clickhouse集群部署和分布式引擎实战
1.认识clickhouse
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)
OLAP: Online AnalyticalProcessing联机分析处理系统
列式存储
2.单机部署
官方文档安装 | ClickHouse Docs
2.1.docker安装单机版
不使用副本表时可以不用zookeeper
当使用Replicated table时,ZooKeeper用于存储关于replica的元数据。
可选的。如果不使用复制表,可以忽略这一点。
参见 https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/
docker安装
## 镜像:
yandex/clickhouse-server:latest 服务端
yandex/clickhouse-clientr:latest 客户端
## 启动服务端命令:
docker run \
--restart always \
--publish=8123:8123 --publish=9000:9000 --publish=9009:9009 \
--volume=/data1/clickhouse/data:/var/lib/clickhouse:rw \
--volume=/data1/clickhouse/log:/var/log/clickhouse-server:rw \
--volume=/data1/clickhouse/config.xml:/etc/clickhouse-server/config.xml:rw \
--volume=/data1/clickhouse/users.xml:/etc/clickhouse-server/users.xml:rw \
--name clickhouse-server \
-d \
yandex/clickhouse-server:latest3.客户端测试
## 运行客户端实例:
docker run -it --rm \
--link clickhouse-server:clickhouse-server yandex/clickhouse-client \
--host clickhouse-server进入命令操作
查询 default 库里的表
select name from system.tables where database='default'
建表 (直接复制)
create table aaa( \
id String,\
name String\
)\
ENGINE = MergeTree\
PARTITION BY name \
ORDER BY (name )\
SETTINGS index_granularity = 8192
插入
insert into `default`.aaa (id,name) values (1,'test')
查询
select * from aaa
修改
ALTER table `default`.bsc_transfer update name = 2 where id = 1
删除表
DROP TABLE IF EXISTS aaa
删除数据
alter table `default`.aaa delete where 1=14.配置文件
4.1修改用户配置
## 进入到 docker 容器内部:
docker exec -it 容器id /bin/bash
## 修改用户配置:
vim etc/clickhouse-server/users.xml
## 安装vim
apt-get update
apt-get install vim用户密码
初次密码是空的,也可以在挂载的user.xml里面配置密码
## 位置:
案例:
4613ee102c0c0caf003a0ac5fbe5b54e6610bf551f76636958911702c994f717
::/0
default
default
用户名: root
密码: baian123ck完整user.xml案例:
10000000000
0
random
5000
1
92925488b28ab12584ac8fcaa8a27a0f497b2c62940c8f4fbc8ef19ebc87c43e
::/0
readonly
default
4613ee102c0c0caf003a0ac5fbe5b54e6610bf551f76636958911702c994f717
::/0
default
default
3600
0
0
0
0
0
4.1.1 用户密码生成
# 用户密码生成:
If you want to specify SHA256, place it in 'password_sha256_hex' element.
Example: 65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5
Restrictions of SHA256: impossibility to connect to ClickHouse using MySQL JS client (as of July 2019).
# 如果密码使用 SHA256 时, 则需要e395796d6546b1b65db9d665cd43f0e858dd4303
# 如果密码使用 SHA1 时, 则需要4.2 修改集群配置
修改config.xml文件
1
false
1
example01-01-1
9000
example01-01-2
9000
2
false
example01-02-1
9000
example01-02-2
1
9440
## 可参考文档: https://clickhouse.com/docs/zh/engines/table-engines/special/distributed
所以一个集群最少需要俩个节点,各为主节点,互为副本节点.
正常合理的做法是: 一个节点对应一个副本节点. 那么如果是3个节点clickhouse集群,就有3个副本.
