Java NIO学习笔记概述
refer to original
文章目录
- 1.Java NIO Tutorial
-
- Java NIO: Channels and Buffers(通道和缓冲区)
- Java NIO: Non-blocking IO(非阻塞IO)
- Java NIO: Selectors(选择器)
- 2.Java NIO Overview
-
- Channels and Buffers
- Selectors
- 3.Java NIO Channel
-
- Channel Implementations
- Basic Channel Example
- 4.Java NIO Buffer
-
- Basic Buffer Usage
- Buffer Capacity, Position and Limit
-
- Capacity
- Position
- Limit
- Buffer Types
- Allocating a Buffer
- Writing Data to a Buffer
-
- flip()
- Reading Data from a Buffer
-
- rewind()
- clear() and compact()
- mark() and reset()
- equals() and compareTo()
-
- equals()
- compareTo()
- 5.Java NIO Scatter / Gather
-
- Scattering Reads
- Gathering Writes
- 6.Java NIO Channel to Channel Transfers
-
- transferFrom()
- transferTo()
- 7.Java NIO Selector
-
- Why Use a Selector?
- Creating a Selector
- Registering Channels with the Selector
- SelectionKey
-
- Interest Set
- Ready Set
- Channel + Selector
- Attaching Objects
- Selecting Channels via a Selector
-
- selectedKeys()
- wakeUp()
- close()
- Full Selector Example
- 8.Java NIO FileChannel
-
- Opening a FileChannel
- Reading Data from a FileChannel
- Writing Data to a FileChannel
- Closing a FileChannel
- FileChannel Position
- FileChannel Size
- FileChannel Truncate
- FileChannel Force
- 9.Java NIO SocketChannel
-
- Opening a SocketChannel
- Closing a SocketChannel
- Reading from a SocketChannel
- Writing to a SocketChannel
- Non-blocking Mode
-
- connect()
- write()
- read()
- Non-blocking Mode with Selectors
- 10.Java NIO ServerSocketChannel
-
- Opening a ServerSocketChannel
- Closing a ServerSocketChannel
- Listening for Incoming Connections
- Non-blocking Mode
- 11.Non-blocking Server
- 12.Java NIO DatagramChannel
-
- Opening a DatagramChannel
- Receiving Data
- Sending Data
- Connecting to a Specific Address
- 13.Java NIO Pipe
-
- Creating a Pipe
- Writing to a Pipe
- Reading from a Pipe
- 14.Java NIO vs. IO
-
- Main Differences Betwen Java NIO and IO
- Stream Oriented vs. Buffer Oriented
- Blocking vs. Non-blocking IO
- Selectors
- How NIO and IO Influences Application Design
-
- The API Calls
- The Processing of Data
- Summary
- 15.Java NIO Path
-
- Creating a Path Instance
-
- Creating an Absolute Path
- Creating a Relative Path
- Path.normalize()
- 16.Java NIO Files
-
- Files.exists()
- Files.createDirectory()
- Files.copy()
-
- Overwriting Existing Files
- Files.move()
- Files.delete()
- Files.walkFileTree()
-
- Searching For Files
- Deleting Directories Recursively
- Additional Methods in the Files Class
- 17.Java NIO AsynchronousFileChannel
-
- Creating an AsynchronousFileChannel
- Reading Data
-
- Reading Data Via a Future
- Reading Data Via a CompletionHandler
- Writing Data
-
- Writing Data Via a Future
- Writing Data Via a CompletionHandler
1.Java NIO Tutorial
Java NIO(New IO)是一个可以替代标准Java IO API的IO API(从Java 1.4开始),Java NIO提供了与标准IO不同的IO工作方式。
Java NIO: Channels and Buffers(通道和缓冲区)
标准的IO基于字节流和字符流进行操作的,而NIO是基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
Java NIO: Non-blocking IO(非阻塞IO)
Java NIO可以让你非阻塞的使用IO,例如:当线程从通道读取数据到缓冲区时,线程还是可以进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。
Java NIO: Selectors(选择器)
Java NIO引入了选择器的概念,选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。
2.Java NIO Overview
Java NIO 由以下几个核心部分组成:
- Channels
- Buffers
- Selectors
虽然Java NIO 中除此之外还有很多类和组件,但在我看来,Channel,Buffer 和 Selector 构成了核心的API。其它组件,如Pipe和FileLock,只不过是与三个核心组件共同使用的工具类。因此我将主要介绍这三个组件在本段,其他组件将在本系列文章的其他章节介绍
Channels and Buffers
基本上,所有的 IO 在NIO 中都从一个Channel 开始。Channel 有点象流。 数据可以从Channel读到Buffer中,也可以从Buffer 写到Channel中。如图所示:
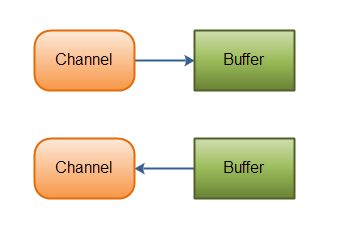
Java NIO: Channels read data into Buffers, and Buffers write data into Channels
JAVA NIO中的一些主要Channel的实现:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
更多详情见NIO-Channel-UML
正如你所看见的一样,这些channel覆盖了UDP、TCP 网络 IO、文件IO。
这些类还附带了一些有趣的接口,但是为了简单起见,我将把它们排除在这个Java NIO概述之外。在本Java NIO教程的其他文本中,将在相关的地方对它们进行解释。
Java NIO里关键的Buffer实现:
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
更多详情见NIO-Buffer-UML
这些Buffer包含通过IO传输的所有基本数据类型:byte, short, int, long, float, double 和 char。
Java NIO还有一个MappedByteBuffer,它与内存映射文件一起使用。不过,我将把这个缓冲区从这个概述中去掉。
Selectors
Selector允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。例如,在一个聊天服务器中。
如图所示
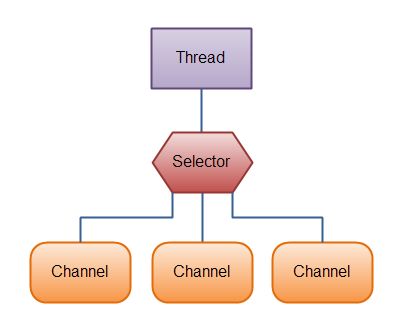
要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新连接进来,数据接收等。
3.Java NIO Channel
Java NIO通道与streams相似,但有一些不同:
- 既可以从通道中读取数据,又可以写数据到通道。但流的读写通常是单向的(read or write)。
- 通道可以异步地读写。
- 通道中的数据总是要先读到一个Buffer,或者总是要从一个Buffer中写入。
正如上面所说,从通道读取数据到缓冲区,从缓冲区写入数据到通道。如下图所示:
Java NIO: Channels read data into Buffers, and Buffers write data into Channels
Channel Implementations
这些是Java NIO中最重要的通道的实现:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
FileChannel 从文件中读写数据。
DatagramChannel 能通过UDP读写网络中的数据。
SocketChannel 能通过TCP读写网络中的数据。
ServerSocketChannel可以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel。
Basic Channel Example
下面是一个使用FileChannel读取数据到Buffer中的示例:
String path = "/Users/nsh/data";
FileInputStream fileInputStream = new FileInputStream(new File(path));
//RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
//FileChannel inChannel = aFile.getChannel();
try {
FileChannel inChannel = fileInputStream.getChannel();
ByteBuffer buf = ByteBuffer.allocate(32);
int bytesRead = 0;
while (bytesRead != -1) {
bytesRead = inChannel.read(buf);
if (bytesRead == -1) {
break;
}
buf.flip();
while (buf.hasRemaining()) {
System.out.print((char) buf.get());
}
System.out.println();
buf.clear();
}
}catch (Exception e){
e.printStackTrace();
}finally {
fileInputStream.close();
}
注意 buf.flip() 的调用,首先读取数据到Buffer,然后反转Buffer,接着再从Buffer中读取数据。下一节会深入讲解Buffer的更多细节。
4.Java NIO Buffer
Java NIO中的Buffer用于和NIO通道进行交互。如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的。
缓冲区本质上(essentially)是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装(wrapped)成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
Basic Buffer Usage
使用Buffer读写数据一般遵循以下四个步骤:
- 写入数据到Buffer
- 调用
flip()方法 - 从Buffer中读取数据
- 调用
clear()方法或者compact()方法
当向buffer写入数据时,buffer会记录下写了多少数据。一旦要读取数据,需要通过flip()方法将Buffer从写模式切换到读模式。在读模式下,可以读取之前写入到buffer的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
下面是一个使用Buffer的例子:
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
//create buffer with capacity of 48 bytes
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf); //read into buffer.
