kubeadm安装高可用k8s集群(十四)
电脑内存最好32G以上。
1 高可用集群规划图

2 主机规划
|
角色
|
IP地址
|
操作系统
|
配置
|
主机名称
|
|
Master1
|
192.168.18.100
|
CentOS7.x,基础设施服务器
|
2核CPU,3G内存,50G硬盘
|
k8s-master01
|
|
Master2
|
192.168.18.101
|
CentOS7.x,基础设施服务器
|
2核CPU,3G内存,50G硬盘
|
k8s-master02
|
|
Master3
|
192.168.18.102
|
CentOS7.x,基础设施服务器
|
2核CPU,3G内存,50G硬盘
|
k8s-master03
|
|
Node1
|
192.168.18.103
|
CentOS7.x,基础设施服务器
|
2核CPU,3G内存,50G硬盘
|
k8s-node01
|
|
Node1
|
192.168.18.104
|
CentOS7.x,基础设施服务器
|
2核CPU,3G内存,50G硬盘
|
k8s-node02
|
3 环境搭建
3.1 前言
● 本次搭建的环境需要五台CentOS服务器(三主二从),然后在每台服务器中分别安装Docker、kubeadm和kubectl以及kubelet。
没有特殊说明,就是所有机器都需要执行。
3.2 环境初始化
3.2.1 检查操作系统的版本
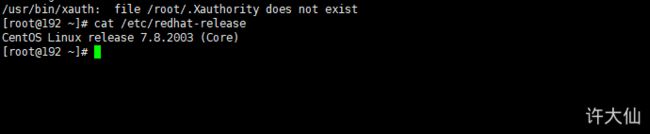
● 检查操作系统的版本(要求操作系统的版本至少在7.5以上):
cat /etc/redhat-release
3.2.2 关闭防火墙并禁止防火墙开机启动
● 关闭防火墙:
systemctl stop firewalld
● 禁止防火墙开机启动:
systemctl disable firewalld
3.2.3 设置主机名
● 设置主机名:
hostnamectl set-hostname <hostname>
● 设置192.168.18.100的主机名:
hostnamectl set-hostname k8s-master01
● 设置192.168.18.101的主机名:
hostnamectl set-hostname k8s-master02
● 设置192.168.18.102的主机名:
hostnamectl set-hostname k8s-master03
● 设置192.168.18.103的主机名:
hostnamectl set-hostname k8s-node01
● 设置192.168.18.104的主机名:
hostnamectl set-hostname k8s-node02
3.2.4 主机名解析
● 为了方便后面集群节点间的直接调用,需要配置一下主机名解析,企业中推荐使用内部的DNS服务器。
cat >> /etc/hosts << EOF
192.168.18.100 k8s-master01
192.168.18.101 k8s-master02
192.168.18.102 k8s-master03
192.168.18.103 k8s-node01
192.168.18.104 k8s-node02
192.168.18.110 k8s-master-lb # VIP(虚拟IP)用于LoadBalance,如果不是高可用集群,该IP可以是k8s-master01的IP
EOF
3.2.5 时间同步
● kubernetes要求集群中的节点时间必须精确一致,所以在每个节点上添加时间同步:
yum install ntpdate -y
ntpdate time.windows.com
3.2.6 关闭selinux
● 查看selinux是否开启:
getenforce
● 永久关闭selinux,需要重启:
sed -i 's/enforcing/disabled/' /etc/selinux/config
● 临时关闭selinux,重启之后,无效:
setenforce 0
3.2.7 关闭swap分区
● 永久关闭swap分区,需要重启:
sed -ri 's/.*swap.*/#&/' /etc/fstab
● 临时关闭swap分区,重启之后,无效::
swapoff -a
3.2.8 将桥接的IPv4流量传递到iptables的链
● 在每个节点上将桥接的IPv4流量传递到iptables的链:
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
EOF
# 加载br_netfilter模块
modprobe br_netfilter
# 查看是否加载
lsmod | grep br_netfilter
# 生效
sysctl --system
3.2.9 开启ipvs
在kubernetes中service有两种代理模型,一种是基于iptables,另一种是基于ipvs的。ipvs的性能要高于iptables的,但是如果要使用它,需要手动载入ipvs模块。
在每个节点安装ipset和ipvsadm:
yum -y install ipset ipvsadm
在所有节点执行如下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
授权、运行、检查是否加载:
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
检查是否加载:
lsmod | grep -e ipvs -e nf_conntrack_ipv4
3.2.10 所有节点配置limit
临时生效:
ulimit -SHn 65536
永久生效:
vim /etc/security/limits.conf
# 末尾追加如下的内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
* soft memlock unlimited
* soft memlock unlimited
3.2.11 在k8s-master01节点设置免密钥登录到其他节点
● 在k8s-master01节点生成配置文件和整数,并传输到其他节点上。
# 遇到输入,直接Enter即可
ssh-keygen -t rsa
for i in k8s-master01 k8s-master02 k8s-master03 k8s-node01 k8s-node02;do ssh-copy-id -i .ssh/id_rsa.pub $i;done
3.2.12 所有节点升级系统并重启
● 所有节点升级系统并重启,此处没有升级内核:
yum -y --exclude=kernel* update && reboot
3.3 内核配置
3.3.1 查看默认的内核
● 查看默认的内核:
uname -r
![]()
3.3.2 升级内核配置
