机器学习——朴素贝叶斯分类
一贝叶斯原理
1.1贝叶斯原理产生背景:
贝叶斯原理是英国数学家托马斯·贝叶斯提出的,他写的一篇关于归纳推理的论文直接影响了接下来两个多世纪的统计学,是科学史上著名的论文之一。
贝叶斯原理是贝叶斯为了解决一个叫“逆向概率”问题写了一篇文章,尝试解答在没有太多可靠证据的情况下,怎样做出更符合数学逻辑的推测。
逆向概率,从字面意思理解,就是相对“正向概率”。
正向概率比较容易理解,例如:已知袋子里面有 N 个球,不是黑球就是白球,其中 M 个是黑球,那么把手伸进去摸一个球,就能知道摸出黑球的概率是多少。但这种情况往往是上帝视角,即我们了解了事情的全貌后再做判断。而在现实生活中,我们很难知道事情的全貌。贝叶斯则从实际场景出发,提了一个问题:如果我们事先不知道袋子里面黑球和白球的比例,而是通过我们摸出来的球的颜色,能判断出袋子里面黑白球的比例吗?还例如: 如果你看到一个人总是花钱,那么会推断这个人多半是个有钱人。当然这也不是绝对,也就是说,当你不能准确预知一个事物本质的时候,你可以依靠和事物本质相关的事件来进行判断,如果事情发生的频次多,则证明这个属性更有可能存在。
1.2贝叶斯原理涉及的概念及计算:
这实际上涉及到了贝叶斯原理中的几个概念:
①先验概率:通过经验来判断事情发生的概率,X的先验概率表示为P(X),Y的先验概率表示为P(Y)。
②后验概率:后验概率就是发生结果之后,推测原因的概率。
③条件概率:事件 A 在另外一个事件 B 已经发生条件下的发生概率,表示为 P(A|B),读作“在 B 发生的条件下 A 发生的概率”。
④似然函数(likelihood function): 概率模型的训练过程可以理解为求参数估计的过程,似然函数就是用来衡量这个模型的参数。似然在这里就是可能性的意思,它是关于统计参数的函数。
假如有两个事件A、B,如果已知A事件发生时B事件的发生概率P(B|A)以及A、B发生的概率P(A)、P(B),根据贝叶斯决策理论能计算出在B事件发生的条件下A事件的概率P(A|B).计算公式如下:

换个形式表达为:

例:
我们假设:A 表示事件 “测出为阳性”, 用 B1 表示“患有贝叶死”, B2 表示“没有患贝叶死”
已知: 患有贝叶死的情况下,测出为阳性的概率为 P(A|B1)=99.9%;没有患贝叶死,但测出为阳性的概率P(A|B2)=0.1%.在群体中,一个人患贝叶斯死的概率为0.01%,不患的概率为99.99%.
可知一人检测出来为阳性,并且它患贝叶死的概率为 P(B1∩A),它可以通过:

计算得出,概率为0.00999%
可得一个人在检查为阳性的情况下,患有贝叶死的概率,也即是 P(B1|A),可以通过:
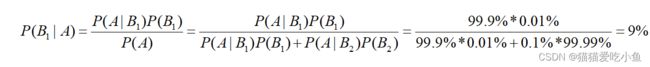
计算得出,概率为9%
即:后验概率=条件概率/全概率,实际上贝叶斯原理就是求解后验概率。
贝叶斯公式为:
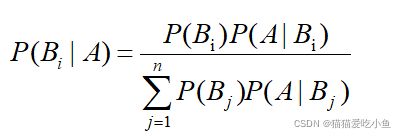
1.3贝叶斯分类:


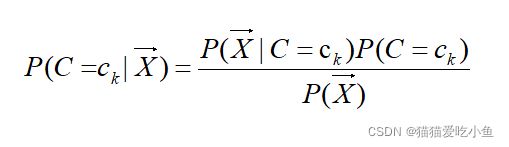

二朴素贝叶斯分类
2.1原理介绍:
朴素贝叶斯是一种简单但极为强大的预测建模算法 ,之所以称为朴素贝叶斯,是因为它假设每个输入变量是独立的。这是一个强硬的假设,实际情况并不一定,但是这项技术对于绝大部分的复杂问题仍然非常有效。朴素贝叶斯分类是一种有监督的分类算法,可以进行二分类,或者多分类。
朴素贝叶斯模型由两种类型的概率组成:
①每个类别的概率P(Cj);
②每个属性的条件概率P(Ai|Cj)。
例:在街上看到一个黑人,如果被问到他从哪里来的,我们十有八九会猜非洲。因为黑人中非洲人的比率最高,当然他也可能是美洲人或亚洲人,但是在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯以贝叶斯定理为基础。
2.2数学表达式:


