利用Lucene.net实现全文搜索
- Lucene.net
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,它提供了完整的查询引擎和索引引擎,可供开发人员灵活的实现全文检索功能。Lucene.net是Apache软件基金会赞助的开源项目,最新版本是2.9.2.2。
使用Lucene.net进行全文索引的关键步骤是建立索引文件:先选择一个分析器(Analyzer)用来分词,再抽取待索引文档中的文本,选择适当的索引方式并添加到Lucene.net索引中。
- 分词
分词是全文索引的基础。
Lucene.net内置了几个分析器,但功能都比较简单,如果只是针对拉丁语系的分词完全够用,但针对中文的分词就不太理想。
中文分词常用的几种方式有:单字分词、二元分词、词库分词。
Lucene.net内置的
StandardAnalyzer类就是单字分词。而其他几个内置的分析器功能更简单,如:
KeywordAnalyzer、
SimpleAnalyze、
StopAnalyzer、
WhitespaceAnalyzer,一般不会使用。
可以自行开发分析器进行分词,以实现二元分词或更复杂的词库分词功能,也可以利用第三方提供的中文分词。比如:博客园
eaglet的盘古分词组件
PanGuSegment,是一款基于字典的中英文分词算法,可以用来实现词库分词功能的分析器。
 PanGuAnalyzer
PanGuAnalyzer

1
using
Lucene.Net.Analysis;
2 using PanGu;
3
4 namespace LuceneTest
5 {
6 public class PanGuAnalyzer : Analyzer
7 {
8 public PanGuAnalyzer()
9 {
10 }
11
12 public override TokenStream TokenStream( string fieldName, TextReader reader)
13 {
14 TokenStream result = new PanGuTokenizer(reader);
15 result = new LowerCaseFilter(result);
16 return result;
17 }
18 }
19
20 public class PanGuTokenizer : Tokenizer
21 {
22 static object _LockObj = new object ();
23 static bool _Inited = false ;
24
25 WordInfo[] _WordList;
26 int _Position = - 1 ;
27 string _InputText;
28
29 static private void InitPanGuSegment()
30 {
31 if ( ! _Inited)
32 {
33 PanGu.Segment.Init();
34 _Inited = true ;
35 }
36 }
37
38 public PanGuTokenizer()
39 {
40 lock (_LockObj)
41 {
42 InitPanGuSegment();
43 }
44 }
45
46 public PanGuTokenizer(TextReader input)
47 : base (input)
48 {
49 lock (_LockObj)
50 {
51 InitPanGuSegment();
52 }
53
54 _InputText = base .input.ReadToEnd();
55
56 if ( string .IsNullOrEmpty(_InputText))
57 {
58 _WordList = new WordInfo[ 0 ];
59 }
60 else
61 {
62 PanGu.Segment segment = new Segment();
63 ICollection < WordInfo > wordInfos = segment.DoSegment(_InputText);
64 _WordList = new WordInfo[wordInfos.Count];
65 wordInfos.CopyTo(_WordList, 0 );
66 }
67 }
68
69 public override Token Next()
70 {
71 int length = 0 ; // 词汇的长度.
72 int start = 0 ; // 开始偏移量.
73
74 while ( true )
75 {
76 _Position ++ ;
77 if (_Position < _WordList.Length)
78 {
79 if (_WordList[_Position] != null )
80 {
81 length = _WordList[_Position].Word.Length;
82 start = _WordList[_Position].Position;
83 return new Token(_WordList[_Position].Word, start, start + length);
84 }
85 }
86 else
87 {
88 break ;
89 }
90 }
91
92 _InputText = null ;
93 return null ;
94 }
95 }
96 }
2 using PanGu;
3
4 namespace LuceneTest
5 {
6 public class PanGuAnalyzer : Analyzer
7 {
8 public PanGuAnalyzer()
9 {
10 }
11
12 public override TokenStream TokenStream( string fieldName, TextReader reader)
13 {
14 TokenStream result = new PanGuTokenizer(reader);
15 result = new LowerCaseFilter(result);
16 return result;
17 }
18 }
19
20 public class PanGuTokenizer : Tokenizer
21 {
22 static object _LockObj = new object ();
23 static bool _Inited = false ;
24
25 WordInfo[] _WordList;
26 int _Position = - 1 ;
27 string _InputText;
28
29 static private void InitPanGuSegment()
30 {
31 if ( ! _Inited)
32 {
33 PanGu.Segment.Init();
34 _Inited = true ;
35 }
36 }
37
38 public PanGuTokenizer()
39 {
40 lock (_LockObj)
41 {
42 InitPanGuSegment();
43 }
44 }
45
46 public PanGuTokenizer(TextReader input)
47 : base (input)
48 {
49 lock (_LockObj)
50 {
51 InitPanGuSegment();
52 }
53
54 _InputText = base .input.ReadToEnd();
55
56 if ( string .IsNullOrEmpty(_InputText))
57 {
58 _WordList = new WordInfo[ 0 ];
59 }
60 else
61 {
62 PanGu.Segment segment = new Segment();
63 ICollection < WordInfo > wordInfos = segment.DoSegment(_InputText);
64 _WordList = new WordInfo[wordInfos.Count];
65 wordInfos.CopyTo(_WordList, 0 );
66 }
67 }
68
69 public override Token Next()
70 {
71 int length = 0 ; // 词汇的长度.