CentOS7需要升级内核到4.18+。
在 CentOS 7 上启用 ELRepo 仓库:
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
仓库启用后,你可以使用下面的命令列出可用的内核相关包:
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
安装最新的主线稳定内核:
yum -y --enablerepo=elrepo-kernel install kernel-ml
设置 GRUB 默认的内核版本:
vim /etc/default/grub
# 修改部分, GRUB 初始化页面的第一个内核将作为默认内核
GRUB_DEFAULT=0
# 重新创建内核配置
grub2-mkconfig -o /boot/grub2/grub.cfg
重启机器应用最新内核:
reboot
查看最新内核版本:
uname -sr
3.4 每个节点安装Docker、kubeadm、kubelete和kubectl
3.4.1 安装Docker
安装Docker:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum -y install docker-ce-20.10.2
systemctl enable docker && systemctl start docker
docker version
设置Docker镜像加速器:
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],
"live-restore": true,
"log-driver":"json-file",
"log-opts": {"max-size":"500m", "max-file":"3"}
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
3.4.2 添加阿里云的YUM软件源
● 由于kubernetes的镜像源在国外,非常慢,这里切换成国内的阿里云镜像源:
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3.4.3 安装kubeadm、kubelet和kubectl
查看kubeadm的版本:
yum list kubeadm.x86_64 --showduplicates | sort -r
由于版本更新频繁,这里指定版本号部署:
yum install -y kubelet-1.20.2 kubeadm-1.20.2 kubectl-1.20.2
为了实现Docker使用的cgroup drvier和kubelet使用的cgroup drver一致,建议修改"/etc/sysconfig/kubelet"文件的内容:
vim /etc/sysconfig/kubelet
# 修改
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
所有的节点设置为开机自启动即可,由于没有生成配置文件,集群初始化后会自动启动:
systemctl enable kubelet
3.5 高可用组件安装
注意:如果不是高可用集群,haproxy和keepalived无需安装。
k8s-master01、k8s-master02、k8s-master03节点通过yum安装HAProxy和keepAlived。
yum -y install keepalived haproxy
k8s-master01、k8s-master02、k8s-master03节点配置HAProxy:
mkdir -pv /etc/haproxy
vim /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
listen stats
bind *:8006
mode http
stats enable
stats hide-version
stats uri /stats
stats refresh 30s
stats realm Haproxy\ Statistics
stats auth admin:admin
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
# 下面的配置根据实际情况修改
server k8s-master01 192.168.18.100:6443 check
server k8s-master02 192.168.18.101:6443 check
server k8s-master03 192.168.18.102:6443 check
k8s-master01配置Keepalived:
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
## 标识本节点的字条串,通常为 hostname
router_id k8s-master01
script_user root
enable_script_security
}
## 检测脚本
## keepalived 会定时执行脚本并对脚本执行的结果进行分析,动态调整 vrrp_instance 的优先级。如果脚本执行结果为 0,并且 weight 配置的值大于 0,则优先级相应的增加。如果脚本执行结果非 0,并且 weight配置的值小于 0,则优先级相应的减少。其他情况,维持原本配置的优先级,即配置文件中 priority 对应的值。
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
# 每2秒检查一次
interval 2
# 一旦脚本执行成功,权重减少5
weight -5
fall 3
rise 2
}
## 定义虚拟路由,VI_1 为虚拟路由的标示符,自己定义名称
vrrp_instance VI_1 {
## 主节点为 MASTER,对应的备份节点为 BACKUP
state MASTER
## 绑定虚拟 IP 的网络接口,与本机 IP 地址所在的网络接口相同
interface ens33
# 主机的IP地址
mcast_src_ip 192.168.18.100
# 虚拟路由id
virtual_router_id 100
## 节点优先级,值范围 0-254,MASTER 要比 BACKUP 高
priority 100
## 优先级高的设置 nopreempt 解决异常恢复后再次抢占的问题
nopreempt
## 组播信息发送间隔,所有节点设置必须一样,默认 1s
advert_int 2
## 设置验证信息,所有节点必须一致
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
## 虚拟 IP 池, 所有节点设置必须一样
virtual_ipaddress {
