视觉答题的方法、数据集和评价指标综述
A survey of methods, datasets and evaluation metrics for visual question answering
- 介绍
-
- VQA目前的主要困境
- VQA的应用
- 特征的提取
-
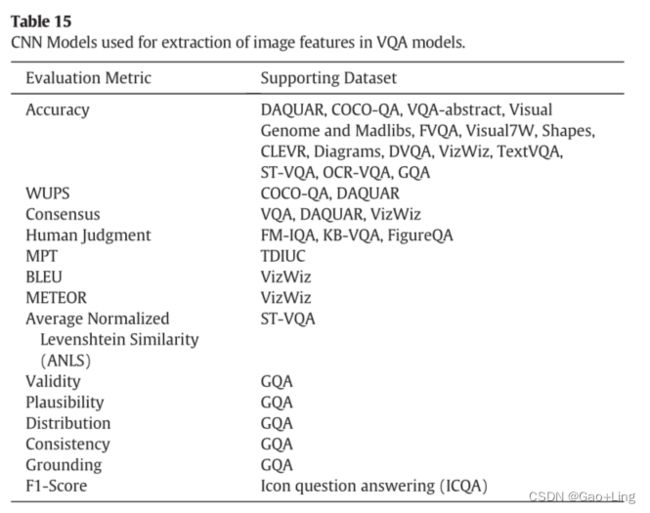
- 图像特征的提取:
- 问题特征的提取:
-
- 基于计数方法
- 基于预测的方法
- Hybrid models混合模型
- 最新的文本嵌入模型
- 数据集
-
- DAQUAR[109](benchmark数据集,但数据集规模较小)
- COCO-QA[50](包含四种类型的问题:对象(69.84%)、颜色(16.59%)、数字(7.47%)和位置(6.10%)。)
- the VQA dataset[11](一张图片对应三个问题,每个问题对应十个答案)
- FM-IQA[55](答案是句子,问题需要进行常识性推理,数据集的QA对有中英文版本,问题和答案由人类给出,但是暂无好的评估方法)
- Visual Genome[110](问题类型:What, Where, How, When, Who, and Why。没有是/否问题)
- Visual7W[12](七类问题:What,Where, How, When, Who, Why, and which。问题以选择题的形式进行评估,每个问题有四个候选答案,其中只有一个是正确的。)
- shapes[111]
- KB-VQA[82]
- FVQA[83]
- Visual Madlibs[112](为了在“填空”任务上评估系统)
- CLEVR[177](用于测试VQA模型的视觉推理能力)
- FigureQA[208](线状图、点状图、水平和垂直柱状图以及饼状图)
- DVQA[209](仅用于评价柱状图的不同方面)
- Diagram[210](用于评价VQA系统的图解释能力)
- TDIUC[211](任务导向图像理解挑战)
- VizWiz[122](处理盲人用户问题的面向目标的VQA数据集)
- VQA- Med[128](医疗VQA数据集)
- ICQA[92]
- 场景文本阅读VQA模型的扩展
-
- TextVQA的新数据集
- 场景文本VQA (ST-VQA)
- OCR-VQA-200 K dataset
- 评估指标(可参考)
-
- simple accuracy
- Wu-Palmer Similarity (WUPS)
- 用于VQA的accuracy
- 人工裁判
- mean -type (MPT)评价指标,归一化指标(算术归一化MPT和谐波归一化MPT)针对分布不均衡任务
- 平均归一化Levenshtein Similarity (ANLS)
- 双语评价替补BiLingual Evaluation Understudy (BLEU)和 METEOR (Metric for Evaluation of Translation with Explicit ordered 显式排序翻译的评价指标)
- 一致性指标Consistency metric,有效性度量The validity metric,可信度评分The plausibility score,分布度量The distribution metric
- Results
-
- Comparison of the SOTA methods on VQA 1.0 dataset
- Comparison of the SOTA methods on VQA 2.0 dataset
- Comparison of the SOTA methods on COCO-QA and DAQAUAR datasets
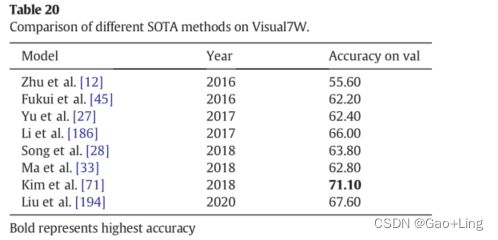
