将 struct Lnode 重命名为 LNode,第二次是将struct Lnode* 重命名为 LinkList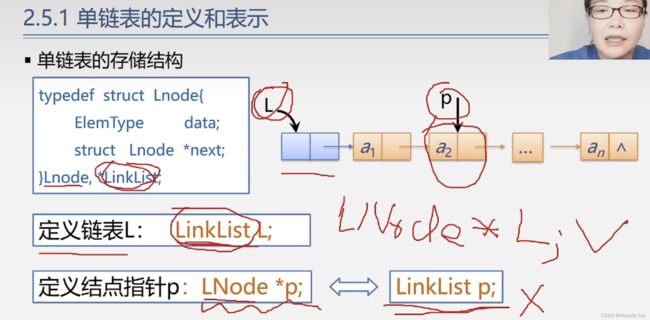
定义链表L其实就是定义链表的 头指针 L
第二部分 --- 线性表的链式表示和实现(3,4)
1.status其实是int,OK其实是 1
2.在使用这个算法前我们需要先创建一个头指针,然后将头指针作为实参以引用的方式传到函数(算法)中。
3.在算法中我们要创建一个指针域为空指针的头结点,来实现我们创建一个空表的算法目的:
首先我们要在堆区中创建一个头结点,然后用我们的头指针指向这个头结点(其实就是算法第一步操作 --- new后会返回我们在堆区创建的内存空间的首个内存单元的地址,传过来的地址的步长跟随接收它的指针的指针类型对应的步长)
然后我们要将这个头结点的指针域置为空指针(实现创建空表的目的) ---- 直接用指向头结点的指针加上尖头操作符加上要访问的成员来实现操作
1.如果链表为空,则链表的头结点的指针域为空指针,若不为空指针则链表不为空
所以我们可以根据链表的头结点的指针域来判断链表是否为空
1.销毁单链表时我们要实现的效果是:头指针变为空指针,所有结点在堆区中开辟的内存空间都被释放掉 ---- 实现这个目的的算法就在上面 ---- 关键点是我们要创建一个临时指针P,来实现L在移动的同时结点的内存空间被释放 --- 具体实现步骤是 令 P = L,使得P指向L当前指向的结点,然后让L前移,然后我们再通过P来释放掉结点的内存空间,然后就这样循环往复知道整个将链销毁完毕
第三部分 --- 线性表的链式表示和实现(5,6)
 1.清空链表要实现的目的是:销毁链表中除头结点外的所有结点,同时将头结点的指针域置为空指针 (头指针依然还在,且指向头结点)
1.清空链表要实现的目的是:销毁链表中除头结点外的所有结点,同时将头结点的指针域置为空指针 (头指针依然还在,且指向头结点)
1.算法执行的逻辑和销毁链表其实差不多

1.创建一个指针P和一个整型变量 i ,从头结点开始,将结点的指针域赋值给指针P,如果指针P不是空指针,则 i ++ ,如果指针P是空指针,则所有结点都已经统计完毕,直接返回当前 i 值 -- 即链表中的结点个数(链表长度)(头指针和头结点不计入链表长度) 
第四部分 --- 线性表的链式表示和实现(7,8)
1.链表是顺序存储结构。
随机存取结构:我们可以直接读取结构中的任意一个元素
顺序存取结构:在读取结构中的第i个元素的时候需要我们先读取它前面的 i - 1个元素 

1.查找分为两种类型:一种是查给定数据在链表中对应的元素的地址,另一种是查给定数据在链表中对应的元素是第几个元素
1.链表查找完毕的标志就是P变为一个空指针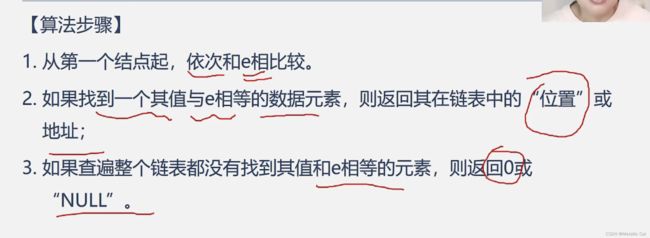

1.如果P不是空指针(没查找完链表)且我们没找到数据对应的元素,那就继续找下去
第五部分 --- 线性表的链式表示和实现(9,10)
1.在插入值之前,我们需要先将这个值创建出来
注意哦,这个算法是在第 i 个结点前插入值
1.
上面这一步其是对选择了结点范围外的位置的报错,一个是在右边范围外,一个是在左边范围外 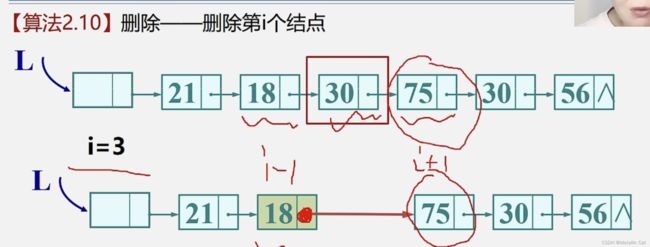
1.无论是删除第 i 个结点,还是在第i 个结点前面插入新结点,我们都需要先找到第 i -1个结点
1.如果有需要的话我们可以自己保存要被删除的结点的值
注意:我们要临时保存被删除结点的地址(用指针来保存),这样我们才能够将被删除结点对应的内存空间释放掉,使其真正被删除
第六部分 --- 前面那些算法的时间效率分析(11)
1.插入和删除算法修改指针的时间复杂度是O(1),但是由于还需要找到前驱结点,所以依然需要进行查找,所以时间复杂度最终是O(n)