72 int start = 0 ; // 开始偏移量.
73
74 while ( true )
75 {
76 _Position ++ ;
77 if (_Position < _WordList.Length)
78 {
79 if (_WordList[_Position] != null )
80 {
81 length = _WordList[_Position].Word.Length;
82 start = _WordList[_Position].Position;
83 return new Token(_WordList[_Position].Word, start, start + length);
84 }
85 }
86 else
87 {
88 break ;
89 }
90 }
91
92 _InputText = null ;
93 return null ;
94 }
95 }
96 }
- 索引
Lucene.net使用的是倒排索引(Inverted Index)技术,搜索引擎都在使用倒排索引。简单来讲,传统的索引是“文档-->关键词”,而倒排索引则是“关键词-->文档”。
在
Lucene.net索引中的最小单位是词(
Term),多个词组成一个字段(
Filed),多个字段再组成一个文档(
Document)。在索引建立过程中,开发者需要将待索引的文本写入具体字段中,再生成文档,写入
Lucene.net索引中。而更进一步的分词处理则由分析器负责。
创建索引时,有一些具体的方式需要选择:
1.索引存储方式
FSDirectory:存放到硬盘,将索引持久化;
RAMDirectory:索引存放到内存,访问速度更快。
2.字段的存储方式
YES:存储;
COMPRESS:压缩存储,依赖于
ICSharpCode的
SharpZipLib.dll组件,在索引文件有一定规模的时候可以压缩内容;
NO:不存储,可以减少索引文件的大小,但不存储到索引文件,只能去数据源读取。
3. 字段的分析方式
NO:不建立索引,不能对此字段进行搜索;
ANALYZED:分词后索引;
NOT_ANALYZED:不分词,直接索引完整内容;
ANALYZED_NO_NORMS:分词后索引,但不存储一些额外的信息,可以节省一些空间;
NOT_ANALYZED_NO_NORMS:不分词索引,也不存储额外的信息。
下面利用上节实现的分析器,针对某个目录下所有的文本文件内容创建索引文件。
创建索引
1
using
Lucene.Net.Documents;
2 using Lucene.Net.Index;
3 using Lucene.Net.Store;
4 using Lucene.Net.Util;
5 using Lucene.Net.Analysis;
6
7 namespace LuceneTest
8 {
9 class Program
10 {
11 // 索引存放位置
12 public static String INDEX_STORE_PATH = @" F:\ TestPath\Index " ;
13 // 数据位置
14 public static String DATA_PATH = @" F:\ TestPath\Data " ;
15
16 static IndexWriter fsWriter = null ;
17
18 static void Main( string [] args)
19 {
20 Boolean rebuild = true ;
21 FSDirectory fsDir = FSDirectory.Open( new DirectoryInfo(INDEX_STORE_PATH));
22 Analyzer analyser = new PanGuAnalyzer();
23 fsWriter = new IndexWriter(fsDir, analyser, rebuild, IndexWriter.MaxFieldLength.UNLIMITED);
24
25 Stopwatch watch = new Stopwatch();
26 watch.Start();
27
28 int count = IndexFiles( new FileInfo(DATA_PATH));
29
30 fsWriter.Optimize();
31 fsWriter.Close();
32
33 watch.Stop();
34
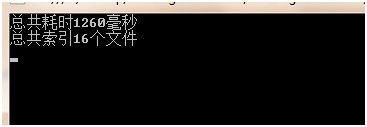
35 Console.WriteLine( " 总共耗时{0}毫秒 " , watch.ElapsedMilliseconds);
36 Console.WriteLine( " 总共索引{0}个文件 " , count);
37
38 Console.ReadLine();
39 }
40
41 static int IndexFiles(FileInfo file)
42 {
43 int num = 0 ;
44
45 if (System.IO.Directory.Exists(file.FullName))
46 {
47 // 处理文件
48 var files = System.IO.Directory.GetFiles(file.FullName).Select(f => new FileInfo(f));
49 if (files != null )
50 {
51 foreach (var f in files)
52 {
53 if (f.Extension.Equals( " .txt " ))
54 {
55 fsWriter.AddDocument(getDocument(f));
56 num ++ ;
57 }
58 }
59 }
60
61 // 处理目录
62 var directorys = System.IO.Directory.GetDirectories(file.FullName).Select(d => new FileInfo(d));
63 if (directorys != null )
64 {
65 foreach (var d in directorys)
66 {
67 num += IndexFiles(d);
68 }
69 }
70 }
71
72 return num;
73 }
74
75 static Document getDocument(FileInfo file)
76 {
77 Document doc = new Document();
78
79 // 文件路径
80 doc.Add( new Field( " path " , file. FullName, Field.Store.YES, Field.Index.NOT_ANALYZED));
81