就可以确定该样本的类别。对每个样本都进行相同的分类,这样对每个样本都有最大概率准确判断它的类别。
2.3算法步骤:
Step1:找出样本中出现的所有特征属性featList,并计算每种类别的概率Pi
Step2:把样本的特征向量转化为以featList相同长度的只包含0、1的向量,其中1代表该 样本中出现了featList中的该属性;0代表没有出现
Step3:计算每种类别的样本每个特征出现的概率
Step4:根据每个样本中的特征属性出现的情况计算它是每种类别的概率选出其中最大的作 为该样本的特征。
Step5:对数据集中所有样本进行分类,计算预测的准确率
训练过程就是基于训练集D来估计类先验概率P(c),并为每个属性估计条件概率
在实际的应用中,根据特征变量是离散的还是连续的,使用不同的模型处理,需要用到最大似然估计的估计方法。
2.4朴素贝叶斯常用的模型及应用情况:
①高斯模型:处理特征是连续型变量的情况
②多项式模型:最常见,要求特征是离散数据
③伯努利模型:要求特征是离散的,且为布尔类型,即true和false,或者1和0
在一些情况下,由于样本数据极度匮乏,很有可能出现某个特征的取值和某个类别的取值在训练集中从未同时出现过,这回造成对概率的估计等于0,这是不合理的,不能因为一个事没有观察到就认为该事件不会发生,所以需要给定一些虚假样本,需要用到平滑估计,称为拉普拉斯平滑。若特征是连续变量时,需要假设该条件概率分布的形式,在使用训练集求解
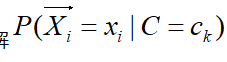
时,需要假设该条件概率分布的形式。一种常见的假设是认为对于给定,
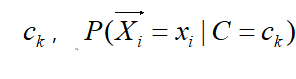
满足正态分布,而正态分布的均值和标准差需要从训练集学习得到。这样的模型称为高斯朴素贝叶斯分类器(Gaussian Naïve Bayes classifier)。
多项式朴素贝叶斯通常用于文本分类,其特征都是指待分类文本的单词出现次数或者频次。
2.5朴素贝叶斯为什么靠谱?:
由于条件独立性这个强假设的存在,朴素贝叶斯分类器十分简单。但是,它仍然有非常不错的效果。原因何在呢?人们在使用分类器之前,首先做的第一步(也是最重要的一步)往往是特征选择(feature selection),这个过程的目的就是为了排除特征之间的共线性、选择相对较为独立的特征。其次,当我们假设特征之间相互独立时,这事实上就暗含了正则化的过程;而不考虑变量之间的相关性有效的降低了朴素贝叶斯的分类方差。虽然这有可能提高分类的偏差,但是如果这样的偏差不改变样本的排列顺序,那么它对分类的结果影响不大。由于这些原因,朴素贝叶斯分类器在实际中往往能够取得非常优秀的结果。Hand and Yu (2001) 通过大量实际的数据表明了这一点。
2.6朴素贝叶斯的优缺点:
优点:
(1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
(2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
(3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
(1)理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
(2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
(3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
(4)对输入数据的表达形式很敏感。
三区别
贝叶斯原理、贝叶斯分类和朴素贝叶斯这三者之间是有区别的
贝 叶斯原理是最大的概念,它解决了概率论中“逆向概率”的问题,在这个理论基础上,人们设计出了贝叶斯分类器,朴素贝叶斯分类是贝叶斯分类器中的一种,也是最简单,最常用的分类器。朴素贝叶斯之所以朴素是因为它假设属性是相互独立的,因此对实际情况有所约束,如果属性之间存在关联,分类准确率会降低。不过好在对于大部分情况下,朴素贝叶斯的分类效果都不错。
它们的关系如图1:
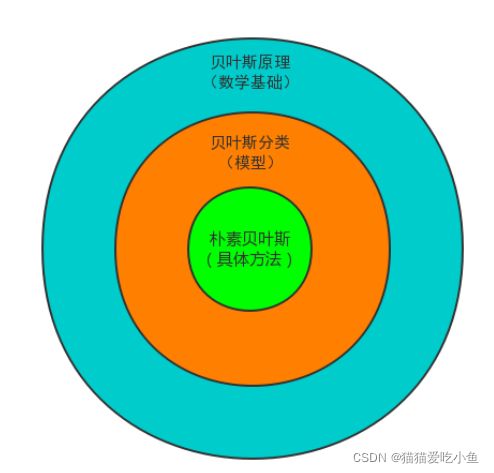
图1:关系图
四实际应用场景
朴素贝叶斯算法在文字识别, 图像识别方向有着较为重要的作用。 可以将未知的一种文字或图像,根据其已有的分类规则来进行分类,最终达到分类的目的。现实生活中朴素贝叶斯算法应用广泛,如文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等等。
应用场景4.1-------英文新闻分类:
算法流程图如图2下:
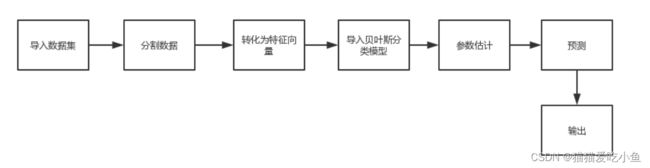
图2: 英文新闻分类流程图
步骤如下:
1.导入来源于sklearn.data的数据集(经典的20类新闻文本数据,20 Newsgroups corpus,约 20 000 篇新闻):
可知:本次下载的新闻共有18846条
输出第一条新闻,如图3:

