AI加速器与机器学习算法:协同设计与进化

此刻,你应该是在电脑或手机上看这篇文章。不管怎样,这些机器都属于现代计算机,它们都有中央处理器(CPU)和其他为特定功能服务的专用芯片,例如显卡、声卡、网卡、传感器融合等。处理特定任务时,专用处理器往往比通用CPU更快更高效。
计算机发展早期,CPU都会和专用处理器配合使用。1970年代的8位和16位CPU需要依赖软件来模拟浮点指令,因此执行浮点运算非常慢。而由于计算机辅助设计(CAD)和工程模拟等应用对浮点运算的速度要求较高,于是人们开始用数学协处理器(math coprocessor)辅助CPU,让数学协处理器分担所有浮点运算任务,它的浮点运算速度和效率都比CPU更高。这就是专用处理器的一个例子。
关注AI和半导体行业的朋友近来可能听说过“机器学习(ML)专用处理器”(即AI加速器)。最常见的AI加速器莫过于NVIDIA GPU,此外还有Intel的Habana Gaudi处理器、Graphcore的Bow IPU、Google的TPU、AWS的Trainium和Inferentia芯片等。
为什么如今有这么多AI加速器可供选择?它们和CPU有什么不同?算法如何改变才能适应这些 硬件? 硬件又该如何发展才能支持最新的算法? 本文将一一解答。本文主要内容包括:
-
为什么需要专用AI加速器?
-
ML硬件的分类:CPU、GPU、AI加速器、FPGA和ASIC
-
“硬件感知(Hardware-aware)”的算法和“算法感知(Algorithms-aware)”的硬件
-
AI加速器与高效ML算法的协同进化
-
针对推理的AI加速器与高效算法
-
针对训练的AI加速器与高效算法
-
AI加速器的未来
1
为什么需要专用AI加速器?
构建ML专用处理器有三个方面的原因:能效、性能、模型大小及复杂度。近来,要提高模型准确率,通常做法是扩大模型参数量,并用更大型的数据集训练模型。计算机视觉、自然语言处理和推荐系统都采用这种做法。
语言模型方面,前几年诞生的GPT-3有1750亿参数,当时被视为大模型的“天花板”,但后来又出现了GLaM和NVIDIA MT-NLG,参数量分别达到1.2万亿和5300亿。按照历史规律,模型将越来越大,而现有处理器的算力将无法满足大模型在训练时间和推理延迟方面的要求。
不过,构建AI专用加速器的最重要原因还是能效,开发AI专用芯片可节省巨大的能源,可覆盖研发投入有余。
为什么需要高能效的处理器?
ML模型越大,需要执行的内存访问操作就越多。与内存访问相比,矩阵-矩阵运算和矩阵-向量运算的能效高很多。根据斯坦福大学韩松博士的论文( https://arxiv.org/pdf/1506.02626v3.pdf ),读取内存的能耗比加/乘运算操作的能耗高出好几个数量级。大型神经网络由于无法片上存储,需要执行更多DRAM读取操作,因此能耗还要更高。
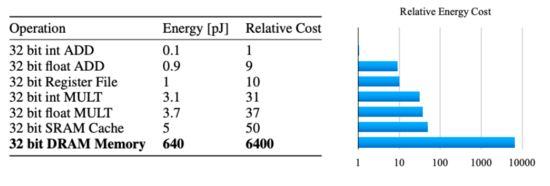
图源:https://arxiv.org/pdf/1506.02626v3.pdf
用通用处理器运行深度神经网络时,扩大处理器规模可以带来性能提升,但即便只是小幅提升也须以大量能耗和巨额设备成本为代价。
CPU等通用处理器牺牲低能耗换取通用性,AI加速器等专用处理器则牺牲通用性换取低能耗。
使用AI加速器则不一样。AI加速器通过改进设计,可以减少内存访问,提供更大的片上缓存,还可以具备特定的硬件功能(如加速矩阵-矩阵计算)。由于AI加速器是基于特定而构建的设备,可根据算法进行适配改进,因此其运行效率会比通用处理器更高。
2
ML硬件的分类——CPU、GPU、AI加速器、FPGA和ASIC