4.3修改zookeeper配置
修改config.xml文件
example1
2181
example2
2181
example3
2181
4.4 引入其他配置文件
/etc/metrika.xml
可参考官方文档:配置文件 | ClickHouse Docs
5.集群部署
5.1手动搭建集群
clickhouse 集群是非主从结构,各个节点是相互独立的。因此,和hdfs、yarn的集群不同,我们可以根据配置,灵活的配置集群,甚至可以将一个节点同时分配给多个集群。
clickhouse集群的概念主要就是用于分布式表和表的副本
部署集群图示
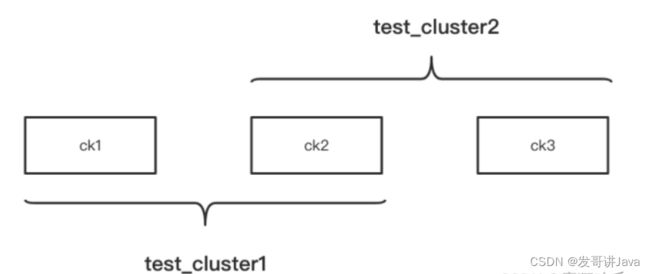
上面这张图有3个节点,这3个节点组成了2个集群。
想要配置集群,需要在 /etc/clickhouse-server/config.xml的
如果要在 /etc/metrika.xml 中配置,需要确保metrika.xml已经被config.xml包含进去了:
要实现上图的集群架构,ck1、ck2、ck3的/etc/metrika.xml配置分别如下:
ck1配置:
ck1
9000
ck2
9000
zk1
2181
ck2配置:
ck1
9000
ck2
9000
ck2
9000
ck3
9000
zk1
2181
ck3:
ck2
9000
ck3
9000
zk1
2181
配置完之后,无需重启clickhouse服务,clickhouse会热加载这些配置。我们可以分别登陆这3台clickhouse,通过 select * from system.clusters; 查看当前节点所属集群的相关信息:
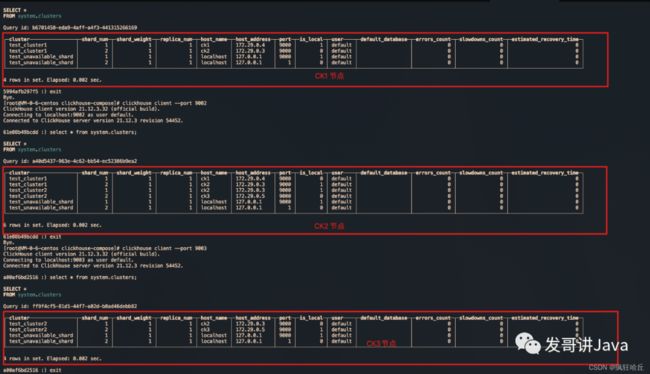
也可以在客户端工具dbeaver上进行sql查询:
select * from `system`.clusters c ;
配置好集群之后,我们就可以基于配置好的集群创建分布式表了:
--在集群test_cluster1上的各个节点创建test表(也就是ck1、ck2) create table default.test on cluster test_cluster1(id Int8,name String) engine = MergeTree order by id; --基于test_cluster1创建分布式表 create table test_all as test engine =Distributed(test_cluster1,default,replicaTest,rand()); 先去各个节点上创建数据表,然后去任意一个节点上创建分布式表,分布式表实际是一个视图
5.2 使用docker-compose搭建集群
当集群机器数量众多,一台一台操作会非常麻烦。另外,如果我们手上没有服务器,又想深入研究clickhouse集群的一些特性时,就可以通过docker快速的搭建起clickhouse集群。
这里简单介绍一下docker-compose,docker-compose会根据定义好的配置文件帮我们启动多个docker container,省去我们一个个容器的操作工作。
下面的docker-compose.yaml是我经常用来快速搭建一个clickhouse集群的docker-compose配置文件:
version: "3.7"
services:
ck1:
image: yandex/clickhouse-server
ulimits:
nofile:
soft: 300001
hard: 300002
ports:
- 8123:8123
- 9001:9000
volumes:
- ./conf/config.xml:/etc/clickhouse-server/config.xml
- ./conf/users.xml:/etc/clickhouse-server/users.xml
- ./conf/metrika1.xml:/etc/metrika.xml
links:
- "zk1"
depends_on:
- zk1
ck2:
image: yandex/clickhouse-server
ulimits:
nofile:
soft: 300001
hard: 300002
volumes:
- ./conf/metrika2.xml:/etc/metrika.xml
- ./conf/config.xml:/etc/clickhouse-server/config.xml
- ./conf/users.xml:/etc/clickhouse-server/users.xml
ports:
- 8124:8123
- 9002:9000
depends_on:
- zk1
ck3:
image: yandex/clickhouse-server
ulimits:
nofile:
soft: 300001
hard: 300002
volumes:
- ./conf/metrika3.xml:/etc/metrika.xml
- ./conf/config.xml:/etc/clickhouse-server/config.xml
- ./conf/users.xml:/etc/clickhouse-server/users.xml
ports:
- 8125:8123
- 9003:9000
depends_on:
- zk1
zk1:
image: zookeeper
restart: always
hostname: zk1
expose:
- "2181"
ports:
- 2181:2181如果是在同一台上模拟集群,连接时则需要将8123端口分别进行映射 - 8123:8123
上面的配置文件定义了4个容器,其中3个容器分别运行clickhouse服务,1个容器运行zookeeper服务。
配置后docker-compose.yaml后,进入该配置文件的目录,执行 docker-compose up -d 就会一起启动这些容器,clickhouse集群也就快速搭建好了。通过docker-compose down可以卸载集群。
上面docker-compose.yaml中引入的./conf/users.xml、./conf/config.xml、./conf/metrika.xml 等内容会在本博客的最后贴出。

6.扩展
6.1 集群扩容
6.2 集群缩容
6.3 数据副本
官方文档:数据副本 | ClickHouse Docs
6.4 数据备份
官方文档: 数据备份 | ClickHouse Docs
尽管 副本 可以提供针对硬件的错误防护, 但是它不能预防人为操作失误: 数据的意外删除, 错误表的删除或者错误集群上表的删除, 以及导致错误数据处理或者数据损坏的软件bug.