- Comparison of the SOTA methods on Visual7W and CLEVR datasets
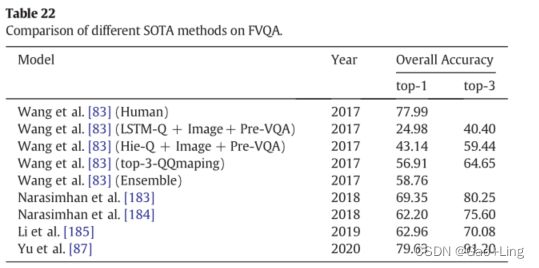
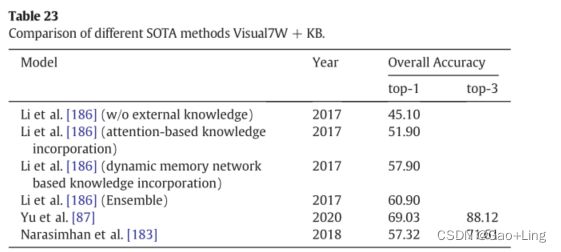
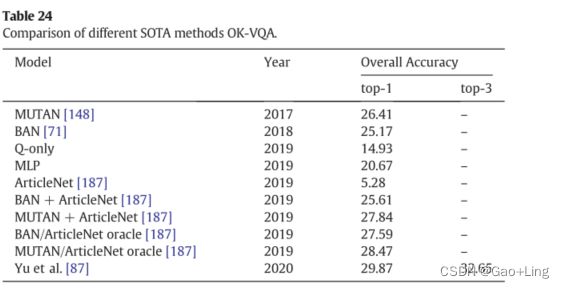
- Comparison of the SOTA methods on FVQA, Visual7W + KB and OK-VQA datasets
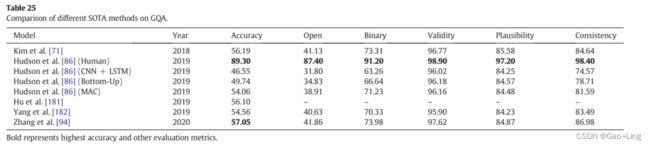
- Comparison of the SOTA methods on GQA dataset
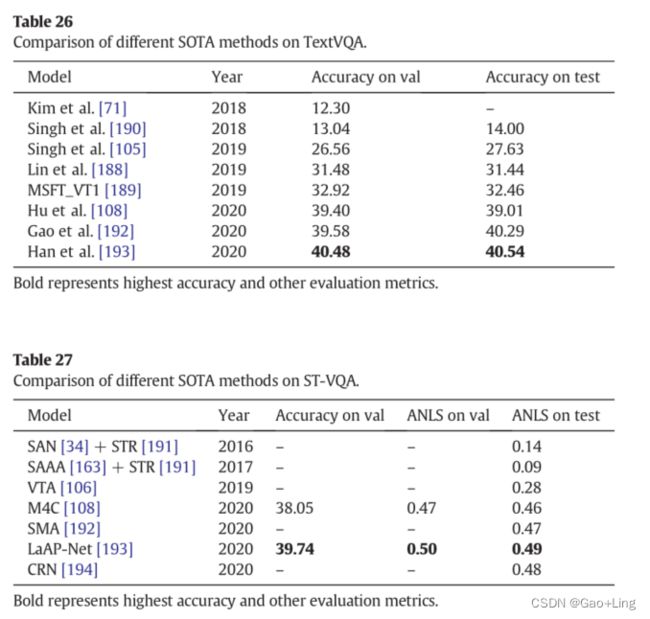
- Comparison of the scene-text reading VQA models on TextVQA, ST-VQA and OCR-VQA datasets
本文讨论了VQA系统中使用的一些核心概念,并对过去为解决这个问题所做的努力进行了全面的调查。除了传统的VQA模型,我们还讨论了视觉问题回答模型,这些模型需要阅读图像中的文本,并在最近开发的数据集(如TextVQA、ST-VQA和or -VQA)上进行评估。除了在之前的调查中讨论的标准数据集,我们还讨论了2019年和2020年开发的一些新数据集,如GQA、OK-VQA、TextVQA、ST-VQA和oc - vqa。对新的评价指标如BLEU、MPT、METEOR、平均归一化Levenshtein相似度(ANLS)、效度(Validity)、似然(合理性)、分布(Distribution)、一致性(Consistency)、接地(接地)、f1得分(F1-Score)等进行了说明。最后,我们对VQA任务每个阶段的开放问题进行了讨论,并提出了一些有希望的未来方向。
本文详细讨论了VQA任务所涉及的所有步骤,如图像编码、问题表示、不同的注意机制以及迄今采用的各种融合策略。图3显示了VQA任务所涉及的所有步骤。这项调查的主要贡献是:
•详细讨论了SOTA模型的图像和问题特征提取,包括最近的(2020)SOTA模型。
•除了在之前的调查中讨论的标准数据集,我们还讨论了2019年和2020年开发的一些新数据集,如GQA、OK-VQA、TextVQA、ST-VQA和oc - vqa。直到今天,这些数据集还没有在任何调查中讨论过。
•对新的评价指标如BLEU, MPT, METEOR,平均标准化Levenshtein相似度(ANLS),有效性,似然性,分布,一致性,接地,F1-Score进行了解释,以及之前调查讨论的评价指标。
•还讨论了视觉特征和问题特征之间的各种注意力机制,即单跳和多跳。深入讨论了SOTA VQA模型采用的不同融合策略。
•也解释了,并基于不同的基准数据集与这些最近开发的数据集比较了不同的基准方法。另一个重要贡献是,我们讨论了需要阅读图像中的文本的视觉问题回答模型,并对最近开发的数据集(如TextVQA、ST-VQA和or - vqa)进行了评估。据我们所知,这是第一次将传统视觉问答与场景文本视觉问答相结合的调查。
•介绍了几乎所有VQA数据集的详细结果分析,如VQA 1.0, VQA 2.0, COCO-QA, DAQUAR, Visual7W, CLEVR, FVQA, Visual7W + KB, GQA, OK-VQA, TextVQA, ST-VQA,和OCRVQA。
•最后分析了一些开放的挑战,并列出了未来的指导方针。
介绍
VQA目前的主要困境
- 对开放式回答和多项选择题任务的评估:
- 面向应用程序的数据集的需求:
- 数据集偏差:
- 来自真实VQA数据集的图像特征:
- 数据集规模相对较小:
- 平衡的二元问题:
- 可回答和不可回答的类之间的不平衡:(do)
- Conversational questions: 可连续的提问:(do)
- 需要阅读场景文本的问题:
现实世界中的许多问题可能需要阅读图像中的文本的能力。在复杂的自然图像中,最大的挑战是将文本从背景中分离出来,这是非常复杂的。此外,各种异域字体样式也给文本的定位和识别带来了困难。由于光照不规律,相机传感器的反应也不规律,提取出失真恶化的视觉特征,从而产生不正确的场景文本检测和识别。
VQA的应用
特征的提取
图像特征的提取:
问题特征的提取:
基于计数方法
one-hot 编码是最简单的词嵌入方法。
另一种基于计数的方法是共现矩阵Co-occurrence Matrix,其大小为|V| × |V|。矩阵中包含的值表示一个单词在另一个单词的上下文中出现的情况。我们可以将上下文定义为围绕特定单词的k大小窗口。
基于预测的方法
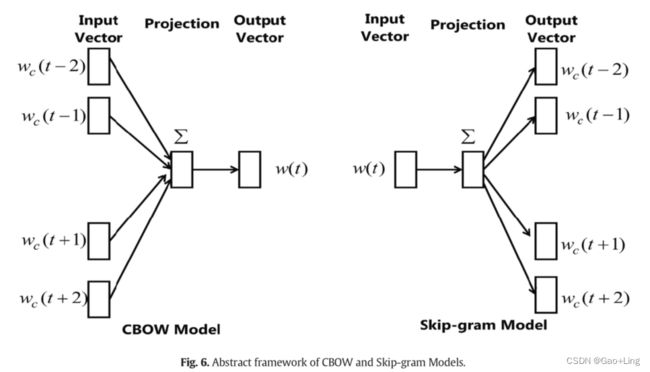
这些方法使用神经网络模块。连续词袋Continuous bag-of-words(CBOW)和skip-gram模型是Mikolov等人提出的两种基于预测的词嵌入技术。图6显示了CBOW(左)和Skip-gram(右)架构的抽象框架。
在CBOW中,当给定(n‐1)个上下文单词时,模型使用前馈神经网络进行单词预测,并将其视为一个多类分类问题。此外,该模型根据一组上下文单词生成一个输出单词。
在Skip-gram模型中(图6),该模型预测给定输入单词两侧的上下文单词。在他的另一篇论文中,Mikolov等人建议对基本skip-gram模型进行不同的修改,以处理在输出层执行的昂贵操作的问题。负采样是word2vec中常用的一种修改方法。
Word2vec是谷歌为skip-grams开发的一个开源项目。
Hybrid models混合模型
全局向量(Glove)由Pennington等人提出。[23]。在GloVe中,基于计数的方法和基于预测的方法被融合在一起生成单词表示。此外,[23]使用了加权最小二乘方法。此外,从共生矩阵中获得的全局信息用于训练该模型。用非零项代替整个稀疏矩阵进行训练。
最新的文本嵌入模型
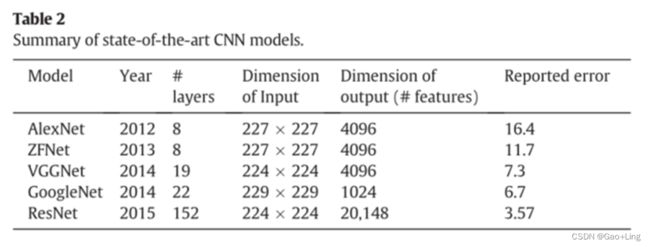
卷积神经网络(CNN)[17]、长短期记忆(LSTM)[19]和门控循环单元(GRU)[20]也被用来表示问题。在基于CNN的问题特征提取中,给出了一个问题的整个单词的串联编码向量作为模型的输入。然后应用多个卷积滤波器,最后进行最大池化操作。然后,将生成的特征图进行平面化,利用后一层作为问题向量表示。
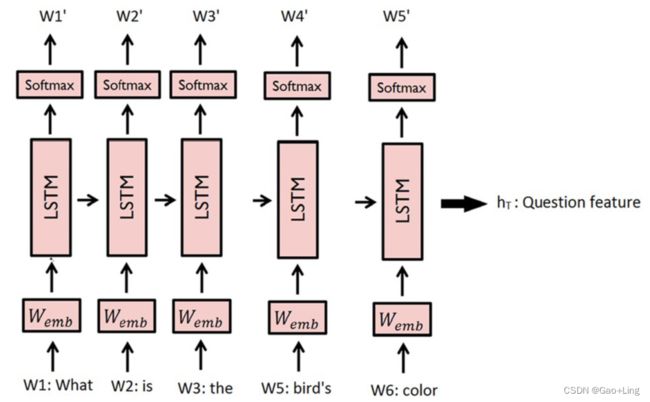
可以观察到,LSTM属于RNN家族,研究者主要使用它来表示问题。
Young et al.[24]声称RNN是基于序列的模型,其性能优于与词序列无关的模型,如word2vec。这些方法依赖于传统的词嵌入,因为由这些传统模型产生的向量被给出作为LSTM或GRU的输入。然而,这些模型需要大量的标记数据进行训练。在图7中,我们展示了一个包含信息流的LSTM网络。
数据集
DAQUAR[109](benchmark数据集,但数据集规模较小)
真实世界图像问答数据集(DAQUAR)[109]被设计为第一个主要的VQA数据集作为基准benchmark。它被认为是VQA任务中最小的数据集之一。它基于NYU-DepthV2 Dataset[114]图像; 共12468对问答,其中6795对问答用于train,5673对问答用于test。本数据集中的图像分为795张用于train,654张用于test,共包含1449张室内场景图像。总共有894个对象类object classes被分配到图像的每个像素。
DAQUAR-37数据集是DAQUAR的一个小版本,只包含37个对象类。它总共由4122对问答组成,其中3825对问答用于train,297对问答用于测试。这个数据集有一定的局限性。