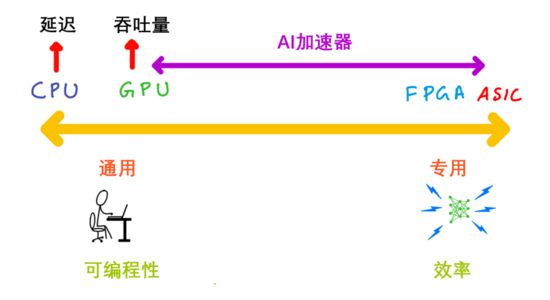
接下来我们谈谈加速器的不同种类,以及它们的通用和专用程度。

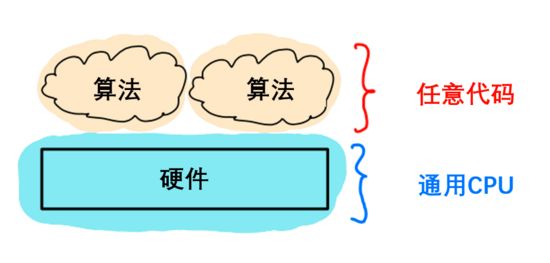
如上图所示,最具通用性的是CPU,可以运行任意代码。专用芯片可执行的任务,CPU也能执行,如图像处理、语音处理、机器学习等。然而,CPU的性能和能效都比较低。
专用性最强的是专用集成电路(ASIC),又称固定功能芯片,因为它只能执行一种或几种任务,而且通常不可编程,也没有面向开发者的API。耳机中的降噪处理器就是一种ASIC芯片,它需要同时具备低能耗和高性能,这样才能既延长耳机电池使用时间,又能实现低延迟,以免用户看节目时遇到声画不同步的糟糕体验。
上图中,越靠左代表通用性和可编程性越强;越靠右代表专用性和效率越高。那么GPU、FPGA和AI加速器分别处于图中什么位置呢?
答案是:它们都处在这两个极端之间。
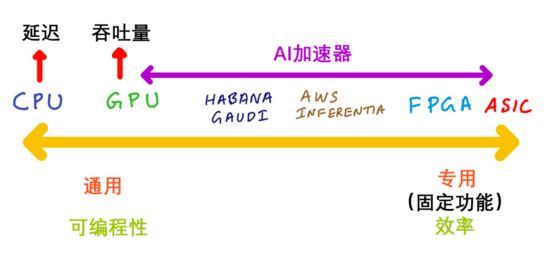
靠近ASIC一端的是现场可编程逻辑门阵列(FPGA)。顾名思义,FPGA是可编程的,但编程人员需要具备硬件设计知识,还须对Verilog、VHDL等硬件描述语言(HDL)有一定了解。换言之,FPGA编程与硬件关联度太高,而软件开发人员缺乏这方面的编程技能和工具,因此难以对它进行编程。
靠近CPU一端的是GPU。GPU是面向特定目的处理器,擅长处理并行任务,例如图形着色器计算和矩阵乘法。CPU更适合延迟敏感型应用,GPU则更适合要求高吞吐量的应用。GPU与CPU的相似之处在于它们都可编程。而作为并行处理器,GPU使用NVIDIA CUDA和OpenCL等语言,虽然能处理的任务种类比CPU少,但在运行包含并行任务的代码时极高效。
Intel的Habana Gaudi处理器、AWS的Trainium和Inferentia芯片等AI加速器则处在GPU的右侧。Habana Gaudi处理器具备可编程性,但通用性比GPU更低,所以应处GPU右侧。AWS的Inferentia芯片不可编程,但可以加速多种操作,如果你的ML模型不支持这些操作,Inferentia就会执行CPU回退(fallback)模式。综上,Inferentia应处Habana Gaudi的右侧。
3
“硬件感知(Hardware-aware)”的算法
和“算法感知(Algorithms-aware)”的硬件
通过以上分类,我们对各种处理器有了大致认识。 下面我们来谈谈这些处理器如何与软件互相配合。
通用计算模型有两个组成部分:(1)软件与算法;(2)运行软件的硬件处理器。一般而言,这两部分互相独立——编写软件时很少会考虑软件会在什么硬件上运行;而硬件设计的出发点则是让硬件尽可能支持更多种类的软件。
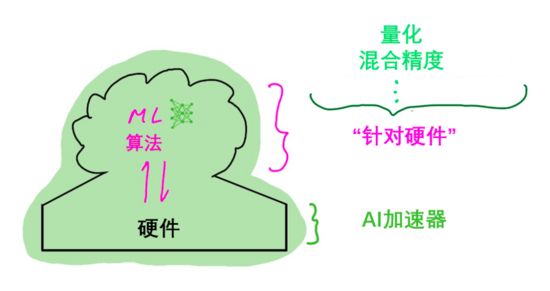
通用计算模型逐渐演进,需要应用于深度学习等要求高性能和高能效的领域,因此需要加强算法设计和硬件设计之间的联系。现代ML计算模型同样包含两个组成部分:(1)ML算法与软件框架;(2)与AI加速器配合使用的通用处理器。
不同于通用计算模型的开发,ML研发人员会针对特定硬件设计ML算法。比如,编写代码时可以充分利用硬件的特定功能(如支持多种精度:INT8、FP16、BF16、FP32)实现特定的芯片功能(混合精度、结构化稀疏)。然后,用户就可以通过常见的ML软件框架使用这些功能。同理,硬件设计师会针对特定算法构建AI加速器。比如,为加速ML矩阵计算而设计专门的芯片功能(如NVIDIA在Volta GPU架构中引入Tensor Core)。