图3:第一条新闻
2.对数据进行分割,并随机采样出一部分数据用于对训练模型进行测试
3.通过sklearn.feature_extraction.text 中的CountVectorizer模块进行特征提取。
因为这些文本数据没有数字化的量度,也没有具体的特征,所以需要对数据进行向量处理。
4.通过 sklearn.naive_bayes 导入 朴素贝叶斯分类模型(MultinomialNB),并对训练数据进行参数估计,再通过向量化后的测试数据进行预测。
5.使用准确率、召回率、精确率 和 F1指标对分类问题进行评估:
评估如图4:
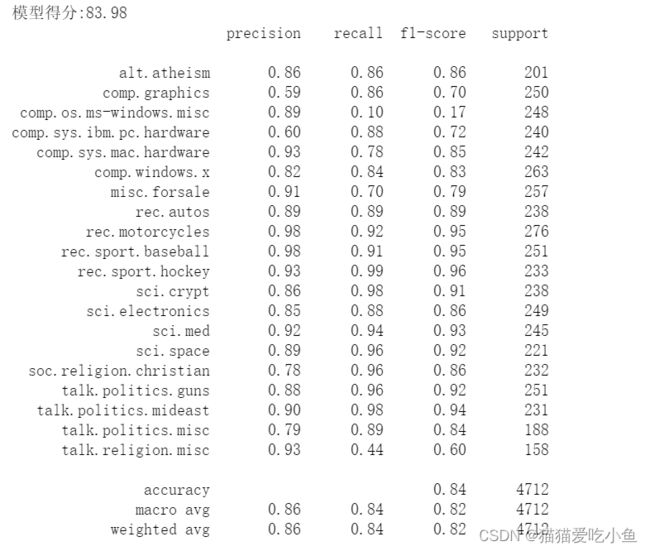
图4:分类评估结果
从上图中可以看出,朴素贝叶斯模型对4712条测试样本新闻进行分类的精确率为83.98%,平均的精确率(0.86)、召回率 (0.84)和 F1指标(0.82) 都在0.8以上,效果还不错。
由于其较强的特征条件独立假设,使得计算规模极大的降低,极大的降低资源消耗和时间开销,因此被广泛的用于海量的文本分类中。理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
应用场景4.2-------垃圾邮件:
流程图如图5:
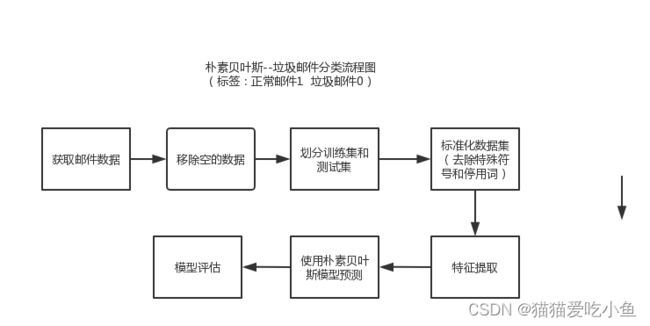
图5:垃圾邮件处理流程图
步骤:
1.获取数据集:
正常邮件存在ham_data.txt中,垃圾邮件存在spam_data.txt中j将正常数据标记为1,将垃圾数据标记为0,停用词存在stop_words.utf8中。
可知,总样本的数量为10001,其中一封邮件内容如图6:

图6:邮件信息
2.移除空的数据。
3.划分训练集和测试集。
4.标准化数据集,去除数据集中的分词,特殊符号和停用词之类的。
5.文本特征提取:
使用TfidfVectorizer()函数,TfidfVectorizer()基于Tf-idf进行特征提取
Tf-idf逆文档频率(Inverse Document Frequency,IDF):
如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词,
词频(TF) = 某个词在文章中的出现次数 / 该文词的个数
逆文档频率(IDF) = log(语料库的文档总数 / 包括该词的文档数 + 1),即这个参数越大,说明这个词越少见。
TF-IDF = 词频(TF) * 逆文档频率(IDF)
所以通过计算TF-IDF可较好地提取关键词
6. 导入贝叶斯模型,使用多项式贝叶斯进行分类
7.评估模型:
可得图7

图7:模型评估
准确率达到0.79,分类效果还不错。
应用场景3-------中文新闻分类:
简化流程图如图8:
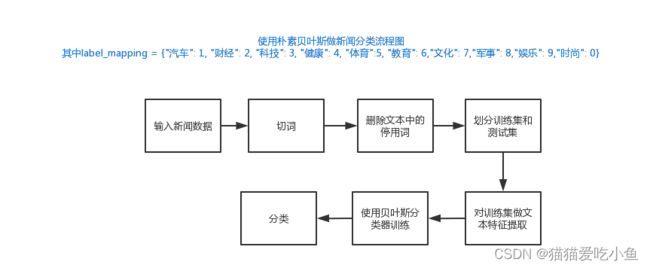
图8:中文新闻分类流程图
步骤如下:
1.导入新闻数据集,提取出标题,内容,URL和 和内容等信息:
将前五条新闻打印(含category,theme,URL,content等信息),结果如图8:

图8:中文新闻信息
2.使用jieba库分词器进行分词。
3.读取停用词表,去掉停用词,进行数据清洗:
停用词例如:! " #$%&'()*+,---...... ...... ................... ./.一 记者数年月日时分秒/ //012345
这些词语会在新闻中大量出现,但又没什么用的,所以需要清理。停用词库存在stopwords.txt中,存放了需要清理的停用词。
未清除停用词时如图9,清除停用词时如图10
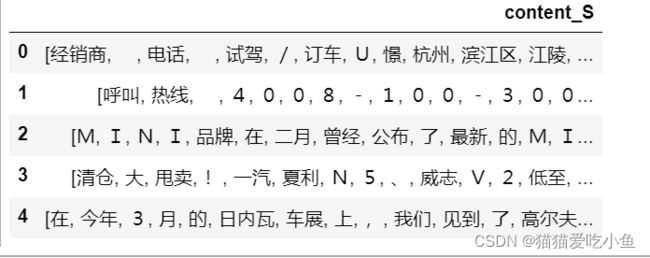 图9:未清除停用词时内容
图9:未清除停用词时内容

图10:清楚停用词后的内容
4.对新闻内容划分训练集和测试集:
其中,分类的标签为label_mapping = {"汽车": 1, "财经": 2, "科技": 3, "健康": 4, "体育":5, "教育": 6,"文化": 7,"军事": 8,"娱乐": 9,"时尚": 0}
5.对训练集做文本特征提取:
可以使用CountVectorizer()(计算词频),也可以使用TfidfVectorizer()(计算逆文档频率),本次应用发现TfidfVectorizer效果好一点,使用TfidfVectorizer,把原始文本转化为tf-idf的特征矩阵.
6.进行贝叶斯分类。
7.输出分类准确度。
模型评估如图11