首先,DAQUAR虽然是VQA任务的第一个数据集,但由于数据集规模小,无法有效训练和评估更高复杂性的VQA模型。
第二,可用的问题种类有限,因为这个数据集只包含室内场景。
第三,由于某些情况下极端的光照条件和杂乱的图像,许多问题都很难回答。
COCO-QA[50](包含四种类型的问题:对象(69.84%)、颜色(16.59%)、数字(7.47%)和位置(6.10%)。)
在COCO-QA[50]中,基于MS-COCO图像字幕,采用自然语言处理(NLP)算法生成QA对。MS-COCO数据集在一句话中包含对一个图像的5个描述。假设我们对一个女孩骑自行车的图像有一个标题,我们可以生成一个问题“这个女孩骑的是什么?”用自然语言回答,就像自行车一样。它由1,17684个问答对组成,其中78,736个QA对用于train,38,948个QA对用于测试。
本数据集中的问题大致属于四类:对象(69.84%)、颜色(16.59%)、数字(7.47%)和位置(6.10%)[9]。数据集中的图像总数为1,23,287张。
COCO-QA的主要局限性是使用NLP算法生成QA对,存在缺陷。COCO-QA中很多问题都有语法错误,很荒谬。另一个限制是由于自动从标题转换而产生的问题的高度重复。另一个主要的限制是数据集只包含四种类型的问题,而这些问题仅限于COCO的标题中描述的那一类问题。
the VQA dataset[11](一张图片对应三个问题,每个问题对应十个答案)
VQA数据集[11115]包括来自MS-COCO的真实图像和抽象剪贴画图像。它是VQA任务中使用最广泛的数据集,并作为VQA挑战的一部分公开发布。真实图像的VQA数据集总共包含6,14,163个问题,其中2,483,49个问题用于训练1,21,512个问题用于验证,2,44,302个问题用于测试。每张图片的问题都是由亚马逊土耳其机器人(AMT)生成的,这些问题的答案由不同的工作人员给出。这个数据集包括与一张图片对应的三个问题和与给定问题对应的十个答案。十个独立的注释者回答了给他们的每个问题。图像总数为2,04,721张。最长的问题由32个单词组成,最长的答案由20个单词组成。
剪贴画的VQA数据集由5万个抽象图像和1.5万个问题组成。这些抽象的图像是由20多个卡通人物模型制成的。100种不同的物品和30种不同的动物模型。
这个数据集有两种类型的图像,即真实和剪贴画图像的开放式和多项选择问题。选择题还提供了18个不同的选项。这些问题由相同的QA对组成。提供的选项包括:
正确答案:这是十个独立注释者给出的最常见的答案。
似是而非的答案:它由3个从独立的注释者那里收集来的答案组成。
热门答案:以下是数据集中最受欢迎的10个答案。
随机答案:对于其他类型的问题,这些是随机首选的正确答案。
然而,这个数据集有许多限制。首先,由于语言偏差,很多问题不考虑图像也能正确回答。例如,二元问题占所有问题的38%,其中59%的问题的答案是“是”。很难说算法是在真正解释VQA任务还是只是在猜测答案。
FM-IQA[55](答案是句子,问题需要进行常识性推理,数据集的QA对有中英文版本,问题和答案由人类给出,但是暂无好的评估方法)
自由式多语言图像问答(FM-IQA)[55]数据集基于MS-COCO。在这个数据集中,答案和问题都是由人类生成的。数据集中的QA对有中英文版本。它使用百度人群资源服务器构造问题和答案。本数据集中的答案是完整的句子。这个数据集包含了大量与人工智能相关的问题,这些问题需要在视觉内容上进行常识性推理(例如:“为什么公共汽车会停在这里?”)。这个数据集由158,392张图片和3,16,193对质量保证(QA)对组成,这些图片最初是中文版本,后来被翻译成英文。因此,使用通用度量的自动评估是困难的。因此,作者建议利用人类法官进行评估,其中法官被委托选择是否由人类给出适当的回答,并在0-2的范围内评估答案的性质。这种方法对大多数研究集会来说是不合逻辑的,并且使算法变得困难。