这就是AI加速器和ML算法的协同进化。硬件设计师为AI加速器增加ML算法可以使用的功能,而ML研发人员则利用AI加速器的硬件功能量身设计新的算法。
硬件和软件的协同可以带来更好的性能和更高的能效。
4
AI加速器与高效ML算法的协同进化
AI加速器分为两类: (1)用于训练的AI加速器; (2)用于推理的AI加速器。 由于训练和推理的目标不同,而AI加速器是针对特定工作负载的专用处理器,因此有必要为不同类型的工作负载分别设计处理器。
用于训练的AI加速器的目标是减少训练时间,而且应具备能配合训练算法的硬件特点。 因此,AI训练加速器的功率通常较大,内存空间也较大,以满足较高的吞吐量(每秒处理的数据)要求。 由于AI训练加速器注重吞吐量,因此提高吞吐量和利用率有助于降低能耗成本(即通过扩大吞吐量降低“能耗/吞吐量”之间的比率)。 AI训练加速器还支持混合精度训练,使用较低精度以加快计算速度,使用高精度累积计算结果,从而实现比通用处理器更高的能效。 (后文还将详谈AI加速器的混合精度训练。 )
AI推理加速器的目标是,在运行大量独立数据批次时降低预测延迟,因此需要具备高能效特点,需要降低“能耗/预测”之间的比率。虽然也可将训练加速器用于推理加速(毕竟训练中的前向传播过程本质上即是一种推理任务),但使用训练加速器时,“能耗/推理”之比会大很多,因为训练加速器处理小型数据批次的推理请求时利用率较低。
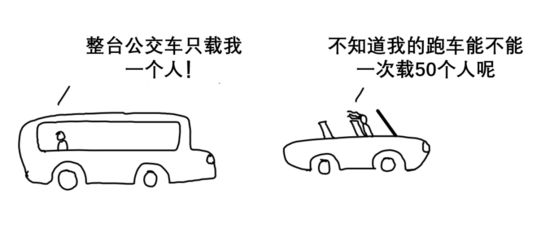
训练加速器就像公交车,只有保持乘客满员才能实现高能效(油耗/乘客数之比低)。如果偌大的公交车每次只载一个人,其油耗/乘客数之比将变得极高。而推理加速器就像跑车,其速度比公交车快,只载一人时能效比公交车高(跑车的单名乘客油耗比公交车低)。但如果想用跑车一次载50个人,它就会跑得极慢(何况超载违法)。
下文将分别谈论训练和推理的工作流,以及AI加速器和软件应具备什么特点才能在训练和推理中实现高性能和高能效。
5
针对推理的AI加速器与高效算法
ML推理即是根据新的数据使用训练好的模型以输出预测结果。 本节将讨论AI加速器上运行的可提升推理性能和效率的算法。
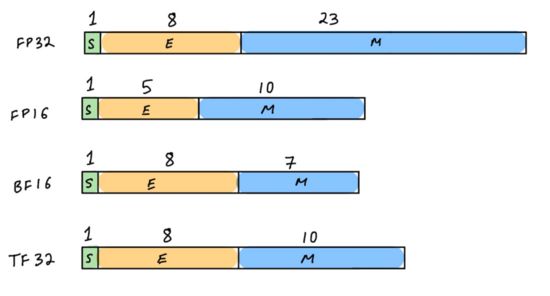
提升机器学习效率最重要的方法是量化。要充分理解量化,首先须了解计算机硬件中的数字表示方法。浮点数是数字计算机中用以表示连续实值的离散表示形式。ML算法通常基于IEEE 754标准用单精度(FP32)储存和处理数字。IEEE 754还规定了AI加速器支持的其他常见浮点类型,如半精度(FP16)和双精度(FP64)。
现代AI加速器也支持IEEE 754以外的数字格式,例如BF16(由Google Brain引进;NVIDIA Ampere GPU、AWS Inferential、AWS Tranium、Intel Habana Gaudi和Google TPU均支持此格式)和TF32(NVIDIA Ampere架构和AWS Tranium芯片支持此格式)。推理加速器还支持整数精度,如INT8和INT4。
量化在推理中的优势
在推理任务中,模型权重和激活函数输出均可被量化,例如可将FP32(训练常用精度)转化为更低精度的表示形式(FP16、BF16和INT8)。使用较低精度可以获得更高的性能和能效。当把FP32转化为FP16操作时,数据大小可减半,能耗可减少约75%(数据来源: https://arxiv.org/pdf/1506.02626v3.pdf ) ,使用的硅面积(silicon area)也可减少约75%。