while (bytesRead != -1) {
buf.flip(); //make buffer ready for read
while(buf.hasRemaining()){
System.out.print((char) buf.get()); // read 1 byte at a time
}
buf.clear(); //make buffer ready for writing
bytesRead = inChannel.read(buf);
}
aFile.close();
Buffer Capacity, Position and Limit
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
为了理解Buffer的工作原理,需要熟悉它的三个属性:
- capacity
- position
- limit
position和limit的含义取决于Buffer处在读模式还是写模式。不管Buffer处在什么模式,capacity的含义总是一样的。
这里有一个关于capacity,position和limit在读写模式中的说明,详细的解释在插图后面。
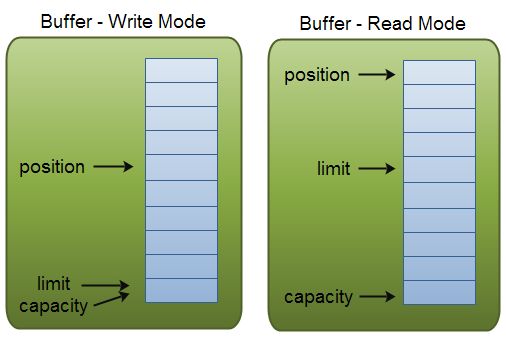
Capacity
作为一个内存块,Buffer有一个固定的大小值,也叫“capacity”.你只能往里写capacity个byte、long,char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续写数据往里写数据。
Position
当你写数据到Buffer中时,position表示当前的位置。初始的position值为0.当一个byte、long等数据写到Buffer后, position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity – 1.
当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0. 当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
Limit
在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。 写模式下,limit等于Buffer的capacity。
当切换Buffer到读模式时, limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)
Buffer Types
Java NIO 有以下Buffer类型
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
如你所见,这些Buffer类型代表了不同的数据类型。换句话说,就是可以通过char,short,int,long,float 或 double类型来操作缓冲区中的字节。
MappedByteBuffer 有些特别,在涉及它的专门章节中再讲。
Allocating a Buffer
To obtain a Buffer object you must first allocate it. Every Buffer class has an allocate() method that does this. Here is an example showing the allocation of a ByteBuffer, with a capacity of 48 bytes:
ByteBuffer buf = ByteBuffer.allocate(48);
Here is an example allocating a CharBuffer with space for 1024 characters:
CharBuffer buf = CharBuffer.allocate(1024);
Writing Data to a Buffer
写数据到Buffer有两种方式:
- 从Channel写到Buffer。
- 通过Buffer的
put()方法写到Buffer里。
Here is an example showing how a Channel can write data into a Buffer:
int bytesRead = inChannel.read(buf); //read into buffer.
Here is an example that writes data into a Buffer via the put() method:
buf.put(127);
put方法有很多版本,允许你以不同的方式把数据写入到Buffer中。例如, 写到一个指定的位置,或者把一个字节数组写入到Buffer。 更多Buffer实现的细节参考JavaDoc。
flip()
lip方法将Buffer从写模式切换到读模式。调用flip()方法会将position设回0,并将limit设置成之前position的值。
换句话说,position现在用于标记读的位置,limit表示之前写进了多少个byte、char等 —— 现在能读取多少个byte、char等。
Reading Data from a Buffer
从Buffer中读取数据有两种方式:
- 从Buffer读取数据到Channel。
- 使用get()方法从Buffer中读取数据。
Here is an example of how you can read data from a buffer into a channel:
//read from buffer into channel.
int bytesWritten = inChannel.write(buf);
Here is an example that reads data from a Buffer using the get() method:
byte aByte = buf.get();
get方法有很多版本,允许你以不同的方式从Buffer中读取数据。例如,从指定position读取,或者从Buffer中读取数据到字节数组。更多Buffer实现的细节参考JavaDoc。
rewind()
Buffer.rewind()将position设回0,所以你可以重读Buffer中的所有数据。limit保持不变,仍然表示能从Buffer中读取多少个元素(byte、char等)。
clear() and compact()
一旦读完Buffer中的数据,需要让Buffer准备好再次被写入。可以通过clear()或compact()方法来完成。
如果调用的是clear()方法,position将被设回0,limit被设置成 capacity的值。换句话说,Buffer 被清空了。Buffer中的数据并未清除,只是这些标记告诉我们可以从哪里开始往Buffer里写数据。
如果Buffer中有一些未读的数据,调用clear()方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有。
如果Buffer中仍有未读的数据,且后续还需要这些数据,但是此时想要先先写些数据,那么使用compact()方法。
compact()方法将所有未读的数据拷贝到Buffer起始处。然后将position设到最后一个未读元素正后面。limit属性依然像clear()方法一样,设置成capacity。现在Buffer准备好写数据了,但是不会覆盖未读的数据。
mark() and reset()
通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。例如:
buffer.mark();
//call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); //set position back to mark.
