DeepLabv3:《Rethinking Atrous Convolution for Semantic Image Segmentataion》
论文地址:https://arxiv.org/abs/1706.05587
Abstract
在这篇文章中,我们重温了atrous convolution(带孔卷积),它可以很好的调整过滤器的感受野以及控制输出feature map的分辨率。为了解决分割中物体的多尺度,我们设计了带孔卷积的串行和并行模块来获取多尺度信息通过多个atrous rate(采样率)。另外,我们建议增加之前提出的ASPP,它可以获取不同的尺度信息,并且可以编码全局上下文的图像特征来提升性能。我们阐述了实现细节并分享了训练经验。本文提出的DeepLabv3在没有CRF后处理的情况下,明显的提高了我们之前DeepLab版本,在PASCAL VOC 2012语义图像分割基准测试中获得与其他最先进的模型相媲美的性能。
1. Introduction
语义分割中由两个挑战,第一是由于卷积中连续的下采样或者卷积的stride造成的分辨率下降,使得DCNN学习到了更抽象的特征表示。这种局部图像变换的不变性可能会影像密集预测任务,这种任务中需要更详细的空间信息。为了解决这种问题,我们提出了带孔卷积,这在语义分割中已经起到了非常大的作用。带孔卷积也叫dilatedd convolution,允许我们去除在ImageNet上预训练的模型的最后几层的下采样操作,并将对应的卷积核扩大(等价与在权重之间插入空洞)来提取密集信息。利用带孔卷积我们可以在不增加额外参数的情况下,控制DCNN输出的feature map的分辨率。
另一个问题就是物体的多尺度。很多模型提出了解决方法,本文我们只考虑图2中的4种情况。
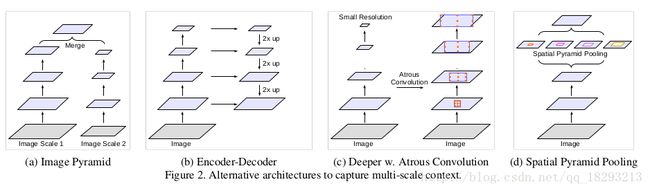
第一个是模型采用了图像金字塔来提取不同尺寸图像输入。第二个是编码-解码结构,挖掘不同尺度的特征从编码部分,然后在解码部分恢复图像的分辨率。第三个是额外的模块级联在原始模型的顶部来获取大范围信息。特别是DenseCRF来编码像素级别的相似性,因此开发了很多额外的层来获长程信息。第四个空间金字塔采样,利用不同尺度的过滤器或者采样操作来应用于输入feature map上,因此可以获得多尺度的物体信息。
在本文中的中框架中,所有的级联模块以及空间金字塔采样中,我们重新采用带孔卷积,它使得我们有效的扩大滤波器的感受野并合并多尺度信息。特别的,我们的模块中具有多个尺度的带孔卷积以及BN层,这对训练来说很重要。我们实验中采用并行或者串行的ASPP模式。我们讨论了一个很重要的实操问题,当采用采样率很大的带孔卷积时,很难获取长程信息,由于图像的边缘影像,退化为1x1的卷积,
3. Methods
3.1. Atrous Convolution for Dense Feature Extraction
DCNN在全卷积情况下已经表现出很好的语义分割性能。但是由于重复的进行pooling和卷积的步长>1导致原图的分辨率下降。反卷积或者转置卷积已经已经用于恢复分辨率。实际上我们推荐使用带孔卷积。
带孔卷积允许我们控制模型的响应密集度。我们用输出步长来表示输入图像与输出图像的分辨率比值。常见的模型中,output_stride为32,如果我们想让输出feature map的密集程度加倍,也就是output_stride=16,我们就要设置最后一个下采样或者卷积层的stride为1。然后接下来的所有卷积层都使用采样率为2的带孔卷积,这使我们能够在不增加额外参数的同时提取更加密集的特征响应。
3.2. Going Deeper with Atrous Convolution
我们首先探索设计级联布局的具有超大卷积的模块。我们复制ResNet的Block4,并且让它们级联起来,如图3所示。
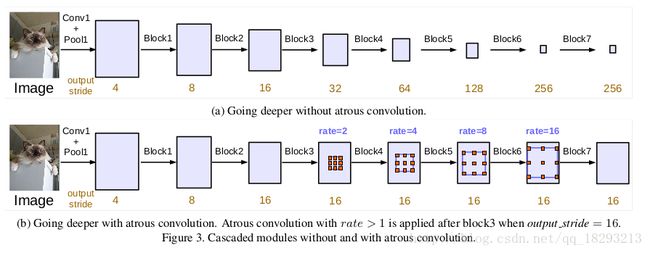
每一个卷积block都有3层卷积层,kernel都是3x3,除了最后一个block之外,其它的block中最后一个卷积层的stride都为2,和原始的Resnet是一致的。这样做的目的就是就是因为在更深的block中采样率可以提取长程信息。举个例子,如图3a所示,整个的图像可以被总结成最后一个小的feature map,但是这对语义分割是非常不利的,因为这会损失细节信息。因此我们采用带孔卷积,采样率可以决定最后的输出步长,如图3b所示。
在这个提出的模型中,我们试验了直到块7的级联ResNet块(即,额外块5,块6,块7作为块4的复制品),如果不应用无量卷积,其具有输出步长= 256。
3.2.1 Multi-grid Method
受不同规模的网格层次的启发。我们采在block4-7中采用不同的采样率。即,定义 Multi_Grid=(r1,r2,r3)为block4~block7的三个convolutional layers的 unit rates.
