MySQL-分区,分表,分库
最近有个业务系统,其中一块的业务预计有几张表数据量会达到千万级,总监安排我对这块业务设计做下调研。我们始终要明白技术是服务于业务的,结合业务的特点来采取相应的方案,根据我们的数据总数据不会变化太多,基本上是一次录入,之后多是查询业务,我分析采用分区方案就可以。架构是演变出来的,不是设计出来的。目前的业务采用分区即可实现。在这里顺带学习了一下分表和分库。
讲这些执行我们需要准备好数据,给数据库表批量造数据有很多方法,常用的有存储过程,压测工具,还有批量造数据的工具,这个我没有使用过,感兴趣的可以自行百度。
这里我使用的是存储过程的方式,如下:
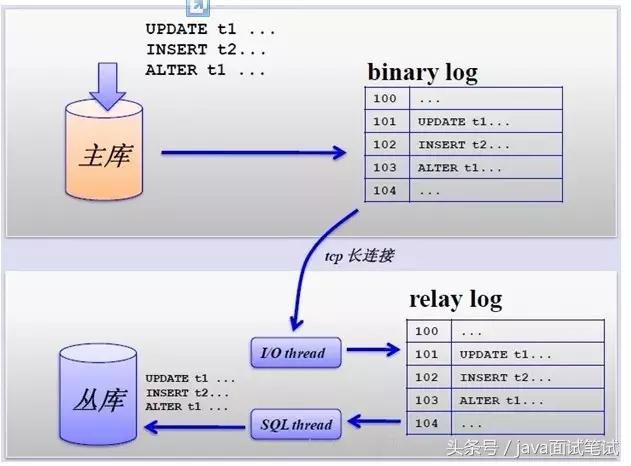
DELIMITER $$ INSERT INTO `test`.`t_user`(`user_id`, `user_name`, `password`, `phone`) VALUES (i, 'kit', '1', '1'); SET i=i+1; 创建好存储过程,开始调用CALL test_pp(1000000);等执行完查一下 select count(*) from t_user; 说明数据已经准备好了 一、分区 就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的 MySQL创建表分区,这里要注意,分区要求:分区中使用的字段必须都包含在主键当中,我们需要把分区使用的字段和主键建立复合主键 先删除主键 alter table t_user drop primary key; alter table t_user add primary key(user_id,created); 创建分区 ALTER TABLE t_user partition by range(YEAR(created))( 创建完成之后可以查看分区名称 select partition_name , subpartition_name from information_schema.partitions where table_schema='test' and table_name='t_user'; 查看分区数据 二、分表 就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则读取指定的表 市面上分表分库的中间件有很多,各有优缺点,这里我使用的是mycat,mycat对原有代码没有侵入,接入现有项目比较分便。 1.垂直分表 把原来有很多列的表拆分成多个表,原则是: 2.水平分表 为了解决单表数据量过大的问题,每个水平拆分表的结构完全一致 三、分库 业务越来越复杂,数据性能出现瓶颈,我们会根据业务分成不同的数据库,还有进行读写分离架构。 下面给一个读写分离的实例来进行说明,首先我们分出一个写库和两个读库 yml配置如下 实现的方式是采用了spring的aop技术,我们先定义两个注解 之后我们定义了一个aop切面, 定义好这些之后我们就可以像下面这样去使用了 } 这样数据库读写分离就实现完成了。 mysql数据库可以做成主从同步架构,写业务在主库,读业务在从库,主从同步会有一些延迟,如果及时性要求比较高的场景可以走主库读取数据,这里不考虑redis缓存
CREATE PROCEDURE test_pp(IN n INTEGER)
BEGIN
DECLARE i INT DEFAULT 1;# can not be 0
WHILE i
END WHILE ;
END $$
DELIMITER ;;
partition p2019 values less than (2019),
partition p2020 values less than (2020),
partition p2021 values less than (2021),
partition p2022 values less than maxvalue
);
select * from t_user partition(p2020)
(1)把常用、不常用的字段分开放
(2)把大字段独立存放在一个表中mysql:
datasource:
readSize: 2 #读库个数
type: com.alibaba.druid.pool.DruidDataSource
mapperLocations: classpath:/com/springboot/dao/*.xml
configLocation: classpath:/mybatis-config.xml
write:
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf-8
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
minIdle: 5
maxActive: 100
initialSize: 10
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 50
removeAbandoned: true
filters: stat
read01:
url: jdbc:mysql://127.0.0.1:3306/test_01?useUnicode=true&characterEncoding=utf-8
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
minIdle: 5
maxActive: 100
initialSize: 10
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 50
removeAbandoned: true
filters: stat
read02:
url: jdbc:mysql://127.0.0.1:3306/test_02?useUnicode=true&characterEncoding=utf-8
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
minIdle: 5
maxActive: 100
initialSize: 10
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 50
removeAbandoned: true
filters: stat @Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface ReadDataSource {
}@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface WriteDataSource {
}@Aspect
@EnableAspectJAutoProxy(exposeProxy=true,proxyTargetClass=true)
@Component
public class DataSourceAopInService implements PriorityOrdered{
private static Logger log = LoggerFactory.getLogger(DataSourceAopInService.class);@Before("execution(* com.fei.springboot.service..*.*(..)) "
+ " and @annotation(com.fei.springboot.annotation.ReadDataSource) ")
public void setReadDataSourceType() {
//如果已经开启写事务了,那之后的所有读都从写库读
if(!DataSourceType.write.getType().equals(DataSourceContextHolder.getReadOrWrite())){
DataSourceContextHolder.setRead();
}
}
@Before("execution(* com.fei.springboot.service..*.*(..)) "
+ " and @annotation(com.fei.springboot.annotation.WriteDataSource) ")
public void setWriteDataSourceType() {
DataSourceContextHolder.setWrite();
}
@Override
public int getOrder() {
/**
* 值越小,越优先执行
* 要优于事务的执行
* 在启动类中加上了@EnableTransactionManagement(order = 10)
*/
return 1;
}
}@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@WriteDataSource @Transactional(propagation=Propagation.REQUIRED,isolation=Isolation.DEFAULT,readOnly=false)
public void insertUser(User u){
this.userMapper.insert(u);
}@ReadDataSource
public PageInfo