可选方案:
-
不能人工删除使用带有MergeTree引擎且包含超过50Gb数据的表. 但是,这些保护措施不能覆盖所有可能情况,并且这些措施可以被绕过。
-
将源数据复制到其它地方,推荐的冷存储,可能是对象存储或分布式文件系统(额外订阅kafka,将数据冷备份一份)
-
文件系统快照,将数据文件拷贝到其他服务器
-
clickhouse-copier 是一个多功能工具,最初创建它是为了用于重新切分pb大小的表。因为它能够在ClickHouse表和集群之间可靠地复制数据,所以它也可用于备份和还原数据
-
part操作
6.5 分布式表写入数据
# 创建一个Distributed引擎的表 :) create table d_table(id UInt8, name String, date Date) engine=Distributed(cluster_name, database, table [,sharding_key]) # cluster_name : 集群名 -- /etc/metrika.xml中这个自定义的标签的名字 # database : 数据库名 # table : 表名 # sharding_key : 分片键(某一列名) 可选 -- 向分布式引擎的表插入数据时 会根据分片名(默认 1 2 3)和你指定的分片键 计算得出实际上数据插入哪一个节点 每次插入的节点可能都不一样 根据默认算法来
sharding_key 必须有,不然会报: ClickHouse exception Method write is not supported by storage Distributed with more than one shard and no sharding key provided.
不建议使用分布式表写入数据
参考文档: ClickHouse合集(一):分布式集群部署及python调用hungry和她的朋友们的博客-CSDN博客python 安装clickhouse
6.6 clickhouse看这一篇就够了
参考文档: ClickHouse合集(一):分布式集群部署及python调用hungry和她的朋友们的博客-CSDN博客python 安装clickhouse
7. docker-compose 中的一些文件
users.xml :
10000000000
random
1
0
1
1
::/0
default
default
default
default
default
test_dictionaries
replicaTest_all
3600
0
0
0
0
0
config.xml:
trace
/var/log/clickhouse-server/clickhouse-server.log
/var/log/clickhouse-server/clickhouse-server.err.log
1000M
10
8123
9000
9004
9005
9009
4096
3
false
/path/to/ssl_cert_file
/path/to/ssl_key_file
false
/path/to/ssl_ca_cert_file
deflate
medium
-1
-1
false
/etc/clickhouse-server/server.crt
/etc/clickhouse-server/server.key
/etc/clickhouse-server/dhparam.pem
none
true
true
sslv2,sslv3
true
true
true
sslv2,sslv3
true
RejectCertificateHandler
100
0
10000
0.9
4194304
0
8589934592
5368709120
1000
134217728
10000
/var/lib/clickhouse/
/var/lib/clickhouse/tmp/
/var/lib/clickhouse/user_files/
users.xml
/var/lib/clickhouse/access/
default
default
true
false
' | sed -e 's|.*>\(.*\)<.*|\1|')
wget https://github.com/ClickHouse/clickhouse-jdbc-bridge/releases/download/v$PKG_VER/clickhouse-jdbc-bridge_$PKG_VER-1_all.deb
apt install --no-install-recommends -f ./clickhouse-jdbc-bridge_$PKG_VER-1_all.deb
clickhouse-jdbc-bridge &
* [CentOS/RHEL]
export MVN_URL=https://repo1.maven.org/maven2/ru/yandex/clickhouse/clickhouse-jdbc-bridge
export PKG_VER=$(curl -sL $MVN_URL/maven-metadata.xml | grep '' | sed -e 's|.*>\(.*\)<.*|\1|')
wget https://github.com/ClickHouse/clickhouse-jdbc-bridge/releases/download/v$PKG_VER/clickhouse-jdbc-bridge-$PKG_VER-1.noarch.rpm
yum localinstall -y clickhouse-jdbc-bridge-$PKG_VER-1.noarch.rpm
clickhouse-jdbc-bridge &
Please refer to https://github.com/ClickHouse/clickhouse-jdbc-bridge#usage for more information.