82 // 文件名
83 doc.Add( new Field( " title " , file.Name, Field.Store.YES, Field.Index.ANALYZED));
84
85 // 文件内容
86 string content = new StreamReader(file.FullName, Encoding.Default).ReadToEnd();
87 doc.Add( new Field( " content " , content, Field.Store.NO, Field.Index.ANALYZED));
88
89 return doc;
90 }
91 }
92 }
2 using Lucene.Net.Index;
3 using Lucene.Net.Store;
4 using Lucene.Net.Util;
5 using Lucene.Net.Analysis;
6
7 namespace LuceneTest
8 {
9 class Program
10 {
11 // 索引存放位置
12 public static String INDEX_STORE_PATH = @" F:\ TestPath\Index " ;
13 // 数据位置
14 public static String DATA_PATH = @" F:\ TestPath\Data " ;
15
16 static IndexWriter fsWriter = null ;
17
18 static void Main( string [] args)
19 {
20 Boolean rebuild = true ;
21 FSDirectory fsDir = FSDirectory.Open( new DirectoryInfo(INDEX_STORE_PATH));
22 Analyzer analyser = new PanGuAnalyzer();
23 fsWriter = new IndexWriter(fsDir, analyser, rebuild, IndexWriter.MaxFieldLength.UNLIMITED);
24
25 Stopwatch watch = new Stopwatch();
26 watch.Start();
27
28 int count = IndexFiles( new FileInfo(DATA_PATH));
29
30 fsWriter.Optimize();
31 fsWriter.Close();
32
33 watch.Stop();
34
35 Console.WriteLine( " 总共耗时{0}毫秒 " , watch.ElapsedMilliseconds);
36 Console.WriteLine( " 总共索引{0}个文件 " , count);
37
38 Console.ReadLine();
39 }
40
41 static int IndexFiles(FileInfo file)
42 {
43 int num = 0 ;
44
45 if (System.IO.Directory.Exists(file.FullName))
46 {
47 // 处理文件
48 var files = System.IO.Directory.GetFiles(file.FullName).Select(f => new FileInfo(f));
49 if (files != null )
50 {
51 foreach (var f in files)
52 {
53 if (f.Extension.Equals( " .txt " ))
54 {
55 fsWriter.AddDocument(getDocument(f));
56 num ++ ;
57 }
58 }
59 }
60
61 // 处理目录
62 var directorys = System.IO.Directory.GetDirectories(file.FullName).Select(d => new FileInfo(d));
63 if (directorys != null )
64 {
65 foreach (var d in directorys)
66 {
67 num += IndexFiles(d);
68 }
69 }
70 }
71
72 return num;
73 }
74
75 static Document getDocument(FileInfo file)
76 {
77 Document doc = new Document();
78
79 // 文件路径
80 doc.Add( new Field( " path " , file. FullName, Field.Store.YES, Field.Index.NOT_ANALYZED));
81
82 // 文件名
83 doc.Add( new Field( " title " , file.Name, Field.Store.YES, Field.Index.ANALYZED));
84
85 // 文件内容
86 string content = new StreamReader(file.FullName, Encoding.Default).ReadToEnd();
87 doc.Add( new Field( " content " , content, Field.Store.NO, Field.Index.ANALYZED));
88
89 return doc;
90 }
91 }
92 }
- 搜索
Lucene.net的搜索和索引是相互独立的,可以分开部署,但搜索必须利用生成的索引。
搜索的关键点是构建搜索表达式(
Query)。首先利用分析器对搜索词进行分词,再将分词进行组合得到具体的搜索表达式。默认是将分词结果进行“与”组合。
开发者也可以直接使用运算符编写表达式进行更复杂规则的搜索,或者可以利用
Lucene.net内置的很多
Query子类以辅助搜索查询,如:
BooleanQuery、
ConstantScoreQuery、
DisjunctionMaxQuery、
MatchAllDocsQuery等等。
下面针对上节创建的索引文件进行简单的全文搜索。
全文搜索
1
using
Lucene.Net.Analysis;
2 using Lucene.Net.Documents;
3 using Lucene.Net.Index;
4 using Lucene.Net.QueryParsers;
5 using Lucene.Net.Store;
6 using Lucene.Net.Search;
7
8 namespace LuceneClient
9 {
10 class Program