equals() and compareTo()
可以使用equals()和compareTo()方法两个Buffer。
equals()
当满足下列条件时,表示两个Buffer相等:
- 有相同的类型(byte、char、int等)。
- Buffer中剩余的byte、char等的个数相等。
- Buffer中所有剩余的byte、char等都相同。
如你所见,equals只是比较Buffer的一部分,不是每一个在它里面的元素都比较。实际上,它只比较Buffer中的剩余元素。
compareTo()
compareTo()方法比较两个Buffer的剩余元素(byte、char等), 如果满足下列条件,则认为一个Buffer“小于”另一个Buffer:
- 第一个不相等的元素小于另一个Buffer中对应的元素 。
- 所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素1. 数比另一个少)。
5.Java NIO Scatter / Gather
Java NIO开始支持scatter/gather,scatter/gather用于描述从Channel中读取或者写入到Channel的操作
scatter从Channel中读取是指在读操作时将读取的数据写入多个buffer中。因此,Channel将从Channel中读取的数据“scatter”到多个Buffer中。
gather写入Channel是指在写操作时将多个buffer的数据写入同一个Channel,因此,Channel 将多个Buffer中的数据“gather”后发送到Channel。
scatter / gather经常用于需要将传输的数据分开处理的场合,例如传输一个由消息头和消息体组成的消息,你可能会将消息体和消息头分散到不同的buffer中,这样你可以方便的处理消息头和消息体。
Scattering Reads
A “scattering read” reads data from a single channel into multiple buffers. Here is an illustration(图示) of that principle:
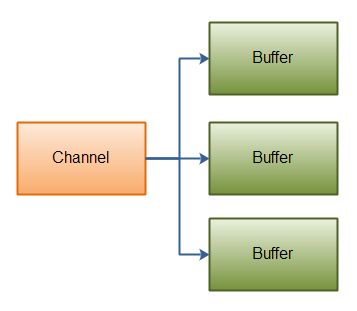
Java NIO: Scattering Read
Here is a code example that shows how to perform a scattering read:
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = { header, body };
channel.read(bufferArray);
注意buffer首先被插入到数组,然后再将数组作为channel.read() 的输入参数。read()方法按照buffer在数组中的顺序将从channel中读取的数据写入到buffer,当一个buffer被写满后,channel紧接着向另一个buffer中写。
Scattering Reads在移动下一个buffer前,必须填满当前的buffer,这也意味着它不适用于动态消息(译者注:消息大小不固定)。换句话说,如果存在消息头和消息体,消息头必须完成填充(例如 128byte),Scattering Reads才能正常工作。
Gathering Writes
A “gathering write” writes data from multiple buffers into a single channel. Here is an illustration of that principle:
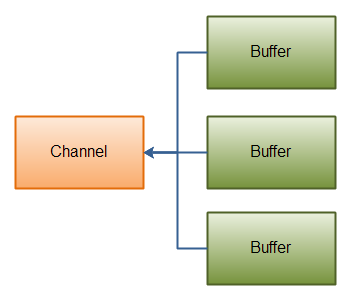
Java NIO: Gathering Write
Here is a code example that shows how to perform a gathering write:
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
//write data into buffers
ByteBuffer[] bufferArray = { header, body };
channel.write(bufferArray);
buffers数组是write()方法的入参,write()方法会按照buffer在数组中的顺序,将数据写入到channel,注意只有position和limit之间的数据才会被写入。因此,如果一个buffer的容量为128byte,但是仅仅包含58byte的数据,那么这58byte的数据将被写入到channel中。因此与Scattering Reads相反,Gathering Writes能较好的处理动态消息。
6.Java NIO Channel to Channel Transfers
In Java NIO you can transfer data directly from one channel to another, if one of the channels is a FileChannel. The FileChannel class has a transferTo() and a transferFrom() method which does this for you.
transferFrom()
FileChannel的transferFrom()方法可以将数据从源通道传输到FileChannel中。下面是一个简单的例子:
RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
FileChannel fromChannel = fromFile.getChannel();
RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
FileChannel toChannel = toFile.getChannel();
long position = 0;
long count = fromChannel.size();
toChannel.transferFrom(fromChannel, position, count);
方法的输入参数position表示从position处开始向目标文件写入数据,count表示最多传输的字节数。如果源通道的剩余空间小于 count 个字节,则所传输的字节数要小于请求的字节数。
此外要注意,在SoketChannel的实现中,SocketChannel只会传输此刻准备好的数据(可能不足count字节)。因此,SocketChannel可能不会将请求的所有数据(count个字节)全部传输到FileChannel中。
transferTo()
The transferTo() method transfer from a FileChannel into some other channel. Here is a simple example:
RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
FileChannel fromChannel = fromFile.getChannel();
RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
FileChannel toChannel = toFile.getChannel();
long position = 0;
long count = fromChannel.size();
fromChannel.transferTo(position, count, toChannel);
是不是发现这个例子和前面那个例子特别相似?除了调用方法的FileChannel对象不一样外,其他的都一样。
上面所说的关于SocketChannel的问题在transferTo()方法中同样存在。SocketChannel会一直传输数据直到目标buffer被填满。
7.Java NIO Selector
Selector(选择器)是Java NIO中能够检测一到多个NIO通道,并能够知晓通道是否为诸如读写事件做好准备的组件。这样,一个单独的线程可以管理多个channel,从而管理多个网络连接。
Why Use a Selector?
仅用单个线程来处理多个Channels的好处(advantage)是,只需要更少的线程来处理通道。
事实上,可以只用一个线程处理所有的通道。对于操作系统来说,线程之间上下文切换的开销很大,而且每个线程都要占用系统的一些资源(如内存)。因此,使用的线程越少越好。
但是,需要记住,现代的操作系统和CPU在多任务方面表现的越来越好,所以多线程的开销随着时间的推移,变得越来越小了。实际上,如果一个CPU有多个内核,不使用多任务可能是在浪费CPU能力。不管怎么说,关于那种设计的讨论应该放在另一篇不同的文章中。在这里,只要知道使用Selector能够处理多个通道就足够了。
Here is an illustration of a thread using a Selector to handle 3 Channel’s:
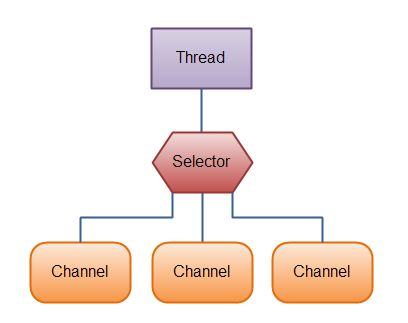
Java NIO: A Thread uses a Selector to handle 3 Channel’s
Creating a Selector
You create a Selector by calling the Selector.open() method, like this:
Selector selector = Selector.open();
Registering Channels with the Selector
为了将Channel和Selector配合使用,必须将channel注册到selector上。通过SelectableChannel.register()方法来实现,如下:
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
与Selector一起使用时,Channel必须处于非阻塞模式下。这意味着不能将FileChannel与Selector一起使用,因为FileChannel不能切换到非阻塞模式。而套接字通道都可以。
注意register()方法的第二个参数。这是一个“interest set”,意思是在通过Selector监听Channel时对什么事件感兴趣。可以监听四种不同类型的事件:
- Connect
- Accept
- Read
- Write
通道触发了一个事件意思是该事件已经就绪。所以,某个channel成功连接到另一个服务器称为“连接就绪”。一个server socket channel准备好接收新进入的连接称为“接收就绪”。一个有数据可读的通道可以说是“读就绪”。等待写数据的通道可以说是“写就绪”。
这四种事件用SelectionKey的四个常量来表示:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
如果你对不止一种事件感兴趣,那么可以用“位或”操作符将常量连接起来,如下:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
在下面还会继续提到interest set。
SelectionKey
在上一小节中,当向Selector注册Channel时,register()方法会返回一个SelectionKey对象。这个对象包含了一些你感兴趣的属性:
- The interest set
- The ready set
- The Channel
- The Selector
- An attached object(附加的对象) (optional)
I’ll describe these properties below.