convolutional layer 最终的 atrous rate 等于 unit rate 与对应的 rate 的乘积. 例如,当 output_stride=16, Multi_Grid=(1,2,4)时, block4 中三个 three convolutions 的 rate 分别为:rates=2∗∗(1,2,4) = (2,4,8).
3.3 Atrous Spatial Pyramid Pooling
我们重新利用论文11中的带孔空间金字塔采样(ASPP),在feature map的顶部有4个不同采样率的带孔卷积核。ASPP的灵感来自与空间金字塔的成功应用,这表明对不同尺度的特征进行重采样是有效的,可以对任意尺度的区域进行准确有效的分类。但是与论文11中不同的是我们的ASPP包括BN层。
ASPP具有不同的采样率,可以非常有效的提取多个尺度的信息。然而我们发现当采样率增大时,卷积核中有效的卷积权重(作用于feature map内部区域,而不是pad区域)越来越小。如图4所示,我们采用采样率不同的3x3的卷积核应用于65x65的feature map。采用最极端的情况当采样率接近feature map的大小时,3x3的卷积核并不是提取整个图像的上下文信息,而是退化为1x1的卷积核,因为只有卷积核中间的权重是有效的。
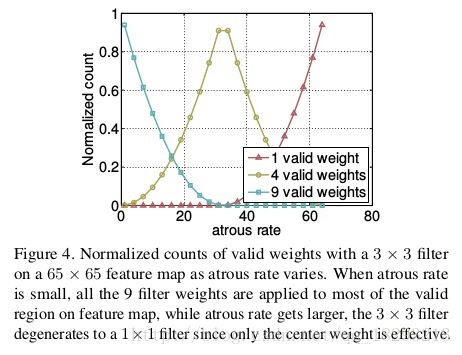
从上图可以看出,横坐标为采样率,纵坐标为权重应用比例。当采样率很小的时候,卷积核的9个权重全部应用与feature map的有效区域,随着采样率的逐渐增大,3x3的卷积核退化为1x1的卷积核。
为了克服这个问题并融合全局上下文信息,我们采用图像级(image-level)的特征,和论文58,95相同的方法。特别的,我们对模型的最后一个feature map采用全局均值池化,然后把池化的结果送入256个11的卷积核以及BN,最后进行双线性插值恢复到想要的分辨率。最后,我们的ASPP部分包含两部分,a)、1x1的卷积核和3个3x3的卷积核采样率分别为(6,12,18)(都是256个卷积核然后BN)。b)、以及如图5所示的图像级特征。

我们可以看出当out_stride=8时,所有的采样率都加倍了。所有分支的结果都会concatenate然后在最后一层1x1卷积和分类之前通过另一个1x1的卷积。
4. Experimental Evaluation
采用ImageNet的预训练模型Resnet,定义outputstride为输入图像分辨率/输出图像分辨率。PASCAL VOL2012语义分割数据集,20个前景1个背景,原始数据集包括1464训练集,1449验证集,1456测试集。然后倍数据增强至10852个训练集。利用IOU来测试分割效果。
4.1. Traning Protocol
Learning rate policy,学习率初始化要乘以(1-ietr/max_ietr)^{power},power=0.9。
Crop Size ,训练过程中,提取图像块,对于带孔卷积需要大的采样了,所以也要裁剪大的patch,否则,具有较大误差率的滤波器权重主要应用于填充的零区域。我们提取的图像块大小为513。
Batch Normalization,模型的顶部添加了bn层,我们认为这是很重要的。因为的大的batchsize需要使用batch normalization的参数。当output_stride=16时,我们计算出batchnormalization的batchsize为16。bn参数的decay=0.9997。在训练集训练了30K次之后,lr=0.0007,然后使bn的参数保持不变,我们使outputstride=8,lr=0.001在官方提供的原始数据集上训练30K次。值得注意的是,我们在不同的阶段训练不同的outputstride值不需要额外的参数。另外,outputstride=16时训练速度会比outputstride=8快很多,因为中间的featuremap小,计算量也小,但是output=16会牺牲精度,产生比较粗糙的分割结果。
Upsampling logits:在之前的工作中,当outputstride=8时,我们会把GT下采样8倍,我们发现保持GT的完好无损是非常重要的而不是对最后的分割结果上采样,因为下采样会去除GT中的精细标注信息导致无法反向传播细节信息。
