机器学习sklearn实战-----随机森林调参乳腺癌分类预测
机器学习sklearn随机森林乳腺癌分类预测
机器学习中调参的基本思想:
1)非常正确的调参思路和方法
2)对模型评估指标有深入理解
3)对数据的感觉和经验
文章目录
-
- 机器学习sklearn随机森林乳腺癌分类预测
- 随机森林原理
- 一、随机森林模型预测
-
- 1.未调参时模型精确度
- 2.调整n_estimators参数
- 二、使用网格搜索调参
- 正确的调参思路
-
- RandomForestClassifier重要参数
- 泛化误差
- 参数对泛化误差的影响
随机森林原理
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
随机森林的优点有 : 1)对于很多种资料,它可以产生高准确度的分类器; 2)它可以处理大量的输入变数; 3)它可以在决定类别时,评估变数的重要性; 4)在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计; 5)它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度; 6)它提供一个实验方法,可以去侦测variable interactions; 7)对于不平衡的分类资料集来说,它可以平衡误差; 8)它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将资料视觉化非常有用; 9)使用上述。它可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。也可侦测偏离者和观看资料; 10)学习过程是很快速的。 随机森林是一种集成模型,利用多棵决策树共同决定,集成学习是通过建立很多模型,集成各个模型的结果和参数来提升最终模型的效果,集成算法会考虑多个评估的建模结果,汇总得到最终的评估结果。
一、随机森林模型预测
1.未调参时模型精确度
利用python自带的乳腺癌数据进行预测。跟之前的方法一样,首先是导入相关的库,导入数据集。实例化模型,利用测试数据训练模型,最后利用测试数据得出模型预测的精确度,这里是未调整参数之前的精确度。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split,cross_val_score,GridSearchCV
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.datasets import load_wine,load_breast_cancer #红酒数据集,乳腺癌数据相对简单
from sklearn.impute import SimpleImputer #数据处理 填补缺失值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import sklearn
data = load_breast_cancer()
rm = RandomForestClassifier(random_state=90, n_estimators=100) #实例化随机森林
score = cross_val_score(rm, data.data, data.target, cv=10).mean()
print("未调参之前的随机森林预测精度为:",score)
![]()
2.调整n_estimators参数
随机森林调参的第一步,先来调n_estimators,并且画出它的学习曲线,方便看变化趋势。
#调参 #画图展示学习曲线
score_list = []
for i in range(0, 200, 10):
rm = RandomForestClassifier(n_estimators=i+1