Interest Set
就像Registering Channels with the Selector一节中所描述的,interest set是你所选择的感兴趣的事件集合。可以通过SelectionKey读写interest set,像这样:
int interestSet = selectionKey.interestOps();
boolean isInterestedInAccept = interestSet & SelectionKey.OP_ACCEPT;
boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT;
boolean isInterestedInRead = interestSet & SelectionKey.OP_READ;
boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE;
可以看到,用“&”操作interest set和给定的SelectionKey常量,可以确定某个确定的事件是否在interest set中。
Ready Set
ready set是通道已经准备就绪的操作的集合。在一次选择(Selection)之后,你会首先访问这个ready set。Selection将在下一小节进行解释。可以这样访问ready集合:
int readySet = selectionKey.readyOps();
可以用像检测interest集合那样的方法,来检测channel中什么事件或操作已经就绪。但是,也可以使用以下四个方法,它们都会返回一个布尔类型:
selectionKey.isAcceptable();
selectionKey.isConnectable();
selectionKey.isReadable();
selectionKey.isWritable();
Channel + Selector
从SelectionKey访问Channel和Selector很简单。如下:
Channel channel = selectionKey.channel();
Selector selector = selectionKey.selector();
Attaching Objects
可以将一个对象或者更多信息附着到SelectionKey上,这样就能方便的识别某个给定的通道。例如,可以附加 与通道一起使用的Buffer,或是包含聚集数据的某个对象。使用方法如下:
selectionKey.attach(theObject);
Object attachedObj = selectionKey.attachment();
还可以在用register()方法向Selector注册Channel的时候附加对象。如:
SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);
Selecting Channels via a Selector
一旦向Selector注册了一或多个通道,就可以调用几个重载的select()方法。这些方法返回你所感兴趣的事件(如连接、接受、读或写)已经准备就绪的那些通道。换句话说,如果你对“读就绪”的通道感兴趣,select()方法会返回读事件已经就绪的那些通道。
下面是select()方法:
- int select()
- int select(long timeout)
- int selectNow()
select()阻塞到至少有一个通道在你注册的事件上就绪了。
select(long timeout)和select()一样,除了最长会阻塞timeout毫秒(参数)。
selectNow()不会阻塞,不管什么通道就绪都立刻返回(此方法执行非阻塞的选择操作。如果自从前一次选择操作后,没有通道变成可选择的,则此方法直接返回零。)
select()方法返回的int值表示有多少通道已经就绪。亦即,自上次调用select()方法后有多少通道变成就绪状态。如果调用select()方法,因为有一个通道变成就绪状态,返回了1,若再次调用select()方法,如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的channel没有做任何操作,现在就有两个就绪的通道,但在每次select()方法调用之间,只有一个通道就绪了。
selectedKeys()
一旦调用了select()方法,并且返回值表明有一个或更多个通道就绪了,然后可以通过调用selector的selectedKeys()方法,访问“已选择键集(selected key set)”中的就绪通道。如下所示:
Set selectedKeys = selector.selectedKeys();
当像Selector注册Channel时,Channel.register()方法会返回一个SelectionKey 对象。这个对象代表了注册到该Selector的通道。可以通过SelectionKey的selectedKeySet()方法访问这些对象。
可以遍历这个已选择的键集合来访问就绪的通道。如下:
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
这个循环遍历已选择键集中的每个键,并检测各个键所对应的通道的就绪事件。
注意每次迭代末尾的keyIterator.remove()调用。Selector不会自己从已选择键集中移除SelectionKey实例。必须在处理完通道时自己移除。下次该通道变成就绪时,Selector会再次将其放入已选择键集中。
SelectionKey.channel()方法返回的通道需要转型成你要处理的类型,如ServerSocketChannel或SocketChannel等。
wakeUp()
某个线程调用select()方法后阻塞了,即使没有通道已经就绪,也有办法让其从select()方法返回。只要让其它线程在第一个线程调用select()方法的那个对象上调用Selector.wakeup()方法即可。阻塞在select()方法上的线程会立马返回。
如果有其它线程调用了wakeup()方法,但当前没有线程阻塞在select()方法上,下个调用select()方法的线程会立即“醒来(wake up)”。
close()
用完Selector后调用其close()方法会关闭该Selector,且使注册到该Selector上的所有SelectionKey实例无效。通道本身并不会关闭。
Full Selector Example
这里有一个完整的示例,打开一个Selector,注册一个通道注册到这个Selector上(通道的初始化过程略去),然后持续监控这个Selector的四种事件(接受,连接,读,写)是否就绪。
Selector selector = Selector.open();
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
while(true) {
int readyChannels = selector.selectNow();
if(readyChannels == 0) continue;
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
}
8.Java NIO FileChannel
Java NIO中的FileChannel是一个连接到文件的通道。可以通过文件通道读写文件。
FileChannel无法设置为非阻塞模式,它总是运行在阻塞模式下。
Opening a FileChannel
在使用FileChannel之前,必须先打开它。但是,我们无法直接打开一个FileChannel,需要通过使用一个InputStream、OutputStream或RandomAccessFile来获取一个FileChannel实例。下面是通过RandomAccessFile打开FileChannel的示例:
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
Reading Data from a FileChannel
调用多个read()方法之一从FileChannel中读取数据。如:
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf);
首先,分配一个Buffer。从FileChannel中读取的数据将被读到Buffer中。
然后,调用FileChannel.read()方法。该方法将数据从FileChannel读取到Buffer中。read()方法返回的int值表示了有多少字节被读到了Buffer中。如果返回-1,表示到了文件末尾。
Writing Data to a FileChannel
使用FileChannel.write()方法向FileChannel写数据,该方法的参数是一个Buffer。如:
String newData = "New String to write to file..." + System.currentTimeMillis();
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()) {
channel.write(buf);
}
注意FileChannel.write()是在while循环中调用的。因为无法保证write()方法一次能向FileChannel写入多少字节,因此需要重复调用write()方法,直到Buffer中已经没有尚未写入通道的字节。
Closing a FileChannel
When you are done using a FileChannel you must close it. Here is how that is done:
channel.close();
FileChannel Position
有时可能需要在FileChannel的某个特定位置进行数据的读/写操作。可以通过调用position()方法获取FileChannel的当前位置。
也可以通过调用position(long pos)方法设置FileChannel的当前位置。
Here are two examples:
long pos channel.position();
channel.position(pos +123);
如果将位置设置在文件结束符之后,然后试图从文件通道中读取数据,读方法将返回-1 —— 文件结束标志。
如果将位置设置在文件结束符之后,然后向通道中写数据,文件将撑大到当前位置并写入数据。这可能导致“文件空洞”,磁盘上物理文件中写入的数据间有空隙。
FileChannel Size
FileChannel实例的size()方法将返回该实例所关联文件的大小。如:
long fileSize = channel.size();
FileChannel Truncate
可以使用FileChannel.truncate()方法截取一个文件。截取文件时,文件将中指定长度后面的部分将被删除。如:
channel.truncate(1024);
这个例子截取文件的前1024个字节。
FileChannel Force
FileChannel.force()方法将通道里尚未写入磁盘的数据强制写到磁盘上。出于性能方面的考虑,操作系统会将数据缓存在内存中,所以无法保证写入到FileChannel里的数据一定会即时写到磁盘上。要保证这一点,需要调用force()方法。
force()方法有一个boolean类型的参数,指明是否同时将文件元数据(权限信息等)写到磁盘上。
下面的例子同时将文件数据和元数据强制写到磁盘上:
channel.force(true);
9.Java NIO SocketChannel
Java NIO中的SocketChannel是一个连接到TCP网络套接字的通道。可以通过以下2种方式创建SocketChannel:
- 打开一个SocketChannel并连接到互联网上的某台服务器。
- 一个新连接到达ServerSocketChannel时,会创建一个SocketChannel。
Opening a SocketChannel
Here is how you open a SocketChannel:
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
Closing a SocketChannel
You close a SocketChannel after use by calling the SocketChannel.close() method. Here is how that is done:
socketChannel.close();
Reading from a SocketChannel
To read data from a SocketChannel you call one of the read() methods. Here is an example:
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = socketChannel.read(buf);
首先,分配一个Buffer。从SocketChannel读取到的数据将会放到这个Buffer中。
然后,调用SocketChannel.read()。该方法将数据从SocketChannel 读到Buffer中。read()方法返回的int值表示读了多少字节进Buffer里。如果返回的是-1,表示已经读到了流的末尾(连接关闭了)。
Writing to a SocketChannel
写数据到SocketChannel用的是SocketChannel.write()方法,该方法以一个Buffer作为参数。示例如下:
String newData = "New String to write to file..." + System.currentTimeMillis();
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()) {
channel.write(buf);
}
注意SocketChannel.write()方法的调用是在一个while循环中的。Write()方法无法保证能写多少字节到SocketChannel。所以,我们重复调用write()直到Buffer没有要写的字节为止。
Non-blocking Mode
可以设置 SocketChannel 为非阻塞模式(non-blocking mode).设置之后,就可以在异步模式下调用connect(), read() 和write()了。
connect()
如果SocketChannel在非阻塞模式下,此时调用connect(),该方法可能在连接建立之前就返回了。为了确定连接是否建立,可以调用finishConnect()的方法。像这样:
socketChannel.configureBlocking(false);
socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
while(! socketChannel.finishConnect() ){
//wait, or do something else...