Visual Genome[110](问题类型:What, Where, How, When, Who, and Why。没有是/否问题)
Visual Genome数据集[110]包含108,249张图像,170万对图像可用QA对。对于一个图像,平均有17个QA对可用。视觉基因组是VQA任务中最大的数据集之一。在Visual Genome数据集中,问题可以以6个w '开头:What, Where, How, When, Who, and Why。该数据集通过两种不同的方式收集数据。对于开放式的自由形式问题,注释者可以问与图像相关的任何问题。
在这个数据集中,有两种类型的问题:特定型和自由形式的开放式问题。
在自由形式的问题中,人工注释者会看到一张图片,并被要求生成8对QA对。
在基于特定的问题中,人工注释人员必须为特定的情况提供QA对
与其他数据集相比,Visual Genome数据集的答案范围更大。在Visual Genome中有高概率出现的前1000个答案只覆盖了数据集中出现的所有答案的65%。数据集中存在的答案的多样性涉及到开放式问题评估的挑战。此外,由于问题类别本身被认为只属于六种“W”形式中的一种,回答的异质性有时可能只是人为地由措辞的差异造成的,而这种差异可以通过鼓励注释者选择更具描述性的回答来避免。此数据集没有二进制(是/否)问题。
Visual7W[12](七类问题:What,Where, How, When, Who, Why, and which。问题以选择题的形式进行评估,每个问题有四个候选答案,其中只有一个是正确的。)
Visual7W[12]数据集是Visual Genome数据集的一个子集。该数据集有来自Visual Genome的47,300张图像,也可在MS-COCO中获得。Visual7W包含七个问题类别:What,Where, How, When, Who, Why, and which。该数据集包括两种不同类型的问题。关于“telling”的问题与Visual Genome数据集中的问题相同,它们的回答都是基于文本的。以“Which”开头的问题被认为是“点”问题,系统将在这些问题可用的选项中选择准确的边界框。
在这个数据集中,问题以选择题的形式进行评估,每个问题有四个候选答案,其中只有一个是正确的。然而,所有在问题中列出的对象都是视觉基础的,即在图像中与其描述的边框对齐。同样,该数据集不像Visual Genome数据集那样包含二进制问题。
shapes[111]
SHAPES数据集[111]由各种排列、形状和颜色的对象组成。问题是关于形状的特征、关系和位置。它强调学习不同物体之间的空间和逻辑关系。这种方法使构建大量数据成为可能,不受许多不同程度影响其他数据集的限制。
SHAPES数据集由244个独特的问题和15616张图片组成。所有问题都是二元问题,只有是或否的答案。该数据集是完全平衡的,没有语言偏见。
KB-VQA[82]
FVQA[83]
Visual Madlibs[112](为了在“填空”任务上评估系统)
CLEVR[177](用于测试VQA模型的视觉推理能力)
FigureQA[208](线状图、点状图、水平和垂直柱状图以及饼状图)
FigureQA数据集包含5类图形图和图形。
这些类是线状图、点状图、水平和垂直柱状图以及饼状图。有15类问题用于寻找图中对象之间的不同关系。
这些问题可以用来检查诸如最大值、最小值、平滑度、区域下面积和交集等属性。
DVQA[209](仅用于评价柱状图的不同方面)
DVQA(数据可视化问答)是一个合成数据集,仅用于评价柱状图的不同方面。在这个数据集中有三类问题:结构理解、数据检索和推理。结构理解问题的例子是“这些条是垂直的吗?”数据检索问题的例子是“从右起第二个水平条的标签是什么?”数据检索问题的例子是“哪种算法对VQA数据集的准确率最高?”