11 {
12 // 索引存放位置
13 public static String INDEX_STORE_PATH = @" F:\ TestPath\Index " ;
14
15 static void Main( string [] args)
16 {
17 bool ReadOnly = true ;
18 FSDirectory fsDir = FSDirectory.Open( new DirectoryInfo(INDEX_STORE_PATH));
19 IndexSearcher searcher = new IndexSearcher(IndexReader.Open(fsDir, ReadOnly));
20
21 Stopwatch watch = new Stopwatch();
22 watch.Start();
23
24 bool InOrder = true ;
25 ScoreDoc[] scoreDoc = Search(searcher, " Geneva框架 " , " content " , 10 , InOrder);
26
27 watch.Stop();
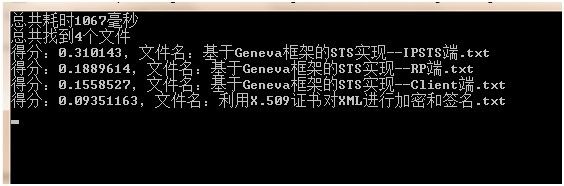
28 Console.WriteLine( " 总共耗时{0}毫秒 " , watch.ElapsedMilliseconds);
29 Console.WriteLine( " 总共找到{0}个文件 " , scoreDoc.Count());
30
31 foreach (var docs in scoreDoc)
32 {
33 Document doc = searcher.Doc(docs.doc);
34 Console.WriteLine( " 得分:{0},文件名:{1} " , docs.score, doc.Get( " title " ));
35 }
36
37
38 searcher.Close();
39
40 Console.ReadLine();
41 }
42
43 static ScoreDoc[] Search(IndexSearcher searcher, string queryString, string field, int numHit, bool inOrder)
44 {
45 TopScoreDocCollector collector = TopScoreDocCollector.create(numHit, inOrder);
46
47 Analyzer analyser = new LuceneTest.PanGuAnalyzer();
48
49 QueryParser parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_29, field, analyser);
50
51 Query query = parser.Parse(queryString);
52
53 searcher.Search(query, collector);
54
55 return collector.TopDocs().scoreDocs;
56 }
57 }
58 }
2 using Lucene.Net.Documents;
3 using Lucene.Net.Index;
4 using Lucene.Net.QueryParsers;
5 using Lucene.Net.Store;
6 using Lucene.Net.Search;
7
8 namespace LuceneClient
9 {
10 class Program
11 {
12 // 索引存放位置
13 public static String INDEX_STORE_PATH = @" F:\ TestPath\Index " ;
14
15 static void Main( string [] args)
16 {
17 bool ReadOnly = true ;
18 FSDirectory fsDir = FSDirectory.Open( new DirectoryInfo(INDEX_STORE_PATH));
19 IndexSearcher searcher = new IndexSearcher(IndexReader.Open(fsDir, ReadOnly));
20
21 Stopwatch watch = new Stopwatch();
22 watch.Start();
23
24 bool InOrder = true ;
25 ScoreDoc[] scoreDoc = Search(searcher, " Geneva框架 " , " content " , 10 , InOrder);
26
27 watch.Stop();
28 Console.WriteLine( " 总共耗时{0}毫秒 " , watch.ElapsedMilliseconds);
29 Console.WriteLine( " 总共找到{0}个文件 " , scoreDoc.Count());
30
31 foreach (var docs in scoreDoc)
32 {
33 Document doc = searcher.Doc(docs.doc);
34 Console.WriteLine( " 得分:{0},文件名:{1} " , docs.score, doc.Get( " title " ));
35 }
36
37
38 searcher.Close();
39
40 Console.ReadLine();
41 }
42
43 static ScoreDoc[] Search(IndexSearcher searcher, string queryString, string field, int numHit, bool inOrder)
44 {
45 TopScoreDocCollector collector = TopScoreDocCollector.create(numHit, inOrder);
46
47 Analyzer analyser = new LuceneTest.PanGuAnalyzer();
48
49 QueryParser parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_29, field, analyser);
50
51 Query query = parser.Parse(queryString);
52
53 searcher.Search(query, collector);
54
55 return collector.TopDocs().scoreDocs;
56 }
57 }
58 }