Oracle-expdp方式升级19c问题合集
前言:
最近在帮客户进行Oracle11g到19c版本的升级,使用expdp导用户的方式进行迁移,在升级过程中遇到了些错误问题,把当时的问题分析过程记录了下来,分享给大家。
问题一:导入出现报错ORA-39346:
ORA-39346: data loss in character set conversion for object COMMENT:"xxx_"
ORA-39346: data loss in character set conversion for object COMMENT:"xxx_"
ORA-39346: data loss in character set conversion for object COMMENT:"xxxFT"
ORA-39346: data loss in character set conversion for object COMMENT:"xxxFT"
ORA-39346: data loss in character set conversion for object COMMENT:"xxxFT"
ORA-39346: data loss in character set conversion for object COMMENT:"xxxFT"
ORA-39346: data loss in character set conversion for object COMMENT:"xxx"
ORA-39346: data loss in character set conversion for object COMMENT:"xxx"
问题分析:
该报错说明在导入的过程字符集转化发生数据丢失的情况
出现该问题是第一要做的就是确认源端和目标端的字符集(NLS_CHARACTERSET),国家字符集(NLS_NCHAR_CHARACTERSET)),操作系统NLS_LANG设置是否一致
1 select property_name,property_value
2 from database_properties
3* where property_name like '%CHARA%'
PROPERTY_NAME PROPERTY_VALUE
------------------------------ ----------------------------------------
NLS_NUMERIC_CHARACTERS .,
NLS_NCHAR_CHARACTERSET UTF8
NLS_CHARACTERSET AL32UTF8
确认目标库和源端的字符集设置都一致排除字符集导致的问题之后,进一步查看报错对象的DDL元数据,发现源库存在中文乱码的情况,这从而导致在19c导入的创建对象的过程中出现ORA-39346: data loss in character set conversion的错误,实际对象创建成功,但乱码会出现字符转化错误

问题解决:
出现乱码丢失的都为注释,对应用的实际使用没影响,后续只能让应用自己慢慢去修改,不影响11g升级19c
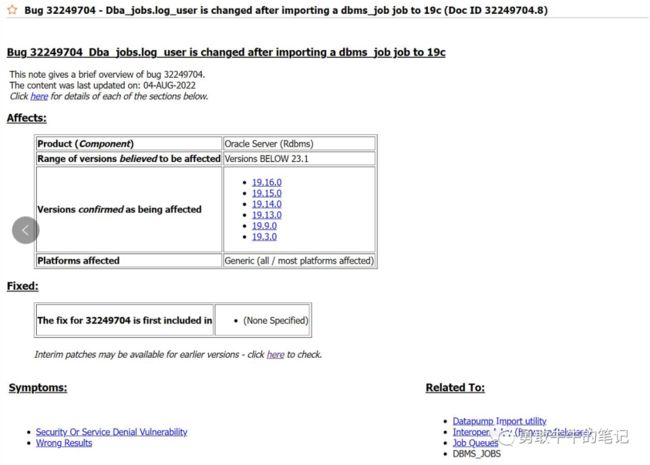
问题二:导入之后dba_jobs的log_user显示为SYS
在导入job之后,检查发现dba_jobs的log_user字段为sys,而不是应用用户,priv_user,schema_user 这两个字段显示正常

问题分析:
一开始以为是使用sys导入的原因,尝试通过dbms_ijob手动创建,log_user还是显示为sys,后面通过Oracle 官方查看案例,才确认命中了bug 32249704,在19c通过impdp导入,log_user会发生改变
问题解决:
1 安装oneoff补丁32249704(online patch)修复了该问题
2 也可以使用job的创建用户进行导出导入,规避该问题
问题三:导入报错ORA-39083,ORA-01858
导入发生物化视图刷新组创建失败的报错
Processing object type SCHEMA_EXPORT/REFRESH_GROUP
ORA-39083: Object type REFRESH_GROUP:"XXXX"."VW_XXXXX" failed to create with error:
ORA-01858: a non-numeric character was found where a numeric was expected
Failing sql is:
BEGIN dbms_refresh.make
(
'"xxx"."xxx"',
list=>null,
next_date=>'00-JAN-01',
interval=>'to_date( concat( to_char( sysdate+1,''dd-mm-yyyy''),'' 01:21:30''),''dd-mm-yyyy hh24:mi:ss'') ',
implicit_destroy=>TRUE,
lax=>FALSE,
job=>52,
rollback_seg=>NULL,
push_deferred_rpc=>TRUE,
refresh_after_errors=>FALSE,
purge_option=>1,
parallelism=>0,
heap_size=>0
);
dbms_refresh.add(name=>'"xxx"."xxx"',list=>'"xxx"."xxx"',siteid=>0,export_db=>'xxx');
END;
/ 问题分析:
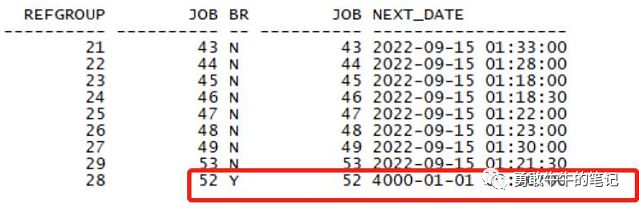
dbms_refresh.make, dbms_refresh.add是用于编译创建物化视图刷新组,刷新组调用的是job 52,执行出现报错的原因为需要数字的参数出现一个非数字的字符串,执行SQL的错误的地方在next_date=>'00-JAN-01',因为next_date的输入参数类型为date,但输入的字符串'00-JAN-02'没法隐式转化为日期,导致出现报错

对于导入的执行SQL为啥会出现'00-JAN-02',我们查看job 52,可以发现job52在源库的状态为禁用(broken=y),导致next_date为4000-01-01 00:00:00,所以在导入的sql执行就变成next_date=>'00-JAN-01'
问题解决:
修改执行的sql,将next_date修改为日期类型to_date('4000-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss'),在手动执行即可
BEGIN dbms_refresh.make
(
'"xxx"."xxx"',
list=>null,
next_date=>to_date('4000-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss'),
interval=>'to_date( concat( to_char( sysdate+1,''dd-mm-yyyy''),'' 01:21:30''),''dd-mm-yyyy hh24:mi:ss'') ',
implicit_destroy=>TRUE,
lax=>FALSE,
job=>52,
rollback_seg=>NULL,
push_deferred_rpc=>TRUE,
refresh_after_errors=>FALSE,
purge_option=>1,
parallelism=>0,
heap_size=>0
);
dbms_refresh.add(name=>'"xxx"."xxx"',list=>'"xxx"."xxx"',siteid=>0,export_db=>'xxx');
END;
/
问题四:查询DBA_REFRESH字段broken出现“?”
1* select ROWNER,RNAME,REFGROUP,JOB,BROKEN,job from DBA_REFRESH
ROWNER RNAME REFGROUP JOB B JOB
------------------------------ -------------------------------------------------------------------------------------------------------------------------------- ---------- ---------- - ----------
xxx xxx_MAIN_TAGS 12 ?
xxx xxx_CATEGORY_NAMES 10 ?
xxx xxx_READ_TIMES 16 ?
xxx xxx_ORG_DEPT_NAMES 15 ?
xxx xxx_READER_USERS 13 ?
xxx xxx_ATT_DOWN_USERS 9 ?
xxx xxx_COMMENT_TIMES 11 ?
xxx xxx_USER_HAS 17 ?
xxx xxx_USER_NO 14 ?