图11:模型评估
分析:
分类的准确度达到了0.8152,说明效果十分不错,很有应用意义。由此可见,即使是一个非常简单的算法,只要能合理利用并进行大量高维数据训练,就可以获得意想不到的效果。
应用1.代码:
英文新闻分类代码,从sklearn.datasets获取数据集
from sklearn.datasets import fetch_20newsgroups
news_data = fetch_20newsgroups(subset = 'all')
print("本次下载的新闻条数为:",len(news_data.data))
print("第一篇文章内容的字符数量为:",len(news_data.data[0]))
print(news_data.data[0])
x = news_data.data
y = news_data.target
from sklearn.model_selection import train_test_split
#from sklearn.cross_validation import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25,random_state=33)
from sklearn.feature_extraction.text import CountVectorizer
#文本数据向量化
vec = CountVectorizer()
x_train=vec.fit_transform(x_train)
x_test=vec.transform(x_test)
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB() #初始化模型
model.fit(x_train,y_train) #调用fit函数进行模型训练
y_predict = model.predict(x_test) #使用predict 函数进行预测
from sklearn.metrics import classification_report
print("模型得分:%.2f" % (float(model.score(x_test,y_test))*100))
print(classification_report(y_test,y_predict,target_names= news_data.target_names))
应用2.代码:
垃圾邮件过滤代码,数据集为ham_data.txt和spam_data.txt和stop_words.utf8中。
import numpy as np
from sklearn.model_selection import train_test_split
# 获取数据函数定义
def get_data():
with open("E://laji//ham_data.txt", encoding="utf8") as ham_f, open("E://laji//spam_data.txt", encoding="utf8") as spam_f:
# 正常的邮件数据
ham_data = ham_f.readlines()
# 垃圾邮件数据
spam_data = spam_f.readlines()
# 正常数据标记为1
ham_label = np.ones(len(ham_data)).tolist()#将数组或者矩阵转化成列表
# 垃圾邮件数据标记为0
spam_label = np.zeros(len(spam_data)).tolist()
# 数据集集合
corpus = ham_data + spam_data
# 标记数据集合
labels = ham_label + spam_label
return corpus, labels
# 数据分割函数定义
def prepare_datasets(corpus, labels, test_data_proportion=0.3):
train_X, test_X, train_Y, test_Y = train_test_split(corpus, labels,
test_size=test_data_proportion, random_state=42)
return train_X, test_X, train_Y, test_Y
# 移除空的数据函数定义
def remove_empty_docs(corpus, labels):
filtered_corpus = []
filtered_labels = []
for doc, label in zip(corpus, labels):
if doc.strip():
filtered_corpus.append(doc)
filtered_labels.append(label)
return filtered_corpus, filtered_labels
# 获取数据集
corpus, labels = get_data()
print("总的数据量:", len(labels))
corpus, labels = remove_empty_docs(corpus, labels)
print('样本之一:', corpus[10])
print('样本的label:', labels[10])
label_name_map = ["垃圾邮件", "正常邮件"]
print('实际类型:', label_name_map[int(labels[10])], label_name_map[int(labels[5900])])
# 对数据进行划分
train_corpus, test_corpus, train_labels, test_labels = prepare_datasets(corpus,
labels,
test_data_proportion=0.3)
# 归一化函数定义
import re
import string
import jieba
# 加载停用词
with open("E://laji//stop_words.utf8", encoding="utf8") as f:
stopword_list = f.readlines()
# 分词
def tokenize_text(text):
tokens = jieba.cut(text)
tokens = [token.strip() for token in tokens]
return tokens
# 去掉特殊符号
def remove_special_characters(text):
tokens = tokenize_text(text)
pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))#匹配特殊字符
filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens])
filtered_text = ' '.join(filtered_tokens)
return filtered_text
# 取出停用词
def remove_stopwords(text):
tokens = tokenize_text(text)
filtered_tokens = [token for token in tokens if token not in stopword_list]
filtered_text = ''.join(filtered_tokens)
return filtered_text
# 标准化数据集
def normalize_corpus(corpus, tokenize=False):
# 声明一个变量用来存储标准化后的数据
normalized_corpus = []
for text in corpus:
# 去掉特殊符号
text = remove_special_characters(text)
# 取出停用词
text = remove_stopwords(text)
normalized_corpus.append(text)
if tokenize:
text = tokenize_text(text)
normalized_corpus.append(text)
return normalized_corpus
# 进行归一化
norm_train_corpus = normalize_corpus(train_corpus)
norm_test_corpus = normalize_corpus(test_corpus)
# 特征提取
import gensim