如果仅从推理的角度考虑硬件设计,可以构建仅供推理使用、仅支持较低精度的加速器,这样就可以缩小加速器的尺寸,并提高能效。将运算结果从FP32转化为INT8数据还可进一步减少能耗,因为数据大小减少到原来的1/4。
然而,通过量化方法提升计算效率会损失一定的预测准确性。因为将高精度表示形式转化为低精度本质上是一种压缩,压缩意味着会损失部分数据。FP32的动态范围比FP16和INT8更大,因此,推理中,量化的目的是保留数据中的“信号”,去除数据中的“噪声”,为实现这个目的可以有多种方法。
使用NVIDIA GPU进行量化
NVIDIA的Ampere和Turing等较新GPU架构均支持多种精度类型。2016年,NVIDIA在Pascal架构中首次引进了FP16精度类型,而最新的Ampere和Turing架构GPU均体现了“硬件与算法的协同进化”。我之前写过一篇文章介绍GPU的完整发展史和不同架构的GPU及其特点:Choosing the right GPU for deep learning on AWS( https://towardsdatascience.com/choosing-the-right-gpu-for-deep-learning-on-aws-d69c157d8c86 )。
本节将聚焦硬件和软件层面如何支持GPU进行量化。
以NVIDIA 的Ampere架构为例。你可以在AWS云服务器上通过启动Amazon EC2 p4d实例或G5实例体验Ampere架构的性能。p4d和G5实例分别使用NVIDIA的A100和A10G GPU,两款GPU都基于Ampere架构,都支持FP64、FP32、FP16、 INT8、BF16和TF32精度类型,也都包含一种被NVIDIA称为“Tensor Core”的运算单元,用于混合精度计算。推理时用到的重点精度类型只有FP16和INT8两种(其他精度类型将在下一节中提到训练时详谈)。
大多数深度学习框架都使用NVIDIA GPU和FP32格式训练模型,因此NVIDIA 推出TensorRT编译器,用以加快推理速度。TensorRT可将FP32格式的模型权重和激活函数量化为FP16和INT8格式。量化时,TensorRT先确定一个比例因子(scaling factor),然后根据该系数将FP32的动态范围映射到FP16或INT8的动态范围。映射到INT8的难度尤其高,因为INT8的动态范围比FP32小太多。INT8仅能表示256个数值,而FP32足足能表示4.2×109个数值。
如何在通过量化提高推理速度的同时减少精度损失?一般有两种方法:
-
训练后量化(PTQ) :使用一个训练好的、以FP32格式计算的模型,确定比例因子,然后将FP32映射为INT8。确定比例因子的方法是:TensorRT衡量每个神经网络层中激活函数输出的分布,然后找到一个使参考分布(reference distribution)和量化分布(quantized distribution)之间信息损失(KL散度)最小的比例因子。
-
量化感知训练(QAT) :在训练中计算比例因子,使模型可以适应信息损失并将信息损失降到最低。
可见,硬件不断发展,具备更多可提升效率的功能(如降低精度)。 同时,算法也不断进化,可以更好地利用硬件的功能。
我的另一篇文章提供了NVIDIA TensorRT在GPU上实行量化的代码示例 ( https://towardsdatascience.com/a-complete-guide-to-ai-accelerators-for-deep-learning-inference-gpus-aws-inferentia-and-amazon-7a5d6804ef1c )。
使用AWS Inferentia芯片进行量化