Data augmentation:我们对输入图像进行0.5-2.0之间的随机缩放,以及随机的左右翻转。
4.2. Going Deeper with Atrous Convolution
我们第一次实验多个带孔卷积block级联的形式。
ResNet-50:表1所示,添加block至第7个,当outputstride=256的时候(没有带孔卷积),性能非常差,因为严重的信息丢失。当outputstride=8并加上带孔卷积时,性能提升至75.18%,可以看出带孔卷积对于级联多个分割block非常有用。

Resnet-50 vs. ResNet-101:表2可以看出,不管是ReNet-50还是ResNet-101随之卷据block的增加,性能都会提升,但是ResNet-50和ResNet-101的差距会越来越小。另外,ResNet-50增加至第7个block时性能略有下降,但是ResNet-101的性能一直在提升。

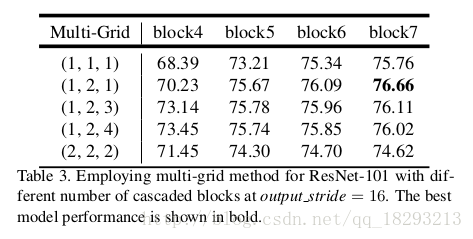
Multi-grid:我们将多网格方法应用于ResNet101,并在模型中添加了几个级联的块如图3所示。 单位速率Multi Grid =(r 1,r 2,r 3)适用于block4和所有其他添加的块。 如表中所示,我们观察到(a)应用多网格方法通常优于(r 1,r 2,r 3)=(1,1,1),(b)简单加倍单位速率(即(r 1,r 2,r 3)=(2,2, 2))没有效果,并且(c)随着多重网格更深入地改善了性能。 我们最好的模型是采用block7和(r 1,r 2,r 3)=(1,2,1)的情况。
Inference strategy on val set:我们提出的模型在训练的时候outputstride=16,然后在推理(测试)的过程中采用outputstride=8来获得细节信息。如表4所示,我们最好的级联模型采用outputstride=8比outputstride=16要好1.39%。当把输入的尺寸按一定的比例缩放并且左右翻转时,性能会更一步提升。具体而言,我们计算每个比例和翻转图像的平均概率作为最终结果
4.3. Atrous Spatial Pyramid Pooling
ASPP:在表5中,我们在block4中使用多网格以及图像级特征应用于ASPP模块中。我们首先固定ASPP=(6,12,18)(6,12,18分别对应三个卷积分支),然后改变multi_grid的值。我们发现multi_grid=(1,2,1)比(1,1,1)要好,然后通过改变multi_grid=(1,2,4)更进一步提高了模型的性能。如果我们再天界一个额外的卷积分支,采样率为24时,性能会略微下降0.12%。另一方面,增加具有图像级特征的ASPP模块是有效的,达到77.21%的最终性能。
Inference strategy on val set:在测试过程中我们采用outputstride=8。如表6所示,outputstride=8比等于16高1.3%。采用多尺度输入以及左右翻转输入图像又分别提高0.94%和0.32%。带有ASPP最好的模型性能为79.77%,比最好的级联带孔卷积模型(表4中的结果79.35%)高。
Comparison with DeeplLabv2:我们最好的级联模型(表4)以及ASPP模型(表6)都比DeepLabv2要好。而且我们这两个模型没有CRF后处理以及在COCO数据集上预训练。而DeepLabv2集进行了后处理也进行了预训练。这两个模型的提高主要来自BN的作用。
5. Conclusion
DeepLab v3提出的带孔卷积扩大了卷积核的视野可以提取更加密集的信息以及长程的上下文信息。特别的,为了适应多尺度信息,我们提出的级联模型逐渐加倍采样速率,而且我们提出的带孔空间金字塔采样模块增加了图像级特征,使用多个采样比例扩大了感受野。
最终的结果:

DeepLab v3的特点:
1、继续沿用带孔卷积,扩大感受野。
2、之前一个block内部使用相同的rate,但是这次同一个block内的三个卷积层使用不同的rate。
3、增加block
4、ASPP,这一块我的理解就是进行了一次图像金字塔,适应多尺度信息。并且加入BN
然后其它方面,数据增强(翻转、缩放)、使用其它数据预训练。先使用增强的数据训练,再使用最原始的数据进行训练(老套路了)。
总结还有不足的地方,请各位朋友指出来,谢谢。