}
write()
非阻塞模式下,write()方法在尚未写出任何内容时可能就返回了。所以需要在循环中调用write()。前面已经有例子了,这里就不赘述了。
read()
非阻塞模式下,read()方法在尚未读取到任何数据时可能就返回了。所以需要关注它的int返回值,它会告诉你读取了多少字节。
Non-blocking Mode with Selectors
非阻塞模式与选择器搭配会工作的更好,通过将一或多个SocketChannel注册到Selector,可以询问选择器哪个通道已经准备好了读取,写入等。Selector与SocketChannel的搭配使用会在后面详讲。
10.Java NIO ServerSocketChannel
Java NIO中的 ServerSocketChannel 是一个可以监听新进来的TCP连接的通道, 就像标准IO中的ServerSocket一样。ServerSocketChannel类在 java.nio.channels包中。
Here is an example:
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(9999));
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
//do something with socketChannel...
}
Opening a ServerSocketChannel
通过调用 ServerSocketChannel.open() 方法来打开ServerSocketChannel.如:
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
Closing a ServerSocketChannel
通过调用ServerSocketChannel.close() 方法来关闭ServerSocketChannel. 如:
serverSocketChannel.close();
Listening for Incoming Connections
通过 ServerSocketChannel.accept() 方法监听新进来的连接。当 accept()方法返回的时候,它返回一个包含新进来的连接的 SocketChannel。因此, accept()方法会一直阻塞到有新连接到达。
while(true){
SocketChannel socketChannel =
serverSocketChannel.accept();
//do something with socketChannel...
}
当然,也可以在while循环中使用除了true以外的其它退出准则。
Non-blocking Mode
ServerSocketChannel可以设置成非阻塞模式。在非阻塞模式下,accept() 方法会立刻返回,如果还没有新进来的连接,返回的将是null。 因此,需要检查返回的SocketChannel是否是null.如:
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(9999));
serverSocketChannel.configureBlocking(false);
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
if(socketChannel != null){
//do something with socketChannel...
}
}
11.Non-blocking Server
12.Java NIO DatagramChannel
Java NIO中的DatagramChannel是一个能收发UDP包的通道。因为UDP是无连接的网络协议,所以不能像其它通道那样读取和写入。它发送和接收的是数据包。
Opening a DatagramChannel
Here is how you open a DatagramChannel:
DatagramChannel channel = DatagramChannel.open();
channel.socket().bind(new InetSocketAddress(9999));
这个例子打开的 DatagramChannel可以在UDP端口9999上接收数据包。
Receiving Data
You receive data from a DatagramChannel by calling its receive() method, like this:
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
channel.receive(buf);
receive()方法会将接收到的数据包内容复制到指定的Buffer. 如果Buffer容不下收到的数据,多出的数据将被丢弃。
Sending Data
You can send data via a DatagramChannel by calling its send() method, like this:
String newData = "New String to write to file..." + System.currentTimeMillis();
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
int bytesSent = channel.send(buf, new InetSocketAddress("jenkov.com", 80));
这个例子发送一串字符到”jenkov.com”服务器的UDP端口80。 因为服务端并没有监控这个端口,所以什么也不会发生。也不会通知你发出的数据包是否已收到,因为UDP在数据传送方面没有任何保证。
Connecting to a Specific Address
可以将DatagramChannel“连接”到网络中的特定地址的。由于UDP是无连接的,连接到特定地址并不会像TCP通道那样创建一个真正的连接。而是锁住DatagramChannel ,让其只能从特定地址收发数据。
Here is an example:
channel.connect(new InetSocketAddress("jenkov.com", 80));
当连接后,也可以使用read()和write()方法,就像在用传统的通道一样。只是在数据传送方面没有任何保证。这里有几个例子:
int bytesRead = channel.read(buf);
int bytesWritten = channel.write(buf);
13.Java NIO Pipe
Java NIO 管道是2个线程之间的单向数据连接。Pipe有一个source通道和一个sink通道。数据会被写到sink通道,从source通道读取。
这里是Pipe原理的图示:
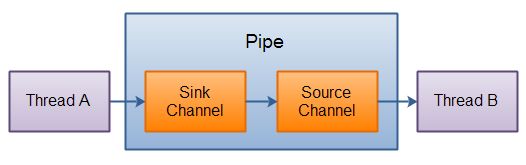
Java NIO: Pipe Internals
Creating a Pipe
You open a Pipe by calling the Pipe.open() method. Here is how that looks:
Pipe pipe = Pipe.open();
Writing to a Pipe
To write to a Pipe you need to access the sink channel. Here is how that is done:
Pipe.SinkChannel sinkChannel = pipe.sink();
You write to a SinkChannel by calling it’s write() method, like this:
String newData = "New String to write to file..." + System.currentTimeMillis();
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()) {
sinkChannel.write(buf);
}
Reading from a Pipe
To read from a Pipe you need to access the source channel. Here is how that is done:
Pipe.SourceChannel sourceChannel = pipe.source();
To read from the source channel you call its read() method like this:
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf);
The int returned by the read() method tells how many bytes were read into the buffer.