NVIDIA GPU设计之初用于图像处理加速,后来才演变成强大的AI加速器,而AWS Inferentia芯片一开始即是为机器学习推理而生。
每块AWS Inferentia芯片含4个NeuronCore。NeuronCore是基于脉动阵列的矩阵相乘引擎,有两级存储层次结构和极大的片上缓存空间。AWS Inferentia芯片支持FP16、BF16和INT8数据类型,不支持更高精度的格式——毕竟AWS Inferentia是一种推理专用处理器,推理时无须用到更高的精度。正如NVIDIA为GPU推出了TensorRT编译器,AWS也推出了AWS Neuron SDK和AWS Neuron编译器,该编译器支持量化和优化,可提高推理效率。
尽管AWS Inferentia芯片支持INT8格式,但截至本文撰写时,AWS Neuron编译器只支持量化到FP16和BF16格式。 用FP32格式训练的模型会在编译过程中自动被转化为BF16格式。 如果在使用AWS Neuron编译器之前人工将FP32格式的权重量化为FP16,那么编译器就会保留FP16精度用于推理。
与GPU相比,AWS Inferentia芯片不可编程,专用性比GPU更强,更接近ASIC。 如果模型中包含的操作均为AWS Inferentia所支持,那么对于特定的模型和批次规模(batch size)而言,使用Inferentia就比使用GPU更能提高模型的能效。 然而,如果模型含有Inferentia不支持的操作,AWS Neuron编译器会自动将相应操作置于主机CPU上,这就导致CPU和加速器之间需要进行数据搬运,进而降低性能和效率。
6
针对训练的AI加速器与高效算法
ML训练即利用训练数据优化模型参数,以提高模型的预测准确度。本节将讨论AI加速器上运行的算法如何提升推理性能和能效。
接下来我们依旧会讨论精度,不过这次是从训练工作流的角度。 如前所述,训练时,模型权重和激活函数都以FP32格式存储,FP32遵循早在深度学习之前就诞生的IEEE 754浮点数标准。 FP32之所以被选为机器学习默认的浮点数表示形式,是因为训练时FP16可表示的信息量不够大,而FP64可表示的信息量则太大,而且也不必用到这么高的精度。 机器学习需要一种精度处在FP16 和FP64之间的表示格式,但当时的硬件并不支持。
换言之,当时的硬件并不能满足ML算法的需求,并未成为“算法感知”的硬件。
如果当时的ML研究人员有更好的选择,他们应该会选一种不同于FP32的格式,或者使用混合精度来提升性能和效率。 混合精度也正是目前AI加速器的发展方向。 实现混合精度,需要硬件和算法的协同设计。

混合精度训练提升性能与效率
矩阵乘法运算是神经网络训练和推理的基本操作。 AI加速器的主要工作即为在神经网络的不同层中将输入数据和权重的大型矩阵相乘。 混合精度训练背后的思想是,训练时的矩阵乘法发生在较低精度表示(FP16、BF16、TF32),因此它们更快和能效更高,然后用FP32格式累积运算结果,以降低信息损失,从而提升训练速度和能效。
使用NVIDIA GPU进行混合精度训练
2017年,NVIDIA宣布推出Volta GPU架构,其中包含专门用于机器学习的Tensor Core运算单元。Tensor Core通过FP16运算和FP32累积结果实现混合精度训练( https://arxiv.org/abs/1710.03740 )。NVIDIA的新一代新架构还支持更多低精度格式(BF16、TF32)。在芯片层次,Tensor Core执行低精度(reduced-precision)融合乘加(FMA)运算,用FP32累积结果。
每一代NVIDIA架构的进步都体现了硬件和算法之间的协同设计和协同发展。