## 虚拟 ip,可以定义多个
192.168.18.110
}
track_script {
chk_apiserver
}
}
k8s-master02配置Keepalived:
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id k8s-master02
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.18.101
virtual_router_id 101
priority 99
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.18.110
}
track_script {
chk_apiserver
}
}
k8s-master02配置Keepalived:
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id k8s-master03
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.18.102
virtual_router_id 102
priority 98
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.18.110
}
track_script {
chk_apiserver
}
}
在k8s-master01、k8s-master02、k8s-master03上新建监控脚本,并设置权限:
vim /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 5)
do
check_code=$(pgrep kube-apiserver)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 5
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
chmod +x /etc/keepalived/check_apiserver.sh
● 在k8s-master01、k8s-master02、k8s-master03上启动haproxy和keepalived:
systemctl daemon-reload
systemctl enable --now haproxy
systemctl enable --now keepalived
● 测试VIP(虚拟IP):
ping 192.168.18.110 -c 4
3.6 部署k8s的Master节点
3.6.1 yaml配置文件的方式部署k8s的Master节点
● 在k8s-master01创建kubeadm-config.yaml,内容如下:
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.18.100 # 本机IP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01 # 本主机名
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.18.110:16443" # 虚拟IP和haproxy端口
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 镜像仓库源
kind: ClusterConfiguration
kubernetesVersion: v1.20.2 # k8s版本
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: "10.96.0.0/12"
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
可以使用如下的命令更新kubeadm-config.yaml文件,需要将k8s设置到对应的版本:
kubeadm config migrate --old-config kubeadm-config.yaml --new-config "new.yaml"
将new.yaml文件复制到所有的master节点
scp new.yaml k8s-master02:/root/new.yaml
scp new.yaml k8s-master03:/root/new.yaml
所有的master节点提前下载镜像,可以节省初始化时间:
kubeadm config images pull --config /root/new.yaml
k8s-master01节点初始化后,会在/etc/kubernetes目录下生成对应的证书和配置文件,之后其他的Master节点加入到k8s-master01节点即可。
kubeadm init --config /root/new.yaml --upload-certs
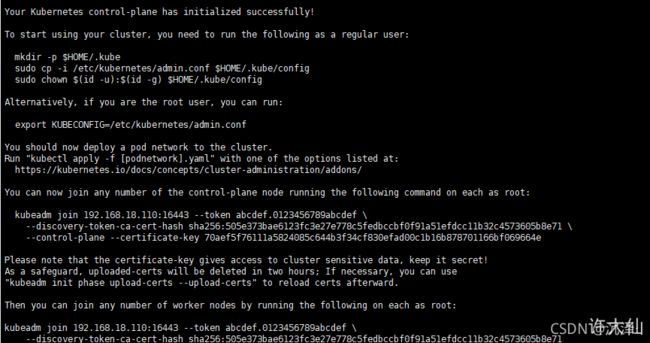
● 如果初始化失败,重置后再次初始化,命令如下:
kubeadm reset -f;ipvsadm --clear;rm -rf ~/.kube
● 初始化成功后,会产生token值,用于其他节点加入时使用,
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:505e373bae6123fc3e27e778c5fedbccbf0f91a51efdcc11b32c4573605b8e71 \
--control-plane --certificate-key 70aef5f76111a5824085c644b3f34cf830efad00c1b16b878701166bf069664e
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:505e373bae6123fc3e27e778c5fedbccbf0f91a51efdcc11b32c4573605b8e71
● k8s-master01节点配置环境变量,用于访问kubernetes集群:
○ 如果是root用户:
cat > /root/.bashrc <<EOF
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source ~/.bash_profile
○ 如果是普通用户:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
● k8s-master01中查看节点的状态:
kubectl get nodes

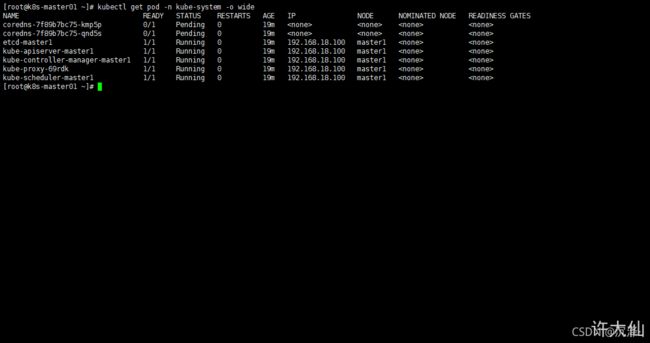
采用初始化安装方式,所有的系统组件均以容器的方式运行并且在kube-system命名空间内,此时可以在k8s-master01节点查看Pod的状态:
kubectl get pod -n kube-system -o wide
3.6.2 命令行的方式部署k8s的Master节点
在k8s-master01、k8s-master02以及k8s-master03节点输入如下的命令:
kubeadm config images pull --kubernetes-version=v1.20.2 --image-repository=registry.aliyuncs.com/google_containers
在k8s-master01节点输入如下的命令:
kubeadm init \
--apiserver-advertise-address=192.168.18.100 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=192.168.18.110:16443 \
--kubernetes-version v1.20.2 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--upload-certs
3.7 高可用Master
将k8s-master02节点加入到集群中:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:505e373bae6123fc3e27e778c5fedbccbf0f91a51efdcc11b32c4573605b8e71 \
--control-plane --certificate-key 70aef5f76111a5824085c644b3f34cf830efad00c1b16b878701166bf069664e
# 防止不能在此节点中不能使用kubectl命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
将k8s-master03节点加入到集群中:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:505e373bae6123fc3e27e778c5fedbccbf0f91a51efdcc11b32c4573605b8e71 \
--control-plane --certificate-key 70aef5f76111a5824085c644b3f34cf830efad00c1b16b878701166bf069664e
# 防止不能在此节点中不能使用kubectl命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
● 如果token过期了,需要生成新的token(在k8s-master01节点):
kubeadm token create --print-join-command
● Master节点如果要加入到集群中,需要生成–certificate-key(在k8s-master01节点):
kubeadm init phase upload-certs --upload-certs
● 然后将其他Master节点加入到集群中:
# 需要做对应的修改
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:505e373bae6123fc3e27e778c5fedbccbf0f91a51efdcc11b32c4573605b8e71 \
--control-plane --certificate-key 70aef5f76111a5824085c644b3f34cf830efad00c1b16b878701166bf069664e
3.8 Node 节点的配置
将k8s-node1加入到集群中:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:505e373bae6123fc3e27e778c5fedbccbf0f91a51efdcc11b32c4573605b8e71
● 将k8s-node2加入到集群中:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:505e373bae6123fc3e27e778c5fedbccbf0f91a51efdcc11b32c4573605b8e71
3.9 部署CNI网络插件
● 根据提示,在Master节点上使用kubectl工具查看节点状态:
kubectl get node

● kubernetes支持多种网络插件,比如flannel、calico、canal等,任选一种即可,本次选择flannel。
● 在所有Master节点上获取flannel配置文件(可能会失败,如果失败,请下载到本地,然后安装,如果网速不行,请点这里,当然,你也可以安装calico,请点这里,推荐安装calico):
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
● 在所有Master节点使用配置文件启动flannel:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
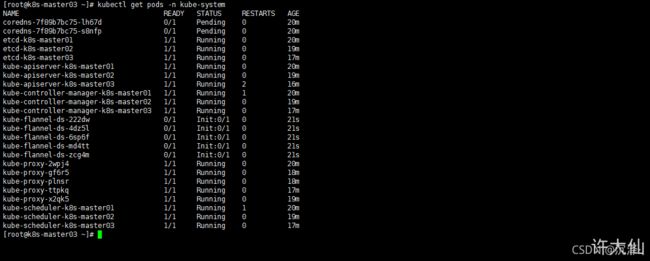
● 在所有Master节点查看部署CNI网络插件进度:
kubectl get pods -n kube-system
● 在所有Master节点再次使用kubectl工具查看节点状态:
kubectl get nodes

在所有Master节点查看集群健康状况:
kubectl get cs

发现集群不健康,那么需要注释掉etc/kubernetes/manifests下的kube-controller-manager.yaml和kube-scheduler.yaml的–port=0:
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.244.0.0/16
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
# 修改部分
# - --port=0
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=10.96.0.0/12
- --use-service-account-credentials=true
vim /etc/kubernetes/manifests/kube-scheduler.yaml
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
# 修改部分
# - --port=0
在所有Master节点再次查看集群健康状况:
kubectl get cs