import jieba
from gensim import corpora, models, similarities
from sklearn.feature_extraction.text import TfidfVectorizer
def tfidf_extractor(corpus, ngram_range=(1, 1)):
vectorizer = TfidfVectorizer(min_df=1,
norm='l2',
smooth_idf=True,
use_idf=True,
ngram_range=ngram_range)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
# tfidf 特征 标准化后的数据送入函数进行提取
tfidf_vectorizer, tfidf_train_features = tfidf_extractor(norm_train_corpus)
tfidf_test_features = tfidf_vectorizer.transform(norm_test_corpus)
# 导入贝叶斯模型
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
from sklearn import metrics
# 模型性能预测函数
def get_metrics(true_labels, predicted_labels):
print('准确率:', np.round(
metrics.accuracy_score(true_labels,
predicted_labels),
2))
print('精度:', np.round(
metrics.precision_score(true_labels,
predicted_labels,
average='weighted'),
2))
print('召回率:', np.round(
metrics.recall_score(true_labels,
predicted_labels,
average='weighted'),
2))
print('F1得分:', np.round(
metrics.f1_score(true_labels,
predicted_labels,
average='weighted'),
2))
# 模型调用函数,这样做的好处是,可以自己人选模型
def train_predict_evaluate_model(classifier,
train_features, train_labels,
test_features, test_labels):
# 模型构建
classifier.fit(train_features, train_labels)
# 使用哪个模型做预测
predictions = classifier.predict(test_features)
# 评估模型预测性能
get_metrics(true_labels=test_labels,
predicted_labels=predictions)
return predictions
# 基于tfidf的多项式朴素贝叶斯模型
print("基于tfidf的贝叶斯模型")
mnb_tfidf_predictions = train_predict_evaluate_model(classifier=mnb,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)应用3.代码:
#中文新闻分类代码,使用数据集为val.txt和stopwords.txt
import pandas as pd
import numpy as np
import jieba
#导入数据
df_news = pd.read_table('E://xinwen//val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna()#删除缺少数据的记录
df_news.head() #读取前5行
#使用jieba分词器分词
#先将content转换成list格式
content = df_news.content.values.tolist()
#输出第五条新闻未切词前的内容
print (content[4])
content_S = []
#按新闻内容进行切词
for line in content:
current_segment = jieba.lcut(line)
if len(current_segment) > 1 and current_segment != '\r\n':
content_S.append(current_segment)
#输出第5条新闻切词后
content_S[4]
#可做可不做
#DataFrame处理
#df_content=pd.DataFrame({'content_S':content_S})
#查看前5条内容
#df_content.head()
#读取停词表
stopwords=pd.read_csv("E://xinwen//stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'], encoding='utf-8')
stopwords.head(20)
#删除停用词的函数
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
#print (contents_clean)
#转化为list
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
#删除停用词,记录有用的单词
contents_clean,all_words = drop_stopwords(contents,stopwords)
#可做可不做
#DataFrame处理
#df_content=pd.DataFrame({'contents_clean':contents_clean})
#打印前5条去除了停用词的新闻内容
#df_content.head()
df_train=pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
label_mapping = {"汽车": 1, "财经": 2, "科技": 3, "健康": 4, "体育":5, "教育": 6,"文化": 7,"军事": 8,"娱乐": 9,"时尚": 0}
df_train['label'] = df_train['label'].map(label_mapping)
#df_train.head()
from sklearn.model_selection import train_test_split
#划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(df_train['contents_clean'].values, df_train['label'].values, random_state=1)
words = []
for line_index in range(len(x_train)):
try:
words.append(' '.join(x_train[line_index]))
except:
print (line_index,word_index)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
#文本特征提取
vec = TfidfVectorizer(analyzer='word', max_features=4000, lowercase = False)
#vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False)
vec.fit(words)
#引入多项式贝叶斯
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(words), y_train)
test_words = []
for line_index in range(len(x_test)):
try:
test_words.append(' '.join(x_test[line_index]))
except:
print (line_index,word_index)
classifier.score(vec.transform(test_words), y_test)