]]>
localhost
9000
localhost
1
3600
3600
60
system
query_log
toYYYYMM(event_date)
7500
system
trace_log
toYYYYMM(event_date)
7500
system
query_thread_log
toYYYYMM(event_date)
7500
system
query_views_log
toYYYYMM(event_date)
7500
system
part_log
toYYYYMM(event_date)
7500
system
metric_log
7500
1000
system
asynchronous_metric_log
7000
engine MergeTree
partition by toYYYYMM(finish_date)
order by (finish_date, finish_time_us, trace_id)
system
opentelemetry_span_log
7500
system
crash_log
1000
system
session_log
toYYYYMM(event_date)
7500
*_dictionary.xml
*_function.xml
/clickhouse/task_queue/ddl
click_cost
any
0
3600
86400
60
max
0
60
3600
300
86400
3600
/var/lib/clickhouse/format_schemas/
hide encrypt/decrypt arguments
((?:aes_)?(?:encrypt|decrypt)(?:_mysql)?)\s*\(\s*(?:'(?:\\'|.)+'|.*?)\s*\)
\1(???)
false
false
https://[email protected]/5226277
/etc/metrika.xml
metrika1.xml、metrika2.xml、metrika3.xml 见第二章ck1、ck2、ck3的配置文件。
8. 集群考虑点
clickhouse多节点组合在一起是需要一个分布式视图表进行关联在一起.
入数据节点的时候可以从分布式视图表入库, 但建议从数据节点进行入库.
通过对Distributed表写入流程的分析,了解了该类型表的实际工作原理,所以在实际应用中有几个点还需要关注一下:
Distributed表在写入时会在本地节点生成临时数据,会产生写放大,所以会对CPU及内存造成一些额外消耗,建议尽量少使用Distributed表进行写操作;
Distributed表写的临时block会把原始block根据sharding_key和weight进行再次拆分,会产生更多的block分发到远端节点,也增加了merge的负担;
Distributed表如果是基于表函数创建的,一般是同步写,需要注意。
了解原理才能更好的使用,遇到问题才能更好的优化。
写入原理参考: 【clickhouse】ClickHouse最佳实战之分布表写入流程分析_九师兄的博客-CSDN博客
写入流程参考:clickhouse 写入 分布式表 - CSDN
9. 集群案列测试:
分别连接 8123,8124,8125clickhouse数据库
连接8123:
-- 查看集群信息
select * from `system`.clusters c ;
-- 创建表:
create table IF NOT EXISTS `default`.hits (
id Int64,
name String,
birthday DateTime64
)ENGINE = MergeTree()
ORDER BY (id)
SETTINGS index_granularity=8192
-- 插入数据
insert into hits(id,name,birthday ) values(1,'张三', toDateTime('2016-06-15 23:00:00'));
insert into hits(id,name,birthday ) values(3,'王五', '2022-7-13 09:14:13');
--查询数据
select * from hits h ;连接 8124:
-- 查看集群信息
select * from `system`.clusters c ;
-- 创建表:
create table IF NOT EXISTS `default`.hits (
id Int64,
name String,
birthday DateTime64
)ENGINE = MergeTree()
ORDER BY (id)
SETTINGS index_granularity=8192
-- 插入数据
insert into hits(id,name,birthday ) values(4,'赵六', '2020-7-13 02:04:53');
--查询数据
select * from hits h ;
-- 在 8124 上创建 分布式表
CREATE TABLE hits_all AS hits
ENGINE = Distributed(test_cluster1, default, hits,id)
SETTINGS
fsync_after_insert=0,
fsync_directories=0;
-- 查询分布式表:
select * from hits_all h ;
-- 给予分布式表写入数据
insert into hits_all(id,name,birthday ) values(5,'王五', '2022-7-13 09:14:13');
--(当前操作必须在创建分布式表时候要有sharding_key,否则会报错)
-- 删除分布式表
drop table hits_all;公众号:发哥讲
这是一个稍偏基础和偏技术的公众号,甚至其中包括一些可能阅读量很低的包含代码的技术文,不知道你是不是喜欢,期待你的关注。
代码分享
发哥讲Java (naimaohome) - Gitee.com
微信公众号 点击关于我,加入QQ群,即可获取到代码以及高级进阶视频和电子书!!