Diagram[210](用于评价VQA系统的图解释能力)
Diagram (AI2D) dataset 主要用于评价VQA系统的图解释能力。它包含了5000多个代表小学科学的图表,每个图表都注释了组件分割,它们彼此之间的关联以及与图表画布的连接。在AI2D数据集中,有超过118 K个组件和53 K个关联的注释。与图表相关的选择题超过15000道。训练集有4000幅图像,盲测集有1000幅图像。
TDIUC[211](任务导向图像理解挑战)
TDIUC (Task Directed Image Understanding Challenge,任务导向图像理解挑战)数据集包括12种代表传统计算机视觉任务的问题类型和一组需要推理能力的新高级任务。是/否 object 存在检测相关问题得到平衡。该数据集包含荒谬的问题,以验证问题是否对给定的图像有效。TDIUC数据集中的问题来自COCO-VQA、Visual Genome和人类注释器。
VizWiz[122](处理盲人用户问题的面向目标的VQA数据集)
VizWiz是第一个处理盲人用户问题的面向目标的VQA数据集。它起源于视障用户。盲人用户拍摄的图像质量一般较差。数据集中的问题以口语形式收集,可能存在听觉缺陷。数据集中的许多问题是无法回答的,因为盲人用户无法验证捕获的图像及其视觉内容。
VQA- Med[128](医疗VQA数据集)
VQA- med数据集是迈向医疗领域VQA的第一步。VQAMed数据集包含带有与医学相关的问答对的医学图像。这项任务的成功提高了通过患者参与对医学图像的解读。此外,如果图像复杂,医生可以听取第二意见。采用半自动方法生成问答对。这些问题首先使用基于规则的方法生成,然后由人类专家进行手工验证。
ICQA[92]
在图标问题解答(ICQA)数据集中,大约有100个不同的30 × 30分辨率的互联网图标形状。它还为这些形状和它们的背景定义了21种不同的颜色。ICQA的作者创建了多组数据。集合A包含260840个问题,对应42021张图片。集合B包含226406个问题,对应42300张大图;集合C包含5408个问题,对应1000张大图(图34)。
场景文本阅读VQA模型的扩展
TextVQA的新数据集
Singh等人[105]提出了一个名为TextVQA的新数据集,包含28,408张图像上的45336个问题,需要对文本和视觉内容进行场景文本检测和推理来回答问题。
TextVQA从开放的图像数据集收集了所有的图像。它共有45,336个问题,其中有37,912个独特问题。在这个数据集中,问题的平均长度是7.18。问题的最小长度是3个。唯一的答案是26,263。它有21,953个训练图像,3166个验证图像和3289个测试集图像。提出了一种将普通VQA模型与独立训练的OCR模块相结合的新模型。这个模块有一个“拷贝”,它基于指针网络,允许在需要时使用OCR识别的单词作为预测答案。
场景文本VQA (ST-VQA)
Biten等人[106]提出了一种根据图像中出现的文本回答问题的方法。他们还提出了一个新的可视化问答数据集,称为场景文本VQA (ST-VQA)[23]。ST-VQA数据集包括来自不同公共数据集的图像,如ICDAR 2013[119]和ICDAR2015[120]、I ma e et[121]、V I z W I z[122]、IIIT场景文本检索[123]、V I u ag g N om e[110]和COCO-Text[124]。它包含了来自这六个数据集的23,038张图像,这些数据集都与通用计算机视觉数据集和场景文本理解数据集有关。它包含了来自这些数据集的总共31791个问题/答案对。其中19,027张图片和26308个问题用于训练,2993张图片和4163个问题用于测试。
OCR-VQA-200 K dataset
OCR-VQA-200 K dataset中的图像来自Iwana等人构建的数据集[171]。该数据集包含图书的封面图片、图书作者名称、书名和图书类别。书的类别可以是艺术、宗教、科学、漫画等。这些问题是通过询问与作者姓名、书名、版本等相关的问题来准备的。为了使疑问句发生变化,需要对疑问句进行释义。例如,“这本书的作者是谁?”可以转述为“谁写的这本书?””