14.Java NIO vs. IO
当学习了Java NIO和IO的API后,一个问题马上涌入脑海:
我应该何时使用IO,何时使用NIO呢?在本文中,我会尽量清晰地解析Java NIO和IO的差异、它们的使用场景,以及它们如何影响您的代码设计。
Main Differences Betwen Java NIO and IO
下表总结了Java NIO和IO之间的主要差别,我会更详细地描述表中每部分的差异。
| NIO | IO |
|---|---|
| Buffer oriented | Stream oriented |
| Non blocking IO | Blocking IO |
| Selectors |
Stream Oriented vs. Buffer Oriented
Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
Blocking vs. Non-blocking IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。
非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
Selectors
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
How NIO and IO Influences Application Design
无论您选择IO或NIO工具箱,可能会影响您应用程序设计的以下几个方面:
- 对NIO或IO类的API调用。
- 数据处理。
- 用来处理数据的线程数。
The API Calls
当然,使用NIO的API调用时看起来与使用IO时有所不同,但这并不意外,因为并不是仅从一个InputStream逐字节读取,而是数据必须先读入缓冲区再处理。
The Processing of Data
使用纯粹的NIO设计相较IO设计,数据处理也受到影响。
在IO设计中,我们从InputStream或 Reader逐字节读取数据。假设你正在处理一基于行的文本数据流,例如:
Name: Anna
Age: 25
Email: [email protected]
Phone: 1234567890
该文本行的流可以这样处理:
InputStream input = ... ; // get the InputStream from the client socket
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
String nameLine = reader.readLine();
String ageLine = reader.readLine();
String emailLine = reader.readLine();
String phoneLine = reader.readLine();
请注意处理状态由程序执行多久决定。换句话说,一旦reader.readLine()方法返回,你就知道肯定文本行就已读完, readline()阻塞直到整行读完,这就是原因。你也知道此行包含名称;同样,第二个readline()调用返回的时候,你知道这行包含年龄等。 正如你可以看到,该处理程序仅在有新数据读入时运行,并知道每步的数据是什么。一旦正在运行的线程已处理过读入的某些数据,该线程不会再回退数据(大多如此)。下图也说明了这条原则:
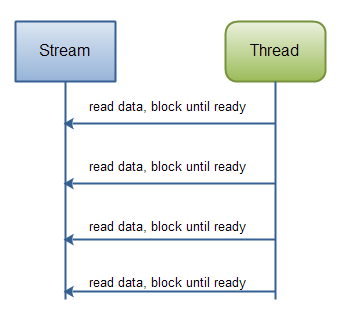
Java IO: Reading data from a blocking stream.
A NIO implementation would look different. Here is a simplified example:
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
注意第二行,从通道读取字节到ByteBuffer。当这个方法调用返回时,你不知道你所需的所有数据是否在缓冲区内。你所知道的是,该缓冲区包含一些字节,这使得处理有点困难。
假设第一次 read(buffer)调用后,读入缓冲区的数据只有半行,例如,“Name:An”,你能处理数据吗?显然不能,需要等待,直到整行数据读入缓存,在此之前,对数据的任何处理毫无意义。
所以,你怎么知道是否该缓冲区包含足够的数据可以处理呢?好了,你不知道。发现的方法只能查看缓冲区中的数据。其结果是,在你知道所有数据都在缓冲区里之前,你必须检查几次缓冲区的数据。这不仅效率低下,而且可以使程序设计方案杂乱不堪。例如:
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
while(! bufferFull(bytesRead) ) {
bytesRead = inChannel.read(buffer);
}
bufferFull()方法必须跟踪有多少数据读入缓冲区,并返回真或假,这取决于缓冲区是否已满。换句话说,如果缓冲区准备好被处理,那么表示缓冲区满了。
bufferFull()方法扫描缓冲区,但必须使缓冲区保持与调用bufferFull()方法之前相同的状态。否则,下一个读入缓冲区的数据可能不会在正确的位置读入。这并非不可能,但这是另一个需要注意的问题。
如果缓冲区已满,它可以被处理。如果它不满,并且在你的实际案例中有意义,你或许能处理其中的部分数据。但是许多情况下并非如此。下图展示了“缓冲区数据循环就绪”:
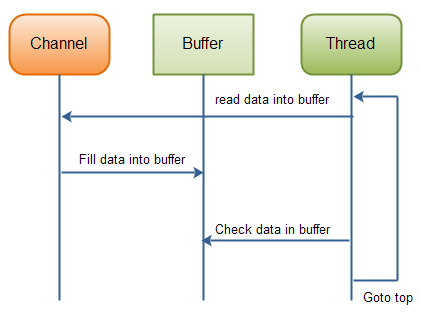
Java NIO: Reading data from a channel until all needed data is in buffer
Summary
NIO可让您只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,实现NIO的服务器可能是一个优势。同样,如果你需要维持许多打开的连接到其他计算机上,如P2P网络中,使用一个单独的线程来管理你所有出站连接,可能是一个优势。一个线程多个连接的设计方案如下图所示:
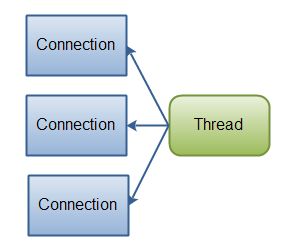
Java NIO: A single thread managing multiple connections.
如果你有少量的连接使用非常高的带宽,一次发送大量的数据,也许典型的IO服务器实现可能非常契合。下图说明了一个典型的IO服务器设计:
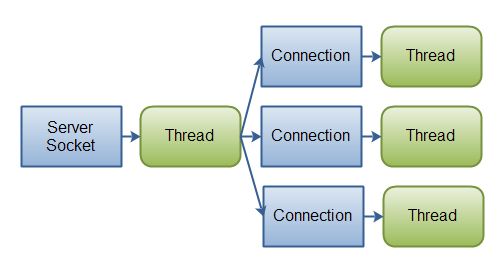
Java IO: A classic IO server design - one connection handled by one thread.
15.Java NIO Path
Java Path接口是Java NIO 2更新的一部分,Java NIO在Java 6和Java 7中接收到了这个更新。
Java Path接口被添加到Java 7中的Java NIO中。Path接口位于java.nio.file包中,因此java Path接口的完全限定名是java.nio.file.Path。
Java Path实例实例表示文件系统中的路径。路径可以指向文件或目录。路径可以是绝对路径,也可以是相对路径。绝对路径包含从文件系统根目录到它指向的文件或目录的完整路径。相对路径包含文件或目录相对于其他路径的路径。相对路径听起来可能有点混乱(confusing)。别担心。我将在本Java NIO Path教程的后面更详细地解释相对路径。
在某些操作系统中,不要将文件系统路径与path环境变量混淆。java.nio.file.Path接口与Path环境变量无关。
在许多方面,java.nio.file.Path接口与java.io.file类类似,但有一些细微的区别。不过,在许多情况下,可以使用Path接口来替换File类的使用。
Creating a Path Instance
要使用java.nio.file.Path实例,必须创建Path实例。使用名为Paths的类(java.nio.file.Paths)中的静态方法Paths.get()创建Paths实例。下面是一个Java path.get()示例:
import java.nio.file.Path;
import java.nio.file.Paths;
public class PathExample {
public static void main(String[] args) {
Path path = Paths.get("c:\\data\\myfile.txt");
}
}
Notice the two import statements at the top of the example. To use the Path interface and the Paths class we must first import them.