问题分析:
查看DBA_REFERSH视图的定义SQL,可以发现broken等于?的条件为decode(bitand(j.flag,1),1,'Y',0,'N','?') AS BROKEN
SELECT ROWNER,
RNAME,
REFGROUP,
IMPLICIT_DESTROY,
PUSH_DEFERRED_RPC,
REFRESH_AFTER_ERRORS,
ROLLBACK_SEG,
JOB,
NEXT_DATE,
INTERVAL,
BROKEN,
PURGE_OPTION,
PARALLELISM,
HEAP_SIZE,
JOB_NAME
FROM (
SELECT r.owner AS ROWNER, r.name AS RNAME, r.REFGROUP AS REFGROUP,
decode(bitand(r.flag,1),1,'Y',0,'N','?') AS IMPLICIT_DESTROY,
decode(bitand(r.flag,2),2,'Y',0,'N','?') AS PUSH_DEFERRED_RPC,
decode(bitand(r.flag,4),4,'Y',0,'N','?') AS REFRESH_AFTER_ERRORS,
r.rollback_seg AS ROLLBACK_SEG,
j.JOB AS JOB, j.NEXT_DATE AS NEXT_DATE, j.INTERVAL# AS INTERVAL,
decode(bitand(j.flag,1),1,'Y',0,'N','?') AS BROKEN,
r.purge_opt# AS PURGE_OPTION,
r.parallelism# AS PARALLELISM,
r.heap_size# AS HEAP_SIZE,
r.job_name AS JOB_NAME
FROM rgroup$ r, job$ j
WHERE r.instsite = 0
AND r.job_name IS NULL AND r.job = j.job(+)
UNION ALL
SELECT r.owner AS ROWNER, r.name AS RNAME, r.REFGROUP AS REFGROUP,
decode(bitand(r.flag,1),1,'Y',0,'N','?') AS IMPLICIT_DESTROY,
decode(bitand(r.flag,2),2,'Y',0,'N','?') AS PUSH_DEFERRED_RPC,
decode(bitand(r.flag,4),4,'Y',0,'N','?') AS REFRESH_AFTER_ERRORS,
r.rollback_seg AS ROLLBACK_SEG,
r.JOB AS JOB,
CAST(s.next_run_date AS DATE) AS NEXT_DATE,
substr(s.repeat_interval,1,200) AS INTERVAL,
decode(s.enabled,'FALSE','Y','TRUE','N','?') AS BROKEN,
r.purge_opt# AS PURGE_OPTION,
r.parallelism# AS PARALLELISM,
r.heap_size# AS HEAP_SIZE,
r.job_name AS JOB_NAME
FROM rgroup$ r, dba_scheduler_jobs s
where r.instsite = 0
AND r.owner = s.owner(+)
and r.job_name IS NOT NULL AND r.job_name = s.job_name(+)
)j.flag字段来着于基表job$,但查看基表job$的数据,可以发现job$没有数据,由于job$没有数据,导致于rgroup$左连接之后,字段j.flag返回null,所以显示为?
SQL> select count(*) from job$;
COUNT(*)
----------
0
问题解决:
从官方上看,没有关于Oracle19c基表job$没有数据的说明,也没有相关的公开bug说明,目前的规避方法只能通过rgroup$与dba_jobs进行关联查询规避问题
问题五:导入出现ORA-02298: cannot validate (XXXX.FK82xxx0705) - parent keys not found
Failing sql is:
ALTER TABLE "xxx"."xxx" ADD CONSTRAINT "FKxxx" FOREIGN KEY ("FD_DOC_ID") REFERENCES "xxx"."xxxx" ("xxxx") ENABLE
ORA-39083: Object type REF_CONSTRAINT:"xxx"."xxxx" failed to create with error:
ORA-02298: cannot validate (xxx.xxxx) - parent keys not found
Failing sql is:
ALTER TABLE "xxx"."xxxx" ADD CONSTRAINT "xxxx" FOREIGN KEY ("xxxx") REFERENCES "xxx"."SYS_NOTIFY_TODO" ("xxxx") ENABLE
ORA-39083: Object type REF_CONSTRAINT:"xxx"."xxxx" failed to create with error:
ORA-02298: cannot validate (xxx.xxxx) - parent keys not found问题分析:
出现外键约束检查失败之后,首先需要检查的是父表以及子表的约束状态是否正常
select constraint_name,status
from dba_constraints
select b.owner, b.table_name, c.column_name FK_column, b.constraint_name, b.delete_rule
from dba_constraints a, dba_constraints b, dba_cons_columns c
where a.owner = b.r_owner and
b.owner = c.owner and
b.table_name = c.table_name and
b.constraint_name = c.constraint_name and
a.constraint_name = b.r_constraint_name and
b.constraint_type = 'R' and
a.owner = '' and
a.table_name in ('') and
a.constraint_type = 'P';如果检查约束状态正常,则很有可能是导出父表以及子表的数据不一致导致,即子表的外键出现父表不存在的数据,导致在添加外键约束的时候,检查不通过
问题解决:
expdp导出的时候,添加flashback_scn确保导出数据时间点一致
---查看数据库的当前scn
select to_char(current_scn) from v$database;
---expdp 添加
FLASHBACK_SCN=问题六:导入对象权限出现丢失
在导入完成之后,比较对象权限两边的数量,出现目标端权限少于源端权限的情况
问题分析:
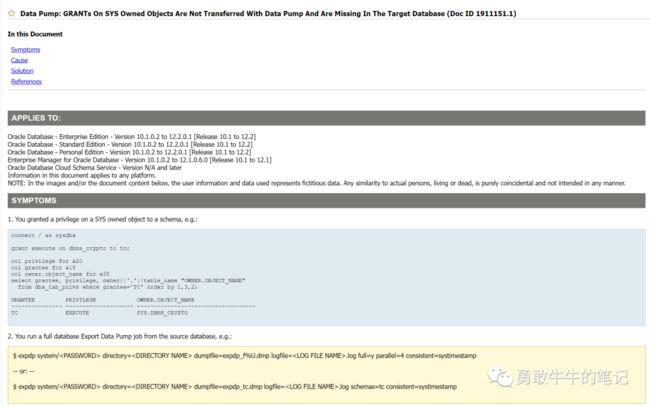
通过对两边对象权限进行比对,发现缺失的授权对象都是sys对象

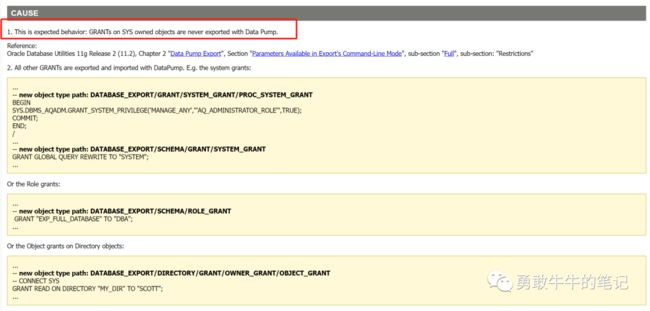
通过Oracle官方查看,用户不导出SYS对象的授权是expdp预期的行为,不是bug或是错误,(PS:这里只能说明自己的方案还不够谨慎!!!)
问题解决:
在源库手动生成批量授权的语句,在导目标库进行导入
1. As the privileges on SYS owned objects are not exported, you need to have another method in place which re-creates these privileges. E.g. a script that is called during export time and that will recreate these grants (or you store these lines in a table).
Example:
connect / as sysdba
spool grants_tc.out
col GRANTS for a80
-- xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
-- Add below the users and/or roles as appropriate for GRANTEE
-- xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
select 'grant ' || privilege || ' on ' ||'"'||table_name ||'"'||
' to ' || grantee || ';' "GRANTS"
from dba_tab_privs
where owner = 'SYS' and privilege not in ('READ', 'WRITE')
and grantee in ('TC')
order by 1;
spool off
-- example of query output:
GRANTS
--------------------------------------------------------------------------------
grant EXECUTE on DBMS_CRYPTO to TC;
2. Before the start of the Import Data pump job, you can pre-create the schema, e.g.:
$ impdp system/ directory= dumpfile=.dmp logfile=..log schemas=tc include=user
3. Then pre-create the grants on SYS owned objects, by running your script (see step 1 above).
4. Followed by the import of the rest of the objects, e.g.:
$ impdp system/ directory= dumpfile=.dmp logfile=.log schemas=tc exclude=user 总结:
以上为在expdp方式11g升级19c遇到的错误合集,希望对大家有所帮助!