评估指标(可参考)
simple accuracy
VQA任务中的问题可以是开放式的,系统必须生成一个字符串来回答问题,也可以是选择题,系统从给定的选项中选择一个选项。
当算法做出正确的选择,得到正确的答案时,可以使用简单精度来评估VQA任务的多项选择题。当算法给出的预测答案与地面真理答案完全匹配时,也可以使用简单精度来评估开放式VQA任务。
这种简单的精度度量有其局限性,因为它需要精确匹配。考虑一下关于图像的问题,“图像中出现了什么水果?”‘,算法输出’ apple ‘,但正确的标签是’ apples ‘,它被认为是错误的,当系统输出’ mango '时,它也同样被认为是错误的。

Wu-Palmer Similarity (WUPS)
第二个评价指标是Wu-Palmer Similarity (WUPS)[125],作为简单精度的替代品。该指标旨在评估算法预测的答案与数据集中可用的ground truth答案之间的差异,这取决于它们语义内涵的差异。基于它们之间的相似性,WUPS将根据数据集中的ground truth答案和算法对问题的预测答案在0到1之间分配值。例如,apple和apples的相似度为0.98,而apple和fruit的相似度为0.86。
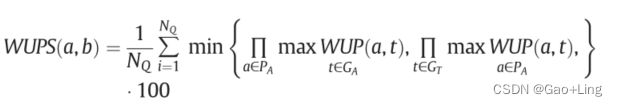
NQ : 问题总数,PA : 预测答案集,GA:ground-truth答案集,
WUP(a,b):它将基于分类树与最小公共子单元the Least Common Subsumer(a, b)位置的关系,返回单词’ ’ a ‘和’ b '的位置。
WUPS度量存在一定的局限性,使得其难以在VQA任务中使用。首先,某些词在词汇上非常相似,但它们的含义可能非常不同。这个问题可能出现在颜色问题上。例如,如果某个问题的答案是白色的,而系统预测答案是黑色的,这个答案仍然会得到0.92的WUPS分数,这似乎很高。另一个限制是,WUPS不能用于短语或句子的答案,因为它总是处理死板的语义概念,这些概念最有可能是单个单词。
用于VQA的accuracy
另一种评估VQA系统的方法是为每个问题收集多个独立的ground- truth answers。这被称为共识度量consensus metric。对VQA数据集[11]进行跟踪。在VQA数据集中,十个不同的受试者为每个问题收集了十个ground- truth answers。通过将生成的答案与10个不同的受试者给出的10个ground- truth answers进行比较,在VQA数据集上进行评估:

如果至少有三个被试提供了这个答案,那么这个答案就被认为是100%正确的。
这个指标也有一定的局限性:
- 首先,它可以为一些问题提供两个正确答案。
- 其次,为每个问题收集ground- truth answers是非常麻烦的。
- 第三,对于“why”这类问题,人与人之间的共识很差,因为很难让三个人给出完全相同的答案。
人工裁判
根据FM-IQA数据集开发人员的建议,VQA系统的另一种评估方法是使用人工裁判来评估多词答案。但这需要大量的时间和资源,而且非常昂贵。它可以包括参与过程的每个人的主观意见。在VQA数据集、Visual7W和Visual Genome中,多项选择范式可以作为评价多词答案的替代方法。在这种情况下,系统必须只选择给定选项中哪个是正确的,而不是生成一个答案。
mean -type (MPT)评价指标,归一化指标(算术归一化MPT和谐波归一化MPT)针对分布不均衡任务
VQA数据集的一个关键限制是问题类型分布的不平衡。对于较少见的题型,简单的准确性并不是有效的评价指标。因此,Kafle和Kanan (2017a)提出了一种mean -type (MPT)评价指标来处理不平衡的问卷类型分布。MPT表示评估的算术或调和平均精度为每个问题类型。他们还建议使用归一化指标,例如算术归一化MPT和谐波归一化MPT,以解决每个问题类型的答案分布的偏见。
平均归一化Levenshtein Similarity (ANLS)
[106]提出的度量是平均归一化Levenshtein Similarity (ANLS),定义为:
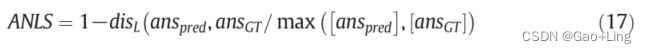