其次,注意Paths.get(“c:\\data\\myfile.txt”)方法调用。创建路径实例的是对Paths.get()方法的调用。换句话说,Path.get()方法是路径实例的工厂方法。
Creating an Absolute Path
创建绝对路径是通过调用Paths.get()factory方法完成的,该方法使用绝对文件作为参数。下面是创建表示绝对路径的路径实例的示例:
Path path = Paths.get("c:\\data\\myfile.txt");
绝对路径是c:\\ data\\myfile.txt。在Java字符串中,\\是必需的,因为\是转义字符,这意味着下面的字符告诉字符串中这个位置真正要定位的字符。通过编写,告诉Java编译器在字符串中写入一个字符。
上面的路径是Windows文件系统路径。在Unix系统(Linux、MacOS、FreeBSD等)上,上述绝对路径可能如下所示:
Path path = Paths.get("/home/jakobjenkov/myfile.txt");
绝对路径现在是/home/jakobjenkov/myfile.txt。
如果在Windows计算机上使用此类路径(以/开头的路径),则该路径将被解释为相对于当前驱动器。例如,路径
/home/jakobjenkov/myfile.txt
可能被解释为位于C驱动器上。然后路径将对应于此完整路径:
C:/home/jakobjenkov/myfile.txt
Creating a Relative Path
相对路径是指从一个路径(基本路径)指向一个目录或文件的路径。相对路径的完整路径(绝对路径)是通过将基路径与相对路径组合而得到的。
Java NIO Path 类也可以用于处理相对路径。使用Paths.get(basePath,relativePath)方法创建相对路径。以下是Java中的两个相对路径示例:
Path projects = Paths.get("d:\\data", "projects");
Path file = Paths.get("d:\\data","projects\\a-project\\myfile.txt");
第一个示例创建一个Java路径实例,该实例指向路径(目录)d:\\ data\\projects。第二个示例创建一个路径实例,该实例指向路径(文件)d:\\data\\projects\a-project\\myfile.txt。
使用相对路径时,可以在路径字符串内使用两个特殊代码。这些代码是:
.
..
这个 .代码表示“当前目录”。例如,如果创建如下相对路径:
Path currentDir = Paths.get(".");
System.out.println(currentDir.toAbsolutePath());
Path.normalize()
Path接口的normalize()方法可以规范化路径。规范化意味着它删除所有的.还有..在路径字符串中间编码,并解析路径字符串引用的路径。下面是一个Java Path.normalize()示例:
String originalPath ="d:\\data\\projects\\a-project\\..\\another-project";
Path path1 = Paths.get(originalPath);
System.out.println("path1 = " + path1);
Path path2 = path1.normalize();
System.out.println("path2 = " + path2);
此Path示例首先创建带有..的路径字符串在中间。然后,该示例从该路径字符串创建一个Path实例,并输出该Path实例(实际上它输出Path.toString())。
然后,该示例对创建的Path实例调用normalize(),该实例将返回一个新的Path实例。这个新的、规范化的Path实例也会被打印出来。
以下是从上述示例打印的输出:
path1 = d:\data\projects\a-project\..\another-project
path2 = d:\data\projects\another-project
如您所见,规范化路径不包含a-project\..部分,因为这是多余的。删除的部分不会向最终绝对路径添加任何内容。
16.Java NIO Files
Java NIO Files类(java.nio.file.Files)提供了几种在文件系统中操作文件的方法。本Java NIO文件教程将介绍这些方法中最常用的方法。Files类包含许多方法,因此如果需要这里没有描述的方法,可以查看JavaDoc。
java.nio.file.Files类与java.nio.file.Path实例一起工作,因此在使用Files类之前,您需要了解Path类。
Files.exists()
The Files.exists() method checks if a given Path exists in the file system.
Path path = Paths.get("data/logging.properties");
boolean pathExists =
Files.exists(path,
new LinkOption[]{ LinkOption.NOFOLLOW_LINKS});
Files.createDirectory()
The Files.createDirectory() method creates a new directory from a Path instance.
Path path = Paths.get("data/subdir");
try {
Path newDir = Files.createDirectory(path);
} catch(FileAlreadyExistsException e){
// the directory already exists.
} catch (IOException e) {
//something else went wrong
e.printStackTrace();
}
Files.copy()
The Files.copy() method copies a file from one path to another.
Path sourcePath = Paths.get("data/logging.properties");
Path destinationPath = Paths.get("data/logging-copy.properties");
try {
Files.copy(sourcePath, destinationPath);
} catch(FileAlreadyExistsException e) {
//destination file already exists
} catch (IOException e) {
//something else went wrong
e.printStackTrace();
}
Overwriting Existing Files
It is possible to force the Files.copy() to overwrite an existing file.
Path sourcePath = Paths.get("data/logging.properties");
Path destinationPath = Paths.get("data/logging-copy.properties");
try {
Files.copy(sourcePath, destinationPath,
StandardCopyOption.REPLACE_EXISTING);
} catch(FileAlreadyExistsException e) {
//destination file already exists
} catch (IOException e) {
//something else went wrong
e.printStackTrace();
}
Files.move()
Java NIO文件类还包含一个用于将文件从一个路径移动到另一个路径的函数。移动文件和重命名文件是一样的,只是移动文件既可以将其移动到不同的目录,也可以在同一操作中更改其名称。是的,java.io.File类也可以使用其renameTo()方法来实现这一点,但是现在在java.nio.File.Files类中也有了文件移动功能。
Path sourcePath = Paths.get("data/logging-copy.properties");
Path destinationPath = Paths.get("data/subdir/logging-moved.properties");
try {
Files.move(sourcePath, destinationPath,
StandardCopyOption.REPLACE_EXISTING);
} catch (IOException e) {
//moving file failed.
e.printStackTrace();
}
Files.delete()
The Files.delete() method can delete a file or directory.