-
NVIDIA Volta架构(2017)引入第一代Tensor Core,当时仅支持FP16运算和FP32累积结果。
-
NVIDIA Turing架构(2018)的Tensor Core支持更低精度的INT8和INT4(主要可以加速推理,而非加速训练)。
-
NVIDIA Ampere架构(2020)的Tensor Core还支持BF16和TF32,也就是说,它可以执行FP16、BF16和TF32运算,并且用FP32累积结果,以实现混合精度
混合精度训练的一大难点是软件层面的实现。 用户必须在训练时执行额外的操作,比如将权重转化为FP16格式,但同时会保留权重的FP32副本和损失缩放(loss scaling)。 尽管NVIDIA可以让深度学习框架在只需修改少量代码的情况下执行这些操作,它对用户的要求依然很高,不像使用FP32训练那么简单。
NVIDIA的Ampere架构支持TF32,可以有效解决这一用户体验难题。TF32格式的好处在于,它结合了FP32的动态范围和FP16的精度,因此深度学习框架无需转换格式和保留副本等额外操作即可直接支持TF32格式。然而,在为开发者减少麻烦的情况下,使用TF32可实现比FP32更好的性能,但NVIDIA依然推荐使用FP16或BF16格式进行混合精度训练,以便获得最快的训练性能。
使用其他AI加速器进行混合精度训练
Intel Habana Gaudi处理器
Habana Gaudi加速器支持混合精度训练的方式与NVIDIA GPU类似——通过一个附加工具配合深度学习框架,使用格式转换和副本保存功能。若想体验Intel Habana Gaudi AI加速器的功能,可以通过AWS云服务器启动Amazon EC2 DL1实例,该实例配备8个Gaudi加速器。
AWS Tranium芯片
AWS在2021年re:Invent大会上宣布推出Tranium芯片,该芯片由AWS的Annapurna实验室研发,用于AI加速。目前,Tranium 芯片尚未得到大规模应用。AWS在大会上介绍称,Tranium将支持FP16、TF32、BF16、INT8,以及一种称为cFP8(定制8位浮点数)的全新格式。
7
AI加速器的未来
如今,ML算法研究和硬件设计都在蓬勃发展。AI加速器也将在性能和能效方面持续进步,逐渐可以像通用处理器一样无缝使用。
现代的AI加速器已具备理想中的硬件功能,例如支持INT1和INT4,这两种精度类型尚未被用于训练和推理,但或许它们的存在可以催生新的ML算法。AI加速器之间的互联也渐见革新。
随着模型规模越来越大,我们需要更大的计算集群,将更多AI加速器连接起来,从而支持更大的工作负载。为此,NVIDIA推出了高带宽的NVLink和NVSwitch,用于GPU之间的互联;Intel的Habana Gaudi处理器则在片上集成了基于以太网的RoCE RDMA。未来AI应用将更加广泛, AI加速器也将成为现代计算环境的中流砥柱。
希望未来的AI加速器带来更好的用户和开发者体验。如今的异构计算模型需要协调多个CPU和AI加速器,对大部分数据科学家和开发人员而言,掌握它们的联网和存储设置难度颇高。使用Amazon SageMaker等云托管服务可省去管理基础设施的麻烦,可以方便地扩大机器学习规模,然而,开源框架仍希望用户对底层硬件、精度类型、编译器选择和联网原语等有较深的了解。
未来,开发人员可以登入远程IDE,然后使用开源ML框架运行代码,而不必考虑代码在何种设备上以何种方式运行。 他们唯一需要思考的只是成本和速度之间的权衡——想获得高速度就多花钱,想省钱就在速度上妥协。我是个乐观的人,我认为距离这样的未来已经不远了。