其中,(anspred和ansGT分别为预测答案和ground-truth答案,disL为编辑距离)对所有问题求平均值。在计算平均数之前,小于阈值0.5的分数被截断为0。
双语评价替补BiLingual Evaluation Understudy (BLEU)和 METEOR (Metric for Evaluation of Translation with Explicit ordered 显式排序翻译的评价指标)
双语评价替补BiLingual Evaluation Understudy (BLEU)由Papineni等人提出。采用Denkowski和Lavie(2014)提出的METEOR (Metric for Evaluation of Translation with Explicit ordered 显式排序翻译的评价指标)作为机器翻译自动评估的评价指标。
Gurari等人(2018)讨论了这两种指标都可以用于VQA任务,并使用VizWiz数据集进行了测试。BLEU检验了n-grams在ground truth标签和预测答案之间的共现情况。通常,它不适合在短句子中使用。另一方面,METEOR可以通过查找GT答案词和预测答案词之间的对齐来使用。有时,这种一对一的对应关系很难捕捉到。

一致性指标Consistency metric,有效性度量The validity metric,可信度评分The plausibility score,分布度量The distribution metric
一致性指标Consistency metric评估不同问题的回答一致性。当给出一个新问题时,VQA系统不会与之前的答案相矛盾。
有效性度量The validity metric验证给定的答案是否在问题范围内,例如以水果的形式回答与水果相关的问题。
可信度评分The plausibility score验证生成的答案是否合理或正当,给定的问题(例如,猫通常不喝酒,不说话,酒)。
分布度量The distribution metric 通过应用 Chi-Square statistic [207],计算gt答案分布与系统生成分布之间的校准[207]。这个指标用于分析模型是否同时预测了最常见的答案和不常见的答案。
F-measure
准确性并不是测量有偏差数据的有效方法。这意味着,如果我们在给定的输入数据中有任何一个类是正的或负的,那么准确性就不被接受为一个显著的度量。因此,我们采用F-measure来评价涉及精度和召回率的加权平均值。假设tp, tn, fp, and fn为连续的真正、真负、假正、假负,将单个问题答案与ground truth进行比较,F1测度可计算如下(F1 Score 需要最大化):
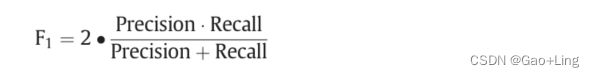


Results
Comparison of the SOTA methods on VQA 1.0 dataset

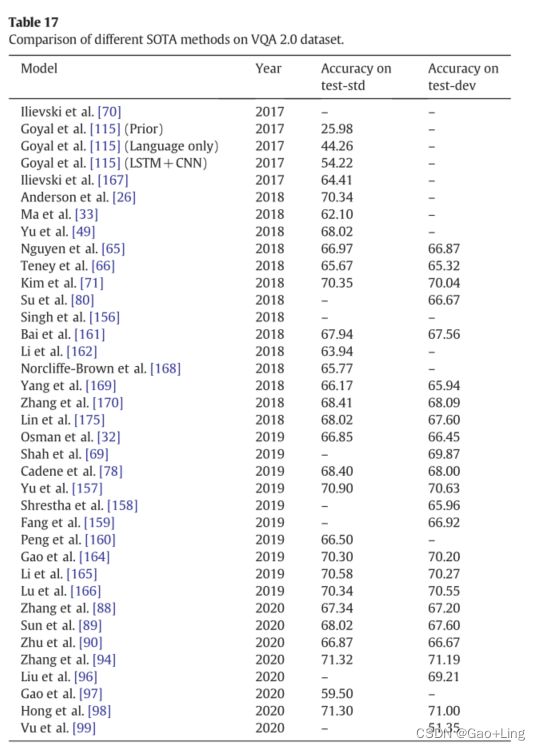
Comparison of the SOTA methods on VQA 2.0 dataset
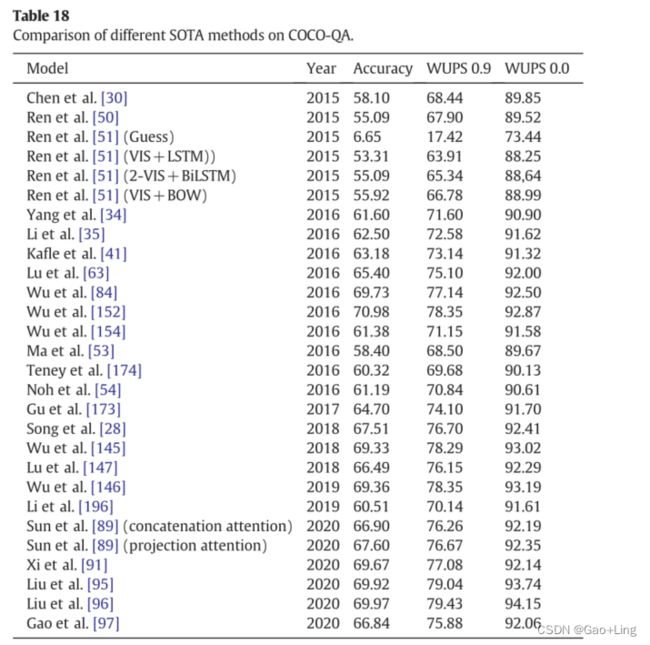
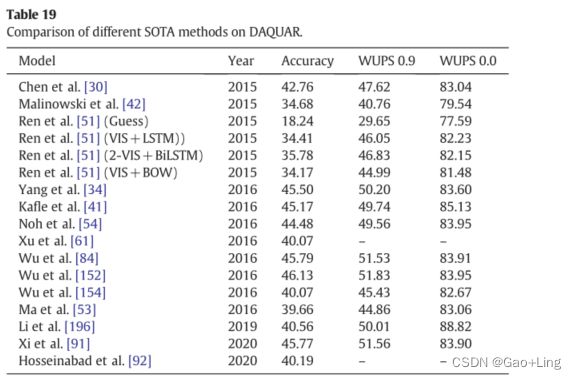
Comparison of the SOTA methods on COCO-QA and DAQAUAR datasets
Comparison of the SOTA methods on Visual7W and CLEVR datasets

Comparison of the SOTA methods on FVQA, Visual7W + KB and OK-VQA datasets
Comparison of the SOTA methods on GQA dataset
Comparison of the scene-text reading VQA models on TextVQA, ST-VQA and OCR-VQA datasets