Path path = Paths.get("data/subdir/logging-moved.properties");
try {
Files.delete(path);
} catch (IOException e) {
//deleting file failed
e.printStackTrace();
}
Files.walkFileTree()
Files.walkFileTree()方法包含递归(recursively)遍历目录树的功能。walkFileTree()方法接受一个Path实例和一个FileVisitor作为参数。路径实例指向要遍历的目录。在遍历期间调用FileVisitor。
public interface FileVisitor {
public FileVisitResult preVisitDirectory(
Path dir, BasicFileAttributes attrs) throws IOException;
public FileVisitResult visitFile(
Path file, BasicFileAttributes attrs) throws IOException;
public FileVisitResult visitFileFailed(
Path file, IOException exc) throws IOException;
public FileVisitResult postVisitDirectory(
Path dir, IOException exc) throws IOException {
}
您必须自己实现FileVisitor接口,并将实现的实例传递给walkFileTree()方法。在目录遍历期间,FileVisitor实现的每个方法都将在不同的时间被调用。如果不需要hook into所有这些方法,可以扩展SimpleFileVisitor类,该类包含FileVisitor接口中所有方法的默认实现。
Files.walkFileTree(path, new FileVisitor() {
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println("pre visit dir:" + dir);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("visit file: " + file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {
System.out.println("visit file failed: " + file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
System.out.println("post visit directory: " + dir);
return FileVisitResult.CONTINUE;
}
});
在遍历期间,在不同的时间调用FileVisitor实现中的每个方法:
preVisitDirectory()方法是在访问任何目录之前调用的。postVisitDirectory()方法是在访问目录之后调用的。
在文件遍历期间,将为访问的每个文件调用visitFile()方法。它仅文件调用目录不会调用。如果访问文件失败,则调用visitFileFailed()方法。例如,如果您没有正确的权限,或者发生了其他问题。
四个方法中的每一个都返回一个FileVisitResult枚举实例。FileVisitResult枚举包含以下四个选项:
- CONTINUE
- TERMINATE
- SKIP_SIBLINGS
- SKIP_SUBTREE
通过返回其中一个值,被调用的方法可以决定如何继续文件遍历。
CONTINUE:意味着文件遍历应继续正常进行。
TERMINATE:意味着文件遍历现在应该终止。
SKIP_SIBLINGS:意味着文件遍历应继续,但不访问此文件或目录的任何同级。
SKIP_SUBTREE:表示文件遍历应该继续,但不访问此目录中的条目。此值只有在从preVisitDirectory()返回时才具有函数。如果从任何其他方法返回,它将被解释为CONTINUE。
Searching For Files
Here is a walkFileTree() that extends SimpleFileVisitor to look for a file named README.txt :
Path rootPath = Paths.get("data");
String fileToFind = File.separator + "README.txt";
try {
Files.walkFileTree(rootPath, new SimpleFileVisitor() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
String fileString = file.toAbsolutePath().toString();
//System.out.println("pathString = " + fileString);
if(fileString.endsWith(fileToFind)){
System.out.println("file found at path: " + file.toAbsolutePath());
return FileVisitResult.TERMINATE;
}
return FileVisitResult.CONTINUE;
}
});
} catch(IOException e){
e.printStackTrace();
}
Deleting Directories Recursively
Files.walkFileTree()还可用于删除包含所有文件和子目录的目录。Files.delete()方法仅在目录为空时删除该目录。通过遍历所有目录并删除每个目录中的所有文件(在visitFile()中),然后删除目录本身(在postVisitDirectory()中),可以删除包含所有子目录和文件的目录。
Path rootPath = Paths.get("data/to-delete");
try {
Files.walkFileTree(rootPath, new SimpleFileVisitor() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("delete file: " + file.toString());
Files.delete(file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
Files.delete(dir);
System.out.println("delete dir: " + dir.toString());
return FileVisitResult.CONTINUE;
}
});
} catch(IOException e){
e.printStackTrace();
}
Additional Methods in the Files Class
java.nio.file.Files类包含许多其他有用的函数,例如用于创建符号链接、确定文件大小、设置文件权限等的函数。有关这些方法的更多信息,请查看java.nio.file.Files类的JavaDoc。
17.Java NIO AsynchronousFileChannel
在Java 7中,异步文件通道被添加到Java NIO中。AsynchronousFileChannel使异步读取数据和将数据写入文件成为可能。本教程将解释如何使用AsynchronousFileChannel。
Creating an AsynchronousFileChannel
You create an AsynchronousFileChannel via its static method open(). Here is an example of creating an AsynchronousFileChannel:
Path path = Paths.get("data/test.xml");
AsynchronousFileChannel fileChannel =
AsynchronousFileChannel.open(path, StandardOpenOption.READ);
open()方法的第一个参数是指向AsynchronousFileChannel要关联的文件的路径实例。
第二个参数是一个或多个打开选项,告诉AsynchronousFileChannel要对基础文件执行哪些操作。在本例中,我们使用StandardOpenOption.READ,这意味着将打开文件进行读取。
Reading Data
可以通过两种方式从异步文件通道读取数据。每种读取数据的方法都调用AsynchronousFileChannel的read()方法之一。以下各节将介绍两种读取数据的方法。
Reading Data Via a Future
从AsynchronousFileChannel读取数据的第一种方法是调用返回Future的read()方法。下面是调用read()方法的方式:
Future operation = fileChannel.read(buffer, 0);
此版本的read()方法将ByteBuffer作为第一个参数。从AsynchronousFileChannel读取的数据将被tebuffer读入此。第二个参数是文件中开始读取的字节位置。
read()方法立即返回,即使读取操作尚未完成。通过调用read()方法返回的Future实例的isDone()方法,可以检查读取操作何时完成。
AsynchronousFileChannel fileChannel =
AsynchronousFileChannel.open(path, StandardOpenOption.READ);
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
Future operation = fileChannel.read(buffer, position);
while(!operation.isDone());
buffer.flip();
byte[] data = new byte[buffer.limit()];
buffer.get(data);
System.out.println(new String(data));
buffer.clear();
本例创建一个AsynchronousFileChannel,然后创建一个ByteBuffer,该ByteBuffer作为参数传递给read()方法,其位置为0。调用read()之后,示例循环,直到返回的Future的isDone()方法返回true。当然,这不是一个非常有效的CPU使用-但不知何故,你需要等到读操作完成。
读取操作完成后,将数据读入ByteBuffer,然后读入字符串并打印到System.out。
Reading Data Via a CompletionHandler
从AsynchronousFileChannel读取数据的第二种方法是调用以CompletionHandler作为参数的read()方法版本。下面是如何调用此read()方法:
fileChannel.read(buffer, position, buffer, new CompletionHandler() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
System.out.println("result = " + result);
attachment.flip();
byte[] data = new byte[attachment.limit()];
attachment.get(data);
System.out.println(new String(data));
attachment.clear();
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
}
});
读取操作完成后,将调用CompletionHandler的completed()方法。当参数传递给completed()方法时,会传递一个整数,告诉读取了多少字节,以及传递给read()方法的“附件”。“attachment”是read()方法的第三个参数。在本例中,数据也被读入ByteBuffer。您可以自由选择要附加的对象。
如果读取操作失败,将改为调用CompletionHandler的failed()方法。
Writing Data
与读取一样,您可以用两种方式将数据写入异步文件通道。每种写入数据的方法都调用AsynchronousFileChannel的write()方法之一。以下各节将介绍两种数据写入方法。
Writing Data Via a Future
AsynchronousFileChannel还允许您异步写入数据。下面是完整的Java AsynchronousFileChannel编写示例:
Path path = Paths.get("data/test-write.txt");
AsynchronousFileChannel fileChannel =
AsynchronousFileChannel.open(path, StandardOpenOption.WRITE);
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
buffer.put("test data".getBytes());
buffer.flip();
Future operation = fileChannel.write(buffer, position);
buffer.clear();
while(!operation.isDone());
System.out.println("Write done");
首先,异步文件通道以写模式打开。然后创建ByteBuffer并将一些数据写入其中。然后ByteBuffer中的数据被写入文件。最后,示例检查返回的Future以查看写入操作何时完成。
注意,该文件必须在该代码生效之前已经存在。如果文件不存在,Read()方法将抛出java. NIO.FIL.NUUCHFILExeExchange。
You can make sure that the file the Path points to exists with the following code:
if(!Files.exists(path)){
Files.createFile(path);
}
Writing Data Via a CompletionHandler
您还可以使用CompletionHandler将数据写入AsynchronousFileChannel,以告诉您何时完成写入而不是Future。下面是使用CompletionHandler将数据写入AsynchronousFileChannel的示例:
Path path = Paths.get("data/test-write.txt");
if(!Files.exists(path)){
Files.createFile(path);
}
AsynchronousFileChannel fileChannel =
AsynchronousFileChannel.open(path, StandardOpenOption.WRITE);
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
buffer.put("test data".getBytes());
buffer.flip();
fileChannel.write(buffer, position, buffer, new CompletionHandler() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
System.out.println("bytes written: " + result);
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
System.out.println("Write failed");
exc.printStackTrace();
}
});
当写入操作完成时,将调用CompletionHandler的completed()方法。如果由于某种原因写操作失败,将调用failed()方法。
注意ByteBuffer是如何被用作附件的-传递给CompletionHandler方法的对象。