, random_state=90
, n_jobs=1)
#交叉验证
score = cross_val_score(rm, data.data, data.target, cv=10).mean()
score_list.append(score) #记录每个n_estimators下的精确度
print((max(score_list), (score_list.index(max(score_list))*10)+1)) #输出最大的n_estimators以及它的下标
plt.figure(figsize=[20,5]) #展示画布的大小
plt.plot(range(1, 201, 10), score_list, color="r", label="random predict")
plt.legend() #展示图例
plt.show()
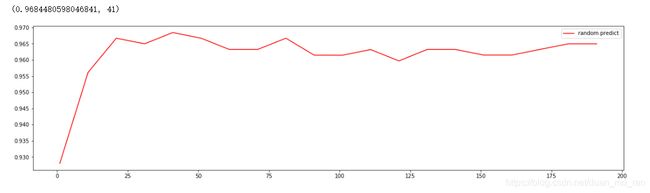
可以看出n_estimators参数在31-41之间。我们在把它具体。
#具体调模型的n_estimators参数
score_list2 = []
for i in range(35,45):
rfc = RandomForestClassifier(n_estimators=i
,n_jobs=-1
,random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score_list2.append(score)
print(max(score_list2),score_list2.index(max(score_list2))+35)
plt.figure(figsize=[20,5])
plt.plot(range(35,45),score_list2)
plt.show()
#可以看见n_estimators最优是取到39

二、使用网格搜索调参
#利用网格搜索,继续调整max_depth
param_grid = {
"max_depth": np.arange(5,30)
}
rm_new = RandomForestClassifier(n_estimators=39
, random_state=90
, n_jobs=1
)
GV = GridSearchCV(rm_new, param_grid=param_grid, cv=10)
GV.fit(data.data, data.target)
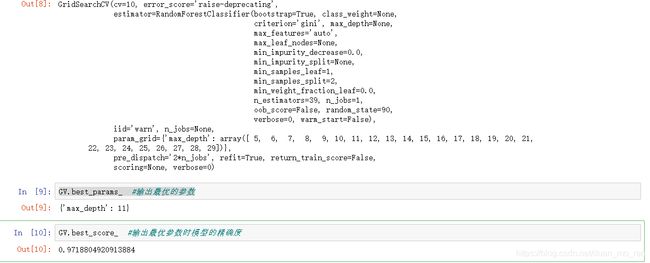
然后输出最优的参数,#输出最优参数时模型的精确度。相对未调参之前的精确度高了一点。
正确的调参思路
RandomForestClassifier重要参数
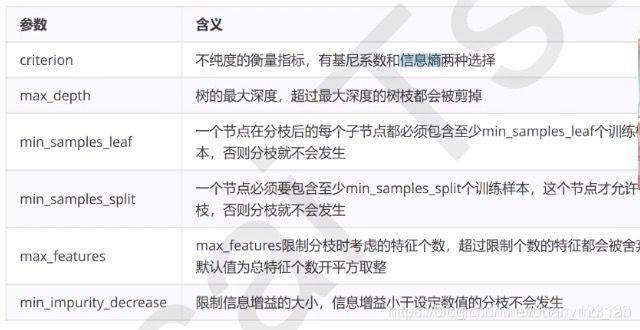
n_estimators控制基评估器的数量,通常都是越大越好,但是受困于计算量的限制。默认值为10或者100,一般我们取0到200。
泛化误差
当模型在未知数据上表现糟糕时,我们说模型的泛化程度不够,泛化误差大。
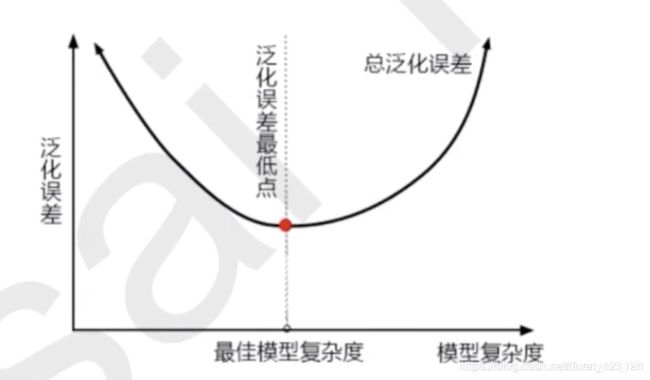
通过上图我们发现模型的复杂度会影响泛化误差:模型太简单和太复杂都会使得泛化误差变大分别是欠拟合和过拟合,树模型是天生的的复杂模型,对于树模型来说非常容易过拟合,同样的,对于以树模型作为基础的随机森林来讲,我们的调参目标就是减少模型的复杂度来降低泛化误差。
参数对泛化误差的影响
影响力从高到低:
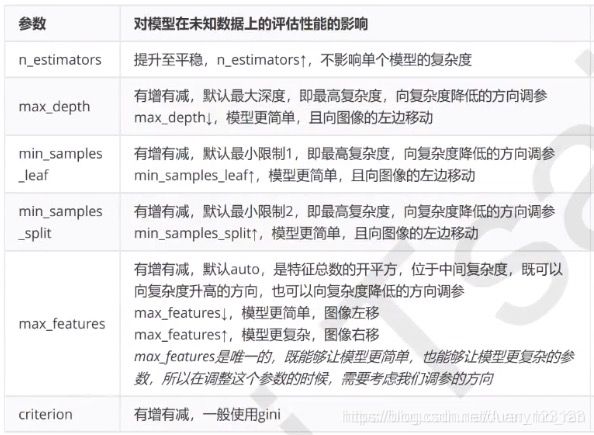
一般调参数是为了模型更加精确,而在实际数据中,调参其实是一个很费时间的事。如果能理解随机森林参数的原理,在调整参数时,可能会好一些。